

Dans ce guide, vous apprendrez :
- Pourquoi GPT Vision est un excellent choix pour les tâches d’extraction de données qui vont au-delà des techniques traditionnelles d’analyse syntaxique.
- Comment réaliser du web scraping visuel en utilisant GPT Vision en Python.
- La principale limite de cette approche et la manière de la contourner.
Plongeons dans l’aventure !
Pourquoi utiliser GPT Vision pour le Data Scraping ?
GPT Vision est un modèle d’IA multimodale qui comprend à la fois le texte et les images. Ces capacités sont disponibles dans les derniers modèles OpenAI. En passant une image à GPT Vision, vous pouvez effectuer une extraction visuelle de données, idéale pour les scénarios où l’analyse traditionnelle des données échoue.
L’analyse syntaxique régulière des données consiste à écrire des règles personnalisées pour extraire des données de documents (par exemple, des sélecteurs CSS ou des expressions XPath pour extraire des données de pages HTML). Le problème est que les informations peuvent être visuellement intégrées dans des images, des bannières ou des éléments complexes de l’interface utilisateur auxquels les techniques d’analyse standard ne permettent pas d’accéder.
GPT Vision vous aide à extraire des données de ces sources plus difficiles d’accès. Les deux cas d’utilisation les plus courants sont les suivants :
- Lescraping visuel du web: Extrayez du contenu web directement à partir de captures d’écran, sans vous soucier des changements de page ou des éléments visuels de la page.
- Extraction de documents à partir d’images: Récupérez des données structurées à partir de captures d’écran ou de scans de fichiers locaux tels que des CV, des factures, des menus et des reçus.
Pour une approche non visuelle, consultez notre guide sur le web scraping avec ChatGPT.
Comment extraire des données de captures d’écran avec GPT Vision en Python
Dans cette section, vous apprendrez étape par étape comment construire un script de scraping web GPT Vision. En détail, le scraper automatisera ces tâches :
- Utilisez Playwright pour vous connecter à la page web cible.
- Faites une capture d’écran de la section spécifique dont vous souhaitez extraire les données.
- Transmettez la capture d’écran à GPT Vision et demandez-lui d’extraire des données structurées.
- Exporter les données extraites vers un fichier JSON.
La cible est une page produit spécifique de “Books to Scrape” :
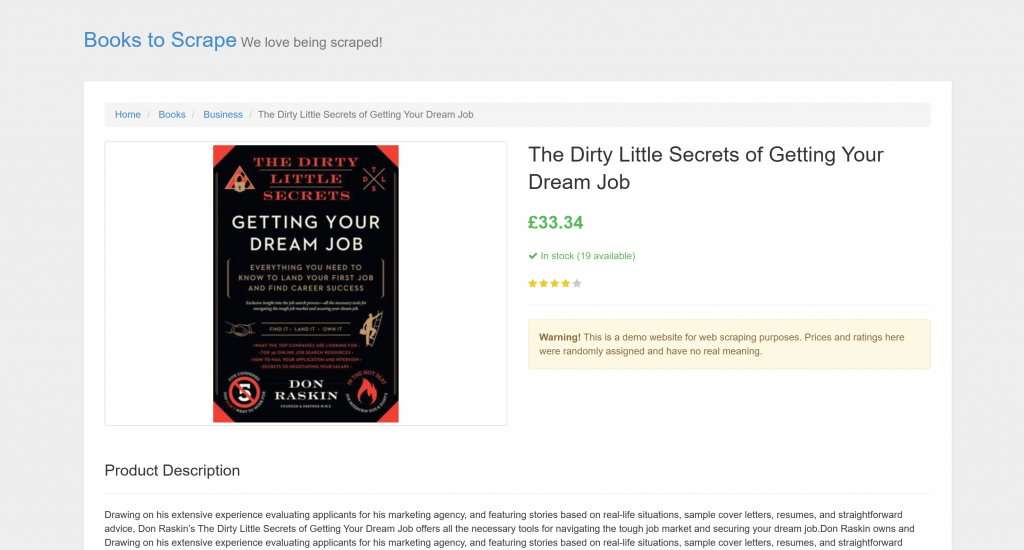
Cette page est parfaite pour les tests, car elle accueille explicitement les robots d’analyse. En outre, elle comporte des éléments visuels tels que le widget d’évaluation par étoiles, qui sont difficiles à traiter à l’aide des méthodes d’analyse conventionnelles.
