

Dans ce guide, vous apprendrez :
- Ce qu’est Undetected ChromeDriver et en quoi il peut être utile
- Comment il minimise la détection des bots
- Comment l’utiliser avec Python pour le Scraping web
- Son utilisation avancée et ses méthodes
- Ses principales limites et inconvénients
- Technologies similaires
Plongeons-nous dans le vif du sujet !
Qu’est-ce que Undetected ChromeDriver ?
Undetected ChromeDriverest une bibliothèque Python qui fournit une version optimisée du ChromeDriver de Selenium. Elle a été modifiée afin de limiter la détection par les services anti-bot tels que :
- Imperva
- DataDome
- Distil Networks
Elle peut également aider à contourner certaines protections Cloudflare, bien que cela puisse s’avérer plus difficile. Pour plus de détails, suivez notre guide surla manière de contourner Cloudflare.
Si vous avez déjà utilisédes outils d’automatisation de navigateurtels que Selenium, vous savez qu’ils vous permettent de contrôler les navigateurs par programmation. Pour ce faire, ils configurent les navigateurs différemment des configurations utilisateur habituelles.
Les systèmes anti-bots recherchent ces différences, ou « fuites », afin d’identifier les bots de navigateur automatisés. ChromeDriver, qui passe inaperçu, modifie les pilotes Chrome afin de minimiser ces signes révélateurs, réduisant ainsi la détection des bots. Cela le rend idéal pour les sites de Scraping web protégés pardes mesures anti-scraping!
Comment ça marche
Undetected ChromeDriver réduit la détection par Cloudflare, Imperva, DataDome et d’autres solutions similaires en utilisant les techniques suivantes :
- Renommer les variables Selenium pour imiter celles utilisées par les navigateurs réels
- Utilisation de chaînes User-Agent légitimes et réelles pour éviter la détection
- Permettre à l’utilisateur de simuler une interaction humaine naturelle
- Gestion correcte des cookies et des sessions lors de la navigation sur les sites web
