

Les marchés financiers génèrent d’énormes quantités de données chaque seconde. Le NASDAQ est l’une des plus grandes bourses du monde, accueillant de grandes entreprises comme Apple, Microsoft, Tesla et Amazon.
Si vous créez des algorithmes de trading, des tableaux de bord de recherche ou des applications fintech, la collecte de ces données financières présente à la fois des opportunités significatives et des défis techniques. Ce guide présente trois méthodes éprouvées pour collecter les données financières du NASDAQ : l’accès direct à l’API via des points d’extrémité internes, la mise en œuvre d’une infrastructure de proxy d’entreprise pour la mise à l’échelle et l’utilisation du web scraping alimenté par l’IA avec le protocole MCP (Model Context Protocol).
Comprendre le paysage des données du NASDAQ
Le NASDAQ fournit des données de marché complètes qui sont parfaites pour la recherche, le backtesting et les applications analytiques. Voici ce à quoi vous pouvez généralement accéder :
- Données sur les prix – dernier cours, cours le plus haut/le plus bas du jour, cours d’ouverture/de clôture, volume des transactions et variations en pourcentage pour les actions cotées en bourse.
- Données historiques – données quotidiennes OHLC (Open, High, Low, Close), historique des dividendes, divisions d’actions et volumes de transactions historiques.
- Informations sur les entreprises – informations de base sur les entreprises, classifications sectorielles et liens vers les dossiers SEC et les actualités sur les entreprises.
- Fonctionnalités supplémentaires – graphiques interactifs, calendriers des résultats et données sur les participations institutionnelles
Les traders et les investisseurs utilisent le backtesting pour analyser les performances historiques des stratégies avant de les mettre en œuvre dans le cadre de transactions réelles. Les entreprises exploitent ces données de marché à des fins de veille concurrentielle, ce qui leur permet de suivre l’activité de leurs concurrents et d’identifier les tendances et les opportunités du marché. Pour des scénarios plus avancés, découvrez nos cas d’utilisation des données financières.
Voyons maintenant comment récupérer ces données.
Méthodologie d’extraction des données
Les sites financiers modernes tels que NASDAQ, yahoo finance et google finance sont construits comme des applications à page unique qui utilisent JavaScript pour rendre le contenu dynamique. Au lieu d’analyser du HTML fragile, il est plus robuste d’appeler directement les points d’extrémité de leur API JSON interne, car les réponses JSON sont plus propres et plus stables.
Voici comment identifier les points d’extrémité JSON du NASDAQ :
- Ouvrez n’importe quelle page de téléscripteur (par exemple, https://www.nasdaq.com/market-activity/stocks/aapl) et ouvrez les outils de développement de votre navigateur.
- Dans l’onglet Réseau, sélectionnez le filtre Fetch/XHR pour isoler le trafic API.
- Rechargez la page pour enregistrer toutes les demandes.
Après le rechargement, vous verrez des requêtes telles que market-info, chart, watchlist, et plusieurs autres.
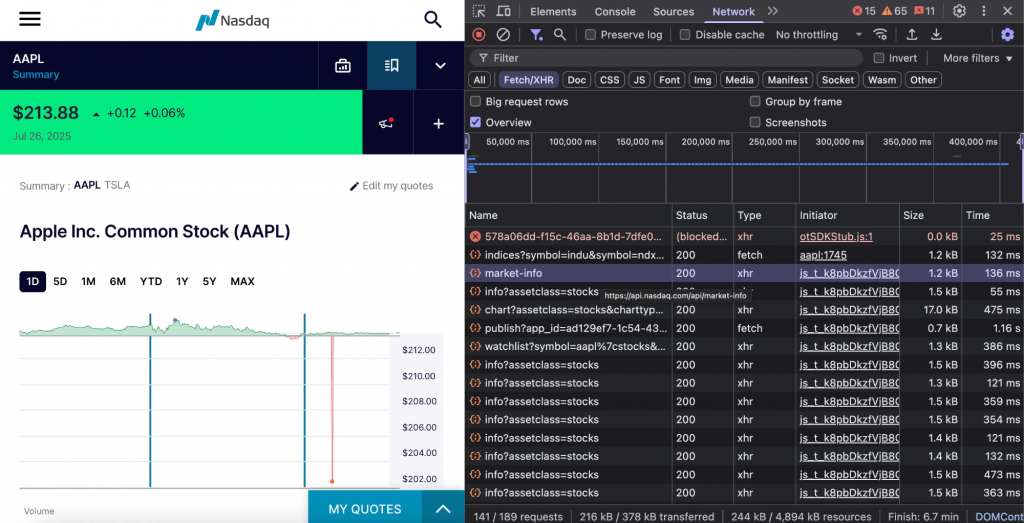
Cliquez sur n’importe quelle requête pour inspecter la charge utile JSON. La requête market-info, par exemple, affiche une structure de données complète avec des informations sur le marché en temps réel.
Une fois ces points d’extrémité identifiés, nous allons mettre en place les outils nécessaires.
Conditions préalables
- Python 3.x
- Un éditeur de code (VS Code, PyCharm, etc.)
- Familiarité de base avec Chrome Developer Tools
- Compréhension des bases du scraping en Python et des bibliothèques d’extraction de données
- La bibliothèque de
requêtes. Installez-la à l’aide de la commandepip install requests
Si vous ne connaissez pas encore la bibliothèque des requêtes, notre guide des requêtes Python couvre toutes les techniques que nous utiliserons dans ce tutoriel.
