

Dans ce guide, vous apprendrez :
- Pourquoi vous devez connaître la différence entre un contenu statique et un contenu dynamique ?
- Qu’est-ce qu’un contenu statique, comment le détecter, quels outils utiliser pour l’extraire et quels sont les défis à relever ?
- Qu’est-ce que le contenu dynamique, comment l’identifier, quels sont les outils les mieux adaptés pour le récupérer et quels sont les obstacles que vous pouvez rencontrer ?
- Un tableau comparatif des contenus statiques et dynamiques dans le contexte du web scraping
Plongeons dans l’aventure !
Introduction au contenu statique et au contenu dynamique dans le Web Scraping
En ce qui concerne le web scraping, l’approche est très différente selon que le contenu que vous souhaitez extraire est statique ou dynamique. Cette distinction influe grandement sur la manière dont vous gérez l’analyse, le traitement et l’extraction des données.
En règle générale, les sections ou les pages optimisées pour le référencement ont tendance à être statiques. En revanche, les sections hautement interactives ou celles qui nécessitent des mises à jour en direct sont généralement dynamiques. Toutefois, dans la plupart des cas, la réalité est plus complexe que cela.
Les pages web modernes sont souvent hybrides, c’est-à-dire qu’elles contiennent à la fois du contenu statique et du contenu dynamique. Par conséquent, il est généralement inexact de qualifier une page entière de simplement “statique” ou “dynamique”. Il est plus précis de dire que le contenu spécifique de la page est soit statique, soit dynamique.
Pour compliquer encore les choses, même si une page d’un site est statique, une autre page du même site peut être dynamique. Tout comme une page web peut contenir les deux types de contenu, un site web peut être une collection de pages statiques et dynamiques.
C’est dans cette optique que nous vous invitons à vous plonger dans la comparaison suivante entre le contenu statique et le contenu dynamique !
Contenu statique
Passons en revue tout ce qu’il faut savoir sur le contenu statique des pages web et sur la manière de le récupérer.
Qu’est-ce qu’un contenu statique ?
Le contenu statique désigne tous les éléments d’une page web qui sont intégrés directement dans le document HTML renvoyé par le serveur. En d’autres termes, il ne nécessite pas de rendu côté client ou de récupération de données supplémentaires par le navigateur. Ainsi, tout est déjà présent dans la réponse HTML initiale.
Il s’agit généralement d’éléments d’interface utilisateur, de texte, d’images et d’autres contenus qui ne changent pas à moins que le code source côté serveur ne soit mis à jour. Même si le serveur récupère dynamiquement des données dans des bases de données ou des API avant de générer le document HTML à envoyer au client, le contenu est toujours considéré comme statique du point de vue du client. En effet, aucun traitement supplémentaire n’est nécessaire dans le navigateur.
Comment savoir si une page web utilise un contenu statique ?
Comme nous l’avons mentionné dans l’introduction, il est rare que les sites web modernes soient 100% statiques. Après tout, la plupart des pages web comportent un certain niveau d’interactivité côté client. La vraie question n’est donc pas de savoir si une page est entièrement statique ou dynamique, mais plutôt quelles parties de la page utilisent un contenu statique.
Pour déterminer si un élément de contenu est statique, vous devez inspecter le document HTML brut renvoyé par le serveur. Notez qu’il ne s’agit pas de la même chose que ce que vous voyez dans votre navigateur. Le navigateur affiche le DOM rendu, qui peut être modifié par JavaScript après le chargement de la page.
Il existe deux façons simples de vérifier si une page utilise un contenu statique et d’identifier les éléments statiques :
- Voir la source de la page
- Utiliser un client HTTP
Pour appliquer la première approche, cliquez avec le bouton droit de la souris sur une zone vierge de la page et sélectionnez l’option “Voir la source de la page” :

Le résultat sera le code HTML original renvoyé par le serveur :

Par exemple, dans ce cas, vous pouvez dire que les éléments de citation sont déjà présents dans ce HTML. Vous pouvez donc supposer qu’ils sont statiques.
