

Dans ce guide, vous apprendrez :
- Pourquoi Gemini est une excellente solution pour le web scraping piloté par l’IA ?
- Comment l’utiliser pour scraper un site en Python à travers un tutoriel guidé
- La plus grande limite de cette méthode de scraping du web et comment la surmonter
Plongeons dans l’aventure !
Pourquoi utiliser Gemini pour le Web Scraping ?
Gemini est une famille de modèles d’IA multimodaux développés par Google qui peuvent analyser et interpréter du texte, des images, du son, des vidéos et du code. L’utilisation de Gemini pour le web scraping simplifie l’extraction des données en automatisant l’interprétation et la structuration du contenu non structuré. Cela élimine le besoin d’efforts manuels, en particulier lorsqu’il s’agit de l’analyse syntaxique des données.
En détail, voici quelques-uns des cas d’utilisation les plus courants de Gemini dans le domaine du web scraping :
- Pages dont la structure change fréquemment: Gemini peut gérer des pages dynamiques dont la mise en page ou les éléments de données changent souvent, comme dans les sites de commerce électronique tels qu’Amazon.
- Pages contenant beaucoup de données non structurées: Il excelle dans l’extraction d’informations utiles à partir de grands volumes de textes non organisés.
- Pages pour lesquelles il est difficile d’écrire une logique d’analyse personnalisée: Pour les pages dont la structure est complexe ou imprévisible, Gemini peut automatiser le processus sans nécessiter de règles d’analyse complexes.
Les scénarios d’utilisation courants de Gemini dans le domaine du web scraping sont les suivants :
- RAG (Retrieval-Augmented Generation): Combinaison de l’extraction de données en temps réel pour améliorer les connaissances en matière d’IA. Pour un exemple complet utilisant une technologie d’IA similaire, suivez notre tutoriel sur la création d’un chatbot RAG à partir de données SERP.
- Raclage des médias sociaux: Collecte de données structurées à partir de plateformes au contenu dynamique.
- Agrégation de contenu: Rassembler des nouvelles, des articles ou des billets de blog à partir de plusieurs sources pour créer des résumés ou des analyses.
Pour plus d’informations, consultez notre guide sur l’utilisation de l’IA pour le web scraping.
Web Scraping avec Gemini en Python : Guide pas à pas
Comme site cible pour cette section, nous utiliserons une page de produit spécifique provenant du bac à sable “Ecommerce Test Site to Learn Web Scraping” (Site test de commerce électronique pour apprendre le scraping Web) :
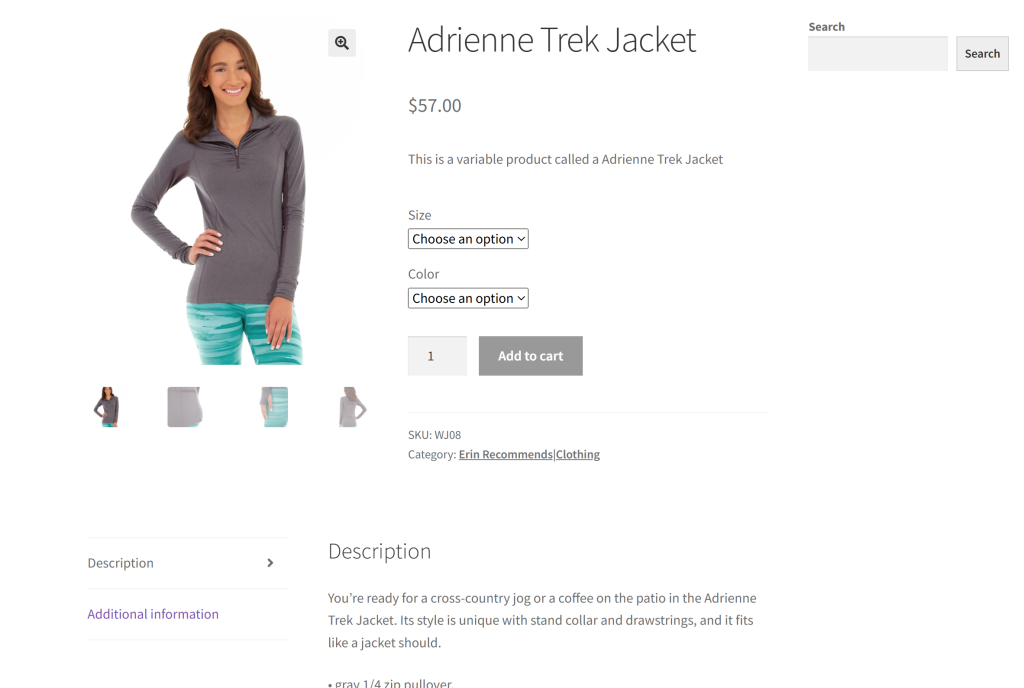
Il s’agit d’un excellent exemple, car la plupart des pages de produits de commerce électronique affichent différents types de données ou ont des structures variées. C’est ce qui rend le web scraping du commerce électronique si difficile, et c’est là que l’IA peut aider.
