
- Scraper basé sur l’API
Utilisez notre interface pour construire votre requête API - Automatisation à grande échelle
Créez votre propre planificateur pour contrôler la fréquence - Livraison
Livrez les données vers le stockage de votre choix ou téléchargez-les



API Web Scraper
Points de terminaison dédiés pour extraire des données Web fraîches et structurées de plus de 120 domaines populaires. Extraction entièrement conforme et éthique.
Aucune carte de crédit requise

1247 scrapers
- Scrape à la demande via API ou scraper sans code
- Responsable de compte dédié
- Gestion de demandes en masse, jusqu'à 5K URLs
- Récupérer les résultats en plusieurs formats
Approuvé par 20,000+ clients dans le monde entier
Collectez des données web en toute simplicité

API de Web Scraper
Utilisez cette API pour commencer à collecter des données avec des paramètres spécifiés

Scraper sans code
Utilisez ce scraper « prêt à l’emploi » pour commencer à collecter des données
- Scraper basé sur le panneau de contrôle
Toute l’interaction se fait dans notre panneau de contrôle - Facile à utiliser
Ajoutez vos entrées au scraper et vous êtes prêt à démarrer - Récupérez les résultats depuis le panneau
Les résultats peuvent être téléchargés directement depuis le panneau de contrôle
Web Scrapers API
API de web scraping disponibles
Éliminez le besoin de développer et de maintenir l'infrastructure. Extrayez simplement des données web en grande quantité et assurez évolutivité et fiabilité grâce aux API de web scraping.
LinkedIn people profiles
ID, Name, City, Country code, Position, About, Posts, Current company, and more.
 117.9K+
117.9K+ 11.1K+
11.1K+Amazon products
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by best sellers category URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by specific category URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by specific keywords
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - find products by using upc numbers
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
LinkedIn company information
ID, Name, Country code, Locations, Followers, Employees in linkedin, About, Specialties, and more.
Instagram - Profiles
Account, Fbid, ID, Followers, Posts count, Is business account, Is professional account, Is verified, and more.
Instagram - Profiles - Collect profile information by user name
Account, Fbid, ID, Followers, Posts count, Is business account, Is professional account, Is verified, and more.
Crunchbase companies information
Name, URL, ID, Cb rank, Region, About, Industries, Operating status, and more.
Crunchbase companies information - Searching data by keyword
Name, URL, ID, Cb rank, Region, About, Industries, Operating status, and more.
Linkedin job listings information
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Linkedin job listings information - Discover new jobs by keyword
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Linkedin job listings information - Discover jobs by company URL
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Instagram - Posts
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Photos, and more.
Instagram - Posts - Collects posts from a specific URLs by using profile URL
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Photos, and more.
Google Maps full information
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - discover records by location search
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - Collect Google Maps Businesses data by place id
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - Discover new records by Customer ID
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Zillow properties listing information
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
Zillow properties listing information - Discover by custom filters - location, home type and status
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
Zillow properties listing information - Search by parameters on zillow and use the direct link as input
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
LinkedIn posts
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover user's articles by URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover posts by Profile URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover new posts company URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
X (formerly Twitter) - Posts
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
X (formerly Twitter) - Posts - Collecting Twitter posts URLs
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
X (formerly Twitter) - Posts - Getting x posts by array of profiles
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
TikTok - Profiles
Account id, Nickname, Biography, Awg engagement rate, Comment engagement rate, Like engagement rate, Bio link, Predicted lang, and more.
TikTok - Profiles - Discover by search URL and country
Account id, Nickname, Biography, Awg engagement rate, Comment engagement rate, Like engagement rate, Bio link, Predicted lang, and more.
Youtube - Videos posts
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Search new youtube videos by keyword
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discover videos by channel URL
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Search videos by keyword and then apply relevant video filters
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Collect YouTube posts by hashtags
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discovery records by Explore page URL
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discovery videos by podcast url
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Amazon Reviews
URL, Product name, Product rating, Product rating object, Product rating max, Rating, Author name, Asin, and more.