- Activation de l’utilisation de Proxies pour contourner le blocage des adresses IP et empêcher la limitation du débit
Ces méthodes aident le navigateur contrôlé par la bibliothèque à contourner efficacement diverses défenses anti-scraping.
Utilisation de ChromeDriver non détecté pour le Scraping web : guide étape par étape
La plupart des sites utilisent des mesures anti-bot avancées pour empêcher les scripts automatisés d’accéder à leurs pages. Ces mécanismes bloquent également efficacementles robots de Scraping web.
Par exemple, supposons que vous souhaitiez extraire le titre et la description de lapage produit GoDaddy suivante :
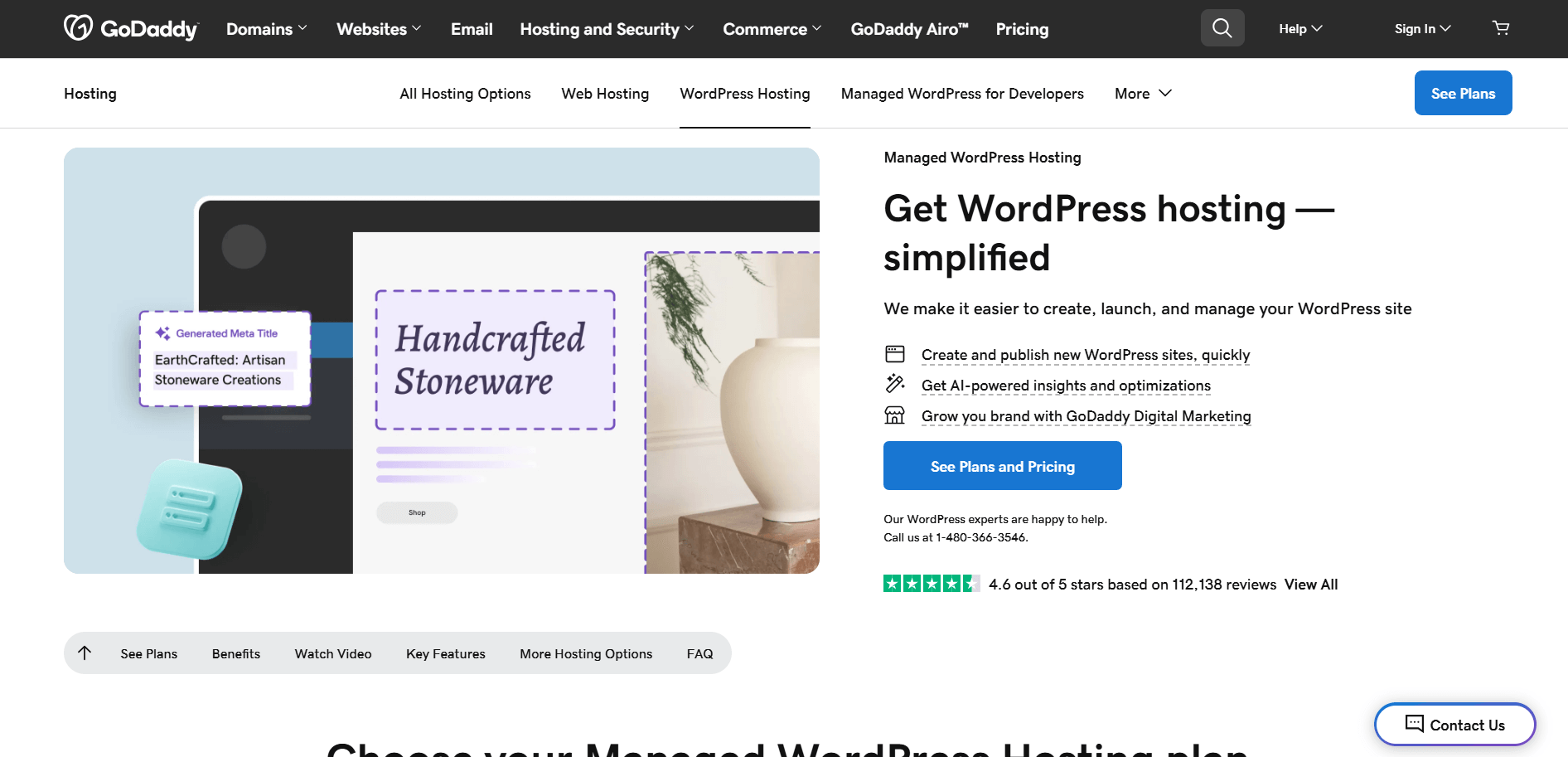
Avec Selenium en Python, votre script de scraping ressemblera à ceci :
# pip install selenium
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# configure une instance Chrome pour démarrer en mode headless
options = Options()
options.add_argument("--headless")
# créer une instance de pilote web Chrome
driver = webdriver.Chrome(service=Service(), options=options)
# se connecter à la page cible
driver.get("https://www.godaddy.com/hosting/wordpress-hosting")
# logique de scraping...
# fermer le navigateur
driver.quit()
Si vous n’êtes pas familier avec cette logique, consultez notre guide surle Scraping web Selenium.
Lorsque vous exécutez le script, il échoue en raison de cette page d’erreur :

En d’autres termes, le script Selenium a été bloqué par une solution anti-bot (Akamai, dans cet exemple).
Alors, comment contourner cela ? La réponse est Undetected ChromeDriver !
Suivez les étapes ci-dessous pour apprendre à utiliser la bibliothèque Python undetected_chromedriver pour le Scraping web.
Étape n° 1 : prérequis et configuration du projet
Undetected ChromeDriver nécessite les prérequis suivants :
- Dernière version de Chrome
- Python 3.6+: si Python 3.6 ou une version ultérieure n’est pas installé sur votre ordinateur,téléchargez-le depuis le site officielet suivez les instructions d’installation.
