

Dans ce guide, vous apprendrez :
- Comment identifier quand un site a une navigation complexe
- Le meilleur outil de scraping pour gérer ces scénarios
- Comment scraper les modèles de navigation complexes courants
C’est parti !
Quand un site présente-t-il une navigation complexe ?
Un site avec une navigation complexe est undéficourant auquel nous sommes confrontés en tant que développeurs dansle domaine du Scraping web. Mais que signifie exactement « navigation complexe » ? Dans le Scraping web, la navigation complexe fait référence aux structures de sites web où le contenu ou les pages ne sont pas facilement accessibles.
Les scénarios de navigation complexes impliquent souvent des éléments dynamiques, le chargement asynchrone de données ou des interactions pilotées par l’utilisateur. Si ces aspects peuvent améliorer l’expérience utilisateur, ils compliquent considérablement les processus d’extraction de données.
La meilleure façon de comprendre la navigation complexe est d’étudier quelques exemples :
- Navigation rendue par JavaScript: sites web qui s’appuient sur des frameworks JavaScript (tels que React, Vue.js ou Angular) pour générer du contenu directement dans le navigateur.
- Contenu paginé: sites dont les données sont réparties sur plusieurs pages. Cela devient plus complexe lorsque la pagination est chargée numériquement via AJAX, ce qui rend plus difficile l’accès aux pages suivantes.
- Défilement infini: pages qui chargent du contenu supplémentaire de manière dynamique lorsque les utilisateurs font défiler vers le bas, ce qui est courant dans les flux des réseaux sociaux et les sites Web d’actualités.
- Menus à plusieurs niveaux: sites avec des menus imbriqués qui nécessitent plusieurs clics ou actions de survol pour révéler des niveaux de navigation plus profonds (par exemple, les arborescences de catégories de produits sur les grandes plateformes de commerce électronique).
- Interfaces de cartes interactives: sites web affichant des informations sur des cartes ou des graphiques, où les points de données sont chargés dynamiquement lorsque les utilisateurs effectuent un panoramique ou un zoom.
- Onglets ou accordéons: pages dont le contenu est masqué sous des onglets rendus dynamiquement ou des accordéons repliables dont le contenu n’est pas directement intégré dans la page HTML renvoyée par le serveur.
- Filtres dynamiques et options de tri: sites dotés de systèmes de filtrage complexes où l’application de plusieurs filtres recharge dynamiquement la liste des éléments, sans modifier la structure de l’URL.
Meilleurs outils de scraping pour gérer les sites web à navigation complexe
Pour scraper efficacement un site à la navigation complexe, vous devez comprendre quels outils vous devez utiliser. La tâche elle-même est intrinsèquement difficile, et ne pas utiliser les bonnes bibliothèques de scraping ne fera que la rendre plus difficile.
La plupart des interactions complexes énumérées ci-dessus ont en commun les caractéristiques suivantes :
- nécessitent une forme d’interaction de l’utilisateur, ou
- sont exécutées côté client dans le navigateur.
En d’autres termes, ces tâches nécessitent l’exécution de JavaScript, ce que seul un navigateur peut faire. Cela signifie que vous ne pouvez pas vous fier àdesimplesanalyseurs HTMLpour ces pages. Vous devez plutôt utiliser un outil d’automatisation de navigateur tel que Selenium, Playwright ou Puppeteer.
Ces solutions vous permettent de programmer un navigateur pour qu’il effectue des actions spécifiques sur une page web, imitant ainsi le comportement d’un utilisateur. On les appelle souvent «navigateurs sans interface graphique» car ils peuvent afficher le navigateur sans interface graphique, ce qui permet d’économiser les ressources du système.
Découvrez lesmeilleurs outils de navigation sans interface graphique pour le Scraping web.
Comment extraire des modèles de navigation complexes courants
Dans cette section du tutoriel, nous utiliserons Selenium en Python. Cependant, vous pouvez facilement adapter la logique à Playwright, Puppeteer ou tout autre outil d’automatisation de navigateur. Nous supposerons également que vous connaissez déjà les bases duScraping web avec Selenium.
Plus précisément, nous aborderons la manière de scraper les modèles de navigation complexes courants suivants :
- Pagination dynamique: sites dont les données paginées sont chargées dynamiquement via AJAX.
- Bouton « Charger plus »: un exemple courant de navigation basée sur JavaScript.
- Défilement infini: une page qui charge continuellement des données à mesure que l’utilisateur fait défiler vers le bas.
C’est parti pour le codage !
