

Dans ce tutoriel guidé, vous découvrirez :
- Une vue d’ensemble de RAG et de ses mécanismes
- Les avantages de l’intégration des données SERP dans GPT-4o à travers RAG
- Comment implémenter un chatbot Python RAG en utilisant les modèles OpenAI GPT et les données SERP.
Plongeons dans l’aventure !
Qu’est-ce que RAG ?
RAG, abréviation de Retrieval-Augmented Generation, est une approche IA qui combine la recherche d’informations avec la génération de texte. Dans un flux de travail RAG, l’application récupère d’abord les données pertinentes à partir de sources externes, telles que des documents, des pages Web ou des bases de données. Elle transmet ensuite les données aux modèles IA afin qu’ils puissent générer des réponses plus pertinentes sur le plan contextuel.
RAG améliore les grands modèles de langage (LLM) tels que GPT en leur permettant d’accéder à des informations actualisées et de les référencer au-delà de leurs données d’apprentissage d’origine. Cette approche est essentielle dans les scénarios où des informations précises et contextuelles sont nécessaires, car elle améliore à la fois la qualité et la précision des réponses générées par l’IA.
Pourquoi alimenter les modèles IA avec des données SERP ?
La date limite de connaissance pour GPT-4o est octobre 2023, ce qui signifie qu’il n’a pas accès aux événements ou aux informations qui ont été publiés après cette date. Cependant, les modèles GPT-4o peuvent extraire des données d’Internet en temps réel grâce à l’intégration de la recherche Bing. Cela leur permet d’offrir des informations plus récentes.
Mais qu’en est-il si vous souhaitez que le modèle IA utilise des sources de données spécifiques ou préfère des moteurs de recherche plus fiables ? C’est là que RAG entre en jeu !
En particulier, l’alimentation des modèles IA en données SERP(page de résultats des moteurs de recherche) via RAG est un excellent moyen d’obtenir de meilleures réponses. Cette approche est particulièrement bénéfique pour les tâches qui nécessitent des informations actuelles ou des connaissances spécialisées.
En bref, le transfert de données provenant de résultats de recherche bien classés à GPT-4o ou GPT-4o mini permet d’obtenir des réponses détaillées, précises et riches en contexte.
RAG avec des données SERP avec des modèles GPT en utilisant Python : Tutoriel étape par étape
Dans ce tutoriel, vous apprendrez à construire un chatbot RAG en utilisant les modèles GPT d’OpenAI. L’idée est de rassembler le texte des pages les plus performantes sur Google pour une recherche spécifique et de l’utiliser comme contexte pour une requête GPT.
Le plus grand défi consiste à récupérer les données des SERP. En effet, la plupart des moteurs de recherche disposent de solutions anti-bots avancées pour empêcher l’accès automatisé à leurs pages. Pour obtenir des conseils détaillés, consultez notre guide sur la manière de récupérer les données de Google en Python.
Pour simplifier le processus de scraping, nous utiliserons l ‘API SERP de Bright Data:
Ce SERP scraper premium vous permet de récupérer facilement les SERP de Google, DuckDuckGo, Bing, Yandex, Baidu et d’autres moteurs de recherche à l’aide de simples requêtes HTTP.
Nous extrairons ensuite les données textuelles des URL renvoyées à l’aide d’un navigateur sans tête. Nous utiliserons ensuite ces informations comme contexte pour le modèle GPT dans un flux de travail RAG. Si vous souhaitez plutôt récupérer des données en ligne directement à l’aide de l’IA, lisez notre article sur le Scraping web avec ChatGPT.
Si vous êtes impatient d’explorer le code ou si vous voulez le garder à portée de main pendant que vous suivez les étapes ci-dessous, clonez le dépôt GitHub qui supporte cet article :
git clone https://github.com/Tonel/rag_gpt_serp_scrapingSuivez les instructions du fichier README.md pour installer les dépendances du projet et le lancer.
Gardez à l’esprit que l’approche présentée dans cet article de blog peut facilement être adaptée à tout autre moteur de recherche ou LLM.
