

Dans ce tutoriel, vous apprendrez :
- Ce qu’est Crawl4AI et ce qu’il offre pour le web scraping
- Les scénarios idéaux pour utiliser Crawl4AI avec un LLM comme DeepSeek
- Comment construire un scraper Crawl4AI alimenté par DeepSeek dans une section guidée.
Plongeons dans l’aventure !
Qu’est-ce que Craw4AI ?
Crawl4AI est un crawler et un scraper web open-source, prêt pour l’IA, conçu pour une intégration transparente avec les grands modèles de langage (LLM), les agents d’IA et les pipelines de données. Il permet d’extraire des données en temps réel et à grande vitesse, tout en étant flexible et facile à déployer.
Les fonctionnalités qu’il offre pour l’IA web scraping sont les suivantes :
- Conçu pour les LLM: Génère du Markdown structuré optimisé pour la génération augmentée par la recherche (RAG) et le réglage fin.
- Contrôle flexible du navigateur: Prise en charge de la gestion des sessions, des proxies et des crochets personnalisés.
- Intelligence heuristique: Utilise des algorithmes intelligents pour optimiser l’analyse des données.
- Entièrement open source: Aucune clé d’API n’est requise ; déploiement possible via Docker et des plateformes en nuage.
Pour en savoir plus, consultez la documentation officielle.
Quand utiliser Crawl4AI et DeepSeek pour le Web Scraping ?
DeepSeek propose des modèles LLM puissants, open-source et gratuits qui ont fait des vagues dans la communauté de l’IA en raison de leur efficacité et de leur efficience. De plus, ces modèles s’intègrent parfaitement à Crawl4AI.
En exploitant DeepSeek dans Crawl4AI, vous pouvez extraire des données structurées des pages web les plus complexes et les plus incohérentes. Tout cela sans avoir besoin d’une logique d’analyse prédéfinie.
Vous trouverez ci-dessous des scénarios clés dans lesquels la combinaison DeepSeek + Crawl4AI est particulièrement utile :
- Changements fréquents de la structure des sites: Les scrapers traditionnels s’arrêtent lorsque les sites web mettent à jour leur structure HTML, alors que l’IA s’adapte dynamiquement.
- Mises en page incohérentes: Les plateformes telles qu’Amazon ont des conceptions de pages de produits différentes. Un LLM peut extraire intelligemment des données indépendamment des différences de mise en page.
- Analyse de contenu non structuré: L’extraction d’informations à partir de commentaires en texte libre, d’articles de blog ou de discussions de forum devient facile grâce au traitement alimenté par LLM.
Scraping Web avec Craw4AI et DeepSeek : Guide étape par étape
Dans ce tutoriel guidé, vous apprendrez à construire un scraper web alimenté par l’IA en utilisant Crawl4AI. Nous utiliserons DeepSeek comme moteur LLM.
Plus précisément, vous verrez comment créer un scraper AI pour extraire des données de la page G2 pour Bright Data :
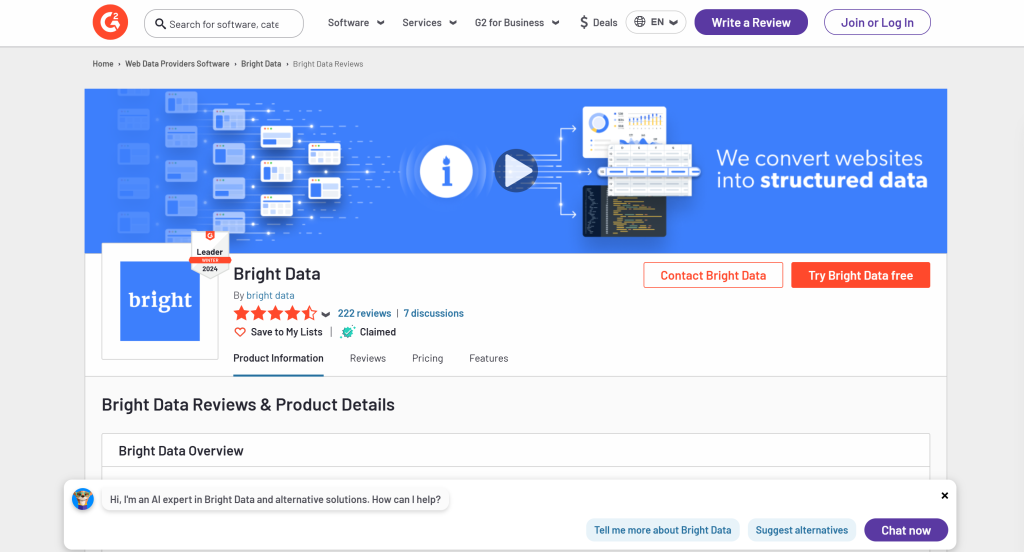
Suivez les étapes ci-dessous et apprenez à faire du web scraping avec Crawl4AI et DeepSeek !
Conditions préalables
Pour suivre ce tutoriel, assurez-vous de remplir les conditions préalables suivantes :
- Python 3+ installé sur votre machine
- Un compte GroqCloud
- Un compte Bright Data
Ne vous inquiétez pas si vous n’avez pas encore de compte GroqCloud ou Bright Data. Vous serez guidé dans leur configuration au cours des prochaines étapes.
Étape 1 : Configuration du projet
Exécutez la commande suivante pour créer un dossier pour votre projet de scraping Crawl4AI DeepSeek :
mkdir crawl4ai-deepseek-scraperNaviguez dans le dossier du projet et créez un environnement virtuel:
cd crawl4ai-deepseek-scraper
python -m venv venvMaintenant, chargez le dossier crawl4ai-deepseek-scraper dans votre IDE Python préféré. Visual Studio Code avec l’extension Python ou PyCharm Community Edition sont deux excellentes options.
Dans le dossier du projet, créez :
scraper.py: Le fichier qui contiendra la logique de scraping alimentée par l’IA.models/: Un répertoire pour stocker les modèles de données Crawl4AI LLM basés sur Pydantic..env: Fichier permettant de stocker les variables d’environnement en toute sécurité.
Après avoir créé ces fichiers et dossiers, la structure de votre projet devrait ressembler à ceci :

Ensuite, activez l’environnement virtuel dans le terminal de votre IDE.
Sous Linux ou macOS, lancez cette commande :
./env/bin/activateDe manière équivalente, sous Windows, exécutez :
env/Scripts/activateSuper ! Vous avez maintenant un environnement Python pour Crawl4AI web scraping avec DeepSeek.
Étape 2 : Installer Craw4AI
Une fois votre environnement virtuel activé, installez Crawl4AI via le paquetage crawl4ai pip :
pip install crawl4aiNotez que la bibliothèque a plusieurs dépendances, l’installation peut donc prendre un certain temps.