L’objectif de notre scraper alimenté par Gemini est d’exploiter l’IA pour extraire les détails des produits de la page sans écrire de logique d’analyse manuelle. Les données sur les produits récupérées par l’IA comprendront :
- SKU
- Nom
- Images
- Prix
- Description
- Tailles
- Couleurs
- Catégorie
Suivez les étapes ci-dessous pour apprendre à faire du web scraping avec Gemini !
Étape 1 : Configuration du projet
Avant de commencer, vérifiez que Python 3 est installé sur votre ordinateur. Sinon, téléchargez-le et suivez l’assistant d’installation.
Maintenant, lancez la commande suivante pour créer un dossier pour votre projet de scraping :
mkdir gemini-scrapergemini-scraper représente le dossier du projet de votre scraper web alimenté par Python Gemini.
Naviguez jusqu’à lui dans le terminal et initialisez un environnement virtuel à l’intérieur :
cd gemini-scraper
python -m venv venvChargez le dossier du projet dans votre IDE Python préféré. Visual Studio Code avec l’extension Python ou PyCharm Community Edition sont deux excellentes options.
Créez un fichier scraper.py dans le dossier du projet, qui devrait maintenant contenir cette structure de fichier :

Actuellement, scraper.py est un script Python vierge, mais il contiendra bientôt la logique de scraping LLM souhaitée.
Dans le terminal de l’IDE, activer l’environnement virtuel. Sous Linux ou macOS, exécuter cette commande :
