

Dans ce guide, nous allons construire un serveur MCP local en Python pour récupérer les données des produits Amazon à la demande. Vous apprendrez les principes fondamentaux de MCP, comment écrire et exécuter votre propre serveur, et comment le connecter à des outils de développement tels que Claude Desktop et Cursor IDE. Nous terminerons par une intégration réelle de Bright Data MCP pour des données web en temps réel et prêtes pour l’IA.
Plongeons dans le vif du sujet.
Le goulot d’étranglement : Pourquoi les LLM ont du mal à interagir avec le monde réel (et comment le MCP y remédie)
Les grands modèles de langage (LLM) sont incroyablement puissants pour traiter et générer du texte à partir d’énormes ensembles de données d’apprentissage. Mais ils présentent une limitation majeure : ils ne peuvent pas interagir de manière native avec le monde réel. Cela signifie qu’ils n’ont pas accès aux fichiers locaux, qu’ils ne peuvent pas exécuter de scripts personnalisés et qu’ils ne peuvent pas récupérer de données en direct sur le web.
Prenons un exemple simple : demandez à Claude d’extraire les détails d’un produit à partir d’une page Amazon, et il n’y parviendra pas. Pourquoi ? Parce qu’il n’a pas la capacité intégrée de naviguer sur le web ou de déclencher des actions externes.

Sans outils externes, les LLM ne peuvent pas effectuer des tâches pratiques qui reposent sur des données en temps réel ou sur l’intégration avec des systèmes externes.
C’est là qu’intervient le protocole de contexte de modèle (MCP) d’Anthropic. Il permet aux LLM de communiquer avec des outils externes (scrapers, API ou scripts) de manière sécurisée et standardisée.
Voici la différence en action. Après avoir intégré un serveur MCP personnalisé, nous avons pu extraire des données structurées sur les produits Amazon directement via Claude :

Ne vous préoccupez pas encore de la manière dont cela fonctionne : nous vous expliquerons tout pas à pas plus loin dans ce guide.
Pourquoi le programme MCP est-il important ?
- Normalisation : MCP a fourni une interface normalisée pour les systèmes basés sur le LLM afin de se connecter à des outils et des données externes, de la même manière que les API ont normalisé les intégrations web. Cela réduit considérablement le besoin d’intégrations personnalisées et accélère le développement.
- Flexibilité et évolutivité : Les développeurs peuvent changer de LLM ou de plateforme d’hébergement sans avoir à réécrire les intégrations d’outils. MCP prend en charge plusieurs transports de communication (tels que
stdio), ce qui lui permet de s’adapter à différentes configurations. - Amélioration des capacités des gestionnaires de l’apprentissage tout au long de la vie : En connectant les LLM à des données en temps réel et à des outils externes, le MCP leur permet d’aller au-delà des réponses statiques. Ils peuvent désormais renvoyer des informations actuelles et pertinentes et déclencher des actions réelles basées sur le contexte.
Analogie: Considérez le MCP comme une interface USB pour les LLM. Tout comme l’USB permet à différents appareils (claviers, imprimantes, disques externes) de se brancher sur n’importe quelle machine compatible sans avoir besoin de pilotes spéciaux, le MCP permet aux LLM de se connecter à une large gamme d’outils à l’aide d’un protocole standardisé, sans qu’il soit nécessaire de procéder à une intégration personnalisée à chaque fois.
Qu’est-ce que le protocole de contexte de modèle (MCP) ?
Model Context Protocol (MCP) est une norme ouverte développée par Anthropic qui permet aux grands modèles de langage (LLM) d’interagir avec des outils externes, des API et des sources de données de manière cohérente et sécurisée. Il agit comme un connecteur universel, permettant aux LLM d’effectuer des tâches réelles telles que le scraping de sites web, l’interrogation de bases de données ou le déclenchement de scripts.
Si Anthropic l’a introduit, MCP est ouvert et extensible, ce qui signifie que tout le monde peut mettre en œuvre la norme ou y contribuer. Si vous avez travaillé avec Retrieval-Augmented Generation (RAG), vous comprendrez le concept. MCP s’appuie sur cette idée en normalisant les interactions au moyen d’une interface JSON-RPC légère afin que les modèles puissent accéder aux données en temps réel et prendre des mesures.
Architecture MCP : Comment ça marche
À la base, MCP normalise la communication entre un modèle d’IA et les capacités externes.
Idée maîtresse : Une interface normalisée (généralement JSON-RPC 2.0 sur des transports tels que stdio) permet à un LLM (via un client) de découvrir et d’invoquer des outils exposés par des serveurs externes.
MCP fonctionne selon une architecture client-serveur avec trois composants clés :
- MCP Host: L’environnement ou l’application qui initie et gère les interactions entre le LLM et les outils externes. Il s’agit par exemple d’assistants d’intelligence artificielle tels que Claude Desktop ou d’IDE tels que Cursor.
- Client MCP: Composant de l’hôte qui établit et maintient les connexions avec les serveurs MCP, en traitant les protocoles de communication et en gérant l’échange de données.
- Serveur MCP : Un programme (que nous créons en tant que développeurs) qui met en œuvre le protocole MCP et expose un ensemble spécifique de capacités. Un serveur MCP peut s’interfacer avec une base de données, un service web ou, dans notre cas, un site web (Amazon). Les serveurs exposent leurs fonctionnalités de manière standardisée
:Polylang placeholder do not modify
Voici le schéma de l’architecture MCP :