Une fois installé, exécutez la commande suivante dans votre terminal :
crawl4ai-setupLe processus :
- Installe ou met à jour les navigateurs Playwright requis (Chromium, Firefox, etc.).
- Effectuer des contrôles au niveau du système d’exploitation (par exemple, s’assurer que les bibliothèques système requises sont installées sous Linux).
- Confirme que votre environnement est correctement configuré pour l’exploration du web.
Après avoir exécuté la commande, vous devriez obtenir un résultat similaire à celui-ci :
[INIT].... → Running post-installation setup...
[INIT].... → Installing Playwright browsers...
[COMPLETE] ● Playwright installation completed successfully.
[INIT].... → Starting database initialization...
[COMPLETE] ● Database backup created at: C:Usersantoz.crawl4aicrawl4ai.db.backup_20260219_092341
[INIT].... → Starting database migration...
[COMPLETE] ● Migration completed. 0 records processed.
[COMPLETE] ● Database initialization completed successfully.
[COMPLETE] ● Post-installation setup completed!C’est incroyable ! Crawl4AI est maintenant installé et prêt à l’emploi.
Étape 4 : Initialiser scraper.py
Comme Crawl4AI nécessite un code asynchrone, commencez par créer un script asyncio de base :
import asyncio
async def main():
# Scraping logic...
if __name__ == "__main__":
asyncio.run(main())N’oubliez pas que le projet implique des intégrations avec des services tiers tels que DeepSeek. Pour mettre cela en œuvre, vous devrez vous appuyer sur des clés d’API et d’autres secrets. Nous les stockerons dans un fichier .env.
Installer python-dotenv pour charger les variables d’environnement :
pip install python-dotenvAvant de définir main(), chargez les variables d’environnement à partir du fichier .env avec load_dotenv() :
load_dotenv()Importer load_dotenv de la bibliothèque python-dotenv:
from dotenv import load_dotenvParfait ! scraper.py est prêt à accueillir une logique de scraping alimentée par l’IA.
Étape 5 : Créer votre premier scraper d’IA
Dans la fonction main() de scraper.py, ajoutez la logique suivante en utilisant un crawler Crawl4AI de base:
# Browser configuration
browser_config = BrowserConfig(
headless=True
)
# Crawler configuration
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS
)
# Run the AI-powered crawler
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://www.g2.com/products/bright-data/reviews",
config=crawler_config
)
# print the first 1000 characters
print(f"Parsed Markdown data:n{result.markdown[:1000]}")Dans l’extrait ci-dessus, les points clés sont les suivants :
BrowserConfig: Contrôle la façon dont le navigateur est lancé et se comporte, y compris des paramètres tels que le mode sans tête et les agents utilisateurs personnalisés pour le web scraping.CrawlerRunConfig: Définit le comportement du crawler, comme la stratégie de mise en cache, les règles de sélection des données, les délais d’attente, etc.headless=True: Configure le navigateur pour qu’il s’exécute en mode headless (sansinterface graphique) afin d’économiser des ressources.CacheMode.BYPASS: cette configuration garantit que le robot d’exploration récupère du contenu frais directement sur le site web au lieu de s’appuyer sur les données mises en cache.crawler.arun(): Cette méthode lance le crawler asynchrone pour extraire les données de l’URL spécifiée.result.markdown: Le contenu extrait est converti au format Markdown, ce qui facilite son analyse.
N’oubliez pas d’ajouter les importations suivantes :
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheModePour l’instant, scraper.py devrait contenir :
import asyncio
from dotenv import load_dotenv
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
# Load secrets from .env file
load_dotenv()
async def main():
# Browser configuration
browser_config = BrowserConfig(
headless=True
)
# Crawler configuration
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS
)
# Run the AI-powered crawler
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://www.g2.com/products/bright-data/reviews",
config=crawler_config
)
# print the first 1000 characters
print(f"Parsed Markdown data:n{result.markdown[:1000]}")
if __name__ == "__main__":
asyncio.run(main())Si vous exécutez le script, vous devriez obtenir le résultat suivant :
[INIT].... → Crawl4AI 0.4.248
[FETCH]... ↓ https://www.g2.com/products/bright-data/reviews... | Status: True | Time: 0.83s
[SCRAPE].. ◆ Processed https://www.g2.com/products/bright-data/reviews... | Time: 1ms
[COMPLETE] ● https://www.g2.com/products/bright-data/reviews... | Status: True | Total: 0.83s
Parsed Markdown data:C’est suspect, car le contenu Markdown analysé est vide. Pour aller plus loin, imprimez l’état de la réponse :
print(f"Response status code: {result.status_code}")Cette fois-ci, les résultats comprendront :
Response status code: 403Le résultat de l’analyse Markdown est vide car la requête Crawl4AI a été bloquée par les systèmes de détection des robots de G2. Le code de statut 403 Forbidden renvoyé par le serveur le montre clairement.
Cela ne devrait pas être surprenant, car G2 a mis en place des mesures anti-bots strictes. En particulier, il affiche souvent des CAPTCHA, même lorsqu’on y accède à partir d’un navigateur ordinaire :

Dans ce cas, comme aucun contenu valide n’a été reçu, Crawl4AI n’a pas pu le convertir en Markdown. Dans l’étape suivante, nous verrons comment contourner cette restriction. Pour en savoir plus, consultez notre guide sur le contournement des CAPTCHA en Python.
Étape 6 : Configuration de l’API de Web Unlocker
Crawl4AI est un outil puissant doté de mécanismes intégrés de contournement des robots. Cependant, il ne peut pas contourner les sites web hautement protégés comme G2, qui utilisent des mesures anti-bots et anti-scraping strictes et de premier ordre.
Face à de tels sites, la meilleure solution consiste à utiliser un outil spécialisé conçu pour débloquer n’importe quelle page web, quel que soit son niveau de protection. Le produit de scraping idéal pour cette tâche est Web Unlocker de Bright Data, une API de scraping qui :
- Simule le comportement d’un utilisateur réel pour contourner la détection des robots.
- Gère automatiquement la gestion du proxy et la résolution des CAPTCHA
- Évolue de manière transparente sans nécessiter de gestion d’infrastructure
Suivez les instructions suivantes pour intégrer l’API Web Unlocker dans votre Crawl4AI DeepSeek scraper.
Vous pouvez également consulter la documentation officielle.
Tout d’abord, connectez-vous à votre compte Bright Data ou créez-en un si vous ne l’avez pas encore fait. Approvisionnez votre compte ou profitez de l’essai gratuit disponible pour tous les produits.
