

Dans ce tutoriel, nous allons apprendre à scraper Amazon à l’aide de Bright Data et d’un projet de scraping prêt à l’emploi.
Nous aborderons les thèmes suivants :
- Comment utiliser l’API Amazon Scraper
- La mise en place d’un projet et la configuration des cibles de scraping Amazon
- Récupération et rendu des pages Amazon
- Comment extraire les données produit à partir des pages de recherche et des pages produit
- Scraping d’Amazon à l’aide du Web MCP de Bright Data avec Claude Desktop
Pourquoi scraper Amazon ?
Amazon est la plus grande place de marché de produits au monde et l’une des sources les plus riches de données commerciales en temps réel sur Internet. Des tendances en matière de prix à l’opinion des clients, la plateforme reflète le comportement du marché à une échelle que peu d’autres sites web peuvent égaler.
Le scraping d’Amazon permet aux équipes d’aller au-delà de la recherche manuelle et des jeux de données statiques, et de prendre des décisions automatisées et basées sur les données à grande échelle.
Cas d’utilisation courants du scraping d’Amazon
Voici quelques-unes des raisons les plus courantes pour lesquelles les entreprises et les développeurs scrappent Amazon :
- Surveillance des prix et intelligence compétitive : suivez les prix des produits, les remises et la disponibilité des stocks pour toutes les catégories et tous les vendeurs en temps quasi réel.
- Étude de marché et des produits : analyser les listes de produits, les catégories et les classements des meilleures ventes afin d’identifier les tendances de la demande et les nouvelles opportunités.
- Analyse des avis et des sentiments : collecter les avis et les notes des clients pour comprendre le sentiment des acheteurs, les performances des produits et les lacunes en matière de fonctionnalités.
- Applications basées sur l’IA : alimenter les LLM et les agents IA avec les données Amazon en temps réel pour des tâches telles que les assistants d’achat, les modèles de tarification dynamique et l’analyse automatisée du marché.
Les cas d’utilisation étant clairs, nous pouvons maintenant passer à la pratique et découvrir comment extraire des données d’Amazon avec Bright Data.
Scraping d’Amazon avec l’API Amazon Scraper de Bright Data
En plus de créer des scrapers personnalisés ou d’utiliser MCP avec Claude, Bright Data propose également une API Amazon Scraper gérée. Vous aurez besoin de votre clé API pour l’authentification.
Choisir un scraper Amazon
Commencez par ouvrir la bibliothèque de scrapers Bright Data.
Dans la liste des scrapers disponibles, sélectionnez celui qui correspond à votre cas d’utilisation, par exemple :
- Détails du produit par ASIN
- Résultats de recherche
- Avis
Chaque scraper est conçu pour un type spécifique de données Amazon.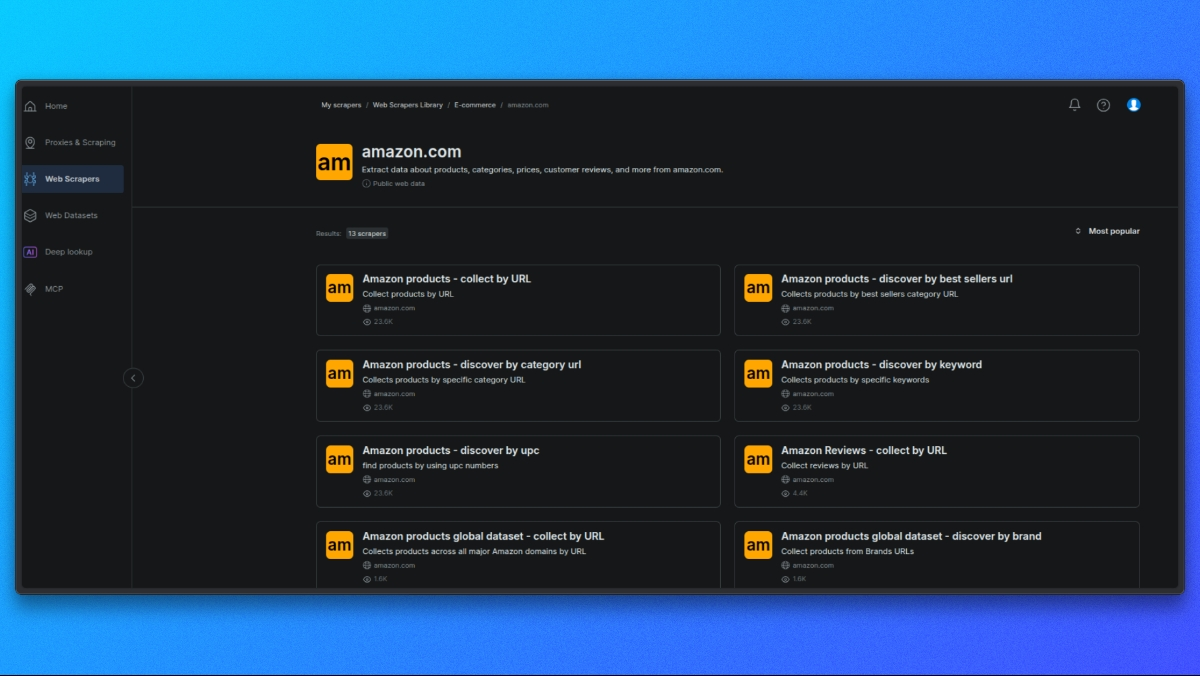
Sélectionnez le point de terminaison du scraper
Chaque scraper propose différents points de terminaison en fonction des données que vous souhaitez obtenir (par exemple, détails du produit, résultats de recherche, avis).
Cliquez sur le point de terminaison qui correspond à votre cas d’utilisation.