Note: L’exemple d’extrait sera écrit en Python pour des raisons de simplicité et parce que le SDK OpenAI Python est largement adopté. Cependant, vous pouvez obtenir les mêmes résultats en utilisant le SDK OpenAI JavaScript ou tout autre langage supporté.
Suivez les étapes ci-dessous pour apprendre à récupérer des données web à l’aide de GPT Vision !
Conditions préalables
Avant de commencer, assurez-vous d’avoir
- Python 3.8 ou supérieur installé sur votre machine.
- Une clé API OpenAI pour accéder à l’API GPT Vision.
Pour récupérer votre clé API OpenAI, suivez le guide officiel.
Les connaissances de base suivantes vous aideront également à tirer le meilleur parti de cet article :
- Une connaissance de base de l’automatisation des navigateurs, en particulier à l’aide de Playwright.
- Connaissance du fonctionnement de GPT Vision.
Remarque: un outil d’automatisation du navigateur tel que Playwright est nécessaire pour cette approche. La raison en est que vous devez rendre la page cible dans un navigateur. Ensuite, une fois la page chargée, vous pouvez prendre une capture d’écran de la section spécifique qui vous intéresse. Cette opération peut être réalisée à l’aide de l’API Playwright Screenshots.
Étape 1 : Créer votre projet Python
Exécutez la commande suivante dans votre terminal pour créer un nouveau dossier pour votre projet de scraping :
mkdir gpt-vision-scrapergpt-vision-scraper/ servira de dossier de projet principal pour construire votre scraper web en utilisant GPT Vision.
Naviguez dans le dossier et créez-y un environnement virtuel Python :
cd gpt-vision-scraper
python -m venv venvOuvrez le dossier du projet dans votre IDE Python préféré. Visual Studio Code avec l’extension Python ou PyCharm Community Edition feront l’affaire.
Dans le dossier du projet, créez un fichier scraper.py :
gpt-vision-scraper
├─── venv/
└─── scraper.py # <------------A ce stade, scraper.py n’est qu’un fichier vide. Bientôt, il contiendra la logique pour le scraping visuel LLM via GPT Vision.
Ensuite, activez l’environnement virtuel dans votre terminal. Sous Linux ou macOS, lancez :
source venv/bin/activateDe manière équivalente, sous Windows, exécutez :
venv/Scripts/activateC’est bien ! Votre environnement Python est maintenant prêt pour le scraping visuel avec GPT Vision.
Note: Dans les étapes suivantes, il vous sera montré comment installer les dépendances nécessaires. Si vous préférez les installer toutes en même temps, exécutez cette commande :
pip install playwright openaiEnsuite :
python -m playwright installC’est très bien ! Votre environnement Python est maintenant en place.
Étape 2 : Connexion au site cible
Tout d’abord, vous devez demander à Playwright de visiter le site cible à l’aide d’un navigateur contrôlé. Dans votre environnement virtuel activé, installez Playwright avec :
pip install playwright Ensuite, terminez l’installation en téléchargeant les binaires du navigateur requis :
python -m playwright installEnsuite, importez Playwright dans votre script et utilisez la fonction goto() pour naviguer vers la page cible :
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
# Launch a new Playwright instance
browser = p.chromium.launch()
page = browser.new_page()
# Visit the target page
url = "https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html"
page.goto(url)
# Screenshotting logic...
# Close the browser and release its resources
browser.close()Si vous ne connaissez pas cette API, lisez notre article sur le scraping web avec Playwright.
Génial ! Vous avez maintenant un script Playwright qui se connecte avec succès à la page cible. Il est temps d’en faire une capture d’écran.
Étape 3 : Faire une capture d’écran de la page
Avant d’écrire la logique pour prendre une capture d’écran, gardez à l’esprit qu’OpenAI facture sur la base de l’utilisation des jetons. En d’autres termes, plus votre capture d’écran est importante, plus vous dépenserez.
Pour réduire les coûts, il est préférable de limiter la capture d’écran aux éléments HTML contenant les données qui vous intéressent. C’est possible, car Playwright prend en charge les captures d’écran basées sur les nœuds. Une capture d’écran restreinte permet également à GPT Vision de se concentrer sur le contenu pertinent, ce qui réduit le risque d’hallucinations.