Ensuite, naviguez vers “Proxies & Scraping” dans le tableau de bord et sélectionnez l’option “unblocker” dans le tableau :
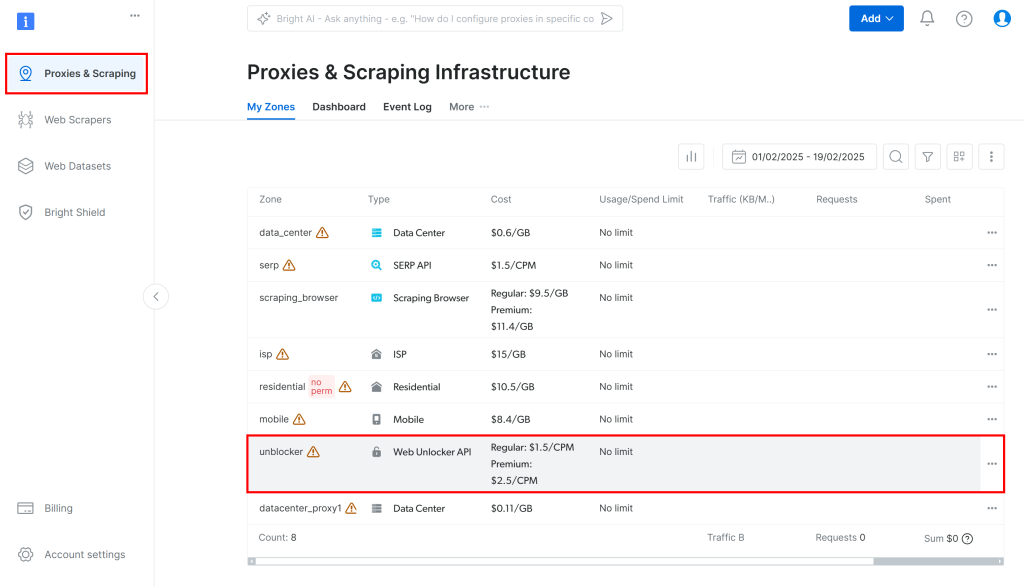
Vous accéderez à la page de configuration de l’API de Web Unlocker illustrée ci-dessous :
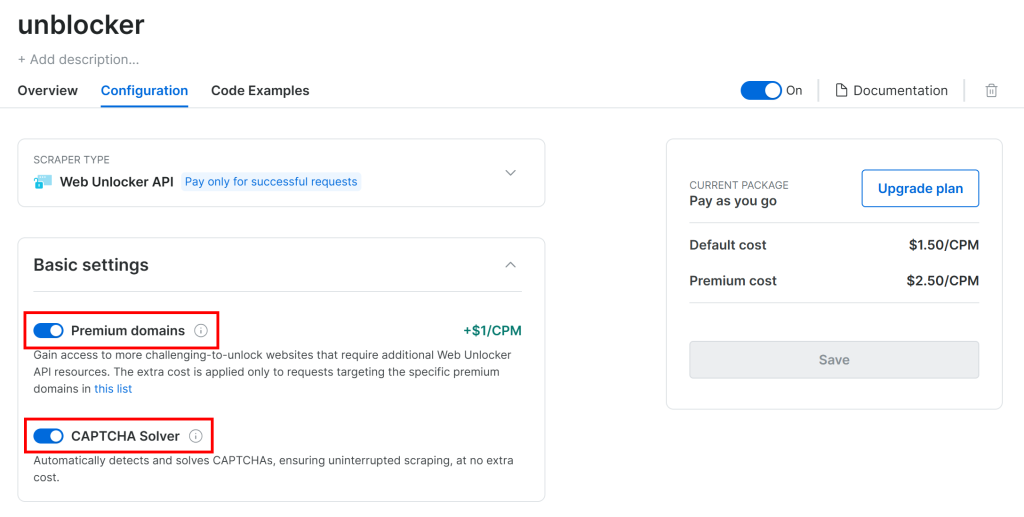
Ici, activez l’API Web Unlocker en cliquant sur la case à cocher :

G2 est protégé par des défenses anti-bots avancées, y compris des CAPTCHAs. Vérifiez donc que les deux options suivantes sont activées sur la page “Configuration” :
Crawl4AI fonctionne en naviguant dans les pages d’un navigateur contrôlé. Sous le capot, il s’appuie sur la fonction goto() de Playwright, qui envoie une requête HTTP GET à la page web cible. En revanche, l’API Web Unlocker fonctionne par le biais de requêtes POST.
Ce n’est pas un problème car vous pouvez toujours utiliser l’API Web Unlocker avec Crawl4AI en la configurant comme un proxy. Cela permet au navigateur de Crawl4AI d’envoyer des requêtes via le produit de Bright Data et de recevoir en retour des pages HTML non bloquées.
