
Le web contient de vastes quantités de données qui peuvent s’avérer précieuses pour la recherche et les décisions commerciales. Voilà pourquoi il est important de savoir utiliser des outils comme Playwright.
Playwright est une puissante bibliothèque Node.js développée par Microsoft qui permet de récupérer des données sur les sites web. Dans cet article, nous allons vous montrer des exemples pratiques et détaillés de l’utilisation de Playwright pour extraire des données de la page d’accueil de Bright Data. Vous pourrez ensuite appliquer ces exemples à tout autre site web que vous souhaitez scraper à l’aide de Playwright.
Pourquoi utiliser Playwright ?
Le scraping de données sur le web n’est pas un concept nouveau. Dans l’écosystème JavaScript, des outils tels que Cheerio, Selenium, Puppeteer, et Playwright ont tous pour but de simplifier le web scraping.
Playwright, une toute nouvelle bibliothèque de web scraping, est particulièrement intéressante en raison des caractéristiques suivantes :
Des localisateurs puissants
Playwright utilise des localisateurs, dotés d’une logique intégrée d’attente automatique et de nouvelle tentative, pour sélectionner des éléments sur une page web. La logique d’attente automatique simplifie votre code de web scraping, car vous n’avez pas à attendre le chargement manuel d’une page web.
La logique de nouvelle tentative fait également de Playwright une bibliothèque adaptée au scraping d’applications modernes à page unique (SPA) qui chargent des données de manière dynamique après le chargement de la page initiale.
Méthodes de localisation multiples
Lorsque vous utilisez des localisateurs, Playwright vous permet de spécifier les éléments à localiser sur la page web à l’aide de plusieurs syntaxes différentes, notamment la syntaxe du sélecteur CSS, la syntaxe XPath et le contenu textuel de l’élément cible. Vous pouvez également appliquer des filtres aux localisateurs pour les affiner davantage.
Web scraping avec Playwright
Dans cette section, vous allez créer un projet Node.js, installer Playwright et apprendre à localiser, interagir avec et extraire des données d’une page web à l’aide de Playwright.
Prérequis
Les extraits de code de cet article fonctionnent avec la dernière version de support à long terme (LTS) de Node.js qui, au moment de la rédaction de cet article, est la version 18.15.0. Vérifiez que Node.js est bien installé sur votre ordinateur avant de commencer.
Nous vous recommandons également d’utiliser un éditeur de code capable de mettre en évidence la syntaxe JavaScript et d’utiliser la fonction d’autocomplétion, tel que Visual Studio Code.
Création d’un nouveau projet
Ouvrez une nouvelle fenêtre de terminal et créez un nouveau dossier pour votre projet Node.js et ouvrez-le à l’aide de la commande suivante :
mkdir playwright-demo
cd playwright-demo
Ensuite, créez votre projet Node.js en exécutant la commande npm suivante :
npm init -y
Installation de Playwright
Une fois que vous avez créé un projet Node.js, installez la bibliothèque Playwright à l’aide de la commande suivante dans votre fenêtre de terminal :
npm install playwright
L’installation de la bibliothèque peut prendre un certain temps, car Playwright télécharge les navigateurs nécessaires dans le cadre de son installation.
Ouverture de la page d’accueil de Bright Data
Une fois la bibliothèque Playwright installée, créez un nouveau fichier dans votre dossier de projet et nommez-le index.js. Copiez le code suivant dans ce fichier :
// Import the Playwright library to use it
const playwright = require("playwright");
(async () => {
// Launch a new instance of a Chromium browser
const browser = await playwright.chromium.launch({
// Set headless to false so you can see how Playwright is
// interacting with the browser
headless: false,
});
// Create a new Playwright context
const context = await browser.newContext();
// Create a new page/tab in the context.
const page = await context.newPage();
// Navigate to the Bright Data home page.