./venv/bin/activateDe manière équivalente, sous Windows, exécutez :
venv/Scripts/activateC’est formidable ! Vous disposez maintenant d’un environnement Python pour le web scraping avec Gemini.
Étape 2 : Configurer Gemini
Gemini fournit une API que vous pouvez appeler à l’aide de n’importe quel client HTTP, y compris les requêtes. Cependant, il est préférable de se connecter via le SDK officiel Google AI Python pour l’API Gemini. Pour l’installer, exécutez la commande suivante dans l’environnement virtuel activé :
pip install google-generativeaiEnsuite, importez-le dans votre fichier scraper.py :
import google.generativeai as genaiPour faire fonctionner le SDK, vous avez besoin d’une clé API Gemini. Si vous n’avez pas encore récupéré votre clé API
n’a pas encore été récupérée, suivez la documentation officielle de Google. Plus précisément, connectez-vous à votre compte Google et rejoignez Google AI Studio. Naviguez jusqu’à la page“Get API Key“, et vous verrez la fenêtre modale suivante :
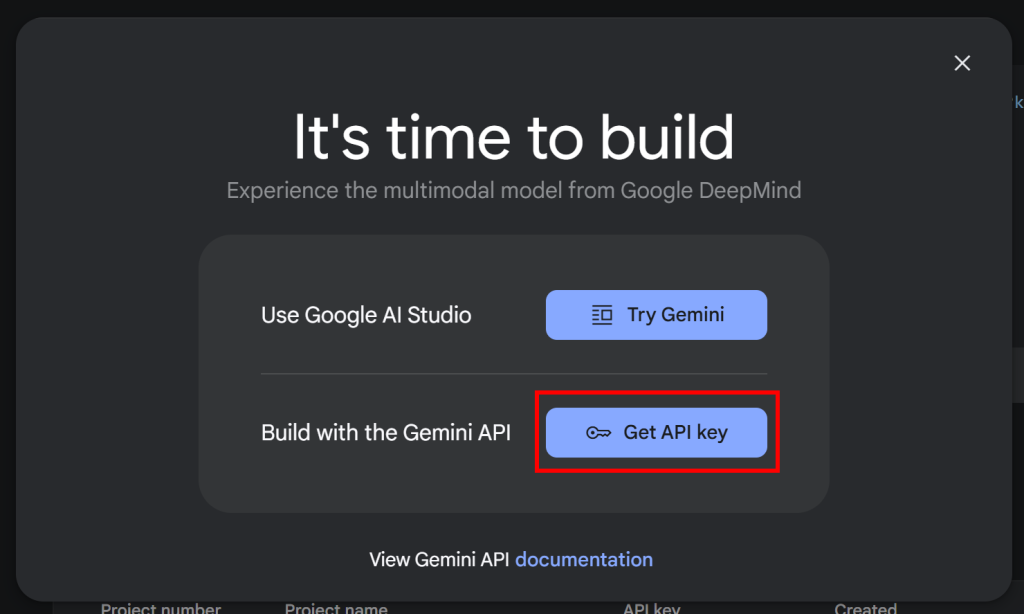
Cliquez sur le bouton “Get API key”, et la section suivante apparaîtra :
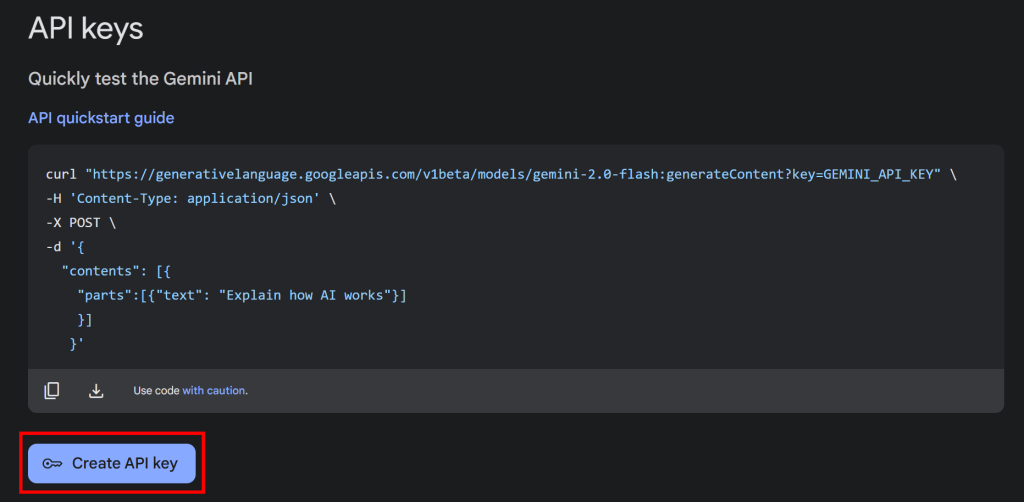
Cliquez ensuite sur “Create API key” pour générer votre clé API Gemini :
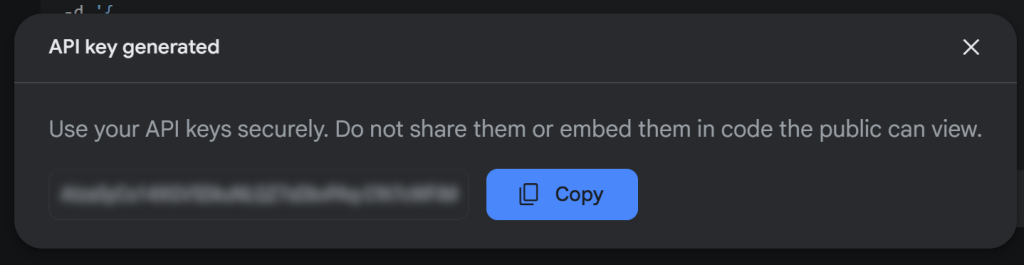
Copiez la clé et conservez-la en lieu sûr.
