

Dans ce tutoriel, vous verrez :
- Qu’est-ce que Qwen3 et qu’est-ce qui le distingue en tant que LLM ?
- Pourquoi il est bien adapté aux tâches d’exploration du web (web scraping)
- Comment utiliser Qwen3 localement pour le web scraping avec Hugging Face ?
- Ses principales limites et comment les contourner
- Quelques alternatives à Qwen3 pour le scraping basé sur l’IA
Plongeons dans l’aventure !
Qu’est-ce que Qwen3 ?
Qwen3 est la dernière génération de LLM développée par l ‘équipe Qwen d’Alibaba Cloud. Le modèle est open-source et peut être exploré librement sur GitHub – disponiblesous la licence Apache 2.0. Il est donc idéal pour la recherche et le développement.
Les principales caractéristiques de Qwen3 sont les suivantes
- Raisonnement hybride: Il peut passer d’un “mode réflexion” pour un raisonnement logique complexe (comme les mathématiques ou le codage) à un “mode non-réflexion” pour des réponses plus rapides et générales. Cela vous permet de contrôler la profondeur du raisonnement pour des performances optimales et un bon rapport coût-efficacité.
- Divers modèles: Qwen3 propose une suite complète de modèles, y compris des modèles denses (allant de 0,6 à 32 milliards de paramètres) et des modèles de mélange d’experts (MoE) (comme les variantes 30B et 235B).
- Des capacités améliorées: Il présente des avancées significatives en matière de raisonnement, de suivi des instructions, de capacités des agents et de prise en charge multilingue (couvrant plus de 100 langues et dialectes).
- Données d’entraînement: Qwen3 a été formé sur un ensemble de données massif d’environ 36 billions de jetons, soit près du double de son prédécesseur, Qwen2.5.
Pourquoi utiliser Qwen3 pour le Web Scraping ?
Qwen3 facilite le web scraping en automatisant l’interprétation et la structuration du contenu non structuré des pages HTML. Cela élimine le besoin d’analyser manuellement les données. Au lieu d’écrire une logique complexe pour extraire des données, le modèle comprend la structure de la page pour vous.
S’appuyer sur Qwen3 pour l’analyse des données Web est particulièrement utile pour faire face aux défis courants du web scraping tels que :
- Des mises en page qui changent fréquemment: Un scénario courant est celui d’Amazon, où chaque page de produit peut afficher des données différentes.
- Données non structurées: Qwen3 peut extraire des informations précieuses d’un texte désordonné et de forme libre sans nécessiter de sélecteurs codés en dur ou de logique regex.
- Contenu difficile à analyser: Pour les pages dont la structure est incohérente ou complexe, un LLM comme Qwen3 supprime la nécessité d’une logique d’analyse personnalisée.
Pour aller plus loin, lisez notre guide sur l’utilisation de l’IA pour le web scraping.
Un autre avantage majeur est que Qwen3 est open-source. Cela signifie que vous pouvez l’exécuter localement sur votre propre machine gratuitement, sans dépendre d’API tierces ni payer pour des LLM premium comme ceux d’OpenAI. Cela vous donne un contrôle total sur votre architecture de scraping.
