

Le scraping web est une technique qui permet d’extraire des données à partir de pages web. Elle est particulièrement utile lorsque le site web cible ne propose pas d’API, que l’API ne peut pas être utilisée ou qu’elle ne renvoie pas les données exactes que vous souhaitez.
Regex, abréviation de « regular expression » (expression régulière), est un puissant modèle grammatical permettant d’extraire des données à partir de texte. Il est couramment utilisé pour le Scraping web. Regex définit un modèle qui peut être mis en correspondance dans des textes et est couramment utilisé pour trouver et extraire des informations à partir de texte. À ce titre, il est largement utilisé dans le Scraping web.
Dans cet article, vous apprendrez à utiliser Regex dansPython pour le Scraping web. À la fin de l’article, vous saurez comment scraper des sites statiques et dynamiques, et vous comprendrez certaines des limites auxquelles vous pourriez être confronté.
Qu’est-ce que Regex ?
Une expression régulière est définie à l’aide de jetons qui correspondent à un modèle particulier. La description détaillée de tous les jetons dépasse le cadre de cet article, mais le tableau suivant répertorie quelques jetons couramment utilisés que vous êtes susceptible de rencontrer :
| Jeton | Correspondances |
|---|---|
| Tout caractère non spécial | Le caractère donné |
^ |
Début d’une chaîne |
$ |
Fin d’une chaîne |
. |
Tout caractère sauf n |
* |
Zéro ou plusieurs occurrences de l’élément précédent |
? |
Zéro ou une occurrence de l’élément précédent |
+ |
Une ou plusieurs occurrences des caractères précédents |
{Chiffre} |
Nombre exact de l’élément précédent |
d |
N’importe quel chiffre |
s |
Tout caractère blanc |
w |
Tout caractère alphabétique |
D |
Inverse de d |
S |
Inverse de s |
W |
Inverse de w |
Pour en savoir plus sur les expressions régulières et acquérir une expérience pratique, rendez-vous surregexr.com. De plus,cet articlepartage quelques conseils importants pour optimiser les performances de vos expressions régulières.
Utilisation des expressions régulières dans Python pour le Scraping web
Dans ce tutoriel, vous allez créer un simple outil de Scraping en Python à l’aide de regex pour extraire des données de pages web.
Pour commencer, créez un répertoire pour votre projet :
mkdir web_scraping_with_regex
cd web_scraping_with_regex
Créez ensuite un environnement virtuel Python :
python -m venv venv
Et activez-le :
source ./venv/bin/activate
Pour écrire le Scraper web, vous devez installer deux bibliothèques :
requestspour récupérer les pages webbeautifulsoup4pour l’analyse du contenu HTML et la recherche d’éléments
Exécutez la commande suivante pour installer les bibliothèques :
pip install beautifulsoup4 requests
Remarque : avant de scraper un site web, assurez-vous de consulter ses conditions générales pour vérifier si vous êtes autorisé à le faire. Vous ne devez pas scraper un site web si cela est interdit.
Récupération d’un site de commerce électronique
Dans cette section, vous allez créer un Scraper web pour scraper unsite de commerce électronique factice simple. Vous allez scraper la première page et extraire les titres et les prix des livres.
Pour ce faire, créez un fichier nommé scraper.py et importez les modules requis :
import requests
from bs4 import BeautifulSoup
import re
Remarque : le module
reest un module Python intégré qui fonctionne avec les expressions régulières.