Remarque: ce guide se réfère à Unix et macOS. Si vous êtes un utilisateur de Windows, vous pouvez toujours suivre le tutoriel en utilisant le Windows Subsystem for Linux(WSL).
Étape 1 : Initialiser un projet Python
Assurez-vous que Python 3 est installé sur votre machine. Sinon, téléchargez-le et installez-le.
Créez un dossier pour votre projet et entrez-le dans le terminal :
mkdir rag_gpt_serp_scraping
cd rag_gpt_serp_scrapingLe dossier rag_gpt_serp_scraping contiendra votre projet Python RAG.
Ensuite, chargez le répertoire du projet dans votre IDE Python préféré. PyCharm Community Edition ou Visual Studio Code avec l’extension Python feront l’affaire.
Dans rag_gpt_serp_scraping, ajoutez un fichier app.py vide. Il contiendra votre logique de scraping et de RAG.
Ensuite, initialisez un environnement virtuel Python dans le répertoire du projet :
python3 -m venv envActivez l’environnement virtuel avec la commande ci-dessous :
source ./env/bin/activateC’est génial ! Vous êtes maintenant complètement prêt.
Étape 2 : Installer les bibliothèques nécessaires
Les dépendances utilisées par ce projet Python RAG basé sur les modèles GPT sont :
python-dotenv: Pour charger les variables d’environnement à partir d’un fichier .env. Il sera utilisé pour gérer de manière sécurisée les informations d’identification sensibles, telles que les informations d’identification de Bright Data et les clés d’API OpenAI.requests: Pour effectuer des requêtes HTTP à l’API SERP de Bright Data. Pour plus d’informations, consultez notre guide sur l ‘utilisation d’un proxy avec Requests.langchain-community: Ceci fait partie du cadre LangChain, un ensemble d’outils pour construire avec des LLM en enchaînant des composants interopérables. Il sera utilisé pour récupérer le texte des pages SERP de Google et le nettoyer afin de générer un contenu pertinent pour RAG.openai: La bibliothèque client Python officielle pour l’API OpenAI. Elle sera utilisée pour interfacer avec les modèles GPT afin de générer des réponses en langage naturel basées sur les entrées données et le contexte RAG.streamlit: Un cadre pour construire des applications web interactives en Python. Il sera utile pour créer une interface utilisateur dans laquelle les utilisateurs peuvent saisir leurs requêtes de recherche Google et leurs invites IA, et afficher les résultats de manière dynamique.
Dans un environnement virtuel activé, lancez la commande ci-dessous pour installer toutes les dépendances :
pip install python-dotenv requests langchain-community openai streamlitEn détail, nous allons utiliser AsyncChromiumLoader de langchain-community, qui nécessite les dépendances suivantes :
pip install --upgrade --quiet playwright beautifulsoup4 html2textPour fonctionner correctement, Playwright nécessite également l’installation des navigateurs avec :
playwright installL’installation de toutes ces bibliothèques prendra un certain temps, alors soyez patient.
Fantastique ! Vous êtes prêt à écrire votre logique Python.
Étape 3 : Préparer votre projet
Dans app.py, ajoutez les importations suivantes :
from dotenv import load_dotenv
import os
import requests
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
from openai import OpenAI
import streamlit as stEnsuite, créez un fichier .env dans le dossier de votre projet pour stocker toutes vos informations d’identification. La structure de votre projet ressemblera alors à ce qui suit :

Utilisez la fonction ci-dessous dans app.py pour demander à python-dotenv de charger les variables d’environnement à partir de .env :
load_dotenv()Vous pouvez maintenant importer des variables d’environnement à partir de .env ou du système avec :
os.environ.get("<ENV_NAME>")C’est aussi la raison pour laquelle nous avons importé la bibliothèque standard Python os.
Etape #4 : Configurer l’API SERP
Comme indiqué dans l’introduction, nous nous appuierons sur l’API SERP de Bright Data pour récupérer le contenu des pages de résultats des moteurs de recherche et l’utiliser dans notre flux de travail RAG Python. Plus précisément, nous extrairons le texte des URL des pages Web renvoyées par l’API SERP.
