

Dans ce guide XPath vs CSS Selector, vous apprendrez :
- Ce que sont les expressions XPath, comment elles fonctionnent, ainsi que leurs avantages et leurs inconvénients.
- Ce que sont les sélecteurs CSS, comment ils fonctionnent, ainsi que leurs avantages et inconvénients.
- Comment les expressions XPath et les sélecteurs CSS se comparent en termes de performances, de simplicité et de cas d’utilisation.
C’est parti !
XPath : analyse complète
Commençons ce guide comparatif entre XPath et les sélecteurs CSS en nous plongeant dans le premier élément de la comparaison, XPath.
Définition
XPath, abréviation de XML Path Language, est un langage de requête permettant de naviguer et d’interroger le DOM. Il offre notamment un moyen puissant de localiser et d’extraire des informations à partir de documents XML/HTML.
XPath a une syntaxe qui ressemble à celle d’un système de fichiers, s’appuyant sur des expressions pour localiser des nœuds dans l’arborescence XML/HTML. Une expression XPath définit le chemin d’accès à des éléments et attributs spécifiques dans la structure hiérarchique du document.
Syntax
Vous trouverez ci-dessous une description des principaux composants de la syntaxe XPath :
/: pour commencer à sélectionner des nœuds à partir du nœud racine.//: pour sélectionner les nœuds du document à partir du nœud actuel qui correspondent à la sélection, quel que soit leur emplacement..:Pour sélectionner le nœud actuel...: pour sélectionner le parent du nœud actuel.@: pour sélectionner les attributs des nœuds.element: Pour sélectionner des nœuds en fonction d’une balise spécifique (par exemple,div).[condition]: pour sélectionner les nœuds en fonction d’une condition spécifiée (par exemple,[@type="submit"]).function(): pour appliquer une fonction XPath spécifique à l’expression (par exemple,text()renvoie le contenu textuel du nœud sélectionné).
Voici quelques exemples pour mieux comprendre la syntaxe de XPath :
//a: sélectionne tous les éléments<a>du document.//ul/li: sélectionne tous les éléments<li>qui sont des enfants des éléments<ul>.//ul/..: sélectionne tous les nœuds parents des éléments<ul>.//ul/li[@category='fiction']: Sélectionne tous les éléments<il>sous les balises<ul>dont l’attributcategoryest égal à «fiction ».//title[@lang='en']: Sélectionne tous les éléments<title>avec un attributlangégal à« en »n’importe où dans le document.- //title/text(): Récupère le contenu textuel de tous les éléments
<title>du document. //div[contains(@class, 'post')]/following-sibling::div[1]: sélectionne le premier élément<div>qui est un élément frère de chaque élément<div>contenant la classe «post ».
Notez que les expressions XPath prennent également en charge les opérateurs booléens et arithmétiques pour combiner plusieurs fonctions et conditions.
Avantages
- Grande polyvalence: il vous permet de naviguer à la fois dans les structures XML et HTML, ce qui permet de cibler avec précision les éléments, les attributs et les nœuds de texte. Il prend également en charge le parcours avant et arrière du DOM ainsi que la sélection des nœuds parents et frères.
- Nombreuses fonctions et opérateurs: il est livré avec un ensemble complet de fonctions intégrées (par exemple,
contains(),concat(),count(), etc.) et d’opérateurs (par exemple,+,or,and, etc.) pour manipuler et comparer des données dans des documents XML/HTML. - Prise en charge des chemins absolus et relatifs: les expressions XPath décrivent le chemin vers les nœuds souhaités à partir de la racine du document (chemins absolus) ou à partir d’un élément spécifique (chemins relatifs).
- Prise en charge de la sélection de nœuds de texte: il permet la sélection directe de nœuds de texte, ouvrant la voie à l’extraction de contenu textuel à partir de documents XML/HTML sans nécessiter de traitement ou d’analyse supplémentaire.
- Indépendance vis-à-vis de la plate-forme: il n’est pas lié à un langage de programmation ou à une plate-forme spécifique, et prend en charge un large éventail d’environnements, de bibliothèques, de navigateurs et de systèmes d’exploitation.
Inconvénients
- Syntaxe complexe et longue: la syntaxe de XPath peut être difficile, en particulier pour les débutants. L’écriture du chemin d’accès à un nœud spécifique profondément imbriqué dans le DOM peut donner lieu à une expression longue pouvant impliquer certaines fonctions et certains opérateurs. Cela peut rendre les expressions XPath sujettes aux erreurs et difficiles à déboguer.
- Prise en charge et popularité limitées: toutes les bibliothèques d’analyse HTML ne prennent pas en charge XPath. En effet, les sélecteurs CSS sont beaucoup plus populaires parmi les développeurs web, et les bibliothèques ont tendance à se concentrer sur ceux-ci. De plus, la plupart des bibliothèques basées sur XPath, comme HtmlAgilityPack, reposent encore sur XPath 1.0, publié en 1999. La version actuelle est XPath 3.1, publiée en 2017. Lisez notre guide sur HtmlAgilityPack pour devenir un expert en Scraping web avec C#.
Conseils et astuces
Chrome vous permet de tester et de récupérer des expressions XPath directement dans le navigateur.
Supposons que vous souhaitiez sélectionner un élément spécifique sur une page web. Rendez-vous sur cette page dans Chrome, cliquez avec le bouton droit de la souris sur le nœud qui vous intéresse et sélectionnez « Inspecter : ».
