

Toutes les données sont précieuses. Les données agrégées sont l’un des types de données les plus recherchés sur le web. Google Finance contient des tonnes de données agrégées pour différents marchés financiers. Ces données sont utiles pour tout, des robots de trading aux rapports généraux.
C’est parti !
Prérequis
Si vous disposez des compétences requises, vous pouvez extraire des données de Google Finance avec une relative facilité. Vous aurez besoin des éléments suivants pour extraire des données de Google Finance.
- Python: vous n’avez besoin que de connaissances de base en Python. Vous devez savoir comment utiliser les variables, les fonctions et les boucles.
- Python Requests: il s’agit du client HTTP Python standard. Il est utilisé pour effectuer des requêtes GET, POST, PUT et DELETE sur l’ensemble du Web.
- BeautifulSoup: BeautifulSoup nous donne accès à un analyseur HTML efficace. C’est ce que nous utilisons pour extraire nos données.
Si vous ne les avez pas déjà installés, vous pouvez installer Requests et BeautifulSoup à l’aide des commandes suivantes.
Installer Requests
pip install requests
Installer BeautifulSoup
pip install beautifulsoup4
Que récupérer sur Google Finance
Voici une capture d’écran de la page d’accueil de Google Finance. Elle contient toutes sortes d’informations sur différents marchés. Nous voulons des informations détaillées sur plusieurs marchés, pas seulement des bribes d’informations.
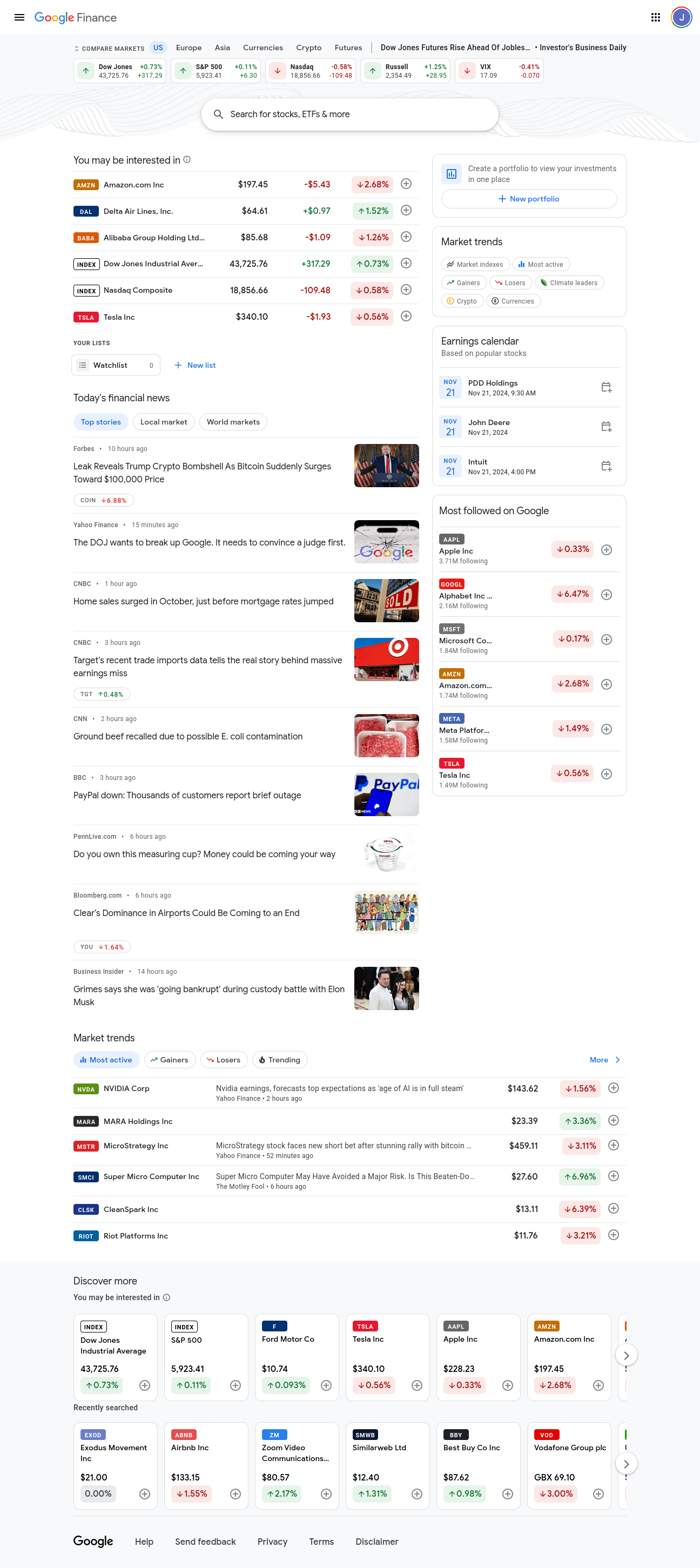
Si vous faites défiler la page vers le bas, vous verrez une section intitulée « Tendances du marché » sur le côté droit de la page. Chaque bulle de cette section renvoie vers des informations détaillées sur un marché spécifique. Nous nous intéressons aux marchés suivants : Gagnants, Perdants, Indices boursiers, Les plus actifs et Crypto.