Créez votre requête
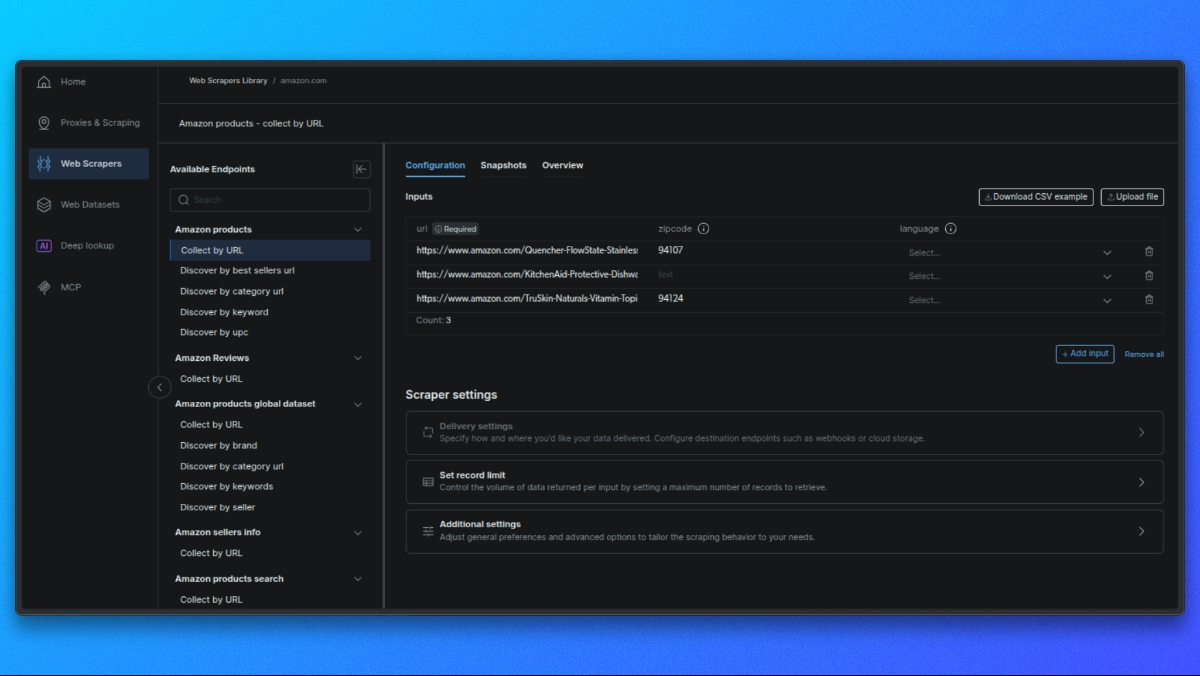
Dans le panneau central, vous verrez un formulaire permettant de configurer votre requête :
- Saisie unique : collez l’URL d’un produit, l’ASIN ou un mot-clé.
- CSV en masse : téléchargez un fichier CSV contenant plusieurs entrées pour un traitement par lots.
Paramètres facultatifs : - Schéma de sortie : sélectionnez uniquement les champs dont vous avez besoin.
- Stockage externe : configurez S3, GCS ou Azure pour une livraison directe.
- URL du webhook : définissez un webhook pour recevoir automatiquement les résultats.
Effectuer la requête API
Voici un exemple simple utilisant curl pour une page produit :
curl -i --silent --compressed "https://api.brightdata.com/dca/trigger?customer=hl_ee3f47e5&zone=YOUR_ZONE_NAME"
-H "Content-Type: application/json"
-H "Authorization: Bearer YOUR_API_KEY"
-d '{
"input": {
"url": "https://www.amazon.com/dp/B08L5TNJHG"
}
}'Remplacez YOUR_ZONE_NAME et YOUR_API_KEY par votre zone et votre clé API réelles.
### Récupérez vos résultats
- Pour les tâches en temps réel (jusqu’à 20 URL), vous obtiendrez les résultats directement.
- Pour les tâches par lots, vous recevrez un identifiant de tâche pour interroger les résultats ou les obtenir via un webhook/stockage externe.
Voyons maintenant comment créer un scraper personnalisé avec les Proxys résidentiels de Bright Data.
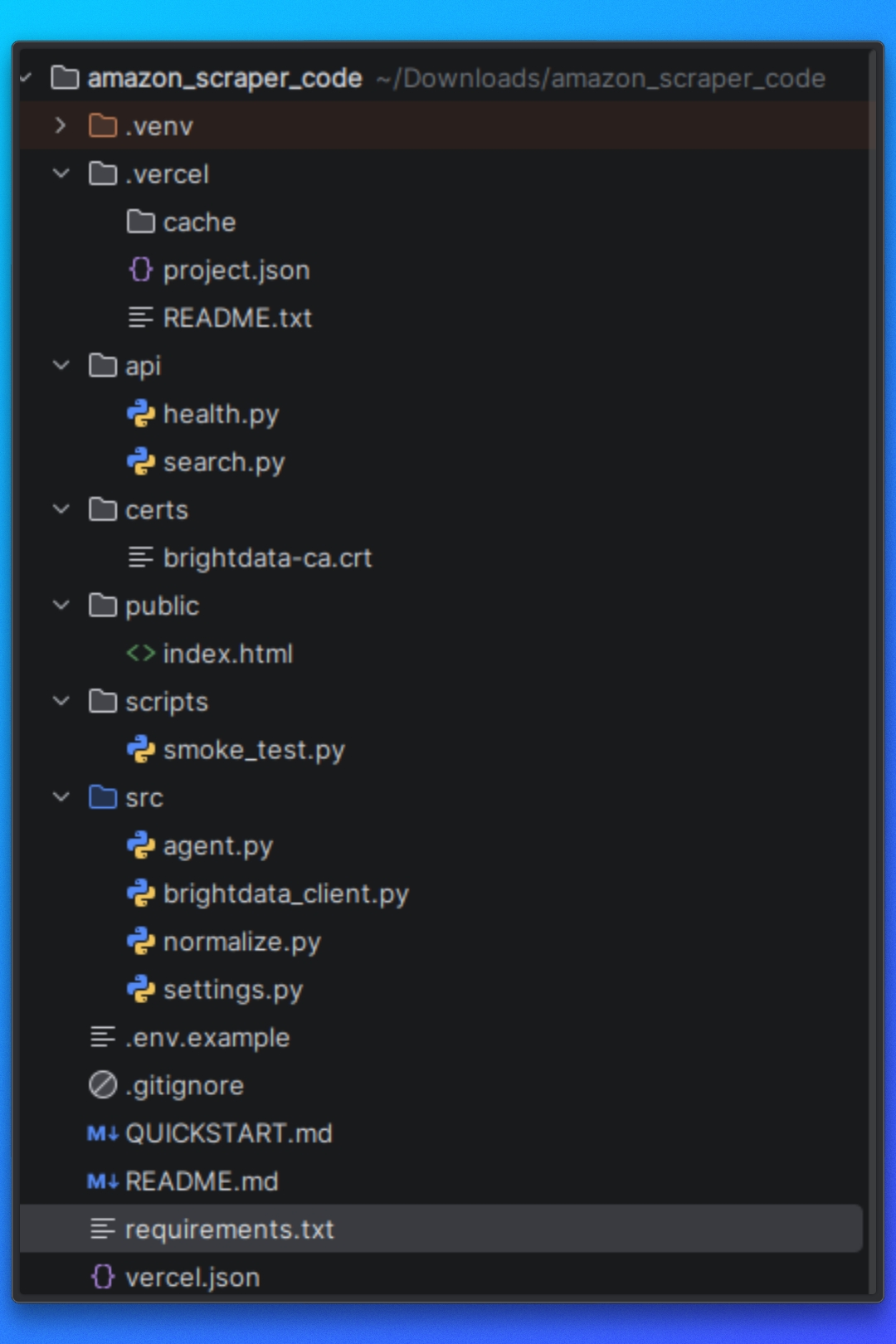
Configuration du projet
Vous pouvez suivre ce tutoriel en utilisant le code de projet disponible dans le référentiel.
