
La plupart des données que les gens souhaitent collecter proviennent de sites web dynamiques, tels que Amazon et YouTube. Ces sites offrent une expérience utilisateur interactive et réactive basée sur ce qui est entré par l’utilisateur. Par exemple, lorsque vous accédez à votre compte YouTube, le contenu vidéo présenté est adapté à ce que vous avez entré. Par conséquent, il peut être plus difficile de faire du web scraping sur des sites dynamiques, puisque les données sont soumises à des modifications constantes, résultant des interactions avec les utilisateurs.
Afin de collecter des données sur des sites dynamiques, vous devez utiliser des techniques avancées qui simulent l’interaction d’un utilisateur avec le site web, permettent de naviguer et de sélectionner un contenu spécifique généré par JavaScript, et traitent les requêtes JavaScript et XML (AJAX) asynchrones.
Dans ce guide, vous apprendrez à collecter des données sur un site web dynamique à l’aide d’une bibliothèque Python open source appelée Selenium.
Collecte de données sur un site web dynamique avec Selenium
Avant de commencer à extraire les données d’un site dynamique, vous devez comprendre le package Python que vous allez utiliser : Selenium.
Qu’est-ce que Selenium ?
Selenium est un package Python open source et un cadre de test automatisé qui vous permet d’exécuter diverses opérations ou tâches sur des sites web dynamiques. Ces tâches incluent des choses telles que l’ouverture/la fermeture de boîtes de dialogue, la recherche de requêtes particulières sur YouTube ou le remplissage de formulaires, le tout dans votre navigateur web préféré.
Lorsque vous utilisez Selenium avec Python, vous pouvez contrôler votre navigateur web et extraire automatiquement des données de sites web dynamiques en écrivant seulement quelques lignes de code Python avec le package Selenium Python.
Maintenant que vous savez comment fonctionne Selenium, commençons.
Créez un nouveau projet Python
La première chose que vous devez faire est de créer un nouveau projet Python. Créez un répertoire nommé data_scraping_project, où seront stockés toutes les données collectées et tous les fichiers de code source. Ce répertoire aura deux sous-répertoires :
scriptscontient tous les scripts Python qui extraient et collectent des données du site web dynamique.dataest l’endroit où toutes les données extraites d’un site web dynamique seront stockées.
Installez les packages Python
Après avoir créé le répertoire data_scraping_project, vous devez installer les packages Python suivants pour vous aider à extraire, collecter et enregistrer les données d’un site web dynamique :
- Webdriver Manager
- pandas
Vous pouvez installer le paquet Selenium de Python en exécutant la commande pip suivante sur votre terminal :
pip install selenium
Sélénium utilisera le pilote binaire pour contrôler le navigateur web de votre choix. Ce package Python fournit des pilotes binaires pour les navigateurs web pris en charge, à savoir : Chrome, Chromium, Brave, Firefox, IE, Edge et Opera.
Exécutez ensuite la commande pip suivante sur votre terminal pour installer webdriver-manager:
pip install webdriver-manager
Pour installer pandas, exécutez la commande pip suivante :
pip install pandas
Ce que vous allez collecter
Dans cet article, vous allez collecter des données dans deux endroits différents : une chaîne YouTube appelée Programming with Mosh ; et Hacker News:
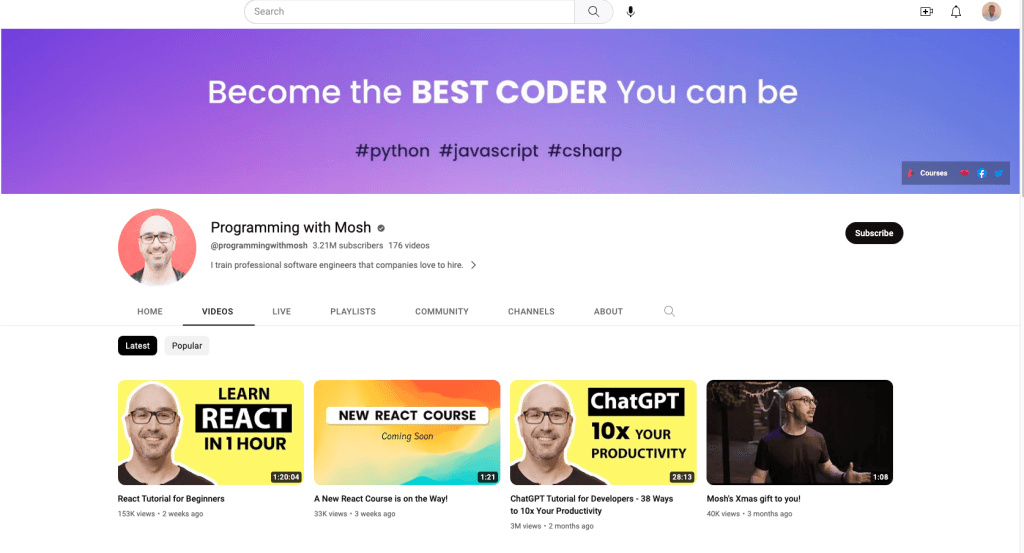
Sur la chaîne YouTube « Programming with Mosh », vous allez collecter les informations suivantes :
- Le titre de la vidéo.