Remarque: le niveau gratuit de Gemini est suffisant pour cet exemple. Le niveau payant n’est nécessaire que si vous avez besoin de limites de taux plus élevées ou si vous voulez vous assurer que vos invites et vos réponses ne sont pas utilisées pour améliorer les produits Google. Pour plus de détails, consultez la page de facturation de Gemini.
Pour utiliser la clé API Gemini en Python, vous pouvez la définir comme variable d’environnement :
export GEMINI_API_KEY=<YOUR_GEMINI_API_KEY>Vous pouvez également l’enregistrer directement dans votre script Python sous la forme d’une constante :
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"Et le transmettre à genai en tant que configuration, comme suit :
genai.configure(api_key=GEMINI_API_KEY)Dans ce cas, nous suivrons la deuxième approche. Cependant, gardez à l’esprit que les deux méthodes fonctionnent, car google-generativeai essaie automatiquement de lire la clé API dans GEMINI_API_KEY si vous ne la transmettez pas manuellement.
C’est incroyable ! Vous pouvez désormais utiliser le SDK Gemini pour effectuer des requêtes API au LLM en Python.
Étape 3 : Obtenir le code HTML de la page cible
Pour se connecter au serveur cible et récupérer le code HTML de ses pages web, nous utiliserons Requests, le client HTTP le plus populaire en Python. Dans un environnement virtuel activé, installez-le avec :
pip install requestsEnsuite, importez-le dans scraper.py :
import requestsUtilisez-le pour envoyer une requête GET à la page cible et récupérer son document HTML :
url = "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/"
response = requests.get(url)response.content contient maintenant le code HTML brut de la page. Il est temps de l’analyser et de se préparer à en extraire des données !
Étape 4 : Convertir le HTML en Markdown
Si vous comparez d’autres technologies de scraping d’IA comme Crawl4AI, vous remarquerez qu’elles vous permettent d’utiliser des sélecteurs CSS pour cibler des éléments HTML. Ces bibliothèques convertissent ensuite le HTML des éléments sélectionnés en texte Markdown. Enfin, elles traitent ce texte avec un LLM.
Vous êtes-vous déjà demandé pourquoi ? Eh bien, deux raisons essentielles expliquent ce comportement :
- Réduire le nombre de jetons envoyés à l’IA, ce qui vous permet d’économiser de l’argent (car tous les fournisseurs de LLM ne sont pas gratuits comme Gemini).
- Rendre le traitement de l’IA plus rapide, car moins de données d’entrée signifie des coûts de calcul plus faibles et des réponses plus rapides.
Pour une présentation complète, consultez notre guide sur le scraping web avec CrawlAI et DeepSeek.
Essayons de reproduire cette logique et de voir si elle a un sens. Commencez par inspecter la page cible en l’ouvrant dans une fenêtre incognito (pour ouvrir une nouvelle session). Cliquez ensuite avec le bouton droit de la souris n’importe où sur la page et sélectionnez l’option “Inspecter”.