await page.goto("https://brightdata.com/");
// Wait 10 seconds (or 10,000 milliseconds)
await page.waitForTimeout(10000);
// Close the browser
await browser.close();
})();
Exécutez l’extrait à l’aide de la commande suivante dans votre terminal :
node index.js
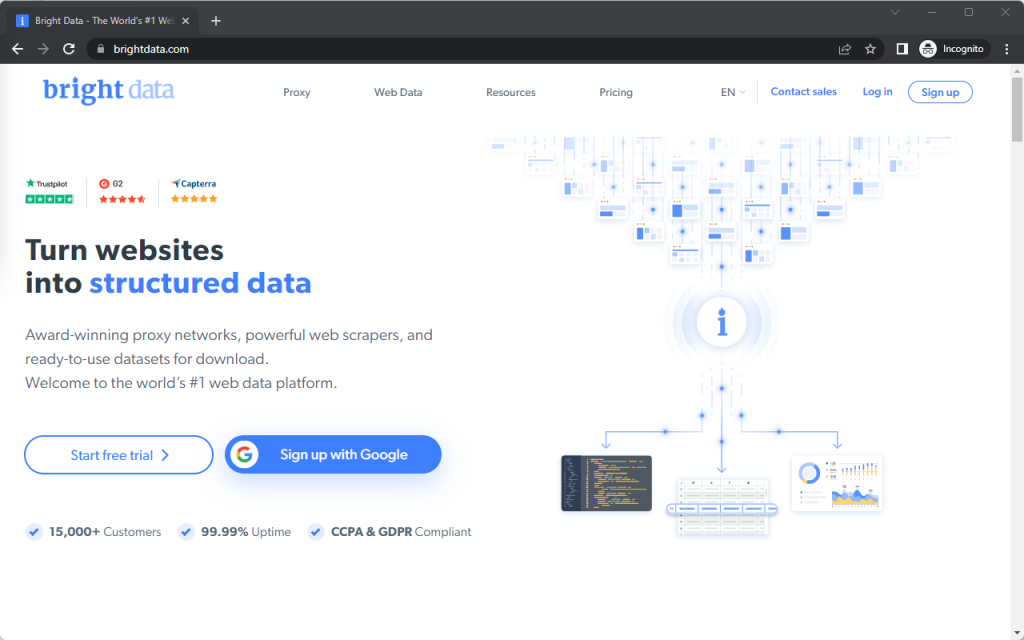
Un navigateur Chromium devrait s’ouvrir et charger la page d’accueil de Bright Data :
Localisation des éléments
Maintenant que vous avez accédé à la page d’accueil de Bright Data à l’aide de Playwright, vous pouvez utiliser des localisateurs pour sélectionner des éléments spécifiques sur la page web. Playwright dispose de plusieurs localisateurs et les sections suivantes démontrent le fonctionnement de chacun d’entre eux.
Localisation d’éléments à l’aide de sélecteurs CSS
Playwright vous permet de localiser des éléments sur une page web à l’aide de sélecteurs CSS, une syntaxe à la fois concise et puissante utilisée en CSS pour appliquer des styles à des éléments HTML particuliers sur la page web.
Par exemple, le logo de Bright Data est un élément <svg> dans l’en-tête de la page, doté de la classe page_header_logo_svg :

Grâce à ces informations, vous pouvez localiser l’élément SVG à l’aide d’un sélecteur CSS :
const logoSvg = page.locator(".page_header_logo_svg");
Le localisateur est stocké dans la variable LogoSVG et peut être utilisé ultérieurement pour interagir avec l’élément ou en extraire des informations.
Localisation d’éléments à l’aide de requêtes XPath
XPath est une autre syntaxe de sélecteur que vous pouvez utiliser pour localiser des éléments dans un document XML. Le HTML étant une forme de XML, vous pouvez utiliser cette syntaxe pour trouver des éléments HTML sur une page web.
Par exemple, vous pouvez sélectionner le même logo SVG que dans la section précédente avec la requête XPath suivante :
const logoSvg = page.locator("//*[@class='page_header_logo_svg']");
La requête recherche tous les éléments auxquels la classe page_header_logo_svg est associée et enregistre leur emplacement dans la variable logoSvg.
Localisation des éléments en fonction de leur rôle
Les éléments HTML peuvent être associés à différents rôles. Ces rôles confèrent une signification sémantique à une page web, ce qui facilite la prise en charge de la page par les lecteurs d’écran et d’autres outils. Pour en savoir plus sur les rôles, cliquez ici.
