

Les données sont l’un des biens les plus précieux aujourd’hui, et leur protection est devenue une priorité absolue pour les entreprises. C’est pourquoi les sites web mettent en œuvre des mesures anti-scraping avancées pour protéger leurs données. Si vous souhaitez recueillir des données de manière efficace, il est important de comprendre ces techniques anti-scraping. Cet article présente les techniques anti-scraping les plus répandues et explique comment les contourner !
Qu’est-ce que l’anti-scraping ?
L’anti-scraping désigne un ensemble de techniques et d’outils mis en œuvre par les sites web pour empêcher l’extraction non autorisée de données. Les sites web emploient diverses méthodes pour détecter les activités de scraping, telles que la surveillance du trafic entrant à la recherche de schémas inhabituels, comme un nombre excessif de requêtes provenant d’une même adresse IP.
Lesdéfis CAPTCHA sont une autre méthode couramment utilisée pour distinguer les utilisateurs humains des robots. Il ne s’agit là que de quelques-unes des nombreuses techniques anti-scraping utilisées aujourd’hui par les sites web. Nous en discuterons plus en détail dans la section suivante !
Les 7 techniques anti-scraping les plus populaires
Explorons les sept techniques anti-scraping les plus populaires et les stratégies pour les surmonter.
1. Liste noire d’adresses IP
La mise en liste noire d’adresses IP est une méthode couramment utilisée par les sites web pour limiter le nombre de requêtes qu’une même adresse IP peut effectuer dans un laps de temps donné. Cette technique est très efficace pour identifier et bloquer les Scraper qui envoient trop de requêtes.
Tout d’abord, il est recommandé de ne pas utiliser sa véritable adresse IP pour le scraping afin de contourner l’interdiction d’IP. Le meilleur moyen est d’utiliser la rotation d’IP grâce à des Proxy rotatifs premium. Il s’agit de changer fréquemment d’adresse IP afin de répartir les requêtes sur plusieurs IP, ce qui réduit les risques de détection et de blocage.
Si vous avez besoin de Proxy fiables, rapides et stables pour le Scraping web, Bright Data propose diverses options adaptées à différents cas d’utilisation. Avec des millions d’IP proxy résidentiels et de centres de données, Bright Data garantit des solutions de proxy fiables et efficaces.
2. Filtrage de l’agent utilisateur et d’autres en-têtes HTTP
Le filtrage de l’agent utilisateur est une autre technique anti-scraping courante. Les sites web analysent la chaîne “User-Agent” dans les en-têtes HTTP pour différencier et bloquer le trafic non humain. Les scrapeurs s’appuient souvent sur des chaînes User-Agent par défaut qui sont facilement détectables par les outils anti-scraping.
De même, les systèmes anti-scraping peuvent bloquer les requêtes qui n’incluent pas d’en-tête Referrer, qui contient l’URL de la page qui a initié la requête.
D’autres en-têtes comme Accept-Language, Accept-Encoding et Connection sont généralement envoyés par les navigateurs web mais rarement inclus par les scrapeurs. Les scrapeurs négligent souvent ces en-têtes parce qu’ils n’affectent pas directement la récupération du contenu.
Pour contourner ces contrôles, vous pouvez faire tourner une liste de chaînes User-Agent imitant les navigateurs et les appareils les plus courants et inclure des en-têtes supplémentaires tels que ceux mentionnés ci-dessus.
Toutefois, les sites web peuvent contrer ce phénomène en croisant les données User-Agent avec d’autres indicateurs comportementaux tels que les schémas de requête et la réputation des adresses IP. Cette technique nécessite des mises à jour constantes de la liste des chaînes User-Agent pour rester efficace, ce qui peut prendre du temps et être difficile à maintenir.
La solution ultime pour éviter ces complications est d’utiliser l’API Bright Data Web Scraper. Cette API de scraping de nouvelle génération contourne sans effort les technologies anti-bots grâce à des fonctionnalités telles que la rotation automatique des IP, la rotation des User-Agent et les Proxys résidentiels. Il n’a jamais été aussi facile d’effectuer des requêtes automatisées avec succès !
3. Défis JavaScript
Les sites web utilisent souvent des défis JavaScript pour empêcher le scraping automatisé. Ces défis peuvent inclure des CAPTCHA, le chargement de contenu dynamique et d’autres techniques qui nécessitent l’exécution de JavaScript.
