

Lorsque vous effectuez du scraping web, vous rencontrez souvent des paginations, où le contenu est réparti sur plusieurs pages. La gestion de ces paginations peut s’avérer difficile, car différents sites Web utilisent différentes techniques de pagination.
Dans cet article, je vais vous expliquer les techniques de pagination courantes et vous montrer comment les gérer à l’aide d’un exemple de code pratique.
Qu’est-ce que la pagination ?
Les sites web tels que les plateformes de commerce électronique, les sites d’offres d’emploi et les réseaux sociaux utilisent la pagination pour gérer de grandes quantités de données. Afficher tout le contenu sur une seule page augmenterait considérablement le temps de chargement et consommerait trop de mémoire. La pagination répartit le contenu sur plusieurs pages et offre des options de navigation telles que « Suivant », les numéros de page ou le chargement automatique lorsque vous faites défiler la page. Cela rend la navigation plus rapide et plus organisée.
Types de pagination
La complexité de la pagination peut varier, allant de la simple pagination numérotée à des techniques plus avancées telles que le défilement infini ou le chargement dynamique de contenu. D’après mon expérience, j’ai rencontré trois principaux types de pagination, qui sont selon moi les plus couramment utilisés sur les sites web :
- Pagination numérotée: les utilisateurs naviguent entre des pages distinctes à l’aide de liens numérotés.
- Pagination par clic: les utilisateurs cliquent sur un bouton (par exemple, « Charger plus ») pour charger du contenu supplémentaire.
- Défilement infini: le contenu se charge automatiquement lorsque les utilisateurs font défiler la page vers le bas.
Examinons chacun de ces types plus en détail !
Pagination numérotée
Il s’agit de la technique de pagination la plus courante, souvent appelée « pagination suivante et précédente », « pagination par flèches » ou « pagination basée sur l’URL ». Malgré les différents noms, le principe de base est le même : les pages sont reliées à l’aide de liens numérotés. Vous pouvez naviguer en modifiant le numéro de page dans l’URL. Pour savoir quand arrêter la pagination, vous pouvez vérifier si le bouton « Suivant » est désactivé ou si aucune nouvelle donnée n’est disponible.
Cela ressemble généralement à ceci :

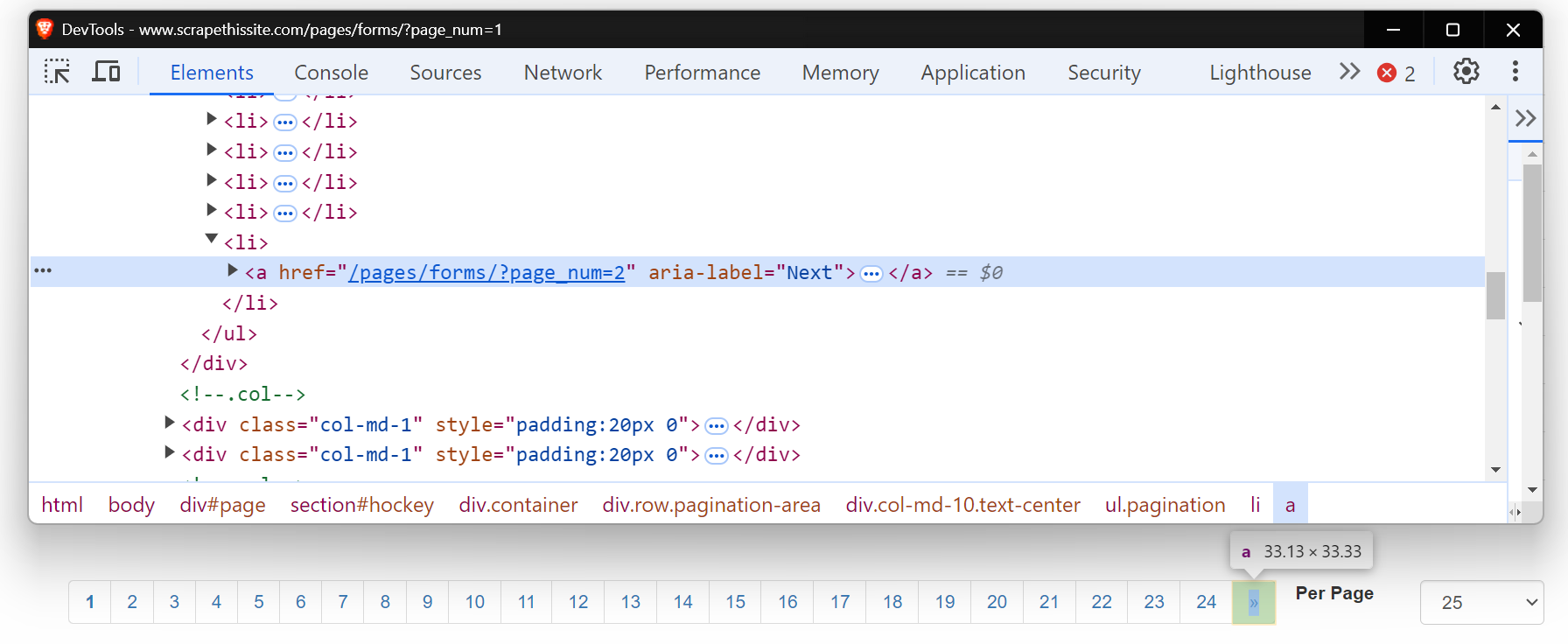
Prenons un exemple ! Nous allons naviguer à travers toutes les pages du site web Scrapethesite. La barre de pagination de ce site comporte un total de 24 pages.

Vous remarquerez que lorsque vous cliquez sur le bouton « >> », l’URL change comme suit :
- 1ère page: https://www.scrapethissite.com/pages/forms/
- 2e page: https://www.scrapethissite.com/pages/forms/?page_num=2
- 3e page: https://www.scrapethissite.com/pages/forms/?page_num=3
Maintenant, examinez le code HTML de ce bouton « Suivant ». Il s’agit d’une balise d’ancrage (<a>) avec un attribut href qui renvoie à la page suivante. L’attribut aria-label indique que le bouton « Suivant » est toujours actif.
Lorsqu’il n’y a plus de pages, l’attribut aria-label disparaît, indiquant la fin de la pagination.