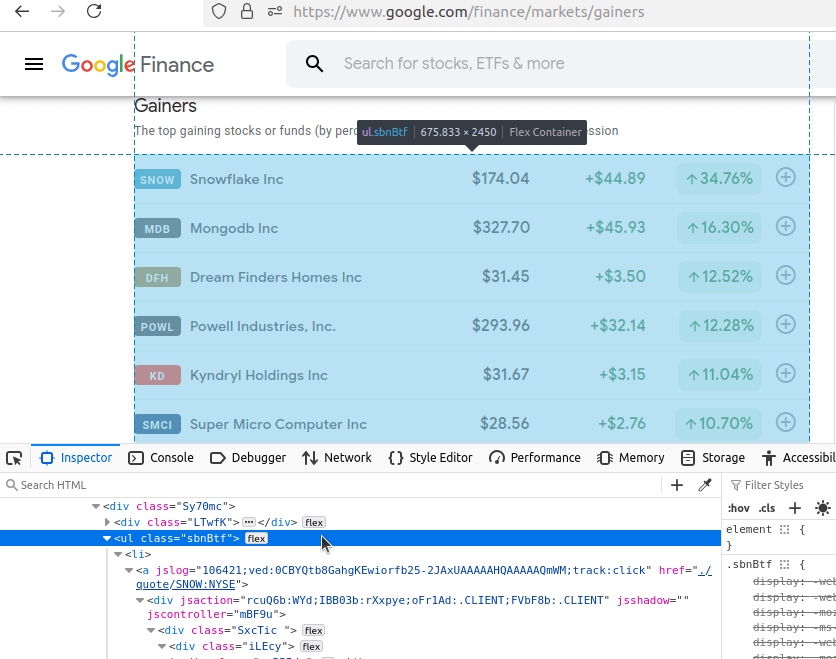
Nous allons maintenant cliquer sur chacune de ces pages et les examiner. Nous commencerons par les gagnants. Comme vous pouvez le voir dans notre barre d’adresse, notre URL est : https://www.google.com/finance/markets/gainers. Si vous regardez la console développeur en bas, vous remarquerez que l’ensemble du jeu de données est intégré dans une liste ul, une liste non organisée.
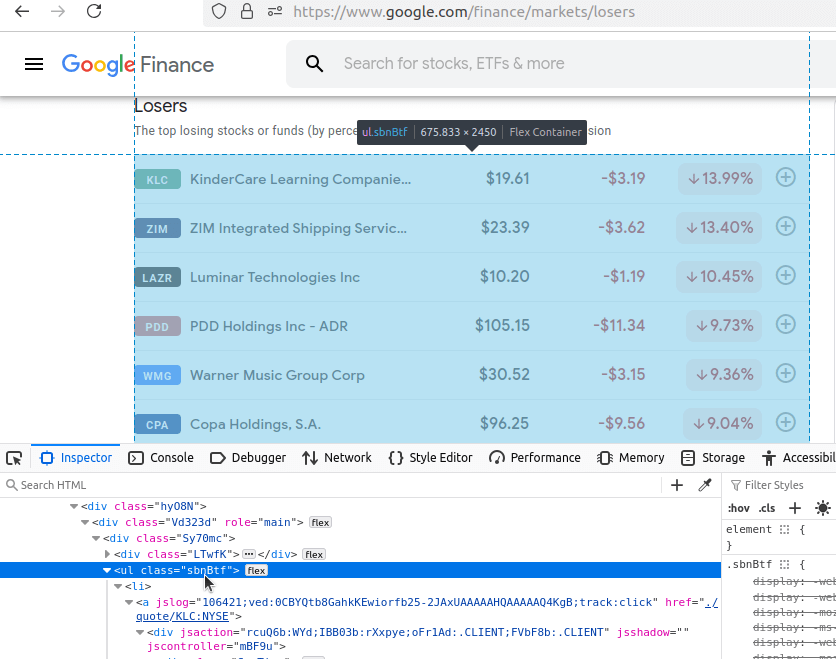
Nous allons maintenant examiner la page Losers. Notre URL est : https://www.google.com/finance/markets/losers. Une fois encore, notre ensemble de données est intégré dans une liste non organisée.
Voici la même capture d’écran de la page des indices boursiers. Cette page est un peu particulière. Elle contient plusieurs éléments ul, nous devrons donc en tenir compte dans notre code. L’URL est : https://www.google.com/finance/markets/indexes. Commencez-vous à remarquer une tendance ?
La page « Most active » (Les plus actifs) est présentée ci-dessous. Une fois encore, toutes nos données cibles sont intégrées dans une balise ul. Notre URL est : https://www.google.com/finance/markets/most-active.
Enfin, jetons un œil à notre page Crypto. Comme vous vous en doutez probablement, nos données se trouvent dans un élément ul. Notre URL est : https://www.google.com/finance/markets/cryptocurrencies.
Sur chacune de ces pages, nos données cibles sont intégrées dans une liste non organisée. Pour extraire nos données, nous devons trouver ces éléments ul et extraire les éléments li (éléments de liste) de chacun d’entre eux. Jetez un œil à notre URL de base : https://www.google.com/finance/markets. Chaque page provient du point de terminaison markets. Notre format d’URL est : https://www.google.com/finance/markets/{NAME_OF_MARKET}. Nous avons 5 Jeux de données et 5 URL, tous structurés de la même manière. Cela facilite le scraping d’une tonne de données à l’aide de quelques variables seulement.
