

Dans ce guide, vous découvrirez :
- Pourquoi Perplexity est un bon choix pour le web scraping piloté par l’IA ?
- Comment récupérer un site web en Python avec un tutoriel étape par étape
- La principale limite de cette approche de “web scraping”, et comment la contourner
C’est parti !
Pourquoi utiliser Perplexity pour le Web Scraping ?
Perplexity est un moteur de recherche alimenté par l’IA qui utilise de grands modèles de langage pour générer des réponses détaillées aux requêtes des utilisateurs. Il récupère des informations en temps réel, les résume et peut répondre en citant des sources.
L’utilisation de Perplexity pour le web scraping réduit le processus d’extraction de données à partir d’un contenu HTML non structuré à une simple invite. Il n’est donc plus nécessaire d’analyser manuellement les données, ce qui facilite considérablement l’extraction d’informations pertinentes.
En outre, Perplexity est conçu pour des scénarios avancés d’exploration du web, grâce à ses capacités de découverte et d’exploration des pages web.
Pour plus d’informations, consultez notre guide sur l’utilisation de l’IA pour le web scraping.
Cas d’utilisation
Voici quelques exemples de cas d’utilisation du scraping alimenté par Perplexity :
- Pages dont la structure change fréquemment: Il peut s’adapter aux pages dynamiques dont la mise en page et les éléments de données changent souvent, comme les sites de commerce électronique tels qu’Amazon.
- L’exploration de grands sites web : il peut aider à découvrir et à naviguer dans les pages ou à effectuer des recherches basées sur l’intelligence artificielle qui guident le processus d’exploration.
- Extraction de données à partir de pages complexes : Pour les sites dont la structure est difficile à analyser, Perplexity peut automatiser l’extraction de données sans nécessiter de logique d’analyse personnalisée.
Scénarios
Voici quelques exemples où l’utilisation de Perplexité s’avère utile :
- Génération améliorée par récupération (RAG) : Amélioration des connaissances en matière d’IA grâce à l’intégration du scraping de données en temps réel. Pour un exemple pratique utilisant un modèle d’IA similaire, lisez notre guide sur la création d’un chatbot RAG avec des données SERP.
- Agrégation de contenu : Collecte de nouvelles, de billets de blog ou d’articles à partir de sources multiples afin de générer des résumés ou des analyses.
- Raclage des médias sociaux : Extraction de données structurées à partir de plateformes dont le contenu est dynamique ou fréquemment mis à jour.
Comment réaliser du Web Scraping avec Perplexity en Python
Pour cette section, nous utiliserons une page de produit spécifique provenant du bac à sable “Ecommerce Test Site to Learn Web Scraping” :

Cette page est un excellent exemple de cible, car les pages de produits de commerce électronique ont souvent des structures différentes, affichant divers types de données. C’est ce qui rend le web scraping si difficile, et c’est là que l’IA peut aider.
En particulier, le scraper alimenté par Perplexity s’appuiera sur l’intelligence artificielle pour extraire les détails des produits de la page sans avoir besoin d’une logique d’analyse manuelle :
- SKU
- Nom
- Images
- Prix
- Description
- Tailles
- Couleurs
- Catégorie
Note : L’exemple suivant sera en Python pour des raisons de simplicité et en raison de la popularité des SDK concernés. Vous pouvez néanmoins obtenir le même résultat en utilisant JavaScript ou tout autre langage de programmation.
Suivez les étapes ci-dessous pour apprendre à récupérer des données web avec Perplexity !
Étape 1 : Mise en place du projet
Avant de commencer, assurez-vous que Python 3 est installé sur votre machine. Si ce n’est pas le cas, téléchargez-le et suivez les instructions d’installation.
Ensuite, exécutez la commande ci-dessous pour initialiser un dossier pour votre projet de scraping :
mkdir perplexity-scraperLe répertoire perplexity-scraper servira de dossier pour votre projet de web scraping à l’aide de Perplexity.