Source de l’image : Modèle de protocole contextuel
Dans cette configuration, l’hôte (Claude Desktop ou Cursor IDE) génère un client MCP, qui se connecte ensuite à un serveur MCP externe. Ce serveur expose des outils, des ressources et des invites, permettant à l’IA d’interagir avec eux selon ses besoins.
En bref, le flux de travail fonctionne comme suit :
- L’utilisateur envoie un message du type “Récupérer les informations sur le produit à partir de ce lien Amazon”.
- Le client MCP recherche un outil enregistré capable de prendre en charge cette tâche
- Le client envoie une demande structurée au serveur MCP
- Le serveur MCP exécute l’action appropriée (par exemple, lancement d’un navigateur sans tête).
- Le serveur renvoie des résultats structurés au client MCP
- Le client transmet les résultats au LLM, qui les présente à l’utilisateur.
Création d’un serveur MCP personnalisé
Construisons un serveur Python MCP pour récupérer les pages produits d’Amazon.

Ce serveur exposera deux outils : l’un pour télécharger du HTML et l’autre pour extraire des informations structurées. Vous interagirez avec le serveur via un client LLM dans Cursor ou Claude Desktop.
Étape 1 : Mise en place de l’environnement
Tout d’abord, assurez-vous que Python 3 est installé. Ensuite, créez et activez un environnement virtuel :
python -m venv mcp-amazon-scraper
# On macOS/Linux:
source mcp-amazon-scraper/bin/activate
# On Windows:
.mcp-amazon-scraperScriptsactivateInstallez les bibliothèques requises : MCP Python SDK, Playwright et LXML.
pip install mcp playwright lxml
# Install browser binaries for Playwright
python -m playwright installIl s’agit d’une installation :
- mcp: SDK Python pour les serveurs et clients Model Context Protocol qui gère tous les détails de la communication JSON-RPC
- playwright: Bibliothèque d’automatisation de navigateur qui fournit des capacités de navigateur sans tête pour le rendu et le scraping de sites web à fort contenu JavaScript.
- lxml: Bibliothèque d’analyse XML/HTML rapide qui facilite l’extraction d’éléments de données spécifiques à partir de pages web à l’aide de requêtes XPath.
En bref, le MCP Python SDK(mcp) gère tous les détails du protocole, vous permettant d’exposer des outils que Claude ou Cursor peuvent appeler via des invites en langage naturel. Playwright nous permet de rendre des pages web complètement (y compris le contenu JavaScript), et lxml nous donne de puissantes capacités d’analyse HTML.
Étape 2 : Initialisation du serveur MCP
Créez un fichier Python nommé amazon_scraper_mcp.py. Commencez par importer les modules nécessaires et initialiser le serveur FastMCP:
import os
import asyncio
from lxml import html as lxml_html
from mcp.server.fastmcp import FastMCP
from playwright.async_api import async_playwright
# Define a temporary file path for the HTML content
HTML_FILE = os.path.join(os.getenv("TMPDIR", "/tmp"), "amazon_product_page.html")
# Initialize the MCP server with a descriptive name
mcp = FastMCP("Amazon Product Scraper")
print("MCP Server Initialized: Amazon Product Scraper")Cela crée une instance du serveur MCP. Nous allons maintenant y ajouter des outils.
Étape 3 : Mise en œuvre de l’outil fetch_page
Cet outil prend une URL en entrée, utilise Playwright pour naviguer jusqu’à la page, attend que le contenu se charge, télécharge le code HTML et l’enregistre dans notre fichier temporaire.
@mcp.tool()
async def fetch_page(url: str) -> str:
"""
Fetches the HTML content of the given Amazon product URL using Playwright
and saves it to a temporary file. Returns a status message.
"""
print(f"Executing fetch_page for URL: {url}")
try:
async with async_playwright() as p:
# Launch headless Chromium browser
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Navigate to the URL with a generous timeout
await page.goto(url, timeout=90000, wait_until="domcontentloaded")
# Wait for a key element (e.g., body) to ensure basic loading
await page.wait_for_selector("body", timeout=30000)
# Add a small delay for any dynamic content rendering via JavaScript
await asyncio.sleep(5)
html_content = await page.content()
with open(HTML_FILE, "w", encoding="utf-8") as f:
f.write(html_content)
await browser.close()
print(f"Successfully fetched and saved HTML to {HTML_FILE}")
return f"HTML content for {url} downloaded and saved successfully to {HTML_FILE}."
except Exception as e:
error_message = f"Error fetching page {url}: {str(e)}"
print(error_message)
return error_messageCette fonction asynchrone utilise Playwright pour gérer le rendu JavaScript potentiel sur les pages Amazon. Le décorateur @mcp.tool() enregistre cette fonction en tant qu’outil appelable au sein de notre serveur.
Étape 4 : Mise en œuvre de l’outil extract_info