Examinez la structure de la page. Vous constaterez que toutes les données pertinentes sont contenues dans l’élément HTML identifié par le sélecteur CSS #main:
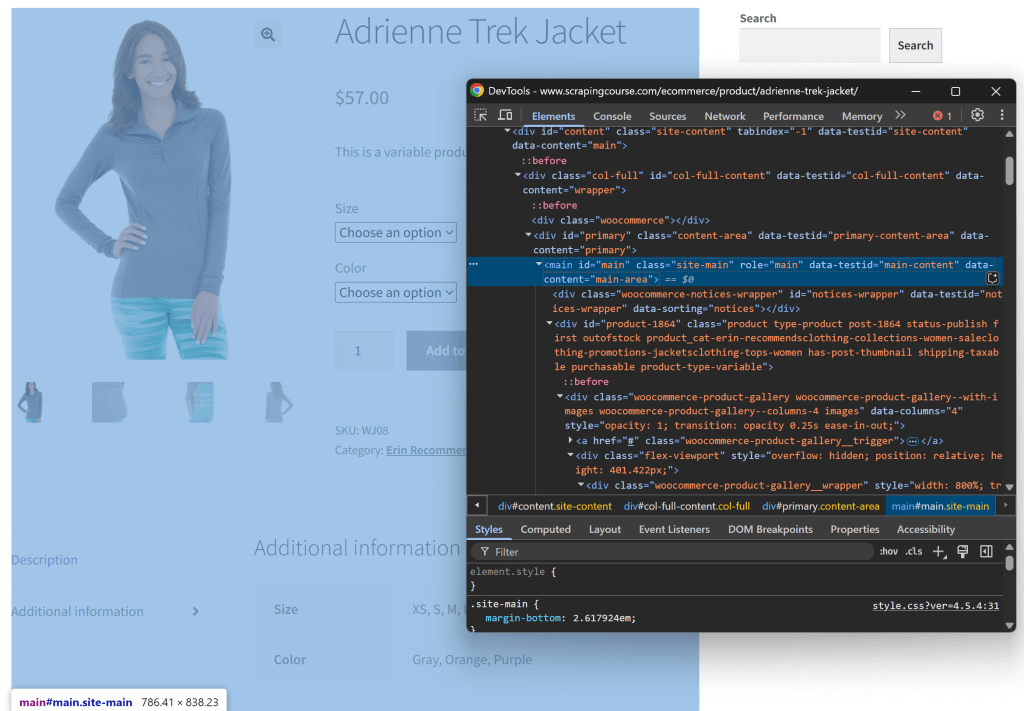
Vous pourriez envoyer tout le code HTML brut à Gemini, mais cela introduirait beaucoup d’informations inutiles (comme les en-têtes et les pieds de page). En revanche, en ne transmettant que le contenu #main, vous réduisez le bruit et évitez les hallucinations de l’IA.
Pour ne sélectionner que #main, vous avez besoin d’un outil d’analyse HTML Python, tel que Beautiful Soup. Installez-le donc avec :
pip install beautifulsoup4Si vous n’êtes pas familier avec sa syntaxe, consultez notre guide sur le web scraping de Beautiful Soup.
Maintenant, importez-le dans scraper.py :
from bs4 import BeautifulSoupUtilisez Beautiful Soup pour analyser le code HTML brut récupéré via Requests, sélectionner l’élément #main et extraire son code HTML :
# Parse the HTML with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Extract the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)Si vous imprimez main_html, vous verrez quelque chose comme ceci :
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<!-- omitted for brevity... -->
</main>Maintenant, vérifiez combien de tokens ce HTML génèrerait et estimez le coût si vous utilisiez le niveau payant de Gemini. Pour ce faire, utilisez un outil comme Token Calculator:
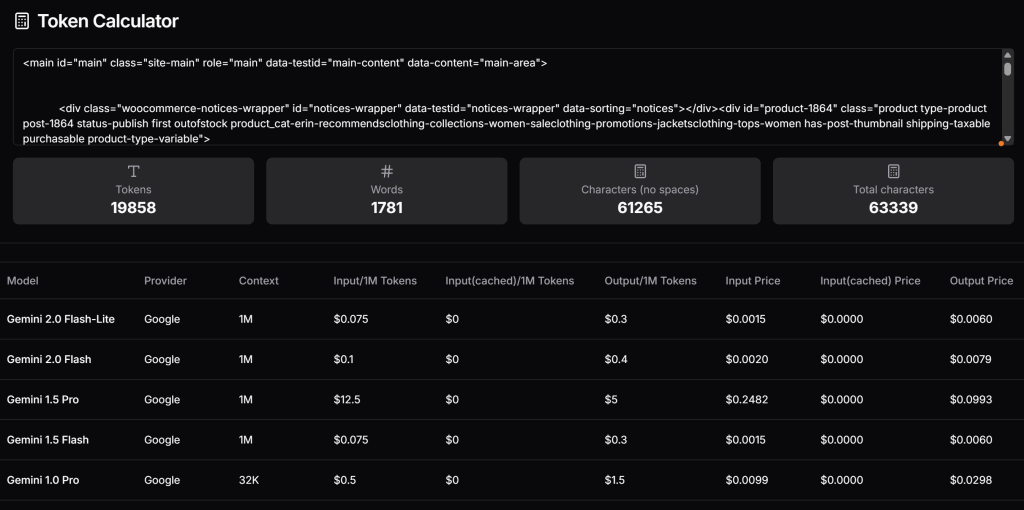
Comme vous pouvez le constater, cette approche équivaut à près de 20 000 jetons, coûtant environ 0,25 $ par requête pour Gemini 1.5 Pro. Sur un projet de scraping à grande échelle, cela peut facilement devenir un problème !
Essayez de convertir le HTML extrait en Markdown, comme le fait Crawl4AI. Tout d’abord, installez une bibliothèque HTML-Markdown comme markdownify:
pip install markdownifyImporter markdownify dans scraper.py:
from markdownify import markdownifyEnsuite, utilisez markdownify pour convertir le HTML extrait en Markdown :
main_markdown = markdownify(main_html)La chaîne main_markdown résultante contient quelque chose comme ceci :
