

Dans ce tutoriel, vous découvrirez :
- La définition du scraping dans le domaine du commerce électronique et son utilité
- Les types d’outils de scraping e-commerce
- Les données que vous pouvez extraire des plateformes de commerce électronique
- Comment créer un script de scraping e-commerce avec Python
- Les défis liés au scraping des sites web de commerce électronique
C’est parti !
Qu’est-ce que le Scraping web pour les sites e-commerce ?
Le scraping web consiste à extraire des données de plateformes de vente en ligne telles qu’Amazon, Walmart, eBay et autres sites similaires. Bien qu’il soit possible de le faire en copiant manuellement les données, cette opération est généralement effectuée à l’aide d’outils ou de scripts automatisés.
Les données extraites des sites de commerce électronique peuvent aider les entreprises, les chercheurs et les développeurs à :
- Analyser les fluctuations des prix des produits
- Suivre les notes attribuées aux avis
- Identifier les tendances du marché
- Étudier la concurrence
Ces informations permettent une prise de décision éclairée et une planification stratégique.
Notez qu’un outil de collecte de données e-commerce est communément appelé « Scraper e-commerce ».
Types de scrapers e-commerce
Vous trouverez ci-dessous une liste des types d’outils de scraping e-commerce les plus populaires :
- Scripts personnalisés: scripts sur mesure permettant d’extraire des données spécifiques du commerce électronique à l’aide de langages de Scraping web tels que Python ou JavaScript.
- Scrapers sans code: outils conviviaux permettant l’extraction de données sans codage, idéaux pour les utilisateurs non techniciens. Découvrez les meilleurs Scrapers sans code.
- API de scraping web: interfaces qui fournissent des données e-commerce structurées par programmation, prenant souvent en charge l’extraction en temps réel ou à grande échelle.
- Extensions de scraping: modules complémentaires basés sur un navigateur qui simplifient la collecte de données directement à partir des pages web de commerce électronique lorsque vous les parcourez.
Dans cet article, nous nous concentrerons spécifiquement sur la création d’un bot de Scraping web e-commerce personnalisé.
Données à extraire des sites de commerce électronique
Les scrapers web de commerce électronique vous aident généralement à récupérer les données suivantes :
- Détails des produits: noms, descriptions, spécifications et images.