Cet outil lit le fichier HTML enregistré par fetch_page, l’analyse à l’aide des sélecteurs LXML et XPath et renvoie un dictionnaire contenant les informations extraites sur le produit.
def _extract_xpath(tree, xpath, default="N/A"):
"""Helper function to extract text using XPath, returning default if not found."""
try:
# Use text_content() to get text from node and children, strip whitespace
result = tree.xpath(xpath)
if result:
return result[0].text_content().strip()
return default
except Exception:
return default
def _extract_price(price_str):
"""Helper function to parse price string into a float."""
if price_str == "N/A":
return None
try:
# Remove currency symbols and commas, handle potential whitespace
cleaned_price = "".join(filter(str.isdigit or str.__eq__("."), price_str))
return float(cleaned_price)
except (ValueError, TypeError):
return None
@mcp.tool()
def extract_info() -> dict:
"""
Parses the saved HTML file (downloaded by fetch_page) to extract
Amazon product details like title, price, rating, features, etc.
Returns a dictionary of the extracted data.
"""
print(f"Executing extract_info from file: {HTML_FILE}")
if not os.path.exists(HTML_FILE):
return {
"error": f"HTML file not found at {HTML_FILE}. Please run fetch_page first."
}
try:
with open(HTML_FILE, "r", encoding="utf-8") as f:
page_html = f.read()
tree = lxml_html.fromstring(page_html)
# --- XPath Selectors for Amazon Product Details ---
title = _extract_xpath(tree, '//span[@id="productTitle"]')
# Handle different price structures (main price, sale price)
price_whole = _extract_xpath(tree, '//span[contains(@class, "a-price-whole")]')
price_fraction = _extract_xpath(
tree, '//span[contains(@class, "a-price-fraction")]'
)
price_str = (
f"{price_whole}.{price_fraction}"
if price_whole != "N/A"
else _extract_xpath(tree, '//span[contains(@class,"a-offscreen")]')
) # Fallback to offscreen if needed
price = _extract_price(price_str)
# Original price (strike-through)
original_price_str = _extract_xpath(
tree, '//span[@class="a-price a-text-price"]//span[@class="a-offscreen"]'
)
original_price = _extract_price(original_price_str)
# Rating
rating_text = _extract_xpath(tree, '//span[@id="acrPopover"]/@title')
rating = None
if rating_text != "N/A":
try:
rating = float(rating_text.split()[0])
except (ValueError, IndexError):
rating = None
# Review Count
reviews_text = _extract_xpath(tree, '//span[@id="acrCustomerReviewText"]')
review_count = None
if reviews_text != "N/A":
try:
review_count = int(reviews_text.split()[0].replace(",", ""))
except (ValueError, IndexError):
review_count = None
# Availability
availability = _extract_xpath(
tree,
'//div[@id="availability"]//span/text()',
)
# Features (bullet points)
feature_elements = tree.xpath(
'//div[@id="feature-bullets"]//li//span[@class="a-list-item"]'
)
features = [
elem.text_content().strip()
for elem in feature_elements
if elem.text_content().strip()
]
# Calculate Discount
discount = None
if price and original_price and original_price > price:
discount = round(((original_price - price) / original_price) * 100)
extracted_data = {
"title": title,
"price": price,
"original_price": original_price,
"discount_percent": discount,
"rating_stars": rating,
"review_count": review_count,
"features": features,
"availability": availability.strip(),
}
print(f"Successfully extracted data: {extracted_data}")
return extracted_data
except Exception as e:
error_message = f"Error parsing HTML: {str(e)}"
print(error_message) # Added for logging
return {"error": error_message}Cette fonction utilise la fonction fromstring de LXML pour analyser le code HTML et des sélecteurs XPath robustes pour trouver les éléments souhaités.
Étape 5 : Exécuter le serveur
Enfin, ajoutez les lignes suivantes à la fin de votre script amazon_scraper_mcp.py pour démarrer le serveur en utilisant le mécanisme de transport stdio, qui est standard pour les serveurs MCP locaux communiquant avec des clients tels que Claude Desktop ou Cursor.
if __name__ == "__main__":
print("Starting MCP Server with stdio transport...")
# Run the server, listening via standard input/output
mcp.run(transport="stdio")Code complet(amazon_scraper_mcp.py)
import os
import asyncio
from lxml import html as lxml_html
from mcp.server.fastmcp import FastMCP
from playwright.async_api import async_playwright
# Define a temporary file path for the HTML content
HTML_FILE = os.path.join(os.getenv("TMPDIR", "/tmp"), "amazon_product_page.html")
# Initialize the MCP server with a descriptive name
mcp = FastMCP("Amazon Product Scraper")
print("MCP Server Initialized: Amazon Product Scraper")
@mcp.tool()
async def fetch_page(url: str) -> str:
"""
Fetches the HTML content of the given Amazon product URL using Playwright
and saves it to a temporary file. Returns a status message.
"""