Comment réaliser du Web Scraping avec Qwen3 en Python
Dans cette section, la page cible sera la page produit “Affirm Water Bottle” du bac à sable “Ecommerce Test Site to Learn Web Scraping” :
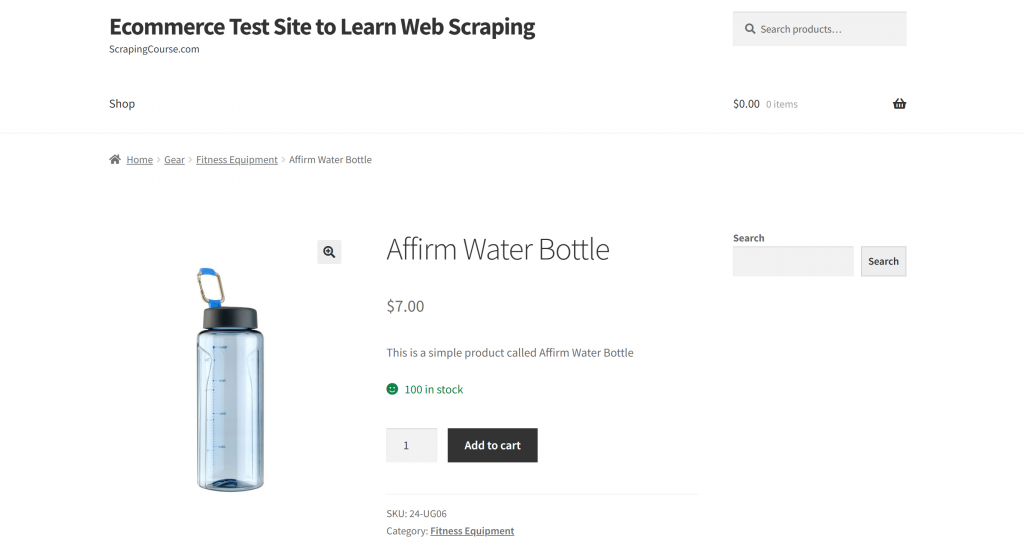
Cette page est un bon exemple, car les pages de produits de commerce électronique ont généralement des structures incohérentes, affichant différents types de données. C’est cette variabilité qui rend le web scraping particulièrement difficile, et c’est aussi là que l’IA peut faire une grande différence.
Ici, nous utiliserons un scraper alimenté par Qwen3 pour extraire intelligemment des informations sur les produits sans écrire de règles d’analyse manuelle.
Remarque: ce tutoriel vous montrera comment utiliser Hugging Face pour exécuter des modèles Qwen3 localement et gratuitement. Il existe maintenant d’autres options viables. Il s’agit notamment de se connecter à un fournisseur LLM hébergeant des modèles Qwen3, ou d’utiliser des solutions telles qu’Ollama.
Suivez les étapes ci-dessous pour commencer à récupérer des données Web à l’aide de Qwen3 !
Étape 1 : Mise en place du projet
Avant de commencer, assurez-vous que Python 3.10+ est installé sur votre machine. Sinon, téléchargez-le et suivez les instructions d’installation.
Ensuite, exécutez la commande ci-dessous pour créer un dossier pour votre projet de scraping :
mkdir qwen3-scraperLe répertoire qwen3-scraper servira de dossier de projet pour le scraping web à l’aide de Qwen3.
Naviguez vers le dossier dans votre terminal et initialisez un environnement virtuel Python à l’intérieur :
cd qwen3-scraper
python -m venv venvChargez le dossier du projet dans votre IDE Python préféré. Visual Studio Code avec l’extension Python ou PyCharm Community Edition sont deux excellentes options.
Créer un fichier scraper.py dans le dossier du projet, qui devrait maintenant contenir :

Pour l’instant, scraper.py n’est qu’un script Python vide, mais il contiendra bientôt la logique de scraping web de LLM.
Activez ensuite l’environnement virtuel. Sous Linux ou macOS, exécutez :
source venv/bin/activateDe manière équivalente, sous Windows, utilisez :
venv/Scripts/activateNote: Les étapes suivantes vous guideront dans l’installation de toutes les bibliothèques requises. Si vous préférez tout installer en une seule fois, vous pouvez utiliser la commande ci-dessous :
pip install transformers torch accelerate requests beautifulsoup4 markdownifyGénial ! Votre environnement Python est entièrement configuré pour le web scraping avec Qwen3.
Étape 2 : Configurer Qwen3 dans Hugging Face
Comme nous l’avons mentionné au début de cette section, nous utiliserons Hugging Face pour exécuter un modèle Qwen3 localement. C’est désormais possible car Hugging Face a récemment ajouté la prise en charge des modèles Qwen3.