Ensuite, vous devez envoyer une requête GET à la page web cible pour récupérer le contenu HTML de la page :
page = requests.get('https://books.toscrape.com/')
Transmettez ces données à Beautiful Soup, qui effectue l’analyse de la structure HTML de la page Web :
soup = BeautifulSoup(page.content, 'html.parser')
Pour comprendre comment les éléments sont structurés en HTML, vous utilisez l’outilInspect Element. Ouvrez lapage Webdans le navigateur et appuyez surCtrl + Maj + Ipour ouvrirl’inspecteur. Comme vous pouvez le voir sur la capture d’écran, les produits sont stockés dans des élémentsliavec la classecol-xs-6 col-sm-4 col-md-3 col-lg-3. Le titre du livre peut être trouvé à partir des élémentsaen lisant leur attributtitle, et les prix sont stockés dans des élémentspavec la classeprice_color:
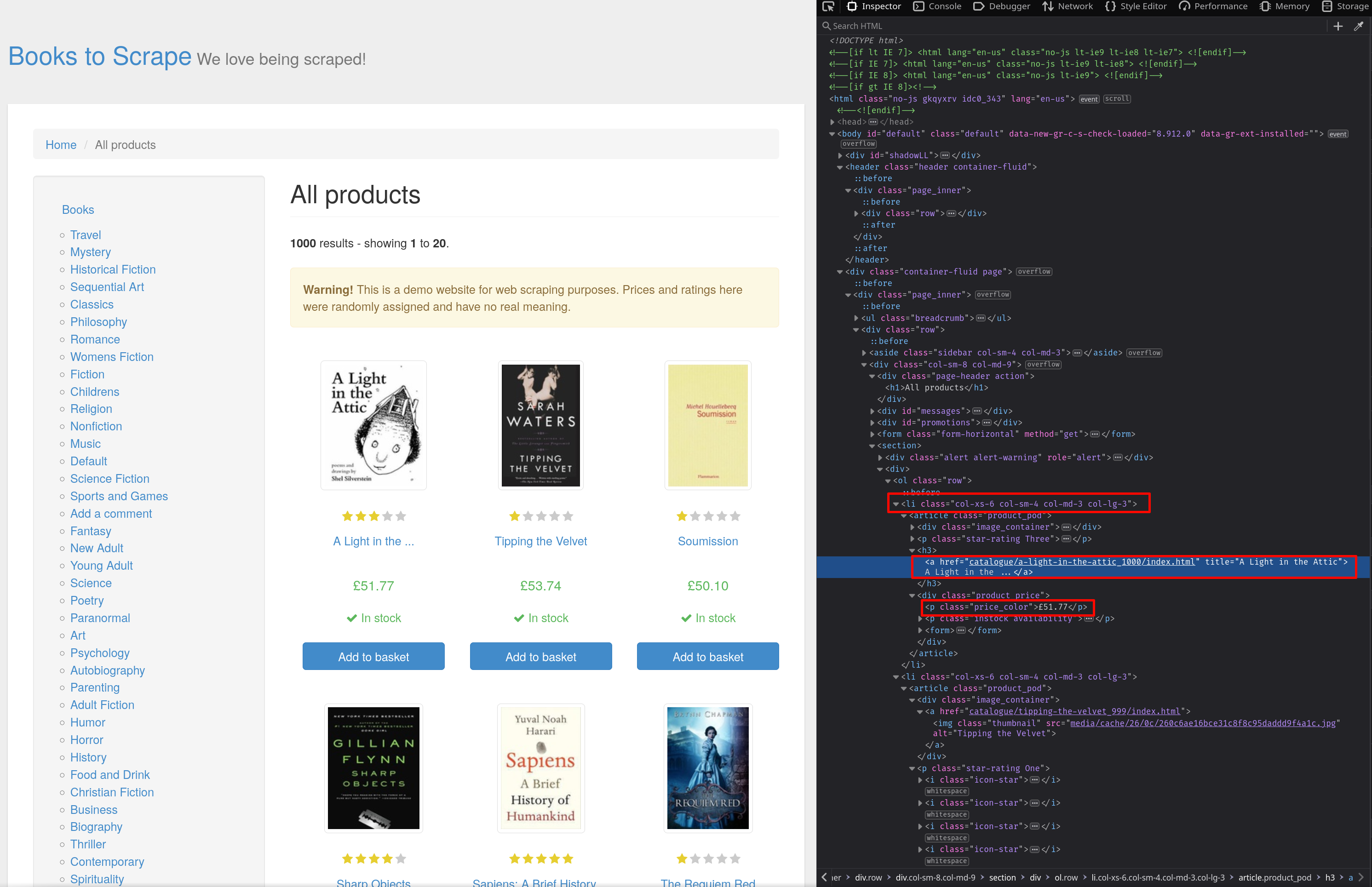
Utilisez la méthode find_all de Beautiful Soup pour trouver tous les éléments li avec la classe col-xs-6 col-sm-4 col-md-3 col-lg-3:
books = soup.find_all("li", class_="col-xs-6 col-sm-4 col-md-3 col-lg-3")
content = str(books)
La variable content contient désormais le texte HTML des éléments li, et vous pouvez utiliser une expression régulière pour extraire les titres et les prix.