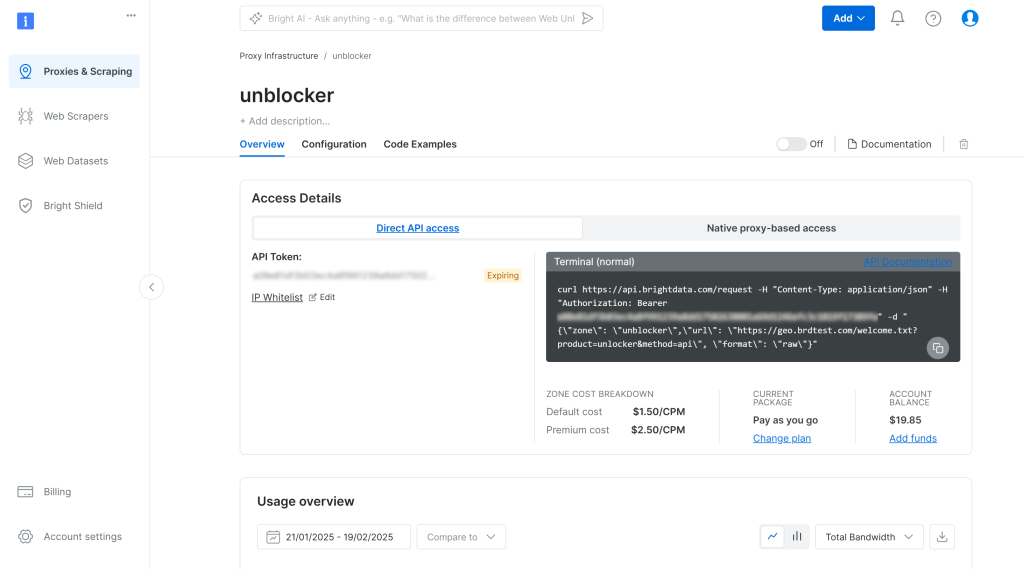
Pour accéder aux informations d’identification de votre proxy Web Unlocker API, accédez à l’onglet “Native proxy-based access” (accès par proxy natif) de la page “Overview” (aperçu) :
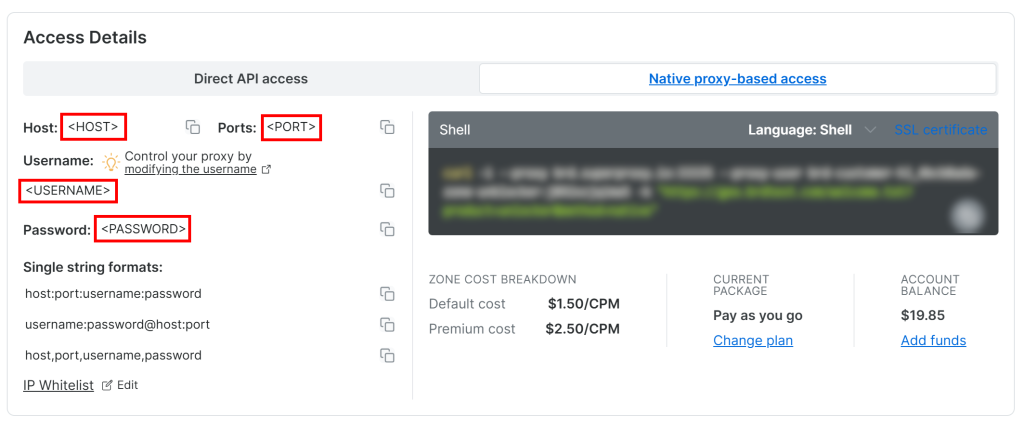
Copiez les informations d’identification suivantes de la page :
<HOST><PORT><USERNAME><MOT DE PASSE>
Ensuite, utilisez-les pour remplir votre fichier .env avec ces variables d’environnement :
PROXY_SERVER=https://<HOST>:<PORT>
PROXY_USERNAME=<USERNAME>
PROXY_PASSWORD=<PASSWORD>Fantastique ! Web Unlocker est maintenant prêt à être intégré à Crawl4AI.
Étape 7 : Intégrer l’API de Web Unlocker
BrowserConfig prend en charge l’intégration de proxy par le biais de l’objet proxy_config. Pour intégrer l’API Web Unlocker avec Crawl4AI, remplissez cet objet avec les variables d’environnement de votre fichier .env et passez-le au constructeur de BrowserConfig:
# Bright Data's Web Unlocker API proxy configuration
proxy_config = {
"server": os.getenv("PROXY_SERVER"),
"username": os.getenv("PROXY_USERNAME"),
"password": os.getenv("PROXY_PASSWORD")
}
# Browser configuration
browser_config = BrowserConfig(
headless=True,
proxy_config=proxy_config,
)N’oubliez pas d’importer os de la bibliothèque standard de Python :
import osGardez à l’esprit que l’API Web Unlocker introduit une certaine surcharge temporelle due à la rotation de l’IP via le proxy et à la résolution éventuelle du CAPTCHA. Pour en tenir compte, vous devez
- Augmenter le délai de chargement de la page à 3 minutes
- Indiquer au robot d’exploration qu’il doit attendre que le DOM soit entièrement chargé avant de l’analyser.
Pour ce faire, utilisez la configuration CrawlerRunConfig suivante :
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded", # wait until the DOM of the page has been loaded
page_timeout=180000, # wait up to 3 mins for page load
)Notez que même l’API de Web Unlocker n’est pas sans faille lorsqu’il s’agit de sites complexes comme G2. Dans de rares cas, l’API de scraping peut ne pas réussir à récupérer la page débloquée, ce qui entraîne la fin du script avec l’erreur suivante :
Error: Failed on navigating ACS-GOTO:
Page.goto: net::ERR_HTTP_RESPONSE_CODE_FAILURE at https://www.g2.com/products/bright-data/reviewsRassurez-vous, vous n’êtes facturé que pour les demandes qui aboutissent. Il n’est donc pas nécessaire de relancer le script jusqu’à ce qu’il fonctionne. Dans le cas d’un script de production, envisagez de mettre en œuvre une logique de relance automatique.
Si la demande aboutit, vous recevrez un message comme celui-ci :
Response status code: 200
Parsed Markdown data:
* [Home](https://www.g2.com/products/bright-data/</>)
* [Write a Review](https://www.g2.com/products/bright-data/</wizard/new-review>)
* Browse
* [Top Categories](https://www.g2.com/products/bright-data/<#>)
Top Categories
* [AI Chatbots Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/ai-chatbots>)
* [CRM Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/crm>)
* [Project Management Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/project-management>)
* [Expense Management Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/expense-management>)
* [Video Conferencing Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/video-conferencing>)
* [Online Backup Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/online-backup>)
* [E-Commerce Platforms](https://www.g2.com/products/brigC’est formidable ! Cette fois, G2 a répondu avec un code de statut 200 OK. Cela signifie que la requête n’a pas été bloquée et que Crawl4AI a pu analyser le HTML en Markdown comme prévu.
Étape 8 : Configuration de Groq
GroqCloud est l’un des rares fournisseurs à prendre en charge les modèles d’IA DeepSeek via des API compatibles avec OpenAI, même dans le cadre d’un plan gratuit. Il s’agit donc de la plateforme utilisée pour l’intégration de LLM dans Crawl4AI.
