

Découvrez l’art de la collecte rapide de données à partir de divers sites Web en maîtrisant le web scraping avec Python. Gagnez du temps et des efforts avec ces compétences essentielles !
Regardez notre tutoriel sur le web scraping avec Python
Le web scraping consiste à extraire des données d’Internet. Plus précisément, un web scraper est un outil permettant d’effectuer une tâche de web scraping. Python est l’un des langages de script les plus simples du marché et comprend diverses bibliothèques de web scraping. Cela en fait le langage de programmation idéal pour le web scraping. Le web scraping sous Python ne nécessite que quelques lignes de code.
Dans ce tutoriel étape par étape, vous apprendrez à créer un script de web scraping simple en Python. Cette application sera exécutée sur un site web entier, extraira des données de chaque page, puis les exportera dans un fichier CSV. Ce tutoriel vous aidera à comprendre quelles sont les meilleures bibliothèques Python pour la collecte de données, lesquelles vous avez intérêt à adopter, et comment les utiliser. Suivez ce tutoriel étape par étape et apprenez à créer un script de web scraping sous Python.
Table des matières
- Prérequis
- Les meilleures bibliothèques Python pour le web scraping
- Construction d’un web scraper en Python
- Conclusion
- FAQ
Prérequis
Pour créer un web scraper sous Python, vous devez disposer au préalable des éléments suivants :
Notez que pip est inclus par défaut dans Python 3.4 ou supérieur. Vous n’avez donc pas besoin de l’installer manuellement. Si vous n’avez pas Python sur votre ordinateur, suivez le guide ci-dessous pour trouver la version correspondant à votre système d’exploitation.
macOS
Par le passé, Python 2.7 était préinstallé sur les Mac, mais ce n’est plus le cas. En fait, cette version est maintenant obsolète.
Si vous voulez la dernière version de Python, vous devez l’installer manuellement. Pour ce faire, téléchargez le programme d’installation, double-cliquez dessus pour le lancer et suivez les instructions de l’assistant d’installation.
Windows
Téléchargez le programme d’installation Python et lancez-le. Dans l’assistant d’installation, assurez-vous de cocher la case « Add python.exe to PATH » (voir ci-dessous) :

Ainsi, Windows reconnaîtra automatiquement les commandes python et pip sur votre terminal. Techniquement, pip est un gestionnaire de packages Python.
Linux
Python est préinstallé sur la plupart des distributions Linux, mais il ne s’agit peut-être pas de la dernière version. La commande permettant d’installer ou de mettre à jour Python sous Linux varie selon le gestionnaire de packages. Dans les distributions Linux basées sur Debian, exécutez :
sudo apt-get install python3Quel que soit votre système d’exploitation, ouvrez le terminal et vérifiez que Python a bien été installé, comme ceci :
python --versionCela devrait renvoyer quelque chose comme :
Python 3.11.0Vous êtes maintenant prêt à construire votre premier web scraper Python. Mais tout d’abord, vous avez besoin d’une bibliothèque Python de web scraping !
Les meilleures bibliothèques Python pour le web scraping
Vous pouvez construire un script de web scraping entier sans recourir à des bibliothèques particulières, mais ce n’est pas la solution idéale. Après tout, Python est bien connu pour sa vaste sélection de packages et il existe de nombreuses bibliothèques de web scraping à choisir. Jetons maintenant un coup d’œil aux plus importantes d’entre elles.
Requêtes
La bibliothèque Requests vous permet d’exécuter des requêtes HTTP en Python. Requests facilite l’envoi de requêtes HTTP, notamment par rapport à la bibliothèque HTTP standard de Python. Requests joue un rôle clé dans les projets de web scraping sous Python. En effet, pour récupérer les données contenues dans une page web, vous devez d’abord les récupérer via une requête HTTP GET. Il vous faudra peut-être également envoyer d’autres requêtes HTTP au serveur du site cible.
Vous pouvez installer des requêtes avec la commande pip suivante :
pip install requestsBeautiful Soup
La bibliothèque Python Beautiful Soup facilite l’extraction d’informations sur des pages web. En particulier, Beautiful Soup fonctionne avec n’importe quel analyseur HTML ou XML et vous fournit tout ce dont vous avez besoin pour vos instructions d’itération, de recherche et de modification sur l’arborescence d’analyse. Notez que vous pouvez utiliser Beautiful Soup avec html.parser, interpréteur fourni avec la bibliothèque standard de Python, qui vous permet d’analyser des fichiers texte HTML. En particulier, Beautiful Soup peut vous aider à parcourir le DOM et à en extraire les données dont vous avez besoin.