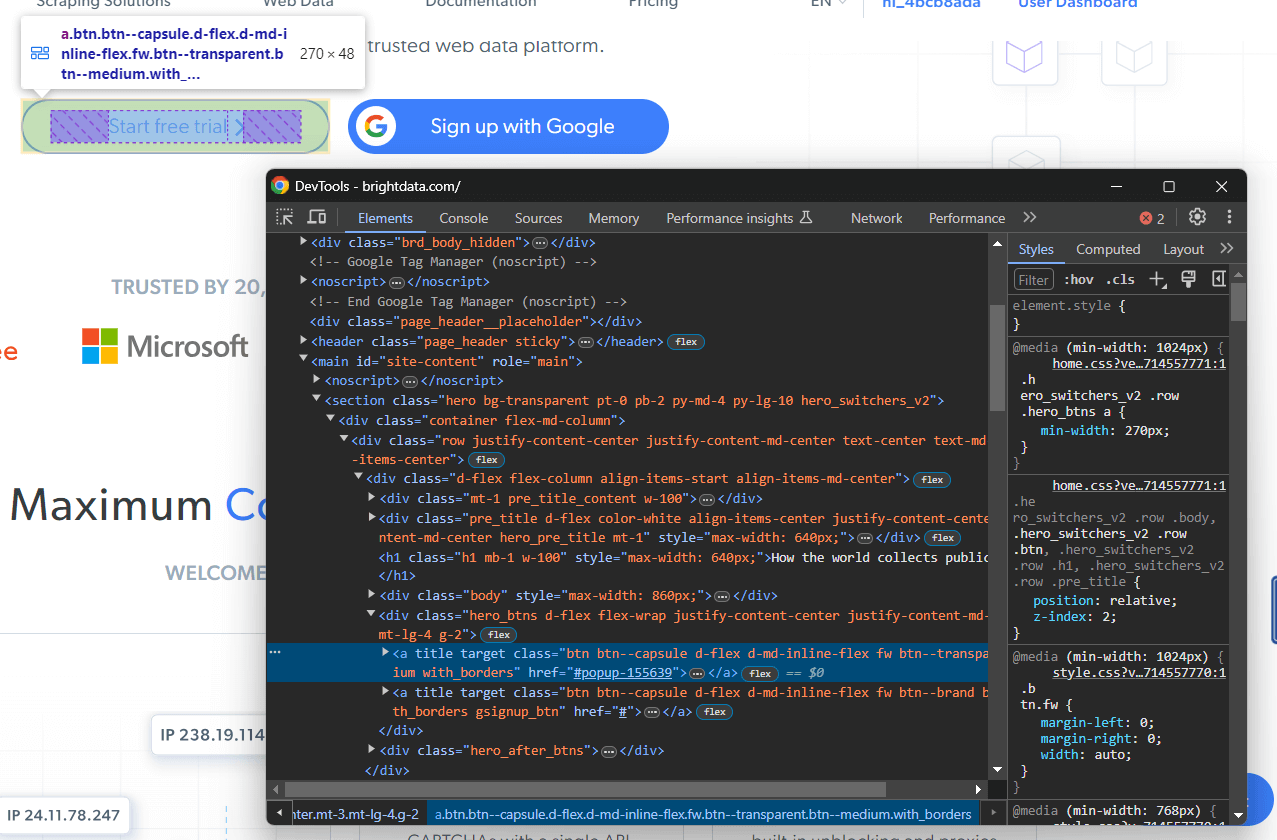
Cliquez avec le bouton droit sur l’élément DOM spécifique et choisissez « Copier > Copier XPath » pour obtenir une expression XPath correspondante. Dans l’exemple ci-dessus, vous obtiendrez :
//*[@id="site-content"]/section[1]/div/div/div[1]/div[4]/a[1]
Remarque: cela est utile pour avoir une idée de la manière de construire une stratégie de sélection XPath efficace. Cependant, les expressions XPath générées automatiquement ont tendance à être trop longues et orientées vers la mise en œuvre. Vous ne pouvez donc pas vous y fier en production.
Vous souhaitez maintenant tester une expression XPath sur la page. Dans Chrome, il existe deux façons de procéder.