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_main.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alt1.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alternate.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_back.jpg)
Adrienne Trek Jacket
====================
$57.00
This is a variable product called a Adrienne Trek Jacket
| | |
| --- | --- |
| Size | Choose an optionXSSMLXL |
| Color | Choose an optionGrayOrangePurple[Clear](#) |
Adrienne Trek Jacket quantity
Add to cart
SKU: WJ08
Category: [Erin Recommends|Clothing](https://www.scrapingcourse.com/ecommerce/product-category/clothing/women/tops-women/jacketsclothing-tops-women/promotions-jacketsclothing-tops-women/women-saleclothing-promotions-jacketsclothing-tops-women/collections-women-saleclothing-promotions-jacketsclothing-tops-women/erin-recommendsclothing-collections-women-saleclothing-promotions-jacketsclothing-tops-women/)
* [Description](#tab-description)
* [Additional information](#tab-additional_information)
Description
-----------
You’re ready for a cross-country jog or a coffee on the patio in the Adrienne Trek Jacket. Its style is unique with stand collar and drawstrings, and it fits like a jacket should.
* gray 1/4 zip pullover.
* Comfortable, relaxed fit.
* Front zip for venting.
* Spacious, kangaroo pockets.
* 27″ body length.
* 95% Organic Cotton / 5% Spandex.
Additional information
----------------------
| | |
| --- | --- |
| Size | XS, S, M, L, XL |
| Color | Gray, Orange, Purple |Cette version Markdown des données d’entrée est beaucoup plus petite que le HTML #main original tout en contenant toutes les données clés nécessaires au scraping.
Utilisez à nouveau le calculateur de jetons pour vérifier combien de jetons la nouvelle entrée consommerait :
Nous avons réduit 19 858 jetons à 765 jetons, soit une réduction de 95 % !
Étape 5 : Utiliser le LLM pour extraire des données
Pour effectuer du web scraping avec Gemini, suivez les étapes suivantes :
- Écrivez une invite bien structurée pour extraire les données souhaitées de l’entrée Markdown. Veillez à définir les attributs que vous souhaitez voir apparaître dans le résultat.
- Envoyer une requête à un modèle Gemini LLM en utilisant
genai, en le configurant pour que la requête renvoie des données au format JSON. - Analyse le JSON retourné.