- Informations sur les prix: prix actuels, remises et historique des tendances des prix.
- Avis clients: notes, contenu des avis et commentaires des clients.
- Catégories et balises: classification et catégorisation des produits.
- Informations sur les vendeurs: noms, notes et coordonnées des vendeurs.
- Détails d’expédition: coûts, délais de livraison et politiques d’expédition.
- Disponibilité des stocks: niveaux de stock et notifications de rupture de stock.
- Données marketing: listes de produits, stratégies de prix, promotions et remises saisonnières.
Maintenant, apprenez à créer un Scraper Python pour le commerce électronique !
Comment créer un Scraper e-commerce
Pour créer manuellement un Scraper e-commerce, vous devez d’abord vous familiariser avec le site cible. Inspectez la page cible avec DevTools pour :
- Comprendre sa structure
- Déterminer les données que vous pouvez extraire
- Décider quelles bibliothèques de scraping utiliser
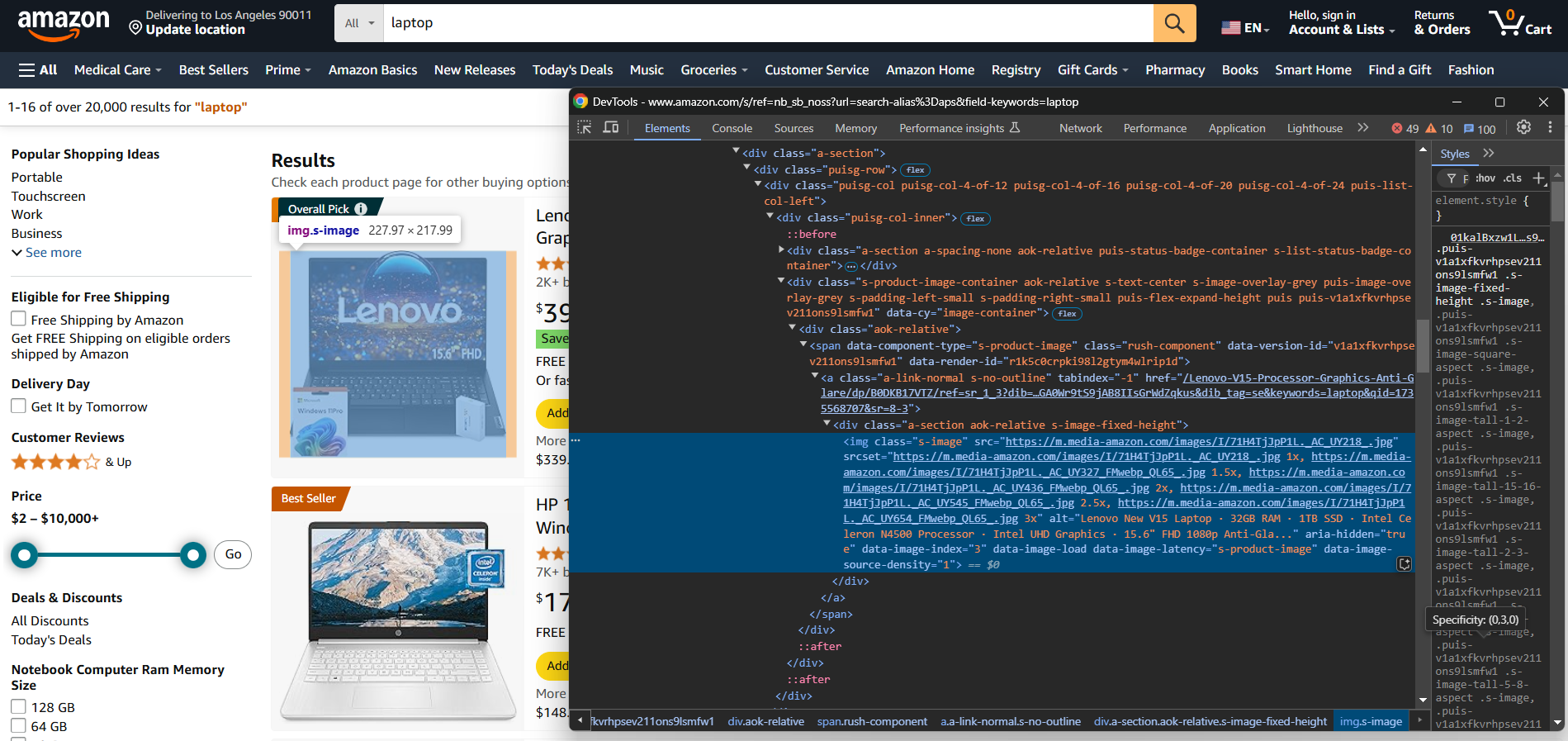
Pour les sites e-commerce plus simples, les deux bibliothèques Python suivantes suffisent :
- Requests: pour envoyer des requêtes HTTP. Elle vous aide à obtenir le contenu HTML brut d’une page web.
- Beautiful Soup: pour analyser les documents HTML et XML. Elle simplifie la navigation et l’extraction de données à partir de la structure HTML d’une page. Pour en savoir plus, consultez notre guide sur le scraping avec Beautiful Soup.
Vous pouvez les installer toutes les deux avec :
pip install requests beautifulsoup4
Pour les plateformes de commerce électronique qui chargent les données de manière dynamique ou qui dépendent fortement du rendu JavaScript, vous aurez besoin d’outils d’automatisation de navigateur tels que Selenium. Pour plus d’informations, consultez notre tutoriel sur le scraping avec Selenium.
Vous pouvez installer Selenium avec :
pip install selenium
Ensuite, le processus de Scraping web se déroule comme suit :
- Connectez-vous au site cible: Utilisez Requests ou Selenium pour récupérer et analyser le code HTML de la page.
- Sélectionnez les éléments qui vous intéressent: localisez des éléments spécifiques (par exemple, l’image du produit, le prix, la description) dans la structure HTML et sélectionnez-les à l’aide de sélecteurs CSS ou d’expressions XPath.
- Extrayez les données: extrayez les informations souhaitées de ces éléments HTML.