Pagination dynamique
La page cible pour cet exemple est le bac à sable «Films oscarisés : AJAX et Javascript » :
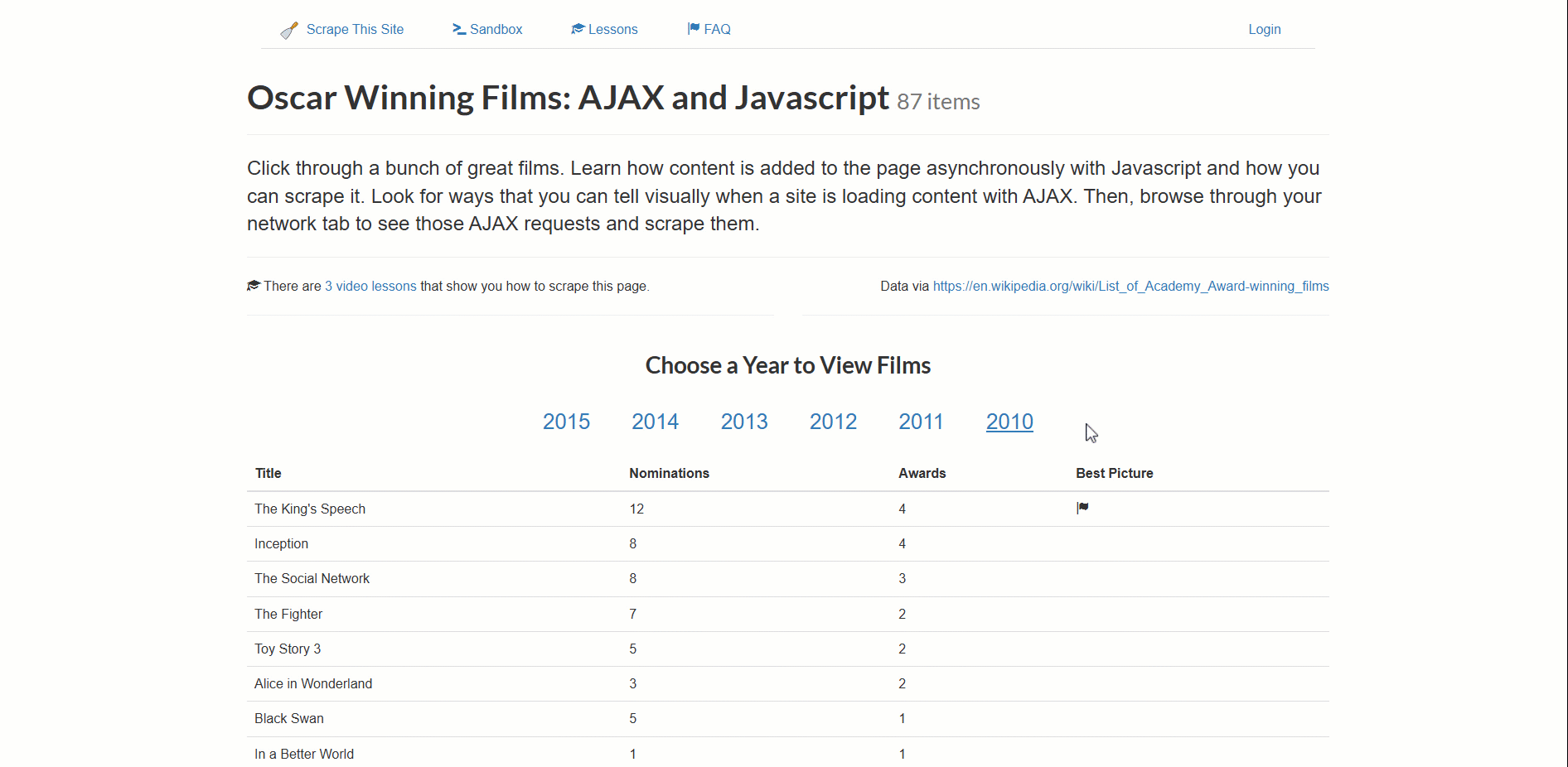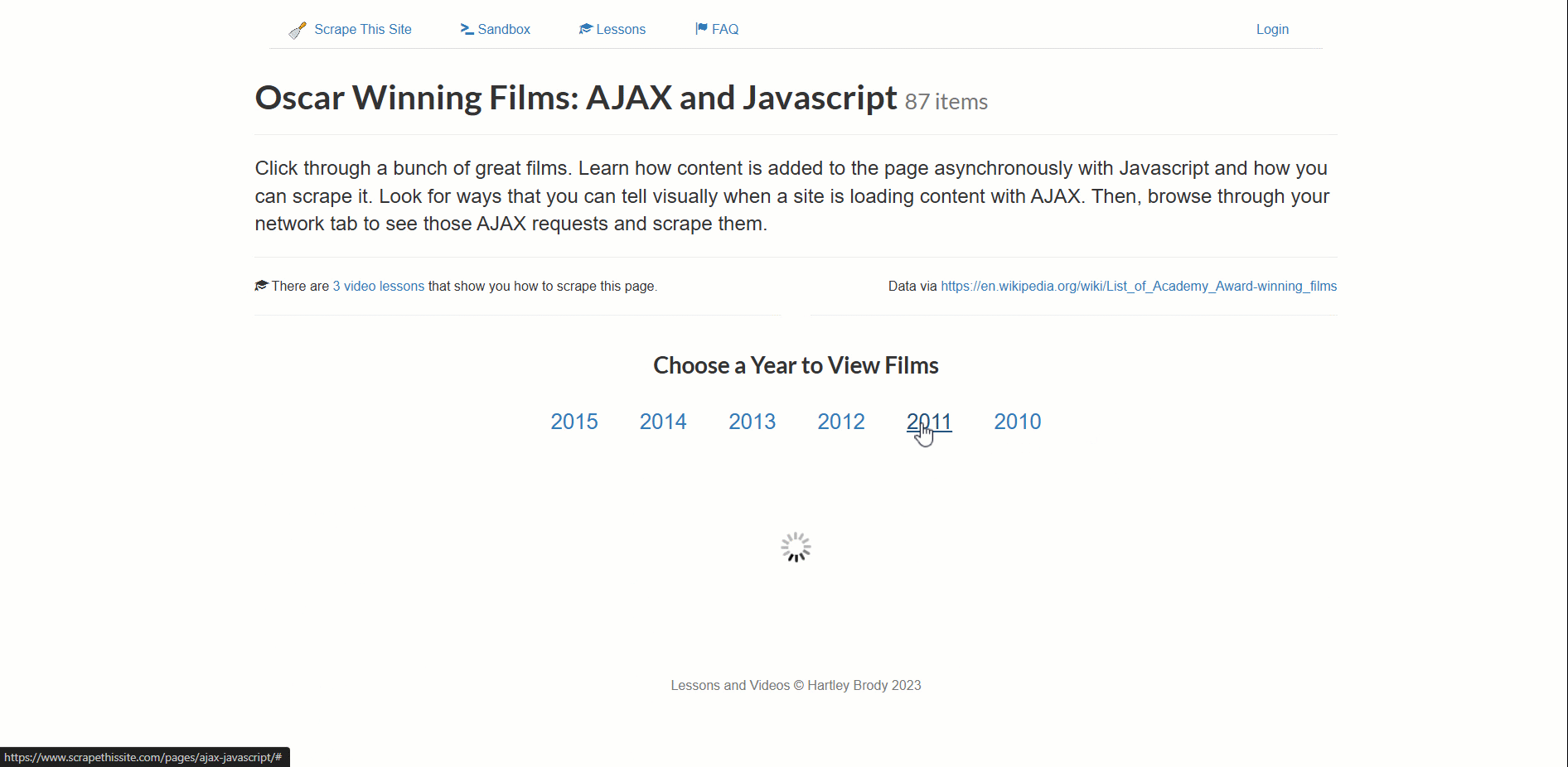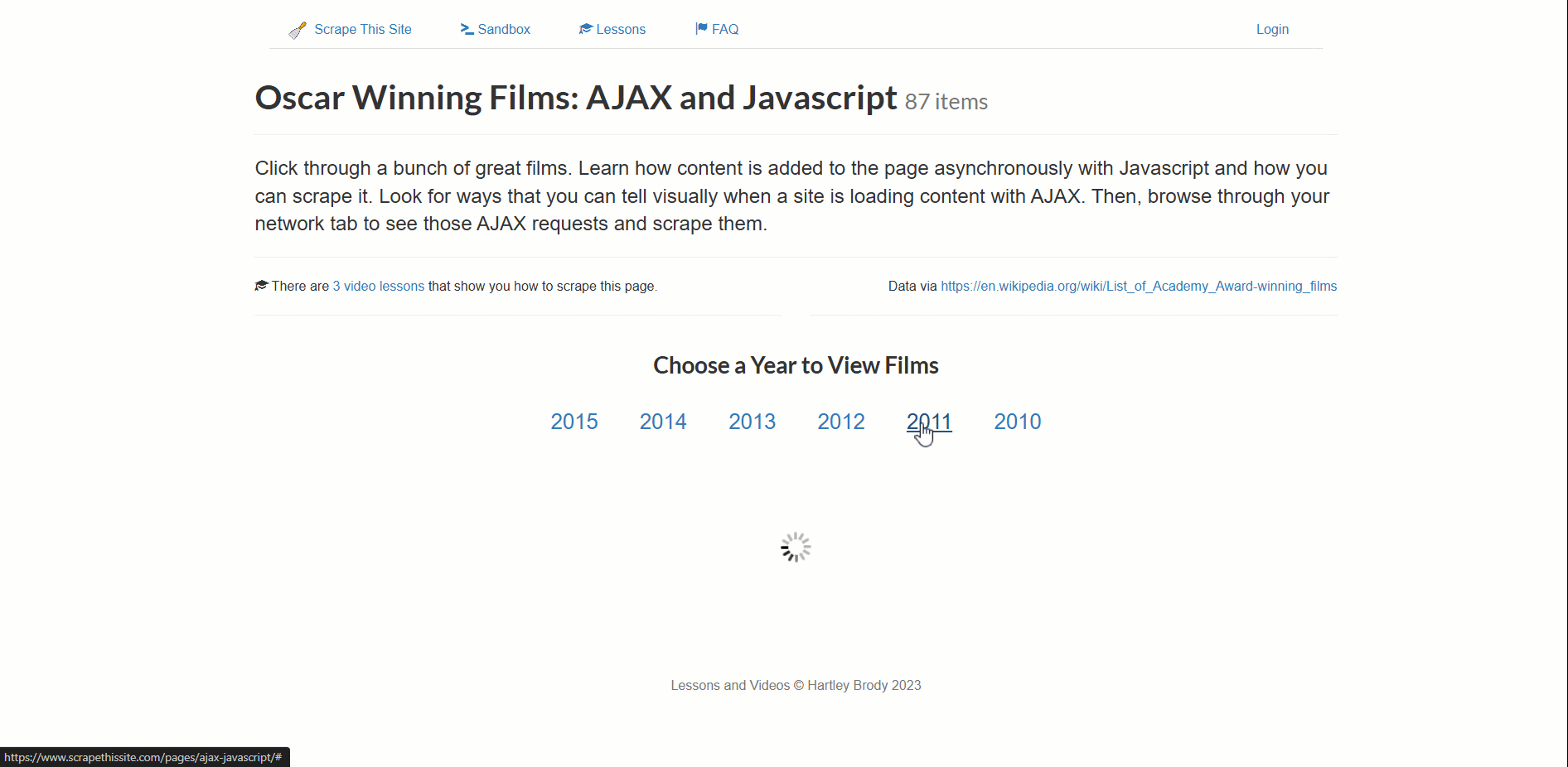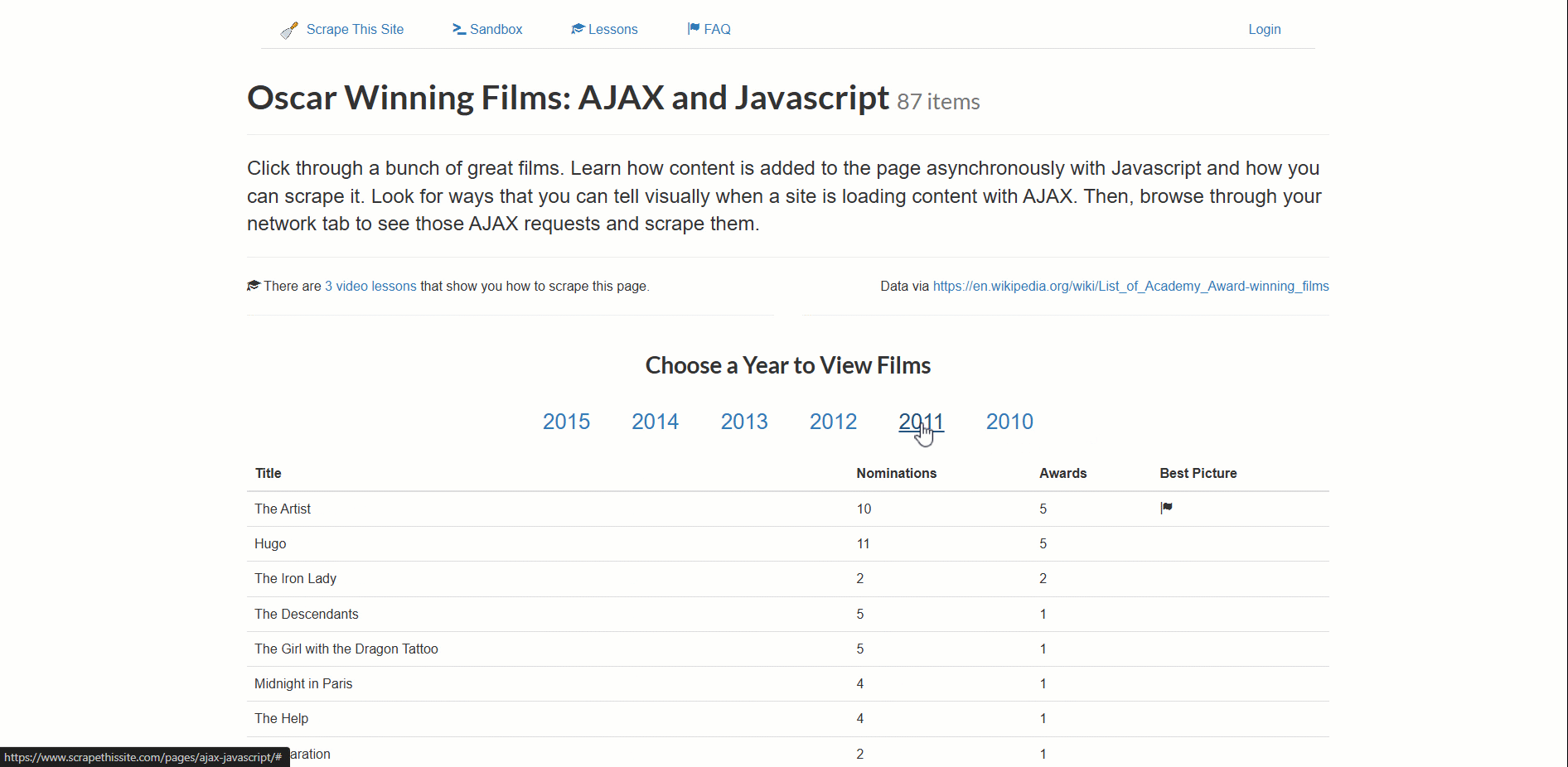
Ce site charge dynamiquement les données relatives aux films oscarisés, paginées par année.
Pour gérer une navigation aussi complexe, l’approche est la suivante :
- Cliquez sur une nouvelle année pour déclencher le chargement des données (un élément de chargement apparaîtra).
- Attendez que l’élément de chargement disparaisse (les données sont alors entièrement chargées).
- Assurez-vous que le tableau contenant les données s’affiche correctement sur la page.
- Récupérez les données une fois qu’elles sont disponibles.
Voici en détail comment vous pouvez mettre en œuvre cette logique à l’aide de Selenium en Python :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
# Configurer les options Chrome pour le mode sans affichage
options = Options()
options.add_argument("--headless")
# Créer une instance de pilote Web Chrome
driver = webdriver.Chrome(service=Service(), options=options)
# Se connecter à la page cible
driver.get("https://www.scrapethissite.com/pages/ajax-javascript/")