Naviguez vers le dossier dans votre terminal et créez un environnement virtuel Python à l’intérieur :
cd perplexity-scraper
python -m venv venvOuvrez le dossier du projet dans votre IDE Python préféré. Visual Studio Code avec l’extension Python ou PyCharm Community Edition sont deux excellentes options.
Créez un fichier scraper.py dans le dossier du projet, qui devrait maintenant ressembler à ceci :

À ce stade, scraper.py n’est qu’un script Python vide, mais il contiendra bientôt la logique de scraping web de LLM.
Ensuite, activez l’environnement virtuel dans le terminal de votre IDE. Sous Linux ou macOS, exécutez :
source venv/bin/activateDe manière équivalente, sous Windows, utilisez :
venv/Scripts/activateC’est génial ! Votre environnement Python est maintenant prêt pour le web scraping avec Perplexity.
Étape 2 : Récupérer votre clé API Perplexity
Comme la plupart des fournisseurs d’IA, Perplexity expose ses modèles via des API. Pour y accéder de manière programmatique, vous devez d’abord obtenir une clé API Perplexity. Vous pouvez vous référer au document officiel “Initial Setup” ou suivre les étapes guidées ci-dessous.
Si vous n’avez pas encore de compte Perplexity, créez-en un et connectez-vous. Ensuite, allez sur la page “API” et cliquez sur “Setup” pour ajouter une méthode de paiement si vous ne l’avez pas encore fait :

Note: Vous ne serez pas facturé à cette étape. Perplexity stocke uniquement vos informations de paiement pour une utilisation future de l’API. Vous pouvez utiliser une carte de crédit/débit, Google Pay ou toute autre méthode de paiement prise en charge.
Une fois que votre méthode de paiement est configurée, vous verrez la section suivante :

Achetez des crédits en cliquant sur “+ Acheter des crédits” et attendez qu’ils soient ajoutés à votre compte. Une fois les crédits disponibles, le bouton “+ Generate” sous la section API Keys deviendra actif. Appuyez dessus pour générer votre clé API Perplexity :

Une clé API s’affiche :

Copiez la clé et conservez-la dans un endroit sûr. Pour plus de simplicité, nous la définirons comme une constante dans scraper.py :
PERPLEXITY_API_KEY="<YOUR_PERPLEXITY_API_KEY>"Important: dans les scripts de production de Perplexity, évitez de stocker les clés d’API en texte brut. Stockez plutôt les secrets de ce type dans des variables d’environnement ou dans un fichier .env géré par des bibliothèques telles que python-dotenv.
Merveilleux ! Vous êtes prêt à utiliser le SDK OpenAI pour effectuer des requêtes API vers les modèles de Perplexity en Python.
Étape 3 : Configurer Perplexity en Python
La dernière phrase de l’étape précédente ne contient pas de faute de frappe, même si elle mentionne le SDK OpenAI. C’est parce que l’API Perplexity est entièrement compatible avec OpenAI. En fait, la manière recommandée de se connecter à l’API Perplexity en utilisant Python est de passer par le SDK OpenAI.
Dans un premier temps, installez le SDK OpenAI Python. Dans un environnement virtuel activé, exécutez :
pip install openaiEnsuite, importez-le dans votre script scraper.py :
from openai import OpenAIPour se connecter à Perplexity au lieu d’OpenAI, configurez le client comme suit :
client = OpenAI(api_key=PERPLEXITY_API_KEY, base_url="https://api.perplexity.ai")C’est très bien ! L’installation de Perplexity Python est maintenant terminée, et vous êtes prêt à faire des requêtes API à leurs modèles.
Étape 4 : Obtenir le code HTML de la page cible
Vous devez maintenant récupérer le code HTML de la page cible. Vous pouvez y parvenir avec un puissant client HTTP Python comme Requests.
Dans un environnement virtuel activé, installez Requests avec :
pip install requestsEnsuite, importez la bibliothèque dans scraper.py :
import requestsUtilisez la méthode get() pour envoyer une requête GET à l’URL de la page :
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)Le serveur cible répondra avec le code HTML brut de la page.