Tout d’abord, assurez-vous que vous êtes dans un environnement virtuel activé. Ensuite, installez les dépendances nécessaires à Hugging Face en exécutant :
pip install transformers torch accelerateEnsuite, dans votre fichier scraper.py, importez les classes nécessaires de la bibliothèque de transformateurs de Hugging Face :
from transformers import AutoModelForCausalLM, AutoTokenizerMaintenant, utilisez ces classes pour charger un tokenizer et le modèle Qwen3 :
model_name = "Qwen/Qwen3-0.6B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)Dans ce cas, nous utilisons le modèle Qwen/Qwen3-0.6B, mais vous pouvez choisir parmi plus de 40 autres modèles Qwen3 disponibles sur Hugging Face.
Génial ! Vous avez maintenant tout ce qu’il faut pour utiliser Qwen3 dans votre script Python.
Étape 3 : Obtenir le code HTML de la page cible
Il est maintenant temps de récupérer le contenu HTML de la page cible. Vous pouvez y parvenir en utilisant un puissant client HTTP Python comme Requests.
Dans votre environnement virtuel activé, installez la bibliothèque Requests:
pip install requestsEnsuite, dans votre fichier scraper.py, importez la bibliothèque :
import requestsUtilisez la méthode get() pour envoyer une requête HTTP GET à l’URL de la page :
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)Le serveur répondra avec le code HTML brut de la page. Pour voir le contenu HTML complet, vous pouvez imprimer response.content :
print(response.content)Le résultat devrait être cette chaîne HTML :
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="profile" href="https://gmpg.org/xfn/11">
<link rel="pingback" href="https://www.scrapingcourse.com/ecommerce/xmlrpc.php">
<!-- omitted for brevity... -->
<title>Affirm Water Bottle – Ecommerce Test Site to Learn Web Scraping</title>
<!-- omitted for brevity... -->
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>Vous disposez maintenant du code HTML complet de la page cible en Python. Passons maintenant à l’analyse et à l’extraction des données dont nous avons besoin à l’aide de Qwen3 !
Étape 4 : Convertir la page HTML en Markdown (facultatif, mais recommandé)
Remarque: cette étape n’est pas strictement nécessaire. Cependant, elle peut vous faire gagner beaucoup de temps localement (et de l’argent si vous utilisez des fournisseurs Qwen3 payants). Elle mérite donc d’être prise en compte.
Prenez le temps d’explorer la façon dont d’autres outils de scraping web alimentés par l’IA, tels que Crawl4AI et ScrapeGraphAI, traitent le HTML brut. Vous remarquerez qu’ils proposent tous deux des options pour convertir le HTML en Markdown avant de transmettre le contenu au LLM configuré.
Pourquoi font-ils cela ? Il y a deux raisons principales :
- Rentabilité: La conversion Markdown réduit le nombre de jetons envoyés à l’IA, ce qui vous permet de réaliser des économies.
- Traitement plus rapide: Moins de données d’entrée signifie moins de coûts de calcul et des réponses plus rapides.
Pour plus d’informations, lisez notre guide sur les raisons pour lesquelles les nouveaux agents d’intelligence artificielle choisissent Markdown plutôt que HTML.
Dans ce cas, étant donné que Qwen3 fonctionne localement, la rentabilité n’est pas importante car vous n’êtes pas connecté à un fournisseur LLM tiers. Ce qui compte vraiment ici, c’est un traitement plus rapide. Pourquoi ? Parce que le fait de demander au modèle Qwen3 choisi (qui est l’un des plus petits modèles disponibles) de traiter l’intégralité de la page HTML peut facilement pousser un processeur i7 à une utilisation à 100 % pendant plusieurs minutes.
C’est trop, car vous ne voulez pas surchauffer ou geler votre ordinateur portable ou PC. Il est donc tout à fait logique de réduire la taille des données en les convertissant en format Markdown.
Il est temps de reproduire la logique de conversion de HTML en Markdown et de réduire l’utilisation des jetons !