Commencez par ouvrir la page cible dans votre navigateur et familiarisez-vous avec sa structure. Ensuite, cliquez avec le bouton droit de la souris sur le contenu et sélectionnez “Inspecter” pour ouvrir les DevTools du navigateur :
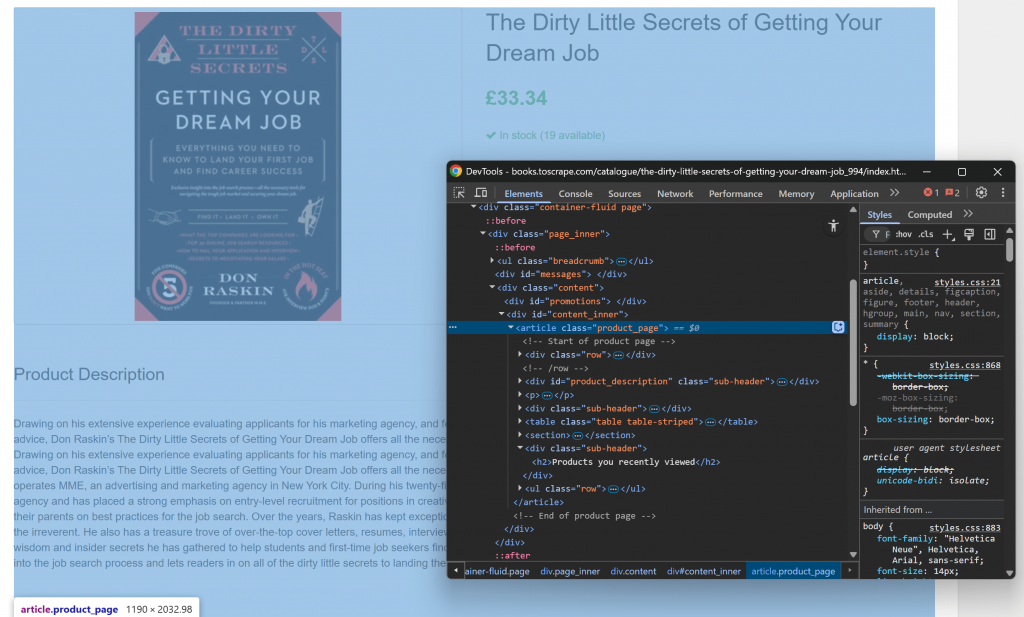
Vous remarquerez que la majeure partie du contenu pertinent est contenue dans l’élément HTML .product_page.
Comme cet élément peut être chargé dynamiquement ou révélé par JavaScript, vous devez l’attendre avant de le capturer :
product_page_element = page.locator(".product_page")
product_page_element.wait_for()Par défaut, wait_for() attendra jusqu’à 30 secondes que l’élément apparaisse dans le DOM. Cette micro-étape est fondamentale, car vous ne voulez pas faire de capture d’écran d’une section vide ou invisible.
Utilisez ensuite la méthode screenshot() sur le localisateur sélectionné pour effectuer une capture d’écran de cet élément uniquement :
product_page_element.screenshot(path=SCREENSHOT_PATH)Ici, SCREENSHOT_PATH est une variable contenant le nom du fichier de sortie, comme par exemple :
SCREENSHOT_PATH = "product_page.png"Stocker ces informations dans une variable est une bonne idée, car vous en aurez bientôt besoin.