Ces outils étant prêts, explorons la première méthode.
Méthode 1 – scraping web avec accès direct à l’API
Les principaux points de terminaison que nous utiliserons fournissent des données de marché complètes par le biais de réponses JSON propres.
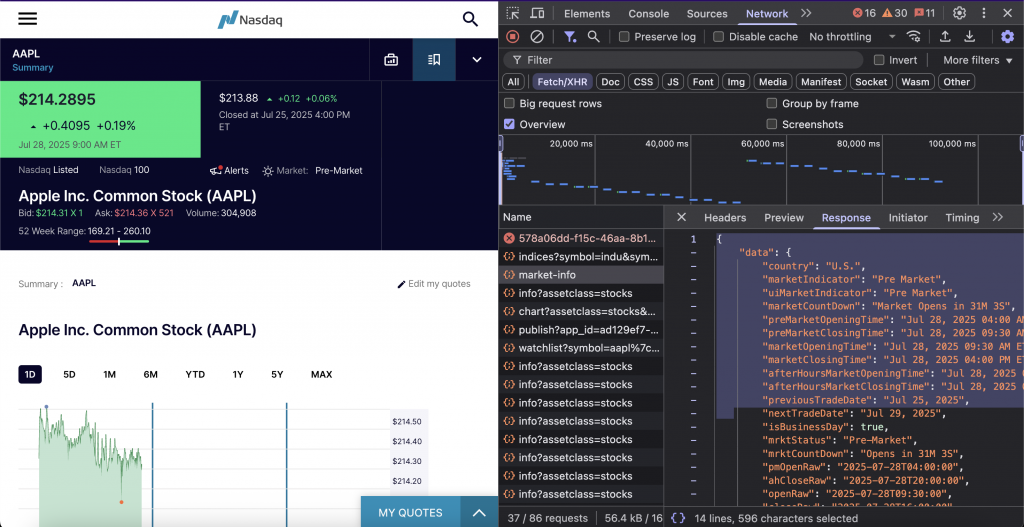
État du marché et calendrier des échanges
Ce point d’accès renvoie l’état des marchés américains avec des informations sur le compte à rebours et des horaires de négociation complets. Il couvre les heures normales, les séances pré-marché et après les heures normales, et fournit les dates de négociation précédentes et suivantes dans plusieurs formats d’horodatage pour faciliter l’intégration.
Le point d’arrivée est https://api.nasdaq.com/api/market-info.
Voici une mise en œuvre simple :
import requests
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
response = requests.get('https://api.nasdaq.com/api/market-info', headers=headers)
print(response.json())L’API renvoie des données sur l’état du marché comme suit :
{
"data": {
"country": "U.S.",
"marketIndicator": "Market Open",
"uiMarketIndicator": "Market Open",
"marketCountDown": "Market Closes in 3H 7M",
"preMarketOpeningTime": "Jul 29, 2026 04:00 AM ET",
"preMarketClosingTime": "Jul 29, 2026 09:30 AM ET",
"marketOpeningTime": "Jul 29, 2026 09:30 AM ET",
"marketClosingTime": "Jul 29, 2026 04:00 PM ET",
"afterHoursMarketOpeningTime": "Jul 29, 2026 04:00 PM ET",
"afterHoursMarketClosingTime": "Jul 29, 2026 08:00 PM ET",
"previousTradeDate": "Jul 28, 2026",
"nextTradeDate": "Jul 30, 2026",
"isBusinessDay": true,
"mrktStatus": "Open",
"mrktCountDown": "Closes in 3H 7M",
"pmOpenRaw": "2026-07-29T04:00:00",
"ahCloseRaw": "2026-07-29T20:00:00",
"openRaw": "2026-07-29T09:30:00",
"closeRaw": "2026-07-29T16:00:00"
}
}Génial ! Ceci montre l’approche de l’API pour récupérer les données de synchronisation du marché en temps réel.
Données sur les cours de bourse
Le point d’accès aux cotations du NASDAQ fournit des données détaillées sur les actions de toutes les sociétés cotées en bourse, y compris les dernières cotations, le volume des transactions, des informations sur la société et des statistiques de marché.
Le point d’accès est https://api.nasdaq.com/api/quote/{symbol}/info?assetclass=stocks. Il nécessite le symbole boursier (AAPL, TSLA) et le paramètre assetclass défini sur stocks pour les données relatives aux actions.