Vous pouvez installer Beautiful Soup avec le pip de la manière suivante :
pip install beautifulsoup4Selenium
Selenium est une infrastructure de test automatisée, avancée et open source qui vous permet d’exécuter des opérations sur une page web dans un navigateur. En d’autres termes, vous pouvez utiliser Selenium pour demander à un navigateur d’effectuer certaines tâches. Notez que vous pouvez également utiliser Selenium comme bibliothèque de web scraping afin de mettre à profit ses capacités de navigateur sans tête. Si vous n’êtes pas familier avec ce concept, un navigateur sans tête est un navigateur web qui s’exécute sans GUI (Interface utilisateur graphique). S’il est configuré en mode sans tête, Selenium exécutera le navigateur contrôlé en arrière-plan.
Les pages web visitées dans Selenium sont rendues dans un véritable navigateur. En conséquence, Selenium permet de faire du web scraping sur des pages qui utilisent JavaScript pour la récupération ou le rendu des données. Selenium vous fournit tout ce dont vous avez besoin pour construire un web scraper ; vous n’avez besoin d’aucune autre bibliothèque. Vous pouvez l’installer avec la commande pip suivante :
pip install seleniumConstruction d’un web scraper en Python
Voyons maintenant comment construire un web scraper en Python. Voici ce à quoi ressemble le site cible :

Il s’agit du site Quotes to Scrape, qui n’est rien de plus qu’un atelier de web scraping pour débutants, contenant une liste paginée de citations.
Le but de ce tutoriel est d’apprendre à extraire toutes les données de citations qui s’y trouvent. Pour chaque citation, vous apprendrez à scraper le texte, l’auteur et la liste des balises. Ensuite, les données extraites seront converties en CSV.
Comme vous pouvez le voir, Quotes to Scrape n’est rien de plus qu’un atelier de web scraping pour débutants. Plus précisément, ce site contient une liste de citations sur plusieurs pages. Le web scraper Python que vous allez construire va récupérer toutes les citations contenues sur chaque page et les renvoyer en tant que données CSV.
Étape 1 : choisissez les bonnes bibliothèques Python de web scraping
Tout d’abord, vous devez comprendre quelles sont les meilleures bibliothèques Python de web scraping pour atteindre votre objectif. Pour ce faire, visitez le site cible dans votre navigateur. Cliquez avec le bouton droit de la souris sur l’arrière-plan et sélectionnez Inspect. La fenêtre DevTools du navigateur s’ouvre. Accédez à l’onglet Network et rechargez la page.
Comme vous le remarquerez, le site web cible n’effectue aucune requête Fetch/XHR.

Cela signifie que Quotes to Scrape ne repose pas sur JavaScript pour récupérer dynamiquement des données. En d’autres termes, les pages renvoyées par le serveur contiennent déjà les données d’intérêt. C’est ce qui se passe généralement avec les sites à contenu statique.
Puisque le site web cible ne s’appuie pas sur JavaScript pour afficher la page ou récupérer des données, vous n’avez pas besoin de Selenium pour votre tâche de web scraping. Vous pouvez toujours l’utiliser, mais ce n’est pas conseillé. En effet, Selenium ouvre des pages web dans un navigateur. Puisque cela consomme du temps et des ressources, Selenium introduit des coûts supplémentaires à performances égales. Vous pouvez éviter cela en utilisant Beautiful Soup avec Requests.
Maintenant que vous avez compris quelles bibliothèques Python utiliser pour le web scraping, apprenez à construire un web scraper simple avec Beautiful Soup.
Étape 2 : initialisation d’un projet Python
Avant d’écrire votre première ligne de code, vous devez configurer votre projet Python de web scraping. Techniquement, vous n’avez besoin que d’un seul fichier .py. Cependant, l’utilisation d’un environnement de développement intégré (IDE) avancé facilitera votre travail de codage. Ici, vous allez apprendre à configurer un projet Python dans PyCharm, mais n’importe quel autre IDE Python ferait également l’affaire.
