Le scraping web traditionnel implique souvent l’écriture de codes complexes et chronophages, adaptés à la mise en page spécifique de chaque site web, qui peuvent facilement être perturbés lorsque les sites changent. ScrapeGraphAI utilise des modèles linguistiques à grande échelle (LLM) pour extraire des informations et les interpréter comme le ferait un humain, vous permettant ainsi de vous concentrer sur les données plutôt que sur la mise en page. L’intégration des LLM à ScrapeGraphAI améliore l’extraction des données, automatise l’agrégation de contenu et permet une analyse en temps réel.
Dans cet article, vous apprendrez à utiliser ScrapeGraphAI pour le Scraping web. Mais avant cela, laissez-nous vous présenter les solutions de Bright Data qui peuvent vous faire gagner du temps et de l’argent.
Solutions de Scraping web de Bright Data
Bright Data propose une suite complète de solutions de Scraping web, optimisées pour une extraction de données efficace, évolutive et conforme :
- API Web Scraper
- Jeux de données prêts à l’emploi
- Jeux de données personnalisés
Ces solutions permettent une collecte de données rapide, précise et évolutive, parfaite pour les projets de toute envergure, des applications à petite échelle aux besoins des entreprises.
Mise en œuvre du Scraping web LLM avec ScrapeGraphAI
Avant de commencer ce tutoriel, vous devez remplir les conditions préalables suivantes :
- Python 3.x installé.
- Un compteOpe nAI. Ce tutoriel utilise les LLM OpenAI pour extraire des données avec ScrapeGraphAI. Bien qu’il soit possible d’utiliser d’autres modèles, tels que Anthropic, Google ou des modèles open source, comme Llama et Mistral AI, ce tutoriel utilise GPT-4 en raison de sa popularité et de sa facilité de configuration.
Si vous n’êtes pas familier avec le Scraping web en Python, consultez ce tutoriel sur le Scraping web pour commencer.
Configurez votre environnement
La première chose à faire est de créer un environnement virtuel. Ouvrez votre terminal et accédez au répertoire de votre projet :
python -m venv venv
Activez ensuite l’environnement virtuel. Sous macOS et Linux, vous pouvez le faire à l’aide de la commande suivante :
source venv/bin/activate
Sous Windows, vous pouvez utiliser cette commande :
venvScriptsactivate
Une fois l’environnement virtuel activé, vous devez installer ScrapeGraphAI et ses dépendances :
pip install scrapegraphai
playwright install
La commande playwright install configure les navigateurs nécessaires pour Chromium, Firefox et WebKit.
Pour gérer les variables d’environnement en toute sécurité, installez python-dotenv:
pip install python-dotenv
Il est important de protéger les informations sensibles, telles que les clés API. Il est recommandé de stocker les variables d’environnement dans un fichier .env afin de les séparer des fichiers de code.
Créez un nouveau fichier nommé .env dans le répertoire du projet et ajoutez la ligne suivante en spécifiant votre clé OpenAI :
OPENAI_API_KEY="votre-clé-API-openai"
Ce fichier ne doit pas être enregistré dans des systèmes de contrôle de version tels que Git. Pour éviter cela, ajoutez .env à votre fichier .gitignore.