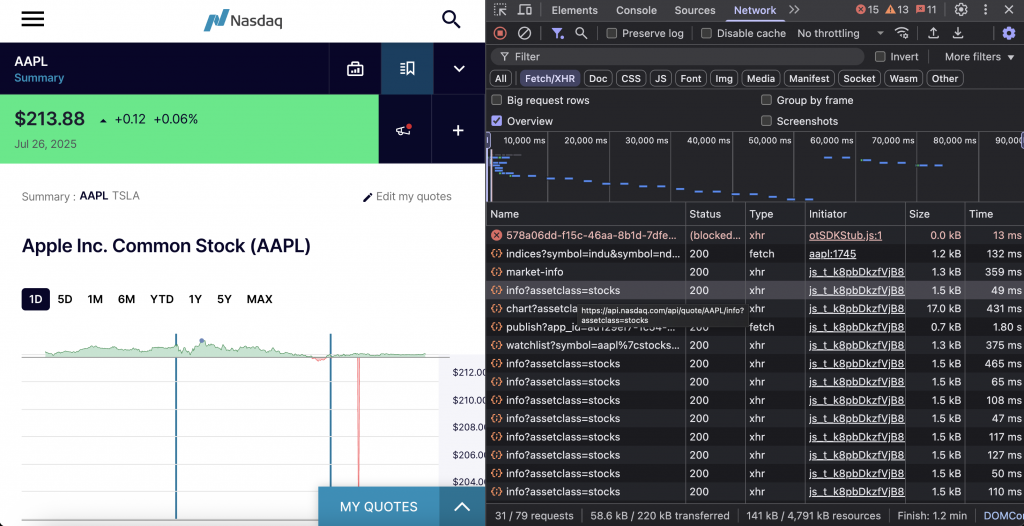
Voici un extrait de code simple :
import requests
def get_stock_info(symbol, headers):
url = f'https://api.nasdaq.com/api/quote/{symbol}/info?assetclass=stocks'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
stock_info = get_stock_info('AAPL', headers)
print(stock_info)L’API renvoie des données sur les cours de bourse comme suit :
{
"data": {
"symbol": "AAPL",
"companyName": "Apple Inc. Common Stock",
"stockType": "Common Stock",
"exchange": "NASDAQ-GS",
"isNasdaqListed": true,
"isNasdaq100": true,
"isHeld": false,
"primaryData": {
"lastSalePrice": "$211.9388",
"netChange": "-2.1112",
"percentageChange": "-0.99%",
"deltaIndicator": "down",
"lastTradeTimestamp": "Jul 29, 2026 12:51 PM ET",
"isRealTime": true,
"bidPrice": "$211.93",
"askPrice": "$211.94",
"bidSize": "112",
"askSize": "235",
"volume": "23,153,569",
"currency": null
},
"secondaryData": null,
"marketStatus": "Open",
"assetClass": "STOCKS",
"keyStats": {
"fiftyTwoWeekHighLow": {
"label": "52 Week Range:",
"value": "169.21 - 260.10"
},
"dayrange": {
"label": "High/Low:",
"value": "211.51 - 214.81"
}
},
"notifications": [
{
"headline": "UPCOMING EVENTS",
"eventTypes": [
{
"message": "Earnings Date : Jul 31, 2026",
"eventName": "Earnings Date",
"url": {
"label": "AAPL Earnings Date : Jul 31, 2026",
"value": "/market-activity/stocks/AAPL/earnings"
},
"id": "upcoming_events"
}
]
}
]
}
}Données fondamentales de l’entreprise et indicateurs clés
L’API de synthèse du NASDAQ fournit des données financières clés, notamment la capitalisation boursière, le volume des transactions, les informations sur les dividendes et la classification sectorielle pour n’importe quel symbole boursier.
Lorsque vous visitez la page d’une entreprise du NASDAQ et que vous faites défiler la page jusqu’à la section “Key Data”, votre navigateur appelle un point de terminaison spécifique. Ce point d’accès est https://api.nasdaq.com/api/quote/{SYMBOL}/summary?assetclass=stocks et contient toutes les données fondamentales de l’entreprise.
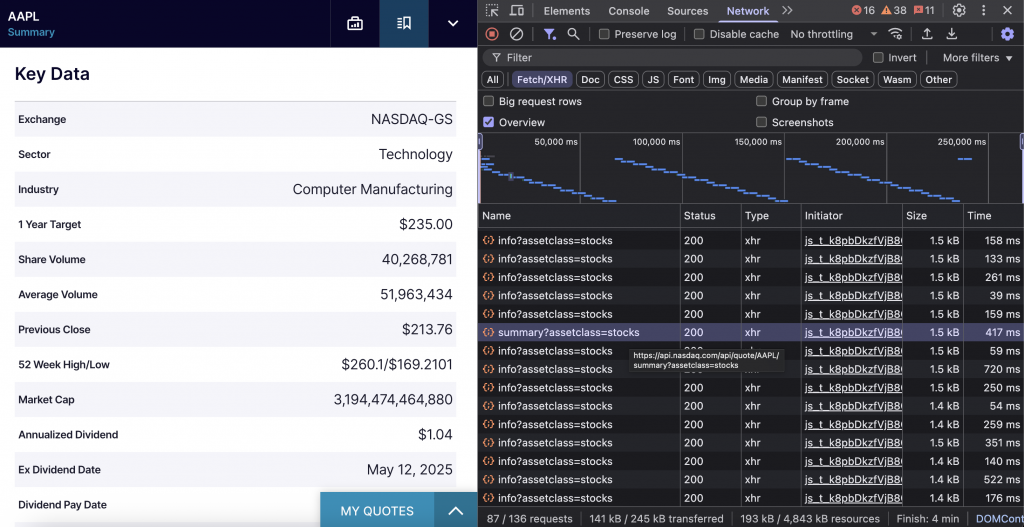
Voici l’extrait de code :
import requests
def get_company_data(symbol, headers):
url = f'https://api.nasdaq.com/api/quote/{symbol}/summary?assetclass=stocks'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
company_data = get_company_data('AAPL', headers)
print(company_data)L’API renvoie les données de la clé de l’entreprise comme suit :
{
"data": {
"symbol": "AAPL",
"summaryData": {
"Exchange": {
"label": "Exchange",
"value": "NASDAQ-GS"
},
"Sector": {
"label": "Sector",
"value": "Technology"
},
"Industry": {
"label": "Industry",
"value": "Computer Manufacturing"
},
"OneYrTarget": {
"label": "1 Year Target",
"value": "$235.00"
},
"TodayHighLow": {
"label": "Today's High/Low",
"value": "$214.81/$210.825"
},
"ShareVolume": {
"label": "Share Volume",
"value": "25,159,852"
},
"AverageVolume": {
"label": "Average Volume",
"value": "51,507,684"
},
"PreviousClose": {
"label": "Previous Close",
"value": "$214.05"
},
"FiftTwoWeekHighLow": {
"label": "52 Week High/Low",
"value": "$260.1/$169.2101"
