

Dans ce guide, vous trouverez les éléments suivants :
- Ce que sont les sites à forte composante JavaScript.
- Défis et méthodes pour les récupérer via le rendu du navigateur.
- Comment fonctionne l’interception des appels AJAX et ses limites.
- La solution moderne pour le scraping de sites web à forte composante JavaScript.
Plongeons dans l’aventure !
Qu’est-ce qu’un site web à forte composante JavaScript ?
Dans le domaine du web scraping, un site est “JavaScript-heavy” lorsque les données à collecter ne se trouvent pas dans le document HTML initial renvoyé par le serveur. Au lieu de cela, le contenu réel est dynamiquement récupéré et rendu par JavaScript dans le navigateur de l’utilisateur.
La manière dont un site utilise JavaScript influe directement sur la façon dont vous devez procéder pour extraire ses données. En règle générale, les sites basés sur JavaScript suivent les trois grands modèles suivants :
- Applications à page unique (SPA): Une SPA est une page web qui s’appuie sur JavaScript pour mettre à jour des sections spécifiques avec du nouveau contenu provenant du serveur. En d’autres termes, l’application web entière n’est qu’une page web unique qui n’est pas rechargée à chaque interaction de l’utilisateur.
- Interactions axées sur l’utilisateur: Le contenu n’apparaît qu’après avoir effectué des actions spécifiques. Les boutons “charger plus” et la pagination dynamique en sont des exemples.
- Données asynchrones: De nombreux sites chargent d’abord une mise en page de base pour des raisons de rapidité, puis effectuent des appels en arrière-plan à l’aide d’AJAX pour récupérer des données. Ce mécanisme est courant pour les mises à jour en direct, comme l’actualisation des cours de la bourse sans recharger la page.
Scraping de sites à forte teneur en JavaScript via le rendu complet du navigateur
Les outils d’automatisation des navigateurs vous permettent d’écrire des scripts qui lancent et contrôlent les navigateurs web. Cela leur permet d’exécuter le JavaScript nécessaire au rendu complet d’une page. Vous pouvez ensuite utiliser la sélection d’éléments HTML et les API d’extraction de données fournies par ces outils pour extraire les données dont vous avez besoin.
Il s’agit de l’approche fondamentale du scraping de sites à forte composante JavaScript, que nous présentons dans les sections suivantes :
- Comment fonctionnent les outils d’automatisation.
- Ce que sont les modes “sans tête” et “avec tête”.
- Défis et solutions de cette approche.
- Les outils d’automatisation des navigateurs les plus utilisés.
Fonctionnement des outils d’automatisation
Les outils d’automatisation des navigateurs utilisent un protocole (par exemple, CDP ou BiDi) pour envoyer des commandes directement à un navigateur. En termes plus simples, ils exposent une API complète pour émettre des commandes telles que “naviguer vers cette URL”, “trouver cet élément” et “cliquer sur ce bouton”.
Le navigateur exécute ces commandes sur la page, en exécutant tout le JavaScript nécessaire aux interactions décrites dans votre script de scraping. L’outil d’automatisation du navigateur peut également accéder aumodèle d’objet du document (DOM). C’est là que vous trouverez les données à extraire.
Navigateurs sans tête et navigateurs avec tête
Lorsque vous automatisez un navigateur, vous devez décider de son mode d’exécution. En général, vous avez le choix entre deux modes :
- Tête haute: Le navigateur se lance avec son interface graphique complète, comme lorsqu’un utilisateur humain l’ouvre. Vous pouvez voir la fenêtre du navigateur sur votre écran et observer les clics, la saisie et la navigation de votre script en temps réel. Cela permet de confirmer visuellement que votre script fonctionne comme prévu. Pour les systèmes anti-bots, cela peut également faire ressembler votre automatisation à l’activité d’un utilisateur réel. D’un autre côté, l’exécution d’un navigateur avec une interface graphique est gourmande en ressources (nous savons tous à quel point les navigateurs peuvent être gourmands en mémoire), ce qui ralentit votre web scraping.