Si vous imprimez response.content, vous verrez le document HTML complet :
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="profile" href="https://gmpg.org/xfn/11">
<link rel="pingback" href="https://www.scrapingcourse.com/ecommerce/xmlrpc.php">
<!-- omitted for brevity... -->
<title>Ajax Full-Zip Sweatshirt – Ecommerce Test Site to Learn Web Scraping</title>
<!-- omitted for brevity... -->
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>Vous avez maintenant le code HTML exact de la page cible en Python. Analysons-le et extrayons-en les données dont nous avons besoin !
Étape 5 : Convertir la page HTML en Markdown (optionnel)
Attention: Cette étape n’est pas techniquement nécessaire, mais elle peut vous faire gagner beaucoup de temps et d’argent. Elle mérite donc d’être prise en compte.
Prenez le temps d’explorer la façon dont d’autres technologies de scraping web alimentées par l’IA, comme Crawl4AI et ScrapeGraphAI, traitent le HTML brut. Vous remarquerez qu’elles proposent toutes deux des options pour convertir le HTML en Markdown avant de transmettre le contenu au LLM configuré.
Pourquoi font-ils cela ? Il y a deux raisons principales :
- Rentabilité: La conversion au format Markdown réduit le nombre de jetons envoyés à l’IA, ce qui vous permet de réaliser des économies.
- Traitement plus rapide: Moins de données d’entrée signifie moins de coûts de calcul et des réponses plus rapides.
Pour plus d’informations, lisez notre guide sur les raisons pour lesquelles les nouveaux agents d’intelligence artificielle choisissent Markdown plutôt que HTML.
Il est temps de reproduire la logique de conversion de HTML en Markdown pour réduire l’utilisation des jetons !
Commencez par ouvrir la page web cible en mode incognito (pour vous assurer que vous travaillez sur une nouvelle session). Ensuite, cliquez avec le bouton droit de la souris n’importe où sur la page et sélectionnez “Inspecter” pour ouvrir les outils de développement.
Examinez la structure de la page. Vous constaterez que toutes les données pertinentes sont contenues dans l’élément HTML identifié par le sélecteur CSS #main:

Techniquement, vous pourriez envoyer l’intégralité du code HTML brut à Perplexity pour l’analyse des données. Cependant, cela inclurait beaucoup d’informations inutiles, telles que les en-têtes et les pieds de page. Au lieu de cela, l’utilisation du contenu de #main comme données brutes d’entrée garantit que vous ne traitez que les données les plus pertinentes. Cela réduira le bruit et limitera les hallucinations de l’IA.
Pour extraire uniquement l’élément #main, vous avez besoin d’une bibliothèque Python d’analyse HTML comme Beautiful Soup. Dans votre environnement virtuel Python activé, installez-la avec cette commande :
pip install beautifulsoup4Si vous n’êtes pas familier avec son API, lisez notre guide sur le web scraping de Beautiful Soup.
Maintenant, importez-le dans scraper.py :
from bs4 import BeautifulSoupUtilisez Beautiful Soup pour :
- Analyser le code HTML brut obtenu avec Requests
- Sélectionner l’élément
#main - Obtenir son contenu HTML
C’est possible grâce à cet extrait :
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)Si vous imprimez main_html, vous verrez quelque chose comme ceci :
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<div class="woocommerce-notices-wrapper"
id="notices-wrapper"
data-testid="notices-wrapper"
data-sorting="notices">
</div>
<div id="product-309"
class="product type-product post-309 status-publish first outofstock
product_cat-hoodies-sweatshirts has-post-thumbnail
shipping-taxable purchasable product-type-variable">
<!-- omitted for brevity... -->
</div>
</main>Utilisez l’outil Tokenizer d’OpenAI pour vérifier à combien de tokens correspond le HTML sélectionné :

Ensuite, estimez le coût de l’envoi de ces jetons à l’API de Perplexity à l’aide du LLM API Pricing Calculator:

Comme vous pouvez le constater, cette approche permet d’obtenir plus de 20 000 jetons. Cela signifie de 0,21 $ à environ 0,63 $ par demande. Sur un projet à grande échelle comportant des milliers de pages, c’est beaucoup !