},
"MarketCap": {
"label": "Market Cap",
"value": "3,162,213,080,720"
},
"AnnualizedDividend": {
"label": "Annualized Dividend",
"value": "$1.04"
},
"ExDividendDate": {
"label": "Ex Dividend Date",
"value": "May 12, 2026"
},
"DividendPaymentDate": {
"label": "Dividend Pay Date",
"value": "May 15, 2026"
},
"Yield": {
"label": "Current Yield",
"value": "0.49%"
}
},
"assetClass": "STOCKS",
"additionalData": null,
"bidAsk": {
"Bid * Size": {
"label": "Bid * Size",
"value": "$211.75 * 280"
},
"Ask * Size": {
"label": "Ask * Size",
"value": "$211.79 * 225"
}
}
}
}Graphique et données historiques du NASDAQ
Le NASDAQ fournit des données graphiques par le biais de points d’accès spécialisés conçus pour différentes périodes et granularités de données.

Le NASDAQ répartit les données graphiques entre les différents points de terminaison en fonction des exigences en matière d’échéances :
- Point final intrajournalier – données minute par minute pour les échéances 1D et 5D.
- Point final historique – données OHLC quotidiennes pour 1M, 6M, YTD, 1Y, 5Y et MAX.
Données graphiques intrajournalières (échelle de temps 1D)
Ce point d’arrivée est idéal pour analyser les mouvements de prix minute par minute pendant les séances de négociation.
Le point d’arrivée est https://api.nasdaq.com/api/quote/{symbol}/chart?assetclass=stocks&charttype=rs.
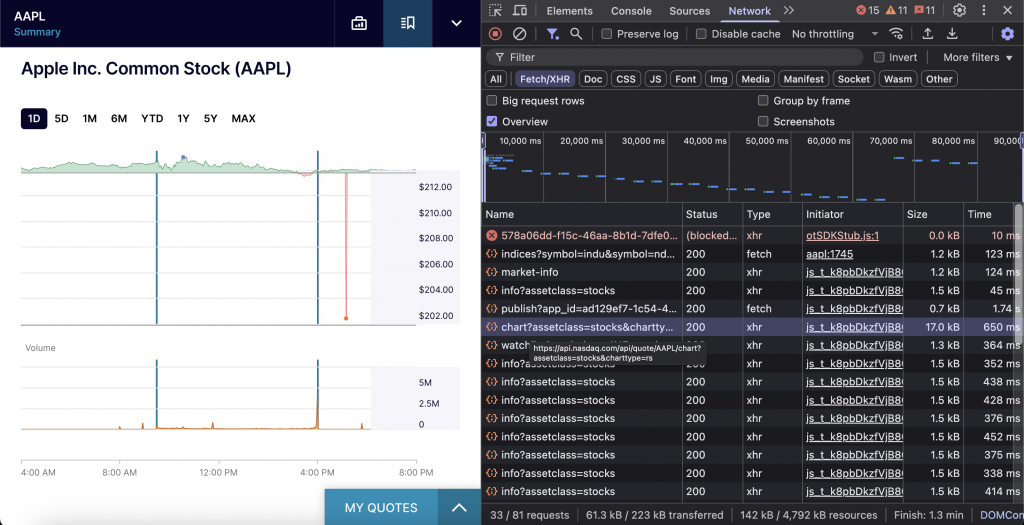
Le point de terminaison requiert trois paramètres : le symbole du titre, assetclass défini sur stocks pour les données sur les actions, et charttype=rs pour les heures d’ouverture normales.
Voici une mise en œuvre simple :
import requests
def get_chart_data(symbol, headers):
url = f'https://api.nasdaq.com/api/quote/{symbol}/chart?assetclass=stocks&charttype=rs'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
chart_data = get_chart_data('AAPL', headers)
print(chart_data)L’API renvoie les données intrajournalières d’une entreprise dans la structure suivante :
{
"data": {
"chart": [
{
"w": 995, // Trading volume for this minute
"x": 1753416000000, // Timestamp (milliseconds)
"y": 214.05, // Price
"z": { // Human-readable format
"time": "4:00 AM",
"shares": "995",
"price": "$214.05",
"prevCls": "213.7600" // Previous day's close
}
}
]
}
}Pour les données sur les minutes de 5 jours, vous devez utiliser un point de terminaison différent :
https://charting.nasdaq.com/data/charting/intraday?symbol=AAPL&mostRecent=5&includeLatestIntradayData=1Il renvoie des données structurées comme suit (par souci de concision) :
{
"companyName": "APPLE INC",
"marketData": [
{
"Date": "2026-07-22 09:30:00",
"Value": 212.639999,
"Volume": 2650933
},
{
"Date": "2026-07-22 09:31:00",
"Value": 212.577103,
"Volume": 232676
}
],
"latestIntradayData": {
"Date": "2026-07-28 16:00:00",
"High": 214.845001,
"Low": 213.059998,
"Open": 214.029999,
"Close": 214.050003,
"Change": 0.169998,
"PctChange": 0.079483,
"Volume": 37858016
}
}Données historiques (1M, 6M, YTD, 1Y, 5Y, MAX)
Pour les périodes plus longues, le NASDAQ fournit des données OHLC quotidiennes jusqu’à la fin de l’historique.