- Sans tête: Le navigateur fonctionne en arrière-plan sans interface visible. Il utilise moins de ressources système et est beaucoup plus rapide. C’est la norme pour les scrapers de production, en particulier lorsqu’il s’agit d’exécuter des centaines d’instances parallèles sur un serveur. En revanche, s’il n’est pas configuré avec soin, un navigateur sans interface graphique peut paraître suspect. Découvrez les meilleurs navigateurs sans interface graphique du marché.
Défis et solutions en matière de rendu par navigateur
L’automatisation d’un navigateur n’est que la première étape lorsqu’il s’agit de sites web à forte composante JavaScript. Lorsque vous scrapez de tels sites, vous êtes inévitablement confronté à deux grandes catégories de défis, à savoir :
- Navigation complexe: Les scripts de scraping ne doivent pas se contenter de suivre des commandes. Vous devez les programmer pour qu’ils gèrent l’ensemble du parcours de l’utilisateur. Cela signifie qu’il faut écrire du code pour récupérer des flux de navigation complexes, comme l’attente du chargement d’un nouveau contenu et la gestion d’un défilement infini. La récupération de sites à forte composante JavaScript comprend la gestion de formulaires multipages, de menus déroulants et de bien d’autres choses encore.
- Échapper aux systèmes anti-bots: Lorsqu’elle n’est pas appliquée correctement, l’automatisation du navigateur est un signal d’alarme que les systèmes anti-bots peuvent détecter. Pour réussir un scénario de scraping avec des outils d’automatisation des navigateurs, votre scraper doit d’une manière ou d’une autre apparaître comme humain en relevant des défis tels que :
- Empreinte digitale du navigateur: Les anti-bots analysent des centaines de données provenant du navigateur du client afin de créer une signature unique. Il s’agit notamment de la chaîne User-Agent, de la résolution de l’écran, des polices installées, des capacités de rendu WebGL, etc. Il est clair qu’une configuration d’automatisation par défaut est facilement identifiable. Définir un User-Agent qui ne soit pas sans tête est un excellent conseil. Vous pouvez également avoir besoin d’outils spécialisés tels que undetected-chromedriver, qui modifie plusieurs options du navigateur pour le faire ressembler à celui d’un utilisateur normal.
- Analyse comportementale: Les anti-bots observent également la manière dont le scraper interagit avec la page. Un script qui clique sur un bouton 5 millisecondes après le chargement d’une page n’est manifestement pas humain. Si ce comportement est considéré comme robotique, le système de défense peut vous bannir.
- CAPTCHAs: Les CAPTCHAs sont souvent le dernier obstacle aux méthodes de scraping basées sur l’automatisation des navigateurs. En effet, les scripts d’automatisation standard ne peuvent pas les résoudre de manière autonome. Pour surmonter ce problème, il faut intégrer des services de résolution de CAPTCHA.
Pour plus d’informations, consultez notre guide sur le scraping de sites dynamiques.
Principaux cadres d’automatisation des navigateurs
Les trois cadres dominants pour l’automatisation des navigateurs sont les suivants :
- Playwright: Il s’agit d’un cadre moderne de Microsoft. Il est conçu dès le départ pour gérer les complexités des sites modernes. Cela en fait un choix de premier ordre pour les nouveaux projets de scraping. Il est disponible en JavaScript, Python, C# et Java, avec une prise en charge de langues supplémentaires fournie par la communauté. Cela fait du scraping web avec Playwright un bon choix pour la plupart des développeurs.
- Selenium: c’est le titan open-source de l’automatisation web. Sa plus grande force réside dans sa polyvalence. En particulier, il prend en charge presque tous les langages de programmation et tous les navigateurs, et dispose d’un écosystème vaste et mature. C’est pourquoi Selenium est largement utilisé comme outil d’automatisation de navigateur pour le scraping.
- Puppeteer: Il s’agit d’une bibliothèque développée par Google qui offre un contrôle granulaire sur Chrome et les navigateurs basés sur Chromium via le CDP(Chrome DevTools Protocol). Elle prend désormais également en charge Firefox. Grâce à cette bibliothèque, vous pouvez vous faire passer pour un utilisateur normal en simulant le comportement d’un utilisateur dans un navigateur contrôlé. Puppeteer est ainsi largement utilisé pour le web scraping.
Voyez comment ces solutions (et d’autres) se comparent dans notre référentiel sur les meilleurs outils d’automatisation des navigateurs.