Pour réduire la consommation de jetons, convertissez le HTML extrait en Markdown à l’aide d’une bibliothèque comme markdownify. Installez-la dans votre projet de scraping alimenté par Perplexity avec :
pip install markdownifyImporter markdownify dans scraper.py:
from markdownify import markdownifyEnsuite, utilisez-le pour convertir le HTML de #main en Markdown :
main_markdown = markdownify(main_html)Le processus de conversion des données produira le résultat suivant :

L’élément “size” à la fin des deux zones de texte montre que la version Markdown des données d’entrée est beaucoup plus petite que le HTML #main original. De plus, après inspection, vous remarquerez qu’elle contient toujours toutes les données clés à récupérer !
Utilisez à nouveau le Tokenizer d’OpenAI pour vérifier combien de tokens la nouvelle entrée Markdown consomme :

Grâce à cette simple astuce, vous avez réduit 20 658 jetons à 950 jetons, soit une réduction de plus de 95 %. Cela se traduit également par une réduction considérable des coûts de l’API Perplexity par requête :
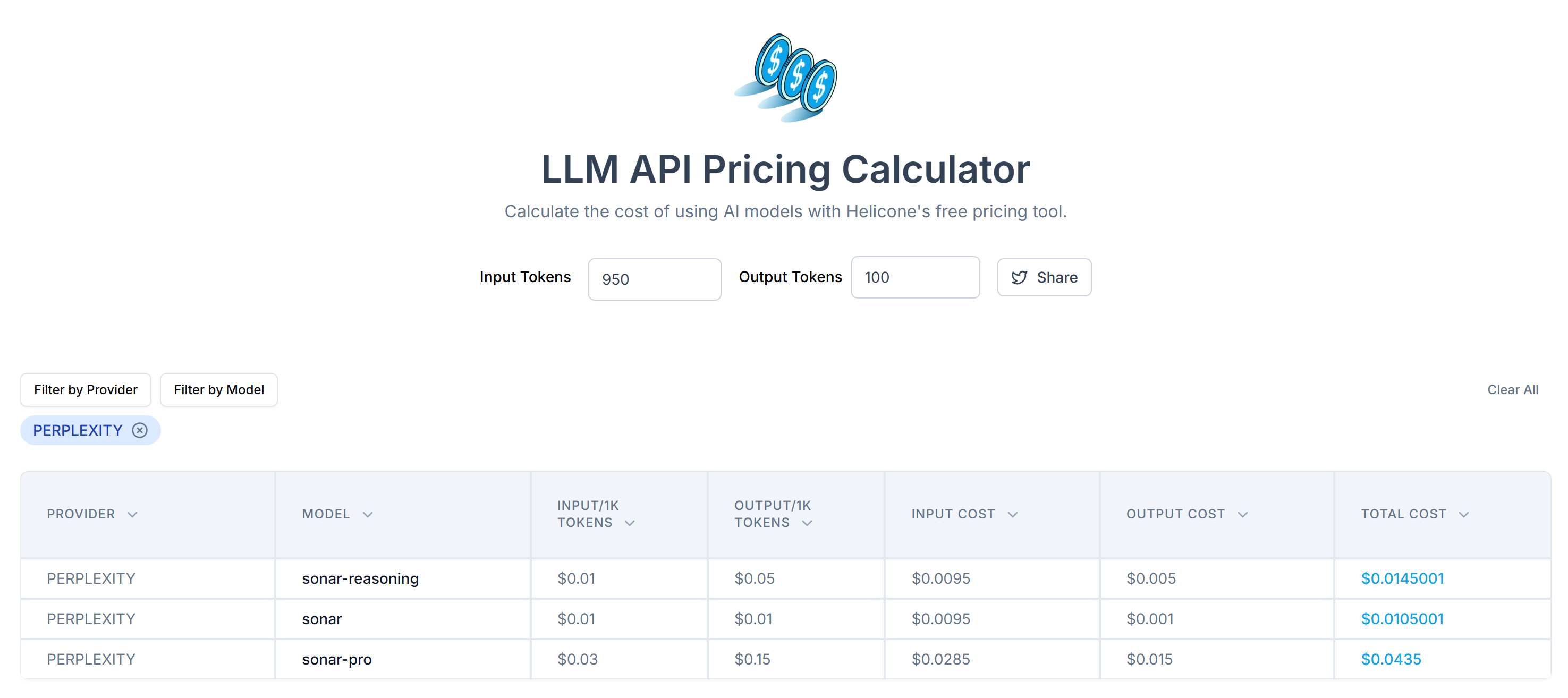
Le coût passe d’environ 0,21 à 0,63 $ par demande à seulement 0,014 à 0,04 $ par demande !