TikTok - Posts
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - Input specific profile URL to get posts published by it
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - Search posts by specific keyword or hashtag
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - discover new records by TikTok discover URL
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
Facebook - Pages Posts by Profile URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Indeed job listings information
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Indeed job listings information - Collect new jobs by keyword search in specific location
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Indeed job listings information - Discover jobs by company URL
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Walmart - products
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Find new products by using specific category URL
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Collects products by specific keywords
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Discover products by using sku numbers
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
TikTok Shop
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - category
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - Collect TikTok shop products by keywords search
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - discover records by shop url
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
YouTube - Channels
URL, Handle, Handle md5, Banner img, Profile image, Name, Subscribers, Description, and more.
YouTube - Channels - Collects channel by keyword related to the channel or video's of the channel
URL, Handle, Handle md5, Banner img, Profile image, Name, Subscribers, Description, and more.
Reddit- Posts
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discover Reddit posts by Subreddit URL
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discovery by keyword of Reddit posts
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discover posts by author
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Glassdoor companies overview information
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - Search for companies by keyword
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - discover new companies by input filters
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - discover by search url
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Google maps reviews
URL, Place id, Place name, Country, Address, Review id, Reviewer name, Reviews by reviewer, and more.
Instagram - Reels
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Instagram - Reels - Discover reels video from Instagram profile or direct search url
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Instagram - Reels - Collect all Reels from Instagram profiles (without the post timestamp)
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Airbnb Properties Information
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
Airbnb Properties Information - Search Airbnb by location
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
Airbnb Properties Information - Discover by search url
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
X (formerly Twitter) - Profiles
X id, URL, ID, Profile name, Biography, Is verified, Profile image link, External link, and more.
X (formerly Twitter) - Profiles - Collect profile information by user name
X id, URL, ID, Profile name, Biography, Is verified, Profile image link, External link, and more.
Glassdoor companies reviews
Overview id, Review id, Review url, Rating date, Count helpful, Count unhelpful, Employee job end year, Employee length, and more.
Booking Hotel Listings
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Booking Hotel Listings -
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Yahoo Finance business information
Name, Company id, Entity type, Summary, Stock ticker, Currency, Earnings date, Exchange, and more.
Yahoo Finance business information - Discover records by keyword
Name, Company id, Entity type, Summary, Stock ticker, Currency, Earnings date, Exchange, and more.
Instagram - Comments
URL, Comment user, Comment user url, Comment date, Comment, Likes number, Replies number, Replies, and more.
Tarification de l'API Scraper Web
Ne payez que pour ce qui est livré avec succès. Pas de frais cachés, pas de frais pour les livraisons échouées.
Obtenez 25% de réduction sur l'API Scraper pendant 3 mois. Utilisez le code APIS25 lors du paiement.
Nous acceptons ces méthodes de paiement:
Chaque plan vous donne un accès complet - payez moins par enregistrement à mesure que vous augmentez
Collecte de données
- Gestion automatisée des proxies
- Rendu complet du navigateur
- Résolution CAPTCHA
Performance à grande échelle
- Concurrence illimitée
- Collecte par lots et planifiée
- APIs de gestion des tâches
Livraison de données
- Validation et découverte de données
- Analyse de données (JSON ou CSV)
- Livraison via webhook ou API
Démo de l'API Web Scraper
EXEMPLES DE CODE
Points de terminaison dédiés pour plus de 100 domaines.