print(f"Executing fetch_page for URL: {url}")
try:
async with async_playwright() as p:
# Launch headless Chromium browser
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Navigate to the URL with a generous timeout
await page.goto(url, timeout=90000, wait_until="domcontentloaded")
# Wait for a key element (e.g., body) to ensure basic loading
await page.wait_for_selector("body", timeout=30000)
# Add a small delay for any dynamic content rendering via JavaScript
await asyncio.sleep(5)
html_content = await page.content()
with open(HTML_FILE, "w", encoding="utf-8") as f:
f.write(html_content)
await browser.close()
print(f"Successfully fetched and saved HTML to {HTML_FILE}")
return f"HTML content for {url} downloaded and saved successfully to {HTML_FILE}."
except Exception as e:
error_message = f"Error fetching page {url}: {str(e)}"
print(error_message)
return error_message
def _extract_xpath(tree, xpath, default="N/A"):
"""Helper function to extract text using XPath, returning default if not found."""
try:
# Use text_content() to get text from node and children, strip whitespace
result = tree.xpath(xpath)
if result:
return result[0].text_content().strip()
return default
except Exception:
return default
def _extract_price(price_str):
"""Helper function to parse price string into a float."""
if price_str == "N/A":
return None
try:
# Remove currency symbols and commas, handle potential whitespace
cleaned_price = "".join(filter(str.isdigit or str.__eq__("."), price_str))
return float(cleaned_price)
except (ValueError, TypeError):
return None
@mcp.tool()
def extract_info() -> dict:
"""
Parses the saved HTML file (downloaded by fetch_page) to extract
Amazon product details like title, price, rating, features, etc.
Returns a dictionary of the extracted data.
"""
print(f"Executing extract_info from file: {HTML_FILE}")
if not os.path.exists(HTML_FILE):
return {
"error": f"HTML file not found at {HTML_FILE}. Please run fetch_page first."
}
try:
with open(HTML_FILE, "r", encoding="utf-8") as f:
page_html = f.read()
tree = lxml_html.fromstring(page_html)
# --- XPath Selectors for Amazon Product Details ---
title = _extract_xpath(tree, '//span[@id="productTitle"]')
# Handle different price structures (main price, sale price)
price_whole = _extract_xpath(tree, '//span[contains(@class, "a-price-whole")]')
price_fraction = _extract_xpath(
tree, '//span[contains(@class, "a-price-fraction")]'
)
price_str = (
f"{price_whole}.{price_fraction}"
if price_whole != "N/A"
else _extract_xpath(tree, '//span[contains(@class,"a-offscreen")]')
) # Fallback to offscreen if needed
price = _extract_price(price_str)
# Original price (strike-through)
original_price_str = _extract_xpath(
tree, '//span[@class="a-price a-text-price"]//span[@class="a-offscreen"]'
)
original_price = _extract_price(original_price_str)
# Rating
rating_text = _extract_xpath(tree, '//span[@id="acrPopover"]/@title')
rating = None
if rating_text != "N/A":
try:
rating = float(rating_text.split()[0])
except (ValueError, IndexError):
rating = None
# Review Count
reviews_text = _extract_xpath(tree, '//span[@id="acrCustomerReviewText"]')
review_count = None
if reviews_text != "N/A":
try:
review_count = int(reviews_text.split()[0].replace(",", ""))
except (ValueError, IndexError):
review_count = None
# Availability
availability = _extract_xpath(
tree,
'//div[@id="availability"]//span/text()',
)
# Features (bullet points)
feature_elements = tree.xpath(
'//div[@id="feature-bullets"]//li//span[@class="a-list-item"]'
)
features = [
elem.text_content().strip()
for elem in feature_elements
if elem.text_content().strip()
]
# Calculate Discount
discount = None
if price and original_price and original_price > price:
discount = round(((original_price - price) / original_price) * 100)
extracted_data = {
"title": title,
"price": price,
"original_price": original_price,
"discount_percent": discount,
"rating_stars": rating,
"review_count": review_count,
"features": features,
"availability": availability.strip(),
}
print(f"Successfully extracted data: {extracted_data}")
return extracted_data
except Exception as e:
error_message = f"Error parsing HTML: {str(e)}"
print(error_message) # Added for logging
return {"error": error_message}
if __name__ == "__main__":
print("Starting MCP Server with stdio transport...")
# Run the server, listening via standard input/output
mcp.run(transport="stdio")Intégration de votre serveur MCP personnalisé
Maintenant que le script du serveur est prêt, connectons-le aux clients MCP tels que Claude Desktop et Cursor.
Connexion à Claude Desktop
Étape 1 : Ouvrez le bureau de Claude.
Étape 2 : Naviguez vers Paramètres -> Développeur -> Modifier la configuration. Cela ouvrira le fichier claude_desktop_config.json dans votre éditeur de texte par défaut.