Tout d’abord, ouvrez la page web cible en mode incognito afin d’ouvrir une nouvelle session. Ensuite, cliquez avec le bouton droit de la souris n’importe où sur la page et sélectionnez “Inspecter” pour ouvrir les DevTools. Examinez maintenant la structure de la page. Vous verrez que toutes les données pertinentes sont contenues dans l’élément HTML identifié par le sélecteur CSS #main:
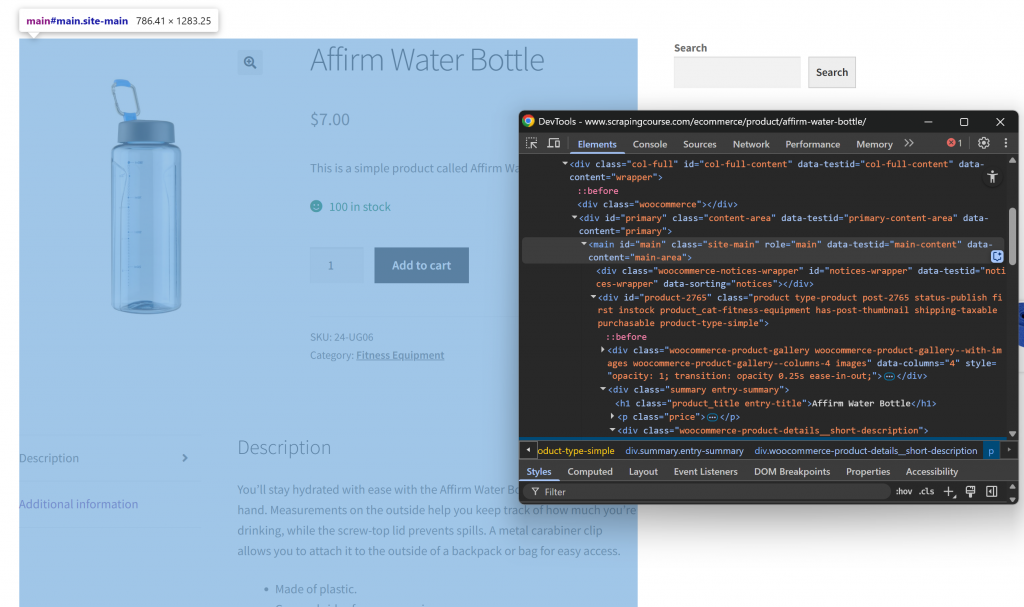
En vous concentrant sur le contenu de #main lors du processus de conversion HTML-Markdown, vous n’extrayez que la partie de la page contenant les données pertinentes. Vous évitez ainsi d’inclure les en-têtes, les pieds de page et d’autres sections qui ne vous intéressent pas. De cette manière, le résultat final en Markdown sera beaucoup plus court.
Pour sélectionner uniquement le HTML dans l’élément #main, vous avez besoin d’une bibliothèque Python d’analyse HTML comme Beautiful Soup. Dans votre environnement virtuel activé, installez-la avec cette commande :
pip install beautifulsoup4Si vous n’êtes pas familier avec son API, suivez notre guide sur le web scraping de Beautiful Soup.
Ensuite, importez-le dans scraper.py :
from bs4 import BeautifulSoupMaintenant, utilisez Beautiful Soup pour :
- Analyser le code HTML brut obtenu avec Requests
- Sélectionner l’élément
#main - Extraire son contenu HTML
Mettez en œuvre les trois micro-étapes ci-dessus à l’aide de cet extrait :
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get the outer HTML of the selected element
main_html = str(main_element)Si vous imprimez main_html, vous verrez quelque chose comme ceci :
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<!-- omitted for brevity... -->
<div id="product-2765" class="product type-product post-2765 status-publish first instock product_cat-fitness-equipment has-post-thumbnail shipping-taxable purchasable product-type-simple">
<!-- omitted for brevity... -->
</div>
</main>Cette chaîne est beaucoup plus petite que la page HTML complète, mais elle contient encore environ 13 402 caractères.