Avant de commencer, assurez-vous que les prérequis suivants sont installés sur votre système.
Prérequis
Ce projet nécessite :
- Python 3.10+
- pip pour la gestion des dépendances
- Node.js 18+ (requis par Vercel)
- Vercel CLI
De plus, vous aurez besoin de :
- Un compte Bright Data
- Accès au Web MCP de Bright Data
- Claude Desktop
Installation des dépendances
Installez les dépendances Python requises à l’aide du fichier requirements.txt fourni :
pip install -r requirements.txtCela installe toutes les bibliothèques utilisées pour la récupération de pages, l’automatisation du navigateur, l’analyse HTML et l’extraction de données.
Certificat CA Bright Data
Ce projet utilise un certificat CA Bright Data pour la vérification TLS lors du routage des requêtes via le Proxy.
Assurez-vous que le fichier de certificat existe à l’emplacement suivant :
certs/brightdata-ca.crtCe fichier est transmis au client HTTP lors des requêtes. S’il est manquant ou incorrectement référencé, les requêtes Amazon échoueront en raison d’erreurs de vérification TLS.
Configuration Vercel
Ce projet est conçu pour fonctionner comme une fonction sans serveur Vercel.
Le fichier api/search.py sert de point d’entrée API et est exécuté par Vercel en réponse aux requêtes HTTP entrantes.
Assurez-vous que la CLI Vercel est installée et authentifiée :
vercel login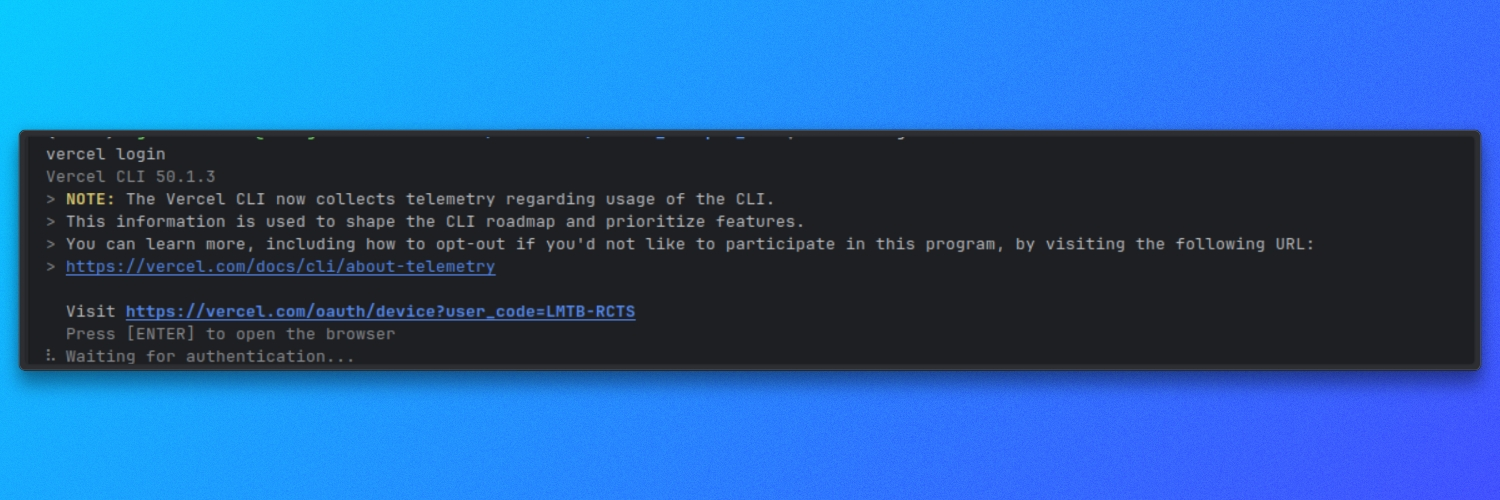
Variables d’environnement
Le projet utilise une configuration basée sur l’environnement pour les paramètres d’exécution.
Créez un fichier .env à la racine du projet et définissez les variables requises comme spécifié dans le référentiel. Ces valeurs contrôlent la manière dont le scraper récupère, affiche et traite les pages Amazon.
Une fois les dépendances installées et les variables d’environnement configurées, le projet est prêt à être utilisé.
Comprendre la structure du projet
Avant d’exécuter le scraper, nous devons comprendre comment le projet est organisé et comment le pipeline de scraping se déroule du début à la fin.