Remarque: la bibliothèque télécharge et corrige automatiquement le fichier binaire du pilote pour vous, il n’est donc pas nécessaire de télécharger manuellementChromeDriver.
À présent, utilisez la commande suivante pour créer un répertoire pour votre projet :
mkdir undetected-chromedriver-Scraper
Le répertoire undetected-chromedriver-scraper servira de dossier de projet pour votre Scraper Python.
Accédez-y et initialisez unenvironnement virtuel:
cd undetected-chromedriver-Scraper
python -m venv env
Ouvrez le dossier du projet dans votre IDE Python préféré.Visual Studio Code avec l’extension PythonouPyCharm Community Editionsont deux excellents choix.
Ensuite, créez un fichierscraper.pydans le dossier du projet, en suivant la structure indiquée ci-dessous :
Actuellement,scraper.pyest un script Python vide. Vous y ajouterez bientôt la logique de scraping.
Dans le terminal de votre IDE, activez l’environnement virtuel. Sous Linux ou macOS, utilisez :
./env/bin/activate
De manière équivalente, sous Windows, exécutez :
env/Scripts/activate
Génial ! Vous disposez désormais d’un environnement Python prêt pour le Scraping web via l’automatisation du navigateur.
Étape n° 2 : installer Undetected ChromeDriver
Dans un environnement virtuel activé, installez Undetected ChromeDriver via le paquet pipundetected_chromedriver:
pip install undetected_chromedriver
En arrière-plan, cette bibliothèque installera automatiquement Selenium, car il s’agit de l’une de ses dépendances. Vous n’avez donc pas besoin d’installer Selenium séparément. Cela signifie également que vous aurez accès à toutes les importations Selenium par défaut.
Étape n° 3 : configuration initiale
Importez undetected_chromedriver:
import undetected_chromedriver as uc
Vous pouvez ensuite initialiser un Chrome WebDriver avec :
driver = uc.Chrome()
Tout comme Selenium, cela ouvrira une fenêtre de navigateur que vous pourrez contrôler à l’aide de l’API Selenium. Cela signifie que l’objet driver expose toutes les méthodes Selenium standard, ainsi que certaines fonctionnalités supplémentaires que nous explorerons plus tard.
La principale différence est que cette version du pilote Chrome est corrigée pour aider à contourner certaines solutions anti-bot.
Pour fermer le pilote, il suffit d’appeler la méthode quit():
driver.quit()
Voici à quoi ressemble une configuration de base de ChromeDriver non détecté :
import undetected_chromedriver as uc
# Initialiser une instance Chrome
driver = uc.Chrome()
# Logique de scraping...
# Fermer le navigateur et libérer ses ressources
driver.quit()
Fantastique ! Vous êtes maintenant prêt à effectuer le Scraping web directement dans le navigateur.
Étape n° 4 : Utilisez-le pour le Scraping web
Avertissement: cette section suit les mêmes étapes qu’une configuration Selenium standard. Si vous êtes déjà familiarisé avec le Scraping web Selenium, n’hésitez pas à passer à la section suivante avec le code final.