Pour réduire encore la taille sans perdre de données importantes, convertissez le HTML extrait en Markdown. Tout d’abord, installez la bibliothèque markdownify:
pip install markdownifyImporter markdownify dans scraper.py:
from markdownify import markdownifyEnsuite, utilisez-le pour convertir le HTML de #main en Markdown :
main_markdown = markdownify(main_html)Le processus de conversion des données doit produire le résultat suivant :
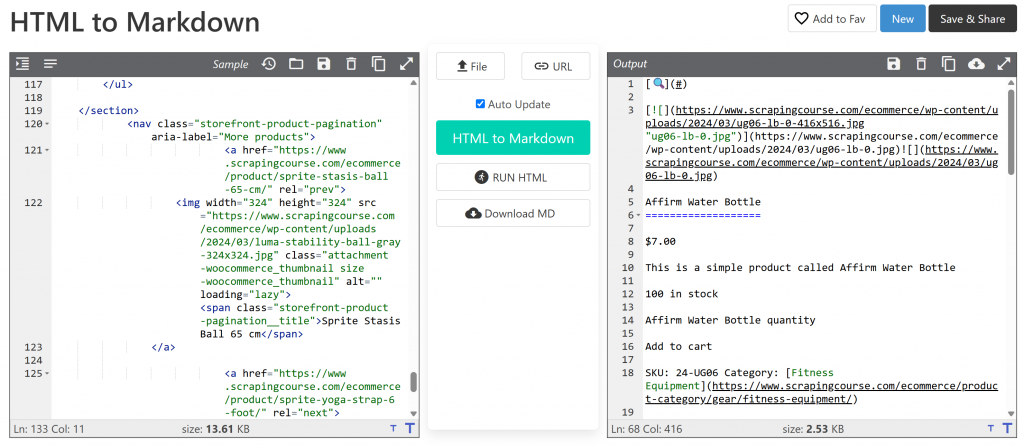
La version Markdown pèse environ 2,53 Ko, contre 13,61 Ko pour l’HTML #main d' origine. Il s’agit d’une réduction de taille de 81 % ! En outre, ce qui importe, c’est que la version Markdown conserve toutes les données clés que vous devez récupérer.
Avec cette astuce simple, vous avez réduit un extrait HTML volumineux en une chaîne Markdown compacte. Cela accélérera considérablement l’analyse des données LLM locales via Qwen3 !
Étape 5 : Utiliser Qwen3 pour l’analyse des données
Pour que Qwen3 scrape correctement les données, vous devez écrire une invite efficace. Commencez par analyser la structure de la page cible :
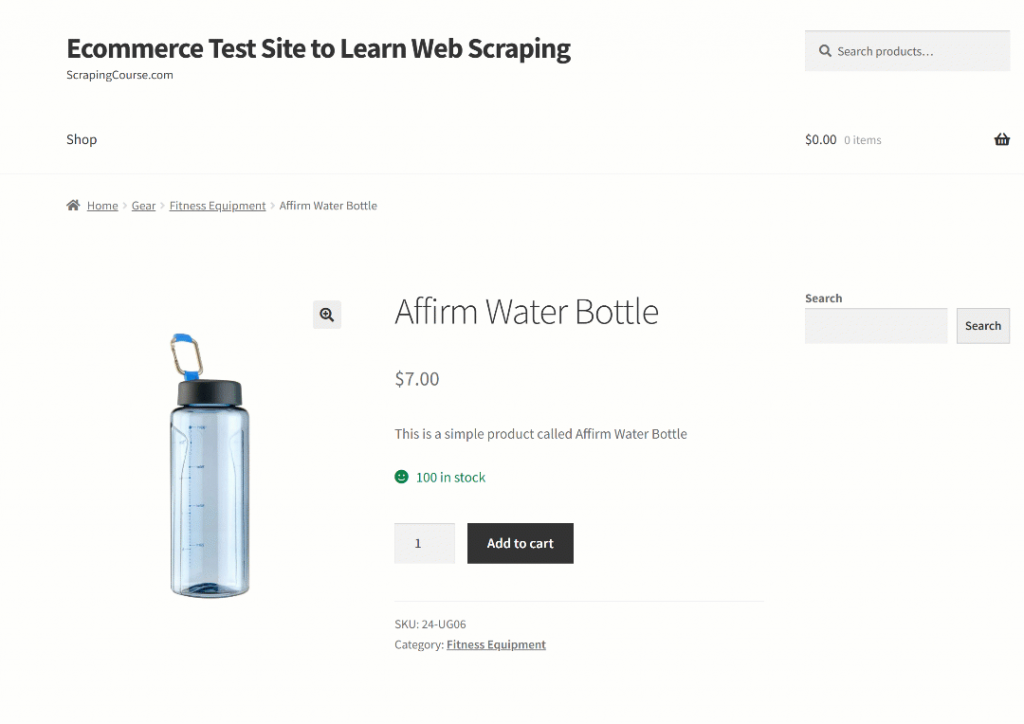
La partie supérieure de la page est cohérente pour tous les produits. En revanche, le tableau “Informations complémentaires” change en fonction du produit. Comme vous souhaitez que votre message fonctionne sur toutes les pages de produits de la plateforme, vous pouvez décrire votre tâche en termes généraux de la manière suivante :
Extract main product data from the HTML content below. Respond with a raw string in JSON format containing the scraped data in product attributes as below:nn
SAMPLE JSON ATTRIBUTES: n
sku, name, images, price, description, category + fields extracted from the "Additional information" section
CONTENT:n
<MARKDOWN_PRODUCT_CONTENT>Cette invite demande à Qwen3 d’extraire des données structurées du contenu main_markdown. Pour obtenir des résultats fiables, il est conseillé de rendre votre invite aussi claire et précise que possible. Cela permet au modèle de comprendre exactement ce que vous attendez.
Maintenant, utilisez Hugging Face pour lancer l’invite, comme expliqué dans la documentation officielle:
# Define tge data extraction prompt
prompt = prompt = f"""Extract main product data from the HTML content below. Respond with a raw string in JSON format containing the scraped data in product attributes as below:nn
SAMPLE JSON ATTRIBUTES: n
sku, name, images, price, description, category + fields extracted from the "Additional information" section
CONTENT:n
{main_markdown}
"""
# Execute the prompt
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# Retrieve the output in text format