Étape 6 : Utiliser la perplexité pour l’analyse des données
Suivez les étapes suivantes pour extraire des données à l’aide de Perplexity :
- Écrire une invite bien structurée pour extraire des données JSON dans le format souhaité à partir de l’entrée Markdown.
- Envoyer une requête au modèle LLM de Perplexity en utilisant le SDK OpenAI Python
- Analyser le JSON retourné
Mettez en œuvre les deux premières étapes avec le code suivant :
# Prepare the Perplexity scraping API request body
prompt = f"""
Extract data from the content below and return JSON string with the specified attributes:nn
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
messages = [
{
"role": "system",
"content": (
"""
You are a scraping agent that returns scraped data in raw JSON format with no other content.
You only return a JSON string with the scraped data, as instructed.
Do not explain what you did whatsoever and only return the JSON string in raw format.
"""
),
},
{
"role": "user",
"content": (
prompt
),
},
]
# Perform the request to Perplexity
completion = client.chat.completions.create(
model="sonar",
messages=messages,
)
# Get the returned raw JSON data
product_raw_string = completion.choices[0].message.contentLa variable prompt demande à Perplexity d’extraire des données structurées du contenu de main_markdown. Pour améliorer les résultats, il est recommandé de définir une invite claire pour le système afin qu’il sache comment se comporter et ce qu’il doit faire.
Note: Perplexity s’appuie toujours sur l’ancienne syntaxe d’OpenAI pour faire des appels d’API. Si vous essayez d’utiliser la nouvelle syntaxe responses.create(), vous rencontrerez l’erreur suivante :
httpx.HTTPStatusError: Client error '404 Not Found' for url 'https://api.perplexity.ai/responses'Maintenant, product_raw_string doit contenir des données JSON dans le format suivant :
"```json
{
"sku": "MH12",
"name": "Ajax Full-Zip Sweatshirt",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_main.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_alt1.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_back.jpg"
],
"price": "$69.00",
"description": "The Ajax Full-Zip Sweatshirt makes the optimal layering or outer piece for archers, golfers, hikers and virtually any other sportsmen. Not only does it have top-notch moisture-wicking abilities, but the tight-weave fabric also prevents pilling from repeated wash-and-wear cycles.nnMint striped full zip hoodie.n• 100% bonded polyester fleece.n• Pouch pocket.n• Rib cuffs and hem.n• Machine washable.",
"sizes": ["XS", "S", "M", "L", "XL"],
"colors": ["Blue", "Green", "Red"],
"category": "Hoodies & Sweatshirts"
}
```"Comme vous pouvez le constater, Perplexity renvoie les données au format Markdown.
Pour mettre en œuvre l’étape 3 de l’algorithme au début de cette section, vous devez extraire le contenu JSON brut à l’aide d’une expression rationnelle. Ensuite, vous pouvez analyser les données JSON résultantes dans le dictionnaire Python json.loads():
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
Try to parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)N’oubliez pas d’importer json et re de la bibliothèque standard de Python:
import json
import reRemarque: si vous êtes un utilisateur Perplexity Tier-3, vous pouvez ignorer l’étape d’analyse des expressions rationnelles en configurant l’API pour qu’elle renvoie directement les données dans un format JSON structuré. Pour plus d’informations, consultez le guide Perplexity “Structured Outputs”.