Ouvrez PyCharm et sélectionnez « File > New Project… ». Dans la fenêtre contextuelle « New Project », sélectionnez « Pure Python » et créez un nouveau projet.

Par exemple, vous pouvez appeler votre projet python-web-scraper. Cliquez sur « Create » ; vous avez maintenant accès à votre projet Python vierge. Par défaut, PyCharm initialise un fichier main.py. Pour plus de clarté, appelez-le scraper.py. Voici à quoi ressemblera votre projet :

Comme vous pouvez le constater, PyCharm initialise automatiquement le fichier Python avec quelques lignes de code. Supprimez-les pour repartir de zéro.
Ensuite, vous devez installer les dépendances du projet. Vous pouvez installer Requests et Beautiful Soup en lançant la commande suivante sur le terminal :
pip install requests beautifulsoup4Cela permet d’installer d’un seul coup les deux bibliothèques. Attendez la fin du processus d’installation. Vous êtes maintenant prêt à vous servir de Beautiful Soup et de Requests pour construire votre web crawler/scraper sous Python. Assurez-vous d’importer les deux bibliothèques en ajoutant les lignes suivantes en haut de votre fichier script scraper.py :
import requests
from bs4 import BeautifulSoupPyCharm affiche ces deux lignes en gris car les bibliothèques ne sont pas utilisées dans le code. S’il les souligne en rouge, cela signifie qu’un problème s’est produit pendant le processus d’installation. Dans ce cas, essayez des réinstaller.

Bien ! Vous êtes maintenant prêt à commencer à écrire une logique de web scraping en Python.
Étape 2 : connexion à l’URL cible
La première chose que vous devez faire dans un web scraper est de vous connecter à votre site cible. Tout d’abord, récupérez l’URL complète de la page cible sur votre navigateur. Assurez-vous de copier également la partie http:// ou https:// du protocole HTTP. Dans notre cas, il s’agit de l’URL complète du site cible :
https://quotes.toscrape.comMaintenant, vous pouvez utiliser Requests pour télécharger une page web avec la ligne de code suivante :
page = requests.get('https://quotes.toscrape.com')Cette ligne affecte simplement le résultat de la méthode request.get() à la page des variables. En arrière-plan, request.get() exécute une requête GET en utilisant l’URL transmise comme paramètre. Il renvoie ensuite un objet Response contenant la réponse du serveur à la requête HTTP.
Si la requête HTTP est exécutée avec succès, page.status_code contiendra 200. Le code de réponse d’état HTTP 200 OK indique que la requête HTTP a été exécutée avec succès. Un code d’état HTTP 4xx ou 5xx représente une erreur. Cela peut se produire pour plusieurs raisons, mais gardez à l’esprit que la plupart des sites web bloquent les requêtes qui ne contiennent pas d’agent utilisateur valide. Cet en-tête particulier est une chaîne qui caractérise l’application et la version du système d’exploitation à l’origine d’une requête. En savoir plus sur les agents utilisateurs pour le web scraping.
Vous pouvez définir un en-tête d’agent utilisateur valide dans Requests de la manière suivante :
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
page = requests.get('https://quotes.toscrape.com', headers=headersRequests va maintenant exécuter la requête HTTP avec les en-têtes passés comme paramètre.
Vous devez faire attention à la propriété page.text. Elle contient le document HTML renvoyé par le serveur au format chaîne. Fournissez la propriété de texte à Beautiful Soup pour extraire les données de la page web. Voyons comment.
Vous devez faire attention à la propriété page.text. Elle contient le document HTML renvoyé par le serveur au format chaîne. Fournissez la propriété text à Beautiful Soup pour analyser la page web. Apprenons comment à l’étape suivante.
Étape 3 : Analysez le contenu HTML
Pour analyser le document HTML renvoyé par le serveur suite à la requête GET, passez page.text au constructeur BeautifulSoup() :
soup = BeautifulSoup(page.text, 'html.parser')Le second paramètre spécifie l’interpréteur que Beautiful Soup utilisera.
La variable soup contient maintenant un objet BeautifulSoup. Il s’agit d’une structure arborescente générée à partir de l’analyse syntaxique du document HTML contenu dans page.text avec l’interpréteur html.parser intégré dans Python.
Vous pouvez maintenant l’utiliser pour sélectionner l’élément HTML souhaité dans la page. Voyons comment.