product_raw_string = tokenizer.decode(output_ids, skip_special_tokens=True).strip("n")Le code ci-dessus utilise apply_chat_template() pour formater le message d’entrée et génère une réponse à partir du modèle Qwen3 configuré.
Remarque: un détail important est le réglage de enable_thinking=False dans apply_chat_template(). Par défaut, cette option est définie sur True, ce qui active le mode de “raisonnement” interne du modèle. Cette tâche est utile pour la résolution de problèmes complexes, mais inutile et potentiellement contre-productive pour des tâches simples telles que le web scraping. En la désactivant, on s’assure que le modèle se concentre uniquement sur l’extraction sans ajouter d’explications ou d’hypothèses.
Fantastique ! Vous venez de demander à Qwen3 d’effectuer du web scraping sur la page cible.
Il ne reste plus qu’à peaufiner la sortie et à l’exporter au format JSON.
Étape 6 : Conversion de la sortie Qwen3
La sortie produite par le modèle Qwen3-0.6B peut varier légèrement d’une exécution à l’autre. Il s’agit d’un comportement typique pour les LLM, en particulier pour les petits modèles comme celui utilisé ici.
Ainsi, la variable product_raw_string contiendra parfois les données souhaitées sous la forme d’une simple chaîne JSON. D’autres fois, elle peut contenir le JSON à l’intérieur d’un bloc de code Markdown, comme ceci :
```jsonn{n "sku": "24-UG06",n "name": "Affirm Water Bottle",n "images": ["https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/ug06-lb-0.jpg"],n "price": "$7.00",n "description": "You’ll stay hydrated with ease with the Affirm Water Bottle by your side or in hand. Measurements on the outside help you keep track of how much you’re drinking, while the screw-top lid prevents spills. A metal carabiner clip allows you to attach it to the outside of a backpack or bag for easy access.",n "category": "Fitness Equipment",n "additional_information": {n "Activity": "Yoga, Recreation, Sports, Gym",n "Gender": "Men, Women, Boys, Girls, Unisex",n "Material": "Plastic"n }n}n```Pour gérer les deux cas, vous pouvez utiliser une expression régulière pour extraire le contenu JSON lorsqu’il apparaît à l’intérieur d’un bloc Markdown. Sinon, traitez la chaîne comme du JSON brut. Ensuite, vous pouvez analyser les données JSON résultantes dans le dictionnaire Python json.loads():
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)Nous y voilà ! À ce stade, vous avez analysé les données extraites en un objet Python utilisable. La dernière étape consiste à exporter les données scannées dans un format plus convivial.