# Cliquer sur le bouton de pagination « 2012 »
element = driver.find_element(By.ID, "2012")
element.click()
# Attendre que le chargeur ne soit plus visible
WebDriverWait(driver, 10).until(
lambda d: d.find_element(By.CSS_SELECTOR, "#loading").get_attribute("style") == "display: none;")
# Les données devraient maintenant être chargées...
# Attendre que le tableau soit présent sur la page
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, ".table")))
# Où stocker les données extraites
films = []
# Extraire les données du tableau
table_body = driver.find_element(By.CSS_SELECTOR, "#table-body")
rows = table_body.find_elements(By.CSS_SELECTOR, ".film")
for row in rows:
title = row.find_element(By.CSS_SELECTOR, ".film-title").text
nominations = row.find_element(By.CSS_SELECTOR, ".film-nominations").text
awards = row.find_element(By.CSS_SELECTOR, ".film-awards").text
best_picture_icon = row.find_element(By.CSS_SELECTOR, ".film-best-picture").find_elements(By.TAG_NAME, "i")
best_picture = True if best_picture_icon else False
# Stocker les données récupérées
films.append({
"title": title,
"nominations": nominations,
"awards": awards,
"best_picture": best_picture
})
# Logique d'exportation des données...
# Fermer le pilote du navigateur
driver.quit()
Voici la décomposition du code ci-dessus :