Étape 4 : sélection d’éléments HTML avec Beautiful Soup
Beautiful Soup propose différentes approches pour sélectionner des éléments du DOM. Voyons d’abord :
- find() : renvoie le premier élément HTML correspondant à la stratégie de sélecteur d’entrée, le cas échéant.
- find_all() : renvoie une liste des éléments HTML correspondant à la condition de sélecteur passée par paramètre.
En fonction des paramètres fournis à ces deux méthodes, celles-ci rechercheront des éléments sur la page de différentes manières. Plus précisément, vous pouvez sélectionner des éléments HTML :
- Par balise :
# get all <h1> elements
# on the page
h1_elements = soup.find_all('h1')
- Par ID :
# get the element with id="main-title"
main_title_element = soup.find(id='main-title')- Par texte :
# find the footer element
# based on the text it contains
footer_element = soup.find(text={'Powered by WordPress'})- Par attribut :
# find the email input element
# through its "name" attribute
email_element = soup.find(attrs={'name': 'email'})- Par classe :
# find all the centered elements
# on the page
centered_element = soup.find_all(class_='text-center')
En concaténant ces méthodes, vous pouvez extraire n’importe quel élément HTML de la page. Observez l’exemple ci-dessous :
# get all "li" elements
# in the ".navbar" element
soup.find(class_='navbar').find_all('li')Pour faciliter les choses, Beautiful Soup utilise également la méthode select(). Cela vous permet d’appliquer directement un sélecteur CSS :
# get all "li" elements
# in the ".navbar" element
soup.select('.navbar > li')Notez qu’au moment de la rédaction de ces lignes, les sélecteurs XPath ne sont pas pris en charge.
Ce qui est important à apprendre, c’est que pour extraire des données d’une page web, vous devez d’abord identifier les éléments HTML qui vous intéressent. En particulier, vous devez définir une stratégie de sélection pour les éléments qui contiennent les données que vous souhaitez extraire.
Vous pouvez y parvenir en utilisant les outils de développement proposés par votre navigateur. Dans Chrome, cliquez avec le bouton droit de la souris sur l’élément HTML souhaité et sélectionnez l’option « Inspect ». En l’occurrence, faites-le sur un élément de citation.

Comme vous pouvez le voir ici, l’élément HTML <div> du devis est identifié par la classe quote. Celle-ci contient :
- Le texte de la citation dans un élément HTML
<span> - L’auteur de la citation dans un élément HTML
<small> - Une liste de balises dans un élément
<div>, chacune étant contenue dans un élément HTML<a>
Techniquement, vous pouvez extraire ces données à l’aide des sélecteurs CSS suivants sur .quote :
.text.author.tags .tag
Étape 5 : extraction des données des éléments
Tout d’abord, vous avez besoin d’une structure de données dans laquelle stocker les données collectées. Pour ce faire, initialisez une variable de tableau.
quotes = []Ensuite, utilisez soup pour extraire les éléments de citation du DOM en appliquant le sélecteur CSS .quote défini précédemment :
quote_elements = soup.find_all('div', class_='quote')La méthode find_all() renvoie la liste de tous les éléments HTML
for quote_element in quote_elements:
# extract the text of the quote
text = quote_element.find('span', class_='text').text
# extract the author of the quote
author = quote_element.find('small', class_='author').text
# extract the tag <a> HTML elements related to the quote
tag_elements = quote_element.select('.tags .tag')
# store the list of tag strings in a list
tags = []
for tag_element in tag_elements:
tags.append(tag_element.text)Grâce à la méthode find() de Beautiful Soup, vous pouvez extraire l’élément HTML précis qui vous intéresse. Puisqu’il y a plusieurs chaînes de balises associées à la citation, vous devez stocker celles-ci dans une liste.
Vous pouvez ensuite transformer ces données extraites en dictionnaire et les ajouter à la liste des citations, comme ceci :
quotes.append(
{
'text': text,
'author': author,
'tags': ', '.join(tags) # merge the tags into a "A, B, ..., Z" string
}
)Stocker les données dans un dictionnaire structuré permet d’y accéder et de les comprendre.
Bien ! Vous venez d’apprendre à extraire toutes les données de citations sur une page unique. Mais n’oubliez pas que votre site cible est constitué de plusieurs pages web. Voyons maintenant comment parcourir l’ensemble du site web.