Si vous n’avez pas encore de compte Groq, créez-en un. Sinon, connectez-vous simplement. Dans votre tableau de bord d’utilisateur, naviguez vers “API Keys” dans le menu de gauche et cliquez sur le bouton “Create API Key” :
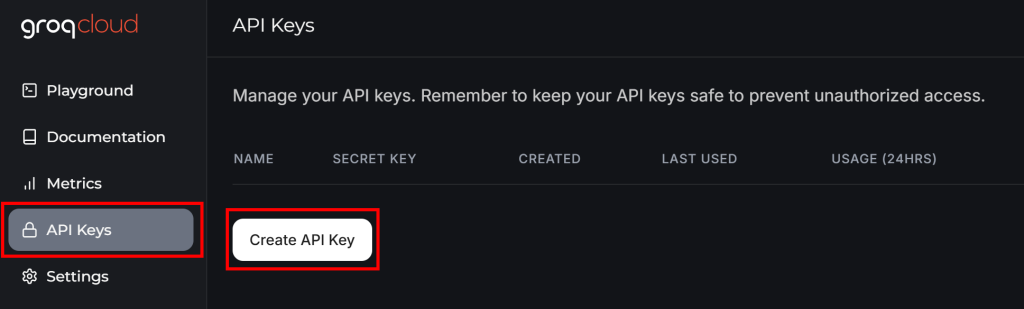
Une fenêtre contextuelle s’affiche :
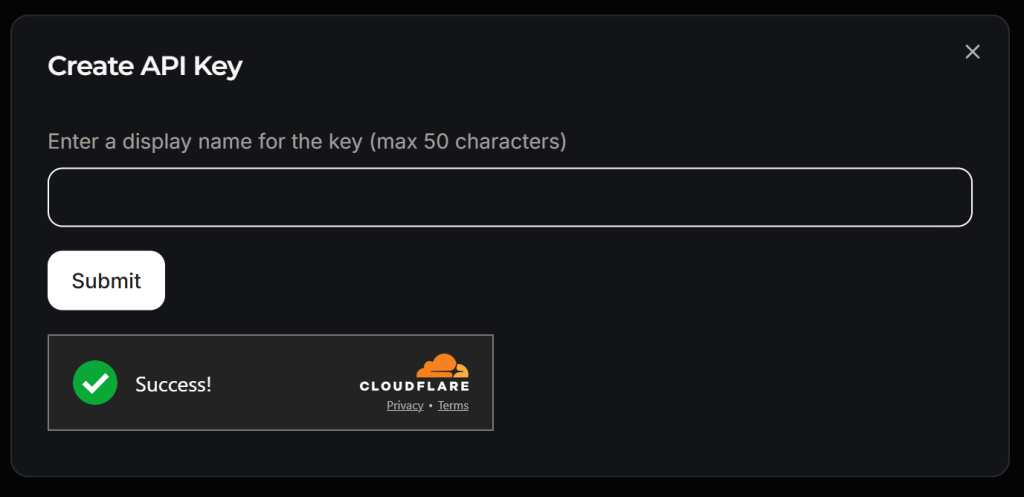
Donnez un nom à votre clé API (par exemple, “Crawl4AI Scraping”) et attendez la vérification anti-bot par Cloudflare. Cliquez ensuite sur “Soumettre” pour générer votre clé API :
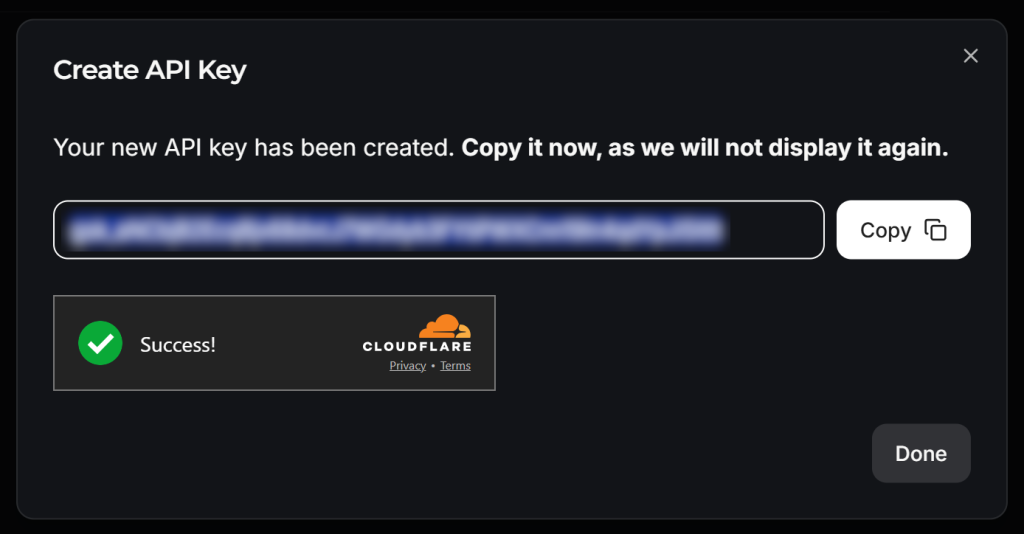
Copiez la clé API et ajoutez-la à votre fichier .env comme ci-dessous :
LLM_API_TOKEN=<YOUR_GROK_API_KEY>Remplacer par la clé API fournie par Groq.
C’est beau ! Vous êtes prêt à utiliser DeepSeek pour le scraping LLM avec Crawl4AI.
Étape 9 : Définir un schéma pour les données récupérées
Crawl4AI effectue du scraping LLM en suivant une approche basée sur des schémas. Dans ce contexte, un schéma est une structure de données JSON qui définit :
- Sélecteur de base qui identifie l’élément “conteneur” de la page (par exemple, une rangée de produits, une carte d’article de blog).
- Champs spécifiant les sélecteurs CSS/XPath pour capturer chaque donnée (par exemple, texte, attribut, bloc HTML).
- Types imbriqués ou de listes pour les structures répétées ou hiérarchiques.
Pour définir le schéma, vous devez d’abord identifier les données que vous souhaitez extraire de la page cible. Pour ce faire, ouvrez la page cible en mode incognito dans votre navigateur :
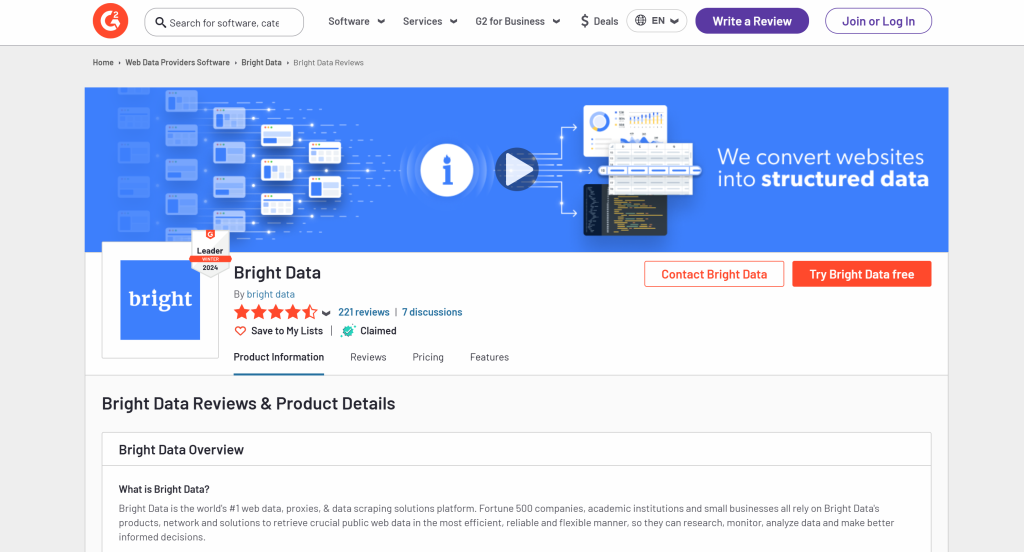
Dans ce cas, supposons que vous soyez intéressé par les domaines suivants :
name: le nom du produit ou de l’entreprise.image_url: L’URL de l’image du produit ou de l’entreprise.description: Une brève description du produit/de l’entreprise.review_score: La note moyenne de l’évaluation du produit/de l’entreprise.number_of_reviews: Le nombre total d’évaluations.revendiqué: Un booléen indiquant si le profil de l’entreprise est revendiqué par son propriétaire.