Le point final est https://charting.nasdaq.com/data/charting/historical?symbol={symbole}&date={début}~{fin}&.
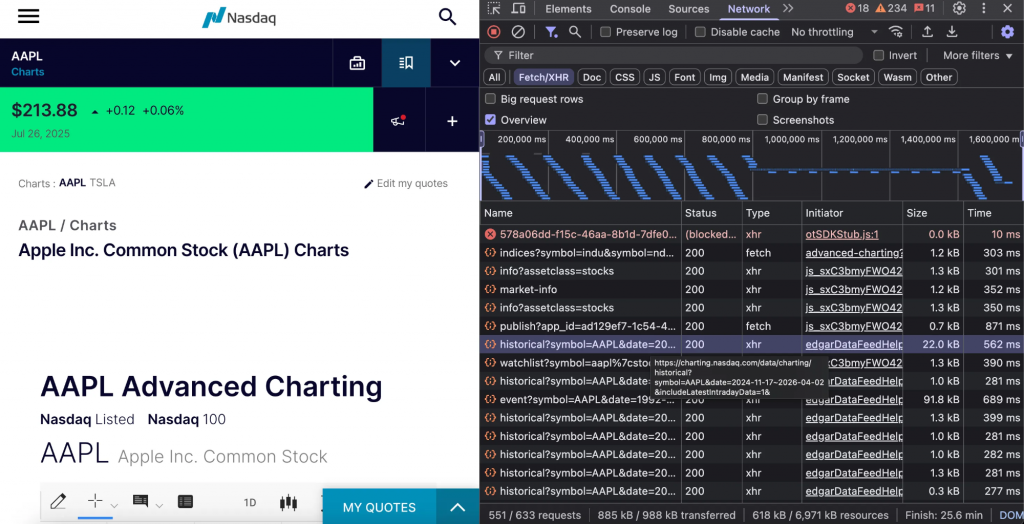
Le point de terminaison requiert le symbole boursier et la plage de dates au format “YYYY-MM-DD~YYY-MM-DD”.
Voici un exemple de code :
import requests
def get_historical_data(symbol, headers):
url = f"https://charting.nasdaq.com/data/charting/historical?symbol={symbol}&date=2024-08-24~2024-10-23&"
response = requests.get(url, headers=headers)
return response.json()
headers = {
"accept": "*/*",
"referer": "https://charting.nasdaq.com/dynamic/chart.html",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36",
}
historical_data = get_historical_data("AAPL", headers)
print(historical_data)Les données obtenues sont structurées comme suit (par souci de concision) :
{
"companyName": "APPLE INC",
"marketData": [
{
"Date": "2024-11-18 00:00:00",
"High": 229.740000,
"Low": 225.170000,
"Open": 225.250000,
"Close": 228.020000,
"Volume": 44686020
}
],
"latestIntradayData": {
"Date": "2026-07-25 16:00:00",
"High": 215.240005,
"Low": 213.399994,
"Open": 214.699997,
"Close": 213.880005,
"Change": 0.120010,
"PctChange": 0.056143,
"Volume": 40268780
}
}Titres de l’ETF
L’API NASDAQ ETF Holdings identifie les fonds négociés en bourse (ETF) qui comptent une action spécifique parmi leurs 10 principaux titres. Ces données montrent les schémas de propriété institutionnelle et permettent d’identifier des opportunités d’investissement connexes.
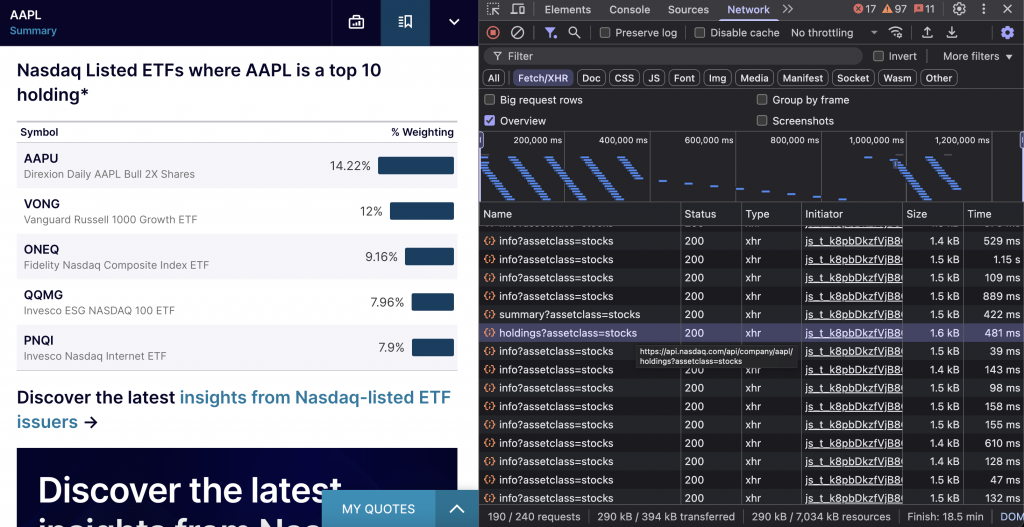
Le point d’arrivée est https://api.nasdaq.com/api/company/{symbol}/holdings?assetclass=stocks.