Commençons par écrire un Scraper web basique pour naviguer à travers ces pages. Tout d’abord, configurez votre environnement en installant les paquets requis. Pour un guide détaillé sur le Scraping web avec Python, vous pouvez consulter l’article de blog approfondi ici.
pip install requests beautifulsoup4 lxmlVoici le code permettant de paginer chaque page :
import requests
from bs4 import BeautifulSoup
base_url = "https://www.scrapethissite.com/pages/forms/?page_num="
# Commencer par la page 1
page_num = 1
while True:
url = f"{base_url}{page_num}"
response = requests.get(url)
soup = BeautifulSoup(response.content, "lxml")
print(f"Actuellement à la page : {page_num}")
# Vérifier si le bouton « Suivant » existe
next_button = soup.find("a", {"aria-label": "Next"})
if next_button:
# Passer à la page suivante
page_num += 1
else:
# Plus de pages, quitter la boucle
print("Dernière page atteinte.")
breakCe code parcourt les pages en vérifiant si le bouton « Suivant » (avec aria-label="Suivant") existe. Si le bouton est présent, il incrémente le page_num et effectue une nouvelle requête avec l’URL mise à jour. La boucle se poursuit jusqu’à ce que le bouton « Suivant » ne soit plus trouvé, indiquant la dernière page.
Exécutez le code et vous verrez que nous avons parcouru toutes les pages avec succès.

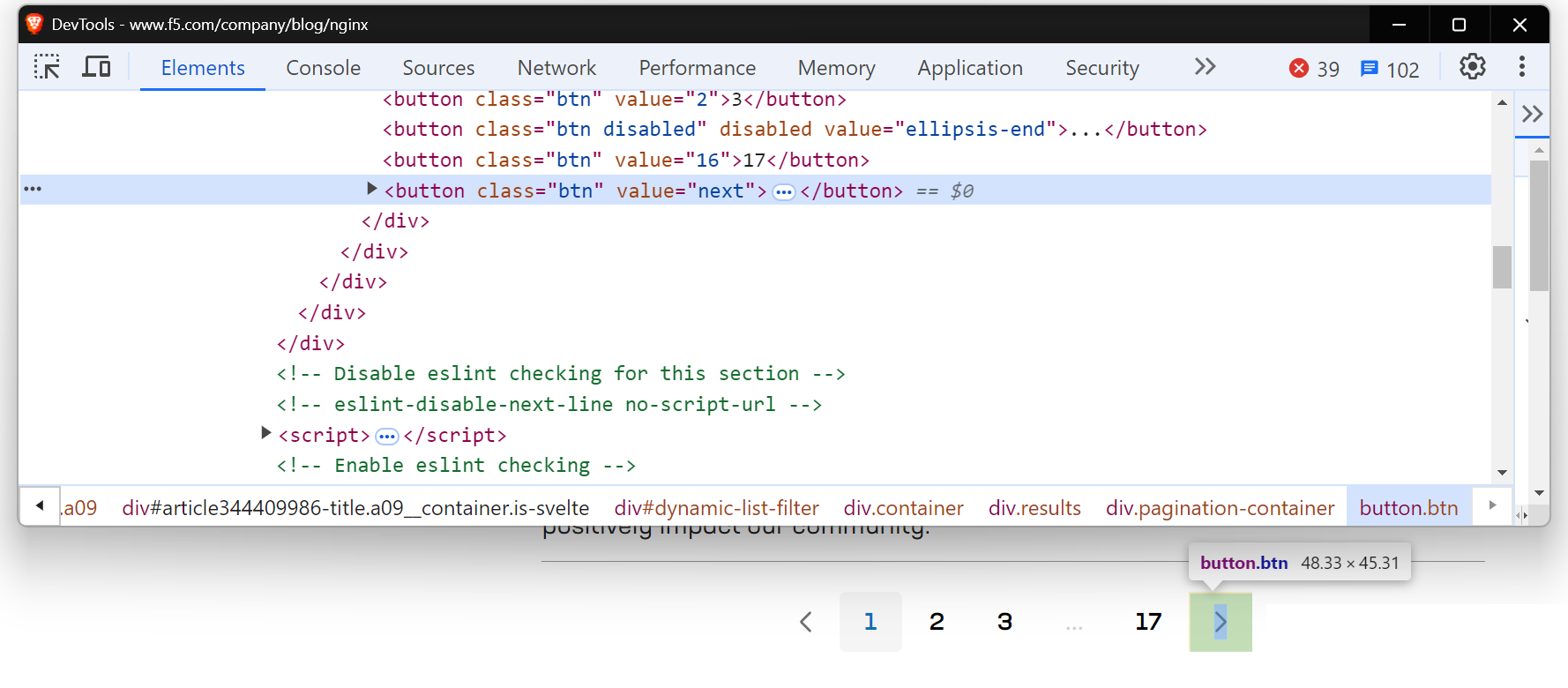
Certains sites web ont un bouton « Suivant » qui ne modifie pas l’URL mais charge tout de même du nouveau contenu sur la même page. Dans ce cas, les méthodes traditionnelles de Scraping web peuvent ne pas fonctionner correctement. Des outils tels que Selenium ou Playwright sont plus adaptés, car ils peuvent interagir avec la page et simuler des actions telles que cliquer sur des boutons pour récupérer le contenu chargé dynamiquement. Pour en savoir plus sur l’utilisation de Selenium pour ce type de tâches, vous pouvez consulter un guide détaillé ici.
Vous rencontrerez une situation similaire lorsque vous essaierez de scraper la page du blog NGINX.
Utilisons Playwright pour traiter le contenu chargé dynamiquement. Si vous découvrez Playwright, consultez ce guide de démarrage utile.
Avant d’écrire le code, exécutez la commande suivante pour configurer Playwright sur votre machine :
pip install playwright
playwright installVoici le code :
import asyncio
from playwright.async_api import async_playwright
# Définir une fonction asynchrone
async def scrape_nginx_blog():
async with async_playwright() as p:
# Lancer une instance du navigateur Chromium en mode headless
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Accéder à la page du blog NGINX
await page.goto("https://www.f5.com/company/blog/nginx")
page_num = 1
while True:
print(f"Actuellement sur la page {page_num}")
# Localiser le bouton « Suivant » à l'aide d'un localisateur de bouton avec la valeur « next »
next_button = page.locator('button[value="next"]')
# Vérifier si le bouton « Suivant » est activé
if await next_button.is_enabled():
await next_button.click() # Cliquer sur le bouton « Suivant » pour passer à la page suivante
await page.wait_for_timeout(
2000
) # Attendre 2 secondes pour permettre le chargement du nouveau contenu
page_num += 1
else:
print("Plus de pages. Le scraping est terminé.")
break # Quittez la boucle s'il n'y a plus de pages disponibles
await browser.close() # Fermez le navigateur
# Exécutez la fonction de scraping asynchrone
asyncio.run(scrape_nginx_blog())Le code utilise Playwright asynchrone pour naviguer à travers toutes les pages. Il entre dans une boucle qui vérifie le bouton « Suivant ». Si le bouton est activé, il clique pour passer à la page suivante et attend que le contenu se charge. Ce processus se répète jusqu’à ce qu’il n’y ait plus de pages disponibles. Enfin, le navigateur est fermé une fois le scraping terminé.
Exécutez le code et vous verrez que nous avons réussi à parcourir toutes les pages.