Le projet est structuré autour d’une séparation claire des responsabilités.
Configuration
Cette partie du projet définit les cibles Amazon, les options d’exécution et le comportement du scraper. Ces paramètres contrôlent ce qui est scrapé et comment le scraper fonctionne.
Récupération et rendu des pages
Cette partie du projet est chargée de charger les pages Amazon et de renvoyer du code HTML utilisable. Elle gère la navigation, le chargement des pages et l’exécution JavaScript afin que la logique en aval fonctionne avec un contenu entièrement rendu.
Logique d’extraction
Une fois le code HTML disponible, la couche d’extraction analyse la page et extrait les données structurées. Cela inclut la logique pour les pages de résultats de recherche Amazon et les pages de produits individuels.
Flux d’exécution
Le flux d’exécution coordonne la récupération, le rendu, l’extraction et la sortie. Il garantit que chaque étape s’exécute dans le bon ordre.
Gestion de la sortie
Les données extraites sont écrites sur le disque dans un format structuré, ce qui facilite leur inspection ou leur utilisation dans d’autres flux de travail.
Cette structure permet de conserver la modularité du scraper et facilite la réutilisation des composants individuels, en particulier lors de l’intégration de méthodes de récupération externes telles que Web MCP de Bright Data plus loin dans le tutoriel.
Une fois cette présentation terminée, nous pouvons passer à la configuration des cibles Amazon et à la définition des données que le scraper doit collecter.
Configuration des cibles Amazon
Dans cette section, nous allons configurer deux éléments :
- Le mot-clé de recherche Amazon que nous voulons scraper
- Les identifiants Bright Data dont nous avons besoin pour récupérer correctement les pages Amazon
1. Transmission du mot-clé de recherche Amazon
Nous envoyons notre mot-clé Amazon à l’aide d’un paramètre de requête nommé q.
Cette opération est gérée dans api/search.py. L’API lit q à partir de l’URL de la requête et s’arrête immédiatement s’il est manquant :
# api/search.py
query = query_params.get("q", [None])[0]
if not query:
self._send_json_response(400, {"error": "Missing required parameter: q"})
returnCe que cela signifie :
Nous devons appeler le point de terminaison avec ?q=...
Si nous oublions q, nous obtenons une réponse 400 et le scraper ne s’exécute pas
Définir le nombre de produits souhaités
Nous pouvons également contrôler le nombre de produits renvoyés à l’aide du paramètre optionnel limit.
Toujours dans api/search.py, nous analysons limit, le convertissons en entier et le limitons à une plage sûre :
# api/search.py
limit_str = query_params.get("limit", [None])[0]
limit = DEFAULT_SEARCH_LIMIT
if limit_str:
try:
limit = int(limit_str)
limit = min(limit, MAX_SEARCH_LIMIT)
limit = max(1, limit)
except ValueError:
limit = DEFAULT_SEARCH_LIMITDonc :
Si nous ne passons pas de limite, nous utilisons la valeur par défaut.
Si nous passons une valeur non valide, nous revenons à la valeur par défaut.
Si nous passons une valeur supérieure à celle autorisée, elle est plafonnée.
Les valeurs par défaut et maximales sont définies dans src/settings.py:
# src/settings.py
DEFAULT_SEARCH_LIMIT = 10
MAX_SEARCH_LIMIT = 50Si nous voulons modifier le comportement par défaut, c’est ici que nous le faisons.
2. Mappage de notre requête vers le point de terminaison de recherche d’Amazon
Une fois que nous avons q, nous récupérons les résultats de recherche Amazon via Bright Data à l’aide de fetch_products(query, limit):
# api/search.py
raw_response = fetch_products(query, limit)Le point de terminaison Amazon qui est scrapé est défini dans src/brightdata_client.py:
# src/brightdata_client.py
AMAZON_SEARCH_URL = "https://www.amazon.com/s"Et lorsque nous récupérons les résultats, nous transmettons notre mot-clé à Amazon à l’aide du paramètre k:
# src/brightdata_client.py
r = requests.get(
AMAZON_SEARCH_URL,
params={"k": query},
proxies=proxies,
headers=headers,
timeout=60,
verify=BRIGHTDATA_CA_CERT_PATH,
)Cela signifie :
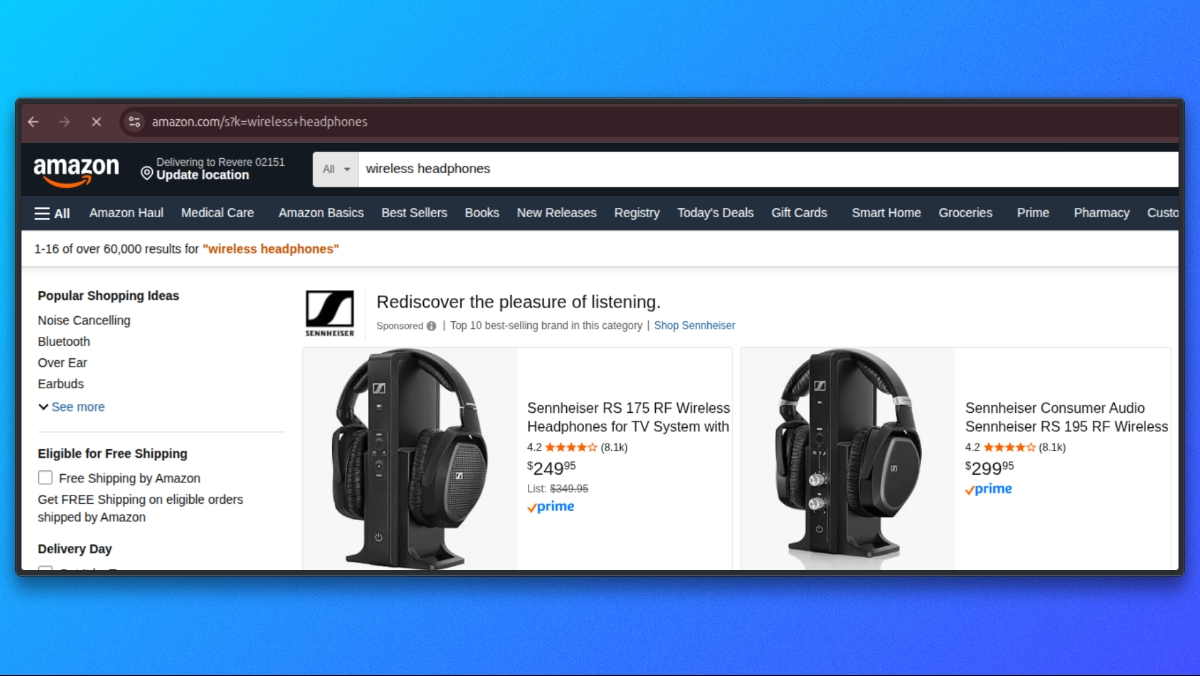
- Notre paramètre API est
q - Le paramètre de recherche d’Amazon est
k - Si nous fournissons q=wireless headphones, la requête est envoyée à Amazon sous la forme
https://www.amazon.com/s?k=wireless+headphones
3. Configuration des identifiants Bright Data
Pour envoyer des requêtes via Bright Data, nous avons besoin d’informations d’identification Proxy disponibles sous forme de variables d’environnement.