L’extrait de code suivant vous montre comment trouver le bouton Inscription en utilisant le rôle et le nom qui lui sont associés :
const signupButton = page.getByRole("button", {
name: "Start free trial",
});
Cet extrait de code permet de localiser le bouton Démarrer l’essai gratuit sur la page d’accueil :
const signupButton = page.getByRole("button", {
name: "Start free trial",
});Cet extrait de code permet de localiser le bouton Démarrer l’essai gratuit sur la page d’accueil :
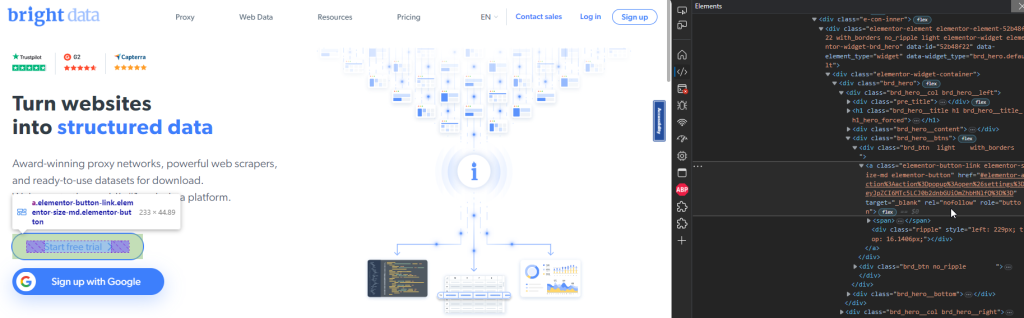
Localisation d’éléments par le texte
Si un élément HTML n’a pas d’attribut d’identification significatif, tel qu’un attribut id ou class, vous pouvez sélectionner l’élément par le texte qui lui est associé à l’aide de la méthode getByText.
Par exemple, la page d’accueil de Bright Data possède un titre dans la section héros avec les mots « données structurées » en bleu :
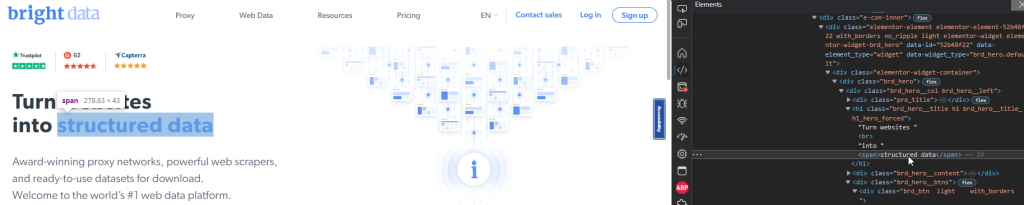
Vous pouvez sélectionner l’élément <span> contenant ces mots à l’aide de l’extrait Playwright suivant :
const structuredData = page.getByText("structured data");
Localisation d’éléments par « label »
Dans un formulaire HTML, les éléments de saisie ont souvent un « label ». Playwright peut utiliser ces labels pour identifier l’élément d’entrée associé à ce label à l’aide de la méthode getByLabel.
Par exemple, la page Identification de Bright Data comporte un élément de saisie dont le label contient les mots « e-mail travail » :
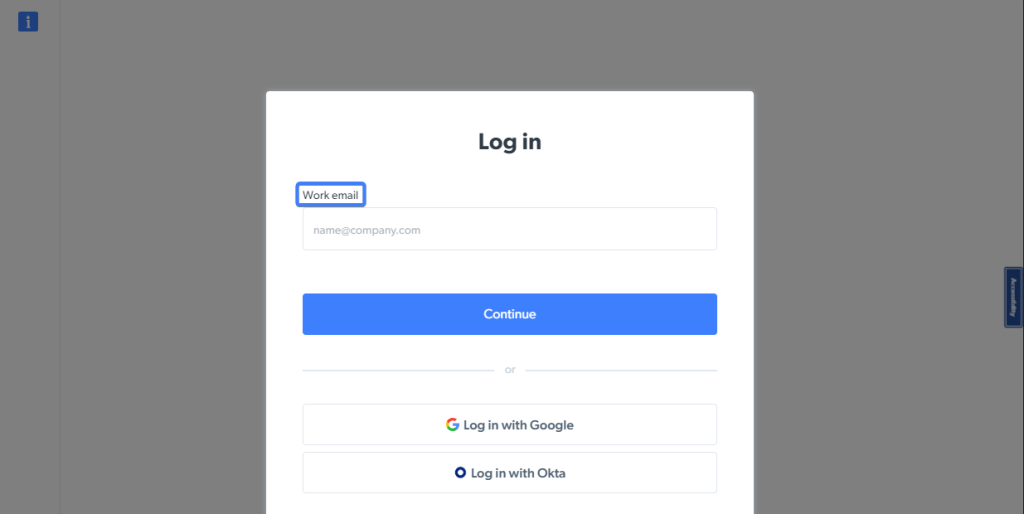
Vous pouvez localiser l’élément de saisie sur la page et le stocker dans une variable pour l’utiliser ultérieurement à l’aide de l’extrait de code suivant :
// Navigate to the Bright Data login page.