Pagination par clic
Sur de nombreux sites web, vous avez probablement déjà vu des boutons tels que « Charger plus », « Afficher plus » ou « Voir plus ». Il s’agit d’exemples de pagination par clic, couramment utilisée sur les sites modernes. Ces boutons chargent dynamiquement le contenu via JavaScript. Le principal défi ici est de simuler l’interaction de l’utilisateur, c’est-à-dire d’automatiser le processus de clic sur le bouton pour charger plus de contenu.
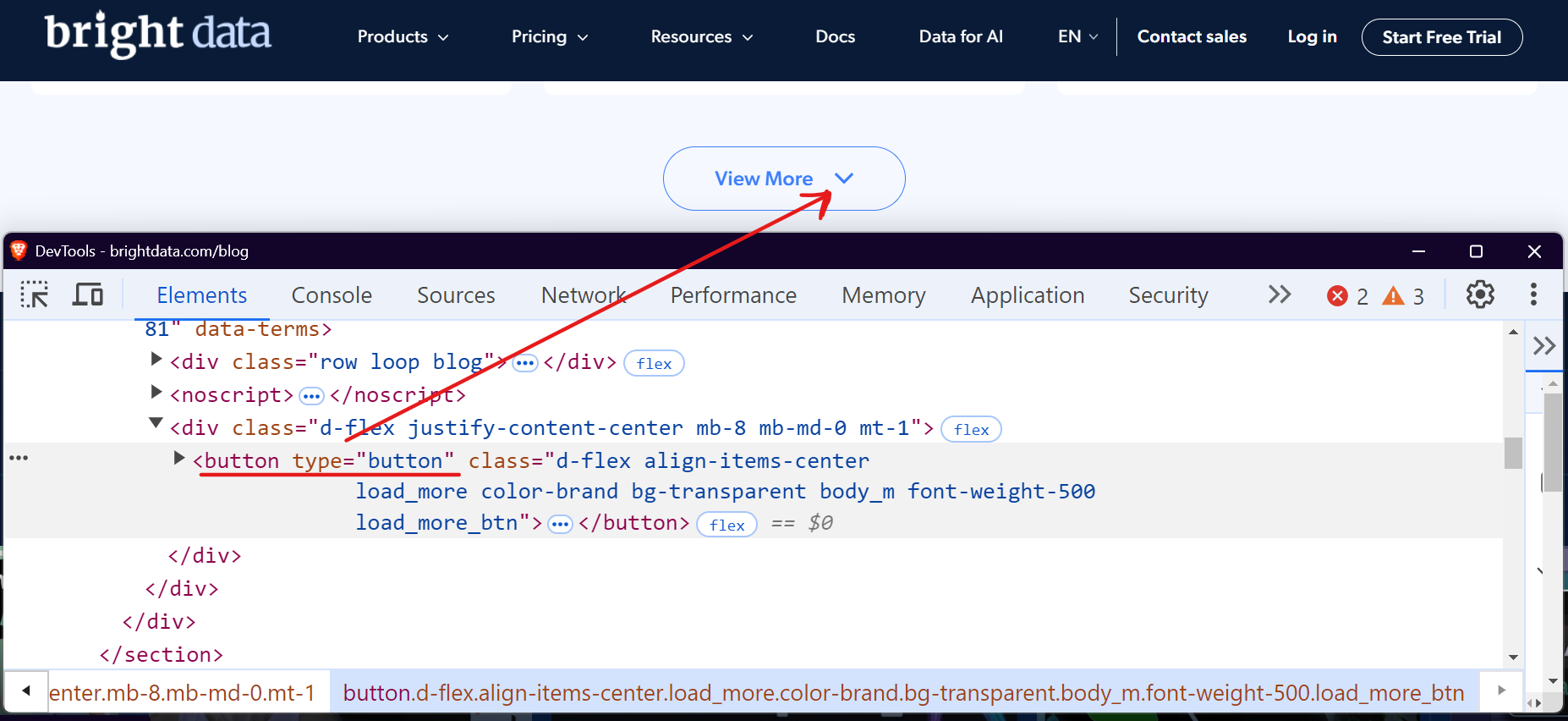
Prenons l’exemple de la section blog de Bright Data. Lorsque vous visitez cette page et que vous faites défiler vers le bas, vous remarquerez un bouton « Voir plus » qui charge les articles de blog lorsque vous cliquez dessus.
Vous pouvez utiliser des outils tels que Selenium ou Playwright pour automatiser ce processus en cliquant de manière répétée sur le bouton « Charger plus » jusqu’à ce qu’il n’y ait plus de contenu disponible. Voyons comment nous pouvons facilement gérer cela avec Playwright.
import asyncio
from playwright.async_api import async_playwright
async def scrape_brightdata_blog():
async with async_playwright() as p:
# Lancer un navigateur sans interface graphique
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Accéder au blog Bright Data
await page.goto("https://brightdata.com/blog")
page_num = 1
while True:
print(f"Actuellement sur la page {page_num}")
# Localiser le bouton « Voir plus »
view_more_button = page.locator("button.load_more_btn")
# Vérifier si le bouton est visible et activé
if (
await view_more_button.count() > 0
and await view_more_button.is_visible()
):
await view_more_button.click()
await page.wait_for_timeout(2000)
page_num += 1
else:
print("Plus aucune page à charger. Récupération terminée.")
break
# Fermer le navigateur
await browser.close()
# Exécuter la fonction de récupération
asyncio.run(scrape_brightdata_blog())Le code localise le bouton « Voir plus » à l’aide du sélecteur CSS button.load_more_btn. Il vérifie ensuite si le bouton existe et est visible à l’aide de count() > 0 et is_visible(). Si le bouton est visible, il interagit avec lui à l’aide de la méthode click() et attend 2 secondes pour permettre le chargement du nouveau contenu. Ce processus se répète en boucle jusqu’à ce que le bouton ne soit plus visible.
Exécutez le code et vous verrez que nous avons réussi à parcourir toutes les pages.

Nous avons réussi à extraire les 52 pages de la section blog de Bright Data. Cela montre que le site compte au total 52 pages, ce que nous n’avons découvert qu’après le processus d’extraction. Cependant, il est possible de connaître le nombre total de pages avant l’extraction.
Pour ce faire, ouvrez les outils de développement, accédez à l’onglet « Réseau » et filtrez les requêtes en sélectionnant « Fetch/XHR ». Cliquez ensuite à nouveau sur le bouton « Afficher plus » et vous remarquerez qu’une requête AJAX est déclenchée.