- Le lien ou l’URL de la vidéo.
- Le lien ou l’URL de l’image.
- Le nombre de vues de la vidéo considérée.
- L’heure à laquelle la vidéo a été publiée.
- Commentaires d’une URL de vidéo YouTube donnée.
Et dans Hacker News, vous allez collecter les données suivantes :
- Le titre de l’article.
- Le lien vers l’article.

Maintenant que vous savez ce que vous allez collecter, créons un nouveau script Python (par exemple data_scraping_project/scripts/youtube_videos_list.py).
Importez les packages Python
Tout d’abord, vous devez importer les packages Python que vous utiliserez pour extraire, collecter et enregistrer des données dans un fichier CSV :
# import libraries
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import pandas as pd
Instanciation du WebDriver
Pour instancier WebDriver, vous devez sélectionner le navigateur que Selenium utilisera (ici, Chrome), puis installer le pilote binaire.
Chrome dispose d’outils de développement pour afficher le code HTML de la page web et identifier les éléments HTML sur lesquels collecter des données. Pour afficher le code HTML, vous devez cliquer avec le bouton droit de la souris sur une page web dans votre navigateur Chrome, puis sélectionner Inspecter l’élément.
Pour installer un pilote binaire pour Chrome, exécutez le code suivant :
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
Le pilote binaire pour Chrome sera installé sur votre machine et instanciera automatiquement WebDriver.
Collecter des données avec Selenium
Pour collecter des données avec Selenium, vous devez définir l’URL YouTube dans une simple variable Python (url). À partir de ce lien, vous allez collecter toutes les données mentionnées précédemment, à l’exception des commentaires d’une URL YouTube particulière :
# Define the URL
url = "https://www.youtube.com/@programmingwithmosh/videos"
# load the web page
driver.get(url)
# set maximum time to load the web page in seconds
driver.implicitly_wait(10)
Selenium charge automatiquement le lien YouTube dans le navigateur Chrome. En outre, un délai est spécifié (en l’occurrence 10 secondes) pour s’assurer que la page web est entièrement chargée (avec tous les éléments HTML). Cela vous aide à collecter les données rendues par JavaScript.
Collecter des données à l’aide d’ID et de balises
L’un des avantages de Selenium est qu’il peut extraire des données en utilisant différents éléments présentés sur la page web, y compris l’ID et la balise.