La deuxième approche consiste à effectuer une simple requête GET à l’URL de la page à l’aide d’un client HTTP :

Là encore, il s’agit du code HTML brut renvoyé par le serveur. Étant donné que les clients HTTP ne peuvent pas exécuter de JavaScript, vous n’avez pas à vous soucier des modifications du DOM. Néanmoins, comme nous le verrons bientôt, votre requête peut être bloquée par le serveur en raison de protections anti-bots. C’est pourquoi il est recommandé d’utiliser la méthode “Voir la source de la page”.
Outils de récupération de contenu statique
La récupération du contenu statique est simple car il est intégré directement dans la source HTML de la page. Vous trouverez ci-dessous une vue d’ensemble du processus :
- Récupérer le document HTML en effectuant une requête GET à l’URL de la page à l’aide d’un simple client HTTP.
- Analyser la réponse à l’aide d’un analyseur HTML.
- Extraire les éléments souhaités à l’aide de sélecteurs CSS, de XPath ou de stratégies similaires fournies par l’analyseur HTML.
Si vous cherchez des outils à utiliser pour le scraping de contenu, consultez nos guides détaillés sur :
Vous trouverez un exemple complet lié au site “Citations à gratter” – dont le code HTML a été montré dans une section précédente – dans notre tutoriel sur le grattage de sites web avec Python.
Parmi les piles de scraping les plus populaires pour récupérer du contenu statique, on peut citer
- Python: Requests + Beautiful Soup, HTTPX + Beautiful Soup, AIOHTTP + Beautiful Soup
- JavaScript: Axios + Cheerio, Node Fetch + Cheerio, Fetch API + Cheerio
- PHP: cURL + DomCrawler, Guzzle + DomCrawler, cURL + Simple HTML DOM Parser
- C#: HttpClient + HtmlAgilityPack, HttpClient + AngleSharp
“BeautifulSoup est plus rapide et utilise moins de mémoire que Selenium. Il n’exécute pas de JavaScript, ou ne fait rien d’autre que d’analyser le HTML et de travailler avec son DOM.” – Discussion sur Reddit
Défis liés à l’extraction de contenu statique
La principale difficulté du scraping de contenu statique réside dans la formulation de la bonne requête HTTP pour récupérer le document HTML. De nombreux serveurs sont configurés pour ne servir le contenu qu’aux vrais navigateurs. Ils peuvent donc bloquer votre requête s’il manque certains en-têtes ou si les vérifications de l’empreinte TLS échouent.
Pour éviter ces problèmes, vous devez définir manuellement les en-têtes HTTP appropriés pour le web scraping. Vous pouvez également utiliser un client HTTP avancé capable de simuler le comportement du navigateur, tel que cURL Impersonate.
Sinon, pour une solution professionnelle qui ne repose pas sur des astuces maladroites ou des solutions de contournement dans votre code, envisagez d’utiliser le Web Unlocker. Il s’agit d’un point d’accès qui renvoie le code HTML de n’importe quelle page web, quels que soient les mécanismes de défense mis en œuvre par le serveur.
En outre, si vous envoyez trop de requêtes à partir de la même adresse IP, vous risquez de déclencher une limitation de débit, voire une interdiction d’IP. Pour éviter cela, intégrez des proxys rotatifs afin de répartir vos demandes sur plusieurs IP. Consultez notre guide sur la manière d’éviter les interdictions d’IP avec les proxys.
Contenu dynamique
Poursuivons ce guide sur les contenus statiques et dynamiques en explorant la manière dont les contenus dynamiques sont chargés ou rendus par les pages web et comment les récupérer.
Qu’est-ce que le contenu dynamique ?
Dans les pages web, le contenu dynamique désigne tout contenu chargé ou rendu du côté client, soit lors du chargement initial de la page, soit après une interaction avec l’utilisateur. Cela inclut les données récupérées via des technologies telles que AJAX et WebSockets, ainsi que le contenu intégré dans JavaScript et rendu au moment de l’exécution dans le navigateur.