Pour configurer l’API SERP, reportez-vous à la documentation officielle. Vous pouvez également suivre les instructions ci-dessous.
Si vous n’avez pas encore créé de compte, inscrivez-vous à Bright Data. Une fois connecté, accédez au tableau de bord de votre compte :

Cliquez sur le bouton “Obtenir des produits Proxy”.
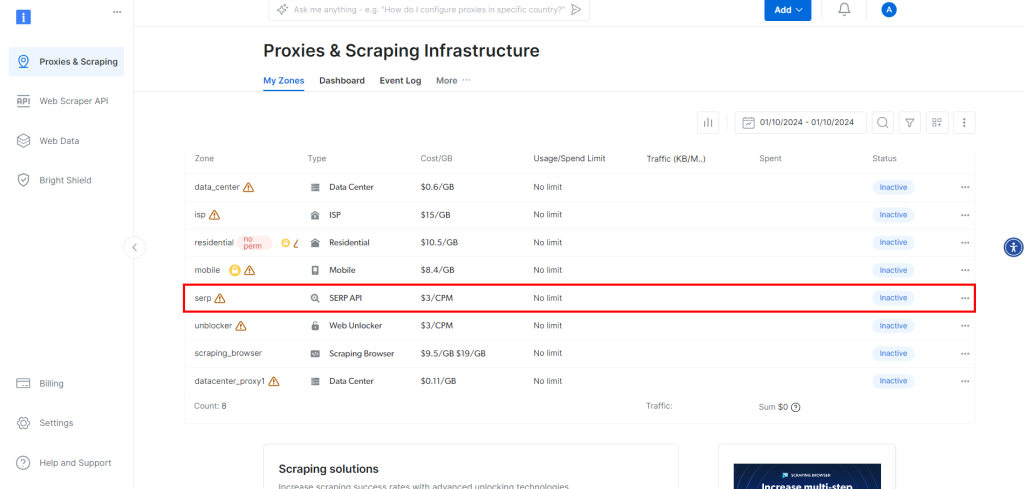
Cela vous amènera à la page ci-dessous, où vous devez cliquer sur la ligne “API SERP” :
Sur la page du produit API SERP, cochez la case “Activer la zone” pour activer le produit :
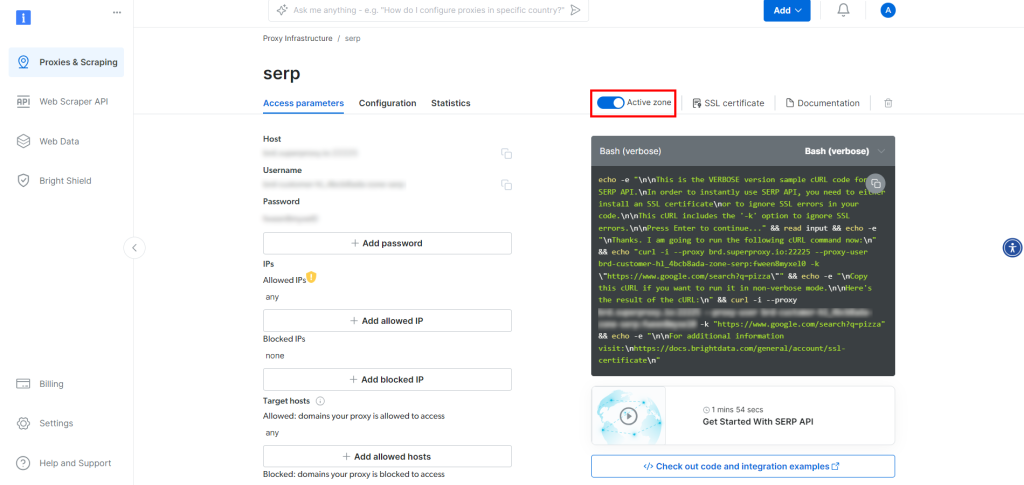
Maintenant, copiez l’hôte, le port, le nom d’utilisateur et le mot de passe de l’API SERP dans la section “Paramètres d’accès” et ajoutez-les à votre fichier .env:
BRIGHT_DATA_SERP_API_HOST="<VOTRE_HÔTE>"
BRIGHT_DATA_SERP_API_PORT=<VOTRE_PORT>
BRIGHT_DATA_SERP_API_USERNAME="<VOTRE_NOM_D'UTILISATEUR>"
BRIGHT_DATA_SERP_API_PASSWORD="<VOTRE_MOT_DE_PASSE>"Remplacez les caractères génériques <YOUR_XXXX> par les valeurs fournies par Bright Data sur la page API SERP.