Par exemple, vous pouvez utiliser l’élément ID (par exemple post-title) ou les balises (par exemple h1 et p) pour collecter les données :
<h1 id ="post-title">Introduction to data scrapping using Python</h1>
<p>You can use selenium python package to collect data from any dynamic website</p>
Mais si vous souhaitez collecter des données à partir du lien YouTube, vous devez utiliser l’ID présenté sur la page web. Ouvrez l’YouTube URL dans votre navigateur, puis cliquez avec le bouton droit de la souris et sélectionnez Inspecter pour identifier l’ID. Utilisez ensuite votre souris pour afficher la page et identifier l’ID qui contient la liste des vidéos présentées sur le canal :
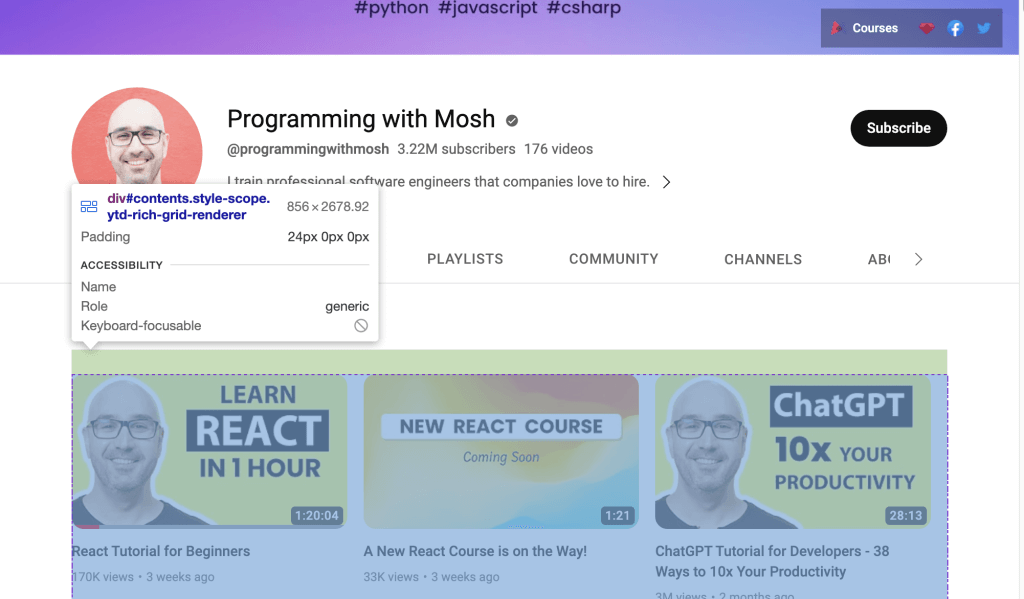
Utilisez WebDriver pour extraire les données qui se trouvent dans l’ID identifié. Pour trouver un élément HTML par attribut ID, appelez la méthode Selenium find_element() et passez By.ID comme premier argument et ID comme second argument.
Pour collecter le titre et le lien vidéo de chaque vidéo, vous devez utiliser l’attribut ID video-title-link. Puisque vous allez collecter plusieurs éléments HTML avec cet attribut ID, vous devrez utiliser la méthode find_elements() find_elements():
# collect data that are withing the id of contents
contents = driver.find_element(By.ID, "contents")
#1 Get all the by video tite link using id video-title-link
video_elements = contents.find_elements(By.ID, "video-title-link")
#2 collect title and link for each youtube video
titles = []
links = []
for video in video_elements:
#3 Extract the video title
video_title = video.get_attribute("title")
#4 append the video title
titles.append(video_title)
#5 Extract the video link
video_link = video.get_attribute("href")
#6 append the video link
links.append(video_link)
Ce code effectue les tâches suivantes :
- Il collecte les données qui se trouvent dans l’attribut ID
contents. - Il collecte tous les éléments HTML qui ont un attribut ID
video-title-linkdans l’objetcontentsdu WebElement. - Il crée deux listes pour ajouter des titres et des liens.
- Il extrait le titre de la vidéo à l’aide de la méthode
get_attribute()et transmet letitle. - Il ajoute le titre de la vidéo dans la liste des titres.
- Il extrait le lien vidéo à l’aide de la méthode
get_atribute()et transmet href comme argument. - Il ajoute le lien vidéo à la liste des liens.
À ce stade, tous les titres et liens vidéo seront dans deux listes Python : titles et links.
Vous devez ensuite extraire le lien de l’image qui est disponible sur la page web avant de cliquer sur le lien de la vidéo YouTube pour regarder la vidéo. Pour extraire ce lien d’image, vous devez trouver tous les éléments HTML en appelant la méthode Selenium find_elements(), en passant By.TAG_NAME comme premier argument et le nom de la balise comme deuxième argument :
#1 Get all the by Tag
img_elements = contents.find_elements(By.TAG_NAME, "img")
#2 collect img link and link for each youtube video
img_links = []
for img in img_elements:
#3 Extract the img link
img_link = img.get_attribute("src")
if img_link:
#4 append the img link
img_links.append(img_link)
Ce code collecte tous les éléments HTML avec le nom de balise img de l’objet WebElement appelé contents. Il crée également une liste pour ajouter les liens d’image et l’extrait à l’aide de la méthode get_attribute(), et transmet src comme argument. Enfin, il ajoute le lien de l’image à la liste img_links.