En particulier, le contenu dynamique ne fait pas partie du document HTML original renvoyé par le serveur. En effet, il est ajouté à la page après l’exécution du JavaScript. Cela signifie qu’il ne sera visible que si la page est rendue dans un navigateur, qui est le seul type d’outil capable d’exécuter JavaScript.
Comment savoir si une page Web utilise un contenu dynamique ?
La façon la plus simple de savoir si une page est dynamique ou non est de suivre l’approche inverse utilisée pour détecter un contenu statique. Si le document HTML renvoyé par le serveur ne contient pas le contenu que vous voyez sur la page, c’est qu’il existe un mécanisme permettant de récupérer ou de restituer ce contenu de manière dynamique dans le client.
L’inverse ne fonctionne pas nécessairement. Si un certain contenu est présent dans le code HTML renvoyé par le serveur, cela ne signifie pas que la page est entièrement statique. Ce contenu peut être périmé et le client peut le mettre à jour dynamiquement une fois ou périodiquement après le chargement de la page. C’est souvent le cas pour les pages qui affichent des mises à jour en direct, par exemple.
En général, pour savoir si une page contient du contenu dynamique, vous pouvez recharger la page ou répéter l’action de l’utilisateur qui provoque l’apparition du contenu en inspectant la section “Réseau” dans les DevTools de votre navigateur :
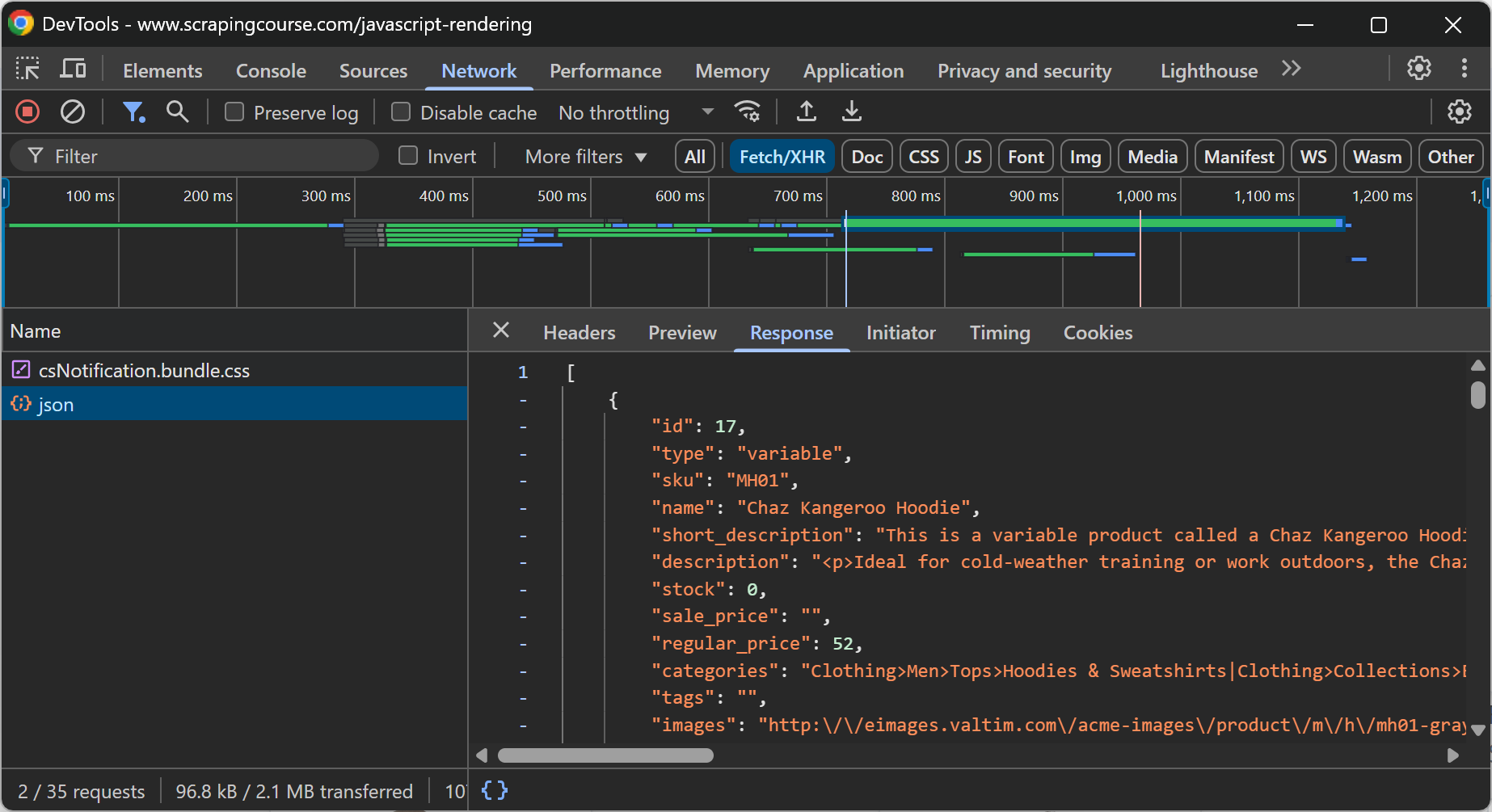
Par exemple, sur la page web ci-dessus, il est clair que les données relatives au commerce électronique sont récupérées dynamiquement par le client grâce à un appel API effectué via AJAX.
Une autre source possible de contenu dynamique est constituée par les applications web conçues comme des SPA(Single-Page Applications). Celles-ci sont alimentées par des technologies frontales telles que React qui s’appuient fortement sur le rendu JavaScript. Ainsi, si le DOM que vous voyez dans DevTools est très différent du HTML renvoyé par le serveur, la page est dynamique.
Outils de récupération de contenu dynamique
Le contenu dynamique nécessite l’exécution de JavaScript pour être rendu ou récupéré. Étant donné que seuls les navigateurs peuvent exécuter du JavaScript, vos options pour récupérer du contenu dynamique sont généralement limitées aux outils d’automatisation des navigateurs tels que Playwright, Selenium et Puppeteer.