Voici la mise en œuvre :
import requests
def get_holdings_data(symbol, headers):
url = f'https://api.nasdaq.com/api/company/{symbol}/holdings?assetclass=stocks'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
holdings_data = get_holdings_data('AAPL', headers)
print(holdings_data)L’API renvoie deux catégories de données sur les ETF : tous les ETF qui détiennent l’action parmi les 10 premières positions, et les ETF spécifiquement cotés au NASDAQ avec les mêmes critères. La réponse comprend les pourcentages de pondération, les données de performance des ETF et les détails du fonds.
{
"data": {
"heading": "ETFs with AAPL as a Top 10 Holding*",
"holdings": { ... }, // All ETFs with the stock as top 10 holding
"nasdaqheading": "Nasdaq Listed ETFs where AAPL is a top 10 holding*",
"nasdaqHoldings": { ... } // Specifically NASDAQ-listed ETFs
}
}Dernières nouvelles de l’entreprise
Ce point d’accès permet de récupérer des articles d’actualité récents liés à des symboles boursiers spécifiques. Il fournit une couverture détaillée de l’actualité, y compris les titres, les détails de la publication, les symboles associés et les métadonnées de l’article.
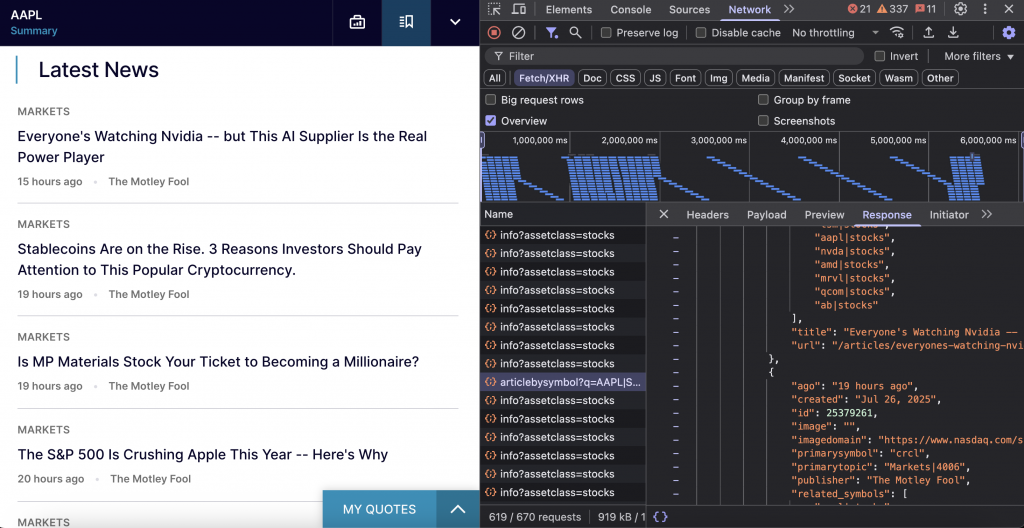
Le point d’arrivée est https://www.nasdaq.com/api/news/topic/articlebysymbol?q={symbol}|STOCKS&offset={offset}&limit={limit}&fallback=true.
Ce qu’il faut pour passer :
- q – symbole boursier avec le suffixe |STOCKS (comme AAPL|STOCKS ou MSFT|STOCKS)
- offset – nombre d’enregistrements à sauter pour la pagination (commence à 0)
- limit – nombre maximum d’articles à renvoyer (10 par défaut)
- fallback – drapeau booléen pour le comportement de repli (recommandé : true)
Voici une mise en œuvre rapide :
import requests
def get_news_data(symbol, headers):
url = f'https://www.nasdaq.com/api/news/topic/articlebysymbol?q={symbol}|STOCKS&offset=0&limit=10&fallback=true'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
news_data = get_news_data('AAPL', headers)
print(news_data)L’API renvoie une réponse JSON structurée qui ressemble à ceci :
{
"data": {
"message": null,
"rows": [...], // Array of news articles
"totalrecords": 8905 // Total number of available articles
}
}Chaque article de presse contient des informations détaillées :
{
"ago": "15 hours ago",
"created": "Jul 26, 2026",
"id": 25379586,
"image": "",
"imagedomain": "https://www.nasdaq.com/sites/acquia.prod/files",
"primarysymbol": "tsm",
"primarytopic": "Markets|4006",
"publisher": "The Motley Fool",
"related_symbols": [
"tsm|stocks",
"aapl|stocks",
"nvda|stocks"
],
"title": "Everyone's Watching Nvidia -- but This AI Supplier Is the Real Power Player",
"url": "/articles/everyones-watching-nvidia-ai-supplier-real-power-player"
}L’API utilise une pagination simple basée sur le décalage pour vous aider à naviguer efficacement parmi des milliers d’articles. Voici comment fonctionne la pagination :
- Premier lot –
offset=0&limit=10récupère les articles 1-10 - Ledeuxième lot –
offset=10&limit=10récupère les articles 11-20 - Troisième lot –
offset=20&limit=10récupère les articles 21-30
Pour obtenir la série d’articles suivante, incrémentez le décalage de votre valeur limite.