- Nettoyez les données: traitez les données extraites pour supprimer le contenu inutile ou les reformater, si nécessaire.
- Exportez les données: enregistrez les données nettoyées dans le format de votre choix, tel que JSON ou CSV.
Cette approche présente plusieurs avantages, notamment le contrôle total du processus d’extraction des données et la possibilité de le personnaliser pour répondre à des exigences spécifiques. Cependant, elle nécessite une expertise technique pour la conception et la maintenance. De plus, chaque site de commerce électronique nécessite son propre script.
Dans les chapitres suivants, vous trouverez des exemples de scripts Python de scraping pour le commerce électronique permettant d’extraire des données d’Amazon, de Walmart et d’eBay !
Scraping Amazon
- Page cible: page de recherche « ordinateur portable » sur Amazon
- URL de la page cible: https://www.amazon.com/s?k=laptop&ref=nb_sb_noss
Amazon dispose de mesures anti-scraping conçues pour bloquer les requêtes qui ne proviennent pas d’un navigateur. Pour contourner ces restrictions, vous devez utiliser un outil d’automatisation de navigateur tel que Selenium :
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import json
# Initialiser le WebDriver
driver = webdriver.Chrome(service=Service())
# Ouvrir la page d'accueil d'Amazon dans le navigateur
driver.get("https://amazon.com/")
# Remplir le formulaire de recherche
search_input_element = driver.find_element(By.ID, "twotabsearchtextbox")
search_input_element.send_keys("laptop")
# Localiser le bouton de recherche et cliquer dessus
search_button_element = driver.find_element(By.ID, "nav-search-submit-button")
search_button_element.click()
# Vous êtes maintenant sur la page cible
# Où stocker les données extraites
products = []
# Sélectionner tous les éléments de produit sur la page
product_elements = driver.find_elements(By.CSS_SELECTOR, "[role="listitem"][data-asin]")
# Les parcourir
for product_element in product_elements:
# Logique de scraping
url_element = product_element.find_element(By.CSS_SELECTOR, ".a-link-normal")
url = url_element.get_attribute("href")
name_element = product_element.find_element(By.CSS_SELECTOR, "h2")
name = name_element.text
image_element = product_element.find_element(By.CSS_SELECTOR, "img[data-image-load]")
image = image_element.get_attribute("src")
# Remplir un nouvel objet avec les données récupérées
product = {
"url": url,
"name": name,
"image": image
}
# L'ajouter à la liste des produits récupérés
products.append(product)
# Exporter les données vers un fichier JSON
with open("products.json", "w", encoding="utf-8") as json_file:
json.dump(products, json_file, indent=4)
Exécutez le Scraper Amazon eCommerce ci-dessus. Si Amazon n’affiche pas de CAPTCHA, vous obtiendrez le résultat suivant :
[
{
"url": "https://www.amazon.com/A315-24P-R7VH-Display-Quad-Core-Processor-Graphics/dp/B0BS4BP8FB/ref=sr_1_3?crid=1W7R6D59KV9L1&dib=eyJ2IjoiMSJ9.iBCtzwnCm6CE8Bx8hKmQ8ez6PkzMg3asWNhAxvflBg3pKVi5IxQUSDpcaksihO-jEO1nyLGkdoGk_2hNyQ7EWOa6epS_hZHxqV7msqdtcEZv4irFZRnYHcP5YnEwKu17BjsYS_IPI1tFVDS65v_roSCu_IiBNfotAEHSx4zOwQ4u1CRKfvnLjIX4VlECydRjsKaAQ-mErT89tyBUCfEGjzKPPZxwHi3Y0MoieuPceL8.jIuIrqzxNYISYPLHifRJq289Vy9Z6hqT8vmMcUQw9HY&dib_tag=se&keywords=laptop&qid=1735572968&sprefix=l%2Caps%2C271&sr=8-3",
« name » : « Ordinateur portable fin Acer Aspire 3 A315-24P-R7VH | Écran IPS Full HD 15,6 pouces | Processeur quadricœur AMD Ryzen 3 7320U | Carte graphique AMD Radeon | 8 Go de mémoire LPDDR5 | SSD NVMe 128 Go | Wi-Fi 6 | Windows 11 Home en mode S »,
« image » : « https://m.media-amazon.com/images/I/61gKkYQn6lL._AC_UY218_.jpg »
},
// omis pour plus de concision...