Entrée
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.linkedin.com/in/elad-moshe-05a90413/"},{"url":"https://www.linkedin.com/in/jonathan-myrvik-3baa01109"},{"url":"https://www.linkedin.com/in/aviv-tal-75b81/"},{"url":"https://www.linkedin.com/in/bulentakar/"},{"url":"https://www.linkedin.com/in/nnikolaev/"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_l1viktl72bvl7bjuj0&format=json&uncompressed_webhook=true"
Sortie
JSON
[
{
"db_source": "1784202467790",
"timestamp": "2026-07-16",
"id": "ane***-ka***m-8*********",
"name": "aneesa k****m",
"city": "South Africa",
"country_code": "ZA",
"position": "--",
"about": null
},
{
"db_source": "1784202467790",
"timestamp": "2026-07-16",
"id": "lil***ia-***b0a******",
"name": "Lili ***",
"city": "Algeria",
"country_code": "DZ",
"position": "Aide chez Citi",
"about": null
},
{
"db_source": "1784202467790",
"timestamp": "2026-07-16",
"id": "ber***is-***y-8*********",
"name": "berkhais m**y",
"city": "Nabeul, Tunisia",
"country_code": "TN",
"position": "--",
"about": null
},
{
"db_source": "1784202467790",
"timestamp": "2026-07-16",
"id": "san***p-k***r-y*********eep******************",
"name": "sandeep k***r y***v s*****p k***r",
"city": "Kakori, Uttar Pradesh, India",
"country_code": "IN",
"position": "--",
"about": null
},
{
"db_source": "1784202467790",
"timestamp": "2026-07-16",
"id": "mar***n-s***iag*********69",
"name": "Maryann S******o",
"city": "Philippines",
"country_code": "PH",
"position": "Supervisor Assistant at SMK Electronics",
"about": null
}
]
Entrée
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.amazon.com/Quencher-FlowState-Stainless-Insulated-Smoothie/dp/B0CRMZHDG8","asin":"B0CRMZHDG8","origin_url":"https://www.amazon.com/Quencher-FlowState-Stainless-Insulated-Smoothie/dp/B0CRMZHDG8","zipcode":"94107","language":""},{"url":"https://www.amazon.com/KitchenAid-Protective-Dishwasher-Stainless-8-72-Inch/dp/B07PZF3QS3","asin":"B07PZF3QS3","zipcode":"","language":""},{"url":"https://www.amazon.com/TruSkin-Naturals-Vitamin-Topical-Hyaluronic/dp/B01M4MCUAF","asin":"","origin_url":"https://www.amazon.com/TruSkin-Naturals-Vitamin-Topical-Hyaluronic/dp/B01M4MCUAF","zipcode":"94124","language":""}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_l7q7dkf244hwjntr0&format=json&uncompressed_webhook=true"
Sortie
JSON
[
{
"db_source": "1784208906131",
"timestamp": "2026-07-16",
"title": "Retro Wildwood New Jersey Waves Sun Ocean Beach NJ Vacation T-Shirt",
"seller_name": "Ama***.co***",
"brand": "Wildwood NJ Design Co",
"description": "Retro Wildwood New Jersey Waves Sun Ocean Beach NJ Vacation Design. Buy This For Yourself Or Someone Who Loves To Vacati...",
"initial_price": 19.99,
"currency": "USD"
},
{
"db_source": "1784208906131",
"timestamp": "2026-07-16",
"title": "SP Hydrate Shampoo 500ml",
"seller_name": "Glo***Hai***",
"brand": "Wella Professionals",
"description": "Produktbeschreibung SP Hydrate Shampoo 500ml Gebrauchsanweisung Das Shampoo auf nasses Haar auftragen, sanft einmassiere...",
"initial_price": 14.88,
"currency": "EUR"
},
{
"db_source": "1784208906131",
"timestamp": "2026-07-16",
"title": "Jewelry Making for Beginners: A Step-by-Step Guide to Wirework, Stone Setting, Chainmaille, Clasps, Mixed Media, Finishi...",
"seller_name": null,
"brand": "Annika Blake",
"description": "Jewelry Making for BeginnersTurn simple materials into beautiful, wearable creations with confidence.Jewelry Making for ...",
"initial_price": 4.99,
"currency": "USD"
},
{
"db_source": "1784208906131",
"timestamp": "2026-07-16",
"title": "Sound Dampening Foam Panels, 6 Pack 48\u0022 x 24\u0022 x 2\u0022 High Density Egg Crate Foam, Acoustic Sound Proofing Wall Panels for ...",
"seller_name": "Xinyang J****i T*****g C**, L**.",
"brand": "Evovoce",
"description": "About this item Noise Reduction Panels:Evovoce egg crate foam panels help reduce echo, reverberation, and reflected soun...",