Maintenant, dans le dossier models, créez un fichier g2_product.py et remplissez-le avec une classe de schéma basée sur Pydantic appelée G2Product comme suit :
# ./models/g2_product.py
from pydantic import BaseModel
class G2Product(BaseModel):
"""
Represents the data structure of a G2 product/company page.
"""
name: str
image_url: str
description: str
review_score: str
number_of_reviews: str
claimed: boolOui ! Le processus de raclage LLM effectué par DeepSeek renverra des objets suivant le schéma ci-dessus.
Étape n° 10 : Préparer l’intégration de DeepSeek
Avant de terminer l’intégration de DeepSeek avec Crawl4AI, consultez la page “Settings > Limits” dans votre compte GroqCloud :
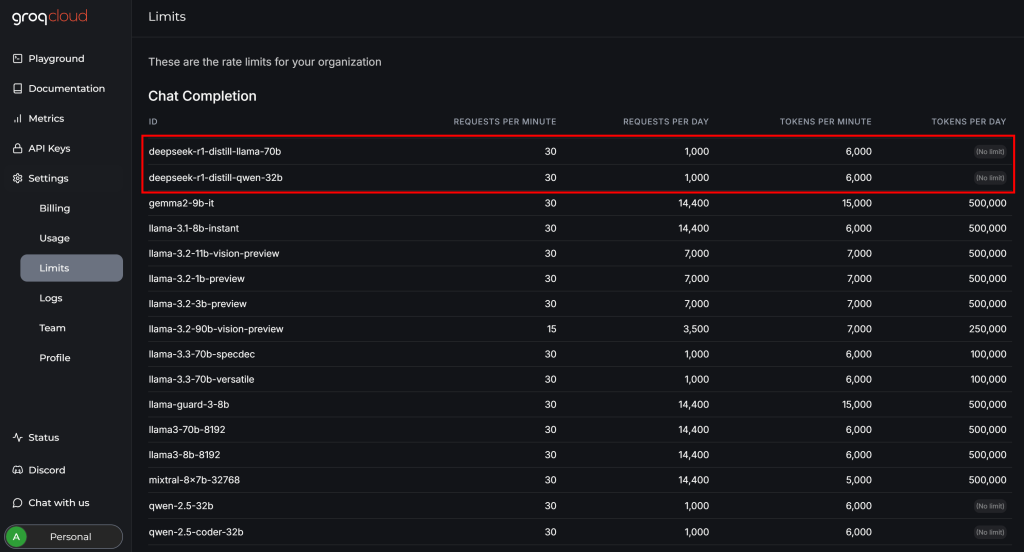
Vous y verrez que les deux modèles de DeepSeek disponibles présentent les limitations suivantes dans le cadre du plan gratuit :
- Jusqu’à 30 demandes par minute
- Jusqu’à 1 000 demandes par jour
- Pas plus de 6 000 jetons par minute
Si les deux premières restrictions ne posent pas de problème pour cet exemple, la dernière pose un problème. Une page web typique peut contenir des millions de caractères, ce qui se traduit par des centaines de milliers de jetons.
En d’autres termes, vous ne pouvez pas introduire l’intégralité de la page G2 directement dans les modèles DeepSeek via Groq en raison des limites de jetons. Pour résoudre ce problème, Crawl4AI vous permet de sélectionner uniquement des sections spécifiques de la page. Ces sections – et non la page entière – seront converties en Markdown et transmises au LLM. Le processus de sélection des sections repose sur les sélecteurs CSS.
Pour déterminer les sections à sélectionner, ouvrez la page cible dans votre navigateur. Cliquez avec le bouton droit de la souris sur les éléments contenant les données qui vous intéressent et sélectionnez l’option “Inspecter” :
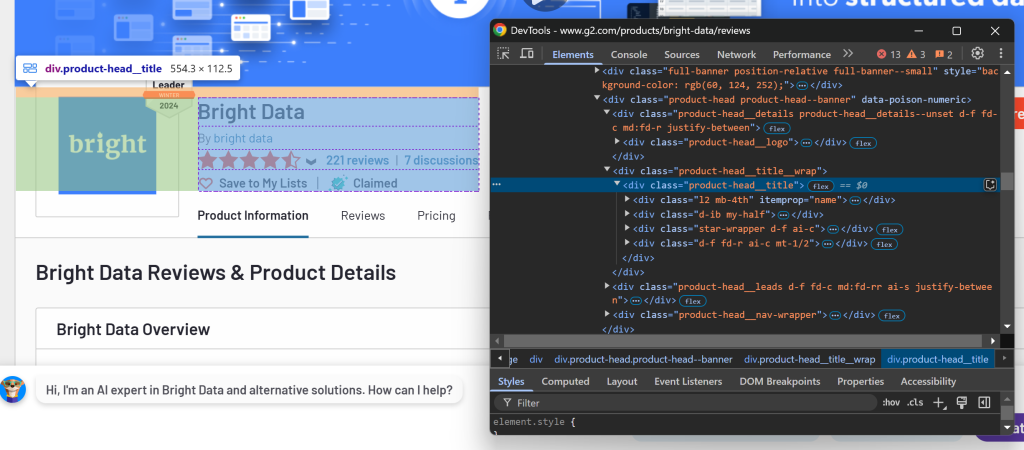
Ici, vous pouvez remarquer que l’élément .product-head__title contient le nom du produit/de la société, le score de l’avis, le nombre d’avis et l’état de la réclamation.
Inspectez maintenant la section du logo :
Vous pouvez récupérer ces informations à l’aide du sélecteur CSS .product-head__logo.