- Le code configure une instance Chrome sans interface graphique.
- Le script ouvre la page cible et clique sur le bouton de pagination « 2012 » pour déclencher le chargement des données.
- Selenium attend que le chargeur disparaisse à l’aide de
WebDriverWait(). - Une fois le chargeur disparu, le script attend que le tableau apparaisse.
- Une fois les données entièrement chargées, le script extrait les titres des films, les nominations, les récompenses et indique si le film a remporté l’Oscar du meilleur film. Il stocke ces données dans une liste de dictionnaires.
Le résultat sera le suivant :
[
{
"title": "Argo",
"nominations": "7",
"awards": "3",
"best_picture": true
},
// ...
{
"title": "Curfew",
"nominations": "1",
"awards": "1",
"best_picture": false
}
]
Notez qu’il n’existe pas toujours une seule façon optimale de gérer ce modèle de navigation. D’autres options peuvent être nécessaires en fonction du comportement de la page. Voici quelques exemples :
- Utilisez
WebDriverWait()en combinaison avec des conditions attendues pour attendre l’apparition ou la disparition d’éléments HTML spécifiques. - Surveillez le trafic des requêtes AJAX pour détecter quand un nouveau contenu est récupéré. Cela peut impliquer l’utilisation de la journalisation du navigateur.