Ces outils exposent des API qui vous permettent de contrôler de manière programmatique un véritable navigateur. Par conséquent, le web scraping de contenu dynamique nécessite ces trois étapes :
- Demander au navigateur de naviguer jusqu’à la page cible.
- Attendre qu’un contenu dynamique spécifique apparaisse sur la page.
- Sélectionner et extraire ce contenu à l’aide des API de sélection de nœuds et d’extraction de données qu’ils fournissent.
Pour plus d’informations, lisez notre article sur la manière de récupérer des sites web dynamiques en Python.
Défis liés à l’extraction de contenu dynamique
L’extraction de contenu dynamique est par nature beaucoup plus difficile que l’extraction de contenu statique. Tout d’abord, parce que vous devrez peut-être simuler les interactions de l’utilisateur dans votre code afin de reproduire toutes les actions requises pour accéder au contenu. Cela peut poser problème lorsqu’il s’agit de sites dont la navigation est complexe.
Ensuite, parce que les pages web dynamiques mettent souvent en œuvre des mesures anti-scraping et anti-bot avancées telles que les CAPTCHA, les défis JavaScript, les empreintes digitales du navigateur, etc.
N’oubliez pas non plus que les outils d’automatisation du navigateur doivent instrumenter le navigateur pour le contrôler. Ces changements dans les paramètres du navigateur peuvent être suffisants pour que les systèmes anti-bots avancés vous détectent comme un bot. C’est particulièrement vrai lorsque vous contrôlez le navigateur en mode “headless” pour économiser des ressources.
Une solution de contournement open-source à ces problèmes consiste à utiliser des bibliothèques d’automatisation de navigateur dotées de fonctions intégrées de contournement des robots, telles que SeleniumBase, Undetected ChromeDriver, Playwright Stealth ou Puppeteer Stealth.
Cependant, ces solutions n’abordent que la partie émergée de l’iceberg et sont sujettes à tous les problèmes mis en évidence par le scraping de contenu statique, tels que les interdictions d’IP, les problèmes de réputation d’IP, et bien plus encore. C’est pourquoi l’approche la plus efficace consiste à utiliser une solution telle que le Scraping Browser de Bright Data, qui :
- S’intègre à Puppeteer, Playwright, Selenium et tout autre outil d’automatisation des navigateurs.