Étape 7 : Exporter les données extraites
Maintenant que vous avez les données sur les produits dans un dictionnaire Python, vous pouvez les enregistrer dans un fichier JSON comme suit :
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Cela créera un fichier nommé product.json contenant les données structurées de votre produit.
Bravo ! Votre scraper web Qwen3 est maintenant terminé.
Étape n° 8 : Assembler le tout
Voici le code final de votre script de scraping Qwen3 scraper .py :
from transformers import AutoModelForCausalLM, AutoTokenizer
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import json
import re
# The Qwen3 model to use for web scraping
model_name = "Qwen/Qwen3-0.6B"
# Load the tokenizer and the Qwen3 model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# Fetch the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/affirm-water-bottle/"
response = requests.get(url)
# Parse the HTML of the target page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get the outer HTML of the selected element and convert it to Markdown
main_html = str(main_element)
main_markdown = markdownify(main_html)
# Define tge data extraction prompt
prompt = prompt = f"""Extract main product data from the HTML content below. Respond with a raw string in JSON format containing the scraped data in product attributes as below:nn
SAMPLE JSON ATTRIBUTES: n
sku, name, images, price, description, category + fields extracted from the "Additional information" section
CONTENT:n
{main_markdown}
"""
# Execute the prompt
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# Retrieve the output in text format
product_raw_string = tokenizer.decode(output_ids, skip_special_tokens=True).strip("n")
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Exécutez le script avec :
python scraper.pyLa première fois que vous exécutez le script, Hugging Face télécharge automatiquement le modèle Qwen3 sélectionné. Ce modèle pèse environ 1,5 Go, le téléchargement peut donc prendre un certain temps en fonction de votre vitesse d’accès à Internet. Dans le terminal, vous verrez une sortie comme :
model.safetensors: 100%|██████████████████████████████████████████████████████████| 1.50G/1.50G [00:49<00:00, 30.2MB/s]
generation_config.json: 100%|█████████████████████████████████████████████████████████████████| 239/239 [00:00<?, ?B/s]Le script peut prendre un peu de temps, car PyTorch sollicite votre processeur pour charger et exécuter le modèle.
Une fois le script terminé, il créera un fichier nommé product.json dans le dossier de votre projet. Ouvrez ce fichier et vous devriez y trouver des données structurées sur les produits, comme suit :
{
"sku": "24-UG06",
"name": "Affirm Water Bottle",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/ug06-lb-0.jpg"
],
"price": "$7.00",
"description": "You’ll stay hydrated with ease with the Affirm Water Bottle by your side or in hand. Measurements on the outside help you keep track of how much youu2019re drinking, while the screw-top lid prevents spills. A metal carabiner clip allows you to attach it to the outside of a backpack or bag for easy access.",
"category": "Fitness Equipment",
"additional_information": {
"Activity": "Yoga, Recreation, Sports, Gym",
"Gender": "Men, Women, Boys, Girls, Unisex",
"Material": "Plastic"
}
}Note: Le résultat exact peut varier légèrement en raison de la nature des LLM, qui peuvent structurer le contenu récupéré de différentes manières.
Et voilà ! Votre script vient de transformer un contenu HTML brut en JSON propre et structuré. Tout cela grâce au web scraping de Qwen3.
Surmonter la principale limite de cette approche du Web Scraping
Bien sûr, dans notre exemple, tout s’est déroulé sans problème. Mais c’est uniquement parce que nous avons récupéré un site de démonstration construit spécifiquement à cette fin.