Une fois que vous avez analysé le dictionnaire product_data, vous pouvez accéder aux champs pour un traitement ultérieur des données. Par exemple :
price = product_data["price"]
price_eur = price * USD_EUR
# ...C’est fantastique ! Vous avez réussi à utiliser Perplexity pour le web scraping. Il ne reste plus qu’à exporter les données scannées selon les besoins.
Étape 7 : Exporter les données extraites
Actuellement, les données extraites sont stockées dans un dictionnaire Python. Pour les enregistrer dans un fichier JSON, utilisez le code suivant :
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Cela génère un fichier product.json contenant les données extraites au format JSON.
Bravo ! Votre scraper web alimenté par Perplexity est maintenant prêt.
Étape n° 8 : Assembler le tout
Voici le code complet de votre script de scraping utilisant Perplexity pour l’analyse des données :
from openai import OpenAI
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import re
import json
# Your Perplexity API key
PERPLEXITY_API_KEY = "<YOUR_PERPLEXITY_API_KEY>" # replace with your API key
# Conffigure the OpenAI SDK to connect to Perplexity
client = OpenAI(api_key=PERPLEXITY_API_KEY, base_url="https://api.perplexity.ai")
# Retrieve the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)
# Convert the #main HTML to Markdown
main_markdown = markdownify(main_html)
# Prepare the Perplexity scraping API request body
prompt = f"""
Extract data from the content below and return JSON string with the specified attributes:nn
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
messages = [
{
"role": "system",
"content": (
"""
You are a scraping agent that returns scraped data in raw JSON format with no other content.
You only return a JSON string with the scraped data, as instructed.
Do not explain what you did whatsoever and only return the JSON string in raw format.
"""
),
},
{
"role": "user",
"content": (
prompt
),
},
]
# Perform the request to Perplexity
completion = client.chat.completions.create(
model="sonar",
messages=messages,
)
# Get the returned raw JSON data
product_raw_string = completion.choices[0].message.content
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Try to parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)
# Futher data processing... (optional)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Exécutez le script de scraping avec :
python scraper.pyÀ la fin de l’exécution, un fichier product.json sera généré dans le dossier de votre projet. Ouvrez-le et vous y trouverez des données structurées comme suit :
{
"sku": "MH12",
"name": "Ajax Full-Zip Sweatshirt",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_main.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_alt1.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_back.jpg"
],
"price": "69.00",
"description": "The Ajax Full-Zip Sweatshirt makes the optimal layering or outer piece for archers, golfers, hikers and virtually any other sportsmen. Not only does it have top-notch moisture-wicking abilities, but the tight-weave fabric also prevents pilling from repeated wash-and-wear cycles.n• Mint striped full zip hoodie.n• 100% bonded polyester fleece.n• Pouch pocket.n• Rib cuffs and hem.n• Machine washable.",
"sizes": [
"XS",
"S",
"M",
"L",
"XL"
],
"colors": [
"Blue",
"Green",
"Red"
],
"category": "Hoodies & Sweatshirts"
}Et voilà ! Le script a transformé les données non structurées d’une page HTML en un fichier JSON bien organisé, tout cela grâce au web scraping alimenté par Perplexity.
Prochaines étapes
Pour que votre scraper alimenté par Perplexity atteigne un niveau supérieur, envisagez les améliorations suivantes :
- Rendez-le réutilisable : Modifiez le script pour qu’il accepte l’invite et l’URL cible comme arguments de ligne de commande. Cela rendra le scraper plus flexible et adaptable à différents cas d’utilisation et projets.