Si vous lancez le script, il générera un fichier nommé product_page.png contenant :
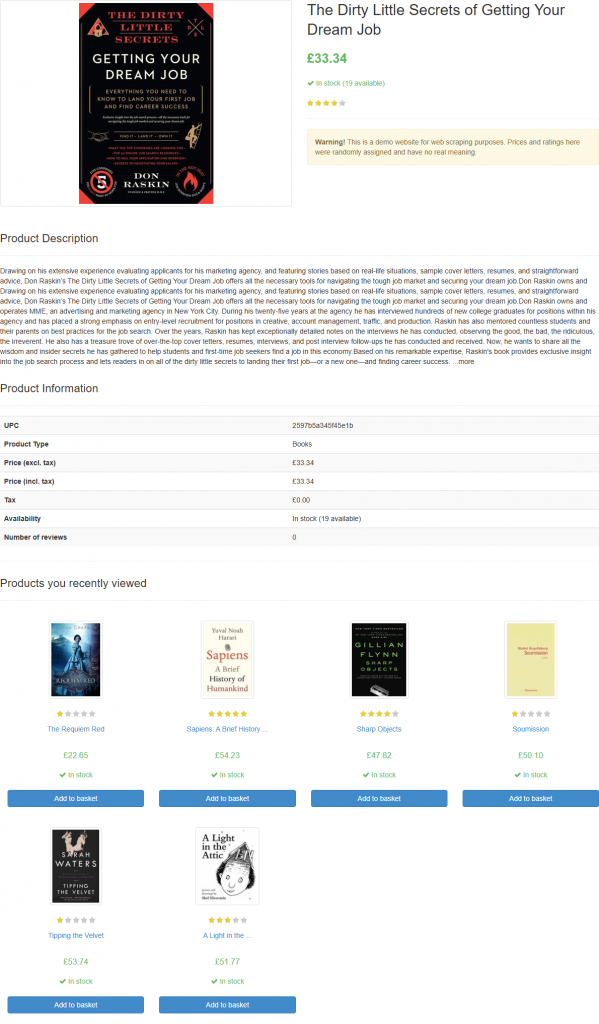
Note: Sauvegarder la capture d’écran dans un fichier est une bonne pratique, car vous voudrez peut-être la réanalyser plus tard en utilisant des techniques ou des modèles différents.
Fantastique ! La partie capture d’écran est terminée.
Étape 4 : Configurer OpenAI en Python
Pour utiliser GPT Vision pour le web scraping, vous pouvez utiliser le SDK OpenAI Python. Avec votre environnement virtuel activé, installez le paquet openai:
pip install openaiEnsuite, importez le client OpenAI dans scraper.py :
from openai import OpenAIContinuez en initialisant une instance de client OpenAI :
client = OpenAI()Cela vous permet de vous connecter plus facilement à l’API OpenAI, y compris aux API Vision. Par défaut, le constructeur OpenAI() recherche votre clé API dans la variable d’environnement OPENAI_API_KEY. Il est recommandé de définir cette variable d’environnement pour configurer l’authentification de manière sécurisée.
À des fins de développement ou de test, vous pouvez également ajouter la clé directement dans le code :
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>"
client = OpenAI(api_key=OPENAI_API_KEY)Remplacez le par votre clé d’API OpenAI.
Merveilleux ! Votre configuration OpenAI est maintenant terminée, et vous êtes prêt à utiliser GPT Vision pour le web scraping.
Étape 5 : Envoyer la demande de scraping de GPT Vision
GPT Vision accepte des images d’entrée dans plusieurs formats, y compris des URL d’images publiques. Comme vous travaillez avec un fichier local, vous devez envoyer l’image au serveur OpenAI en la convertissant en une chaîne encodée en Base64.
Pour convertir votre fichier de capture d’écran en Base64, écrivez le code suivant :
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8") Cela nécessite l’importation de la bibliothèque standard de Python:
import base64Transmettez ensuite l’image encodée à GPT Vision pour le web scraping visuel :
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
text={"format": {"type": "json_object"}} # Enable JSON Mode to get output data in JSON format
)Note : L’exemple ci-dessus utilise le modèle gpt-4.1, mais vous pouvez utiliser n’importe quel modèle OpenAI qui supporte les capacités visuelles.
Remarquez que GPT Vision est directement intégré à l’API Responses. Cela signifie que vous n’avez pas besoin de configurer quoi que ce soit de spécial. Il vous suffit d’inclure votre image Base64 en utilisant "type" : "input_image", et vous êtes prêt à partir.
L’invite à la recherche utilisée ci-dessus est la suivante :
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.Il se peut que vous ne connaissiez pas la structure exacte de la page cible, c’est pourquoi vous devez garder l’invite assez générique (tout en vous concentrant sur l’objectif). Ici, nous avons explicitement demandé au modèle d’ignorer les sections qui ne nous intéressent pas. Nous avons également demandé au modèle de renvoyer un objet JSON avec des noms de clés propres et bien structurés.