Dans src/settings.py, nous chargeons les paramètres Bright Data comme suit :
# src/settings.py
BRIGHTDATA_USERNAME = os.getenv('BRIGHTDATA_USERNAME', '')
BRIGHTDATA_PASSWORD = os.getenv('BRIGHTDATA_PASSWORD', '')
BRIGHTDATA_PROXY_HOST = os.getenv('BRIGHTDATA_PROXY_HOST', 'brd.superproxy.io')
BRIGHTDATA_PROXY_PORT = os.getenv('BRIGHTDATA_PROXY_PORT', 'your_port)Dans votre fichier .env, ajoutez les informations d’identification suivantes :
BRIGHTDATA_USERNAME=votre_nom_d'utilisateur_brightdata
BRIGHTDATA_PASSWORD=votre_mot_de_passe_brightdata
BRIGHTDATA_PROXY_HOST=brd.superproxy.io
BRIGHTDATA_PROXY_PORT=votre_portLorsque nous exécutons le scraper, ces valeurs sont utilisées pour créer l’URL du Proxy Bright Data dans src/brightdata_client.py:
# src/brightdata_client.py
proxy_url = (
f"http://{BRIGHTDATA_USERNAME}:{BRIGHTDATA_PASSWORD}"
f"@{BRIGHTDATA_PROXY_HOST}:{BRIGHTDATA_PROXY_PORT}")
proxies = {"http": proxy_url, "https": proxy_url}Si nous ne définissons pas BRIGHTDATA_USERNAME ou BRIGHTDATA_PASSWORD, le scraper échoue rapidement avec une erreur claire :
# src/brightdata_client.py
if not BRIGHTDATA_USERNAME or not BRIGHTDATA_PASSWORD:
raise ValueError(
"Bright Data Proxy credentials not configured. "
"Set BRIGHTDATA_USERNAME and BRIGHTDATA_PASSWORD."
)Une fois notre mot-clé et nos identifiants Bright Data configurés, nous sommes prêts à récupérer les pages Amazon.
Récupération des pages Amazon
À ce stade, nous avons déjà validé les entrées et configuré Bright Data. Nous allons maintenant nous concentrer sur l’endroit où la requête Amazon est exécutée et sur les hypothèses minimales qu’elle pose.
Toutes les requêtes Amazon sont envoyées depuis src/brightdata_client.py.
Point de terminaison de recherche Amazon
Nous définissons le point de terminaison de recherche Amazon une seule fois et le réutilisons pour toutes les requêtes de recherche :
# src/brightdata_client.py
AMAZON_SEARCH_URL = "https://www.amazon.com/s"En-têtes de requête
Nous envoyons des en-têtes génériques, similaires à ceux des navigateurs, afin de garantir qu’Amazon renvoie la mise en page HTML standard pour ordinateur de bureau. Ces en-têtes ne sont pas liés au système d’exploitation de l’utilisateur.
# src/brightdata_client.py
headers = {
"User-Agent": (
"Mozilla/5.0 "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/120.0 Safari/537.36"
),
"Accept-Language": "en-US,en;q=0.9",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
}Envoi de la requête
Une fois le point de terminaison, les en-têtes et la configuration du Proxy en place, nous exécutons la requête Amazon :
# src/brightdata_client.py
response = requests.get(
AMAZON_SEARCH_URL,
params={"k": query},
proxies=proxies,
headers=headers,
timeout=60,
verify=BRIGHTDATA_CA_CERT_PATH,)
response.raise_for_status()
html = response.text or ""À la fin de cet appel, html contient le contenu brut de la page de recherche Amazon.
La phase de récupération étant terminée, nous pouvons maintenant passer à l’analyse du code HTML et à l’extraction des liens vers les produits et des métadonnées de la page de résultats de recherche Amazon.
Extraction des résultats de recherche
Une fois la page de recherche Amazon récupérée, l’étape suivante consiste à extraire les listes de produits du HTML renvoyé. Cette étape se déroule entièrement dans src/brightdata_client.py.
Une fois la requête terminée, nous transmettons le code HTML brut au parseur interne :
products = _parse_amazon_search_html(html, limit=limit)
return {"products": products}Toute la logique d’extraction des résultats de recherche se trouve dans _parse_amazon_search_html.