Récupérer manuellement les données de Google Finance avec Python
Si vous pouvez éviter d’être bloqué, vous pouvez extraire Google Finance avec Python Requests et BeautifulSoup. Nous devons être en mesure d’extraire nos données. Nous devons également être en mesure de les stocker. Nous avons plusieurs points de terminaison, mais ils proviennent tous de la même URL de base : https://google.com/finance/markets/. Chaque fois que nous récupérons une page, nous devons trouver les éléments ul et extraire tous les éléments li de chaque liste.
Passons en revue les fonctions de base que nous utiliserons dans notre script. Nous les appelons write_to_csv() et scrape_page(). Ces noms sont assez explicites.
Fonctions individuelles
Examinons write_to_csv().
def write_to_csv(data, filename):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"google-finance-{filename}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Écriture des données dans le fichier CSV...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"Écriture réussie de {filename} dans CSV...")
- Notre fonction doit écrire une liste d’objets
dictdans un fichier CSV. Si nosdonnéesne sont pas uneliste, nous les convertissons avecdata = [data]. - Chaque fichier que nous générons provient de Google Finance, nous l’ajoutons donc lors de la création du fichier
filename = f"google-finance-{filename}.csv". - Notre
modepar défaut est« w »(écriture), mais si le fichier existe, nous changeons notremodeen« a »(ajout). csv.DictWriter(file, fieldnames=data[0].keys())initialise notre rédacteur de fichiers.- Si nous sommes en mode écriture, le fichier n’existe pas encore, nous créons donc ses en-têtes à partir du premier
dictionnairede laliste. - Une fois la configuration terminée, nous ajoutons nos données au fichier avec
writer.writerows(data).
Examinons maintenant la fonction de scraping proprement dite, scrape_page(). C’est là que la magie opère vraiment. Nous envoyons notre requête à notre URL formatée. Ensuite, nous utilisons BeautifulSoup pour analyser le code HTML que nous recevons en retour. Nous créons une liste vide appelée scraped_data pour contenir nos données extraites. Nous trouvons tous les éléments ul de la page. Nous extrayons ensuite les éléments li de chaque ul trouvé. Il y a cependant un hic. Le texte de chaque élément de la liste est imbriqué dans plusieurs éléments div. Le tableau réel que nous scrapons contient de nombreuses répétitions. Pour contourner ce problème, nous extrayons les éléments 3, 6, 8 et 11 et les ajoutons à scraped_data à l’aide de la fonction append().
Notre fonction scrape_page() se trouve dans l’extrait ci-dessous.
def scrape_page(endpoint: str):
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
soup = BeautifulSoup(response.text, "html.parser")
tables = soup.find_all("ul")
scraped_data = []
for table in tables:
list_elements = table.find_all("li")
for list_element in list_elements:
divs = list_element.find_all("div")
asset = {
"ticker": divs[3].text,
"name": divs[6].text,
"currency": divs[8].text[0] if endpoint != "cryptocurrencies" else "n/a",
« price » : divs[8].text,
« change » : divs[11].text
}
scraped_data.append(asset)
write_to_csv(scraped_data, endpoint)
- Nous envoyons notre requête GET à ce point de terminaison :
requests.get(f"https://google.com/finance/markets/{endpoint}"). - Nous utilisons le parseur HTML de BeuatifulSoup sur notre
réponse:soup = BeautifulSoup(response.text, "html.parser"). - Nous trouvons tous les tableaux de la page :
tables = soup.find_all("ul"). scraped_data = []nous donne un tableau pour stocker nos résultats.- Nous parcourons chacune des tables trouvées et effectuons les opérations suivantes :
- Nous recherchons tous les éléments de la liste :
table.find_all("li"). - Nous parcourons chacun des éléments de la liste et trouvons leurs éléments
div. Cela renvoie une liste appeléedivs. - Extrait le texte des éléments 3, 6, 8 et 11 de
divset en fait undictionnaire. - Ajoutez le
dictionnaireà notrescraped_data. - Les cryptomonnaies sont évaluées en fonction de leur paire de négociation. Par conséquent, si nous sommes sur le point de terminaison des cryptomonnaies, nous réinitialisons notre
deviseàn/a.
- Nous recherchons tous les éléments de la liste :
- Une fois l’analyse de la page terminée, nous enregistrons nos
scrape_datadans un fichier CSV :write_to_csv(scraped_data, endpoint). Nous transmettons notre point de terminaison sous forme de nom de fichier.