Récupérer des données avec ScrapeGraphAI
Dans ce tutoriel, vous commencerez par extraire des données de produits à partir de Books to Scrape, un site web de démonstration spécialement conçu pour s’entraîner aux techniques de Scraping web. Ce site web imite une librairie en ligne, proposant une variété de livres de différents genres, avec leurs prix, leurs notes et leur disponibilité :
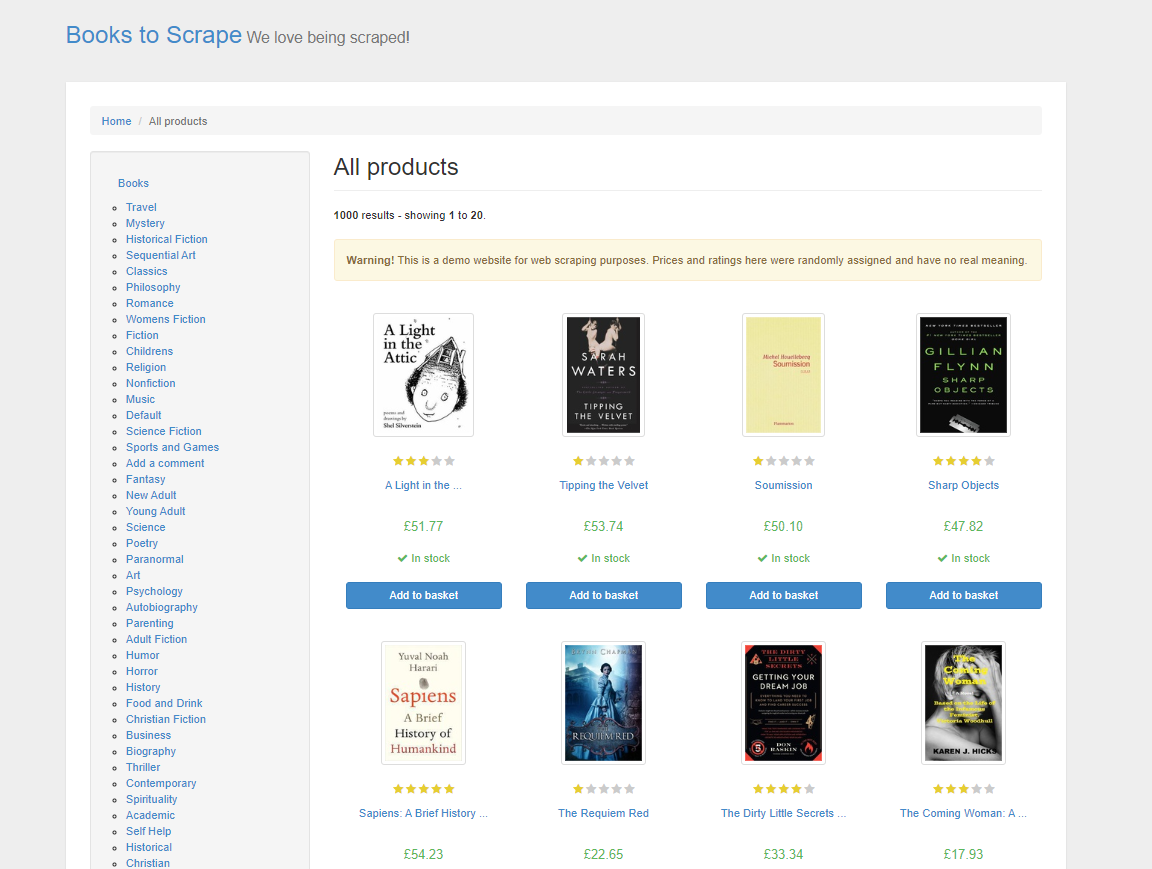
Dans le Scraping web HTML traditionnel, vous devriez analyser le code HTML de la page, inspecter manuellement les éléments et les balises pour localiser les données que vous souhaitez. Ce processus prend beaucoup de temps et nécessite une solide compréhension des structures web. Avec ScrapeGraphAI, il vous suffit de spécifier les données que vous souhaitez à l’aide d’une invite, et le LLM est suffisamment intelligent pour les extraire.
ScrapeGraphAI propose différents types de graphiques pour différents besoins de scraping. Ces graphiques définissent la structure du processus de scraping et son objectif. Voici un bref aperçu de certains de ces graphiques :
- SmartScraperGraph est un Scraper d’une seule page où vous fournissez une invite et une URL ou un fichier local. Il utilise un LLM pour extraire les informations que vous spécifiez.
- SearchGraph est un Scraper multipages qui extrait des informations à partir des résultats des moteurs de recherche en fonction de votre invite.
- SpeechGraph étend SmartScraperGraph en ajoutant une fonctionnalité de synthèse vocale, générant un fichier audio du contenu extrait.
- ScriptCreatorGraph prend une invite et une URL et, au lieu de générer des résultats, produit un script Python capable de scraper l’URL donnée.
Si ces graphes ne correspondent pas exactement à vos besoins, ScrapeGraphAI vous permet également de créer des graphes personnalisés en combinant différents nœuds et en adaptant le processus de scraping à vos exigences spécifiques.