await page.goto("https://brightdata.com/cp/start");
// Locate the <input> using the label
const emailInput = page.getByLabel("Work email");
Localisation d’éléments à l’aide d’un espace réservé (PlaceHolder)
Vous pouvez également localiser un élément de saisie en fonction de la valeur de l’espace réservé affichée à l’aide de la méthode getByPlaceholder.
Vous remarquerez que le champ « e-mail » de la page Identification sur Bright Data contient un texte de remplacement pour donner à l’utilisateur le contexte des informations à saisir.
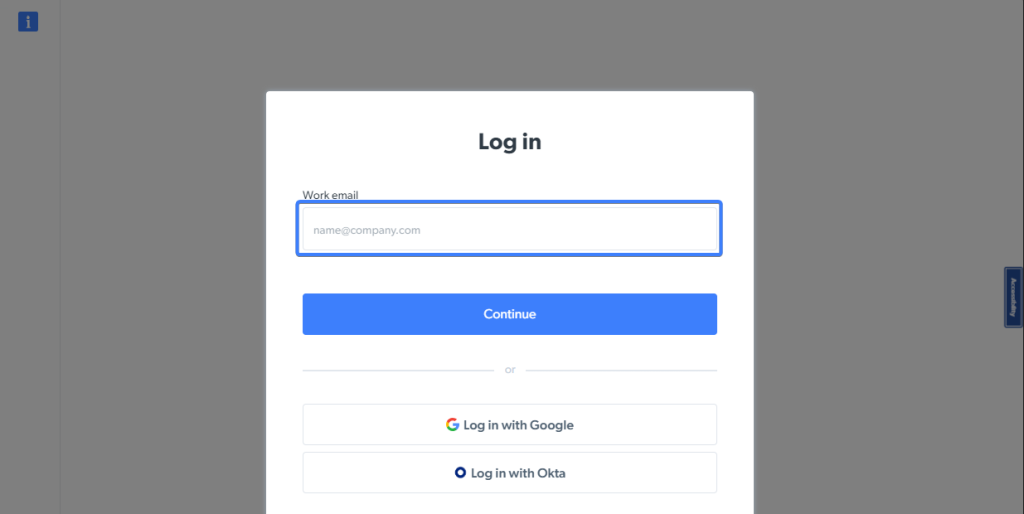
L’extrait suivant localisera cet élément en fonction de la valeur de l’espace réservé affichée par l’entrée :
// Navigate to the Bright Data login page.
await page.goto("https://brightdata.com/cp/start");
// Locate the <input> using the placeholder
const emailInput = page.getByPlaceholder("[email protected]");
Localisation d’éléments à l’aide du texte Alt
HTML vous permet d’ajouter une description textuelle aux images à l’aide de l’attribut alt, qui s’affiche si l’image ne se charge pas et qui est lu à haute voix par les lecteurs d’écran pour décrire l’image. La méthode getByAltText de Playwright vous permet de localiser un élément img à l’aide de son attribut alt.