Tout d’abord, collez l’expression XPath dans la barre de recherche de la section « Éléments » de DevTools, que vous pouvez activer avec CTRL/Commande + F:
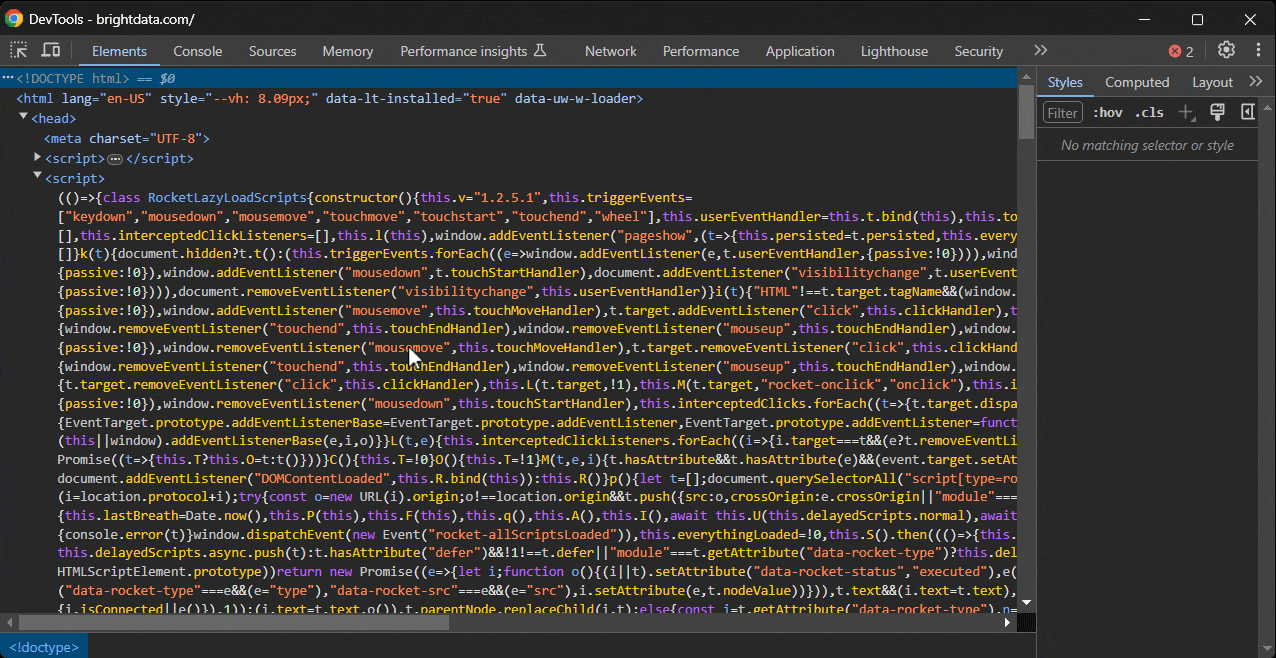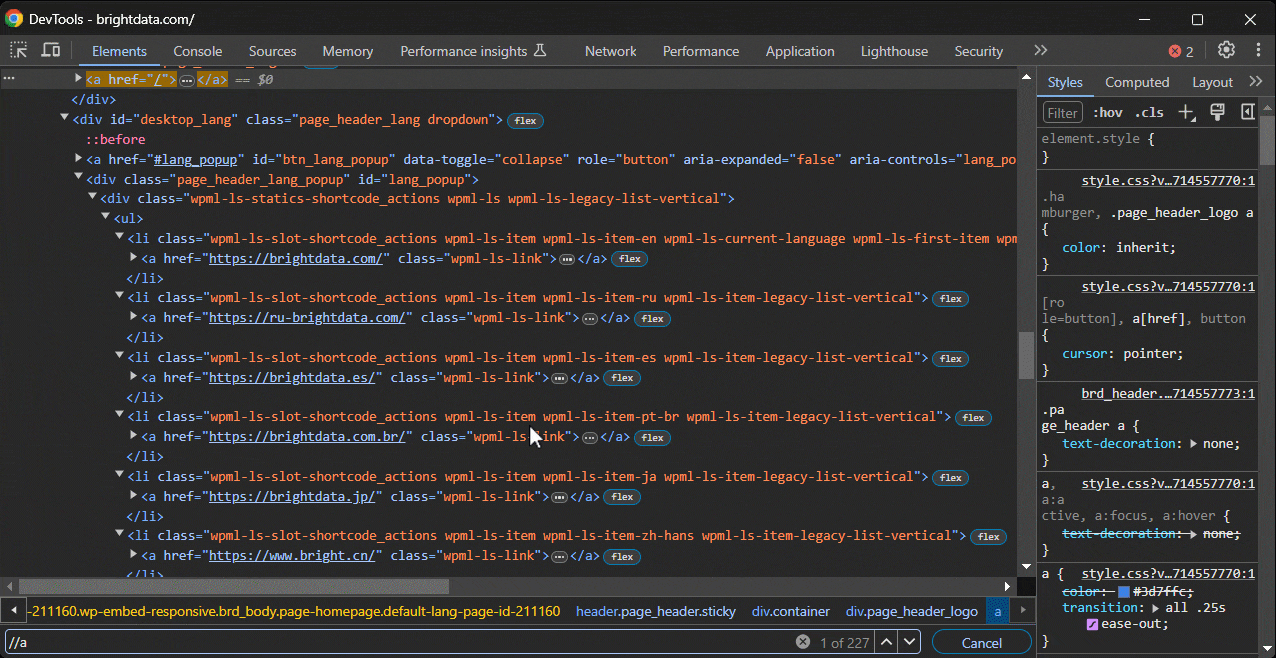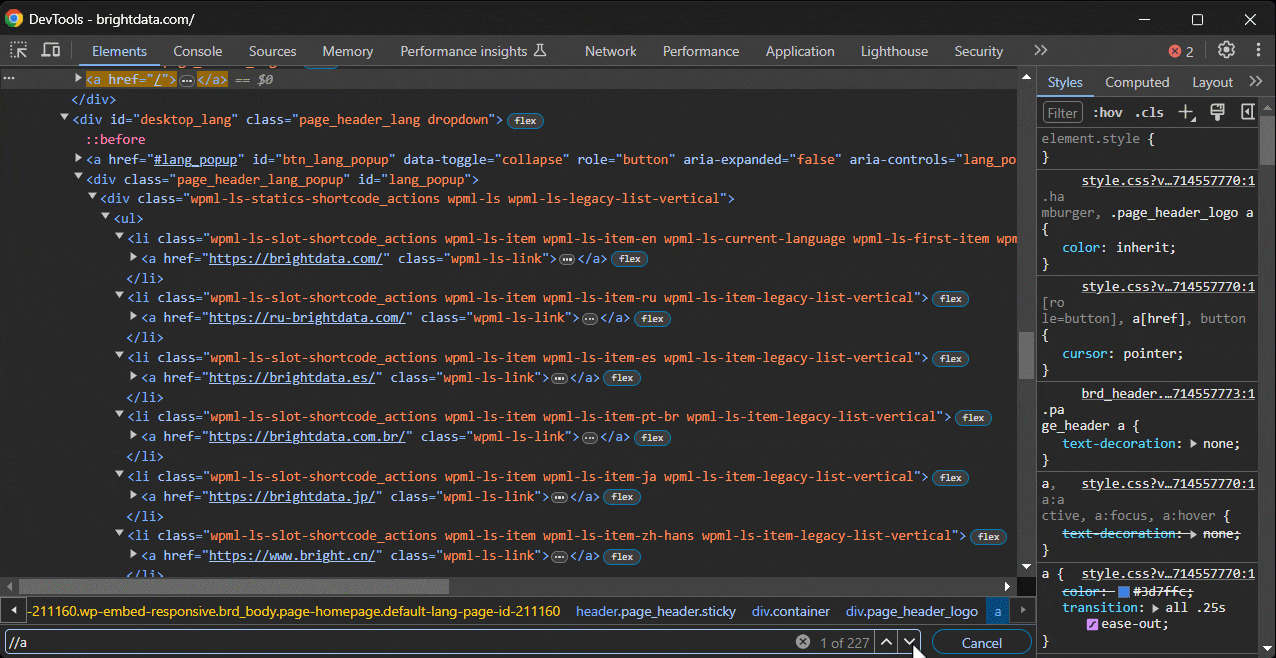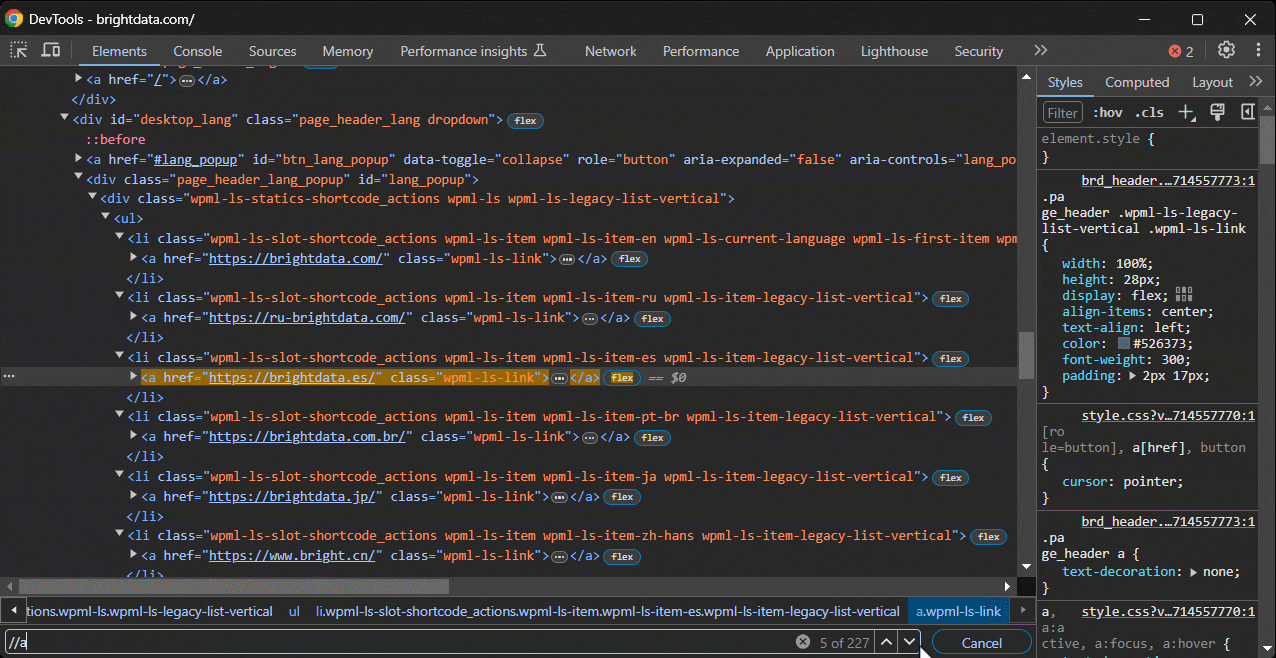
Ensuite, appelez-la dans la console à l’aide de la fonction spéciale $x():
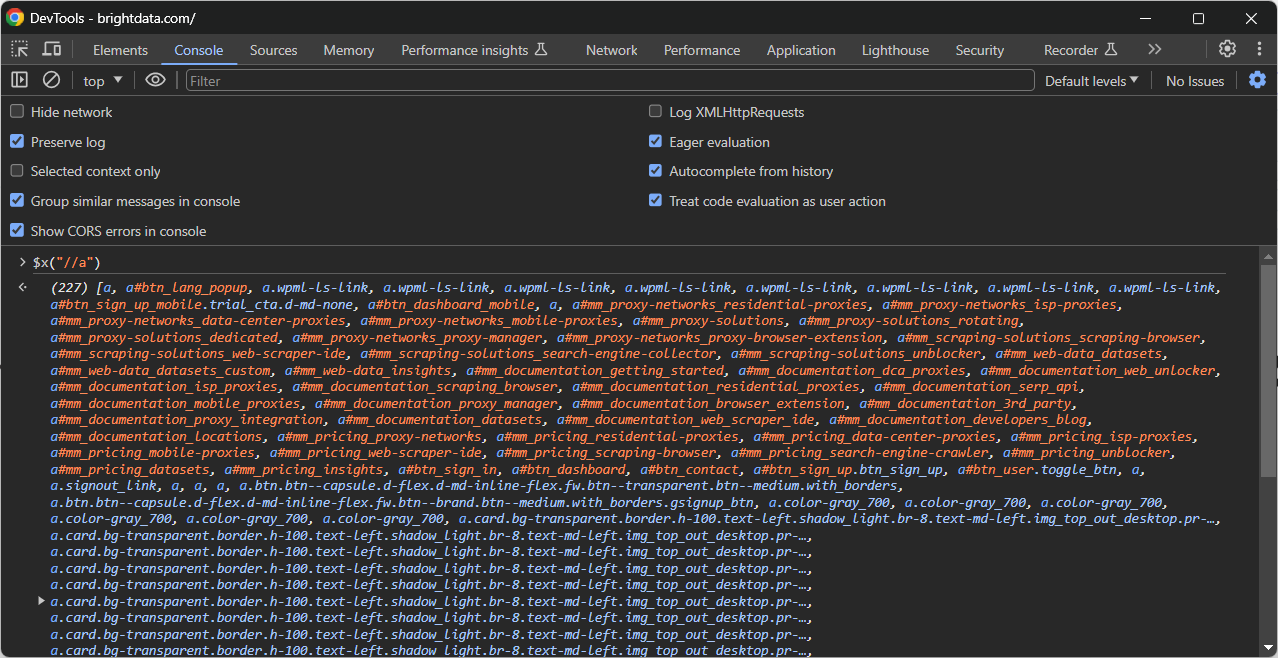
Sélecteurs CSS : examen approfondi
Poursuivez cet article sur les sélecteurs XPath et CSS en explorant le deuxième élément de la comparaison, les sélecteurs CSS.
Définition
Les sélecteurs CSS vous permettent de sélectionner des éléments HTML dans une page web. Ils font partie du CSS et sont utilisés pour cibler les éléments HTML sur les pages web. De même, les outils de navigation sans interface graphique et les bibliothèques d’analyse HTML les prennent en charge comme moyen de sélectionner des nœuds sur le DOM.
Un sélecteur CSS peut cibler des éléments individuels ou des groupes d’éléments en fonction de leur ID, de leur classe, de leurs attributs et de leur position dans l’arborescence du document. Si les sélecteurs CSS jouent un rôle crucial dans l’application de styles et de formats aux pages web, ils constituent également un excellent outil pour le Scraping web.