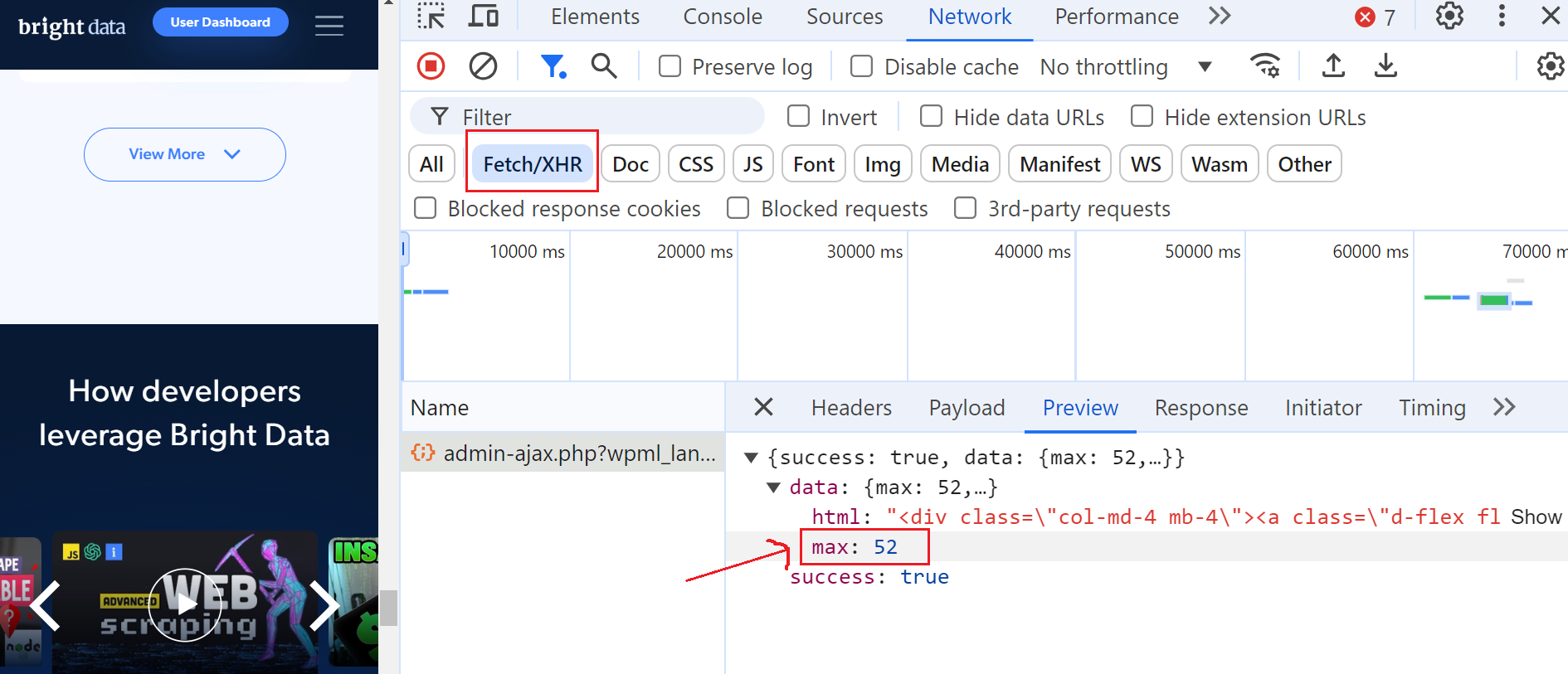
Cliquez sur cette requête et accédez à la section « Aperçu », où vous verrez que le nombre maximum de pages est de 52. Ensuite, rendez-vous dans la section « Charge utile » et vous constaterez qu’il y a 6 articles de blog par page et que nous sommes actuellement à la page 3.
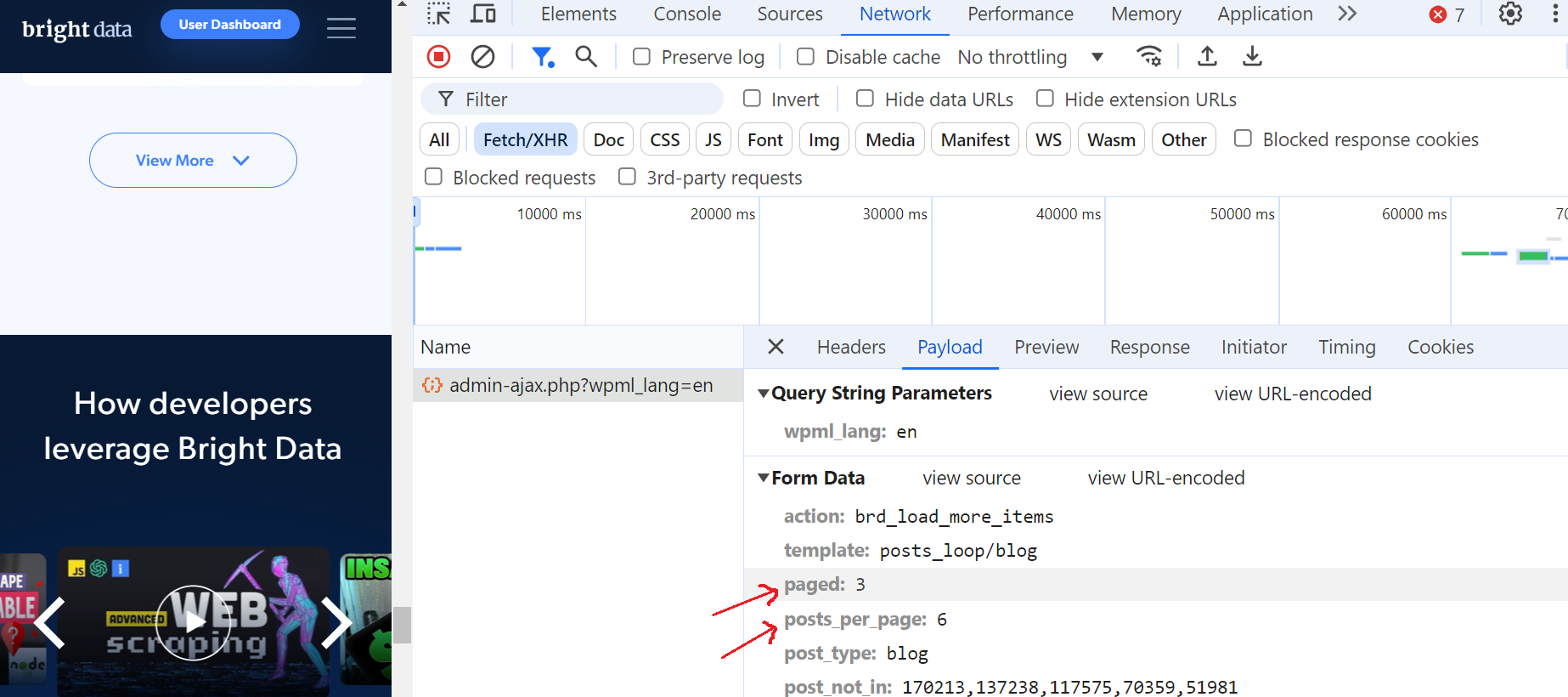
C’est fantastique !
