

Des assistants de recherche autonomes aux agents qui gèrent l’ensemble des flux de travail, les agents IA sont en train de devenir bien plus qu’une simple tendance ; ils façonnent l’avenir du travail, du développement et de la prise de décision. Mais derrière chaque agent compétent se cache une pile technologique soigneusement construite, un système d’outils à plusieurs niveaux qui permet à ces agents de raisonner, d’agir et de s’adapter.
Ce qui alimente la prochaine génération d’automatisation
Pour les développeurs, il est essentiel de comprendre cette pile. Il ne s’agit pas seulement de savoir quels outils sont à la mode, mais aussi comment ils fonctionnent ensemble, où se trouve leur véritable valeur et quels éléments fondamentaux doivent être en place pour que les agents fonctionnent de manière fiable.
Chez Bright Data, nous travaillons avec des équipes d’IA dans tous les secteurs, et une chose est claire : chaque agent commence par les données. Dans cet article, nous allons passer en revue les couches fondamentales de la pile technologique des agents IA, en commençant par la plus critique : la collecte et l’intégration des données.
Collecte et intégration des données
La première étape dans la création d’agents plus intelligents
Avant qu’un agent IA puisse raisonner, planifier ou agir, il doit comprendre le monde dans lequel il évolue. Cette compréhension commence par des données réelles, en temps réel et souvent non structurées. Qu’il s’agisse de former un modèle, d’alimenter un système de génération augmentée par la récupération (RAG) ou de permettre à un agent de réagir aux changements du marché en temps réel, les données sont le carburant.
C’est là que Bright Data entre en jeu.
Nous fournissons l’infrastructure qui permet aux équipes d’IA d’exploiter le web public à grande échelle, avec précision et en toute conformité. Nos outils sont conçus pour rendre la collecte de données non seulement possible, mais aussi transparente.
Le rôle de Bright Data dans la pile
- API de recherche – Affiche le contenu web pertinent en temps réel, idéal pour la recherche améliorée par RAG et LLM.
- API Unlocker – Contourne les protections anti-bot pour garantir un accès fiable aux sources de données publiques.
- API Web Scraper – Extrait des données structurées de plus de 120 000 sites web, prêtes à être utilisées immédiatement.
- Custom Scraper – Solutions sur mesure pour les marchés verticaux de niche et les besoins spécifiques des agents.
- Dataset Marketplace – Jeux de données pré-collectés pour un prototypage rapide ou un ajustement précis des modèles.
- Annotations IA – Services humains pour l’étiquetage et le raffinement des données d’entraînement.
« Si les agents IA sont le cerveau, Bright Data est les yeux. »
Cas d’utilisation : agent de veille commerciale
Une entreprise de vente au détail crée un agent IA pour surveiller les prix et la disponibilité des produits de ses concurrents. À l’aide des API Web Scraper et Unlocker de Bright Data, l’agent collecte des données en temps réel sur les sites des concurrents et les transmet à un moteur de tarification qui ajuste les offres de manière dynamique.
Stack technologique complet de l’agent IA
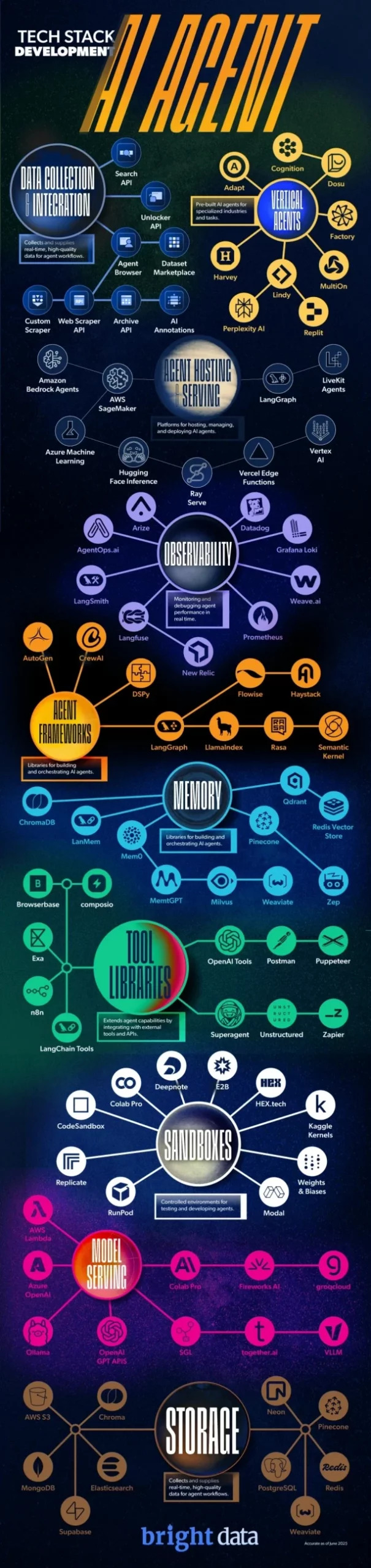
Services d’hébergement d’agents
Là où les agents IA prennent vie
Une fois qu’un agent a accès aux données, il a besoin d’un environnement numérique où il peut raisonner, prendre des décisions et agir. C’est le rôle des services d’hébergement d’agents : ils fournissent l’infrastructure qui transforme les modèles statiques en systèmes dynamiques et autonomes.