- Identifiez la requête API déclenchée par la pagination et effectuez des requêtes directes pour récupérer les données par programmation (par exemple, à l’aide de labibliothèque
de requêtes).
Bouton « Charger plus »
Pour représenter des scénarios de navigation complexes basés sur JavaScript impliquant une interaction avec l’utilisateur, nous avons choisi l’exemple du bouton « Charger plus ». Le concept est simple : une liste d’éléments s’affiche et des éléments supplémentaires sont chargés lorsque l’on clique sur le bouton.
Cette fois-ci, le site cible sera la paged’exemple « Charger plus »du cours sur le scraping :
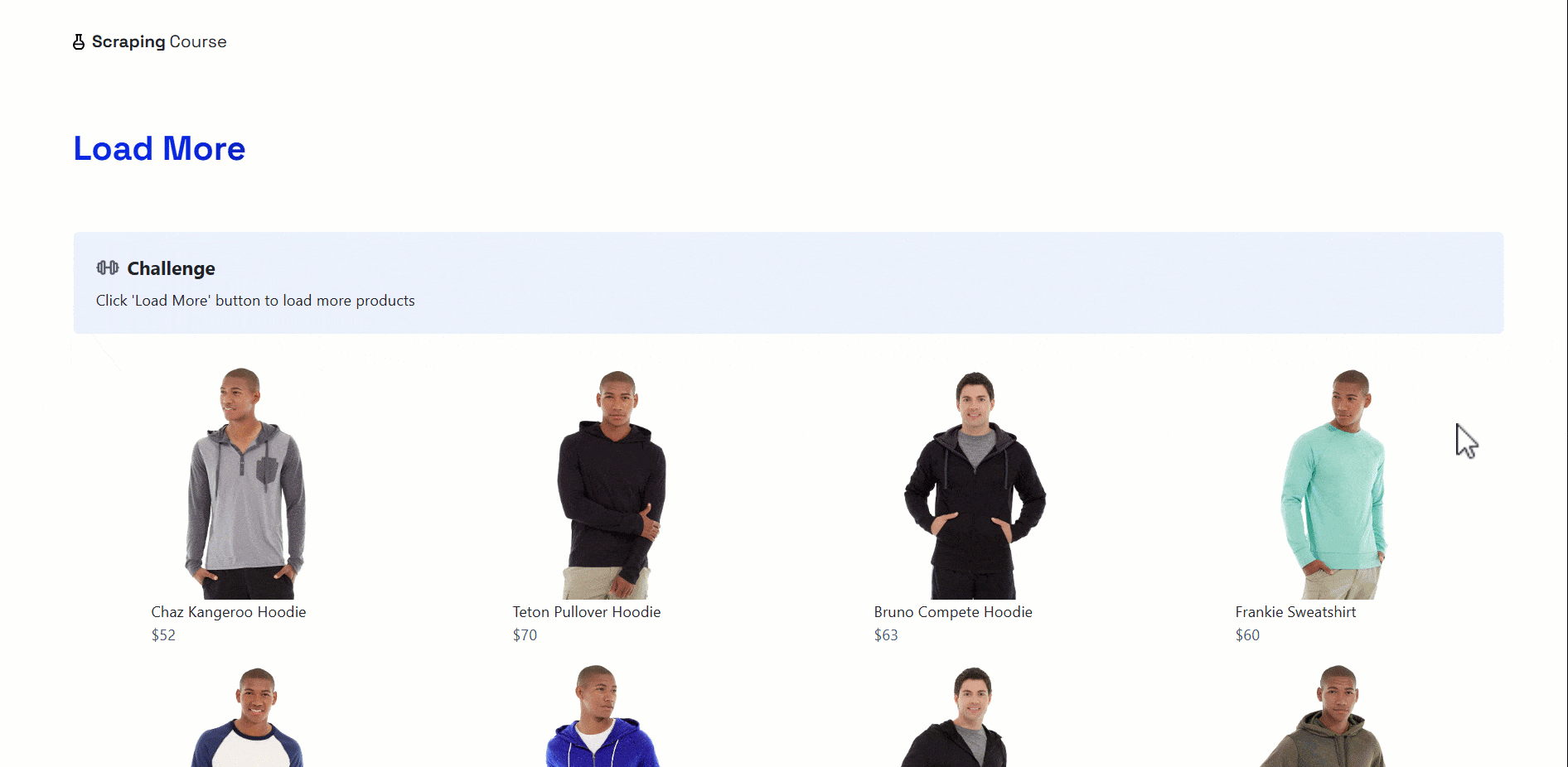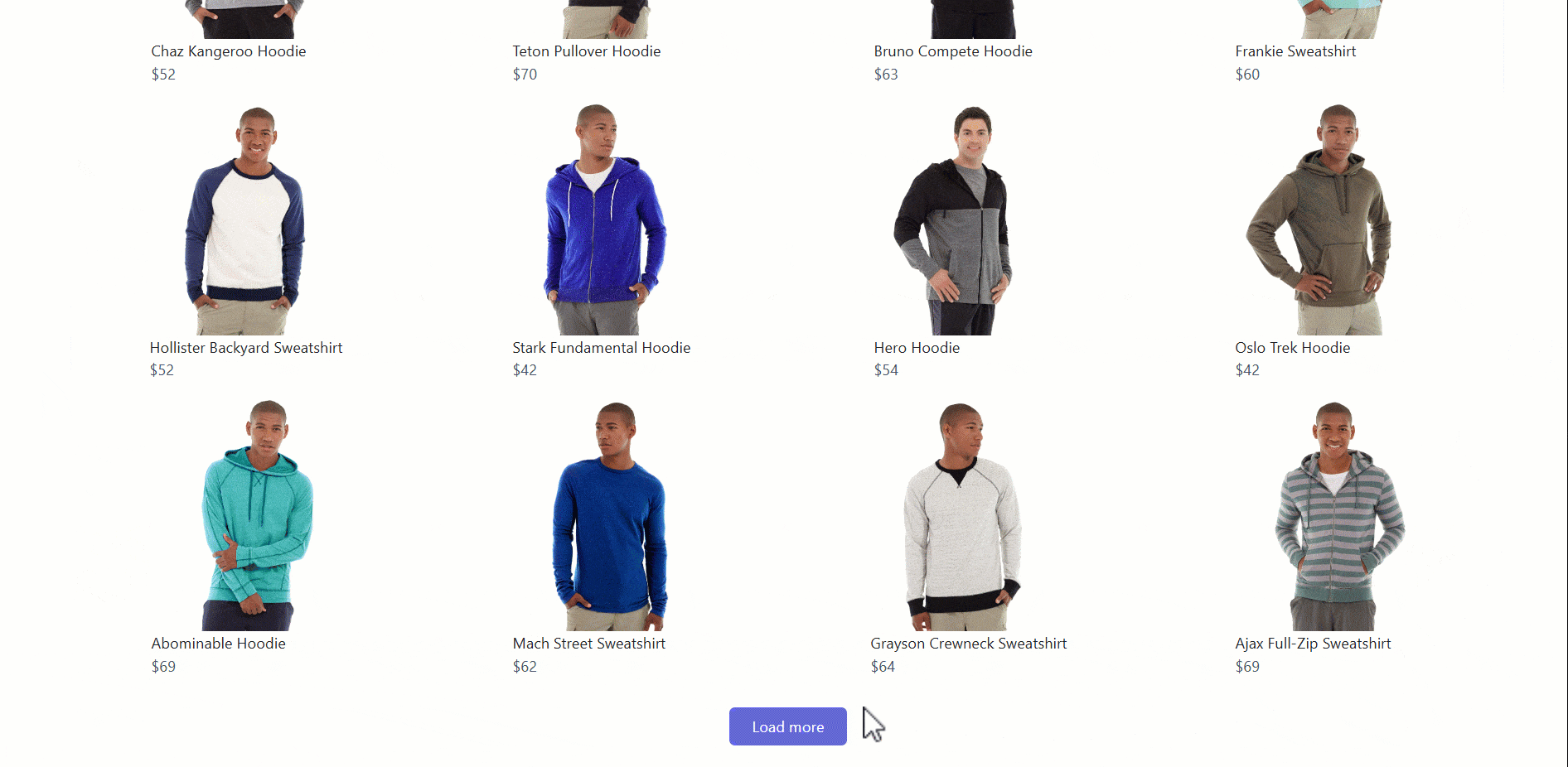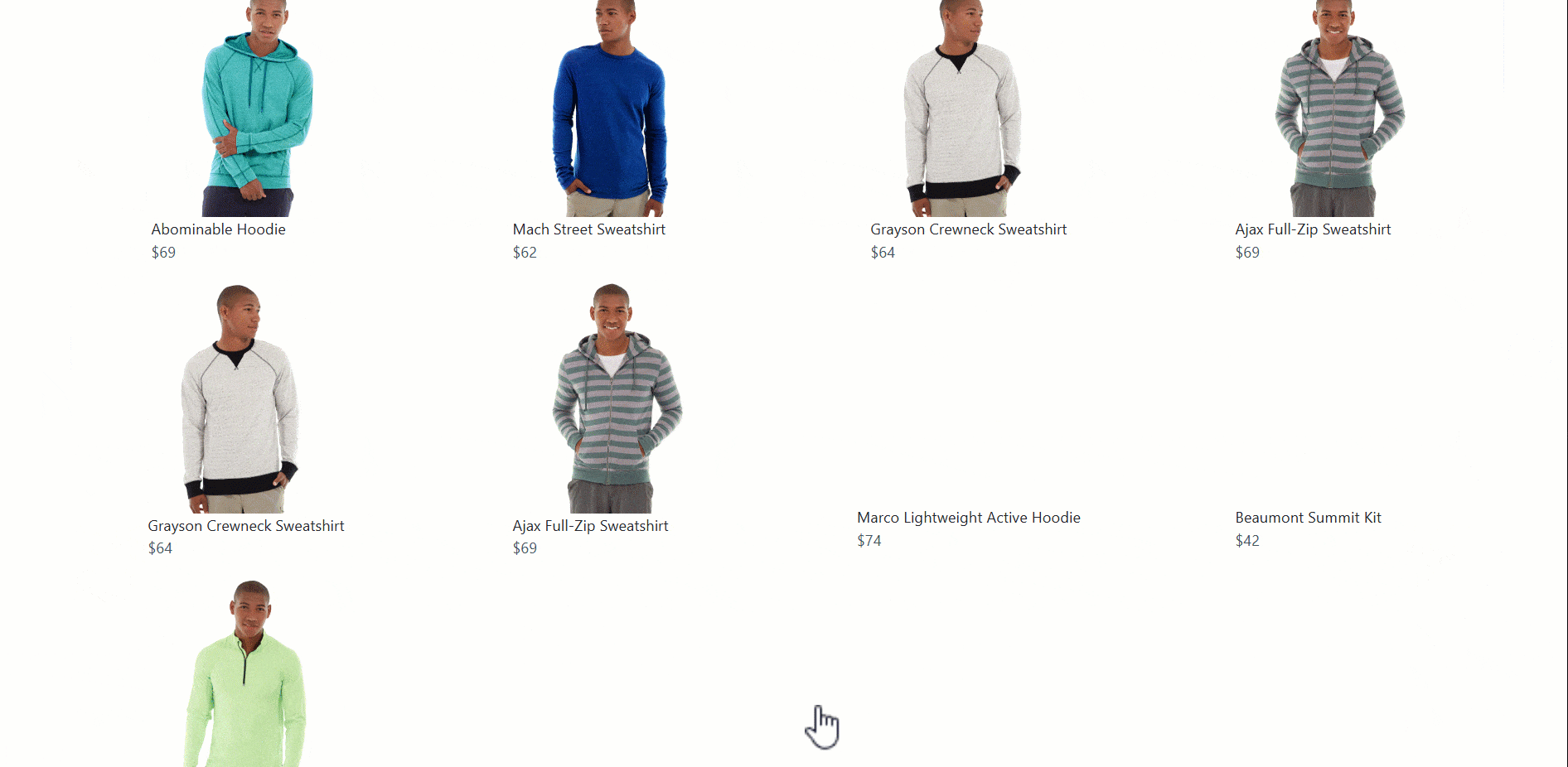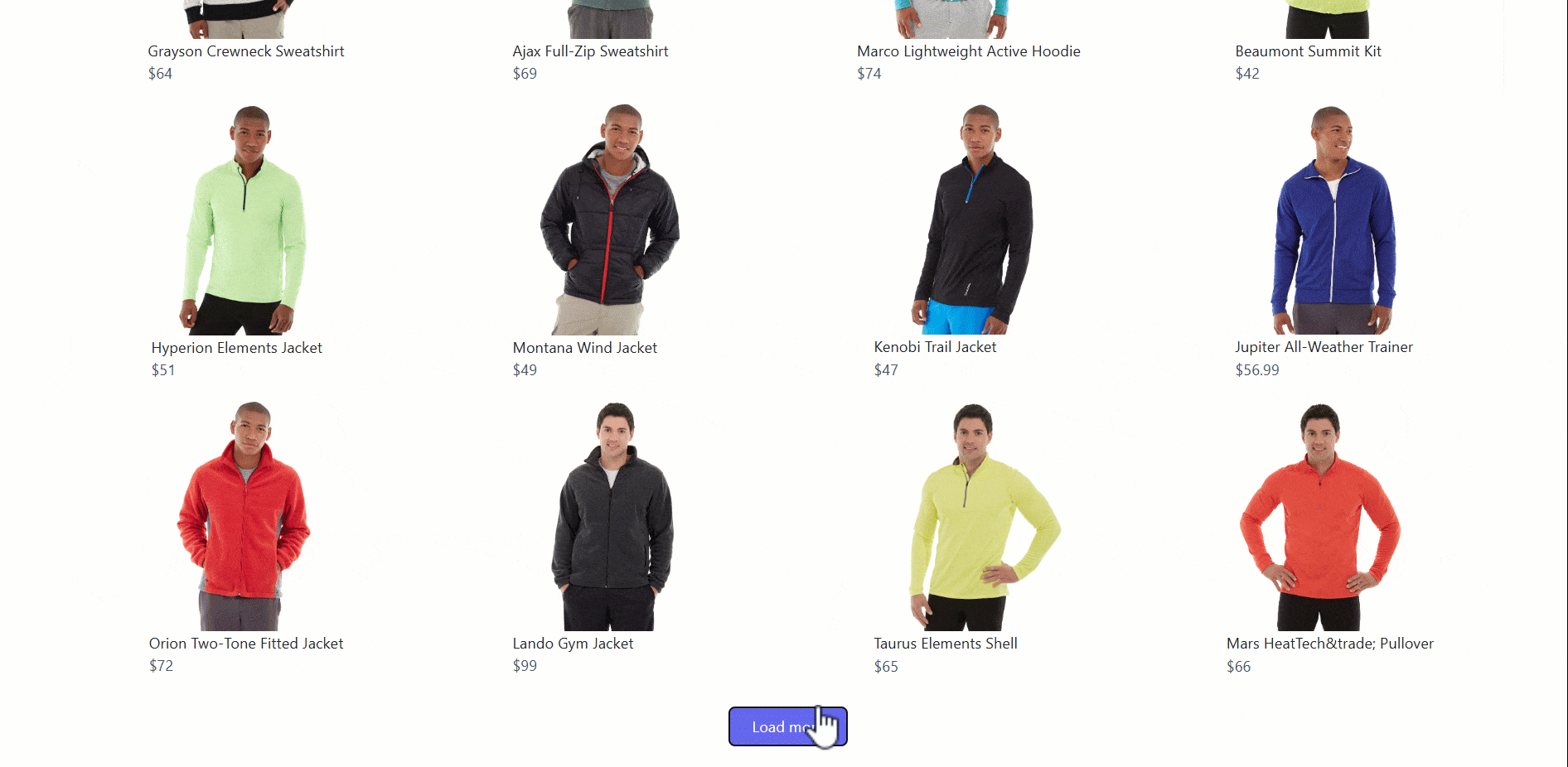
Pour gérer ce modèle de scraping de navigation complexe, procédez comme suit :