Commencez par utiliser la méthode get() pour naviguer dans le navigateur jusqu’à la page cible :
driver.get("https://www.godaddy.com/hosting/wordpress-hosting")
Ensuite, visitez la page en mode incognito dans votre navigateur et inspectez l’élément que vous souhaitez extraire :
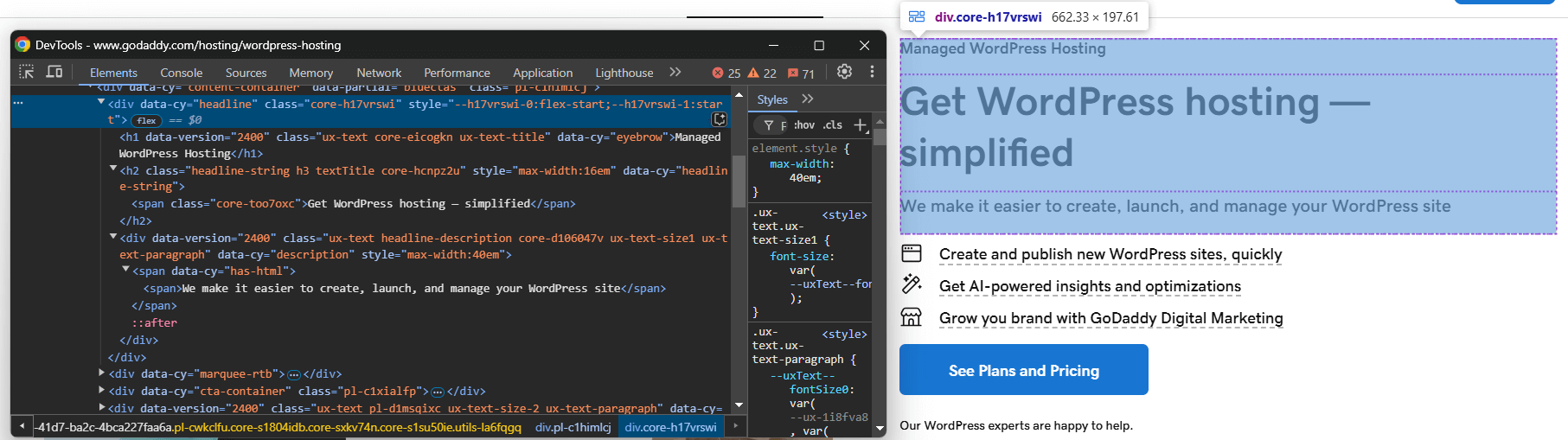
Supposons que vous souhaitiez extraire le titre, le slogan et la description du produit.
Vous pouvez extraire tous ces éléments à l’aide du code suivant :
headline_element = driver.find_element(By.CSS_SELECTOR, "[data-cy="headline"]")
title_element = headline_element.find_element(By.CSS_SELECTOR, "h1")
title = title_element.text
tagline_element = headline_element.find_element(By.CSS_SELECTOR, "h2")
tagline = tagline_element.text
description_element = headline_element.find_element(By.CSS_SELECTOR, "[data-cy="description"]")
description = description_element.text
Pour que le code ci-dessus fonctionne, vous devez importer By depuis Selenium :
from selenium.webdriver.common.by import By
Enregistrez maintenant les données extraites dans un dictionnaire Python :
product = {
"title": title,
"tagline": tagline,
"description": description
}
Enfin, exportez les données vers un fichier JSON :
with open("product.json", "w") as json_file:
json.dump(product, json_file, indent=4)
N’oubliez pas d’importer json depuis la bibliothèque standard Python :
import json
Et voilà ! Vous venez d’implémenter la logique de base du Scraping web Undetected ChromeDriver.