Vous pouvez également utiliser l’ID et le nom de la balise pour extraire davantage de données de chaque vidéo YouTube. Sur la page web de l’YouTube URL, vous devriez être en mesure de voir le nombre de vues et l’heure de publication pour chaque vidéo répertoriée sur la page. Pour extraire ces données, vous devez collecter tous les éléments HTML ayant un ID de metadata-line, puis collecter les données des éléments HTML avec un nom de balise span:
#1 find the element with the specific ID you want to scrape
meta_data_elements = contents.find_elements(By.ID, 'metadata-line')
#2 collect data from span tag
meta_data = []
for element in meta_data_elements:
#3 collect span HTML element
span_tags = element.find_elements(By.TAG_NAME, 'span')
#4 collect span data
span_data = []
for span in span_tags:
#5 extract data for each span HMTL element.
span_data.append(span.text)
#6 append span data to the list
meta_data.append(span_data)
# print out the scraped data.
print(meta_data)
Ce bloc de code collecte tous les éléments HTML qui ont un attribut ID de metadata-line dans l’objet WebElement contents et crée une liste pour ajouter des données de la balise span qui aura le nombre de vues et l’heure de publication.
Il collecte également tous les éléments HTML dont le nom de balise est span dans l’objet WebElement nommé meta_data_elements , puis crée une liste avec ces données span. Il extrait ensuite les données de texte de l’élément HTML span et les ajoute à la liste span_data. Enfin, il ajoute les données de la liste span_data au meta_data.
Les données extraites de l’élément HTML span ressemblent à ceci :

Ensuite, vous devez créer deux listes Python et enregistrer le nombre de vues et l’heure de publication séparément :
#1 Iterate over the list of lists and collect the first and second item of each sublist
views_list = []
published_list = []
for sublist in meta_data:
#2 append number of views in the views_list
views_list.append(sublist[0])
#3 append time published in the published_list
published_list.append(sublist[1])
Ici, vous créez deux listes Python qui extraient des données de meta_data, puis vous ajoutez le nombre de vues pour chaque sous-liste à view_list et l’heure de publication de chaque sous-liste à published_list.
À ce stade, vous avez extrait le titre de la vidéo, l’URL de la page vidéo, l’URL de l’image, le nombre de vues et l’heure de publication de la vidéo. Ces données peuvent être enregistrées dans un DataFrame pandas à l’aide du pandas Python package. Utilisez le code suivant pour enregistrer les données de la liste des titles, links, img_links, views_list et published_list dans le DataFrame pandas :
# save in pandas dataFrame
data = pd.DataFrame(
list(zip(titles, links, img_links, views_list, published_list)),
columns=['Title', 'Link', 'Img_Link', 'Views', 'Published']
)
# show the top 10 rows
data.head(10)
# export data into a csv file.
data.to_csv("../data/youtube_data.csv",index=False)
driver.quit()
Voici ce à quoi devraient ressembler les données collectées dans le DataFrame pandas :

Ces données enregistrées sont exportées depuis pandas vers un fichier CSV appelé youtube_data.csv à l’aide de to_csv().
Vous pouvez maintenant exécuter youtube_videos_list.py et vous assurer que tout fonctionne correctement.
Collecte de données à l’aide du sélecteur CSS
Selenium peut également extraire des données sur la base des modèles spécifiques des éléments HTML à l’aide du CSS selector de la page web. Le sélecteur CSS est appliqué aux éléments spécifiques de la cible en fonction de leur ID, nom de balise, classe ou autres attributs.
Ici, par exemple, la page HTML contient des éléments div, et l’un d’eux a pour nom de classe "inline-code" :
<html>
<body>
<p>Hello World!</p>
<div>Learn Data Scraping</div>
<div class="inline-code"> data scraping with Python code</div>
<div>Saving</div>
</body>
</html>
Vous pouvez utiliser un sélecteur CSS pour trouver, sur une page web, l’élément HTML dont le nom de balise est div et dont le nom de classe est “inline-code”. Vous pouvez appliquer cette même approche pour extraire des commentaires de la section de commentaires de vidéos YouTube.