- Localisez le bouton « Charger plus » et cliquez dessus.
- Attendez que les nouveaux éléments se chargent sur la page.
Voici comment vous pouvez implémenter cela avec Selenium :
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
# Configurer les options Chrome pour le mode headless
options = Options()
options.add_argument("--headless")
# Créer une instance de pilote Web Chrome
driver = webdriver.Chrome(options=options)
# Se connecter à la page cible
driver.get("https://www.scrapingcourse.com/button-click")
# Collecte du nombre initial de produits
initial_product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# Localisation du bouton « Charger plus » et clic dessus
load_more_button = driver.find_element(By.CSS_SELECTOR, "#load-more-btn")
load_more_button.click()
# Attendre que le nombre d'articles sur la page ait augmenté
WebDriverWait(driver, 10).until(lambda driver: len(driver.find_elements(By.CSS_SELECTOR, ".product-item")) > initial_product_count)
# Où stocker les données récupérées
products = []
# Récupérer les détails des produits
product_elements = driver.find_elements(By.CSS_SELECTOR, ".product-item")
for product_element in product_elements:
# Extraire les détails des produits
name = product_element.find_element(By.CSS_SELECTOR, ".product-name").text
image = product_element.find_element(By.CSS_SELECTOR, « .product-image »).get_attribute(« src »)
price = product_element.find_element(By.CSS_SELECTOR, « .product-price »).text
url = product_element.find_element(By.CSS_SELECTOR, "a").get_attribute("href")
# Stocker les données extraites
products.append({
"name": name,
"image": image,
"price": price,
"url": url
})