Notez que l’hôte dans les “Paramètres d’accès” a un format comme celui-ci :
brd.superproxy.io:33335Vous devez le diviser comme suit :
BRIGHT_DATA_SERP_API_HOST="brd.superproxy.io"
BRIGHT_DATA_SERP_API_PORT=33335Génial ! Vous pouvez maintenant utiliser l’API SERP en Python.
Étape #5 : Implémenter la logique de scraping SERP
Dans app.py, ajoutez la fonction suivante pour récupérer le premier nombre d' URLs d’une page SERP de Google :
def get_google_serp_urls(query, number_of_urls=5) :
# effectuer une demande d'API SERP de Bright Data
# avec analyse automatique de JSON
host = os.environ.get("BRIGHT_DATA_SERP_API_HOST")
port = os.environ.get("BRIGHT_DATA_SERP_API_PORT")
username = os.environ.get("BRIGHT_DATA_SERP_API_USERNAME")
password = os.environ.get("BRIGHT_DATA_SERP_API_PASSWORD")
proxy_url = f "http://{nom d'utilisateur}:{mot de passe}@{hôte}:{port}"
proxies = {"http" : proxy_url, "https" : proxy_url}
url = f "https://www.google.com/search?q={query}&brd_json=1"
response = requests.get(url, proxies=proxies, verify=False)
# récupérer la réponse JSON analysée
response_data = response.json()
# extraire un nombre "number_of_urls" de
# Google SERP URLs de la réponse
google_serp_urls = []
if "organic" in response_data :
for item in response_data["organic"] :
si "link" dans item :
google_serp_urls.append(item["link"])
return google_serp_urls[:number_of_urls]Cette commande envoie une requête HTTP GET à l’API SERP avec la demande de recherche spécifiée dans l’argument query. Le paramètre de requête brd_json=1 garantit que l’API SERP analyse les résultats en JSON pour vous, dans le format ci-dessous :
{
"general" : {
"search_engine" : "google",
"results_cnt" : 1980000000,
"search_time" : 0.57,
"language" : "en",
"mobile" : false,
"basic_view" : false,
"search_type" : "texte",
"page_title" : "Pizza - Recherche Google",
"code_version" : "1.90",
"timestamp" : "2023-06-30T08:58:41.786Z"
},
"input" : {
"original_url" : "https://www.google.com/search?q=pizza&brd_json=1",
"user_agent" : "Mozilla/5.0 (Macintosh ; Intel Mac OS X 10_12) AppleWebKit/608.2.11 (KHTML, like Gecko) Version/13.0.3 Safari/608.2.11",
"request_id" : "hl_1a1be908_i00lwqqxt1"
},
"organic" : [
{
"link" : "https://www.pizzahut.com/",
"display_link" : "https://www.pizzahut.com",
"title" : "Pizza Hut | Livraison et vente à emporter - Personne ne sortPizzas The Hut !",
"image" : "omis par souci de concision...",
"image_alt" : "pizza de www.pizzahut.com",
"image_base64" : "omis pour des raisons de brièveté...",
"rang" : 1,
"global_rank" : 1
},
{
"link" : "https://www.dominos.com/en/",
"display_link" : "https://www.dominos.com ' ...",
"title" : "Domino's : Livraison de pizzas et plats à emporter, pâtes, poulet et plus encore",
"description" : "Le site internet de Domino's permet de commander en ligne des pizzas, des pâtes, des sandwichs et bien d'autres choses encore, à emporter ou à livrer. Voir le menu, trouver les emplacements, suivre les commandes. Inscrivez-vous pour recevoir les e-mails de Domino's ...",
"image" : "omis pour des raisons de concision...",
"image_alt" : "pizza de www.dominos.com",
"image_base64" : "omis pour des raisons de brièveté...",
"rang" : 2,
"global_rank" : 3
},
// omis par souci de concision...