Analyse du code HTML
Nous commençons par analyser le code HTML brut dans une arborescence DOM à l’aide de BeautifulSoup. Cela nous permet d’interroger la structure de la page de manière fiable.
soup = BeautifulSoup(html, "lxml")Nous normalisons également la limite demandée afin de garantir l’extraction d’au moins un élément :
max_items = max(1, int(limit)) if isinstance(limit, int) else 10Localisation des conteneurs de résultats de recherche
Les pages de recherche Amazon contiennent de nombreux éléments qui ne sont pas des listes de produits. Pour isoler les résultats réels, nous ciblons d’abord le conteneur principal des résultats de recherche Amazon :
containers = soup.select('div[data-component-type="s-search-result"]')À titre de solution de secours, nous recherchons également les éléments qui contiennent un attribut data-asin valide :
fallback = soup.select('div[data-asin]:not([data-asin=""])')Si le sélecteur principal ne renvoie aucun résultat, mais que le sélecteur de secours en renvoie, nous passons au sélecteur de secours :
if not containers and fallback:
containers = fallbackCela nous permet de faire face aux variations mineures de mise en page tout en limitant l’extraction aux entrées de produits réels.
Itération à travers les résultats
Nous parcourons les conteneurs sélectionnés et nous nous arrêtons une fois que nous avons atteint la limite demandée :
products = []
for c in containers:
if len(products) >= max_items:
breakPour chaque conteneur, nous extrayons les champs principaux. Si une fiche produit ne contient ni titre ni URL, nous la sautons.
title = _extract_title(c)
url = _extract_url(c)
if not title or not url:
continueExtraction des champs du produit
Chaque fiche produit est analysée à l’aide de petites fonctions d’aide, toutes définies dans le même fichier.
image = _extract_image(c)
rating = _extract_rating(c)
reviews = _extract_reviews_count(c)
price = _extract_price(c)Nous assemblons ensuite un objet produit structuré :
products.append(
{
"title": title,
"price": price,
"rating": rating,
"reviews": reviews,
"url": url,
"image": image,
}
)Aides à l’extraction de champs
Chaque aide se concentre sur un champ et gère les balises manquantes ou partielles en toute sécurité.
Extraction du titre
def _extract_title(container) -> str:
a = container.select_one('a.a-link-normal[href*="/dp/"]')
if a:
t = a.get_text(" ", strip=True)
if t:
return t
img = container.select_one("img.s-image")
alt = img.get("alt") if img else ""
return alt.strip() if isinstance(alt, str) else ""URL du produit
def _extract_url(container) -> str:
a = container.select_one('a.a-link-normal[href*="/dp/"]')
href = a.get("href") if a else ""
if isinstance(href, str) and href:
return "https://www.amazon.com" + href if href.startswith("/") else href
return ""Image
def _extract_image(container) -> Optional[str]:
img = container.select_one("img.s-image")
src = img.get("src") if img else None
return src if isinstance(src, str) and src else NoneNote
def _extract_rating(container) -> Optional[float]:
el = container.select_one("span.a-icon-alt")
text = el.get_text(" ", strip=True) if el else ""
if not text:
el = container.select_one('span:contains("out of 5 stars")')
text = el.get_text(" ", strip=True) if el else ""
if not text:
return None
m = re.search(r"(d+(?:.d+)?)", text)
return float(m.group(1)) if m else NoneNombre d’avis
def _extract_reviews_count(container) -> Optional[int]:
el = container.select_one("span.s-underline-text")
text = el.get_text(" ", strip=True) if el else ""
m = re.search(r"(d[d,]*)", text)
return int(m.group(1).replace(",", "")) if m else NonePrix
def _extract_price(container) -> str:
whole = container.select_one("span.a-price-whole")
frac = container.select_one("span.a-price-fraction")
whole_text = whole.get_text(strip=True).replace(",", "") if whole else ""
frac_text = frac.get_text(strip=True) si frac sinon ""
si pas whole_text :
retourner ""
retourner f"${whole_text}.{frac_text}" si frac_text sinon f"${whole_text}"À la fin de cette étape, nous disposons d’une liste d’entrées de produits structurées extraites directement des résultats de recherche Amazon.
Chaque élément comprend :
- titre
- prix
- note
- les avis
- URL du produit
- URL de l’image
Une fois l’extraction des résultats de recherche terminée, nous passons à la normalisation et au renvoi de la réponse, qui sont gérés dans src/normalize.py.
Normalisation de la réponse
À ce stade, notre extraction de recherche renvoie des objets produit, mais les champs ne sont pas encore normalisés. Par exemple, le prix est toujours une chaîne de caractères (comme « 129,99 $ »), le nombre d’avis peut inclure des virgules et certains champs peuvent être manquants selon la fiche.
Afin d’assurer la cohérence de la réponse API, nous normalisons tout dans src/normalize.py.
Dans api/search.py, la normalisation a lieu juste après la récupération des résultats bruts :
# api/search.py
normalized = normalize_response(raw_response, query)Cet appel unique convertit la sortie brute de Bright Data en une réponse propre qui se présente toujours comme suit :
items: une liste d’objets produits normaliséscount: nombre d’éléments renvoyés
Normalisation d’une réponse dict
normalize_response prend en charge plusieurs types d’entrée. Dans notre flux API, nous transmettons un dict tel que {"products": [...]} à partir de fetch_products(...).
Voici la branche dict :
# src/normalize.py
if isinstance(raw_response, dict):
products = raw_response.get("products", []) or raw_response.get("items", [])
normalized_items = [normalize_product(p) for p in products if isinstance(p, dict)]
return {"items": normalized_items[:limit], "count": len(normalized_items[:limit])}Ce que cela fait :
- Lit les produits à partir de products (ou items s’ils sont présents)
- Normalise chaque produit à l’aide de normalize_product
- Renvoie une charge utile cohérente
{"items": [...], "count": N}
Normalisation d’un seul produit
Chaque produit est normalisé par normalize_product(...).