Ces plateformes gèrent tout, de l’orchestration à l’exécution, et garantissent que les agents peuvent évoluer, interagir avec les API et fonctionner en continu.
Ce que les développeurs utilisent
- LangGraph – Un runtime basé sur des graphes pour créer des workflows d’agents à plusieurs étapes et avec état.
- Hugging Face Inference Endpoints – Héberge et fournit des modèles et des agents, avec des outils tels que Transformers Agents pour les interactions en temps réel.
- AWS (Bedrock, Lambda, SageMaker) – Offre une infrastructure flexible et évolutive pour déployer et gérer des agents à grande échelle.
Les plateformes d’hébergement sont les systèmes d’exploitation du monde des agents, mais même le meilleur agent hébergé n’est aussi performant que les données sur lesquelles il repose.
Observabilité
Rendre les agents IA transparents, traçables et fiables
À mesure que les agents deviennent plus autonomes, il devient essentiel de comprendre ce qu’ils font et pourquoi. Les outils d’observabilité aident les développeurs à surveiller les performances, à suivre les décisions et à déboguer les problèmes en temps réel.
Ce que les développeurs utilisent
- LangSmith (LangChain) – Trace, débogue et évalue les flux de travail alimentés par LLM.
- Weights & Biases – Suit les performances des modèles, les expériences et le comportement des agents au fil du temps.
- WhyLabs – Surveille la dérive des données et les anomalies des modèles dans les environnements de production.
L’observabilité transforme les agents de boîtes noires en boîtes transparentes, offrant aux développeurs la visibilité dont ils ont besoin pour instaurer la confiance et itérer en toute sécurité.
Cadres d’agents
Les plans pour créer des agents plus intelligents et plus performants
Les cadres définissent la structure des agents, leur mode de raisonnement, leur interaction avec les outils et leur collaboration avec d’autres agents. À mesure que la complexité des agents augmente, les cadres évoluent pour prendre en charge les systèmes multi-agents, la décomposition des tâches et la planification dynamique.
Ce que les développeurs utilisent
- Crew IA – Permet à des équipes d’agents de collaborer, chacun ayant des rôles et des responsabilités définis.
- LangGraph – Prend en charge la logique de branchement et les workflows avec état pour les comportements complexes des agents.
- DSPy – Un cadre déclaratif pour optimiser et affiner les pipelines LLM.
Les frameworks donnent aux agents leur structure et leur logique, mais ils dépendent de données précises et en temps réel pour fonctionner efficacement.
Mémoire
Comment les agents mémorisent, apprennent et restent sensibles au contexte
Les systèmes de mémoire permettent aux agents de conserver le contexte, de se souvenir des interactions passées et de développer une compréhension à long terme. Généralement alimentée par des bases de données vectorielles, la mémoire est essentielle pour la personnalisation, la continuité et le raisonnement complexe.
Ce que les développeurs utilisent
- ChromaDB – Léger et idéal pour le développement local.
- Qdrant – Recherche vectorielle évolutive et prête à la production avec filtrage hybride.
- Weaviate – Modulaire et compatible avec le ML, souvent utilisé dans les déploiements de niveau entreprise.
La mémoire permet aux agents d’apprendre et de s’adapter, mais elle n’est utile que dans la mesure où les données qu’elle stocke le sont également, ce qui renforce la nécessité d’une entrée de haute qualité dès le départ.
Bibliothèques d’outils
Comment les agents agissent dans le monde réel
Les bibliothèques d’outils permettent aux agents d’interagir avec des API de systèmes externes, des bases de données, des moteurs de recherche, etc. C’est ce qui transforme les modèles linguistiques en agents opérationnels.
Ce que les développeurs utilisent
- LangChain – Un écosystème robuste pour enchaîner les LLM avec des outils, de la mémoire et des flux de travail.
- OpenAI Functions – Permet aux agents d’appeler des outils externes directement à partir des modèles GPT.
- Exa – Permet la recherche Web en temps réel, souvent utilisée dans les agents de recherche et les systèmes RAG.