Étape n° 5 : assembler le tout
Voici le script de scraping final :
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import json
# Créer une instance de Chrome Web Driver
driver = uc.Chrome()
# Se connecter à la page cible
driver.get("https://www.godaddy.com/hosting/wordpress-hosting")
# Logique de scraping
headline_element = driver.find_element(By.CSS_SELECTOR, "[data-cy="headline"]")
title_element = headline_element.find_element(By.CSS_SELECTOR, "h1")
title = title_element.text
tagline_element = headline_element.find_element(By.CSS_SELECTOR, "h2")
tagline = tagline_element.text
description_element = headline_element.find_element(By.CSS_SELECTOR, "[data-cy="description"]")
description = description_element.text
# Remplir un dictionnaire avec les données extraites
produit = {
"title": titre,
"tagline": slogan,
"description": description
}
# Exporter les données extraites au format JSON
avec open("produit.json", "w") comme json_file :
json.dump(produit, json_file, indent=4)
# Fermer le navigateur et libérer ses ressources
driver.quit()
Exécutez-le avec :
python3 Scraper.py
Ou, sous Windows :
python Scraper.py
Cela ouvrira un navigateur affichant la page Web cible, et non la page d’erreur comme avec Selenium vanilla :
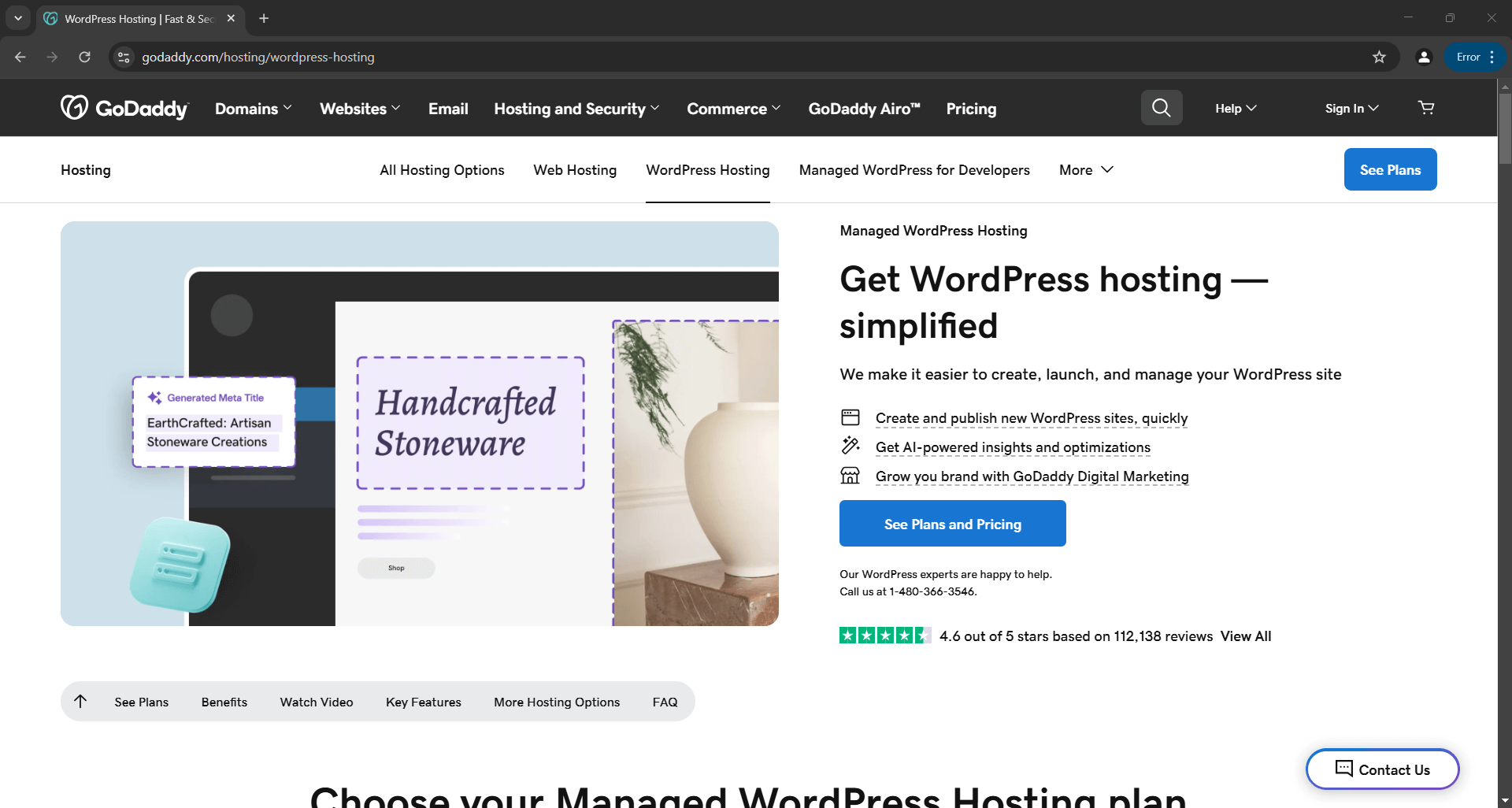
Le script extraira les données de la page et produira le fichier product.json suivant :
{
"title": "Hébergement WordPress géré",
"tagline": "Obtenez un hébergement WordPress simplifié",
"description": "Nous facilitons la création, le lancement et la gestion de votre site WordPress"
}
undetected_chromedriver: utilisation avancée
Maintenant que vous savez comment fonctionne la bibliothèque, vous êtes prêt à explorer des scénarios plus avancés.