{
« url » : « https://www.amazon.com/Lenovo-Newest-Flagship-Chromebook-HubxcelAccesory/dp/B0CBJ46QZX/ref=sr_1_8?crid=1W7R6D59KV9L1&dib=eyJ2IjoiMSJ9.iBCtzwnCm6CE8Bx8hKmQ8ez6PkzMg3asWNhAxvflBg3pKVi5IxQUSDpcaksihO-jEO1nyLGkdoGk_2hNyQ7EWOa6epS_hZHxqV7msqdtcEZv4irFZRnYHcP5YnEwKu17BjsYS_IPI1tFVDS65v_roSCu_IiBNfotAEHSx4zOwQ4u1CRKfvnLjIX4VlECydRjsKaAQ-mErT89tyBUCfEGjzKPPZxwHi3Y0MoieuPceL8.jIuIrqzxNYISYPLHifRJq289Vy9Z6hqT8vmMcUQw9HY&dib_tag=se&keywords=laptop&qid=1735572968&sprefix=l%2Caps%2C271&sr=8-8",
« name » : « Chromebook phare le plus récent de Lenovo, ordinateur portable fin et léger avec écran tactile FHD 14 pouces, processeur MediaTek Kompanio 520 à 8 cœurs, 4 Go de RAM, 64 Go eMMC, WiFi 6, Chrome OS + HubxcelAccesory, bleu abysse »,
« image » : « https://m.media-amazon.com/images/I/61KlKRdsQ7L._AC_UY218_.jpg »
}
]
Notez qu’Amazon peut toujours afficher un CAPTCHA et bloquer votre demande, même si vous la faites via Selenium. Dans ce cas, vous devriez consulter SeleniumBase comme alternative. Sinon, continuez à lire l’article car nous vous présenterons une solution définitive.
Pour un guide complet, consultez notre tutoriel détaillé sur le Scraping web d’Amazon.
Scraping Walmart
- Page cible: page de recherche « keyboard » sur Walmart
- URL de la page cible: https://www.walmart.com/search?q=keyboard
Tout comme Amazon, Walmart utilise des solutions anti-bot pour bloquer les requêtes provenant de clients HTTP automatisés. Vous pouvez donc le scraper avec Selenium comme ci-dessous :
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import json
# Initialiser le WebDriver
driver = webdriver.Chrome(service=Service())
# Accéder à la page cible
driver.get("https://www.walmart.com/search?q=keyboard")
# Où stocker les données récupérées
products = []
# Sélectionner tous les éléments de produit sur la page
product_elements = driver.find_elements(By.CSS_SELECTOR, ".carousel-4[data-testid="carousel-container"] li")
# Itérer sur ceux-ci
for product_element in product_elements:
# Logique de scraping
url_element = product_element.find_element(By.CSS_SELECTOR, "a")
url = url_element.get_attribute("href")
name_element = product_element.find_element(By.CSS_SELECTOR, "h3")
name = name_element.get_attribute("innerText")
image_element = product_element.find_element(By.CSS_SELECTOR, "img[data-testid="productTileImage"]")
image = image_element.get_attribute("src")
# Remplir un nouvel objet avec les données récupérées
product = {
"url": url,
"name": name,
"image": image
}
# L'ajouter à la liste des produits récupérés
products.append(product)
# Exporter les données vers un fichier JSON
with open("products.json", "w", encoding="utf-8") as json_file:
json.dump(products, json_file, indent=4)
Exécutez le Scraper e-commerce Walmart, et vous obtiendrez :
[
{