Pagination à défilement infini
Au lieu des boutons « précédent/suivant », de nombreux sites web utilisent désormais le défilement infini, qui améliore l’expérience utilisateur en éliminant le besoin de cliquer sur plusieurs pages. Cette technique charge automatiquement du nouveau contenu lorsque l’utilisateur fait défiler la page vers le bas. Cependant, elle présente des défis uniques pour les Scrapers, car elle nécessite de surveiller les changements DOM et de gérer les requêtes AJAX.
Prenons un exemple concret. Lorsque vous visitez le site web de Nike, vous remarquerez que les chaussures se chargent automatiquement lorsque vous faites défiler la page vers le bas. À chaque défilement, une icône de chargement apparaît brièvement, et en un clin d’œil, d’autres chaussures s’affichent, comme le montre l’image ci-dessous :
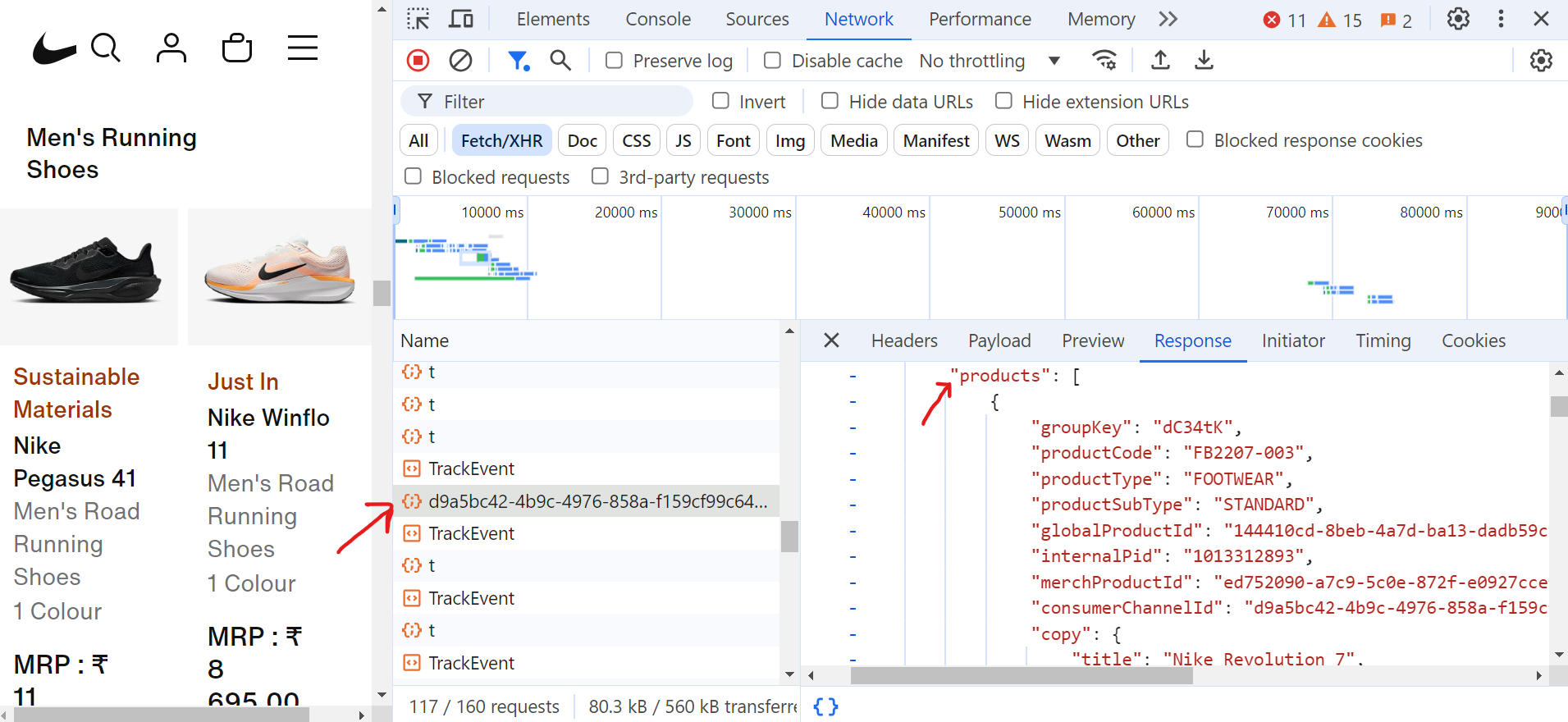
Lorsque vous cliquez sur la requête (d9a5bc), vous pouvez trouver toutes les données de la page actuelle dans l’onglet « Réponse ».
Maintenant, pour gérer la pagination, vous devez continuer à faire défiler la page jusqu’à la fin. Au fur et à mesure que vous faites défiler, le navigateur effectuera de nombreuses requêtes, mais seules certaines de ces requêtes Fetch/XHR contiendront les données réelles dont vous avez besoin.
Voici le code qui gère la pagination et extrait les titres des chaussures :
import asyncio
from urllib.parse import parse_qs, urlparse
from playwright.async_api import async_playwright
async def scroll_to_bottom(page) -> None:
"""Faites défiler la page vers le bas jusqu'à ce qu'il n'y ait plus de contenu à charger."""
last_height = await page.evaluate("document.body.scrollHeight")
scroll_count = 0
while True:
# Faites défiler vers le bas
await page.evaluate("window.scrollTo(0, document.body.scrollHeight);")
await asyncio.sleep(2) # Attendez que le nouveau contenu se charge
scroll_count += 1
print(f"Itération de défilement : {scroll_count}")
# Vérifier si la hauteur de défilement a changé
new_height = await page.evaluate("document.body.scrollHeight")
if new_height == last_height:
print("Fin de la page atteinte.")
break # Quitter si aucun nouveau contenu n'est chargé
last_height = new_height
async def extract_product_data(response, extracted_products) -> None:
"""Extraire les données produit de la réponse."""
parsed_url = urlparse(response.url)
query_params = parse_qs(parsed_url.query)
if "queryType" in query_params and query_params["queryType"][0] == "PRODUCTS":
data = await response.json()
for grouping in data.get("productGroupings", []):
for product in grouping.get("products", []):
title = product.get("copy", {}).get("title")
extracted_products.append({"title": title})
async def scrape_shoes(target_url: str) -> None:
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=True)
page = await browser.new_page()
extracted_products = []
# Configurer l'écouteur pour les réponses relatives aux données produit
page.on(
"response",
lambda response: extract_product_data(
response, extracted_products),
)
# Accéder à la page et faire défiler vers le bas
print("Accès à la page...")