Notez que la requête API OpenAI Responses est configurée pour fonctionner en mode JSON. C’est ainsi que vous pouvez vous assurer que le modèle produira une sortie en format JSON. Pour que cette fonctionnalité fonctionne, votre invite doit inclure une instrcution pour renvoyer des données en JSON comme :
Return the data in JSON format using lowercase snake_case attribute names.Dans le cas contraire, la demande échouera avec :
openai.BadRequestError: Error code: 400 - {
'error': {
'message': "Response input messages must contain the word 'json' in some form to use 'text.format' of type 'json_object'.",
'type': 'invalid_request_error',
'param': 'input',
'code': None
}
}Une fois la requête terminée avec succès, vous pouvez accéder aux données structurées analysées à l’aide de la fonction :
json_product_data = response.output_textOptionnellement, analyser la chaîne résultante pour la convertir en un dictionnaire Python :
import json
product_data = json.loads(json_product_data)La logique d’analyse des données de GPT Vision est terminée ! Il ne reste plus qu’à exporter les données scannées vers un fichier JSON local.
Étape 6 : Exporter les données extraites
Écrire la chaîne JSON produite par l’appel à l’API GPT Vision avec :
with open("product.json", "w", encoding="utf-8") as f:
f.write(json_product_data)Cela créera un fichier product.json contenant les données extraites visuellement.
Bravo ! Votre scraper web alimenté par GPT Vision est maintenant prêt.
Étape n° 7 : Assembler le tout
Voici le code final de scraper.py :
from playwright.sync_api import sync_playwright
from openai import OpenAI
import base64
# Where to store the page screenshot
SCREENSHOT_PATH = "product_page.png"
with sync_playwright() as p:
# Launch a new Playwright instance
browser = p.chromium.launch()
page = browser.new_page()
# Visit the target page
url = "https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html"
page.goto(url)
# Wait for the product page element to be on the DOM
product_page_element = page.locator(".product_page")
product_page_element.wait_for()
# Take a full screenshot of the element
product_page_element.screenshot(path=SCREENSHOT_PATH)
# Close the browser and release its resources
browser.close()
# Initialize the OpenAI client
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>" # Replace with your OpenAI API key
client = OpenAI(api_key=OPENAI_API_KEY)
# Read the screenshot from the filesystem
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8")
# Perform the data extraction request via GPT Vision
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
text={"format": {"type": "json_object"}} # Enable JSON Mode to get output data in JSON format
)
# Extract the output data and export it to a JSON file
json_product_data = response.output_text
with open("product.json", "w", encoding="utf-8") as f:
f.write(json_product_data)Ouah ! En moins de 65 lignes de code, vous venez de réaliser du web scraping visuel avec GPT Vision.
Exécutez le scraper GPT Vision avec :
python scraper.pyLe script va prendre un certain temps et écrire un fichier product.json dans le dossier de votre projet. Ouvrez-le, et vous devriez voir :
{
"title": "The Dirty Little Secrets of Getting Your Dream Job",
"price_gbp": "£33.34",
"availability": "In stock (19 available)",
"rating": "4/5",
"description": "Drawing on his extensive experience evaluating applicants for his marketing agency, and featuring stories based on real-life situations, sample cover letters, resumes, and straightforward advice, Don Raskin’s The Dirty Little Secrets of Getting Your Dream Job offers all the necessary tools for navigating the tough job market and securing your dream job... [omitted for brevity]",
"product_information": {
"upc": "2597b5a345f45e1b",
"product_type": "Books",
"price_excl_tax": "£33.34",
"price_incl_tax": "£33.34",
"tax": "£0.00",
"availability": "In stock (19 available)"
}
}Notez qu’il a réussi à extraire toutes les informations relatives au produit sur la page, y compris l’évaluation de l’avis, à partir de l’élément purement visuel :
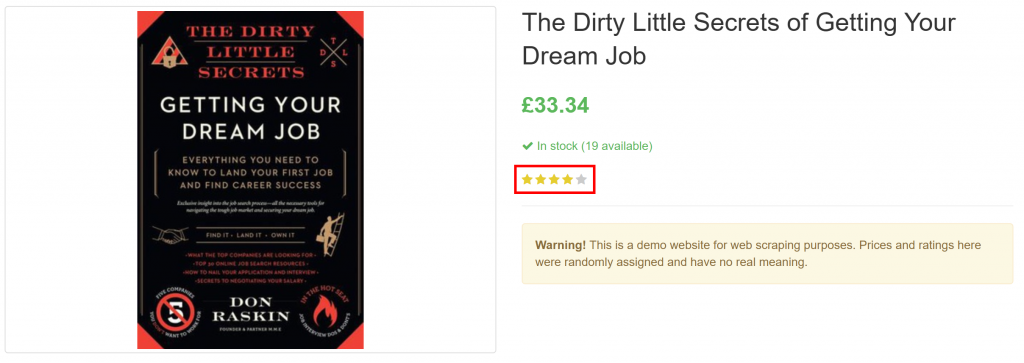
Et voilà ! GPT Vision a pu transformer une capture d’écran en un fichier JSON bien structuré.