Syntaxe
La meilleure façon d’expliquer la syntaxe des sélecteurs CSS est de les présenter à l’aide d’exemples :
- Sélecteur d’élément: pour cibler des éléments en fonction de leur nom de balise. Par exemple,
psélectionne tous les éléments<p>dans le DOM. - Sélecteur de classe: pour cibler des éléments avec un attribut de classe spécifique. Par exemple,
.highlightsélectionne tous les éléments avec l’attribut HTMLclass="highlight <other_classes>". - Sélecteur d’ID: pour cibler un élément spécifique en fonction de son attribut ID. Par exemple,
#navbarsélectionne l’élément avecid="navbar". - Sélecteur d’attribut: pour cibler des éléments en fonction de leurs attributs. Par exemple,
input[type="text"]sélectionne tous les éléments<input>avec l’attributtype="text". - Sélecteur descendant: pour cibler les éléments qui sont les descendants d’un autre élément. Par exemple,
div asélectionne tous les éléments<a>qui sont les descendants des éléments<div>. - Sélecteur enfant: pour cibler les éléments qui sont les enfants directs d’un autre élément. Par exemple,
ul > lisélectionne tous les éléments<li>qui sont les enfants directs des éléments<ul>. - Sélecteur de frère adjacent: pour cibler un élément immédiatement précédé par un élément frère spécifié. Par exemple,
h2 + psélectionne l’élément<p>immédiatement suivant un élément<h2>.
Gardez à l’esprit que différents navigateurs fournissent différentes implémentations de la norme CSS. Consultez des sites tels que caniuse.com pour obtenir des informations sur la compatibilité d’un opérateur ou d’une syntaxe CSS spécifique.
Avantages
- Excellentes performances: la plupart des navigateurs disposent d’un moteur de sélecteur CSS dédié qui garantit des performances élevées. Ce moteur est principalement utilisé pour la mise en forme, mais peut également s’avérer utile lors de l’utilisation de sélecteurs CSS sur une page via un outil d’automatisation du navigateur.
- Rapide à apprendre: la courbe d’apprentissage des sélecteurs CSS est assez faible, même pour les débutants, grâce à sa syntaxe intuitive.
- Syntaxe simple et bien connue: ils ont une syntaxe concise qui n’implique pas d’opérateurs ou de fonctions complexes. De plus, la plupart des développeurs web savent comment les utiliser, ce qui leur permet de les utiliser dans d’autres domaines que le stylisme.
- Grande facilité de maintenance: les sélecteurs CSS sont conçus pour être faciles à lire et à mettre à jour, ce qui simplifie la maintenance du code.