La première étape consiste à construire une expression régulière qui correspond aux titres et aux prix du texte. Pour cela, vous devez à nouveau utiliser l’outil Inspect Element.
Notez que les titres des livres sont stockés dans l’attribut title des éléments a, et que les éléments a se présentent comme suit :
<a href="..." title="...">
Pour faire correspondre le contenu des guillemets doubles après le titre, utilisez l’expression régulière classique .*?. Le caractère . correspond à un seul caractère, le caractère * correspond à zéro ou plusieurs occurrences de l’élément précédent (dans ce cas, tout ce qui correspond à .), et le caractère ? correspond à zéro ou une occurrence de l’élément précédent (dans ce cas, tout ce qui correspond à .*). Ensemble, ils sont utilisés pour faire correspondre le contenu des guillemets doubles dans cette expression complète :
<a href=".*?" title="(.*?)"
Les parenthèses autour de.*?sont utilisées pour créer ungroupe de capture. Les groupes de capture mémorisent les informations relatives à la correspondance du motif et, dans les expressions complexes, sont utilisés pour identifier et renvoyer aux motifs déjà correspondants. Cependant, dans ce cas, le groupe de capture est utilisé pour extraire le texte correspondant. Sans le groupe de capture, le texte correspondrait toujours, mais vous ne pourriez pas accéder au texte correspondant.
Pour extraire le prix, utilisez la même expression régulière (.*?). Les prix sont stockés dans des éléments p avec la classe price_color, donc l’expression régulière complète est <p class="price_color">(.*?)</p>.
Définissez les deux modèles :
re_book_title = r'<a href=".*?" title="(.*?)"'
re_prices = r'<p class="price_color">(.*?)</p>'
Remarque :si vous vous demandez pourquoi le
?est nécessaire après.*,cette réponse Stack Overflowexplique bien le rôle du?.
Vous pouvez maintenant utiliser re.findall() pour trouver toutes les correspondances d’expressions régulières dans la chaîne HTML :
titles = re.findall(re_book_title, content)
prices = re.findall(re_prices, content)
Enfin, parcourez les correspondances et affichez les résultats :
for i in zip(titles, prices):
print(f"{i[0]}: {i[1]}")
Vous pouvez exécuter ce code avec python scraper.py. Le résultat ressemble à ceci :
A Light in the Attic : 51,77 £
Tipping the Velvet : 53,74 £
Soumission : 50,10 £
Sharp Objects : 47,82 £
Sapiens : A Brief History of Humankind : 54,23 £
The Requiem Red : 22,65 £
The Dirty Little Secrets of Getting Your Dream Job : 33,34 £
The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull : 17,93 £
The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics : 22,60 £
The Black Maria : 52,15 £
Starving Hearts (Triangular Trade Trilogy, #1) : 13,99 £
Les Sonnets de Shakespeare : 20,66 £
Libérez-moi : 17,46 £
La précieuse petite vie de Scott Pilgrim (Scott Pilgrim n° 1) : 52,29 £
Déchirez tout et recommencez : 35,02 £
Notre groupe pourrait être votre vie : Scènes de la scène indie underground américaine, 1981-1991 : 57,25 £
Olio : 23,88 £
Mesaerion : The Best Science Fiction Stories 1800-1849 : 37,59 £
Libertarianism for Beginners : 51,33 £
It's Only the Himalayas : 45,17 £
Récupérer le contenu d’une page Wikipédia
Maintenant, créons un Scraper capable d’extraire unepage Wikipédiaet d’extraire des informations sur tous les liens.