Choisissez une version spécifique de Chrome
Vous pouvez spécifier une version particulière de Chrome à utiliser par la bibliothèque en définissant l’argument version_main:
import undetected_chromedriver as uc
# Spécifiez la version cible de Chrome
driver = uc.Chrome(version_main=105)
Notez que la bibliothèque fonctionne également avec d’autres navigateurs basés sur Chromium, mais cela nécessite quelques ajustements supplémentaires.
avec Sytnax
Pour éviter d’appeler manuellement la méthodequit()lorsque vous n’avez plus besoin du pilote, vous pouvez utiliser la syntaxewithcomme indiqué ci-dessous :
import undetected_chromedriver as uc
with uc.Chrome() as driver:
driver.get("<VOTRE_URL>")
Lorsque le code à l’intérieur du bloc with est terminé, Python ferme automatiquement le navigateur pour vous.
Remarque: cette syntaxe est prise en charge à partir de la version 3.1.0.
Intégration d’un Proxy
La syntaxe pour ajouter un Proxy à Undetected ChromeDriver est similaire à celle de Selenium. Il suffit de passer votre URL Proxy au drapeau --proxy-server comme indiqué ci-dessous :
import undetected_chromedriver as uc
proxy_url = "<VOTRE_URL_PROXY>"
options = uc.ChromeOptions()
options.add_argument(f"--proxy-server={proxy}")
Remarque: Chrome ne prend pas en charge les Proxys authentifiés via le drapeau --proxy-server.
API étendue
undetected_chromedriver étend les fonctionnalités standard de Selenium avec certaines méthodes, notamment :
WebElement.click_safe(): utilisez cette méthode si le fait de cliquer sur un lien entraîne une détection. Bien que son fonctionnement ne soit pas garanti, elle offre une approche alternative pour des clics plus sûrs.WebElement.children(tag=None, recursive=False): cette méthode vous aide à trouver facilement les éléments enfants. Par exemple :
# Obtenir le 6e enfant (de n'importe quelle balise) dans le corps, puis trouver tous les éléments <img> de manière récursive.
images = body.children()[6].children("img", True)
Limitations de la bibliothèque Python undetected_chromedriver
Bien que undetected_chromedriver soit une bibliothèque Python puissante, elle présente certaines limites connues. Voici les plus importantes que vous devez connaître !
Blocages IP
La page GitHub de la bibliothèque l’indique clairement :le package ne masque pas votre adresse IP. Ainsi, si vous exécutez un script à partir d’un centre de données, il y a de fortes chances que la détection ait toujours lieu. De même, si votre adresse IP personnelle a une mauvaise réputation, vous risquez également d’être bloqué !

Pour masquer votre adresse IP, vous devez intégrer le navigateur contrôlé à un Proxy, comme démontré précédemment.
Pas de prise en charge de la navigation GUI
En raison du fonctionnement interne du module, vous devez naviguer par programmation à l’aide de la méthode get(). Évitez d’utiliser l’interface graphique du navigateur pour la navigation manuelle : interagir avec la page à l’aide de votre clavier ou de votre souris augmente le risque de détection !
La même règle s’applique à la gestion des nouveaux onglets. Si vous devez travailler avec plusieurs onglets, ouvrez un nouvel onglet avec une page vierge en utilisant l’URL data: ( oui, y compris la virgule) , que le pilote accepte. Ensuite, poursuivez avec votre logique d’automatisation habituelle.