Les bibliothèques d’outils sont ce qui rend les agents utiles, mais leur efficacité dépend de la qualité des données avec lesquelles ils interagissent.
Sandboxes
Où les agents exécutent du code et testent des idées en toute sécurité
Les agents ont de plus en plus besoin d’écrire et d’exécuter du code, que ce soit pour l’analyse de données, les simulations ou la prise de décision dynamique. Les sandbox offrent des environnements sécurisés et isolés pour cela.
Ce que les développeurs utilisent
- OpenAI Code Interpreter – Exécute Python en toute sécurité dans GPT-4 pour les tâches nécessitant un volume important de données.
- Replit – Un environnement de codage basé sur le cloud avec intégration de l’IA.
- Modal – Infrastructure sans serveur qui sert également de couche d’exécution de code sécurisée.
Les sandbox permettent aux agents de raisonner sur des problèmes et de générer des résultats exploitables, mais là encore, la qualité de ces résultats dépend de la qualité des entrées.
Modèle de service
Le deuxième cerveau : là où les décisions sont prises
Si les données constituent le premier cerveau de l’agent IA, ce que les agents savent, alors le service de modèles est leur deuxième mode de réflexion.
C’est là que les LLM sont hébergés et accessibles, fournissant le raisonnement et la génération de langage qui alimentent chaque décision de l’agent. Les performances, la latence et la précision de cette couche ont un impact direct sur l’efficacité de l’agent.
Ce que les développeurs utilisent
- OpenAI (GPT-4, GPT-4o) – Norme industrielle pour le raisonnement général et les capacités multimodales.
- Anthropic (Claude) – Connu pour ses longues fenêtres contextuelles et sa conception axée sur l’alignement.
- Mistral – Modèles à poids ouvert offrant des performances élevées à moindre coût.
- Groq – Inférence à très faible latence pour des réponses en temps réel des agents.
- AWS ( SageMaker, Bedrock) – Infrastructure évolutive pour servir à la fois des modèles propriétaires et ouverts.
La mise en service des modèles est le moment où les informations deviennent des actions, mais même les meilleurs modèles ont besoin de données de haute qualité en temps réel pour raisonner efficacement.
Stockage
Où les agents conservent leur historique, leurs connaissances et leur état
Les systèmes de stockage prennent en charge la persistance à long terme, l’enregistrement des interactions, la sauvegarde des résultats et le maintien de l’état entre les sessions. Ils sont essentiels pour la reproductibilité, la conformité et l’amélioration continue.
Ce que les développeurs utilisent
- Amazon S3 – La référence en matière de stockage d’objets évolutif.
- Google Cloud Storage (GCS) – Sécurisé et intégré aux outils d’IA de Google.
- Bases de données vectorielles (par exemple, Qdrant, Weaviate) – Stockent les intégrations et le contexte sémantique pour la récupération.
Le stockage permet aux agents d’apprendre du passé et d’évoluer au fil du temps, mais la valeur de ce qui est stocké dépend avant tout de la qualité des données collectées.
Vos agents ne sont aussi intelligents que leurs données
Les agents IA ne sont aussi performants que les informations sur lesquelles ils sont basés. Ils peuvent raisonner, planifier et agir, mais uniquement s’ils ont accès aux bonnes données au bon moment. Sans cela, même la pile technologique la plus sophistiquée devient une boucle fermée : puissante, mais déconnectée du monde réel.
C’est pourquoi les données ne sont pas seulement une partie de la pile, elles en sont le fondement. Et dans l’écosystème actuel de l’IA, la source de données la plus précieuse est le web public.
Chez Bright Data, nous rendons ces données accessibles.
Nos outils alimentent la première étape, qui est aussi la plus critique, du flux de travail des agents IA : la collecte et l’intégration des données. Nous connectons les agents au web public en temps réel, leur fournissant les données structurées, fiables et évolutives dont ils ont besoin pour comprendre le monde, prendre des décisions éclairées et mener des actions significatives.
Chaque couche de la pile technologique (cadres d’agents, systèmes de mémoire, bibliothèques d’outils, modèles de service) dépend de cette base. Car sans informations précises et à jour, les agents ne peuvent pas s’adapter, se personnaliser ou fonctionner.
En quelque sorte, vos agents ont deux cerveaux :
- Les données : ce qu’ils savent.
- Le modèle : leur façon de penser.
Avant de pouvoir agir, vos agents doivent comprendre.
Avant de pouvoir comprendre, ils doivent voir.
Bright Data est leur façon de voir le monde.
Étape suivante
Découvrez comment Bright Data peut optimiser votre pile d’agents IA : https://brightdata.com/ai/products-for-ai