En plus de choisir le bon type de graphique, vous devez également configurer correctement votre Scraper, en particulier en ce qui concerne la sélection de la requête et du modèle. La requête guide le LLM dans la compréhension exacte des données à extraire. Veillez à ce qu’elle soit claire et explicite. De plus, le choix du bon modèle LLM détermine la qualité du traitement et de l’interprétation du contenu du site web par le Scraper. Vous pouvez également configurer d’autres options telles que les Proxy pour garantir un scraping plus fluide du contenu géorestreint et le mode headless pour que le processus reste efficace et rapide. Une configuration adéquate détermine en fin de compte la précision et la pertinence des données scrapées.
Écrire le code du Scraper
Pour écrire le code du Scraper, créez un nouveau fichier nommé app.py et ajoutez-y les lignes de code suivantes :
from dotenv import load_dotenv
import os
from scrapegraphai.graphs import SmartScraperGraph
# Charger les variables d'environnement à partir du fichier .env
load_dotenv()
# Accéder à la clé API OpenAI
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
# Configuration pour ScrapeGraphAI
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "openai/gpt-4o-mini",
}
}
# Définir l'invite et la source
prompt = "Extraire le titre, le prix et la disponibilité de tous les livres sur cette page."
source = "http://books.toscrape.com/"
# Créer le graphique du Scraper
smart_scraper_graph = SmartScraperGraph(
prompt=prompt,
source=source,
config=graph_config)
# Exécuter le Scraper
result = smart_scraper_graph.run()
# Afficher les résultats
print(result)
Ce code importe des modules essentiels tels que os et dotenv pour gérer les variables d’environnement, ainsi que la classe SmartScraperGraph de ScrapeGraphAI, qui est utilisée pour le scraping. Il charge ensuite les variables d’environnement via dotenv afin de sécuriser les données sensibles telles que les clés API. Ensuite, le code crée une configuration LLM pour le scraping, en spécifiant le modèle à utiliser et la clé API. Cette configuration, ainsi que l’URL du site et l’invite de scraping, sont utilisées pour définir votre SmartScraperGraph, qui est exécuté à l’aide de la méthode run(), déclenchant le processus de collecte des données spécifiées.
Pour exécuter ce code, ouvrez votre terminal et exécutez python app.py. Votre résultat devrait ressembler à ceci :
{
"books": [
{
"title": "A Light in the Attic",
"price": "£51.77",
"availability": "In stock"
},
{
"title": "Tipping the Velvet",
"price": "£53.74",
"availability": "In stock"
}, ...
]
}
Remarque : si vous rencontrez des problèmes lors de l’exécution du code, vous devrez peut-être installer manuellement le package
grpcio, qui est une dépendance sous-jacente de ScrapeGraphAI. Pour ce faire, utilisez la commande suivante :
pip install grpcio
Bien que ScrapeGraphAI facilite l’extraction des données lors du Scraping web, il existe encore certains défis courants, tels que les CAPTCHA et les blocages d’IP, que vous devez savoir gérer.
Pour imiter le comportement de navigation, vous pouvez implémenter des délais dans votre code. Vous pouvez également utiliser des Proxy rotatifs pour éviter la détection. De plus, des services de Résolution de CAPTCHA tels que le solveur de CAPTCHA de Bright Data ou Anti Captcha peuvent être intégrés à votre Scraper afin de résoudre automatiquement les CAPTCHAs à votre place.
Remarque : veillez à toujours respecter les conditions d’utilisation d’un site web. Le scraping à des fins personnelles est souvent acceptable, mais la redistribution des données peut avoir des implications juridiques.
Utilisation de Proxys avec ScrapeGraphAI
ScrapeGraphAI vous permet de configurer un service Proxy pour éviter le blocage d’IP et accéder à du contenu soumis à des restrictions géographiques. Vous pouvez utiliser un service Proxy gratuit ou configurer votre propre serveur Proxy personnalisé.
Pour utiliser un service Proxy gratuit, ajoutez ce qui suit à votre graph_config:
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "openai/gpt-4o-mini",
},
"loader_kwargs": {
"Proxy": {
"server": "broker",
"criteria": {
"anonymous": True,
"secure": True,
"countryset": {"US"},
"timeout": 10.0,
"max_tries": 3
},
},
}
}
Cette configuration indique à ScrapeGraphAI d’utiliser un service Proxy gratuit qui correspond à vos critères.