],
// omis par souci de concision...
}Les dernières lignes de la fonction récupèrent chaque URL de SERP à partir des données JSON résultantes, sélectionnent uniquement les premières URL number_of_urls et les renvoient dans une liste.
Il est temps d’extraire le texte de ces URLs !
Étape n° 6 : Extraire le texte des URL des SERP
Définissez une fonction qui extrait le texte de chaque URL de SERP :
def extract_text_from_urls(urls, number_of_words=600) :
# demande à une instance de Chrome sans tête de visiter les URLs fournies
# avec le user-agent spécifié
loader = AsyncChromiumLoader(
urls,
user_agent="Mozilla/5.0 (Windows NT 10.0 ; Win64 ; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36",
)
html_documents = loader.load()
# traiter les documents HTML extraits pour en extraire le texte
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
html_documents,
tags_to_extract=["p", "em", "li", "strong", "h1", "h2"],
unwanted_tags=["a"],
remove_comments=True,
)
# s'assurer que chaque document texte HTML ne contient qu'un nombre
# nombre_de_mots mots
liste_texte_extrait = []
pour doc_transformed dans docs_transformed :
# diviser le texte en mots et joindre le premier nombre_de_mots
words = doc_transformed.page_content.split()[:nombre_de_mots]
texte_extrait = " ".join(words)
# ignorer les documents texte vides
si len(texte_extrait) != 0 :
liste_texte_extrait.append(texte_extrait)
return extracted_text_listCette fonction :
- Charge des pages web à partir des URL passées en argument en utilisant une instance de navigateur Chrome sans tête.
- Utilise BeautifulSoupTransformer pour traiter le HTML de chaque page et extraire le texte de balises spécifiques (comme <p>, <h1>, <strong>, etc.), en omettant les balises non désirées (comme <a>) et les commentaires.
- Limite le texte extrait pour chaque page web à un nombre de mots spécifié par l’argument
nombre_de_mots. - Renvoie une liste du texte extrait de chaque URL.
Gardez à l’esprit que les balises [“p”, “em”, “li”, “strong”, “h1”, “h2”] suffisent à extraire le texte de la plupart des pages web. Toutefois, dans certains cas spécifiques, vous devrez peut-être personnaliser cette liste de balises HTML. Il se peut également que vous deviez augmenter ou diminuer le nombre cible de mots pour chaque élément de texte.
Prenons l’exemple de la page web ci-dessous:

En appliquant cette fonction à cette page, vous obtiendrez le tableau de texte suivant :
["La critique de Lisa Johnson Mandell sur Transformers One révèle l'inconcevable : C'est l'un des meilleurs films d'animation de l'année ! Je n'aurais jamais cru me voir écrire cela un jour à propos d'un film de Transformers, mais Transformers One est en fait un film exceptionnel ! ..."]Incroyable ! Même s’il n’est pas parfait, il reste d’une grande qualité pour les standards des modèles de l’IA.
La liste des éléments textuels renvoyés par extract_text_from_urls() représente le contexte RAG à fournir au modèle OpenAI.
Étape 7 : Générer l’invite RAG
Définir une fonction qui transforme la demande d’invite IA et le contexte textuel en l’invite RAG finale :
def get_openai_prompt(request, text_context=[]) :
# invite par défaut
prompt = demande
# ajoute le contexte à l'invite, s'il est présent
si len(text_context) != 0 :
chaîne_contexte = "nn--------nn".join(texte_contexte)
prompt = f "Répondre à la demande en utilisant uniquement le contexte ci-dessous.nnContext:n{chaîne_contexte}nnRequest : {request}"
return promptLes invites renvoyées par la fonction précédente lorsqu’un contexte RAG est spécifié ont ce format :
Répondre à la demande en utilisant uniquement le contexte ci-dessous.
Contexte :
Bla bla bla...