Maintenant, utilisons un sélecteur CSS pour recueillir les commentaires publiés sur cette vidéo YouTube.
La section des commentaires YouTube est disponible sous la balise et le nom de classe suivants :
<ytd-comment-thread-renderer class="style-scope ytd-item-section-renderer">...</tyd-comment-thread-renderer>
Créons un nouveau script (par exemple data_scraping_project/scripts/youtube_video_
comments.py). Importez tous les packages nécessaires comme précédemment, puis ajoutez le code suivant pour démarrer automatiquement le navigateur Chrome, parcourir l’URL de la vidéo YouTube, puis extraire les commentaires à l’aide du sélecteur CSS :
#1 instantiate chrome driver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#2 Define the URL
url = "https://www.youtube.com/watch?v=hZB5bHDCmeY"
#3 Load the webpage
driver.get(url)
#4 define the CSS selector
comment_section = 'ytd-comment-thread-renderer.ytd-item-section-renderer’
#5 wait until element matching the given criteria to be found
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, comment_section))
)
except:
driver.quit()
#6. collect HTML elements within the CSS selector
comment_blocks = driver.find_elements(By.CSS_SELECTOR,comment_section)
Ce code instancie le pilote Chrome et définit le lien vidéo YouTube pour collecter les commentaires qui ont été publiés. Ensuite, il charge la page web dans le navigateur et attend dix secondes jusqu’à ce que les éléments HTML correspondant au sélecteur CSS soient disponibles.
Ensuite, il collecte tous les éléments HTML comment à l’aide du sélecteur CSS appelé ytd-comment-thread-renderer.ytd-item-section-renderer et enregistre tous les éléments de commentaire dans l’objet WebElement comment_blocks.
Vous pouvez ensuite extraire le nom de chaque auteur à l’aide de l’author-text de l’ID et le texte de commentaire à l’aide du content-text de l’ID dans chaque commentaire de l’objet WebElement comment_blocks :
#1 specify the id attribute for author and comment
author_id = 'author-text'
comment_id = 'content-text'
#2 Extract the text value for each comment and author in the list
comments = []
authors = []
for comment_element in comment_blocks:
#3 collect author for each comment
author = comment_element.find_element(By.ID, author_id)
#4 append author name
authors.append(author.text)
#5 collect comments
comment = comment_element.find_element(By.ID, comment_id)
#6 append comment text
comments.append(comment.text)
#7 save in pandas dataFrame
comments_df = pd.DataFrame(list(zip(authors, comments)), columns=['Author', 'Comment'])
#8 export data into a CSV file.
comments_df.to_csv("../data/youtube_comments_data.csv",index=False)
driver.quit()
Ce code spécifie l’ID de l’auteur et du commentaire. Ensuite, il crée deux listes Python auxquelles seront ajoutés le nom de l’auteur et le texte du commentaire. Il collecte chaque élément HTML qui possède les attributs d’ID spécifiés dans l’objet WebElement et ajoute les données aux listes Python.
Enfin, il enregistre les données collectées dans un DataFrame pandas et les exporte dans un fichier CSV appelé youtube_comments_data.csv.
Voici ce à quoi ressembleront les auteurs et les commentaires des dix premières lignes dans un DataFrame pandas :

Collecte de données à l’aide du nom de classe
Outre la collecte de données avec le sélecteur CSS, vous pouvez également effectuer une collecte de données en fonction d’un nom de classe spécifique. Pour trouver un élément HTML grâce à son attribut de nom de classe avec Selenium, vous devez appeler la méthode find_element(), passer By.CLASS_NAME comme premier argument, puis trouver le nom de classe pour le deuxième argument.