Ce n’est qu’en respectant ces consignes que vous pourrez minimiser le risque de détection et profiter de sessions de Scraping web plus fluides.
Prise en charge limitée du mode sans affichage
Officiellement, le mode sans affichage n’est pas entièrement pris en charge par la bibliothèque undetected_chromedriver. Cependant, vous pouvez l’essayer en utilisant la syntaxe suivante :
driver = uc.Chrome(headless=True)
L’auteur a annoncé dans le journal des modifications de la version 3.4.5 que le mode headless devrait fonctionner et garantir la capacité de contournement des bots. Cependant, il reste instable. Utilisez cette fonctionnalité avec prudence et effectuez des tests approfondis pour vous assurer qu’elle répond à vos besoins en matière de scraping.
Problèmes de stabilité
Comme mentionné sur la page PyPI du package, les résultats peuvent varier en fonction de nombreux facteurs. Aucune garantie n’est fournie, si ce n’est des efforts continus pour comprendre et contrer les algorithmes de détection.
Cela signifie qu’un script qui contourne aujourd’hui avec succès Distil, Cloudflare, Imperva, DataDome ou hCaptcha pourrait échouer demain si les solutions anti-bot sont mises à jour :
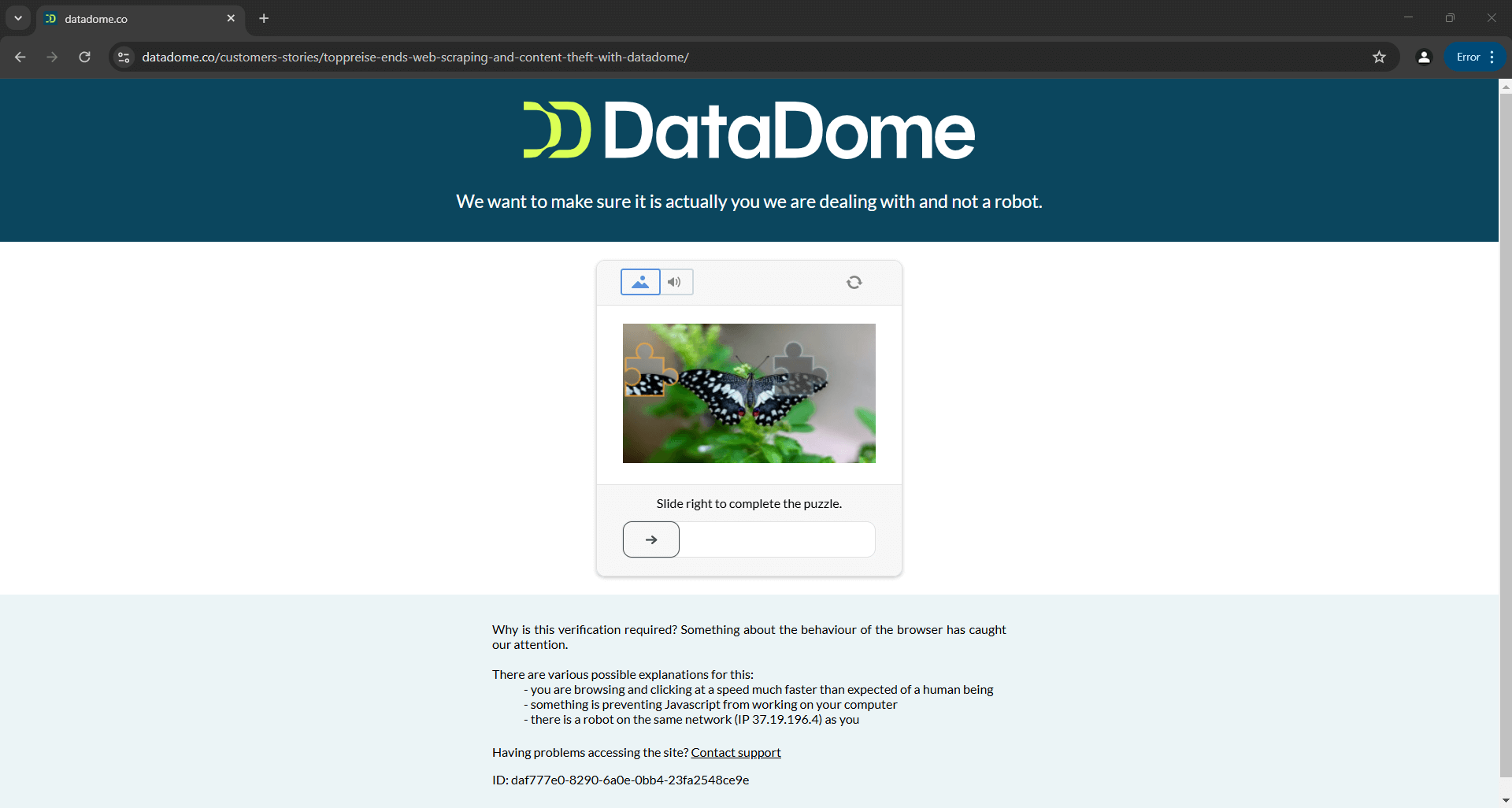
L’image ci-dessus est le résultat d’un script fourni dans la documentation officielle. Cela démontre que même les scripts créés par les développeurs de l’outil peuvent ne pas toujours fonctionner comme prévu. Plus précisément, le script a déclenché un CAPTCHA, qui peut facilement bloquer votre logique d’automatisation.
Pour en savoir plus, consultez notre guide surla manière de contourner les CAPTCHA en Python.
Lectures complémentaires
Undetected ChromeDriver n’est pas la seule bibliothèque qui modifie les pilotes de navigateur pour empêcher leur détection. Si vous souhaitez découvrir des outils similaires ou en savoir plus sur ce sujet, consultez ces guides :