"initial_price": 79.99,
"currency": "USD"
},
{
"db_source": "1784208906131",
"timestamp": "2026-07-16",
"title": "51mm Coffee Distributor, Tamper Leveler Espresso Tamper,Coffee Distribution Tool Adjustable Height,Espresso Accessories ...",
"seller_name": "FAN***SI",
"brand": "Fixiooz",
"description": "51mm Coffee Distributor",
"initial_price": 16.99,
"currency": "USD"
}
]
Entrée
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.zillow.com/homedetails/2506-Gordon-Cir-South-Bend-IN-46635/77050198_zpid/?t=for_sale"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lfqkr8wm13ixtbd8f5&format=json&uncompressed_webhook=true"
Sortie
JSON
[
{
"db_source": "1784192189126",
"timestamp": "2026-07-16",
"zpid": 120742808,
"city": "Charleston",
"state": "SC",
"homeStatus": "RECENTLY_SOLD",
"address:city": "Charleston",
"address:streetAddress": "1119 Oak Overhang St"
},
{
"db_source": "1784192189126",
"timestamp": "2026-07-16",
"zpid": 447697956,
"city": "Johns Island",
"state": "SC",
"homeStatus": "SOLD",
"address:city": "Johns Island",
"address:streetAddress": "4091 Briars Creek Ln"
},
{
"db_source": "1784192189126",
"timestamp": "2026-07-16",
"zpid": 10861113,
"city": "Johns Island",
"state": "SC",
"homeStatus": "OTHER",
"address:city": "Johns Island",
"address:streetAddress": "4966 Green Dolphin Way"
},
{
"db_source": "1784192189126",
"timestamp": "2026-07-16",
"zpid": 110231160,
"city": "Johns Island",
"state": "SC",
"homeStatus": "SOLD",
"address:city": "Johns Island",
"address:streetAddress": "55 Cotton Hall"
},
{
"db_source": "1784192189126",
"timestamp": "2026-07-16",
"zpid": 10857946,
"city": "Johns Island",
"state": "SC",
"homeStatus": "SOLD",
"address:city": "Johns Island",
"address:streetAddress": "1374 Dunlin Ct"
}
]
Entrée
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.instagram.com/p/Cuf4s0MNqNr"},{"url":"https://www.instagram.com/p/DP861NijuwE"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lk5ns7kz21pck8jpis&format=json&uncompressed_webhook=true"
Sortie
JSON
[
{
"db_source": "1784143874161",
"timestamp": "2026-07-15",
"url": "https:\/\/www.instagram.com\/p\/DREdllLDePe",
"user_posted": "paulziemiak",
"description": "Viva Polonia an Rhein und Ruhr! \n 🇩🇪 🇵🇱 \n\nWusstet ihr, dass Millionen Menschen in Nordrhein-Westfalen polnische Vorf...",
"hashtags": [
"#NRW."
],
"num_comments": 11,
"date_posted": "2025-11-15T08:03:54.000Z"
},
{
"db_source": "1784143874161",
"timestamp": "2026-07-15",
"url": "https:\/\/www.instagram.com\/p\/DJeauFvT6GZ",
"user_posted": "theindianidiot",
"description": "🙏🏾",
"hashtags": null,
"num_comments": 350,
"date_posted": "2025-05-10T13:47:56.000Z"
},
{
"db_source": "1784143874161",
"timestamp": "2026-07-15",
"url": "https:\/\/www.instagram.com\/reel\/DQwBJGXCEbg",
"user_posted": "gretchenrole",
"description": "+32 🎂 \n#harrypotter #harrypottercake",
"hashtags": [
"#harrypotter",
"#harrypottercake"
],
"num_comments": 123,
"date_posted": "2025-11-07T08:49:40.000Z"
},
{
"db_source": "1784143874161",
"timestamp": "2026-07-15",
"url": "https:\/\/www.instagram.com\/reel\/DQpbapXjtak",
"user_posted": "bb.realestates",
"description": "Wie läuft die Vermarktung in Zusammenarbeit mit Berenfänger \u0026 Bechtold ab?👨🏻💻\n\n#bbrealestate #berenfaengerbechtold #...",
"hashtags": [
"#bbrealestate",
"#berenfaengerbechtold",
"#immobilien",
"#architecture",
"#realestate",
"#luxuryhomes",
"#interior",
"#immobilienmakler"
],
"num_comments": 0,
"date_posted": "2025-11-04T20:06:25.000Z"
},
{
"db_source": "1784143874161",
"timestamp": "2026-07-15",
"url": "https:\/\/www.instagram.com\/p\/DQN2K_UgRU0",
"user_posted": "eluniversalmx",
"description": "Con una sonrisa en el rostro y saludando al público, Pato entró con un saco de color negro con distintos diseños que rea...",
"hashtags": null,
"num_comments": 0,
"date_posted": "2025-10-25T03:00:30.000Z"
}
]
LE MEILLEUR DX DE SA CATÉGORIE
Facile à démarrer. Plus facile à mettre à l’échelle.