"url": "https://www.walmart.com/sp/track?bt=1&eventST=click&plmt=sp-search-middle~desktop~Results%20for%20%22Electronics%22&pos=1&tax=3944_1089430_132959_1008621_7197407&rdf=1&rd=https%3A%2F%2Fwww.walmart.com%2Fip%2FLogitech-920-004536-Mk270-Clavier-Souris-USB-Sans fil-Combo-Noir%2F28540111%3FclassType%3DREGULAR%26adsRedirect%3Dtrue&adUid=094fb4ae-62f3-4954-ae99-b2938550d72c&mloc=sp-search-middle&pltfm=desktop&pgId=keyboard&pt=search&spQs=sAX_0l4wzWXzBji34bVpmheXU7_ETXGbDXcA9LhcshG_YbqBx24VWzt7yesHivpt1lpckuNhxQqbLidA-d8L4agqx_YPQVlj2EfM_TnEyfsSWiTEkvBaqgkaMzy6bgIZ4eC8t9-qqz7qtb7uXMz3cH92UCf5EEgQlfKwnxJ-SAF1EW1ouCjC10Ur3hELs3143xQPjxNUSUoN8FIF12fxJmTlSlTe4makoj1s2NoubYTqnlJLs3pohowJCRFT76Vl&storeId=3081&couponState=na&bkt=ace1_default%7Cace2_default%7Cace3_default%7Ccoldstart_off%7Csearch_default&classType=REGULAR",
"name": "Logitech Wireless Combo MK270",
« image » : « https://i5.walmartimages.com/seo/Logitech-920-004536-Mk270-Keyboard-Mouse-USB-Wireless-Combo-Black_99591453-341e-4c5b-937e-b2ab9b321519.3860011d84a23ccd0732e46474590b15.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF »
},
{
« url » : « https://www.walmart.com/sp/track?bt=1&eventST=click&plmt=sp-search-middle~desktop~Results%20for%20%22Electronics%22&pos=2&tax=3944_1089430_132959_1008621_7197407&rdf=1&rd=https%3A%2F%2Fwww.walmart.com%2Fip%2FSteelSeries-Apex-3-TKL-RGB-Gaming-Keyboard-Tenkeyless-Water-Dust-Resistant-PC-and-USB-A%2F996783321%3FclassType%3DVARIANT%26adsRedirect%3Dtrue&adUid=094fb4ae-62f3-4954-ae99-b2938550d72c&mloc=sp-search-middle&pltfm=desktop&pgId=keyboard&pt=search&spQs=Dp3ons-xIcmPw9Ze7UUZuW3PD9Dto_vYCLjglme5vSy5Ze1p4NXg3uzApRy4mgfB-dGDchsq6FDoaZeMy6Dmeagqx_YPQVlj2EfM_TnEyfv_0r9GA9WwEd1cWbcx63Diahe72Zw6lw8suSf-OFKKH6UaiJl_8Qtpar-x0VhgrMsbqG7gDKh5DkQZql3HeMLncWSwburhSEjvpT1dXlDoWKxUrZwxZhOMry-uCqhuSb7Y6B-xZGrNPjYyel0nw11Z&storeId=3081&couponState=na&bkt=ace1_default%7Cace2_default%7Cace3_default%7Ccoldstart_off%7Csearch_default&classType=VARIANT",
"name": "Clavier gaming SteelSeries Apex 3 TKL RGB - Sans pavé numérique - Résistant à l'eau et à la poussière - PC et USB-A",
« image » : « https://i5.walmartimages.com/seo/SteelSeries-Apex-3-TKL-RGB-Gaming-Keyboard-Tenkeyless-Water-Dust-Resistant-PC-and-USB-A_876430c2-eed8-404a-aa55-1c66193daf8e.8c617e57ba48bc49d003f917f85cb535.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF »
},
// omis pour plus de concision...
{
"url": "https://www.walmart.com/ip/DEP-06-Portable-Digital-Piano-with-X-Stand/7598762909?classType=REGULAR",
"name": "Piano numérique portable Donner 88 touches avec clavier synthétiseur, support X, pédale, accompagnement automatique pour débutants, 128 sons, 83 rythmes, prise en charge USB/MIDI/Melodics, connexion sans fil",
« image » : « https://i5.walmartimages.com/seo/DEP-06-Portable-Digital-Piano-with-X-Stand_1175fc1e-c191-4c71-9e9a-7e4a13274487.6673e0430c23d122744cfb63ccc8c155.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF »
}
]
Pour plus d’informations, consultez notre article sur le Scraping web de Walmart.