Récupérer les données de Google Finance
Nous pouvons intégrer nos fonctions ci-dessus dans un script pour que tout fonctionne. En plus de ces fonctions, nous ajoutons une liste de points de terminaison. Nous ajoutons également un main pour contenir notre runtime. N’hésitez pas à copier-coller le code ci-dessous et à l’essayer !
import requests
from bs4 import BeautifulSoup
import csv
from pathlib import Path
endpoints = ["gainers", "losers", "indexes", "most-active", "cryptocurrencies"]
def write_to_csv(data, filename):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"google-finance-{filename}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Writing data to CSV File...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"Écriture réussie de {filename} dans CSV...")
def scrape_page(endpoint: str):
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
soup = BeautifulSoup(response.text, "html.parser")
tables = soup.find_all("ul")
scraped_data = []
for table in tables:
list_elements = table.find_all("li")
for list_element in list_elements:
divs = list_element.find_all("div")
asset = {
"ticker": divs[3].text,
"name": divs[6].text,
"currency": divs[8].text[0] if endpoint != "cryptocurrencies" else "n/a",
« price » : divs[8].text,
« change » : divs[11].text
}
scraped_data.append(asset)
write_to_csv(scraped_data, endpoint)
if __name__ == "__main__":
for endpoint in endpoints:
print("---------------------")
scrape_page(endpoint)
Lorsque nous exécutons le code ci-dessus, nous obtenons le résultat suivant.
---------------------
Écriture dans CSV...
Écriture des données dans le fichier CSV...
Écriture réussie de google-finance-gainers.csv dans CSV...
---------------------
Écriture dans CSV...
Écriture des données dans le fichier CSV...
Écriture réussie du fichier google-finance-losers.csv au format CSV...
---------------------
Écriture au format CSV...
Écriture des données dans le fichier CSV...
Écriture réussie du fichier google-finance-indexes.csv au format CSV...
---------------------
Écriture au format CSV...
Écriture des données dans le fichier CSV...
Écriture réussie du fichier google-finance-most-active.csv au format CSV...
---------------------
Écriture au format CSV...
Écriture des données dans le fichier CSV...
Écriture réussie du fichier google-finance-cryptocurrencies.csv au format CSV...
Si vous exécutez le script à l’aide de VSCode, vous pouvez voir les fichiers CSV s’afficher à mesure que le Scraper termine son travail. Ils sont mis en évidence dans la capture d’écran ci-dessous.