Méthode 2 – Mise à l’échelle des données du NASDAQ avec des proxys résidentiels
Si l’accès direct à l’API fonctionne bien pour la plupart des cas d’utilisation, la mise à l’échelle de la collecte de données au niveau de l’entreprise présente des défis importants en matière de grattage Web. Les opérations à fort volume sont confrontées à des limites de débit, à des systèmes de détection des robots et à des blocages d’adresses IP qui peuvent interrompre complètement la collecte de données.
Le principal goulot d’étranglement du scraping à grande échelle est la gestion de la réputation des adresses IP. Les sites financiers comme le NASDAQ déploient des systèmes anti-bots avancés qui surveillent activement les schémas et la fréquence des requêtes provenant d’adresses IP individuelles. Lorsque ces systèmes détectent des schémas de trafic automatisés à partir d’une seule source IP, ils mettent en œuvre des blocages allant de la limitation du débit à l’interdiction complète de l’IP.
Les proxys résidentiels résolvent ces problèmes en acheminant les demandes par le biais de connexions internet domestiques réelles. Ainsi, vos demandes ressemblent au trafic légitime d’utilisateurs répartis sur différents sites géographiques, ce qui réduit considérablement la probabilité de déclencher des systèmes anti-bots.
Notre infrastructure de proxy résidentiel fournit plus de 150 millions d’adresses IP résidentielles sur plus de 195 sites, spécialement conçue pour la collecte de données à l’échelle de l’entreprise. Les nouveaux utilisateurs peuvent commencer par consulter notre guide de démarrage rapide pour une mise en œuvre de base, tandis que les entreprises qui ont besoin de configurations avancées peuvent consulter notre documentation d’installation détaillée.
La mise en place de proxys résidentiels avec des requêtes Python nécessite une configuration minimale. Configurez les informations d’identification de votre proxy comme suit :
proxies = {
'http': 'http://brd-customer-{CUSTOMER_ID}-zone-{ZONE_NAME}:{PASSWORD}@brd.superproxy.io:{PORT}',
'https': 'http://brd-customer-{CUSTOMER_ID}-zone-{ZONE_NAME}:{PASSWORD}@brd.superproxy.io:{PORT}'
}Voici la mise en œuvre complète :
import requests
import urllib3
# Disable SSL warnings
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
proxies = {
"http": "http://brd-customer-{CUSTOMER_ID}-zone-{ZONE_NAME}:{PASSWORD}@brd.superproxy.io:{PORT}",
"https": "http://brd-customer-{CUSTOMER_ID}-zone-{ZONE_NAME}:{PASSWORD}@brd.superproxy.io:{PORT}",
}
headers = {
"accept": "application/json, text/plain, */*",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36",
}
response = requests.get(
"https://www.nasdaq.com/api/news/topic/articlebysymbol?q=AAPL|STOCKS&offset=0&limit=10&fallback=true",
headers=headers,
proxies=proxies,
verify=False,
timeout=30,
)
print(f"Status Code: {response.status_code}")
print(response.json())Avec cette configuration de proxy résidentiel, vous pouvez exécuter des centaines ou des milliers de requêtes simultanées sur différentes adresses IP sans déclencher de limites de taux.
Nous proposons également un outil de gestion de proxy gratuit et open-source qui offre un contrôle avancé sur vos opérations de proxy, telles que la gestion centralisée de proxy, la surveillance des demandes en temps réel, les paramètres de rotation avancés et bien plus encore. Notre guide d’installation vous accompagne tout au long du processus de configuration.
Méthode 3 – Grattage de données NASDAQ par l’IA avec MCP
Le protocole Model Context Protocol normalise l’intégration de l’IA aux données, permettant des interactions en langage naturel avec l’infrastructure de scraping web. La mise en œuvre du MCP de Bright Data combine des solutions de collecte de données avec une extraction alimentée par l’IA, rationalisant les opérations de scraping par le biais d’interfaces conversationnelles.
Ce serveur MCP pour l’extraction de données financières simplifie la complexité de la découverte des points d’extrémité, de la gestion des en-têtes et de la protection anti-bot en tirant parti de l’infrastructure des données web. Le système navigue intelligemment et extrait des données de sites web modernes comme le NASDAQ, en gérant le rendu JavaScript, le contenu dynamique et les systèmes de sécurité tout en fournissant des données structurées en sortie.
Voyons maintenant comment cela fonctionne en intégrant Bright Data MCP à l’application de bureau Claude. Naviguez vers l’application de bureau Claude, puis allez dans Paramètres > Développeur > Modifier la configuration. Vous verrez le fichier claude_desktop_config.json, où vous devez ajouter la configuration suivante :
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "<your-brightdata-api-token>",
"WEB_UNLOCKER_ZONE": "<optional – override default zone name 'mcp_unlocker'>",
"BROWSER_AUTH": "<optional – enable full browser control via Scraping Browser>"
}
}
}
}Configuration requise :
- Clé API – configurez votre compte Bright Data et générez une clé API à partir de votre tableau de bord.