Créez un nouveau fichier nommé wiki_scraper.py. Comme précédemment, commencez par importer les bibliothèques, effectuer une requête GET et réaliser l’analyse du contenu :
import requests
from bs4 import BeautifulSoup
import re
page = requests.get('https://en.wikipedia.org/wiki/Web_scraping')
soup = BeautifulSoup(page.content, 'html.parser')
Pour trouver tous les liens, utilisez la méthode find_all():
links = soup.find_all("a")
content = str(links)
Les textes des liens sont stockés dans l’attribut title, et les URL des liens sont stockées dans l’attribut href. Vous pouvez utiliser la même expression régulière (.*?) pour extraire les informations. L’expression complète ressemble à ceci :
<a href="(.*?)" title="(.*?)">.*?</a>
Notez que le troisième .*? ne se trouve pas dans un groupe de capture, car vous n’êtes pas intéressé par le contenu des balises a.
Comme précédemment, utilisez findall() pour trouver toutes les correspondances et afficher le résultat :
re_links = r'<a href="(.*?)" title="(.*?)">.*?</a>'
links = re.findall(re_links, content)
for i in links:
print(f"{i[0]} => {i[1]}")
Lorsque vous exécutez cela avec python wiki_scraper.py, vous obtenez le résultat suivant :
RÉSULTAT TRONQUÉ POUR PLUS DE CONCISION
/wiki/Category:Scraping web => Category:Scraping web
/wiki/Category:CS1_maint:_multiple_names:_authors_list => Category:CS1 maint: multiple names: authors list
/wiki/Category:CS1_Danish-language_sources_(da) => Category:CS1 Danish-language sources (da)
/wiki/Category:CS1_French-language_sources_(fr) => Category:CS1 French-language sources (fr)
/wiki/Catégorie:Articles_avec_description_courte => Catégorie:Articles avec description courte
/wiki/Catégorie:Description_courte_correspondant_à_Wikidata => Catégorie:Description courte correspondant à Wikidata
/wiki/Catégorie:Articles_nécessitant_des_références_supplémentaires_à_partir_d'avril_2023 => Catégorie:Articles nécessitant des références supplémentaires à partir d'avril 2023
/wiki/Category:All_articles_needing_additional_references => Catégorie : Tous les articles nécessitant des références supplémentaires
/wiki/Category:Articles_with_limited_geographic_scope_from_October_2015 => Catégorie : Articles à portée géographique limitée à partir d'octobre 2015
/wiki/Catégorie:Centré sur les États-Unis => Catégorie:Centré sur les États-Unis
/wiki/Catégorie:Tous les articles avec des déclarations non sourcées => Catégorie:Tous les articles avec des déclarations non sourcées
/wiki/Catégorie:Articles avec des déclarations non sourcées à partir d'avril 2023 => Catégorie:Articles avec des déclarations non sourcées à partir d'avril 2023
Récupération de données sur un site dynamique
Jusqu’à présent, toutes les pages web que vous avez scrapées étaient statiques. Le scraping de pages web dynamiques est un peu plus difficile, car il nécessite un outil d’automatisation du navigateur tel queSelenium. Voici un exemple de scraping de la page d’accueild’OpenWeatherMappour Londres et d’utilisation de regex et Selenium pour scraper la température actuelle :
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
driver = webdriver.Firefox()
driver.get("https://openweathermap.org/city/2643743")
elem = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.CSS_SELECTOR, ".current-temp")))
content = elem.get_attribute('innerHTML')
re_temp = r'<span .*?>(.*?)</span>'
temp = re.findall(re_temp, content)
print(repr(temp))
driver.close()
Ce code utilise Selenium pour lancer une instance de Firefox et utilise le sélecteur CSS pour sélectionner l’élément contenant la température actuelle. Il utilise ensuite l’expression régulière <span .*?>(.*?)</span> pour extraire la température.
Si vous recherchez davantage d’informations pour vous aider à démarrer avec le scraping web de pages web dynamiques avec Selenium, consultezce tutoriel.