Nous vous montrerons également une capture d’écran de ce à quoi chacun d’entre eux ressemble dans ONLYOFFICE.
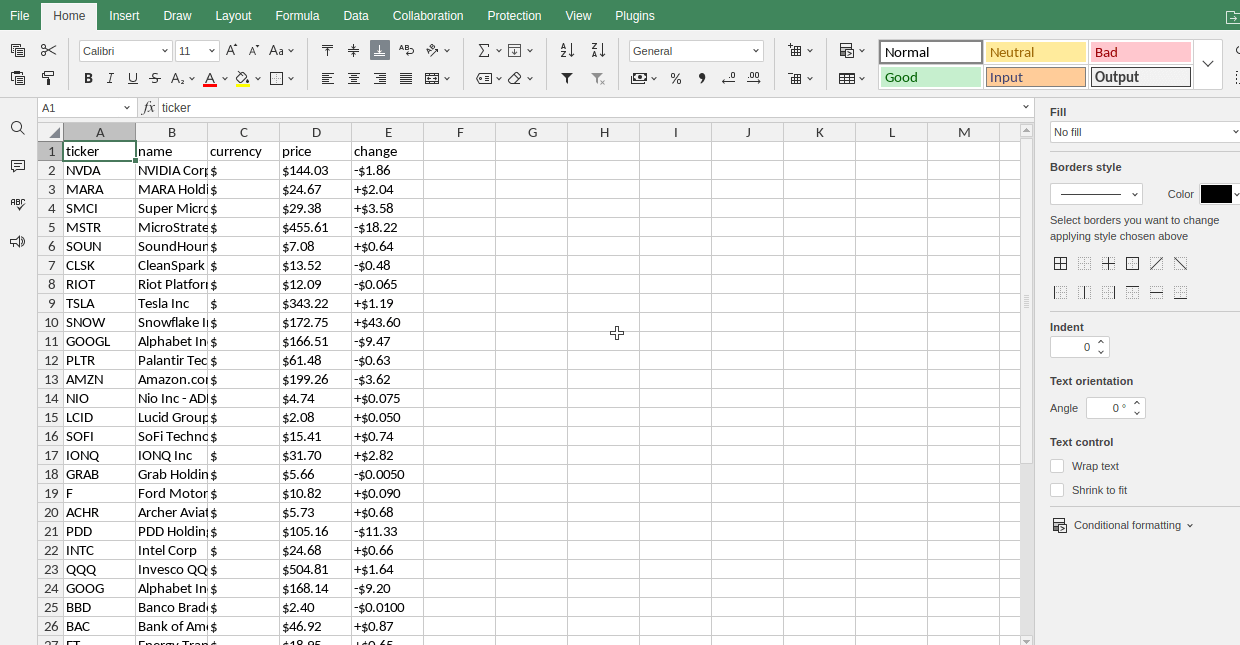
Les plus actifs
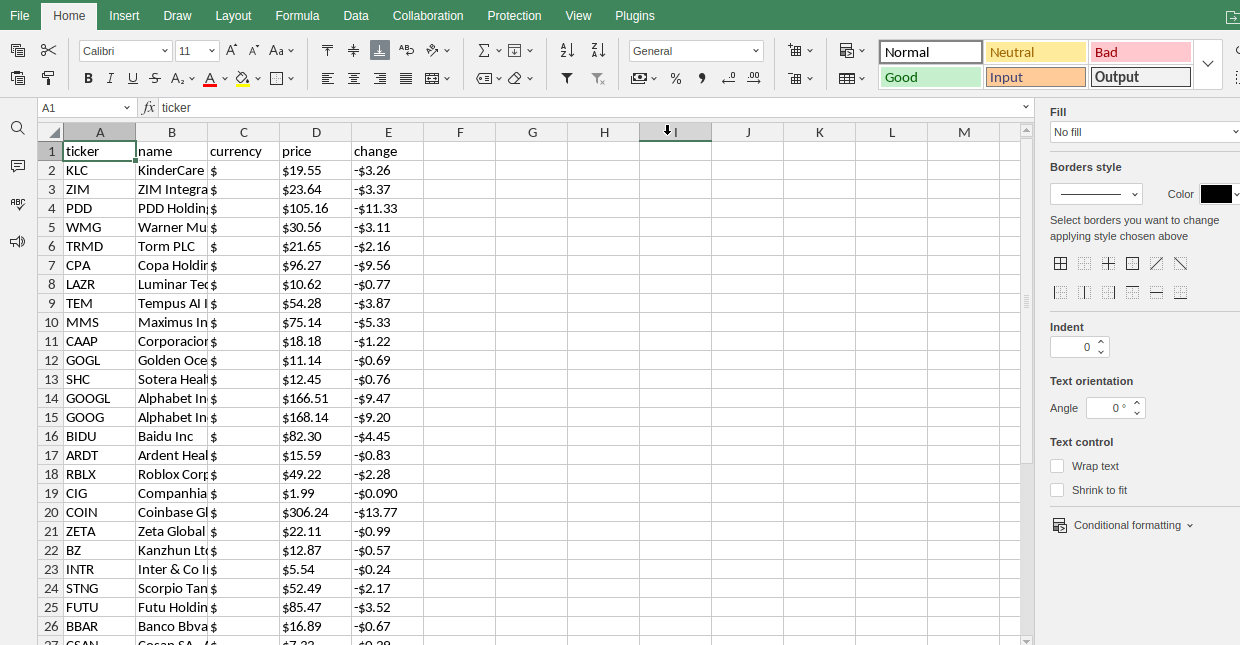
Perdants
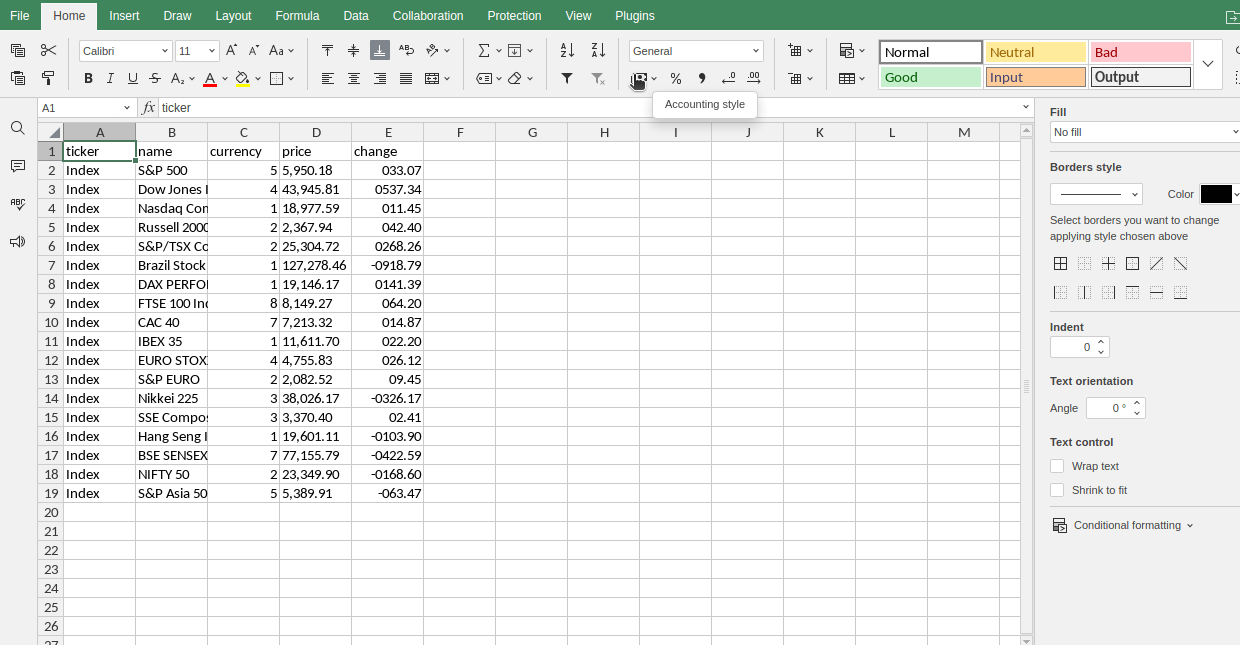
Indices
Gagnants
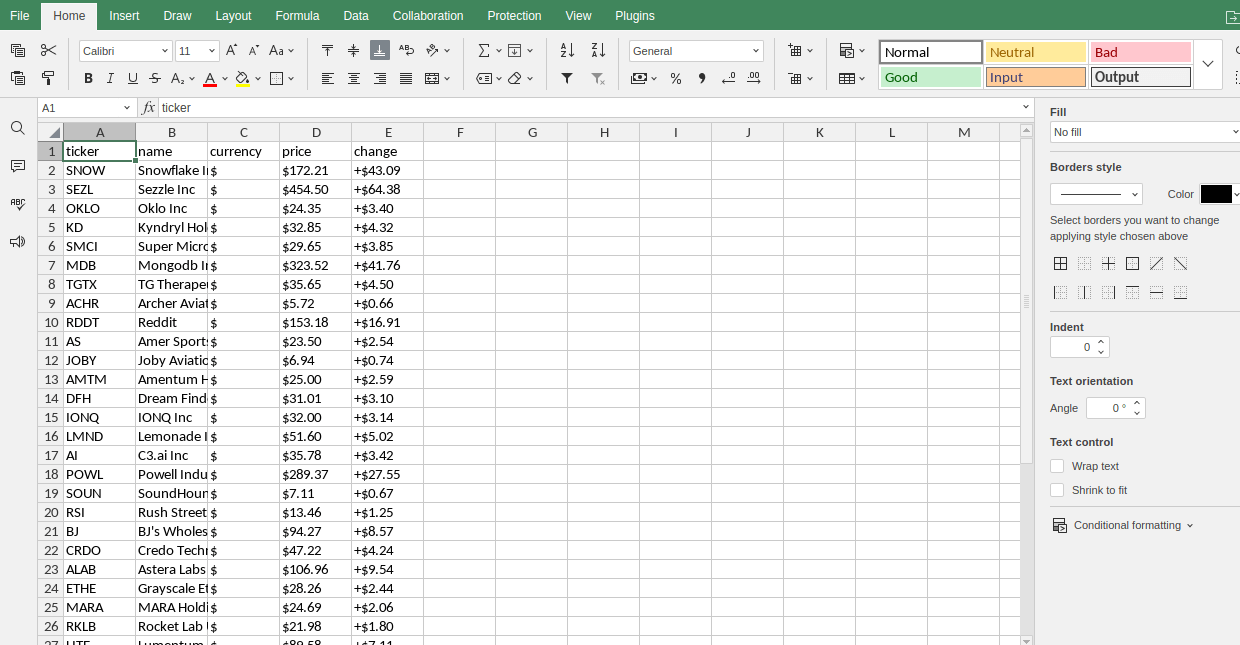
Cryptomonnaies
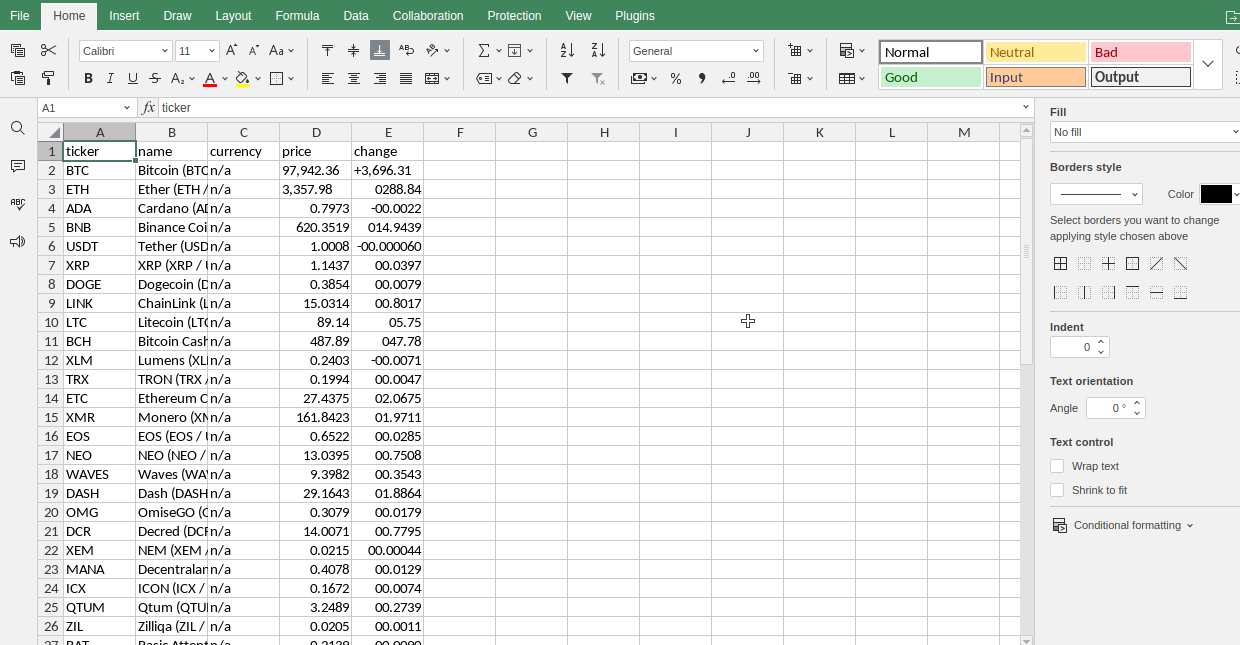
Techniques avancées
Gestion de la pagination
Traditionnellement, la pagination est gérée à l’aide de chiffres. Pour Google Finance, nous utilisons en fait notre tableau d'endpoints pour gérer notre pagination. Chaque élément de notre liste d’endpoints représente une page individuelle que nous souhaitons extraire. Jetez à nouveau un œil à cette liste. Pour en savoir plus sur la gestion de la pagination lors du Scraping web, cliquez ici.
endpoints = ["gainers", "losers", "indexes", "most-active", "cryptocurrencies"]
Voyons maintenant comment cela s’utilise. Avec la pagination traditionnelle, vous auriez soit un endpoint, soit un paramètre de requête dans lequel vous passeriez un nombre. Cependant, avec ce Scraper, nous passons plutôt l’endpoint de chaque page dans notre URL de base.