Stabilité inégalée
Garantissez des performances constantes et minimisez les défaillances en vous appuyant sur la première infrastructure de proxy au monde.
Web Scraping simplifié
Mettez votre scraping en pilote automatique en utilisant des API prêtes à la production, ce qui permet d’économiser des ressources et de réduire la maintenance.
Évolutivité illimitée
Adaptez sans effort vos projets de scraping pour répondre aux demandes de données, tout en maintenant des performances optimales.
DÉPLOYEZ PLUS RAPIDEMENT
Un API call. Des tonnes de données.
Découverte des données
Détecter les structures et les modèles de données afin de garantir une extraction efficace et ciblée des données.
Gestion des demandes en bulk
Réduisez la charge du serveur et optimisez la collecte de données pour les tâches de scraping à haut volume.
Analyse des données
Convertit efficacement le HTML brut en données structurées, facilitant ainsi l’intégration et l’analyse des données.
Validation des données
Garantissez la fiabilité des données et gagnez du temps lors des contrôles manuels et du prétraitement.
SOUS LE CAPOT
Ne vous souciez plus jamais des proxies et des CAPTCHA
- Rotation automatique des IP
- Résolution de CAPTCHA
- Rotation des agents utilisateur
- En-têtes personnalisés
- Rendu JavaScript
- Proxys résidentiels
API pour un accès fluide aux données Web
Extraction de données web complète, évolutive et conforme
API pour un accès fluide aux données Web
Extraction de données web complète, évolutive et conforme
Adapté à votre flux de travail
Obtenez des données structurées en fichiers JSON, NDJSON ou CSV via Webhook ou livraison par API.
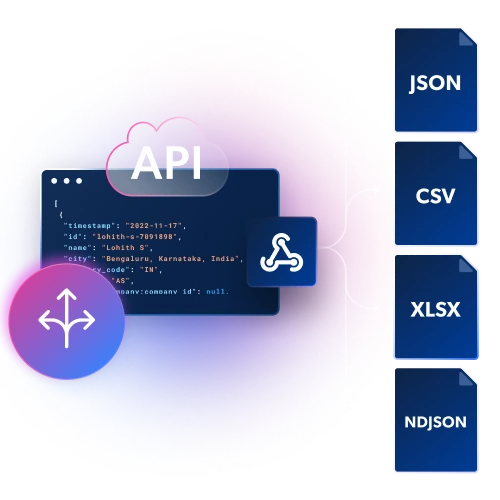
Infrastructure intégrée et déblocage
Bénéficiez d’un contrôle et d’une flexibilité maximaux sans maintenir de Proxy ni d’infrastructure de déblocage. Scrapez facilement des données depuis n’importe quelle géolocalisation en évitant les CAPTCHAs et les blocages.

Infrastructure éprouvée
La plateforme de Bright Data alimente plus de 20 000 entreprises dans le monde, offrant une tranquillité d’esprit avec 99,99 % de disponibilité et l’accès à plus de 150 M d’IPs d’utilisateurs réels couvrant 195 pays.

Conformité de premier plan dans le secteur
Nos pratiques de confidentialité respectent les lois sur la protection des données, notamment le cadre réglementaire européen de protection des données, le RGPD et le CCPA.