Limites des expressions régulières pour le Scraping web
Les expressions régulières sont des outils puissants pour la recherche de motifs et l’extraction d’informations à partir de textes. Les développeurs apprennent souvent les expressions régulières et essaient de les utiliser pour le Scraping web. Cependant, les expressions régulières ne sont pas adaptées au Scraping web. Elles fonctionnent sur du texte et n’ont aucune connaissance des structures HTML. Cela signifie que les résultats dépendent fortement de la façon dont le code HTML est écrit. Par exemple, dans l’exemple Wikipédia, vous avez peut-être remarqué que certains liens n’ont pas été extraits correctement :

Si vous modifiez le code Python et ajoutez print(content) pour imprimer la chaîne HTML renvoyée par Beautiful Soup, vous verrez que le coupable ressemble à ceci :
<a href="#cite_ref-9">^</a>
Ici, l’attribut title est manquant, mais dans l’expression régulière, vous avez supposé la structure <a href="(.*?)" title="(.*?)">.*?</a>. Comme l’expression régulière n’a aucune connaissance des éléments HTML, au lieu de générer une erreur ou d’arrêter la correspondance, le motif .*? a continué à faire correspondre aveuglément les caractères jusqu’à ce qu’il puisse faire correspondre « title="(.*?)">.*?</a> » pour terminer le motif. Cela a fini par engloutir les balises a suivantes et montre que l’utilisation d’expressions régulières peut avoir des effets indésirables si le code HTML est écrit d’une manière inattendue.
De plus, le HTML n’est pas un langage régulier, ce qui signifie que les expressions régulières ne peuvent pas être utilisées seules pour analyser des données HTML arbitraires. Cetteréponse Stack Overflowest un classique culte parmi les développeurs pour se moquer des développeurs qui tentent d’analyser le HTML avec des expressions régulières. Cependant, il existe quelques situations où vous pouvez utiliser des expressions régulières pour analyser et extraire des données HTML.
Par exemple, si vous disposez d’un ensemble connu et limité de code HTML et que vous connaissez parfaitement la structure du code, vous pouvez utiliser des expressions régulières. Par exemple, si vous savez que toutes les balises a du code HTML ont les attributs href et title et se conforment à un modèle fixe, vous pouvez utiliser des expressions régulières pour extraire des informations. Cependant, une solution meilleure et plus robuste consiste à utiliser un analyseur HTML tel que Beautiful Soup pour trouver des éléments et en extraire des données textuelles.
Une fois les données textuelles extraites, vous pouvez utiliser des expressions régulières pour les traiter davantage. Voici par exemple une version modifiée du Scraper Wikipédia qui utilise Beautiful Soup pour extraire les attributs href et title, puis utilise des expressions régulières pour filtrer toutes les balises contenant des caractères non alphanumériques :
import requests
from bs4 import BeautifulSoup
import re
page = requests.get('https://en.wikipedia.org/wiki/Web_scraping')
soup = BeautifulSoup(page.content, 'html.parser')
links = soup.find_all("a")
for link in links:
href = link.get('href')
title = link.get('title')
if title == None:
title = link.string
if title == None:
continue
pattern = r"[a-zA-Z0-9]"
if re.match(pattern, title):
print(f"{href} => {title}")
Conclusion
Regex est un outil puissant pour trouver des modèles dans des données textuelles. Grâce à sa robustesse, il est souvent utilisé dans le Scraping web pour extraire des informations.
Dans cet article, vous avez appris ce qu’est regex et comment l’utiliser avec Beautiful Soup pour scraper des sites web de commerce électronique, Wikipédia et des pages web dynamiques. Vous avez également découvert certaines des limites de regex et comment l’utiliser au mieux en combinaison avec un autre outil.
Même si vous utilisez pleinement Regex, le Scraping web comporte de nombreux défis. Un Scraping web répété peut entraîner le blocage de l’adresse IP de votre Scraper. Vous pouvez également être confronté à des CAPTCHA qui peuvent empêcher votre Scraper de fonctionner correctement. Bright Datapropose des proxys puissants qui permettent de contourner les interdictions d’IP. Son réseau mondial de proxys comprenddes proxys de centres de données,des proxys résidentiels,des proxys ISP etdes proxys mobiles. AvecWeb Unlocker, vous pouvez contourner la détection des bots et résoudre les CAPTCHA sans aucun problème. Commencez un essai gratuit dès aujourd’hui !