--------
Bla bla bla...
--------
Bla bla bla...
Demande : <Votre_requête>Étape #8 : Effectuer la requête GPT
Tout d’abord, initialiser le client OpenAI au début du fichier app.py:
openai_client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))Ceci repose sur la variable d’environnement OPENAI_API_KEY, que vous pouvez définir directement dans les environnements de votre système ou dans le fichier .env:
OPENAI_API_KEY="<VOTRE_CLÉ_API>"
Remplacez <Votre_clé_API> par la valeur de votre clé d’API OpenAI. Si vous ne savez pas comment en obtenir une, suivez le guide officiel.
Ensuite, écrivez une fonction qui utilise le client officiel OpenAI pour effectuer une requête au modèle d’IA GPT-4o mini:
def interrogate_openai(prompt, max_tokens=800) :
# interroge le modèle OpenAI avec l'invite donnée
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role" : "user", "content" : prompt}],
max_tokens=max_tokens,
)
return response.choices[0].message.contentNotez que vous pouvez configurer n’importe quel autre modèle GPT pris en charge par l’API OpenAI.
Si elle est appelée avec une invite renvoyée par get_openai_prompt() qui inclut un contexte textuel spécifié, interrogate_openai() exécutera avec succès la génération augmentée par récupération comme prévu.
Étape 9 : Créer l’interface utilisateur de l’application
Utilisez Streamlit pour définir une interface utilisateur simple où les utilisateurs peuvent spécifier :
- La requête de recherche Google à transmettre à l’API SERP
- L’invite IA à envoyer à GPT-4o mini
Réalisez cela avec ces lignes de code :
avec st.form("prompt_form") :
# initialiser les résultats de sortie
result = ""
final_prompt = ""
# zone de texte pour que l'utilisateur puisse saisir sa requête de recherche Google
google_search_query = st.text_area("Google Search :", None)
# zone de texte permettant à l'utilisateur de saisir son invitation à l'IA
request = st.text_area("IA Prompt :", None)
# bouton pour soumettre le formulaire
submitted = st.form_submit_button("Send")
# si le formulaire est soumis
si soumis :
# récupérer les URL des SERP de Google à partir de la requête de recherche donnée
google_serp_urls = get_google_serp_urls(google_search_query)
# extrait le texte des pages HTML respectives
extracted_text_list = extract_text_from_urls(google_serp_urls)
# générer l'invite IA en utilisant le texte extrait comme contexte
final_prompt = get_openai_prompt(request, extracted_text_list)
# interroger un modèle OpenAI avec le message généré
result = interrogate_openai(final_prompt)
# liste déroulante contenant l'invite générée
final_prompt_expander = st.expander("IA Final Prompt :")
final_prompt_expander.write(final_prompt)
# écrire le résultat du modèle OpenAI
st.write(result)Nous y voilà ! Le script Python RAG est prêt.
Etape #10 : Assembler le tout
Votre fichier app.py devrait contenir le code suivant :
from dotenv import load_dotenv
import os
import requests
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
from openai import OpenAI
import streamlit as st
# charger les variables d'environnement à partir du fichier .env
load_dotenv()
# initialiser le client API OpenAI avec votre clé API
openai_client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
def get_google_serp_urls(query, number_of_urls=5) :
# effectue une requête d'API SERP de Bright Data
# avec analyse automatique de JSON
host = os.environ.get("BRIGHT_DATA_SERP_API_HOST")
port = os.environ.get("BRIGHT_DATA_SERP_API_PORT")
username = os.environ.get("BRIGHT_DATA_SERP_API_USERNAME")
password = os.environ.get("BRIGHT_DATA_SERP_API_PASSWORD")
proxy_url = f "http://{nom d'utilisateur}:{mot de passe}@{hôte}:{port}"
proxies = {"http" : proxy_url, "https" : proxy_url}
url = f "https://www.google.com/search?q={query}&brd_json=1"
response = requests.get(url, proxies=proxies, verify=False)
# récupérer la réponse JSON analysée
response_data = response.json()