Le prix est analysé en une valeur numérique et un code de devise à l’aide de parse_price(...):
# src/normalize.py
price_str = raw_product.get("price", "")
price, currency = parse_price(price_str)La note est convertie en nombre flottant si possible :
# src/normalize.py
rating = raw_product.get("rating")
if rating is not None:
try:
rating = float(rating)
except (ValueError, TypeError):
rating = None
else:
rating = NoneLe nombre d’avis est normalisé en un nombre entier, prenant en charge à la fois les clés reviews et reviews_count:
# src/normalize.py
reviews_count = raw_product.get("reviews") or raw_product.get("reviews_count")
if reviews_count is not None:
try:
reviews_count = int(str(reviews_count).replace(",", ""))
except (ValueError, TypeError) :
reviews_count = None
else :
reviews_count = NoneEnfin, nous renvoyons un objet produit normalisé :
# src/normalize.py
return {
"title": raw_product.get("title", ""),
"price": price,
"currency": currency,
« rating » : rating,
« reviews_count » : reviews_count,
« url » : raw_product.get(« url », « »),
« image » : raw_product.get(« image »),
« source » : « brightdata »,
}Une fois la normalisation terminée, nous disposons désormais d’une liste d’éléments cohérente qui peut être renvoyée en toute sécurité depuis l’API et facilement utilisée par les clients.
Exécution du Scraper sur Vercel
Ce scraper s’exécute en tant que fonction sans serveur Vercel. Localement, nous l’exécutons à l’aide du serveur de développement Vercel afin que les routes api/ se comportent de la même manière qu’en production.
Exécution locale avec Vercel
À partir de la racine du référentiel, démarrez le serveur de développement :
vercel dev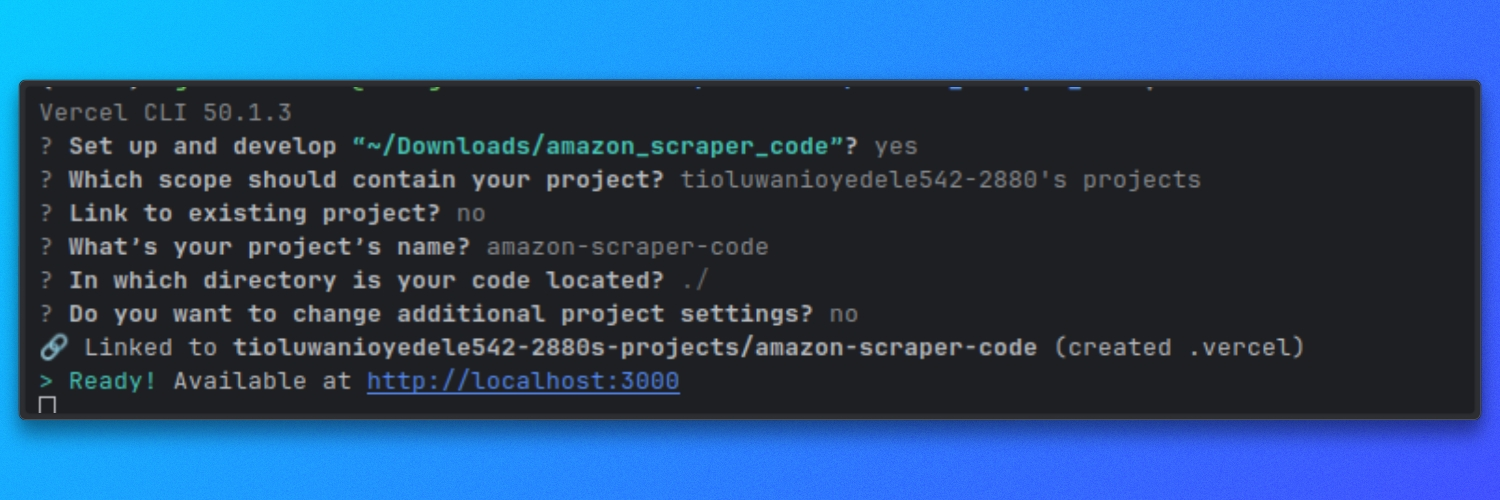
Par défaut, cela démarre le serveur à l’adresse :
http://localhost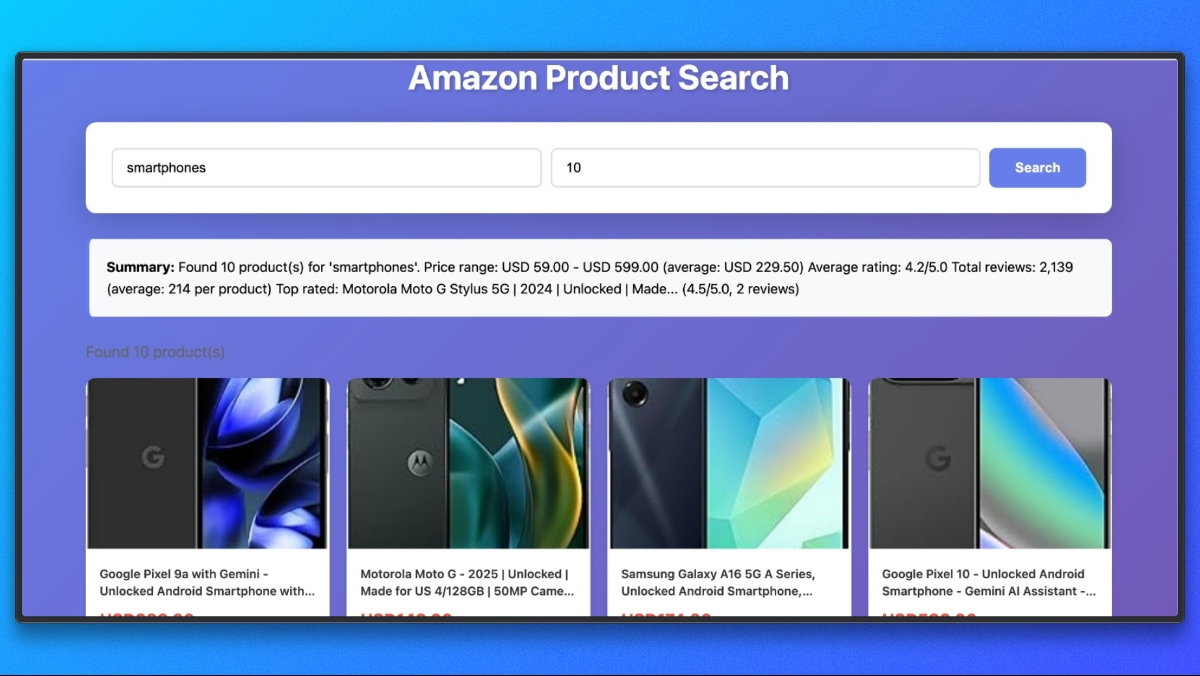
Notre projet de scraper est désormais entièrement opérationnel. Vous pouvez l’exécuter et essayer de scraper différents produits Amazon.