- Zone de déverrouillage Web – spécifiez le nom de votre zone de déverrouillage Web ou utilisez la valeur par défaut
mcp_unlocker. - Configuration du navigateur de balayage (API du navigateur) – Pour les scénarios de contenu dynamique, configurez l’API du navigateur pour les pages rendues en JavaScript. Utilisez les informations d’identification
Nom d'utilisateur:Mot de passede l’onglet Vue d’ensemble de votre zone API du navigateur.
Une fois la configuration terminée, quittez l’application Claude et rouvrez-la. Vous verrez l’option Bright Data disponible, indiquant que les outils MCP sont maintenant intégrés dans votre environnement Claude.

Grâce à l’intégration de Claude et de Bright Data MCP, vous pouvez extraire des données par le biais d’invites conversationnelles sans écrire de code.
Exemple d’invite : “Extraire les données clés de l’URL NASDAQ au format JSON : https://www.nasdaq.com/market-activity/stocks/aapl. Gérer le chargement dynamique puisque le NASDAQ utilise un rendu JavaScript.”
Autoriser les permissions de l’outil lorsque cela est demandé. Le système appelle automatiquement les outils MCP de Bright Data, en utilisant l’API du navigateur pour gérer le rendu JavaScript et contourner les protections anti-bots. Il renvoie ensuite des données JSON structurées contenant des informations complètes sur les actions.
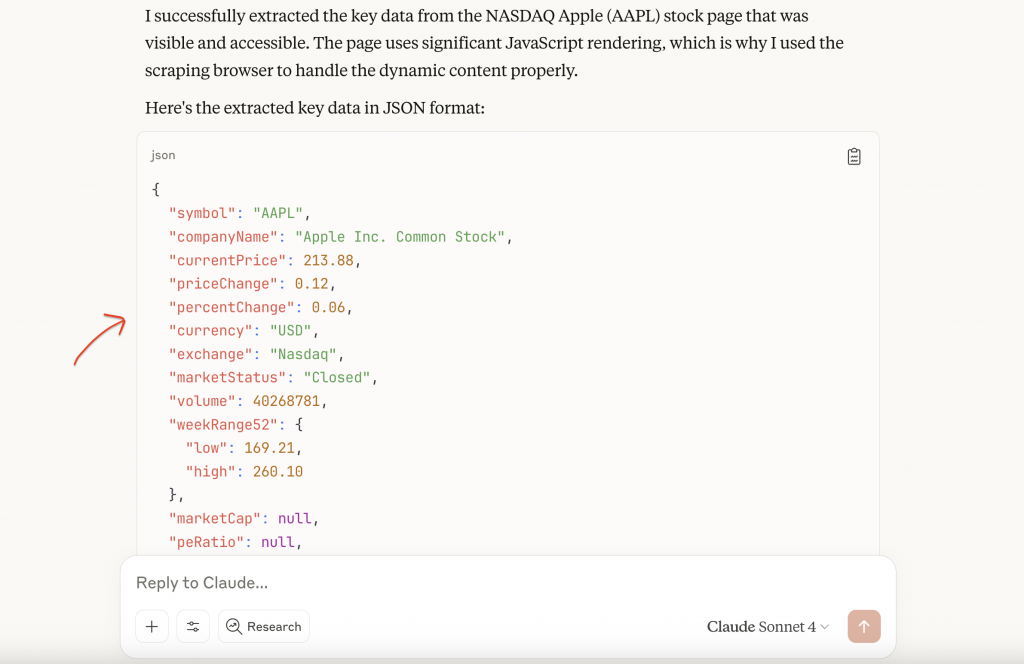
Il s’agit d’une application de MCP pour l’extraction de données financières. La polyvalence du protocole s’étend bien au-delà de l’extraction de données financières, car les équipes qui élaborent des flux de travail d’IA combinent régulièrement plusieurs serveurs MCP pour obtenir différentes capacités.
Notre aperçu des principaux serveurs MCP compare et met en évidence les capacités uniques de chaque fournisseur, couvrant tout, de l’extraction de données web et de l’automatisation du navigateur à l’intégration de code et à la gestion de base de données.
Conclusion
Pour extraire efficacement les données du NASDAQ, il faut choisir l’approche la mieux adaptée à vos besoins spécifiques. Alors que le scraping de base fonctionne pour l’extraction de faibles volumes de données, les applications de production bénéficient de manière significative d’une infrastructure proxy robuste et de solutions d’entreprise.
Pour les organisations qui ont besoin de solutions de données financières au niveau de l’entreprise, il vaut la peine d’évaluer différentes options. Notre analyse des principaux fournisseurs de données financières peut vous aider à choisir entre la création de scrapers personnalisés et l’achat d’ensembles de données auprès de fournisseurs spécialisés.
Au-delà des données financières, la vaste place de marché de Bright Data propose également des données commerciales, des données sur les médias sociaux, des données immobilières, des données sur le commerce électronique et bien d’autres encore.
Avec autant d’options de jeux de données et d’approches de collecte disponibles, parlez à l’un de nos experts en données pour découvrir quels produits et services de Bright Data répondent le mieux à vos besoins spécifiques.