- Compatibilité globale: les navigateurs web modernes et les meilleurs outils de Scraping web les prennent en charge. Cela garantit une sélection cohérente des nœuds sur différentes plateformes, différents appareils et différents cas d’utilisation, sans avoir besoin de solutions de contournement spécifiques à l’environnement.
Inconvénients
- Ne prennent pas en charge les fonctions et opérateurs avancés: contrairement à XPath, les sélecteurs CSS sont assez simples et ne disposent pas de nombreuses fonctions ou opérateurs. Par exemple, vous ne pouvez pas les utiliser pour sélectionner des nœuds de texte ou extraire des données du DOM.
- Ne prennent pas en charge le parcours ascendant de l’arborescence DOM: ils peuvent rechercher des éléments dans le DOM uniquement à partir du nœud racine et en descendant.
Conseils et astuces
Tout comme dans le cas de XPath, Chrome peut tester et générer des sélecteurs CSS directement sur une page.
Supposons que vous souhaitiez écrire un sélecteur CSS pour cibler un nœud spécifique. Rendez-vous sur la page de destination dans Chrome, cliquez avec le bouton droit de la souris sur l’élément qui vous intéresse et sélectionnez « Inspecter » :
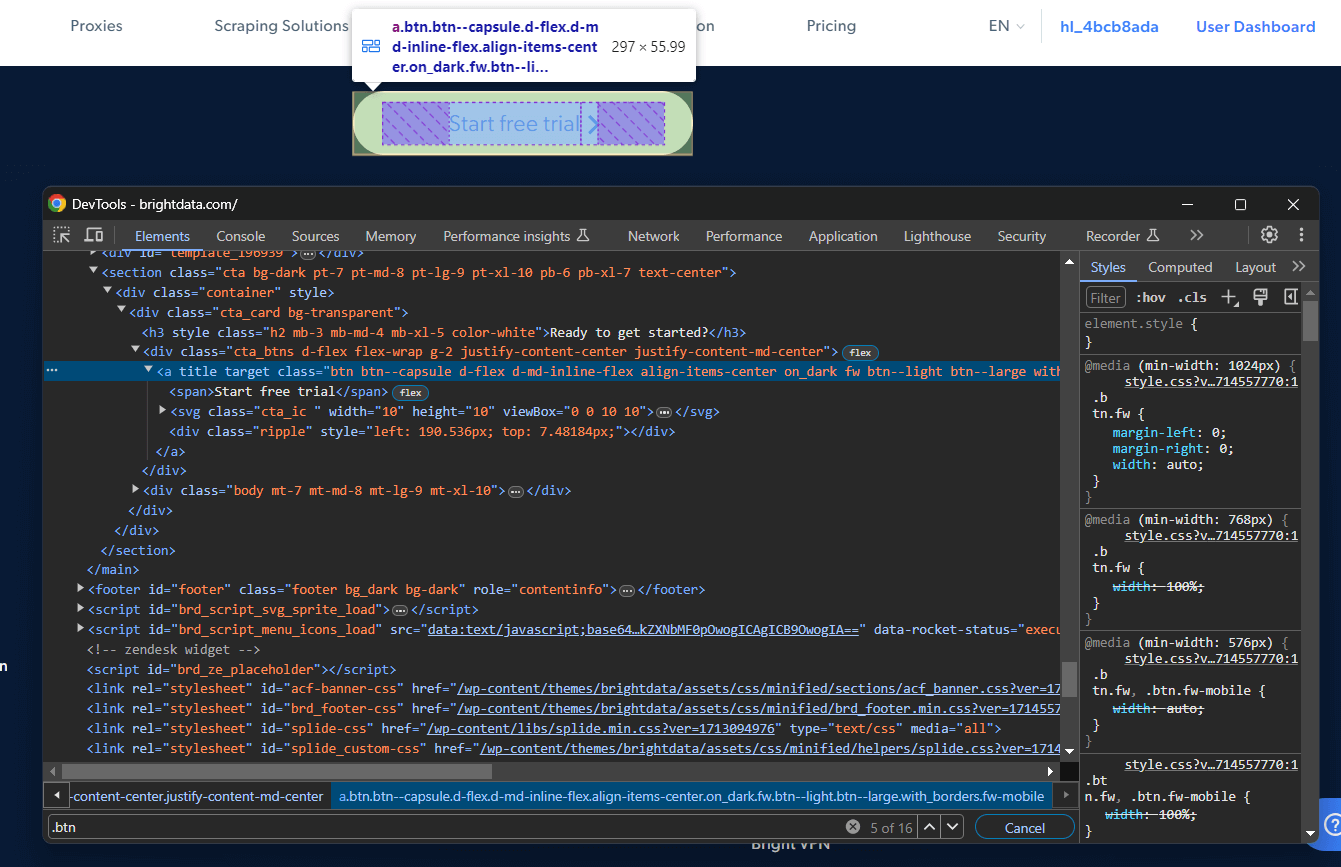
Cliquez avec le bouton droit sur l’élément DOM spécifique et sélectionnez « Copier > Copier le sélecteur » pour obtenir un sélecteur CSS complet pour celui-ci. Dans l’exemple ci-dessus, vous obtiendrez :
#site-content > section.cta.bg-dark.pt-7.pt-md-8.pt-lg-9.pt-xl-10.pb-6.pb-xl-7.text-center > div > div > div.cta_btns.d-flex.flex-wrap.g-2.justify-content-center.justify-content-md-center > a
Comme vous pouvez le constater, il est trop long et spécifique à l’implémentation. Bien qu’il soit utile pour se faire une idée, n’utilisez pas les sélecteurs CSS générés avec cette fonction en production.