Enfin, vérifiez la section de description :
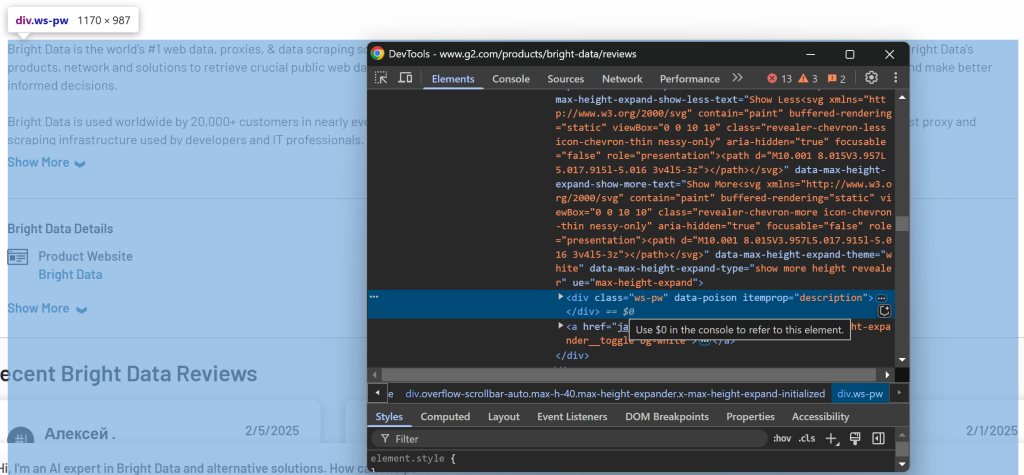
La description est disponible en utilisant le sélecteur [itemprop="description"].
Configurez ces sélecteurs CSS dans CrawlerRunConfig comme suit :
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded",
page_timeout=180000,
css_selector=".product-head__title, .product-head__logo, [itemprop="description"]", # the CSS selectors of the elements to extract data from
)Si vous exécutez à nouveau scraper.py, vous obtiendrez quelque chose comme :
Response status code: 200
Parsed Markdown data:
[](https:/www.g2.com/products/bright-data/reviews)
[Editedit](https:/my.g2.com/bright-data/product_information)
[Bright Data](https:/www.g2.com/products/bright-data/reviews)
By [bright data](https:/www.g2.com/sellers/bright-data)
Show rating breakdown
4.7 out of 5 stars
[5 star78%](https:/www.g2.com/products/bright-data/reviews?filters%5Bnps_score%5D%5B%5D=5#reviews)
[4 star19%](https:/www.g2.cLa sortie ne comprend que les sections pertinentes au lieu de la page HTML entière. Cette approche réduit considérablement l’utilisation des jetons, ce qui vous permet de rester dans les limites du niveau libre de Groq tout en extrayant efficacement les données qui vous intéressent !
Étape #11 : Définir la stratégie d’extraction LLM basée sur DeepSeek
Craw4AI prend en charge l’extraction de données basée sur LLM grâce à l’objet LLMExtractionStrategy. Vous pouvez en définir une pour l’intégration de DeepSeek comme suit :
extraction_strategy = LLMExtractionStrategy(
provider=os.getenv("LLM_MODEL"),
api_token=os.getenv("LLM_API_TOKEN"),
schema=G2Product.model_json_schema(),
extraction_type="schema",
instruction=(
"Extract the 'name', 'description', 'image_url', 'review_score', and 'number_of_reviews' "
"from the content below. "
"'review_score' must be in "x/5" format. Get the entire description, not just the first few sentences."
),
input_format="markdown",
verbose=True
)Pour spécifier le modèle LLM, ajoutez la variable d’environnement suivante au fichier .env :
LLM_MODEL=groq/deepseek-r1-distill-llama-70bCela indique à Craw4AI d’utiliser le modèle deepseek-r1-distill-llama-70b de GroqCloud pour l’extraction de données basée sur LLM.
Dans scraper.py, importer LLMExtractionStrategy et G2Product:
from crawl4ai.extraction_strategy import LLMExtractionStrategy
from models.g2_product import G2ProductPassez ensuite l’objet extraction_strategy à crawler_config:
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded",
page_timeout=180000, # 3 mins
css_selector=".product-head__title, .product-head__logo, [itemprop="description"]",
extraction_strategy=extraction_strategy
)Lorsque vous exécutez le script, Craw4AI :
- Connectez-vous à la page web cible via le proxy API de Web Unlocker.
- Récupère le contenu HTML de la page et filtre les éléments à l’aide des sélecteurs CSS spécifiés.
- Convertit les éléments HTML sélectionnés au format Markdown.
- Envoyer le format Markdown à DeepSeek pour l’extraction des données.
- Indiquer à DeepSeek de traiter l’entrée en fonction de l’invite
(instruction) fournie et de renvoyer les données extraites.
Après avoir exécuté crawler.arun(), vous pouvez vérifier l’utilisation des jetons avec :
print(extraction_strategy.show_usage())Vous pouvez ensuite accéder aux données extraites et les imprimer avec :
result_raw_data = result.extracted_content
print(result_raw_data)Si vous exécutez le script et imprimez les résultats, vous devriez obtenir une sortie comme celle-ci :
=== Token Usage Summary ===
Type Count
------------------------------
Completion 525
Prompt 2,002
Total 2,527
=== Usage History ===
Request # Completion Prompt Total
------------------------------------------------
1 525 2,002 2,527
None
[
{
"name": "Bright Data",
"image_url": "https://images.g2crowd.com/uploads/product/image/large_detail/large_detail_9d7645872b9abb68923fb7e2c07c9d834/bright-data.png",
"description": "Bright Data is the world's #1 web data, proxies, & data scraping solutions platform. Fortune 500 companies, academic institutions and small businesses all rely on Bright Data's products, network and solutions to retrieve crucial public web data in the most efficient, reliable and flexible manner, so they can research, monitor, analyze data and make better informed decisions. Bright Data is used worldwide by 20,000+ customers in nearly every industry. Its products range from no-code data solutions utilized by business owners, to a robust proxy and scraping infrastructure used by developers and IT professionals. Bright Data products stand out because they provide a cost-effective way to perform fast and stable public web data collection at scale, effortless conversion of unstructured data into structured data and superior customer experience, while being fully transparent and compliant.",
"review_score": "4.7/5",
"number_of_reviews": "221",
"claimed": true
}
]La première partie de la sortie (utilisation des jetons) provient de show_usage(), confirmant que nous sommes bien en dessous de la limite des 6 000 jetons. Les données résultantes suivantes sont une chaîne JSON correspondant au schéma G2Product.
Tout simplement incroyable !
Étape n° 12 : Traiter les données des résultats
Comme vous pouvez le voir dans le résultat de l’étape précédente, DeepSeek renvoie généralement un tableau au lieu d’un objet unique. Pour gérer cela, analyser les données retournées en JSON et extraire le premier élément du tableau :
# Parse the extracted data from JSON
result_data = json.loads(result.extracted_content)
# If the returned data is an array, access its first element
if result_data:
result_data = result_data[0]N’oubliez pas d’importer json de la bibliothèque standard de Python :
import jsonÀ ce stade, result_data doit être une instance de G2Product. La dernière étape consiste à exporter ces données vers un fichier JSON.