Prochaines étapes
Pour améliorer votre racleur GPT Vision, envisagez les modifications suivantes :
- Le rendre réutilisable: Reformulez le script pour qu’il accepte l’URL cible, le sélecteur CSS de l’élément à attendre et l’invite LLM de l’interface de programmation. De cette façon, vous pouvez récupérer différentes pages sans modifier le code.
- Sécurisez votre clé API: Au lieu de coder en dur votre clé API OpenAI, stockez-la dans un fichier
.envet chargez-la à l’aide du paquetagepython-dotenv. Vous pouvez également la définir comme une variable d’environnement globale nomméeOPENAI_API_KEY. Ces deux méthodes permettent de protéger vos informations d’identification et de sécuriser votre base de code.
Surmonter la plus grande limitation du Web Scraping visuel
La principale difficulté de cette approche du web scraping réside dans l’étape de la capture d’écran. Si elle a parfaitement fonctionné sur un site “bac à sable” comme “Books to Scrape”, les sites web réels présentent une réalité différente.
De nombreux sites web modernes déploient des mesures anti-scraping qui peuvent bloquer votre script avant que vous ne puissiez accéder à la page. Même si votre scraper réussit à accéder à la page, il se peut que vous receviez une erreur ou un défi de vérification humaine. C’est ce qui se produit, par exemple, lorsque vous utilisez vanilla Playwright sur des sites tels que G2.com :

Ces problèmes peuvent être causés par l’empreinte digitale du navigateur, la réputation IP, la limitation du débit, les défis CAPTCHA, etc.
Le moyen le plus efficace de contourner ces blocages est de s’appuyer sur une API de déverrouillage Web dédiée !
Web Unlocker de Bright Data est un puissant point final de scraping qui s’appuie sur un réseau de proxy de plus de 150 millions d’adresses IP. Il offre notamment des fonctions d’usurpation d’empreintes digitales, de rendu JavaScript, de résolution de CAPTCHA et bien d’autres. Il prend même en charge la capture d‘écran, ce qui signifie que vous pouvez ignorer complètement la logique de capture d’écran manuelle de Playwright.
Supposons que vous souhaitiez extraire l’évaluation moyenne par étoiles de la page vendeur G2 de Bright Data :
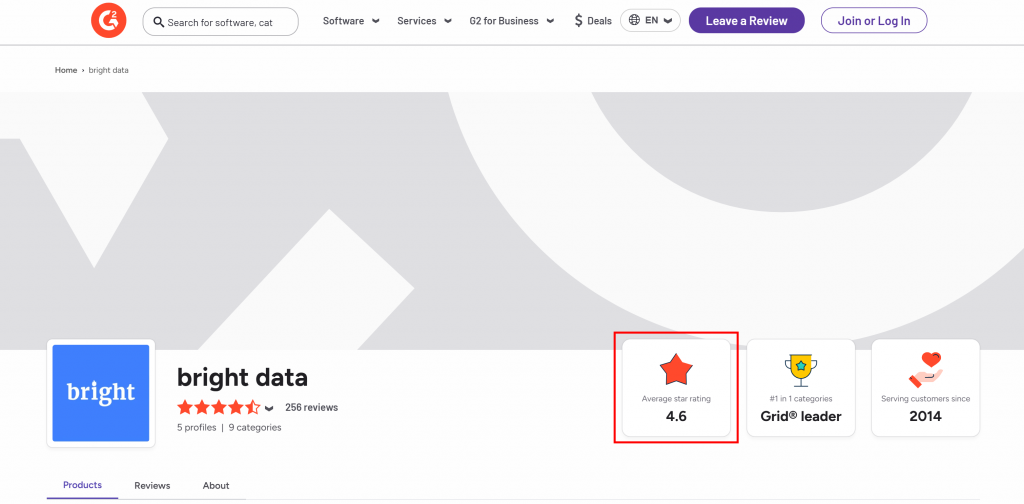
Pour commencer, configurez Web Unlocker comme expliqué dans la documentation et récupérez votre clé API Bright Data. Utilisez GPT Vision avec Web Unlocker comme suit :
# pip install requests
import requests
from openai import OpenAI
import base64
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Replace with your Bright Data API key