# extraire un nombre "number_of_urls" de
# Google SERP URLs de la réponse
google_serp_urls = []
if "organic" in response_data :
for item in response_data["organic"] :
si "link" dans item :
google_serp_urls.append(item["link"])
return google_serp_urls[:number_of_urls]
def extract_text_from_urls(urls, number_of_words=600) :
# demande à une instance de Chrome sans tête de visiter les URLs fournies
# avec l'agent utilisateur spécifié
loader = AsyncChromiumLoader(
urls,
user_agent="Mozilla/5.0 (Windows NT 10.0 ; Win64 ; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36",
)
html_documents = loader.load()
# traiter les documents HTML extraits pour en extraire le texte
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
html_documents,
tags_to_extract=["p", "em", "li", "strong", "h1", "h2"],
unwanted_tags=["a"],
remove_comments=True,
)
# s'assurer que chaque document texte HTML ne contient qu'un nombre
# nombre_de_mots mots
liste_texte_extrait = []
pour doc_transformed dans docs_transformed :
# diviser le texte en mots et joindre le premier nombre_de_mots
words = doc_transformed.page_content.split()[:nombre_de_mots]
texte_extrait = " ".join(words)
# ignorer les documents texte vides
si len(texte_extrait) != 0 :
liste_texte_extrait.append(texte_extrait)
return extracted_text_list
def get_openai_prompt(request, text_context=[]) :
# invite par défaut
prompt = demande
# ajoute le contexte à l'invite, s'il est présent
si len(text_context) != 0 :
chaîne_contexte = "nn--------nn".join(texte_contexte)
prompt = f "Répondre à la demande en utilisant uniquement le contexte ci-dessous.nnContext:n{chaîne_contexte}nnRequest : {request}"
return prompt
def interrogate_openai(prompt, max_tokens=800) :
# interroge le modèle OpenAI avec l'invite donnée
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role" : "user", "content" : prompt}],
max_tokens=max_tokens,
)
return response.choices[0].message.content
# créer un formulaire dans l'application Streamlit pour l'entrée de l'utilisateur
avec st.form("prompt_form") :
# initialiser les résultats de sortie
result = ""
final_prompt = ""
# zone de texte pour que l'utilisateur puisse saisir sa requête de recherche Google
google_search_query = st.text_area("Google Search :", None)
# zone de texte permettant à l'utilisateur de saisir son invitation à l'IA
request = st.text_area("IA Prompt :", None)
# bouton pour soumettre le formulaire
submitted = st.form_submit_button("Send")
# si le formulaire est soumis
si soumis :
# récupérer les URL des SERP de Google à partir de la requête de recherche donnée
google_serp_urls = get_google_serp_urls(google_search_query)
# extrait le texte des pages HTML respectives
extracted_text_list = extract_text_from_urls(google_serp_urls)
# générer l'invite IA en utilisant le texte extrait comme contexte
final_prompt = get_openai_prompt(request, extracted_text_list)
# interroger un modèle OpenAI avec le message généré
result = interrogate_openai(final_prompt)
# liste déroulante contenant l'invite générée
final_prompt_expander = st.expander("IA Final Prompt")
final_prompt_expander.write(final_prompt)
# écrire le résultat du modèle OpenAI
st.write(result)Pouvez-vous le croire ? En moins de 150 lignes de code, vous pouvez réaliser un RAG en utilisant Python !
Étape 11 : Tester l’application
Lancez votre application Python RAG avec :
streamlit run app.pyDans le terminal, vous devriez voir la sortie suivante :
Vous pouvez maintenant visualiser votre application Streamlit dans votre navigateur.
URL locale : http://localhost:8501
URL réseau : http://172.27.134.248:8501Suivez les instructions et visitez http://localhost:8501 dans le navigateur. Voici ce que vous devriez voir :

Comme vous pouvez le constater, le formulaire contient les zones de texte “Google Search :” et “IA Prompt :” définies dans le code, ainsi que le bouton “Envoyer” et la liste déroulante “IA Final Prompt”.