# Logique d'exportation des données...
# Fermer le pilote du navigateur
driver.quit()
Pour gérer cette logique de navigation, le script :
- Enregistre le nombre initial de produits sur la page
- Clique sur le bouton « Charger plus »
- Attend que le nombre de produits augmente, confirmant que de nouveaux articles ont été ajoutés
Cette approche est à la fois intelligente et générique, car elle ne nécessite pas de connaître le nombre exact d’éléments à charger. Gardez toutefois à l’esprit qu’il existe d’autres méthodes permettant d’obtenir des résultats similaires.
Défilement infini
Le défilement infini est une interaction courante utilisée par de nombreux sites pour améliorer l’engagement des utilisateurs, en particulier sur les réseaux sociaux et les plateformes de commerce électronique. Dans ce cas, la cible sera la même page que ci-dessus, mais avecun défilement infini au lieu d’un bouton « Charger plus »:
La plupart des outils d’automatisation des navigateurs (y compris Selenium) ne fournissent pas de méthode directe pour faire défiler une page vers le bas ou vers le haut. Vous devez plutôt exécuter un script JavaScript sur la page pour effectuer l’opération de défilement.
L’idée est d’écrire un script JavaScript personnalisé qui fait défiler vers le bas :
- Un nombre spécifié de fois, ou
- Jusqu’à ce qu’il n’y ait plus de données à charger.
Remarque: chaque défilement charge de nouvelles données, augmentant ainsi le nombre d’éléments sur la page.
Vous pouvez ensuite extraire le contenu nouvellement chargé.
Voici comment gérer le défilement infini dans Selenium :
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
# Configurer les options Chrome pour le mode sans affichage
options = Options()
# options.add_argument("--headless")
# Créer une instance de pilote Web Chrome
driver = webdriver.Chrome(options=options)
# Se connecter à la page cible avec défilement infini
driver.get("https://www.scrapingcourse.com/infinite-scrolling")
# Hauteur actuelle de la page
scroll_height = driver.execute_script("return document.body.scrollHeight")
# Nombre de produits sur la page
product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# Nombre maximal de défilements
max_scrolls = 10
scroll_count = 1
# Limiter le nombre de défilements à 10
while scroll_count < max_scrolls:
# Faire défiler vers le bas
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Attendre que le nombre d'articles sur la page ait augmenté
WebDriverWait(driver, 10).until(lambda driver: len(driver.find_elements(By.CSS_SELECTOR, ".product-item")) > product_count)
# Mettre à jour le nombre de produits
product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# Obtenir la nouvelle hauteur de la page
new_scroll_height = driver.execute_script("return document.body.scrollHeight")
# Si aucun nouveau contenu n'a été chargé
if new_scroll_height == scroll_height:
break
# Mettre à jour la hauteur de défilement et incrémenter le nombre de défilements
scroll_height = new_scroll_height
scroll_count += 1
# Récupérer les détails du produit après un défilement infini
products = []
product_elements = driver.find_elements(By.CSS_SELECTOR, « .product-item »)
for product_element in product_elements:
# Extraire les détails du produit
name = product_element.find_element(By.CSS_SELECTOR, « .product-name »).text
image = product_element.find_element(By.CSS_SELECTOR, ".product-image").get_attribute("src")
price = product_element.find_element(By.CSS_SELECTOR, ".product-price").text
url = product_element.find_element(By.CSS_SELECTOR, "a").get_attribute("href")
# Stocker les données extraites
products.append({
"name": name,
"image": image,
"price": price,
"url": url
})
# Exporter vers CSV/JSON...
# Fermer le pilote du navigateur
driver.quit()
Ce script gère le défilement infini en déterminant d’abord la hauteur actuelle de la page et le nombre de produits. Ensuite, il limite les actions de défilement à un maximum de 10 itérations. À chaque itération, il :
- Fait défiler vers le bas
- Attend que le nombre de produits augmente (indiquant que du nouveau contenu a été chargé)
- Il compare la hauteur de la page pour détecter si du contenu supplémentaire est disponible
Si la hauteur de la page reste inchangée après un défilement, la boucle s’interrompt, indiquant qu’il n’y a plus de données à charger. C’est ainsi que vous pouvez gérer des modèles de défilement infini complexes.
Bravo ! Vous êtes désormais un expert en matière de scraping de sites web à navigation complexe.
Conclusion
Dans cet article, vous avez découvert les sites qui reposent sur des modèles de navigation complexes et comment utiliser Selenium avec Python pour les gérer. Cela démontre que le Scraping web peut être difficile, mais qu’il peut être rendu encore plus difficile pardes mesures anti-scraping.
Les entreprises comprennent la valeur de leurs données et les protègent à tout prix, c’est pourquoi de nombreux sites mettent en place des mesures pour bloquer les scripts automatisés. Ces solutions peuvent bloquer votre IP après un trop grand nombre de requêtes, présenter des CAPTCHA, voire pire.
Les outils traditionnels d’automatisation des navigateurs, tels que Selenium, ne peuvent pas contourner ces restrictions…
La solution consiste à utiliser un navigateur de scraping basé sur le cloud, tel queNavigateur de scraping. Il s’agit d’un navigateur qui s’intègre à Playwright, Puppeteer, Selenium et d’autres outils, et qui fait automatiquement tourner les adresses IP à chaque requête. Il peut gérer les empreintes digitales des navigateurs, les nouvelles tentatives,la Résolution de CAPTCHA, et bien plus encore. Oubliez les blocages lorsque vous traitez des sites complexes !