Étape 3 : Ajoutez une entrée pour votre serveur sous la clé mcpServers. Assurez-vous de remplacer le chemin dans args par le chemin absolu de votre fichier amazon_scraper_mcp.py.
{
"mcpServers": {
"amazon_product_scraper": {
"command": "python", // Or python3 if needed
"args": ["/full/path/to/your/amazon_scraper_mcp.py"], // <-- IMPORTANT: Use the correct absolute path
}
}
}Étape 4 : Enregistrez le fichier claude_desktop_config.json, puis fermez et rouvrez Claude Desktop pour que les modifications soient prises en compte.
Étape 5 : Dans Claude Desktop, vous devriez maintenant voir une petite icône d’outils (comme un marteau 🔨) dans la zone de saisie du chat.
Étape 6 : En cliquant dessus, vous devriez voir apparaître votre “Amazon Product Scraper” avec ses outils fetch_page et extract_info.

Étape 7 : Envoyez une invite, par exemple : “Obtenir le prix actuel, le prix original et l’évaluation de ce produit Amazon : https://www.amazon.com/dp/B09C13PZX7″.
Étape 8 : Claude détectera que cela nécessite des outils externes et vous demandera la permission d’exécuter d’abord fetch_page et ensuite extract_info. Cliquez sur “Allow for this chat” pour chaque outil.

Étape 9 : Après avoir accordé les permissions, le serveur MCP exécutera les outils. Claude recevra alors les données structurées et les présentera dans le chat.