Étape #13 : Exporter les données scrapées en JSON
Utilisez json pour exporter les données de résultat dans un fichier g2.json :
with open("g2.json", "w", encoding="utf-8") as f:
json.dump(result_data, f, indent=4)Mission accomplie !
Étape n° 14 : Assembler le tout
Votre fichier scraper.py final devrait contenir :
import asyncio
from dotenv import load_dotenv
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
import os
from crawl4ai.extraction_strategy import LLMExtractionStrategy
from models.g2_product import G2Product
import json
# Load secrets from .env file
load_dotenv()
async def main():
# Bright Data's Web Unlocker API proxy configuration
proxy_config = {
"server": os.getenv("PROXY_SERVER"),
"username": os.getenv("PROXY_USERNAME"),
"password": os.getenv("PROXY_PASSWORD")
}
# Browser configuration
browser_config = BrowserConfig(
headless=True,
proxy_config=proxy_config,
)
# LLM extraction strategy for data extraction using DeepSeek
extraction_strategy = LLMExtractionStrategy(
provider=os.getenv("LLM_MODEL"),
api_token=os.getenv("LLM_API_TOKEN"),
schema=G2Product.model_json_schema(),
extraction_type="schema",
instruction=(
"Extract the 'name', 'description', 'image_url', 'review_score', and 'number_of_reviews' "
"from the content below. "
"'review_score' must be in "x/5" format. Get the entire description, not just the first few sentences."
),
input_format="markdown",
verbose=True
)
# Crawler configuration
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded",
page_timeout=180000, # 3 mins
css_selector=".product-head__title, .product-head__logo, [itemprop="description"]",
extraction_strategy=extraction_strategy
)
# Run the AI-powered crawler
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://www.g2.com/products/bright-data/reviews",
config=crawler_config
)
# Log the AI model usage info
print(extraction_strategy.show_usage())
# Parse the extracted data from JSON
result_data = json.loads(result.extracted_content)
# If the returned data is an array, access its first element
if result_data:
result_data = result_data[0]
# Export the scraped data to JSON
with open("g2.json", "w", encoding="utf-8") as f:
json.dump(result_data, f, indent=4)
if __name__ == "__main__":
asyncio.run(main())Ensuite, models/g2_product.py stockera :
from pydantic import BaseModel
class G2Product(BaseModel):
"""
Represents the data structure of a G2 product/company page.
"""
name: str
image_url: str
description: str
review_score: str
number_of_reviews: str
claimed: boolEt .env aura :
PROXY_SERVER=https://<WEB_UNLOCKER_API_HOST>:<WEB_UNLOCKER_API_PORT>
PROXY_USERNAME=<WEB_UNLOCKER_API_USERNAME>
PROXY_PASSWORD=<WEB_UNLOCKER_API_PASSWORD>
LLM_API_TOKEN=<GROQ_API_KEY>
LLM_MODEL=groq/deepseek-r1-distill-llama-70bLancez votre DeepSeek Crawl4AI scraper avec :
python scraper.pyLa sortie dans le terminal sera quelque chose comme ceci :
[INIT].... → Crawl4AI 0.4.248
[FETCH]... ↓ https://www.g2.com/products/bright-data/reviews... | Status: True | Time: 56.13s
[SCRAPE].. ◆ Processed https://www.g2.com/products/bright-data/reviews... | Time: 397ms
[LOG] Call LLM for https://www.g2.com/products/bright-data/reviews - block index: 0
[LOG] Extracted 1 blocks from URL: https://www.g2.com/products/bright-data/reviews block index: 0
[EXTRACT]. ■ Completed for https://www.g2.com/products/bright-data/reviews... | Time: 12.273853100006818s
[COMPLETE] ● https://www.g2.com/products/bright-data/reviews... | Status: True | Total: 68.81s
=== Token Usage Summary ===
Type Count
------------------------------
Completion 524
Prompt 2,002
Total 2,526
=== Usage History ===
Request # Completion Prompt Total
------------------------------------------------
1 524 2,002 2,526
NoneDe plus, un fichier g2.json apparaîtra dans le dossier de votre projet. Ouvrez-le et vous verrez :
{
"name": "Bright Data",
"image_url": "https://images.g2crowd.com/uploads/product/image/large_detail/large_detail_9d7645872b9abb68923fb7e2c7c9d834/bright-data.png",
"description": "Bright Data is the world's #1 web data, proxies, & data scraping solutions platform. Fortune 500 companies, academic institutions and small businesses all rely on Bright Data's products, network and solutions to retrieve crucial public web data in the most efficient, reliable and flexible manner, so they can research, monitor, analyze data and make better informed decisions. Bright Data is used worldwide by 20,000+ customers in nearly every industry. Its products range from no-code data solutions utilized by business owners, to a robust proxy and scraping infrastructure used by developers and IT professionals. Bright Data products stand out because they provide a cost-effective way to perform fast and stable public web data collection at scale, effortless conversion of unstructured data into structured data and superior customer experience, while being fully transparent and compliant.",
"review_score": "4.7/5",
"number_of_reviews": "221",
"claimed": true
}Félicitations ! Vous êtes parti d’une page G2 protégée par un bot et avez utilisé Crawl4AI, DeepSeek et l’API Web Unlocker pour en extraire des données structurées, sans écrire une seule ligne de logique d’analyse.
Conclusion
Dans ce tutoriel, vous avez exploré ce qu’est Crawl4AI et comment l’utiliser en combinaison avec DeepSeek pour construire un scraper alimenté par l’IA. L’un des principaux défis du scraping est le risque d’être bloqué, mais il a été surmonté grâce à l’API Web Unlocker de Bright Data.
Comme le montre ce tutoriel, en combinant Crawl4AI, DeepSeek et l’API Web Unlocker, vous pouvez extraire des données de n’importe quel site, même ceux qui sont plus protégés, comme G2, sans avoir besoin d’une logique d’analyse spécifique. Ce n’est qu’un des nombreux scénarios pris en charge par les produits et services de Bright Data, qui vous aident à mettre en œuvre un scraping web efficace piloté par l’IA.
Découvrez nos autres outils de scraping web qui s’intègrent à Crawl4AI :
- Services Proxy: 4 types de proxy différents pour contourner les restrictions de localisation, y compris plus de 400M+ monthly d’adresses IP résidentielles.
- API de grattage Web: Points d’extrémité dédiés à l’extraction de données web fraîches et structurées à partir de plus de 100 domaines populaires.
- API SERP: API pour gérer toutes les opérations de déverrouillage en cours pour les SERP et extraire une page.
- Navigateur de scraping: Navigateur compatible avec Puppeteer, Selenium et Playwright avec activités de déverrouillage intégrées.
Inscrivez-vous dès maintenant à Bright Data et testez gratuitement nos services de proxy et nos produits de scraping !