Étape 6 : implémentez la logique de crawling
En bas de la page d’accueil, vous trouverez un élément HTML “Next →” qui redirige vers la page suivante. Cet élément HTML figure sur toutes les pages sauf la dernière. Un tel scénario est commun dans tous les sites web qui s’étalent sur plusieurs pages.

En suivant le lien contenu dans cet élément HTML, vous pouvez facilement naviguer sur l’ensemble du site. Commencez donc par la page d’accueil et voyez comment parcourir chaque page du site cible. Il vous suffit de rechercher l’élément HTML .Next
Vous pouvez implémenter votre logique de crawling comme ceci :
# the URL of the home page of the target website
base_url = 'https://quotes.toscrape.com'
# retrieve the page and initializing soup...
# get the "Next →" HTML element
next_li_element = soup.find('li', class_='next')
# if there is a next page to scrape
while next_li_element is not None:
next_page_relative_url = next_li_element.find('a', href=True)['href']
# get the new page
page = requests.get(base_url + next_page_relative_url, headers=headers)
# parse the new page
soup = BeautifulSoup(page.text, 'html.parser')
# scraping logic...
# look for the "Next →" HTML element in the new page
next_li_element = soup.find('li', class_='next')La boucle where est itérée sur chaque page jusqu’à ce qu’il n’y ait plus de page suivante. Plus précisément, elle permet d’extraire l’URL de la page suivante et de l’utiliser pour créer l’URL de la prochaine page à scraper. Elle télécharge ensuite la page suivante. Puis elle la scrape et réitère la logique.
Parfait ! Vous savez maintenant extraire les données de l’ensemble d’un site web. Il vous reste maintenant à apprendre comment convertir les données extraites dans un format plus exploitable, par exemple CSV.
Étape 7 : exportation des données extraites dans un fichier CSV
Voyons comment exporter la liste de dictionnaires contenant les données des citations dans un fichier CSV. Nous allons pour cela utiliser les lignes suivantes :
import csv
# scraping logic...
# reading the "quotes.csv" file and creating it
# if not present
csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='')
# initializing the writer object to insert data
# in the CSV file
writer = csv.writer(csv_file)
# writing the header of the CSV file
writer.writerow(['Text', 'Author', 'Tags'])
# writing each row of the CSV
for quote in quotes:
writer.writerow(quote.values())
# terminating the operation and releasing the resources
csv_file.close()Ce code écrit les données de citations contenues dans la liste des dictionnaires dans un fichier quotes.csv. Notez que csv fait partie de la bibliothèque standard de Python. Vous pouvez donc l’importer et l’utiliser sans installer de dépendance supplémentaire.
Plus précisément, il vous suffit de créer un fichier CSV avec open(). Vous pouvez ensuite remplir ce fichier avec la fonction writerow() de l’objet Writer de la bibliothèque csv. Chaque dictionnaire de citation est alors écrit en tant que ligne au format CSV.
Vous êtes passé de données brutes contenues dans un site web à des données semi-structurées stockées dans un fichier CSV. Le processus d’extraction de données est terminé et vous pouvez maintenant jeter un coup d’œil à l’ensemble de votre web scraper Python.