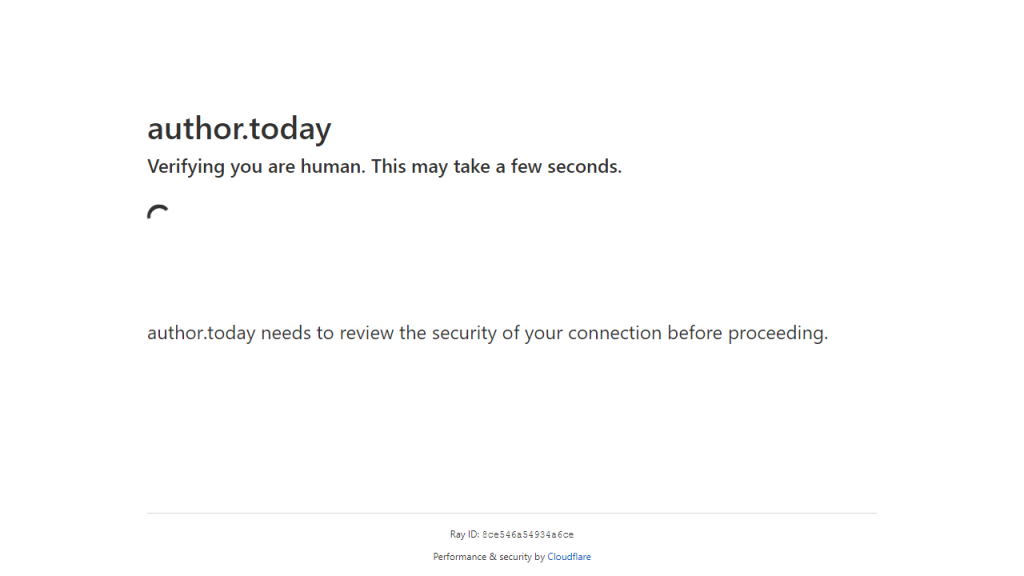
Pour relever ces défis, vous pouvez utiliser des navigateurs sans tête tels que Playwright ou Selenium, qui exécutent JavaScript et interagissent avec les pages web comme un utilisateur humain. Toutefois, les systèmes avancés de protection contre les robots, tels que Cloudflare et Akamai, présentent certains des défis les plus difficiles à relever en matière de JavaScript sur le marché. Pour surmonter ces défis, il faut souvent passer beaucoup de temps à bricoler des outils au lieu de se concentrer sur l’écriture du Scraper. Néanmoins, il est possible de les contourner en utilisant le Navigateur de scraping de données Bright.
Le Navigateur de scraping est doté d’une fonction intégrée de déverrouillage des sites web, qui se charge automatiquement de gérer les mécanismes de blocage. Il gère toutes les opérations de déverrouillage de sites web en coulisses, y compris la Résolution de CAPTCHA, les nouvelles tentatives automatiques et la sélection des en-têtes, des cookies et du rendu JavaScript appropriés. En outre, le Navigateur de scraping s’intègre de manière transparente à Puppeteer, Selenium et Playwright, offrant ainsi une expérience complète de navigation sans tête.
4. Défis CAPTCHA
LesCAPTCHA sont un système populaire de protection contre les robots qui exige des utilisateurs qu’ils relèvent un défi pour vérifier leur identité humaine.

Ces défis peuvent consister à identifier des objets dans des images, à résoudre des énigmes ou à taper un texte déformé. Les CAPTCHA sont efficaces parce qu’ils sont conçus pour être difficiles à résoudre pour les systèmes automatisés.
De nombreux services CDN(Content Delivery Network), comme Cloudflare et Akamai, intègrent désormais les CAPTCHA dans leurs offres de protection anti-bots. Cela aide les sites web à présenter automatiquement des CAPTCHA aux utilisateurs suspects, notamment lorsque des schémas de trafic inhabituels sont détectés.
Heureusement, des résolveurs de CAPTCHA ont été mis au point pour résoudre ce problème. Il existe de nombreux solveurs de CAPTCHA disponibles sur le marché, que nous avons examinés en détail dans notre article, Best 9 CAPTCHA Solvers for Web Scraping web. Vous pouvez les passer en revue en fonction de facteurs tels que la vitesse, la précision, le prix, les types de CAPTCHA qu’ils résolvent et l’intégration de l’API pour trouver celui qui répond le mieux à vos besoins.
D’après mon expérience, le Web Unlocker de Bright Data se démarque en termes de taux de réussite, de vitesse et de capacité à résoudre différents types de CAPTCHA. Pour plus d’informations, vous pouvez consulter le guide détaillé sur le contournement des CAPTCHA à l’aide de Web Unlocker.