Méthode alternative : Réplication des appels AJAX
Au lieu de supporter le coût du rendu d’une page web visuelle complète dans le navigateur, vous pouvez adopter une approche de détective. Vous pouvez identifier les appels directs de l’API que le front-end du site web effectue vers son back-end et les reproduire vous-même.
Ces appels d’API renvoient généralement les données brutes que le site restitue ensuite sur la page, de sorte que vous pouvez les cibler directement. Cette technique repose sur l’imitation des appels AJAX et est généralement connue sous le nom de web scraping API.
Voyons comment cela fonctionne !
Fonctionnement de l’approche de réplication des appels AJAX
La réplication AJAX est une technique de scraping pratique. L’idée de base est d’éviter le rendu de la page entière en imitant les requêtes réseau (généralement des appels AJAX) que l’application web effectue pour extraire des données de son backend.
À un niveau élevé, cela implique deux étapes principales :
- Fouinez: Ouvrez les outils de développement de votre navigateur (généralement l’onglet “Réseau” avec le filtre “Fetch/XHR” activé) et interagissez avec le site web. Observez quels appels API sont effectués en arrière-plan lorsque de nouvelles données sont chargées. Par exemple, lors d’un défilement infini ou d’un clic sur le bouton “Charger plus”.
- Reproduire: Une fois que vous avez identifié la bonne requête API, notez son URL, sa méthode HTTP (GET, POST, etc.), ses en-têtes et sa charge utile (le cas échéant). Reproduisez ensuite cette requête dans votre script de scraping à l’aide d’un client HTTP tel que Requests in Python.
Ces points d’extrémité de l’API renvoient généralement des données dans un format structuré, le plus souvent JSON. C’est un avantage considérable, car vous pouvez accéder aux données JSON sans avoir à analyser le code HTML.
Par exemple, regardez l’appel API effectué par un site qui utilise le défilement infini pour charger plus de données :
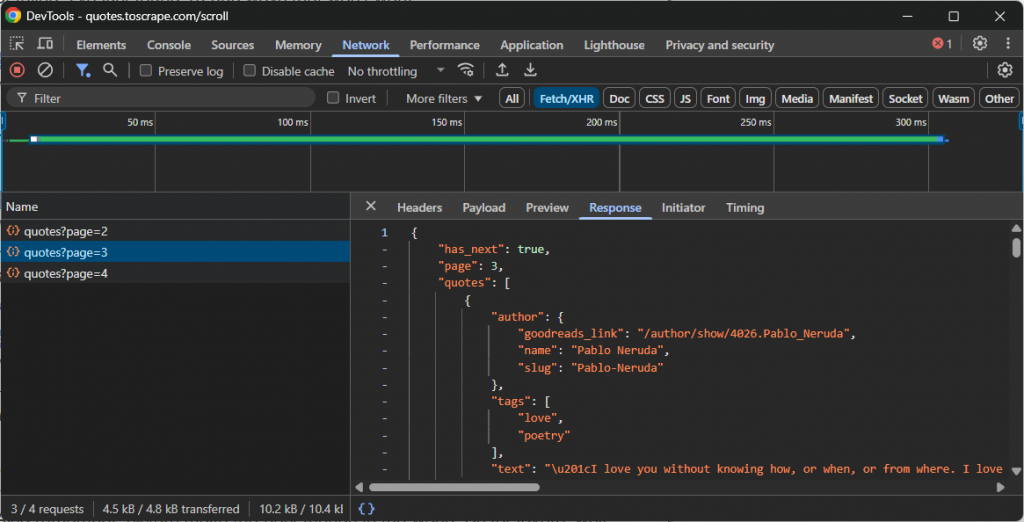
Dans ce cas, vous pouvez écrire un simple script de scraping qui reproduit l’appel API de défilement infini ci-dessus et accède ensuite aux données.
Principaux défis à relever lors de l’interception d’appels AJAX
Lorsqu’elle fonctionne, cette approche est rapide, efficace et simple. Elle comporte néanmoins quelques difficultés :
- Charges utiles obscurcies: L’API peut exiger des données utiles cryptées ou ne pas renvoyer de JSON propre et lisible. Il peut s’agir d’une chaîne cryptée qu’une fonction JavaScript spécifique sait décoder. Il s’agit d’une mesure anti-scraping qui nécessite une rétro-ingénierie.