Par exemple, Bright Data répertorie les entreprises qui utilisent ses données. Vous pouvez récupérer l’image utilisée pour le secteur de la santé en utilisant sa valeur alt, « cas utilisation santé » :
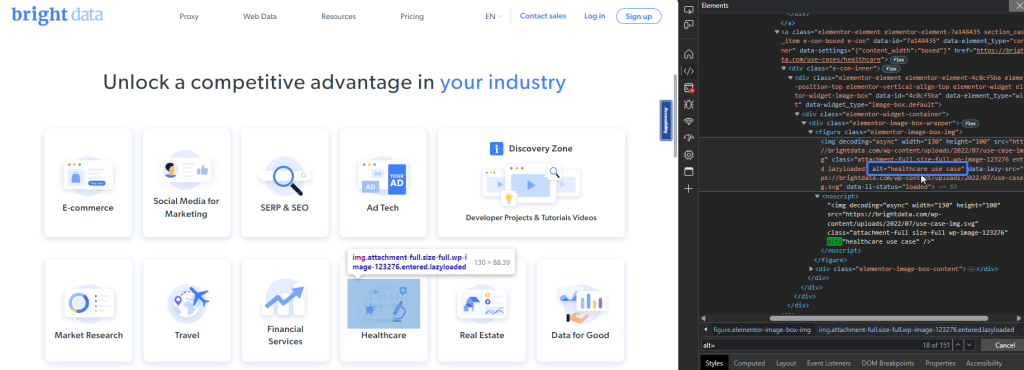
L’extrait de code suivant permet de localiser l’élément image :
const healthcareImage = page.getByAltText("healthcare use case");
Localisation des éléments par titre
Le dernier sélecteur Playwright que vous pouvez utiliser pour le scraping est la méthode getByTitle, qui localise un élément HTML par son attribut « title ». Vous verrez la valeur du titre lorsque vous survolerez le composant HTML avec le pointeur de votre souris.
Par exemple, le site web du service d’assistance de Bright Data contient un lien de connexion avec un attribut title :

Vous pouvez utiliser l’extrait Playwright suivant pour localiser le lien à l’aide de son attribut title :
// Navigate to the Bright Data helpdesk webpage.
await page.goto("https://help.brightdata.com/hc/en-us");
// Locate the Sign in link using its title attribute
const signInLink = page.getByTitle("Opens a dialog");
Maintenant que vous avez vu plusieurs méthodes permettant de localiser des éléments sur une page web à l’aide de Playwright, apprenons à interagir avec ces éléments et à en extraire des données.
Interaction avec les éléments
Après avoir localisé un élément sur une page web, vous pouvez interagir avec lui. Par exemple, il se peut que vous deviez vous connecter à un site web avant de récupérer des pages protégées.
Cet extrait de code présente les différentes méthodes de Playwright permettant d’interagir avec les éléments d’une page web. Vous trouverez une explication de chaque fonction dans le code suivant :
// Import the Playwright library to use it
const playwright = require("playwright");
(async () => {
// Launch a new instance of a Chromium browser
const browser = await playwright.chromium.launch({
// Set headless to false so you can see how Playwright is
// interacting with the browser
headless: false,
});
// Create a new Playwright context
const context = await browser.newContext();
// Create a new page/tab in the context.
const page = await context.newPage();
// Navigate to the Bright Data login page.
await page.goto("https://brightdata.com/");
// Locate and click on the signup button
await page
.locator("#hero_new")
.getByRole("button", {
name: "Start free trial",
})
.click();
// Locate the first name field and FILL in a first name
await page.locator(".hs_firstname input").fill("John");
// Locate the last name field and FILL in a last name
await page.locator(".hs_lastname input").fill("Smith");
// Locate the email field and TYPE in an email address
await page.locator(".hs_email input").type("[email protected]");
// Locate the company size field and SELECT an option
await page.locator(".hs_numemployees select").selectOption("1-9 employees");
// Locate the terms and conditions checkbox and CHECK it.
await page.locator(".legal-consent-container input").check();
// Wait 10 seconds so you can see the result.