Dans le monde réel, la plupart des sites web sont bien conscients de la valeur de leurs données publiques. C’est pourquoi ils mettent souvent en œuvre des techniques anti-scraping qui peuvent rapidement bloquer les requêtes HTTP automatisées effectuées à l’aide d’outils tels que requests.
De plus, cette approche ne fonctionnera pas sur les sites à forte composante JavaScript. En effet, la combinaison des requêtes et de BeautifulSoup fonctionne bien pour les pages statiques, mais ne peut pas gérer le contenu dynamique. Si vous n’êtes pas familier avec la différence, jetez un coup d’œil à notre article sur le contenu statique et le contenu dynamique.
Parmi les autres bloqueurs potentiels, citons les interdictions d’IP, les limiteurs de débit, les empreintes TLS, les CAPTCHA, etc. En résumé, il n’est pas facile de faire du scraping sur le web, surtout maintenant que la plupart des sites web sont équipés pour détecter et bloquer les robots d’indexation et les bots.
La solution consiste à utiliser une API de déverrouillage du Web conçue pour le grattage moderne du Web à l’aide de requêtes. Un tel service s’occupe de toutes les tâches difficiles pour vous, y compris la rotation des IP, la résolution des CAPTCHA, le rendu du JavaScript et le contournement de la protection contre les robots.
Il vous suffit de transmettre l’URL de la page cible au point de terminaison de l’API Web Unlocker. L’API renverra un code HTML entièrement déverrouillé, même si la page repose sur JavaScript ou est protégée par des systèmes anti-bots avancés.
Pour l’intégrer dans votre script, il suffit de remplacer la ligne requests.get() de l’étape 3 par le code suivant :
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the payload with the target URL
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/affirm-water-bottle/", # Replace this with your target URL on a different scraping scenario
"format": "raw"
}
# Send the request
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)
# Get the unlocked HTML
html_content = response.textPour plus de détails, consultez la documentation officielle de Web Unlocker.
Avec un Web Unlocker en place, vous pouvez utiliser Qwen3 en toute confiance pour extraire des données structurées de n’importe quel site Web – plus de blocages, de problèmes de rendu ou de contenu manquant.
Alternatives à Qwen3 pour le Web Scraping
Qwen3 n’est pas le seul LLM que vous pouvez utiliser pour l’analyse automatique des données Web. Découvrez d’autres approches dans les guides suivants :
- Web Scraping avec Gemini : Tutoriel complet
- Récupération de données sur le Web à l’aide de Perplexity : Guide étape par étape
- LLM Web Scraping avec ScrapeGraphAI
- Comment construire un scraper d’IA avec Crawl4AI et DeepSeek
- Web Scraping avec LLaMA 3 : Transformer n’importe quel site web en JSON structuré
Conclusion
Dans ce didacticiel, vous avez appris à exécuter Qwen3 localement à l’aide de Hugging Face pour créer un scraper Web alimenté par l’IA. L’un des plus grands obstacles au scraping web est le blocage, mais ce problème a été résolu grâce à l’API Web Unlocker de Bright Data.
Comme nous l’avons vu précédemment, la combinaison de Qwen3 et de l’API Web Unlocker vous permet d’extraire des données de pratiquement n’importe quel site Web. Et ce, sans qu’aucune logique d’analyse personnalisée ne soit nécessaire. Cette configuration ne représente qu’un des nombreux cas d’utilisation puissants rendus possibles par l’infrastructure de Bright Data, qui vous aide à construire des pipelines de données Web évolutifs et pilotés par l’IA.
Alors, pourquoi s’arrêter là ? Envisagez d’explorer les API Web Scraper – despoints de terminaison dédiés àl’extraction de données web fraîches, structurées et entièrement conformes à partir de plus de 120 sites web populaires.
Ouvrez un compte Bright Data gratuit dès aujourd’hui et commencez à construire avec des solutions de scraping prêtes pour l’IA !