- Sécuriser les informations d’identification de l’API : Stockez votre clé API Perplexity dans un fichier .env et utilisez python-dotenv pour le charger en toute sécurité. Cette approche évite de coder en dur des identifiants sensibles dans le script, améliorant ainsi la sécurité en gardant les secrets privés et séparés de la base de code.
- Mettre en œuvre l’exploration du Web : Exploitez les capacités de recherche et d’exploration alimentées par l’IA de Perplexity pour une exploration intelligente et optimisée. Configurez le scraper pour qu’il navigue à travers les pages liées, en extrayant des données structurées à partir de diverses sources.
Dépasser la plus grande limite de cette méthode de Web Scraping
Quelle est la plus grande limite de cette approche du web scraping alimentée par l’IA ? La requête HTTP faite par les requêtes !
Si l’exemple ci-dessus a parfaitement fonctionné, c’est parce que le site cible est essentiellement un terrain de jeu pour le web scraping. En réalité, les entreprises et les propriétaires de sites web comprennent la valeur de leurs données, même lorsqu’elles sont accessibles au public. Pour les protéger, ils mettent en œuvre des mesures anti-scraping qui peuvent facilement bloquer vos requêtes HTTP automatisées.
Dans ce cas, le script échouera avec des erreurs 403 Forbidden, comme par exemple :
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: <YOUR_TARGET_URL>
En outre, cette approche ne fonctionne pas sur les pages web dynamiques qui s’appuient sur JavaScript pour le rendu ou pour récupérer des données de manière asynchrone. Ainsi, les sites web n’ont même pas besoin de défenses anti-bots avancées pour bloquer votre scraper alimenté par LLM.
Quelle est donc la solution à tous ces problèmes ? Une API de déverrouillage du Web!
L’API Web Unlocker de Bright Data est un point final de scraping que vous pouvez appeler à partir de n’importe quel client HTTP. Elle renvoie le code HTML entièrement déverrouillé de toute URL que vous lui transmettez, en contournant pour vous les blocs anti-scraping. Quel que soit le nombre de protections d’un site cible, une simple requête au Web Unlocker vous permettra de récupérer le code HTML de la page.
Pour commencer, suivez la documentation officielle de Web Unlocker pour récupérer votre clé API. Ensuite, remplacez votre code de requête existant de l'”Étape #4″ par ces lignes :
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers for Web Unlocker
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the request payload
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/", # Replace with your target URL
"format": "raw"
}
# Fetch the unlocked HTML of the target page
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)
Et c’est ainsi qu’il n’y a plus de blocages, plus de limitations ! Vous pouvez désormais explorer le Web avec Perplexity sans craindre d’être arrêté.
Conclusion
Dans ce tutoriel, vous avez appris à utiliser Perplexity en combinaison avec Requests et d’autres outils pour créer un scraper alimenté par l’IA. L’un des plus grands défis du scraping web est le risque d’être bloqué, mais ce problème a été résolu grâce à l’API Web Unlocker de Bright Data.
Comme nous l’avons vu, en intégrant Perplexity à l’API Web Unlocker, vous pouvez extraire des données de n’importe quel site sans avoir besoin d’une logique d’analyse personnalisée. Ce n’est qu’un des nombreux cas d’utilisation pris en charge par les produits et services de Bright Data, qui vous permettent de mettre en œuvre un scraping web efficace piloté par l’IA.
Découvrez nos autres outils de scraping web :
- Services Proxy: Quatre types de proxy pour contourner les restrictions de localisation, y compris l’accès à plus de 400M+ monthly d’adresses IP résidentielles.
- API de grattage Web: Points d’extrémité dédiés à l’extraction de données web fraîches et structurées à partir de plus de 100 domaines populaires.
- API SERP: API pour la gestion du déverrouillage continu des SERP et l’extraction de pages individuelles.
- Navigateur de scraping: Un navigateur en nuage compatible avec Puppeteer, Selenium et Playwright, doté de capacités de déverrouillage intégrées.
Inscrivez-vous dès maintenant à Bright Data et testez gratuitement nos services de proxy et nos produits de scraping !