🔥 Génial, vous avez réussi à construire et à intégrer votre premier serveur MCP !
Connexion au curseur
Le processus pour Cursor (un IDE axé sur l’IA) est similaire.
Étape 1 : Ouvrir le curseur.
Étape 2 : Allez sur Settings ⚙️ et naviguez dans la section MCP.

Étape 3 : Cliquez sur “+Ajouter un nouveau serveur MCP global”. Cela ouvrira le fichier de configuration mcp.json. Ajoutez une entrée pour votre serveur, en utilisant à nouveau le chemin absolu vers votre script.
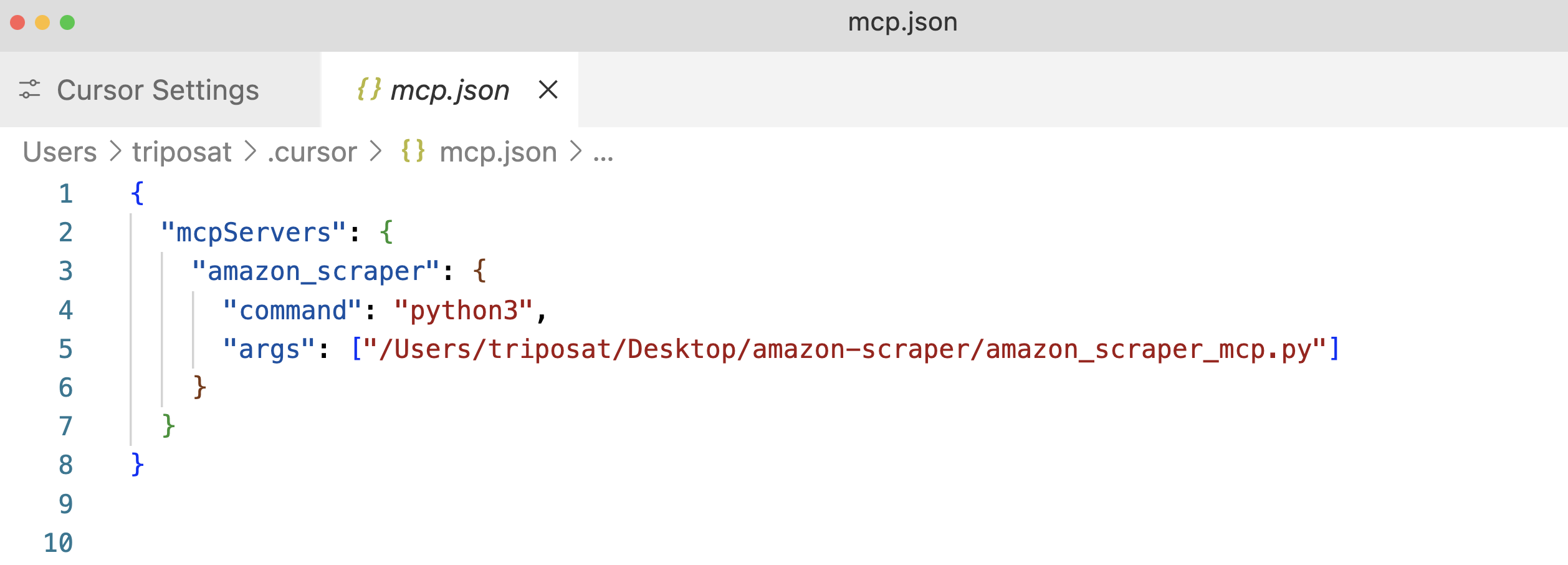
Étape 4 : Sauvegardez le fichier mcp.json et vous devriez voir votre “amazon_product_scraper” listé, avec un point vert indiquant qu’il est en cours d’exécution et connecté.

Étape 5 : Utilisez la fonction de chat de Cursor(Cmd+l ou Ctrl+l).
Étape 6 : Envoyer une invite, par exemple : “Extraire toutes les données disponibles sur les produits à partir de cette URL Amazon : https://www.amazon.com/dp/B09C13PZX7. Formatez la sortie sous la forme d’un objet JSON structuré”.
Étape 7 : Comme pour Claude Desktop, le curseur demandera la permission d’exécuter les outils fetch_page et extract_info. Approuvez ces demandes (“Exécuter l’outil”).
Étape 8 : Le curseur affichera le flux d’interaction, montrant les appels à vos outils MCP et présentant finalement les données JSON structurées renvoyées par votre outil extract_info.