await page.waitForTimeout(10000);
// Close the browser
await browser.close();
})();
Collez cet extrait dans votre fichier index.js et réexécutez-le à l’aide de la commande suivante :
node index.js
La page d’accueil de Bright Data apparaîtra brièvement avant d’afficher une boîte de dialogue vous demandant de vous inscrire. Vous verrez ensuite comment Playwright remplit le formulaire d’Inscription à l’aide des différentes méthodes de cet extrait :
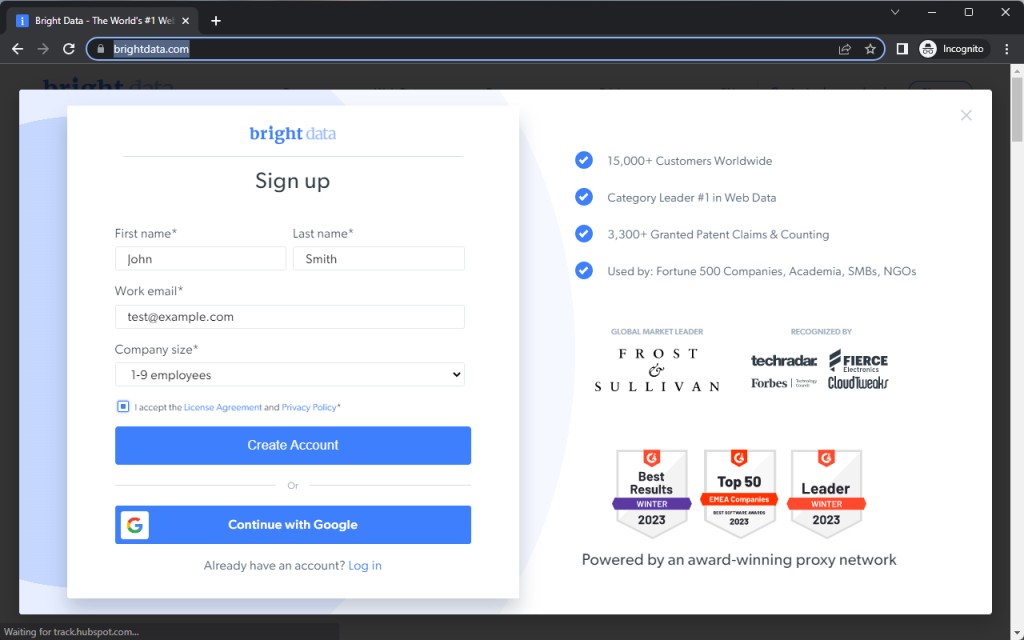
Cliquer sur des éléments
Dans l’extrait précédent, Playwright a d’abord cliqué sur le bouton Inscription pour faire apparaître la boîte de dialogue :
// Locate and click on the signup button
await page
.getByRole("button", {
name: "Start free trial",
})
.click();
Playwright dispose de deux méthodes pour cliquer sur des éléments :
- La méthode «
click» simule un simple clic sur un élément. - La méthode «
» simule un double-clic sur un élément.
Dans cet exemple, vous ne deviez cliquer qu’une seule fois sur le bouton Inscription, c’est pourquoi l’extrait utilise la méthode « click ».
Remplissage des champs de texte
Dans cet exemple, l’extrait utilise deux méthodes pour remplir les champs de texte du formulaire d’Inscription :
// Locate the first name field and FILL in a first name
await page.locator(".hs_firstname input").fill("John");
// Locate the last name field and FILL in a last name
await page.locator(".hs_lastname input").fill("Smith");
// Locate the email field and TYPE in an email address
await page.locator(".hs_email input").type("[email protected]");
L’extrait utilise les méthodes « fill » et « type » pour différents champs. Ces fonctions remplissent toutes deux un champ de texte, mais elles le font de manière légèrement différente :
filltype
Vous utiliserez probablement la méthode « fill » dans la plupart des cas, mais si nécessaire, vous pouvez utiliser la méthode « type » pour simuler la saisie manuelle de la valeur.
Sélection d’une option de liste déroulante
Le formulaire d’Inscription comporte un champ déroulant pour sélectionner la taille de l’entreprise, que Playwright a rempli avec « 1 à 9 employés » :
// Locate the company size field and SELECT an option
await page.locator(".hs_numemployees select").selectOption("1-9 employees");
Playwright vous permet d’utiliser la méthode « selectOption » pour remplir les champs déroulants d’un formulaire. Cette fonction vous permet de sélectionner un élément de liste déroulante en fonction de la valeur ou du label et de choisir plusieurs options dans une sélection multiple.