Supposons que vous ayez besoin de tester un sélecteur CSS sur une page web. Dans Chrome, il existe plusieurs façons de le faire.
La première approche consiste à coller le sélecteur CSS dans la barre de recherche comme ci-dessous, qui peut être activée avec le raccourci CTRL/Commande + F :
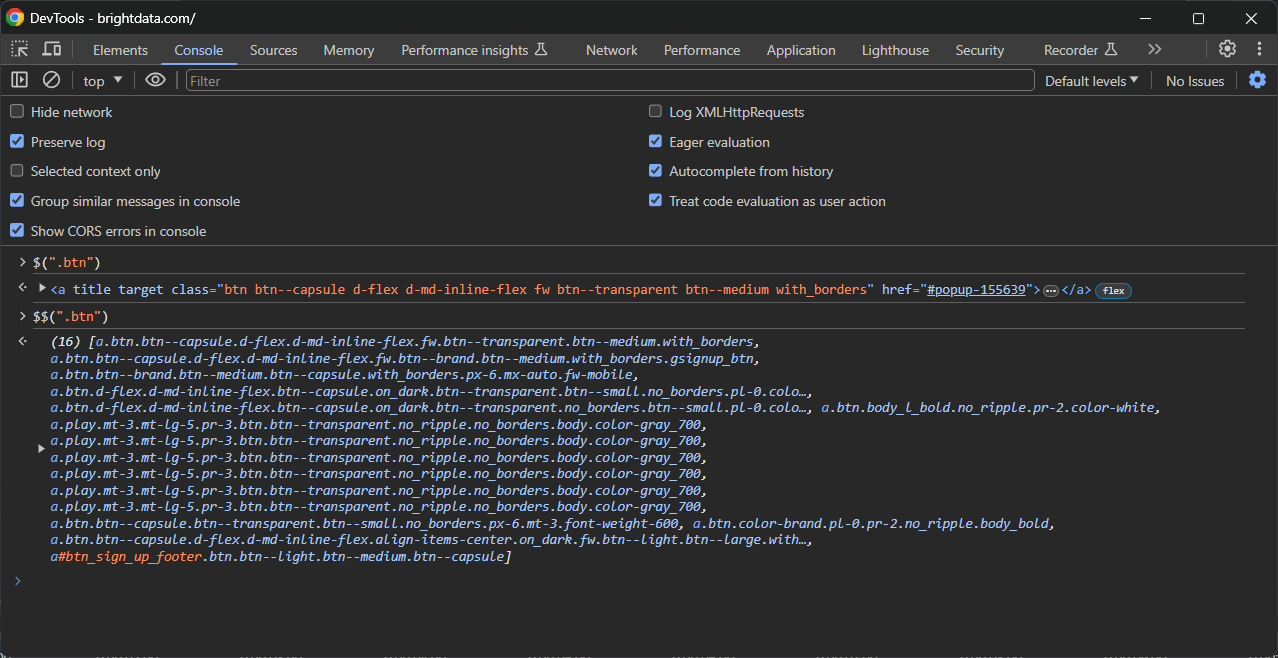
La deuxième consiste à les tester dans la console à l’aide de ces fonctions spéciales :
$(): pour sélectionner un seul élément avec le sélecteur CSS spécifié.- $$(): pour sélectionner tous les éléments correspondants.
Utilisez-les comme dans l’exemple suivant :
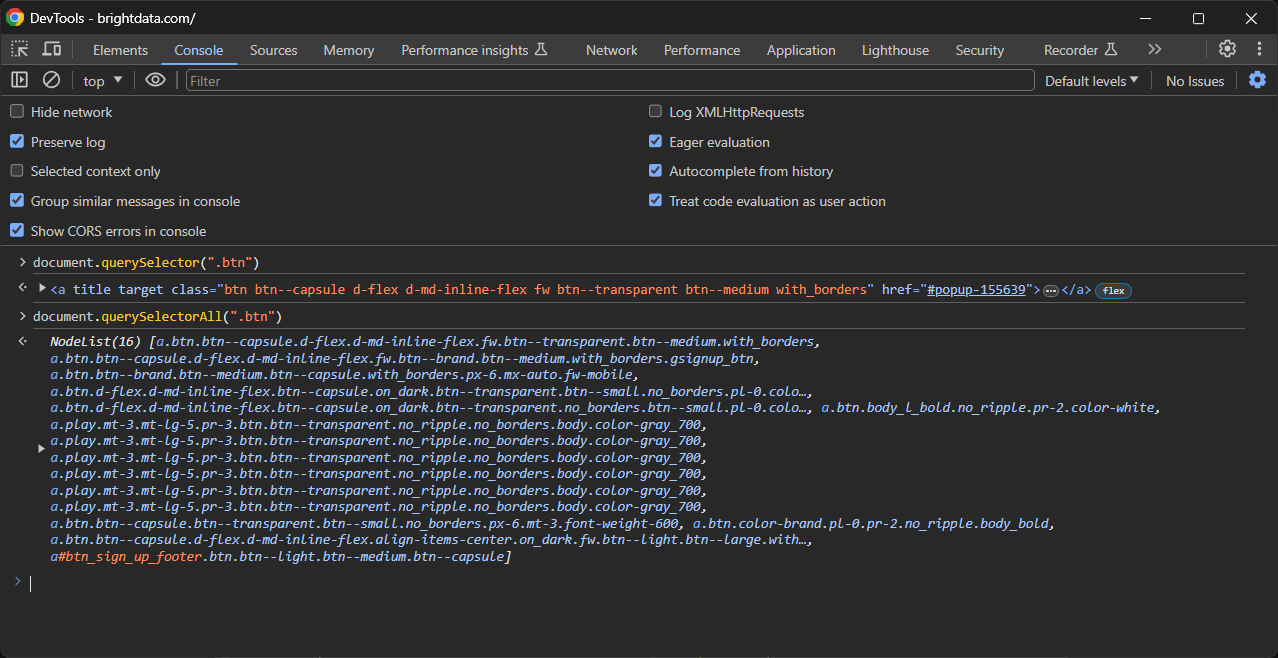
De manière équivalente, vous pouvez utiliser les fonctions JavaScript querySelector() et querySelectorAll():
XPath vs sélecteur CSS : comparaison directe
Maintenant que vous savez ce que sont les sélecteurs XPath et CSS, vous êtes prêt à vous plonger dans l’analyse comparative entre XPath et CSS.