Voici un exemple de sortie JSON du curseur :
{
"title": "Razer Basilisk V3 Customizable Ergonomic Gaming Mouse: Fastest Gaming Mouse Switch - Chroma RGB Lighting - 26K DPI Optical Sensor - 11 Programmable Buttons - HyperScroll Tilt Wheel - Classic Black",
"price": 39.99,
"original_price": 69.99,
"discount_percent": 43,
"rating_stars": 4.6,
"review_count": 7782,
"features": [
"ICONIC ERGONOMIC DESIGN WITH THUMB REST — PC gaming mouse favored by millions worldwide with a form factor that perfectly supports the hand while its buttons are optimally positioned for quick and easy access",
"11 PROGRAMMABLE BUTTONS — Assign macros and secondary functions across 11 programmable buttons to execute essential actions like push-to-talk, ping, and more",
"HYPERSCROLL TILT WHEEL — Speed through content with a scroll wheel that free-spins until its stopped or switch to tactile mode for more precision and satisfying feedback that's ideal for cycling through weapons or skills",
"11 RAZER CHROMA RGB LIGHTING ZONES — Customize each zone from over 16.8 million colors and countless lighting effects, all while it reacts dynamically with over 150 Chroma integrated games",
"OPTICAL MOUSE SWITCHES GEN 2 — With zero unintended misclicks these switches provide crisp, responsive execution at a blistering 0.2ms actuation speed for up to 70 million clicks",
"FOCUS+ 26K DPI OPTICAL SENSOR — Best-in-class mouse sensor with intelligent functions flawlessly tracks movement with zero smoothing, allowing for crisp response and pixel-precise accuracy",
// ... (other features)
],
"availability": "In Stock"
}Cela montre la flexibilité de MCP – le même serveur fonctionne de manière transparente avec différentes applications clientes.
Intégration de MCP de Bright Data pour l’extraction de données Web pilotée par l’IA
Les serveurs MCP personnalisés offrent un contrôle total, mais présentent des difficultés, telles que la gestion de l’infrastructure proxy, la gestion de mécanismes anti-bots sophistiqués et la garantie de l’évolutivité. Bright Data résout ces problèmes grâce à sa solution MCP préconstruite de niveau production, conçue pour une intégration transparente avec les agents d’IA et les LLM.
L’intégration du protocole Model Context Protocol (MCP) à Bright Data offre aux LLM et aux agents d’intelligence artificielle un accès transparent et en temps réel aux données Web publiques, adaptées aux flux de travail d’intelligence artificielle. En se connectant au MCP de Bright Data, vos applications et modèles peuvent récupérer les résultats des SERP de tous les principaux moteurs de recherche et débloquer de manière transparente l’accès aux sites Web difficiles à atteindre.
La solution Model Context Protocol (MCP) de Bright Data connecte votre application à une suite d’outils puissants d’extraction de données Web, notamment Web Unlocker, SERP API, Web Scraper API et Scraping Browser, fournissantune infrastructure complète qui.. :
- Fournit des données prêtes pour l’IA: Récupère et formate automatiquement le contenu web, réduisant ainsi les étapes de prétraitement supplémentaires.
- Garantit l’évolutivité et la fiabilité : S’appuie sur une infrastructure robuste pour gérer des volumes importants de demandes sans compromettre les performances.
- Contourne les blocages et les CAPTCHA : Utilise des stratégies anti-bots avancées pour naviguer et récupérer le contenu des sites Web les plus protégés.
- Offre une couverture IP mondiale : Utilise un vaste réseau de proxy couvrant 195 pays pour accéder aux contenus soumis à des restrictions géographiques.
- Simplifie l’intégration : Minimise les efforts de configuration en fonctionnant de manière transparente avec tous les clients MCP.
Conditions préalables à l’obtention du MCP de Bright Data
Avant de commencer à intégrer Bright Data MCP, assurez-vous que vous disposez des éléments suivants :
- Compte Bright Data : Inscrivez-vous sur brightdata.com. Les nouveaux utilisateurs reçoivent des crédits gratuits pour les tests.
- Jeton API : Obtenez votre clé API à partir des paramètres de votre compte Bright Data(page Paramètres de l’utilisateur).
- Zone Web Unlocker : Créez une zone proxy Web Unlocker dans votre panneau de contrôle Bright Data. Donnez-lui un nom mémorable, comme
mcp_unlocker(vous pourrez le remplacer plus tard par des variables d’environnement si nécessaire). - (Facultatif) Scraping Browser Zone : Si vous avez besoin de capacités avancées d’automatisation du navigateur (par exemple, pour des interactions JavaScript complexes ou des captures d’écran), créez une zone Scraping Browser. Notez les détails d’authentification (nom d’utilisateur et mot de passe) fournis pour cette zone (dans l’onglet Vue d’ensemble ), généralement sous le format
brd-customer-ACCOUNT_ID-zone-ZONE_NAME:PASSWORD.
Démarrage rapide : Configuration de Bright Data MCP pour Claude Desktop
Étape 1 : le serveur MCP de Bright Data est généralement exécuté à l’aide de npx, qui est fourni avec Node.js. Installez Node.js si vous ne l’avez pas encore fait à partir du site officiel.
Étape 2 : Ouvrez Claude Desktop -> Paramètres -> Développeur -> Modifier la configuration(claude_desktop_config.json).
Étape 3 : ajoutez la configuration du serveur Bright Data sous mcpServers. Remplacez les espaces réservés par vos identifiants réels.
{
"mcpServers": {
"Bright Data": { // Choose a name for the server
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "YOUR_BRIGHTDATA_API_TOKEN", // Paste your API token here
"WEB_UNLOCKER_ZONE": "mcp_unlocker", // Your Web Unlocker zone name
// Optional: Add if using Scraping Browser tools
"BROWSER_AUTH": "brd-customer-ACCOUNTID-zone-YOURZONE:PASSWORD"
}
}
}
}Étape 4 : Enregistrez le fichier de configuration et redémarrez Claude Desktop.
Étape 5 : Survolez l’icône du marteau (🔨) sur le bureau de Claude. Vous devriez maintenant voir plusieurs outils MCP.