Cocher des boutons radio et des cases à cocher
Avant de soumettre le formulaire, vous devez accepter les conditions d’utilisation. L’extrait suivant coche la case à cocher correspondante :
// Locate the terms and conditions checkbox and CHECK it.
await page.locator(".legal-consent-container input").check();
Pour modifier une case à cocher, vous pouvez utiliser les méthodes « check » et « uncheck » :
- La méthode «
check» permet de s’assurer que la case est cochée. - La méthode «
uncheck» permet de décocher la case.
Maintenant que vous avez vu comment Playwright vous permet d’interagir avec les éléments HTML d’une page, la section suivante vous montrera comment extraire des données de la page.
Extraction de données à partir d’éléments
L’extraction de données est essentielle pour le web scraping. Playwright vous permet d’utiliser plusieurs méthodes pour extraire différents types de données des éléments que vous avez localisés. Les sections suivantes présentent certaines de ces méthodes.
Extraction du texte intérieur
La méthode innerText vous permet d’extraire le texte à l’intérieur d’un élément. Par exemple, la page d’accueil de Bright Data comporte un élément héros en haut :
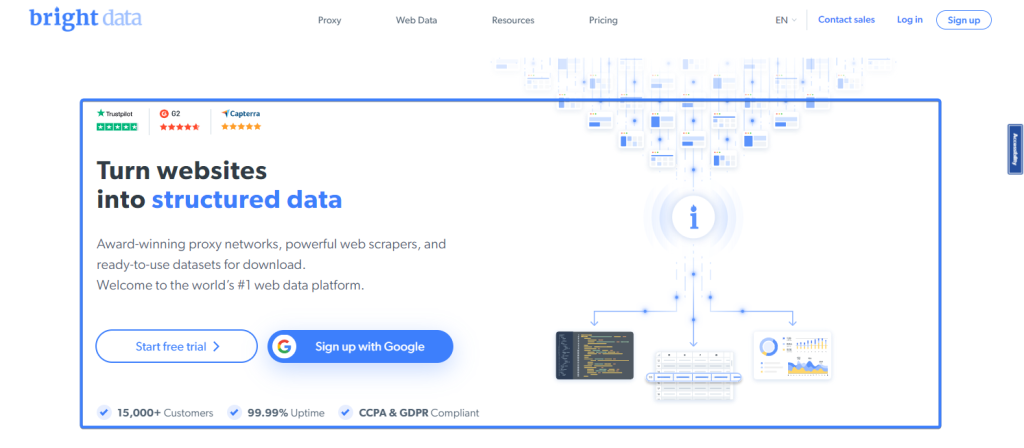
Vous pouvez extraire le titre du héros de la page d’accueil de Bright Data à l’aide de l’extrait suivant :
const headerText = await page.locator(".brd_hero__title.h1").innerText();
// headerText = "Turn websitesninto structured data"
Si votre localisateur pointe vers plusieurs éléments, vous pouvez récupérer le texte de tous les éléments sous la forme d’une suite de tableaux à l’aide de la méthode allInnerTexts. Par exemple, la page d’accueil de Bright Data contient une liste de cas d’utilisation de ses données :
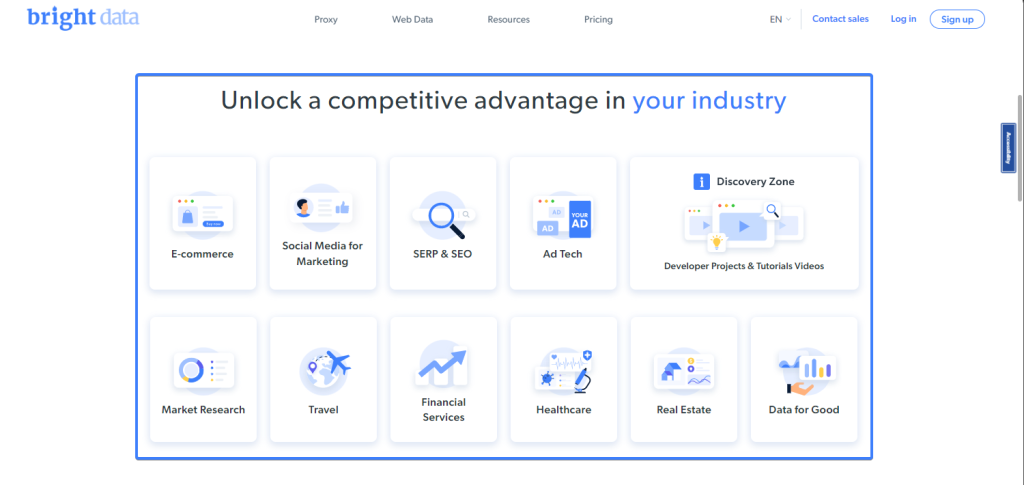
Vous pouvez extraire une liste de tous les cas d’utilisation de Bright Data à l’aide de l’extrait suivant :
const useCases = await page
.locator(".section_cases_row_col .elementor-image-box-title")
.allInnerTexts();
// useCases = [
// 'E-commerce',
// 'Social Media for Marketing',
// 'SERP & SEO',
// 'Ad Tech',
// 'Market Research',
// 'Travel',
// 'Financial Services',
// 'Healthcare',
// 'Real Estate',
// 'Data for Good'
// ]
Extraction du code HTML interne
Playwright vous permet également d’extraire le code HTML interne d’un élément à l’aide de la méthode innerHTML. Par exemple, vous pouvez obtenir le code HTML du pied de page de la page d’accueil de Bright Data à l’aide de l’extrait suivant :
const footerHtml = await page.locator("#footer").innerHTML();