Étape 8 : au final
Voici à quoi ressemble notre script Python complet de web scraping :
import requests
from bs4 import BeautifulSoup
import csv
def scrape_page(soup, quotes):
# retrieving all the quote <div> HTML element on the page
quote_elements = soup.find_all('div', class_='quote')
# iterating over the list of quote elements
# to extract the data of interest and store it
# in quotes
for quote_element in quote_elements:
# extracting the text of the quote
text = quote_element.find('span', class_='text').text
# extracting the author of the quote
author = quote_element.find('small', class_='author').text
# extracting the tag <a> HTML elements related to the quote
tag_elements = quote_element.find('div', class_='tags').find_all('a', class_='tag')
# storing the list of tag strings in a list
tags = []
for tag_element in tag_elements:
tags.append(tag_element.text)
# appending a dictionary containing the quote data
# in a new format in the quote list
quotes.append(
{
'text': text,
'author': author,
'tags': ', '.join(tags) # merging the tags into a "A, B, ..., Z" string
}
)
# the url of the home page of the target website
base_url = 'https://quotes.toscrape.com'
# defining the User-Agent header to use in the GET request below
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
# retrieving the target web page
page = requests.get(base_url, headers=headers)
# parsing the target web page with Beautiful Soup
soup = BeautifulSoup(page.text, 'html.parser')
# initializing the variable that will contain
# the list of all quote data
quotes = []
# scraping the home page
scrape_page(soup, quotes)
# getting the "Next →" HTML element
next_li_element = soup.find('li', class_='next')
# if there is a next page to scrape
while next_li_element is not None:
next_page_relative_url = next_li_element.find('a', href=True)['href']
# getting the new page
page = requests.get(base_url + next_page_relative_url, headers=headers)
# parsing the new page
soup = BeautifulSoup(page.text, 'html.parser')
# scraping the new page
scrape_page(soup, quotes)
# looking for the "Next →" HTML element in the new page
next_li_element = soup.find('li', class_='next')
# reading the "quotes.csv" file and creating it
# if not present
csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='')
# initializing the writer object to insert data
# in the CSV file
writer = csv.writer(csv_file)
# writing the header of the CSV file
writer.writerow(['Text', 'Author', 'Tags'])
# writing each row of the CSV
for quote in quotes:
writer.writerow(quote.values())
# terminating the operation and releasing the resources
csv_file.close()Comme nous l’avons montré ici, vous pouvez construire un web scraper en moins de 100 lignes de code. Ce script Python est capable de parcourir un site web entier, d’extraire automatiquement toutes ses données et de les exporter en CSV.
Félicitations ! Vous venez d’apprendre à construire un web scraper Python avec Requests et Beautiful Soup.
Étape 9 : exécutez le script Python de web scraping
Si vous utilisez PyCharm, exécutez le script en cliquant sur le bouton ci-dessous :

Sinon, lancez la commande Python suivante sur votre terminal, à l’intérieur du répertoire du projet :
python scraper.pyAttendez la fin du processus ; vous avez maintenant accès à un fichier quotes.csv. Ouvrez-le ; il doit contenir les données suivantes :
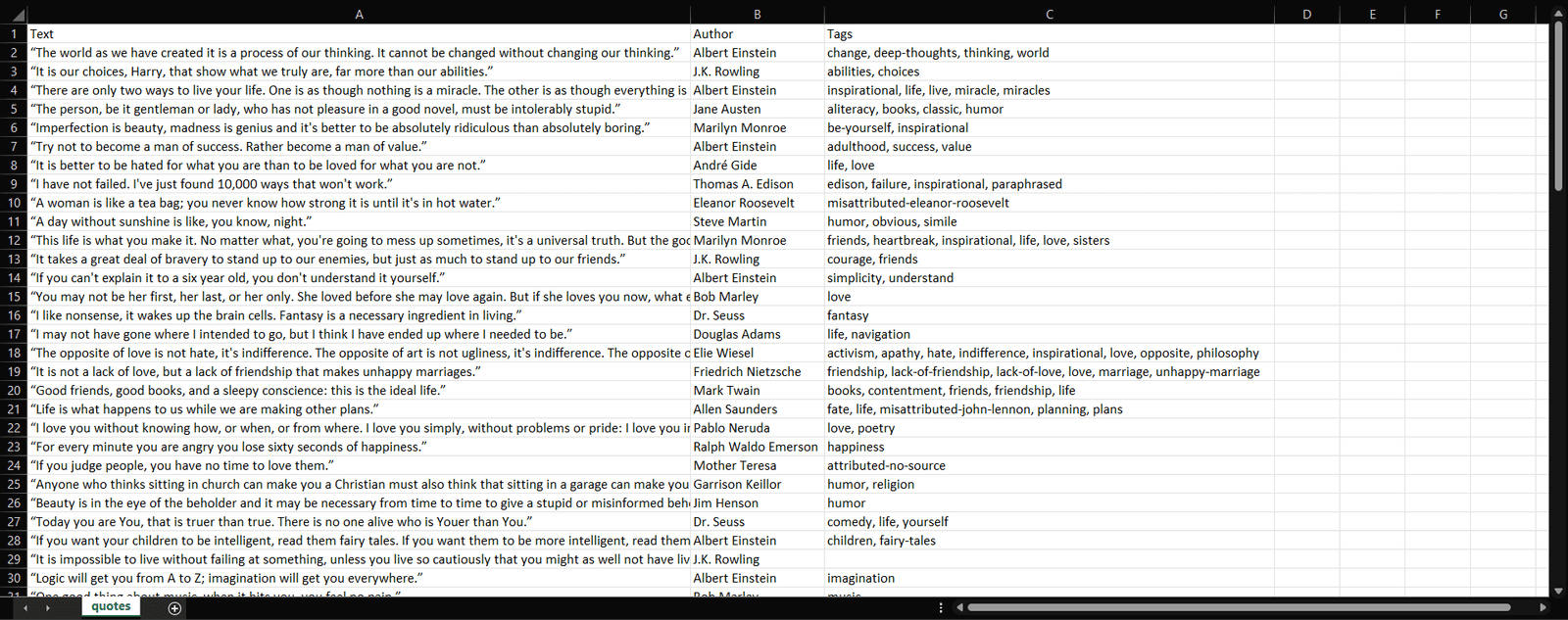
Et voilà ! Vous avez maintenant les 100 citations du site cible dans un fichier unique, sous un format facile à lire.