- Fonctionne dans le nuage et s’adapte à l’infini
- Fonctionne avec un réseau de proxy de plus de 150 millions d’IP
- Fonctionne en mode tête haute pour éviter la détection des têtes basses
- Il est doté de capacités intégrées de résolution des CAPTCHA.
- Dispose de fonctions de contournement anti-bot de premier ordre.
Contenu statique ou dynamique pour le scraping web : Tableau de comparaison
Il s’agit d’un tableau récapitulatif comparant le contenu statique au contenu dynamique pour le web scraping :
| Aspect | Contenu statique | Contenu dynamique |
|---|---|---|
| Définition | Contenu intégré directement dans la réponse HTML initiale du serveur | Contenu chargé ou rendu par JavaScript après le chargement de la page |
| Visibilité en HTML | Visible dans le document HTML brut renvoyé par le serveur | Non visible dans le document HTML initial |
| Emplacement du rendu | Rendu côté serveur | Rendu côté client |
| Méthodes de détection | – Option “Voir la source de la page – Inspecter le code HTML dans un client HTTP |
– Vérifier les différences entre le HTML source et le DOM rendu – Inspecter l’onglet “Réseau” de DevTools |
| Cas d’utilisation courants | – Contenu orienté vers le référencement – Listes d’informations simples |
– Mises à jour en direct – Tableaux de bord spécifiques à l’utilisateur – Contenu de la SPA |
| Difficulté de raclage | Facile | De moyen à dur |
| Approche par grattage | Client HTTP + analyseur HTML | Outils d’automatisation des navigateurs |
| Performance | Rapide, car il n’y a pas besoin de rendu JS | Lent, car il implique le rendu des pages dans le navigateur et l’attente du chargement des éléments. |
| Principaux défis en matière de raclage | – Empreinte TLS – Limitation du débit – Interdictions d’IP |
– CAPTCHAs – Flux de navigation/interaction complexes – Défis JS |
| Outils recommandés pour éviter les blocages | Proxies, Web Unlocker | Navigateur d’exploration |
| Exemple de pile | Requêtes + belle soupe | Playwright, Selenium ou Puppeteer |
Pour une liste d’outils de scraping dans des langages de programmation spécifiques couvrant les deux scénarios, consultez les guides ci-dessous :
- Meilleures bibliothèques JavaScript pour le web scraping
- Meilleures bibliothèques Python pour le web scraping
- Les 7 meilleures bibliothèques de scraping web en PHP
- Les 7 meilleures bibliothèques de web scraping en C#
Conclusion
Dans cet article, vous avez compris les différences entre le contenu statique et le contenu dynamique des pages web, en vous concentrant sur le web scraping. Vous avez appris ce que sont ces deux types de contenu, en quoi ils diffèrent et comment gérer les deux lors de l’analyse des données web.
Qu’il s’agisse de contenu statique ou dynamique, les choses peuvent se compliquer en raison des mesures anti-scraping et anti-bot. C’est là que Bright Data intervient, en proposant un ensemble complet d’outils pour couvrir tous vos besoins en matière de scraping :
- Services de proxy: Plusieurs types de proxys pour contourner les restrictions géographiques, avec plus de 150 millions d’adresses IP[1].
- Navigateur de récupération: Un navigateur compatible avec Playright, Selenium et Puppeter, avec des capacités de déverrouillage intégrées.
- Web Scraper APIs: API préconfigurées pour l’extraction de données structurées à partir de plus de 100 domaines majeurs.
- Web Unlocker: Une API tout-en-un qui gère le déverrouillage des sites dotés de protections anti-bots.
- SERP API: Une API spécialisée qui déverrouille les résultats des moteurs de recherche et extrait les données SERP complètes de tous les principaux moteurs de recherche[2].
Créez un compte Bright Data et testez gratuitement nos produits de scraping !