- Évitez d’être bloqué avec Puppeteer Stealth
- Évitez la détection des bots avec Playwright Stealth
- Guide du Scraping web avec SeleniumBase
Conclusion
Dans cet article, vous avez compris comment gérer la détection des bots dans Selenium à l’aide d’Undetected ChromeDriver. Cette bibliothèque fournit une version corrigée de ChromeDriver pour le Scraping web sans être bloqué.
Le problème est que les technologies anti-bot avancées telles que Cloudflare seront toujours en mesure de détecter et de bloquer vos scripts. Les bibliothèques telles que undetected_chromedriver sont instables : elles peuvent fonctionner aujourd’hui, mais ne fonctionneront peut-être plus demain.
Le problème ne réside pas dans l’API de Selenium pour contrôler un navigateur, mais dans les paramètres du navigateur lui-même. Cela implique que la solution est un navigateur basé sur le cloud, toujours mis à jour, évolutif et doté d’une fonctionnalité intégrée de contournement anti-bot. Ce navigateur existe, et il s’appelleNavigateur de scraping!
Le Navigateur de scraping de Bright Data est un navigateur cloud hautement évolutif qui fonctionne avecSelenium,Puppeteer,Playwright et bien d’autres. Il peut gérer pour vous l’empreinte digitale du navigateur, la résolution CAPTCHA et les nouvelles tentatives automatisées. De plus, il fait automatiquement tourner l’IP de sortie à chaque requête. Cela est possible grâce au réseau mondial de Proxy qui comprend :
- Proxy de centre de données– Plus de 770 000 adresses IP de centres de données.
- Proxys résidentiels– Plus de 72 millions d’IPs résidentielles dans plus de 195 pays.
- Proxy ISP– Plus de 700 000 adresses IP FAI.
- Proxy mobile– Plus de 7 millions d’adresses IP mobiles.
Créez dès aujourd’hui un compte Bright Data gratuit pour essayer notre Navigateur de scraping ou tester nos Proxy.