Conclusion
Dans ce tutoriel, vous avez découvert ce qu’est le web scraping avec Python, ce dont vous avez besoin pour démarrer avec Python, ainsi que les bibliothèques Python les plus adaptées au web scraping. Ensuite, vous avez vu comment utiliser Beautiful Soup et Requests pour construire une application de web scraping à travers un exemple réel. Comme vous l’avez appris, le web scraping sous Python ne nécessite que quelques lignes de code.
Cependant, le web scraping comporte plusieurs défis. Dans le détail, les technologies anti-bot et anti-scraping sont devenues de plus en plus populaires. Et c’est là qu’interviennent les procurations.
Un serveur proxy agit comme intermédiaire entre votre script de scraping dans X et les pages cibles. Il reçoit vos demandes, les transmet au serveur de destination, reçoit les réponses et vous les renvoie. De cette façon, le site cible verra son adresse IP et non la vôtre. Cela signifie cacher votre adresse IP pour préserver sa réputation et sauvegarder votre vie privée, en évitant les interdictions et les restrictions géographiques. Grâce aux proxys rotatifs, vous pouvez obtenir de nouvelles adresses IP à chaque demande pour contourner même les systèmes limitant le débit.
Il ne reste plus qu’à sélectionner un fournisseur fiable qui peut vous donner accès à des serveurs proxy de premier ordre avec des adresses IP réputées. Bright Data est le fournisseur proxy le plus populaire au monde, au service de dizaines d’entreprises Fortune 500 et de plus de 20 000 clients. Son réseau proxy mondial comprend :
- Proxy de centre de données – Plus de 770 000 IP provenant de centres de données.
- Proxies résidentiels : plus de 72 millions d’adresses IP provenant d’appareils résidentiels dans plus de 195 pays.
- Proxies FAI : plus de 700 000 IP provenant d’appareils enregistrés auprès d’un FAI.
FAQ
Python est-il un bon langage pour le web scraping ?
Python n’est pas seulement un bon choix pour le web scraping ; il est en fait considéré comme l’un des meilleurs langages pour cela. Cela est dû à sa lisibilité et à sa courbe d’apprentissage douce. En outre, Python bénéficie de l’une des plus grandes communautés dans le monde de l’informatique et d’un large éventail de bibliothèques et d’outils conçus pour le web scraping.
Le web scraping et le web crawling sont-ils des disciplines de la science des données ?
Oui, le web scraping et le web crawling sont des disciplines de la science des données. Le web scraping et le web crawling servent de base à tous les autres produits dérivés pouvant être obtenus à partir de données structurées et non structurées. Cela comprend les analyses, les modèles/résultats algorithmiques, les informations et les « connaissances applicables ».
Comment extraire des données spécifiques d’un site web avec Python ?
L’extraction des données d’un site web avec Python implique l’inspection de la page de votre URL cible, l’identification des données que vous souhaitez extraire, l’écriture et l’exécution du code d’extraction de données, et enfin le stockage des données au format souhaité.
Comment construire un web scraper avec Python ?
La première étape pour construire un web scraper avec Python est d’utiliser des méthodes de chaîne afin d’analyser les données du site web, puis d’analyser les données du site web à l’aide d’un analyseur HTML, et enfin d’interagir avec les formulaires et les composants nécessaires sur le site web.