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
Atténuer le blocage
Au cours de nos tests, nous n’avons rencontré aucun problème de blocage. Cependant, ce monde n’est pas parfait et il est possible que vous en rencontriez à l’avenir. Il existe diverses tactiques que vous pouvez utiliser pour contourner tout blocage que vous pourriez rencontrer.
Faux agents utilisateurs
Lorsque vous effectuez une requête sur un site web (à l’aide d’un navigateur ou de Python Requests), votre client HTTP envoie une chaîne d’agent utilisateur au serveur du site. Celle-ci sert à identifier l’application à l’origine de la requête. Pour définir un faux agent utilisateur dans Python, nous créons une chaîne d’agent utilisateur. Nous l’ajoutons ensuite à nos en-têtes.
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
headers = {
"User-Agent": USER_AGENT
}
response = requests.get(f"https://google.com/finance/markets/{endpoint}", headers=headers)
Demandes chronométrées
Le chronométrage de nos requêtes peut être très utile. Si quelque chose demande 200 pages par minute, il est probable que ce ne soit pas humain. Pour contourner la limitation du débit et paraître plus humain, nous pouvons demander à notre Scraper d’attendre entre les requêtes. Cela rend notre activité de navigation beaucoup plus normale. Tout d’abord, vous devez importer sleep depuis time.
from time import sleep
Ensuite, dormez pendant un certain temps entre les requêtes. Cela ralentira votre Scraper et le fera paraître plus humain.
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
sleep(5)
Envisagez d’utiliser Bright Data
Le scraping web peut représenter beaucoup de travail. Bright Data est l’un des meilleurs fournisseurs de Jeux de données. Avec nos Jeux de données, le scraping est déjà effectué et vous disposez déjà des rapports. Il vous suffit de les télécharger. Nous comprenons que le scraping web ne convient pas à tout le monde et que certaines personnes souhaitent simplement obtenir leurs données et les utiliser.
Nous ne disposons pas d’un ensemble de données Google Finance, mais nous avons un ensemble de données Yahoo Finance. Yahoo Finance offre en fait un éventail plus large de données financières et peut facilement répondre à vos besoins en matière de Google Finance. Nous vous montrons ci-dessous comment acheter cet ensemble de données.
Création d’un compte
Vous devez d’abord créer un compte. Rendez-vous sur notre page d’inscription et créez un compte.
Téléchargement des jeux de données Bright Data
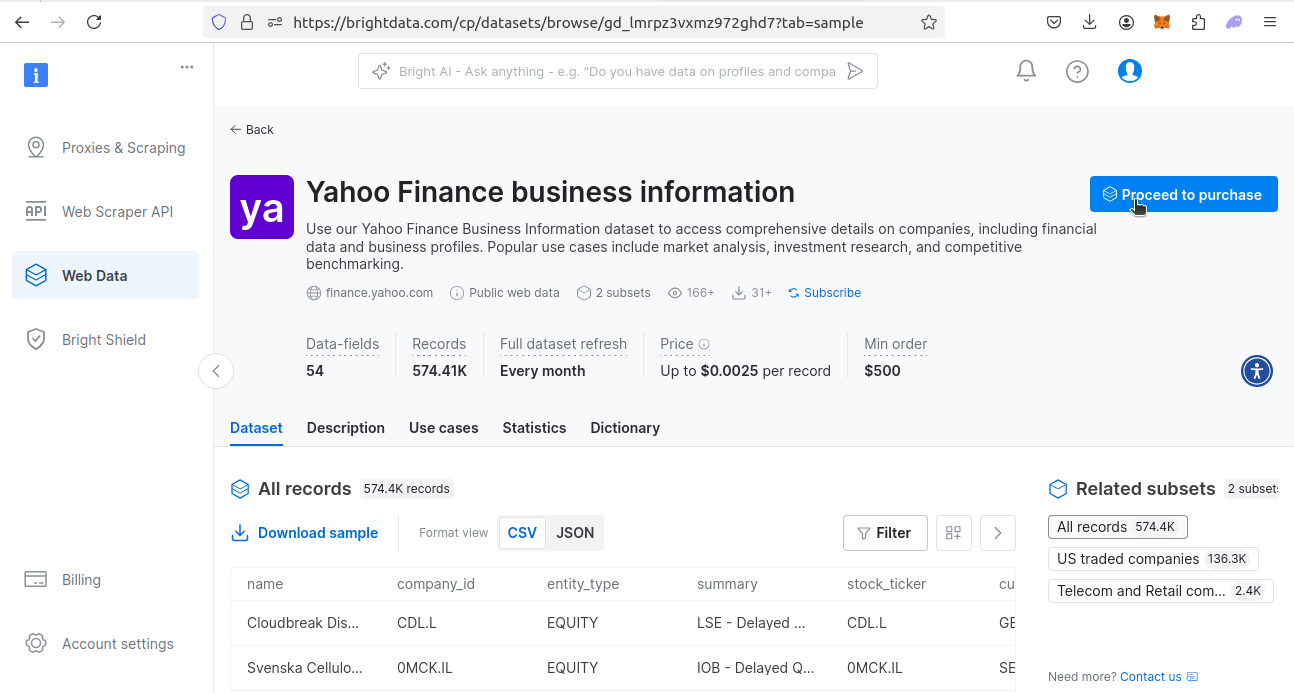
Ensuite, rendez-vous sur notre page consacrée aux Jeux de données financiers. Trouvez l’ensemble de données Yahoo Finance. Cliquez sur le bouton « Afficher l’ensemble de données ».