# Get a screenshot of the target page using Bright Data Web Unlocker
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}"
}
payload = {
"zone": "web_unlocker", # Replace with your Web Unlocker zone name
"url": "https://www.g2.com/sellers/bright-data", # Your target page
"format": "raw",
"data_format": "screenshot" # Enable the screenshotting mode
}
response = requests.post(url, headers=headers, json=payload)
# Where to store the scraped screenshot
SCREENSHOT_PATH = "screenshot.png"
# Save the screenshot to a file (e.g., for further analysis in the future)
with open(SCREENSHOT_PATH, "wb") as f:
f.write(response.content)
# Initialize the OpenAI client
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>" # Replace with your OpenAI API key
client = OpenAI(api_key=OPENAI_API_KEY)
# Read the screenshot file and convert its contents to Base64
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8")
# Perform the scraping request using GPT Vision
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Return the average star rating from the following image.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
)
print(response.output_text)Exécutez le script ci-dessus, et il produira une sortie comme :
The average star rating from the image is 4.6.Cette information est correcte, comme vous pouvez le confirmer visuellement dans le fichier screenshot.png généré par Web Unlocker :
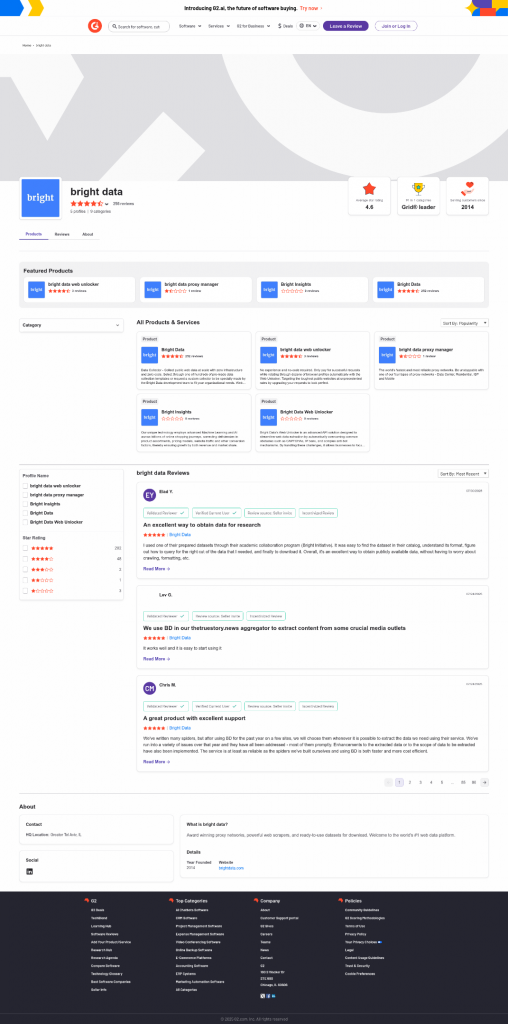
Notez que vous pouvez utiliser Web Unlocker pour récupérer le code HTML entièrement déverrouillé de la page, ou même obtenir son contenu dans un format Markdown optimisé pour l’IA.
Et c’est ainsi qu’il n’y a plus de blocages, plus de maux de tête. Vous disposez maintenant d’un scraper de niveau production, alimenté par GPT Vision, qui fonctionne même sur les sites Web protégés.
Voir le SDK OpenAI et le Web Unlocker fonctionner ensemble dans un scénario de scraping plus complexe.
Conclusion
Dans ce tutoriel, vous avez appris à combiner GPT Vision avec les capacités de capture d’écran de Playwright pour construire un grattoir Web alimenté par l’IA. Le plus grand défi (c’est-à-dire le blocage des captures d’écran) a été relevé grâce à l’API Bright Data Web Unlocker.
Comme nous l’avons vu, la combinaison de GPT Vision et de la fonctionnalité de capture d’écran fournie par l’API Web Unlocker vous permet d’extraire visuellement des données de n’importe quel site web. Et ce, sans avoir à écrire un code d’analyse personnalisé. Ce n’est qu’un des nombreux scénarios couverts par les produits et services d’IA de Bright Data.
Créez gratuitement un compte Bright Data et expérimentez nos solutions de données !