Pour une comparaison directe en un coup d’œil, consultez le tableau récapitulatif ci-dessous :
| Aspect | XPath | Sélecteurs CSS |
| Norme W3C | Oui | Oui |
| Dernière spécification | XPath 3.1 (2017) | CSS niveau 4 (mis à jour en permanence) |
| Compatibilité | La plupart des navigateurs de scraping et des outils de scraping prennent toujours en charge XPath 1.0 | La plupart des navigateurs de scraping et des outils de scraping le prennent en charge dans sa dernière spécification |
| Syntaxe | Complexe et verbeuse | Simple et concise |
| Fonctions et opérateurs | Nombreuses | Peu |
| Sélection de nœuds de texte | Prise en charge | Non pris en charge |
| Performances dans le navigateur | Moyennes/lentes | Rapide |
| Prise en charge par les bibliothèques | Généralement pris en charge par les bibliothèques d’analyse XML | Généralement pris en charge par la plupart des bibliothèques d’analyse HTML |
Simplicité
La syntaxe XPath semble généralement beaucoup plus complexe que celle des sélecteurs CSS. Elle ressemble à un langage de requête basé sur les chemins d’accès, ce qui implique une courbe d’apprentissage abrupte pour les développeurs qui ne la connaissent pas bien. Cependant, XPath offre un contrôle précis sur la sélection et le parcours des éléments.
Les sélecteurs CSS sont généralement plus simples et plus intuitifs lorsqu’il s’agit de sélectionner des éléments DOM. Ils utilisent des modèles familiers tels que les noms de balises, les classes et les identifiants, ce qui les rend faciles à comprendre et à utiliser, même pour les débutants. Les sélecteurs CSS sont largement adoptés dans le développement web, ce qui rend leur syntaxe assez familière.
Vitesse
Comme le montre un benchmark, les expressions XPath appliquées aux arborescences DOM dans un navigateur ont tendance à être plus lentes que les sélecteurs CSS. La raison en est que les moteurs XPath doivent généralement effectuer des opérations de parcours plus complexes que les moteurs de sélecteurs CSS. De plus, la plupart des navigateurs modernes disposent de moteurs de sélecteurs CSS hautement optimisés, qui permettent une sélection efficace des éléments HTML. En ce qui concerne les bibliothèques d’analyse HTML, les différences de performances dépendent de l’implémentation sous-jacente.
Cas d’utilisation
XPath est idéal pour interroger et naviguer dans des documents XML à l’aide de XSLT ou pour une extraction de données simple. Ses capacités avancées peuvent s’avérer utiles dans certains scénarios de scraping, par exemple lorsque l’on cible des nœuds parents. Les sélecteurs CSS sont principalement utilisés pour styliser des documents HTML et sélectionner des nœuds dans les scripts de Scraping web modernes.
Conclusion
XPath ou sélecteurs CSS ? Dans ce guide sur les sélecteurs XPath et CSS, vous avez appris qu’il s’agit de deux méthodes efficaces pour sélectionner des éléments DOM. XPath se concentre davantage sur les documents XML et offre des fonctionnalités avancées, tandis que les sélecteurs CSS fonctionnent très bien sur les pages HTML et sont plus simples.
Lorsque vous utilisez des expressions XPath et des sélecteurs CSS dans le Scraping web, le véritable problème est d’être bloqué par les technologies anti-bot. Quelle que soit la stratégie de sélection de nœuds que vous adoptez, ces systèmes peuvent détecter et bloquer votre script de scraping automatisé. Heureusement, Bright Data vous propose plusieurs solutions de premier ordre :
- API Web Scraper: API faciles à utiliser pour accéder de manière programmatique à des données web structurées provenant de dizaines de domaines populaires.
- Navigateur de scraping: un navigateur contrôlable basé sur le cloud qui offre des capacités de rendu JavaScript tout en gérant les CAPTCHA, les empreintes digitales du navigateur, les réessais automatisés, etc. Il s’intègre aux bibliothèques de navigateurs d’automatisation les plus populaires, telles que Playwright et Puppeteer.
- Web Unlocker: une API de déverrouillage qui peut renvoyer de manière transparente le code HTML brut de n’importe quelle page, contournant ainsi toutes les mesures anti-scraping.
Vous ne voulez pas vous occuper du Scraping web, mais vous êtes toujours intéressé par les données en ligne ? Découvrez nos jeux de données prêts à l’emploi !