Scraping eBay
- Page cible: page de recherche « souris » sur eBay
- URL de la page cible: https://www.ebay.com/sch/i.html?_from=R40&_trksid=m570.l1313&_nkw=mouse&_sacat=0
eBay n’utilise pas JavaScript pour afficher les produits ou charger les données de manière dynamique. Il est donc possible de le scraper avec Requests et Beautiful Soup comme suit :
import requests
from bs4 import BeautifulSoup
import json
# Page cible
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=m570.l1313&_nkw=mouse&_sacat=0"
# Envoyer une requête GET à la page de recherche eBay
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
# Analyser le contenu de la page avec BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Où stocker les données extraites
products = []
# Sélectionner tous les éléments de produit sur la page
product_elements = soup.select("li.s-item")
# Itérer sur eux
for product_element in product_elements:
# Logique de scraping
url_element = product_element.select("a[data-interactions]")[0]
url = url_element["href"]
name_element = product_element.select("[role="heading"]")[0]
name = name_element.text
image_element = product_element.select("img")[0]
image = image_element["src"]
# Remplir un nouvel objet avec les données récupérées
product = {
"url": url,
"name": name,
"image": image
}
# L'ajouter à la liste des produits récupérés
products.append(product)
# Exporter les données vers un fichier JSON
with open("products.json", "w", encoding="utf-8") as json_file:
json.dump(products, json_file, indent=4)Lancez le script de Scraping web du site e-commerce eBay, et vous obtiendrez :
[
{
« url » : « https://www.ebay.com/itm/193168148815?_skw=mouse&itmmeta=01JGC679WKT327K11R9YCGMQAN&hash=item2cf9b8094f :g:8F4AAOSw3B1drMr-&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKlr8NKoodwElhyHbl4CwcBMRqdGJme95%2F3tIll4uI7QYBk4%2BUBpwVvwiXdAl2%2BcILZ9axc%2BdHSZStWWMxWVyq4JdZ6r52PrRP2aS1jUoFoJ11vL4KyH2S8R5ha71xBtDFcGA2%2BtzhTzcR7J25kxuxbyd%2Frd4YnKbTPKwhn2Q0TP8qL30BJKcj4FnJYP0zhgO4WOGgOCHQhM21%2BanVk%2Fl0eg1H8mqCU91mkgKAt8KghFmw%3D%3D%7Ctkp%3ABlBMULSenYaDZQ",
« name » : « Souris optique sans fil 2,4 GHz et récepteur USB pour PC portable DPI USA »,
« image » : « https://i.ebayimg.com/images/g/8F4AAOSw3B1drMr-/s-l500.webp »
},
{
« url » : « https://www.ebay.com/itm/356159975164?_skw=mouse&itmmeta=01JGC679WKE9V782ZXT15SEPHP&hash=item52ecc9eefc:g:0ikAAOSwHStnD33Q&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKlZ7pO0lYrvftkZhnT7ja625fcsjcktK0eaub2HNzEgsmo3b2VehoA4tffYdt0xiTXwHb%2BzYU4NBZ5onBh68cyKWhhMJowbRvnCwuwy2IQIRlkeijpbRtJNJPuaaiDZdV0eabGGkps8433kCR6fcX1xEodUxujoeYUjp0VP81OWcl%2BbBGd70%2Fq45HC3SXg4k%2FlK0%2FqR80yJYexSEfzUq7%2BN3Sa6Y01uCo5XPWFLHzRoSw%3D%3D%7Ctkp%3ABlBMULSenYaDZQ",
« name » : « Souris de jeu sans fil ergonomique avec écran LED et prise en charge Bluetooth 2,4 GHz filaire »,
« image » : « https://i.ebayimg.com/images/g/0ikAAOSwHStnD33Q/s-l500.webp »
},
// omis pour plus de concision...