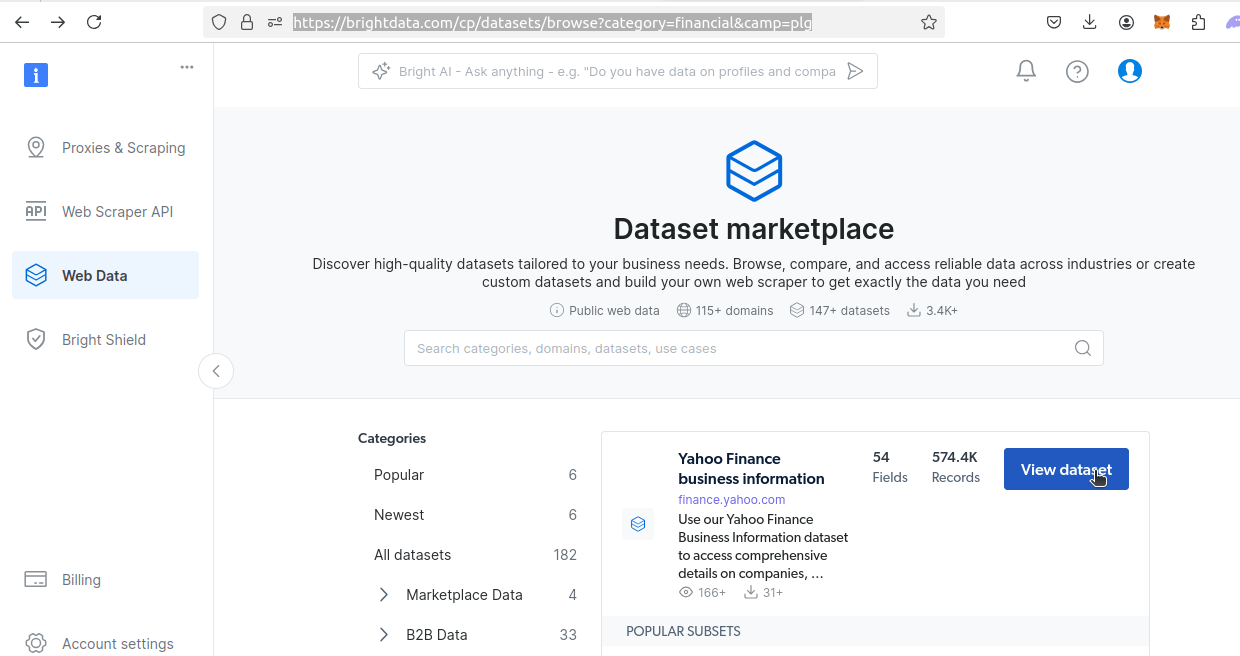
Une fois que vous visualisez l’ensemble de données, plusieurs options s’offrent à vous. Vous pouvez télécharger un échantillon de l’ensemble de données ou acheter l’ensemble de données. Le prix est de 0,0025 $ par enregistrement, avec un achat minimum de 500 $. Si vous souhaitez acheter l’ensemble de données, cliquez sur « Passer à l’achat » et suivez la procédure de paiement.
Avec nos jeux de données pré-créés, le scraping est déjà effectué pour vous. Il vous suffit d’obtenir vos données et de poursuivre votre journée !
Conclusion
Vous avez réussi ! Les données agrégées sont un outil très précieux pour les personnes du monde entier. Vous savez désormais comment les extraire de Google Finance, mais aussi comment les obtenir à partir de notre ensemble de données Yahoo Finance ! À présent, vous devriez savoir comment créer un Scraper basique à l’aide de Python Requests et BeautifulSoup. Vous devriez savoir comment utiliser la méthode find_all() lors de l’analyse d’objets de page avec BeautifulSoup.
Nous avons également abordé certaines méthodes plus avancées, telles que la gestion de la pagination avec des points de terminaison et l’atténuation des techniques de blocage. Mettez ces connaissances en pratique et créez un Scraper ou gagnez du temps et réduisez votre charge de travail en téléchargeant l’un de nos Jeux de données prêts à l’emploi.
Inscrivez-vous dès maintenant et commencez votre essai gratuit dès aujourd’hui, avec des échantillons de jeux de données gratuits.