5. Pièges de type “Honeypot
Lespots de miel sont un moyen simple mais efficace d’identifier et de bloquer les robots non sophistiqués qui ne parviennent pas à faire la différence entre le contenu visible et le contenu caché. Ces pièges comprennent souvent des liens ou des formulaires cachés qui sont invisibles pour les utilisateurs humains mais détectables par les robots. Lorsqu’un Scraper interagit avec un honeypot, il déclenche le blocage du système anti-scraping.
Pour éviter les pots de miel, les Scraper doivent analyser soigneusement la structure HTML des pages web et éviter d’interagir avec des éléments qui ne sont pas visibles pour les utilisateurs humains, tels que ceux qui ont des propriétés comme "display : none" ou "visibility : hidden". Une autre stratégie consiste à alterner les Proxy, de sorte que si l’une des adresses IP du serveur proxy est prise dans un pot de miel et interdite, vous pouvez toujours vous connecter par le biais d’autres Proxy.
6. Analyse du comportement
L’analyse comportementale consiste à surveiller les actions de l’utilisateur au fil du temps afin de détecter des schémas indiquant un scraping automatisé. Les robots ont des comportements prévisibles et répétitifs, comme le fait de faire des demandes à intervalles réguliers, de suivre des chemins de navigation inhabituels ou d’accéder à des pages dans un ordre spécifique. Les sites web analysent également des facteurs tels que la durée de la session, les mouvements de la souris et le moment de l’interaction pour identifier les activités non humaines.
Les systèmes anti-bots avancés utilisent l’apprentissage automatique pour s’adapter aux nouvelles techniques de scraping. En formant des modèles sur de vastes Jeux de données d’interactions avec les utilisateurs, ces systèmes peuvent différencier plus précisément les comportements humains et ceux des robots. Cette approche adaptative permet aux algorithmes d’apprentissage automatique d’évoluer en fonction des stratégies des robots.
Il peut être difficile de contourner ces systèmes, et vous aurez probablement besoin de services anti-scraping avancés pour rester dans la course. Web Unlocker est une solution avancée basée sur l’IA et l’apprentissage automatique. Elle est conçue pour s’attaquer à ces blocages et les contourner. Il utilise l’apprentissage automatique pour déterminer les meilleures méthodes de contournement des défenses des sites et emploie des algorithmes entraînés pour appliquer des configurations d’empreintes digitales personnalisées.
7. Empreinte du navigateur
L’empreinte digitale du navigateur est une technique utilisée par les sites web pour collecter des informations sur votre navigateur, telles que la résolution de l’écran, le système d’exploitation, la langue, le fuseau horaire, les extensions installées et les polices de caractères. En combinant ces détails, les sites web peuvent créer un identifiant unique pour votre appareil, qui peut être utilisé pour suivre et bloquer les scrapeurs. Pour éviter l’empreinte digitale du navigateur, vous pouvez randomiser ces caractéristiques afin de rendre plus difficile la création d’une empreinte digitale cohérente par les sites web. Pour ce faire, vous pouvez changer fréquemment d’adresse IP, utiliser différents en-têtes de requête (y compris différents User-Agents) et configurer votre navigateur sans tête pour qu’il utilise différentes tailles d’écran, résolutions et polices.
Bien que ces méthodes puissent fonctionner dans certains cas, elles comportent des risques et des limites. Pour économiser du temps et des efforts et garantir le bon déroulement des opérations de scraping, envisagez d’utiliser des outils tels que Bright Data Web Unlocker ou Scraping Browser, qui sont spécifiquement conçus pour relever efficacement ces défis.
Conclusion
Cet article a couvert tout ce que vous devez savoir sur les techniques anti-scraping les plus répandues. En comprenant ces techniques et en mettant en œuvre des tactiques d’évasion avancées, vous pouvez extraire efficacement des données des sites web.
Pour plus de conseils, nous avons un guide détaillé sur le Scraping web sans se faire bloquer, où nous discutons de diverses solutions pour surmonter les restrictions des sites web.
Vous pouvez également rationaliser le processus en utilisant le Navigateur de scraping web ou le Web Unlocker de Bright Data pour accéder aux données de n’importe quel site web, quelles que soient leurs restrictions. Commencez à utiliser les produits Bright Data dès aujourd’hui avec un essai gratuit, inscrivez-vous ci-dessous !