Testez l’application en utilisant une requête de recherche Google comme ci-dessous :
Transformers One reviewEt une invite de l’IA comme suit :
Écrire une critique du film Transformers OneCliquez sur “Envoyer” et attendez que votre application traite la requête. Après quelques secondes, vous devriez obtenir un résultat comme celui-ci :
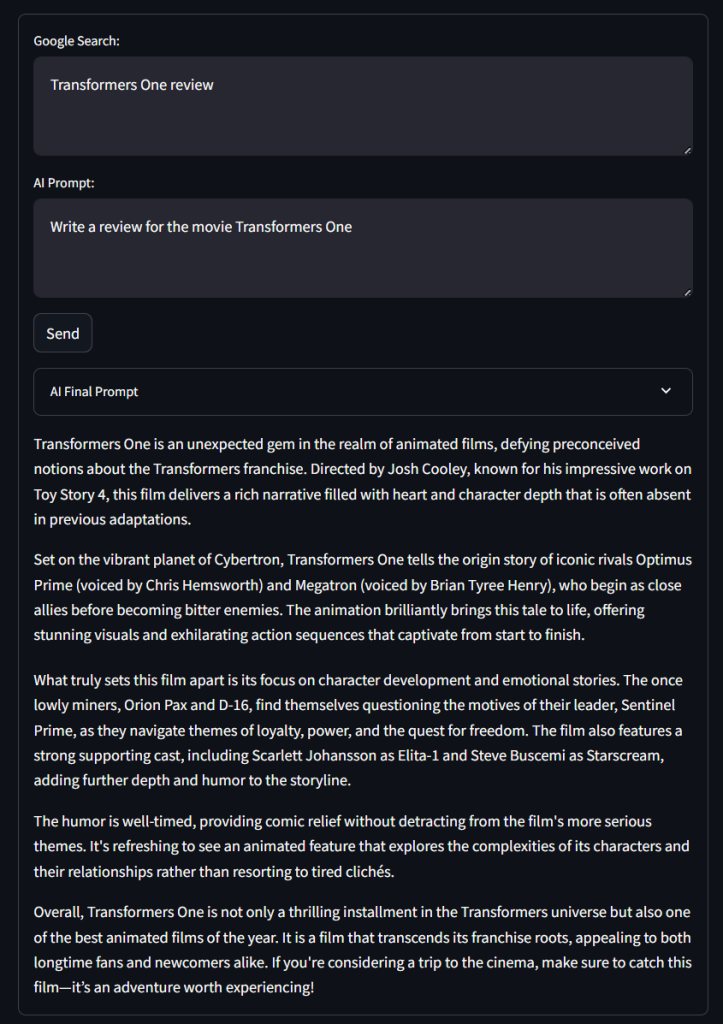
Ouah ! Ce n’est pas une mauvaise critique…
Si vous développez le menu déroulant “IA Final Prompt”, vous verrez l’invite complète utilisée par l’application pour RAG.
Et voilà ! Vous venez d’implémenter un chatbot RAG en Python avec GPT-4o mini en utilisant les données SERP.
Conclusion
Dans ce tutoriel, vous avez exploré ce qu’est le RAG et comment il peut être réalisé en alimentant des modèles IA avec des données SERP. Plus précisément, vous avez appris à construire un chatbot Python RAG qui récupère les données SERP et les utilise dans les modèles GPT pour améliorer la précision des résultats.
La principale difficulté de cette approche réside dans la récupération des données des moteurs de recherche tels que Google, qui modifient fréquemment la structure de leurs SERP :
- Ils modifient fréquemment la structure de leurs pages SERP.
- Ils sont protégés par des mesures anti-bots parmi les plus sophistiquées qui soient.
- L’extraction simultanée de grands volumes de données SERP est complexe et peut coûter très cher.
Comme indiqué ici, l ‘API SERP de Bright Data vous permet d’extraire en temps réel les données SERP de tous les principaux moteurs de recherche, sans aucun effort. Cette API prend en charge RAG et de nombreuses autres applications. Obtenez votre essai gratuit maintenant !
Inscrivez-vous dès maintenant pour découvrir les services de proxy ou les produits de scraping de Bright Data qui répondent le mieux à vos besoins. Essai gratuit !