- Points de terminaison et en-têtes dynamiques: Les points de terminaison de l’API et la manière de les appeler (par exemple, en définissant les en-têtes appropriés, en ajoutant la charge utile adéquate, etc. Le principal défi de cette solution est que toute évolution de l’API interrompt le scraper. Cela nécessite une maintenance du code pour restaurer la fonctionnalité, ce qui est un problème commun à la plupart des approches de web scraping (mais pas toutes, comme nous allons le voir).
- Empreinte TLS: Les anti-bots les plus avancés analysent la “poignée de main TLS”, qui est la signature numérique du programme. Ils peuvent facilement faire la différence entre une requête provenant de Chrome et une requête provenant d’un script Python standard. Pour contourner ce problème, vous avez besoin d’outils spécialisés capables d’imiter la signature TLS d’un navigateur.
Une approche moderne du scraping des sites à forte composante JavaScript : Agents de scraping de navigateur alimentés par l’IA
Les méthodes décrites jusqu’à présent se heurtent encore à des difficultés majeures. Une solution plus moderne pour le scraping de sites à forte composante JavaScript nécessite un changement de paradigme. L’idée est de passer de l’écriture de commandes impératives à la définition d’objectifs déclaratifs à l’aide d’agents de navigation pilotés par l’IA.
Un navigateur agent est un navigateur intégré à un LLM qui comprend le contenu, le contexte et la présentation visuelle de la page. Cela change fondamentalement la façon dont nous abordons le scraping web, en particulier pour les sites web à forte composante JavaScript.
Ces sites nécessitent généralement des interactions complexes avec l’utilisateur pour charger les données souhaitées. Traditionnellement, vous devez injecter de la logique pour reproduire ces interactions dans vos scripts. Cette approche est intrinsèquement fragile et nécessite beaucoup de maintenance. Le problème est que chaque fois que le flux d’utilisateurs change, vous devez mettre à jour manuellement votre logique d’automatisation.
Grâce aux agents de navigation dotés d’une intelligence artificielle, vous pouvez éviter tout cela. Une simple invite descriptive peut conduire à une automatisation efficace qui s’adapte même lorsque l’interface utilisateur ou le flux du site change. Cette flexibilité est un énorme avantage et ouvre la porte à de nombreuses autres possibilités d’automatisation, ce qui explique pourquoi l ‘IA agentique gagne rapidement du terrain.
Désormais, quelle que soit la puissance de votre bibliothèque d’agents de navigation IA, votre logique de scraping dépend toujours des navigateurs classiques. Cela signifie que vous restez vulnérable à des problèmes tels que l’empreinte du navigateur et les CAPTCHA. La mise à l’échelle de ces solutions devient également difficile en raison des limites de débit et des interdictions d’IP.
La vraie solution est une plateforme de scraping basée sur le cloud, prête pour l’IA, qui s’intègre à n’importe quelle bibliothèque agentique et qui est conçue pour éviter d’être bloquée. C’est exactement ce que propose l’Agent Browser de Bright Data.
Agent Browser vous permet d’exécuter des flux de travail pilotés par l’IA sur des navigateurs distants qui ne sont jamais bloqués. Il est évolutif à l’infini, prend en charge les modes “headless” et “headful” et s’appuie sur le réseau de proxy le plus fiable au monde.
Conclusion
Dans cet article, vous avez appris ce que sont les sites web à forte composante JavaScript, ainsi que les défis et les solutions les plus courants pour extraire des données de ces sites. Chaque solution décrite a ses limites, mais celle qui s’impose est l’utilisation d’un navigateur agent.
Comme nous l’avons vu, l’Agent Browser de Bright Data vous permet de résoudre tous les problèmes courants de scraping tout en intégrant les bibliothèques d’IA agentique les plus populaires.
Si vous utilisez des agents de scraping IA avancés, vous avez besoin d’outils fiables pour récupérer, valider et transformer le contenu Web. Pour toutes ces capacités et bien plus encore, explorez l’infrastructure d’IA de Bright Data.
Créez un compte Bright Data et essayez tous nos produits et services pour le développement d’agents d’IA !