API pour un accès fluide aux données Web
Extraction de données web complète, évolutive et conforme
FLEXIBLE
Adapté à votre flux de travail
Obtenez des données structurées en fichiers JSON, NDJSON ou CSV via Webhook ou livraison par API.SCALABLE
Infrastructure intégrée et déblocage
Bénéficiez d'un contrôle et d'une flexibilité maximaux sans maintenir de Proxy ni d'infrastructure de déblocage. Scrapez facilement des données depuis n'importe quelle géolocalisation en évitant les CAPTCHAs et les blocages.STABLE
Infrastructure éprouvée
La plateforme de Bright Data alimente plus de 20 000 entreprises dans le monde, offrant une tranquillité d'esprit avec 99,99 % de disponibilité et l'accès à plus de 150 M d'IPs d'utilisateurs réels couvrant 195 pays.COMPLIANT
Conformité de premier plan dans le secteur
Nos pratiques de confidentialité respectent les lois sur la protection des données, notamment le cadre réglementaire européen de protection des données, le RGPD et le CCPA.
FAQ sur l'API Web Scraper
Qu'est-ce que les API Scrapers ?
Les API Scrapers sont un service basé sur le cloud qui simplifie l'extraction de données web, offrant une gestion automatisée de la rotation IP, la résolution des CAPTCHA et l'analyse des données dans des formats structurés. Il permet une collecte de données efficace et évolutive, adaptée aux entreprises qui ont besoin d'accéder facilement à de précieuses données web.
Qui peut bénéficier de l'utilisation des API Scrapers ?
Les analystes de données, les scientifiques, les ingénieurs et les développeurs à la recherche de méthodes efficaces pour collecter et analyser les données web pour l'IA, la ML, les applications big data, et plus encore, trouveront les API Scrapers particulièrement bénéfiques.
Pourquoi choisir les API Scrapers plutôt que les méthodes de scraping manuelles ?
Les API Scrapers permettent de surmonter les limites du scraping web manuel, telles que la gestion des changements de structure des sites web, la rencontre de blocs et de captchas, et les coûts élevés associés à la maintenance de l'infrastructure. Il offre une solution automatisée, évolutive et fiable pour l'extraction des données, réduisant de manière significative les coûts et les délais opérationnels.
Qu'est-ce qui rend les API Scrapers de Bright Data uniques sur le marché ?
Le caractère unique des API Scrapers réside dans leurs caractéristiques spécialisées telles que la gestion des demandes en masse, la découverte de données et la validation automatisée, soutenues par des technologies avancées telles que les proxys résidentiels et le rendu JavaScript. Ces capacités garantissent un accès étendu, préservent l'intégrité des données et améliorent l'efficacité globale, ce qui distingue les API Scrapers dans le paysage concurrentiel.
Comment puis-je commencer à utiliser les API Scrapers ?
La mise en route des API Scrapers est simple grâce au panneau de contrôle de Bright Data, qui fournit une documentation complète et un tableau de bord convivial pour la gestion et les paramètres des clés API. Cette approche minimise les besoins d'installation et permet un accès immédiat à une plateforme hautement évolutive et fiable pour les besoins d'extraction de données web.
Pour quels cas d'utilisation spécifiques les API Scrapers sont-elles optimisées ?
Les API Scrapers prennent en charge une série de besoins de développement, notamment l'analyse comparative de la concurrence, l'analyse des tendances du marché, les algorithmes de tarification dynamique, l'extraction de sentiments et l'alimentation des données dans les pipelines d'apprentissage automatique. Essentielles pour le commerce électronique, la fintech et l'analyse des médias sociaux, ces API permettent aux développeurs de mettre en œuvre efficacement des stratégies basées sur les données.
Comment les API Scrapers gèrent-elles les tâches d'extraction de données à grande échelle ?
Dotées de fonctionnalités de simultanéité élevée et de traitement par lots, les API Scraper excellent dans les scénarios d'extraction de données à grande échelle. Les développeurs peuvent ainsi faire évoluer leurs opérations de scraping de manière efficace, en prenant en charge des volumes massifs de requêtes avec un débit élevé.
Dans quels formats de données les API Scraper peuvent-elles fournir des informations extraites ?
Les API Scrapers fournissent des données extraites dans des formats polyvalents, notamment NDJSON et CSV, garantissant une intégration fluide avec un large éventail d'outils d'analyse et de flux de travail de traitement des données, facilitant ainsi leur adoption dans les environnements de développement.