{
« url » : « https://www.ebay.com/itm/116250548048?_skw=mouse&itmmeta=01JGC679WN076MJ17QJ9P4FA5J&hash=item1b11129750:g:gr8AAOSwsSFmkXG3&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKkArX38iC0VVXTpfv4BzqCegsh22yxmsDAwZAmd4RxM9JlEMfuVRoYGVZFVCeurJYwAjWd2YK3%2BNs6m5rQHZXISyWtev1lEvfVVKP4Rd5QeC2KzLgqXOvp1lWiK5b31kfujkmKjF%2BEaR1kplulwrgUvzMO%2F78F%2BFukgIAoL8dE4nRD9jo%2BieiAgIpLBUcs8AmCy5vk65gt1JGonUOncRksGYciF%2FJg6arB9%2FVOYYq7N8A%3D%3D%7Ctkp%3ABlBMULyenYaDZQ",
« name » : « Razer x Sanrio Kuromi DeathAdder Gaming Mouse and Mouse Pad Combo »,
« image » : « https://i.ebayimg.com/images/g/gr8AAOSwsSFmkXG3/s-l500.webp »
}
]
Incroyable ! Vous venez de voir quelques exemples de scripts Python pour le scraping de données e-commerce !
Les défis du Scraping web dans le commerce électronique et comment les surmonter
Dans les exemples ci-dessus, nous nous sommes concentrés sur l’extraction d’informations de base telles que le nom du produit, l’URL et l’URL de l’image à partir de quelques sites de commerce électronique. Si cette simplicité donne l’impression que le scraping dans le domaine du commerce électronique est facile, la réalité est bien plus complexe pour plusieurs raisons :
- Structures de pages dynamiques: les plateformes de commerce électronique mettent fréquemment à jour la conception de leurs pages, ce qui nécessite une maintenance constante des scripts.
- Pages produits variées: différents produits peuvent afficher des ensembles de données variables et utiliser des mises en page totalement différentes.
- Tarification dynamique: l’extraction de données précises sur les prix peut s’avérer difficile en raison des offres temporaires, des remises ou des offres spécifiques à une région.
De plus, les principaux sites de commerce électronique comme Amazon utilisent des mesures anti-scraping avancées, telles que les CAPTCHA :
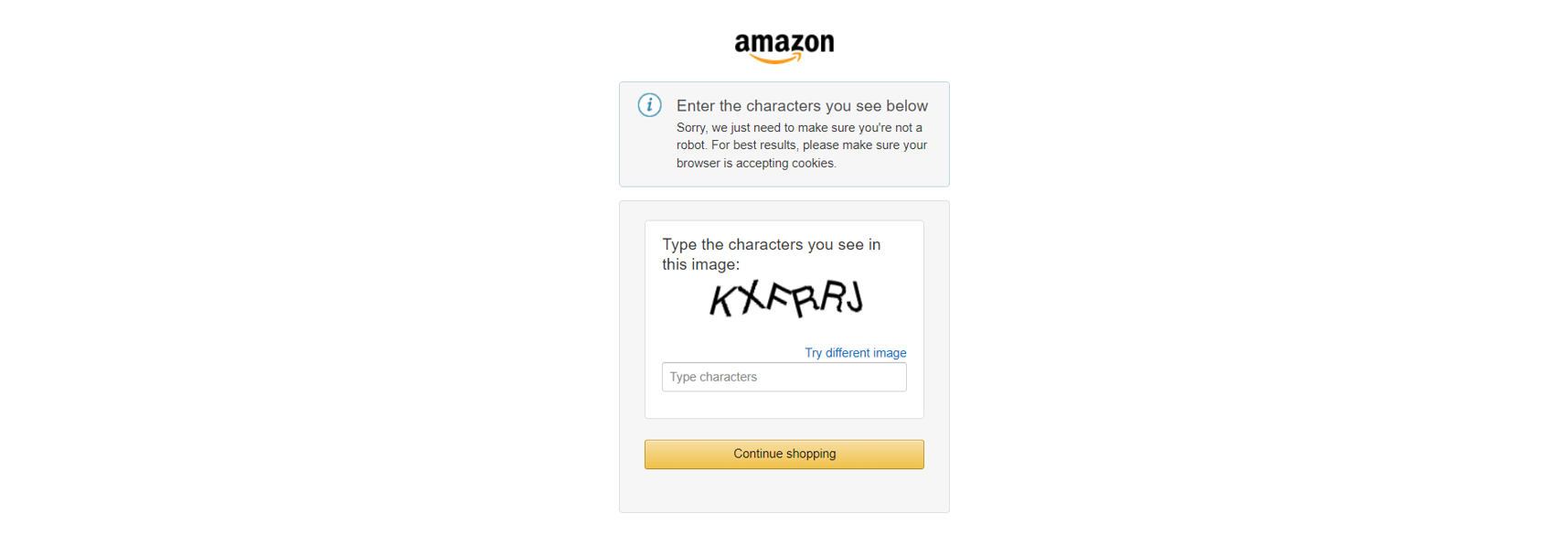
Ou, de manière similaire, des défis JavaScript:

Pour surmonter ces obstacles, vous pouvez :
- Apprendre des techniques avancées de scraping: lisez notre guide sur le contournement des CAPTCHA avec Python et consultez nos tutoriels approfondis sur le scraping pour obtenir des conseils pratiques.