Essayons d’extraire des données de Zillow, un site connu pour bloquer potentiellement les scrapers. Invitez claude à “Extraire les données des propriétés clés au format JSON à partir de cette URL Zillow : https://www.zillow.com/apartments/arverne-ny/the-tides-at-arverne-by-the-sea/ChWHPZ/”

Permettre à Claude d’utiliser les outils MCP de Bright Data nécessaires. Le serveur MCP de Bright Data s’occupera des complexités sous-jacentes (rotation de proxy, rendu JavaScript via Scraping Browser si nécessaire).
Le serveur de Bright Data effectue l’extraction et renvoie des données structurées, que Claude présente.

Voici un extrait du résultat potentiel :
{
"propertyInfo": {
"name": "The Tides At Arverne By The Sea",
"address": "190 Beach 69th St, Arverne, NY 11692",
"propertyType": "Apartment building",
// ... more info
},
"rentPrices": {
"studio": { "startingPrice": "$2,750", /* ... */ },
"oneBed": { "startingPrice": "$2,900", /* ... */ },
"twoBed": { "startingPrice": "$3,350", /* ... */ }
},
// ... amenities, policies, etc.
}🔥 C’est génial !
Un autre exemple : Les titres de Hacker News
Une requête plus simple :“Donnez-moi les titres des 5 derniers articles de Hacker News“.

Cet exemple montre comment le serveur MCP de Bright Data simplifie l’accès aux contenus web dynamiques ou fortement protégés directement dans votre flux de travail d’IA.
Conclusion
Comme nous l’avons exploré tout au long de ce guide, le Protocole Modèle Contexte d’Anthropic représente un changement fondamental dans la façon dont les systèmes d’intelligence artificielle interagissent avec le monde extérieur. Comme nous l’avons vu, il est possible de créer des serveurs MCP personnalisés pour des tâches spécifiques, comme notre scraper Amazon. L’intégration MCP de Bright Data va encore plus loin en offrant des capacités de scraping web de niveau entreprise qui contournent les protections anti-bots et fournissent des données structurées prêtes pour l’IA.
Nous avons également sélectionné quelques-unes des meilleures ressources sur l’IA et les grands modèles de langage (LLM). Ne manquez pas de les consulter pour en savoir plus :