await page.goto(target_url, wait_until="domcontentloaded")
await asyncio.sleep(2)
await scroll_to_bottom(page)
# Enregistrer les titres des produits dans un fichier texte
with open("product_titles.txt", "w") as title_file:
for product in extracted_products:
title_file.write(product["title"] + "n")
print(f"Récupération terminée !")
await browser.close()
if __name__ == "__main__":
asyncio.run(
scrape_shoes(
"https://www.nike.com/in/w/mens-running-shoes-37v7jznik1zy7ok")
)Dans le code, la fonction scroll_to_bottom fait défiler continuellement la page vers le bas pour charger davantage de contenu. Elle commence par enregistrer la hauteur de défilement actuelle, puis fait défiler la page vers le bas de manière répétée. Après chaque défilement, elle vérifie si la nouvelle hauteur de défilement diffère de la dernière hauteur enregistrée. Si la hauteur reste inchangée, elle conclut qu’aucun autre contenu n’est chargé et quitte la boucle. Cette approche garantit que tous les produits disponibles sont entièrement chargés avant que le processus de scraping ne se poursuive.
Voici ce qui se passe lorsque vous exécutez le code :

Une fois le code exécuté avec succès, un nouveau fichier texte contenant tous les titres des chaussures Nike est créé.
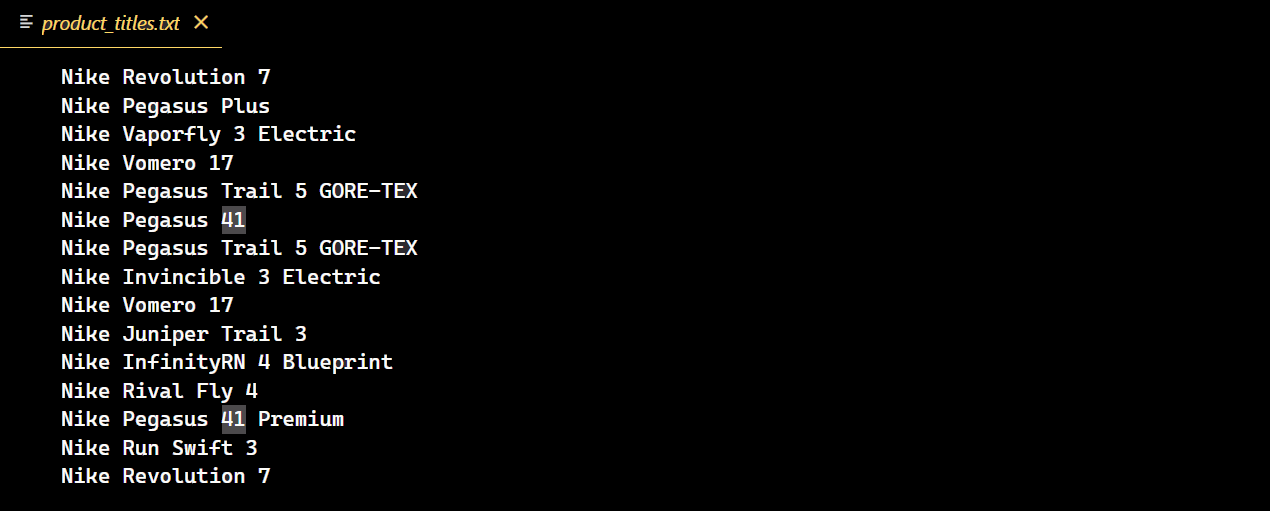
Les défis de la pagination
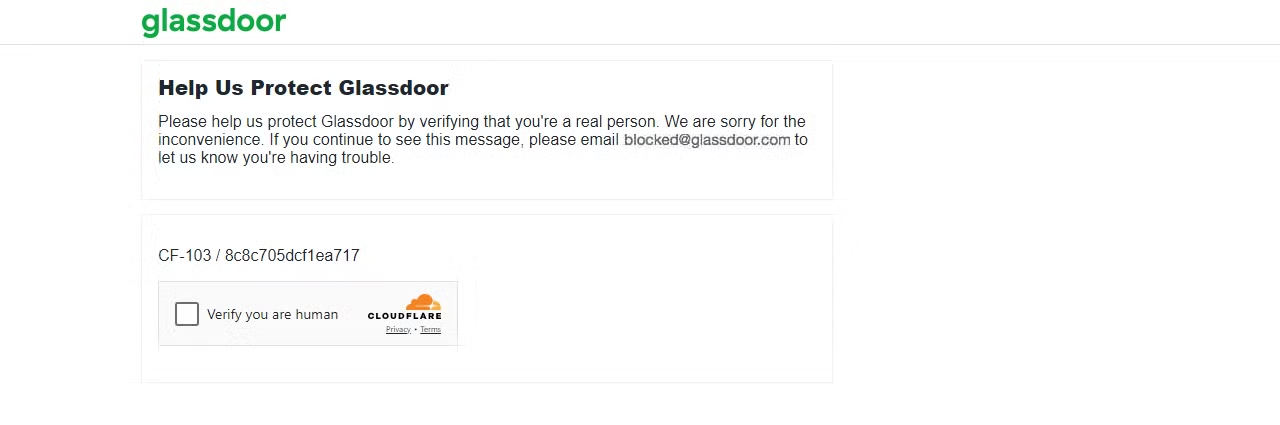
Le risque d’être bloqué augmente lorsque vous traitez du contenu paginé, et certains sites web peuvent vous bloquer après une seule page. Par exemple, si vous essayez de scraper Glassdoor, vous pouvez rencontrer divers défis liés au Scraping web, dont le défi CAPTCHA Cloudflare, comme je l’ai moi-même expérimenté.
Envoyons une requête à la page Glassdoor et voyons ce qui se passe.
import requests
url = "https://www.glassdoor.com/"
response = requests.get(url)
print(f"Code d'état : {response.status_code}")Le résultat est un code d’état 403.
Cela montre que Glassdoor a détecté que votre requête provenait d’un bot ou d’un Scraper, ce qui a entraîné un défi CAPTCHA. Si vous continuez à envoyer plusieurs requêtes, votre IP pourrait être immédiatement bloquée.
Pour contourner ces blocages et extraire efficacement les données dont vous avez besoin, vous pouvez utiliser des Proxy dans Python Requests afin d’éviter les interdictions d’IP ou imiter un navigateur réel en faisant tourner l’agent utilisateur. Cependant, il est important de noter qu’aucune de ces méthodes ne peut garantir d’éviter la détection avancée des robots.
Alors, quelle est la solution ultime ? Voyons cela maintenant !
Intégrez les solutions Bright Data
Bright Data est une excellente solution pour contourner les mesures anti-bots sophistiquées. Elle s’intègre de manière transparente à votre projet à l’aide de quelques lignes de code et offre une gamme de solutions pour tous les mécanismes anti-bots avancés.