- Utiliser des outils d’automatisation avancés: utilisez des outils robustes tels que Playwright Stealth pour extraire des données sur des sites dotés de mécanismes anti-bot.
Toutefois, la solution la plus efficace consiste à utiliser une API dédiée au Scraper du commerce électronique.
L’API eCommerce Scraper de Bright Data est une solution fiable pour extraire des données de plateformes de commerce électronique telles qu’Amazon, Target, Walmart, Lazada, Shein, Shopee, etc. Ses principaux avantages sont les suivants :
- Récupérez des informations structurées telles que le titre du produit, le nom du vendeur, la marque, la description, les avis, le prix initial, la devise, la disponibilité, les catégories, etc.
- Éliminer les soucis liés à la gestion des serveurs, des Proxies ou à la prévention des blocages de sites web.
- Évitez les interruptions dues aux CAPTCHA ou aux défis JavaScript.
Rationalisez dès aujourd’hui votre processus de scraping e-commerce !
Conclusion
Dans cet article, vous avez découvert ce qu’est un Scraper e-commerce et le type de données qu’il peut extraire des pages web e-commerce. Quelle que soit la sophistication de votre script de Scraping web e-commerce, la plupart des sites peuvent toujours détecter les activités automatisées et vous bloquer.
La solution réside dans une API de Scraper e-commerce puissante, spécialement conçue pour récupérer de manière fiable des données e-commerce à partir de diverses plateformes. Ces API offrent des données structurées et complètes, notamment :
- API Amazon Scraper: scrapez Amazon et collectez des données telles que le titre, le nom du vendeur, la marque, la description, les avis, le prix initial, la devise, la disponibilité, les catégories, l’ASIN, le nombre de vendeurs, et bien plus encore.
- API eBay Scraper: collectez des données telles que l’ASIN, le nom du vendeur, l’identifiant du commerçant, l’URL, l’URL de l’image, la marque, la présentation du produit, la description, les tailles, les couleurs, le prix final, etc.
- API Walmart Scraper: collectez des données telles que l’URL, le SKU, le prix, l’URL de l’image, les pages connexes, la disponibilité pour la livraison et le retrait, la marque, la catégorie, l’ID et la description du produit, et bien plus encore.
- API Target Scraper: collectez des données telles que l’URL, l’ID du produit, le titre, la description, la note, le nombre d’avis, le prix, la remise, la devise, les images, le nom du vendeur, les offres, la politique d’expédition, etc.
- API Lazada Scraper: récupérez des données telles que l’URL, le titre, la note, les avis, le prix initial et final, la devise, l’image, le nom du vendeur, la description du produit, le SKU, les couleurs, les promotions, la marque, etc.
- API Shein Scraper: récupérez des données telles que le nom du produit, la description, le prix, la devise, la couleur, la disponibilité, la taille, le nombre d’avis, l’image principale, le code pays, le domaine, etc.
- API Shopee Scraper: récupérez des données telles que l’URL, l’ID, le titre, la note, les avis, le prix, la devise, le stock, les favoris, l’image, l’URL de la boutique, les notes, la date d’inscription, les abonnés, les ventes, la marque, etc.
Pour extraire des données de produits spécifiques, pensez à notre API Web Scraper. Si la création d’un Scraper n’est pas votre tasse de thé, explorez nos Jeux de données e-commerce prêts à l’emploi.
Créez dès aujourd’hui un compte Bright Data gratuit pour essayer nos API de Scraper ou explorer nos Jeux de données.