De plus, vous pouvez également scraper à l’aide du Bright Data MCP avec un agent IA. Voyons brièvement comment procéder.
Connexion de Claude Desktop au Web MCP de Bright Data
Claude Desktop doit être configuré pour démarrer le serveur Web MCP de Bright Data.
Ouvrez le fichier de configuration de Claude Desktop.
Vous pouvez naviguer vers Paramètres, cliquer sur l’icône Développeur et sélectionner Modifier la configuration. Cela ouvre le fichier de configuration utilisé par Claude Desktop.

Ajoutez la configuration suivante et remplacez YOUR_TOKEN_HERE par votre jeton API Bright Data :
{
"mcpServers": {
"brightdata": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "YOUR_TOKEN_HERE"
}
}
}
}Enregistrez le fichier et redémarrez Claude Desktop.
Une fois Claude redémarré, le Web MCP de Bright Data sera disponible en tant qu’outil.
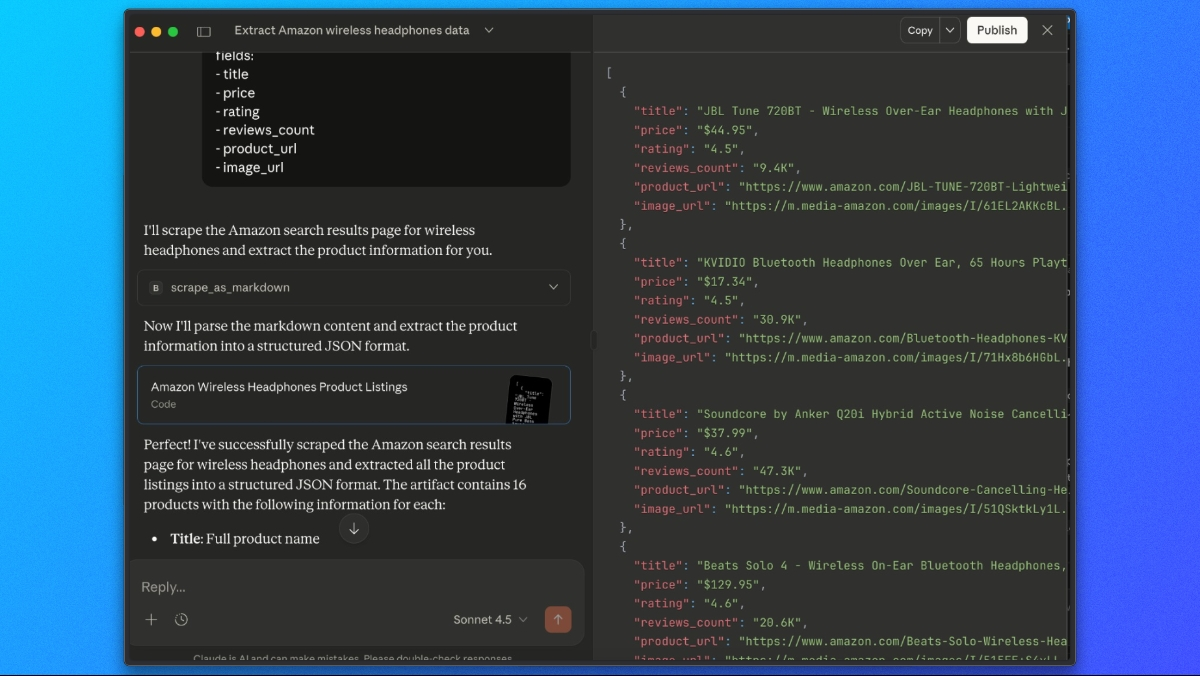
Extraction des listes de produits Amazon avec Claude
Une fois le Web MCP de Bright Data connecté, nous pouvons demander à Claude de récupérer et d’extraire les résultats de recherche Amazon en une seule étape.
Utilisez une invite comme celle-ci :
Veuillez utiliser l'outil scrape_as_markdown pour aller à :
https://www.amazon.com/s?k=wireless+headphones
Ensuite, regardez la sortie markdown et extrayez toutes les listes de produits dans une liste JSON avec les champs suivants :
- titre
- prix
- note
- nombre_d'avis
- url_du_produit
- url_de_l'imageClaude récupérera la page via le Web MCP de Bright Data, analysera le contenu rendu et renverra une réponse JSON structurée contenant les données produit Amazon extraites.
Conclusion
Dans ce tutoriel, nous avons exploré trois façons de scraper Amazon à l’aide de Bright Data :
- API Amazon Scraper– La manière la plus rapide de commencer. Utilisez des points de terminaison prédéfinis pour les détails des produits, les résultats de recherche et les avis sans avoir à écrire de code de scraping.
- Scraper personnalisé avec les Proxy Bright Data– Créez un scraper prêt à l’emploi sous forme de fonction Vercel Serverless avec un contrôle total sur la récupération, l’extraction et la normalisation.
- Claude Desktop avec Web MCP– Récupérez les données d’Amazon de manière interactive à l’aide d’une extraction alimentée par l’IA sans écrire de code.
Évitez complètement le scraping
Si vous avez besoin de données Amazon à grande échelle et prêtes à l’emploi sans avoir à créer d’infrastructure, pensez aux jeux de données Amazon de Bright Data. Accédez à :
- Listes de produits, prix et avis pré-collectés
- Des données historiques pour l’analyse des tendances
- Des jeux de données prêts à l’emploi et régulièrement mis à jour
- Une couverture de plusieurs marchés Amazon
Que vous ayez besoin d’un scraping en temps réel ou de jeux de données prêts à l’emploi, Bright Data fournit l’infrastructure nécessaire pour accéder aux données Amazon de manière fiable et à grande échelle.