// footerHtml = '<div class="container"><div class="footer__logo">...'
Extraction des valeurs d’attributs
Vous pouvez avoir besoin d’extraire des données des attributs d’un élément HTML, comme l’attribut hrefd’un lien. L’extrait Playwright suivant montre comment vous pouvez extraire la propriété href du lien Identification :
const signUpHref = await page.getByText("Log in").getAttribute("href");
// signUpHref = '/cp/start'
Capture d’écran de pages
Lorsque vous récupérez des données, vous pouvez avoir besoin de faire des captures d’écran à des fins d’audit. Pour ce faire, vous pouvez utiliser la méthode « screenshot ». Cette fonction vous permet de configurer plusieurs options, telles que l’emplacement d’enregistrement du fichier de la capture d’écran et la réalisation d’une capture d’écran pleine page.
L’extrait suivant effectue une capture d’écran pleine page de la page d’accueil de Bright Data et l’enregistre :
await page.screenshot({
// Save the screenshot to the "homepage.png" file
path: "homepage.png",
// Take a screenshot of the entire page
fullPage: true,
});
Utilisation de services de capture automatisés
Les extraits précédents expliquent en détail comment localiser une page web, interagir avec elle et en extraire les données. Ces méthodes vous permettront d’extraire presque toutes les données d’une page web. Cependant, elles nécessitent un effort, car vous devez identifier les éléments appropriés avant de les localiser. Vous devez également tenir compte des CAPTCHA et des limites de taux lorsque vous scrapez plusieurs pages d’un même site web.
Bright Data propose plusieurs solutions qui vous permettront de vous concentrer sur l’extraction de données. Bright Data fournit une IDE de web scraping possédant des fonctions JavaScript et des modèles prêts à l’emploi pour vous aider à scraper des données des sites web les plus populaires. Vous pouvez également contourner les CAPTCHA à l’aide de Web Unlocker et éviter les limites de débit et les blocages de géolocalisation à l’aide des services proxy de Bright Data. Ces services éliminent de nombreux obstacles dans Playwright, vous aidant à récupérer des données plus rapidement et plus facilement.
Conclusion
Dans cet article, vous avez découvert Playwright, une bibliothèque développée par Microsoft qui aide à extraire des données des sites web, et vous avez appris à utiliser Playwright pour localiser, interagir avec et extraire des données à partir d’éléments d’une page web. Enfin, vous avez vu comment un service de scraping automatisé tel que Bright Data peut simplifier vos processus de web scraping.