Pour utiliser un Proxy personnalisé provenant d’un fournisseur tel que Bright Data, modifiez votre graph_config comme suit, en insérant l’URL de votre serveur, votre nom d’utilisateur et votre mot de passe :
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "openai/gpt-4o-mini",
},
"loader_kwargs": {
"Proxy": {
"server": "http://your_proxy_server:port",
"username": "your_username",
"password": "your_password",
},
}
}
L’utilisation d’un serveur Proxy personnalisé offre plusieurs avantages, en particulier pour le Scraping web à grande échelle. Il vous permet de contrôler l’emplacement du Proxy, ce qui vous permet de scraper du contenu soumis à des restrictions géographiques. De plus, les Proxy personnalisés sont plus fiables et plus sûrs que les Proxy gratuits, ce qui réduit les risques de blocage de votre IP ou de limitation de débit.
Nettoyer et préparer les données
Après avoir scrapé les données, vous devez les nettoyer et les prétraiter, en particulier si vous prévoyez de les intégrer dans un modèle d’IA. Le nettoyage des données garantit que vos modèles apprennent à partir d’informations précises et cohérentes, ce qui a un impact direct sur leurs performances et leur fiabilité. Le nettoyage des données implique généralement de traiter les valeurs manquantes, de corriger les types de données, de normaliser le texte et de supprimer les doublons.
Voici un exemple de la manière dont vous pouvez nettoyer les données que vous avez récupérées précédemment à l’aide de pandas:
import pandas as pd
# Convertir le résultat en DataFrame
df = pd.DataFrame(result["books"])
# Supprimer les symboles monétaires et convertir les prix en flottants
df['price'] = df['price'].str.replace('£', '').astype(float)
# Normaliser le texte de disponibilité
df['availability'] = df['availability'].str.strip().str.lower()
# Traiter les valeurs manquantes, le cas échéant
df.dropna(inplace=True)
# Prévisualiser les données nettoyées
print(df.head())
Ce code nettoie les données en supprimant le symbole monétaire des prix des livres, normalise le statut de disponibilité en le convertissant en minuscules et traite les valeurs manquantes.
Avant d’exécuter le code, vous devez installer la bibliothèque pandas pour la manipulation des données :
pip install pandas
Pour exécuter le code, ouvrez votre terminal et exécutez python app.py. Votre résultat devrait ressembler à ceci :
titre prix disponibilité
0 A Light in the Attic 51,77 en stock
1 Tipping the Velvet 53,74 en stock
2 Soumission 50,10 en stock
3 Sharp Objects 47,82 en stock
4 Sapiens: A Brief History of Humankind 54,23 en stock
Il ne s’agit là que d’un exemple illustrant comment vous pouvez nettoyer les données récupérées. Le processus de nettoyage varie en fonction des données et du cas d’utilisation du LLM en cours de formation. Lorsque vous nettoyez vos données, vous vous assurez que vos modèles linguistiques reçoivent des entrées bien structurées et significatives. Si vous souhaitez en savoir plus sur la manière d’utiliser les données pour des projets d’IA, pensez aux données pour l’IA.
Tout le code de ce tutoriel est disponible dans ce dépôt GitHub.
Conclusion
ScrapeGraphAI utilise des LLM pour fournir une approche adaptative du Scraping web, s’adaptant aux changements dans les structures des sites web et extrayant les données de manière intelligente. Cependant, la mise à l’échelle du Scraping web s’accompagne de défis, tels que le blocage des adresses IP, la Résolution de CAPTCHA et le respect de la conformité légale.
Pour vous aider à surmonter ces défis, Bright Data propose une suite complète de solutions de Scraping web adaptées aux projets d’IA et d’apprentissage automatique. Celle-ci comprend les API Bright Data Web Scraper, des services Proxy et le Scraping sans serveur. En outre, Bright Data propose également des jeux de données prêts à l’emploi contenant des données pour l’IA provenant de plus d’une centaine de sites web populaires.
Commencez votre essai gratuit dès aujourd’hui !