Dans cette section, vous utiliserez le nom de classe pour extraire le titre et le lien des articles publiés sur Hacker News. Sur cette page web, l’élément HTML qui a le titre et le lien de chaque article a pour nom de classe titleline, comme le montre le code de la page web :
<span class="titleline"><a href="https://mullvad.net/en/browser">The Mullvad Browser</a><span class="sitebit comhead"> (<a href="from?site=mullvad.net"><span class="sitestr">mullvad.net</span></a>)</span></span></td></tr><tr><td colspan="2"></td><td class="subtext"><span class="subline">
<span class="score" id="score_35421034">302 points</span> by <a href="user?id=Foxboron" class="hnuser">Foxboron</a> <span class="age" title="2023-04-03T10:11:50"><a href="item?id=35421034">2 hours ago</a></span> <span id="unv_35421034"></span> | <a href="hide?id=35421034&auth=60e6bdf9e482441408eb9ca98f92b13ee2fac24d&goto=news" class="clicky">hide</a> | <a href="item?id=35421034">119 comments</a> </span>
Créez un nouveau script Python (par exemple data_scraping_project/scripts/hacker_news.py), importez tous les packages nécessaires, puis ajoutez le code Python suivant pour extraire le titre et le lien de chaque article publié sur la page Hacker News :
#1 define url
hacker_news_url = 'https://news.ycombinator.com/'
#2 instantiate chrome driver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#3 load the web page
driver.get(hacker_news_url)
#4 wait until element matching the given criteria to be found
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, 'titleline'))
)
except:
driver.quit()
#5 Extract the text value for each title and link in the list
titles= []
links = []
#6 Find all the articles on the web page
story_elements = driver.find_elements(By.CLASS_NAME, 'titleline')
#7 Extract title and link for each article
for story_element in story_elements:
#8 append title to the titles list
titles.append(story_element.text)
#9 extract the URL of the article
link = story_element.find_element(By.TAG_NAME, "a")
#10 appen link to the links list
links.append(link.get_attribute("href"))
driver.quit()
Ce code définit l’URL de la page web, lance automatiquement le navigateur Chrome, puis accède à l’URL de Hacker News. Il attend dix secondes jusqu’à ce que les éléments HTML correspondant au CLASS NAME soient disponibles.
Ensuite, il crée deux listes Python auxquelles seront ajoutés le titre et le lien de chaque article. Il collecte également chaque élément HTML ayant pour nom de classe titleline dans l’objet pilote WebElement, puis extrait le titre et le lien de chaque article représenté dans l’objet WebElement story_elements.
Enfin, le code ajoute le titre de l’article à la liste des titres et collecte l’élément HTML qui a pour nom de balise a dans l’objet story_element. Il extrait le lien à l’aide de la méthode get_attribute() et ajoute le lien à la liste des liens.
Ensuite, vous devez utiliser la méthode to_csv() de pandas pour exporter les données extraites. Vous allez exporter les titres et les liens dans un fichier CSV hacker_news_data.csv et enregistrer les données dans le répertoire :
# save in pandas dataFrame
hacker_news = pd.DataFrame(list(zip(titles, links)),columns=['Title', 'Link'])
# export data into a csv file.
hacker_news.to_csv("../data/hacker_news_data.csv",index=False)
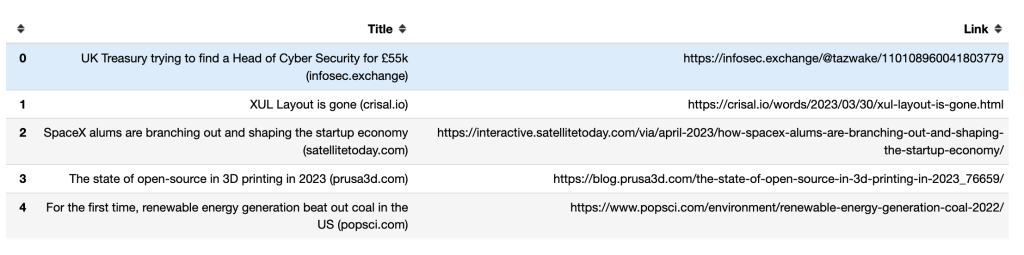
Voici comment les titres et les liens des cinq premières lignes apparaissent dans un DataFrame pandas :
Comment gérer les défilements infinis
Certaines pages web dynamiques chargent des contenus supplémentaires lorsque vous les faites défiler jusqu’en bas. Si vous ne naviguez pas vers le bas, Selenium peut seulement extraire les données visibles sur votre écran.