L’une de ses solutions est l’API de scraping web, qui simplifie l’extraction de données à partir de n’importe quel site web en gérant automatiquement la rotation des adresses IP et la Résolution de CAPTCHA. Cela vous permet de vous concentrer sur l’analyse des données plutôt que sur les subtilités de leur récupération.
Par exemple, dans notre cas, nous avons rencontré des difficultés lorsque nous avons essayé de contourner le CAPTCHA sur Glassdoor. Pour y remédier, vous pouvez utiliser l’API Glassdoor Scraper de Bright Data, spécialement conçue pour contourner ces obstacles et extraire les données de manière transparente du site.
Pour commencer à utiliser l’API Glassdoor Scraper, suivez ces étapes :
Tout d’abord, créez un compte. Rendez-vous sur le site web de Bright Data, cliquez sur « Essai gratuit » et suivez les instructions d’inscription. Une fois connecté, vous serez redirigé vers votre tableau de bord, où vous obtiendrez des crédits gratuits.
Rendez-vous ensuite dans la section « Web Scraper API » et sélectionnez « Glassdoor » dans la catégorie « B2B data ». Vous trouverez différentes options de collecte de données, telles que la collecte d’entreprises par URL ou la collecte d’offres d’emploi par URL.
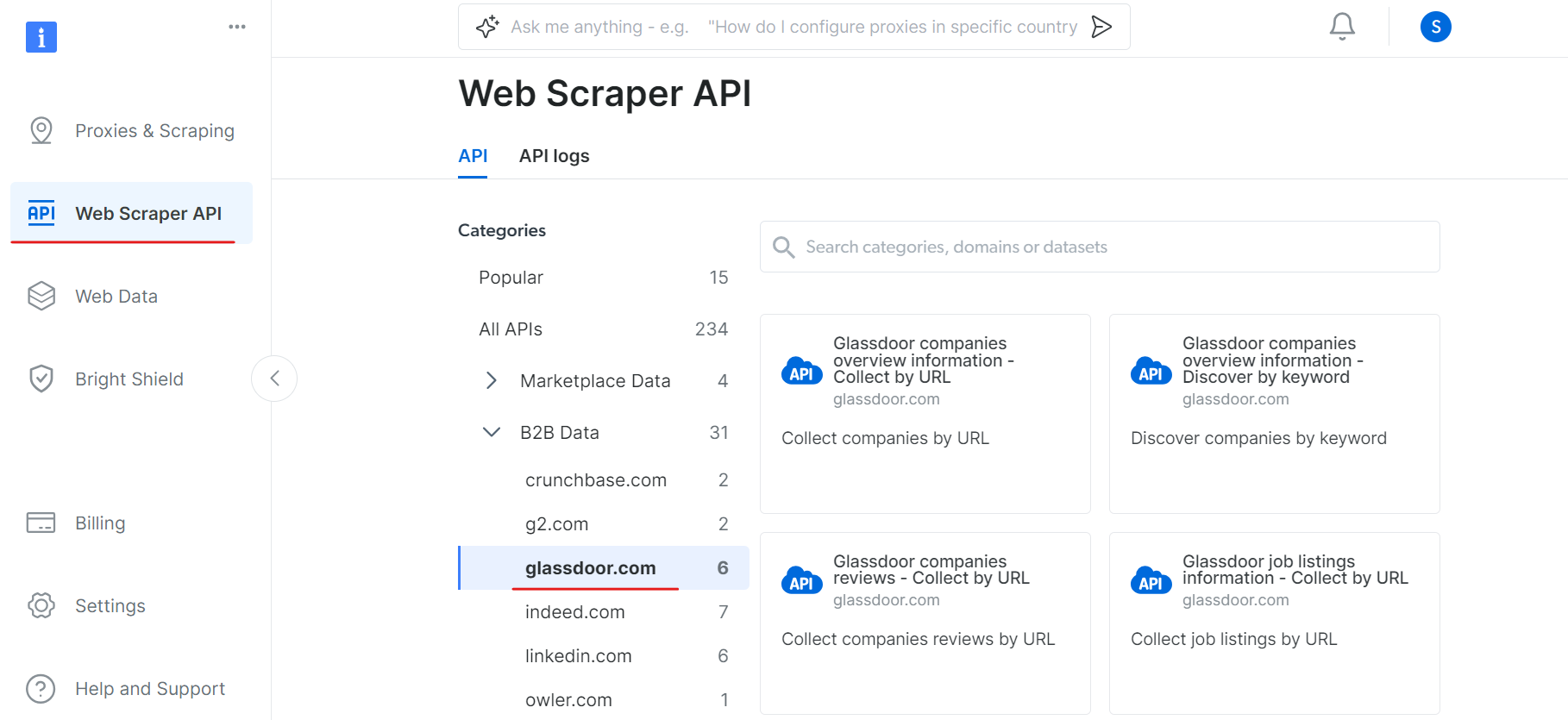
Sous « Informations générales sur les entreprises Glassdoor », obtenez votre jeton API et copiez votre ID de jeu de données (par exemple, gd_l7j0bx501ockwldaqf).