Mettez en œuvre la logique ci-dessus à l’aide des lignes de code suivantes :
# Extract structured data using Gemini
prompt = f"""Extract data from the content below. Respond with a raw string in JSON format containing the scraped data in the specified attributes:nn
JSON ATTRIBUTES: n
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
model = genai.GenerativeModel("gemini-2.0-flash-lite", generation_config={"response_mime_type": "application/json"})
response = model.generate_content(prompt)
# Get the response and parse it from JSON
product_raw_string = response.text
product_data = json.loads(product_raw_string)La variable prompt demande à Gemini d’extraire des données structurées du contenu main_markdown. Ensuite, genai.GenerativeModel() définit le modèle "gemini-2.0-flash-lite" pour effectuer la requête LLM. Enfin, la chaîne de réponse brute au format JSON est convertie en un dictionnaire Python utilisable avec json.loads().
Notez la configuration "application/json" pour indiquer à Gemini de renvoyer des données JSON.
N’oubliez pas d’importer json de la bibliothèque standard de Python :
import jsonMaintenant que vous disposez des données extraites dans un dictionnaire product_data, vous pouvez accéder à ses champs pour un traitement ultérieur des données, comme dans l’exemple ci-dessous :
price = product_data["price"]
price_eur = price * USD_EUR
# ...Fantastique ! Vous venez d’utiliser Gemini pour le web scraping. Il ne reste plus qu’à exporter les données scannées.
Étape 6 : Exporter les données extraites
Actuellement, les données extraites sont stockées dans un dictionnaire Python. Pour les exporter vers un fichier JSON, utilisez le code suivant :
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Cela créera un fichier product.json contenant les données extraites au format JSON.
Félicitations ! Le scraper web alimenté par Gemini est terminé.
Étape n° 7 : Assembler le tout
Vous trouverez ci-dessous le code complet de votre script de scraping Gemini :
import google.generativeai as genai
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import json
# Your Gemini API key
GEMINI_API_KEY = "<YOUR_GEMINI_API_KEY>"
# Set up the Google Gemini API
genai.configure(api_key=GEMINI_API_KEY)
# Fetch the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/"
response = requests.get(url)
# Parse the HTML of the target page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML and convert it to Markdown
main_html = str(main_element)
main_markdown = markdownify(main_html)
# Extract structured data using Gemini
prompt = f"""Extract data from the content below. Respond with a raw string in JSON format containing the scraped data in the specified attributes:nn
JSON ATTRIBUTES: n
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
model = genai.GenerativeModel("gemini-2.0-flash-lite", generation_config={"response_mime_type": "application/json"})
response = model.generate_content(prompt)
# Get the response and parse it from JSON
product_raw_string = response.text
product_data = json.loads(product_raw_string)
# Futher data processing... (optional)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Lancez le script avec :
python scraper.pyUne fois exécuté, un fichier product.json apparaîtra dans le dossier de votre projet. Ouvrez-le, et vous verrez des données structurées comme ceci :
{
"sku": "WJ08",
"name": "Adrienne Trek Jacket",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_main-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alt1-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alternate-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_back-416x516.jpg"
],
"price": "$57.00",
"description": "Youu2019re ready for a cross-country jog or a coffee on the patio in the Adrienne Trek Jacket. Its style is unique with stand collar and drawstrings, and it fits like a jacket should.nnu2022 gray 1/4 zip pullover. nu2022 Comfortable, relaxed fit. nu2022 Front zip for venting. nu2022 Spacious, kangaroo pockets. nu2022 27u2033 body length. nu2022 95% Organic Cotton / 5% Spandex.",
"sizes": [
"XS",
"S",
"M",
"L",
"XL"
],
"colors": [
"Gray",
"Orange",
"Purple"
],
"category": "Erin Recommends|Clothing"
}Et voilà ! Vous êtes parti de données non structurées dans une page HTML et vous les avez maintenant dans un fichier JSON structuré, grâce au web scraping alimenté par Gemini.