Pour collecter plus de données, vous devez demander à Selenium de faire défiler la page jusqu’en bas, d’attendre que le nouveau contenu se charge, puis d’extraire automatiquement les données qui vous intéressent. Par exemple, le script Python suivant fera défiler les quarante premiers résultats des livres Python et extraira leurs liens :
#1 import packages
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
#2 Instantiate a Chrome webdriver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#3 Navigate to the webpage
driver.get("https://example.com/results?search_query=python+books")
#4 instantiate a list to keep links
books_list = []
#5 Get the height of the current webpage
last_height = driver.execute_script("return document.body.scrollHeight")
#6 set target count
books_count = 40
#7 Keep scrolling down on the web page
while books_count > len(books_list):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
#8 Wait for the page to load
time.sleep(5)
#9 Calculate the new height of the page
new_height = driver.execute_script("return document.body.scrollHeight")
#10 Check if you have reached the bottom of the page
if new_height == last_height:
break
last_height = new_height
#11 Extract the data
links = driver.find_elements(By.TAG_NAME, "a")
for link in links:
#12 append extracted data
books_list.append(link.get_attribute("href"))
#13 Close the webdriver
driver.quit()
Ce code importe les packages Python qui seront utilisés, instancie et ouvre Chrome. Ensuite, il accède à la page web et crée une liste Python à laquelle sera ajouté le lien correspondant à chacun des résultats de la recherche.
Il obtient la hauteur de la page en cours en exécutant le script return document.body.scrollHeight et définit le nombre de liens que vous souhaitez collecter. Ensuite, il continue à défiler vers le bas tant que la valeur de la variable book_count est supérieure à la longueur de la book_list et attend cinq secondes pour charger la page.
Il calcule la nouvelle hauteur de la page web en exécutant le script return document.body.scrollHeight et vérifie si le bas de la page a été atteint. Si c’est le cas, la boucle est terminée ; sinon, il met à jour last_height et continue à défiler vers le bas. Enfin, il collecte l’élément HTML qui a un nom de balise a dans l’objet WebElement, puis extrait et ajoute le lien à la liste des liens. Une fois les liens collectés, il ferme le WebDriver.
Remarque : Pour que votre script se termine à un certain point, vous devez définir un nombre total d’éléments à extraire si la page a un défilement infini. Si vous ne le faites pas, votre code continuera à s’exécuter.
Le web scraping avec Bright Data
Bien qu’il soit possible de collecter des données avec des web scrapers open source comme Selenium, il est difficile d’obtenir de l’assistance pour ces derniers. En outre, le processus peut être compliqué et chronophage. Si vous recherchez une solution de web scraping puissante et fiable, envisagez de faire appel à Bright Data.
Bright Data est une plateforme de données web qui vous permet de collecter des données web publiques en vous fournissant différents outils et services, notamment des solutions de web scraping, des proxys et des jeux de données précollectés. Vous pouvez même utiliser le Web Scraper IDE hébergé pour construire vos propres web scrapers dans un environnement de codage JavaScript.
Le Web Scraper IDE utilise également des fonctions de scraping prêtes à l’emploi ainsi que des modèles de code pour différents sites web dynamiques populaires, par exemple des modèles de scraper Indeed et scraper Walmart. Cela signifie qu’il est facile d’accélérer rapidement le développement et l’adaptation de vos web scrapers.
Bright Data propose diverses options pour le format de vos données, notamment JSON, NDJSON, CSV et Microsoft Excel. Le Web Scraper IDE s’intègre également à différentes plateformes pour vous permettre de livrer facilement vos données collectées.
Conclusion
La collecte de données sur des sites web dynamiques nécessite des efforts et une planification. Avec Selenium, vous pouvez interagir automatiquement avec n’importe quel site web dynamique et en extraire des données.
Bien qu’il soit possible de collecter des données avec Selenium, il s’agit d’une tâche longue et difficile. C’est pourquoi il est recommandé d’utiliser le Web Scraper IDE pour collecter des données sur des sites web dynamiques. Grâce à ses fonctions de scraping prêtes à l’emploi et à ses modèles de code, vous pouvez commencer à extraire des données immédiatement.