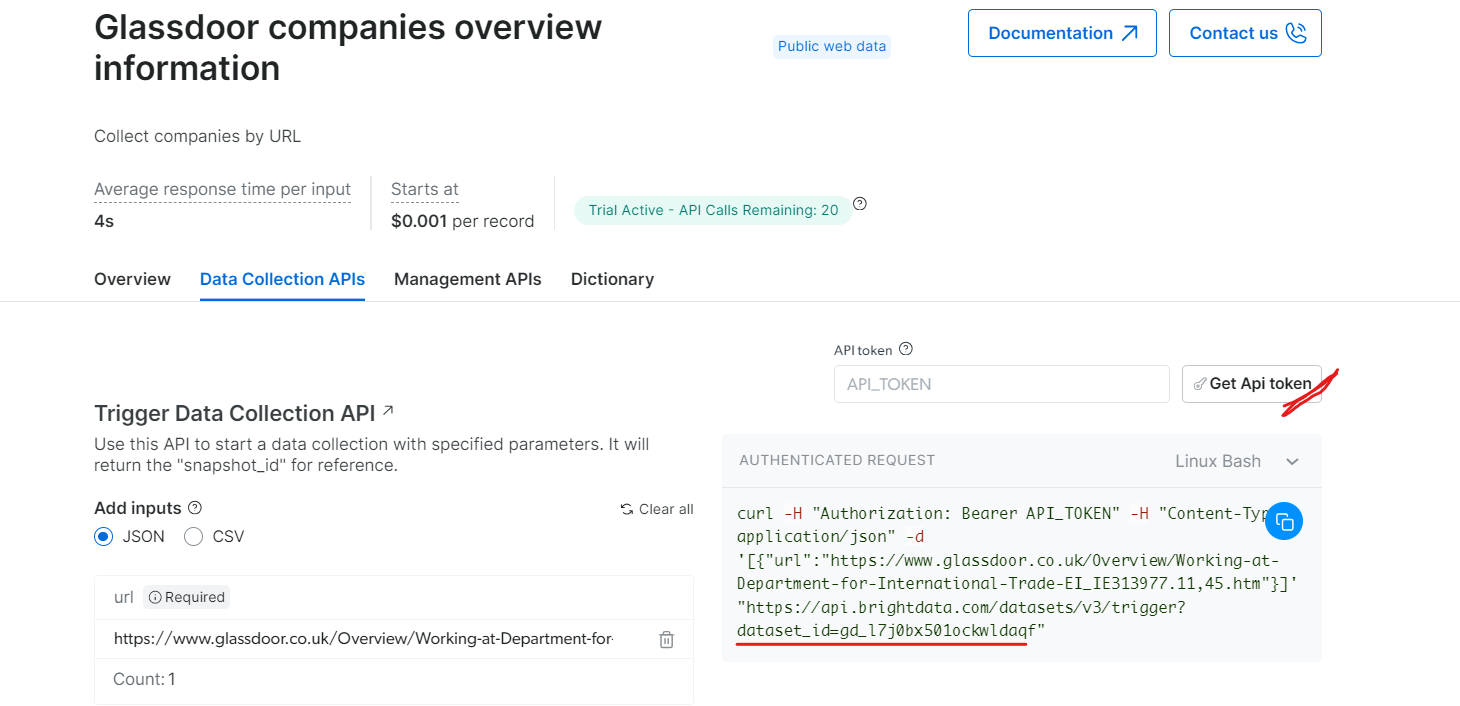
Voici un extrait de code simple qui montre comment extraire les données d’une entreprise en fournissant l’URL, le jeton API et l’ID de l’ensemble de données.
import requests
import json
def trigger_dataset(api_token, dataset_id, company_url):
"""
Déclenche un ensemble de données à l'aide de l'API BrightData.
Arguments :
api_token (str) : le jeton API pour l'authentification.
dataset_id (str) : l'ID de l'ensemble de données à déclencher.
company_url (str) : l'URL de la page de l'entreprise à analyser.
Retourne :
dict : la réponse JSON de l'API.
"""
headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
payload = json.dumps([{"url": company_url}])
response = requests.post(
"https://api.brightdata.com/datasets/v3/trigger",
headers=headers,
params={"dataset_id": dataset_id},
data=payload,
)
return response.json()
api_token = "API_Token"
dataset_id = "DATASET_ID"
company_url = "https://www.glassdoor.com/"
response_data = trigger_dataset(api_token, dataset_id, company_url)
print(response_data)Une fois le code exécuté, vous recevrez un identifiant de snapshot comme indiqué ci-dessous :

Utilisez l’ID de l’instantané pour récupérer les données réelles de l’entreprise. Exécutez la commande suivante dans votre terminal. Pour Windows, utilisez :
curl.exe -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/Jeux de données/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"Pour Linux:
curl -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/Jeux de données/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"Après avoir exécuté la commande, vous obtiendrez les données souhaitées.
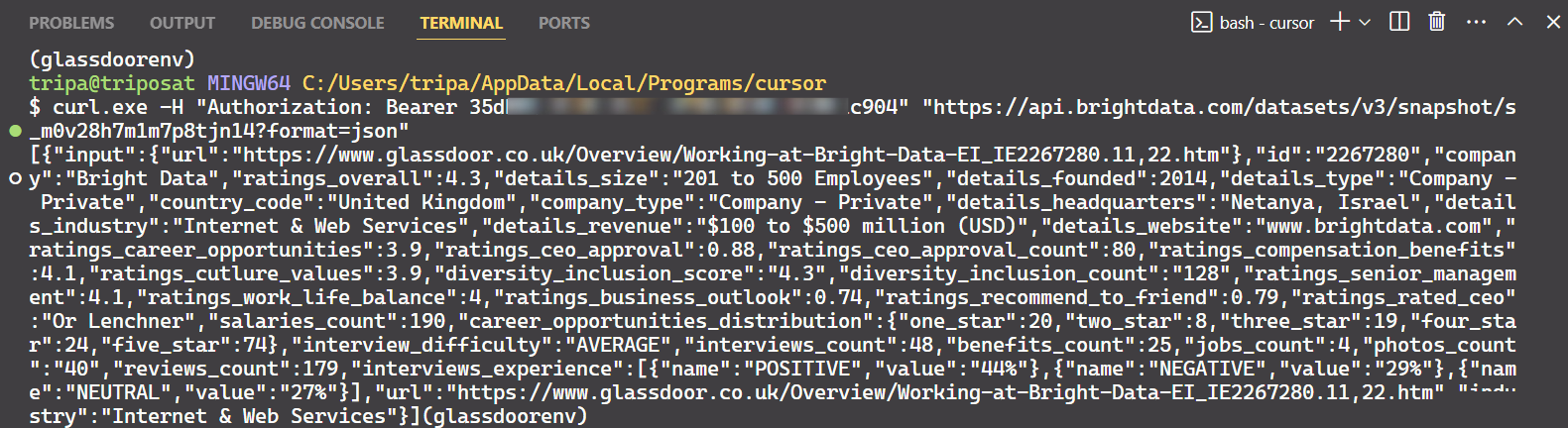
C’est tout ce qu’il faut faire !
De la même manière, vous pouvez extraire différents types de données de Glassdoor en modifiant le code. Je vous ai expliqué une méthode, mais il en existe cinq autres. Je vous recommande donc d’explorer ces options pour extraire les données que vous souhaitez. Chaque méthode est adaptée à des besoins spécifiques et vous aide à obtenir exactement les données dont vous avez besoin.
Conclusion
Cet article a présenté différentes méthodes de pagination couramment utilisées sur les sites web modernes, telles que la pagination numérotée, les boutons « charger plus » et le défilement infini. Il a également fourni des exemples de code pour mettre en œuvre efficacement ces techniques de pagination. Cependant, si la pagination ne représentait qu’une partie du Scraping web, le contournement de la détection anti-bot constituait un défi de taille.
Contourner les détections anti-bot avancées peut être assez complexe et donne souvent des résultats variables. Les outils de Bright Data offrent une solution rationalisée et rentable, comprenant Web Unlocker, Navigateur de scraping et Web Scraper APIs pour tous vos besoins en matière de Scraping web. Avec seulement quelques lignes de code, vous pouvez obtenir un taux de réussite plus élevé sans avoir à gérer des mesures anti-bot complexes.
Vous ne souhaitez pas vous impliquer dans le processus de scraping ? Découvrez notre marché de jeux de données!
Inscrivez-vous dès aujourd’hui pour un essai gratuit.