Prochaines étapes
Pour faire passer votre grattoir Gemini à la vitesse supérieure, envisagez les améliorations suivantes :
- Rendez-le réutilisable: Modifiez le script pour qu’il accepte l’invite et l’URL cible comme arguments de ligne de commande. Cela le rendra polyvalent et adaptable à différents scénarios d’utilisation.
- Mettre en œuvre l’exploration du web: Étendre le scraper pour gérer les sites web multipages en ajoutant une logique d’exploration et de pagination.
- Sécuriser les informations d’identification de l’API: Stockez votre clé d’API Gemini dans un fichier
.envet utilisezpython-dotenvpour le charger. Cela évite d’exposer votre clé d’API dans le code.
Surmonter les principales limites de cette approche du Web Scraping
Quelle est la plus grande limitation de cette approche du web scraping ? La requête HTTP faite par les requêtes !
Certes, dans l’exemple ci-dessus, cela a parfaitement fonctionné, mais c’est parce que le site cible n’est qu’un terrain de jeu pour le web scraping. En réalité, les entreprises et les propriétaires de sites web savent à quel point leurs données sont précieuses, même lorsqu’elles sont accessibles au public. Pour les protéger, ils mettent en œuvre des mesures anti-scraping qui peuvent facilement bloquer vos requêtes HTTP automatisées.
En outre, l’approche ci-dessus ne fonctionnera pas sur les sites dynamiques qui s’appuient sur JavaScript pour le rendu ou la récupération de données de manière asynchrone. Par conséquent, les sites n’ont même pas besoin de cadres anti-scraping avancés pour arrêter votre scraper. L’utilisation d’un chargement de contenu basé sur JavaScript suffit.
La solution à tous ces problèmes ? Une API de déverrouillage du Web !
Une API Web Unlocker est un point de terminaison HTTP que vous pouvez appeler à partir de n’importe quel client HTTP. La différence essentielle ? Elle renvoie le code HTML entièrement déverrouillé de toute URL que vous lui transmettez, en contournant tout bloc anti-scraping. Quel que soit le nombre de protections d’un site cible, une simple demande à Web Unlocker permet de récupérer le code HTML de la page.
Pour commencer à utiliser cet outil et récupérer votre clé API, suivez la documentation officielle de Web Unlocker. Ensuite, remplacez votre code de requête existant de l'”Étape #3″ par ces lignes :
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers for Web Unlocker
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the request payload
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/", # Replace with your target URL
"format": "raw"
}
# Fetch the unlocked HTML of the target page
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)Et c’est ainsi qu’il n’y a plus de blocages, plus de limitations ! Vous pouvez désormais explorer le Web à l’aide de Gemini sans craindre d’être arrêté.
Conclusion
Dans cet article de blog, vous avez appris à utiliser Gemini en combinaison avec Requests et d’autres outils pour construire un scraper alimenté par l’IA. L’un des principaux défis du scraping web est le risque d’être bloqué, mais ce problème a été résolu grâce à l’API Web Unlocker de Bright Data.
Comme expliqué ici, en combinant Gemini et l’API Web Unlocker, vous pouvez extraire des données de n’importe quel site sans avoir besoin d’une logique d’analyse personnalisée. Ce n’est qu’un des nombreux scénarios pris en charge par les produits et services de Bright Data, qui vous aident à mettre en œuvre un scraping web efficace piloté par l’IA.
Découvrez nos autres outils de scraping web :
- Services Proxy: Quatre types de proxy différents pour contourner les restrictions de localisation, y compris plus de 150 millions d’adresses IP résidentielles.
- API de grattage Web: Points d’extrémité dédiés à l’extraction de données web fraîches et structurées à partir de plus de 100 domaines populaires.
- API SERP: API pour gérer toutes les opérations de déverrouillage en cours pour les SERP et extraire une page.
- Navigateur de scraping: Navigateur compatible avec Puppeteer, Selenium et Playwright avec activités de déverrouillage intégrées.
Inscrivez-vous dès maintenant à Bright Data et testez gratuitement nos services de proxy et nos produits de scraping !






