
Avec la croissance exponentielle continue de l’économie numérique, il est plus important que jamais de collecter les bonnes données à partir de diverses sources, telles que des API, des sites web et des bases de données.
L’un des moyens les plus courants d’extraire des données est le web scraping. Cette technique consiste à utiliser des outils automatisés pour récupérer l’intégralité des pages d’un site web pour en analyser le contenu afin d’en extraire des informations spécifiques en vue d’une analyse et d’une utilisation ultérieures. Les études de marché, la surveillance des prix et l’agrégation de données font partie des cas d’utilisation courants.
La mise en œuvre d’un processus de web scraping implique la gestion du contenu dynamique, la gestion des sessions et des cookies, le traitement des mesures anti-scraping et la garantie de la conformité à la législation. Ces défis requièrent des outils et des techniques avancés pour extraire efficacement les données. ChatGPT peut vous aider à résoudre ces problèmes complexes en tirant parti de ses capacités de traitement du langage naturel pour générer du code et résoudre les erreurs.
Dans cet article, vous allez apprendre comment utiliser ChatGPT pour générer du code de scraping pour des sites web contenant principalement du code HTML statique, mais aussi pour des sites web plus complexes qui utilisent des techniques de génération de pages.
Prérequis
Avant de commencer ce tutoriel, vous devez avoir :
- Une bonne connaissance de Python
- Un environnement Python installé et configuré sur votre machine à l’aide de Visual Studio Code
- Un compte ChatGPT
Lorsque vous utilisez ChatGPT pour générer vos scripts de web scraping, il y a deux étapes principales :
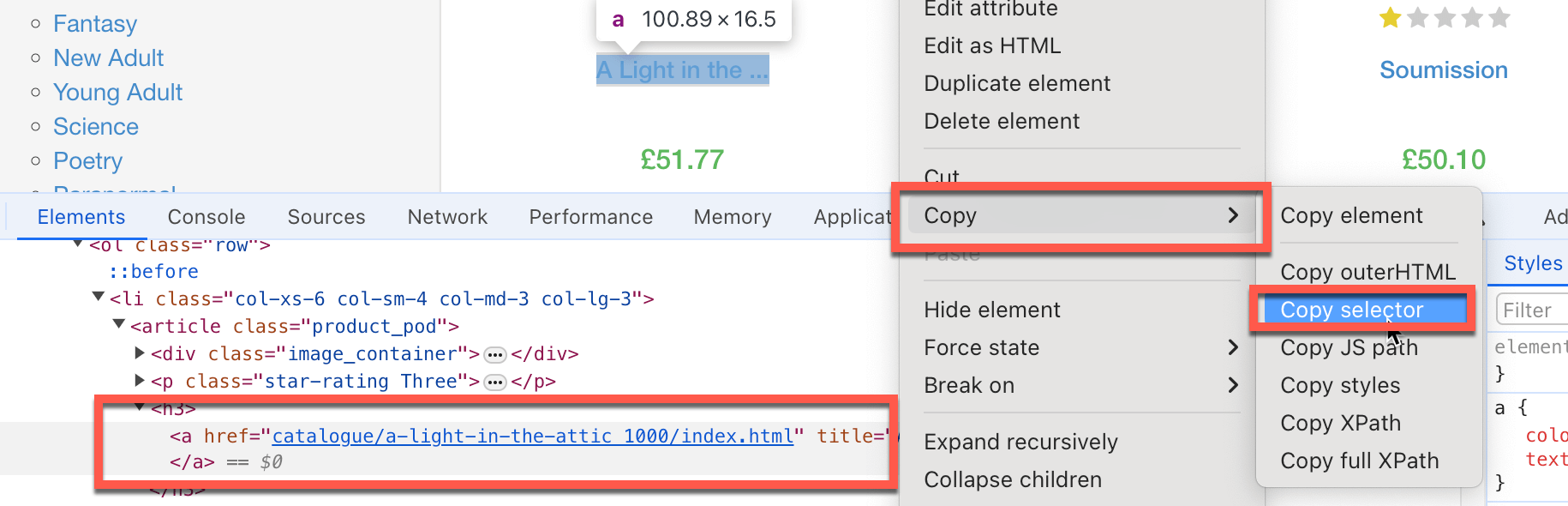
- Documenter chaque étape que le code doit suivre pour trouver l’information à récupérer, comme les éléments HTML à cibler, les zones de texte à remplir et les boutons à cliquer. Souvent, vous devrez copier le sélecteur d’élément HTML spécifique. Pour ce faire, cliquez avec le bouton droit de la souris sur l’élément particulier de la page que vous souhaitez récupérer, puis cliquez sur Inspecter. Chrome mettra en évidence l’élément DOM cible. Cliquez avec le bouton droit de la souris et choisissez Copier > Copier le sélecteur pour que le chemin du sélecteur HTML soit copié dans votre presse-papiers :
- Rédiger des invites ChatGPT spécifiques et détaillées pour générer le code de scraping.
- Exécuter et tester le code généré.
Récupérer des sites web avec du code HTML statique à l’aide de ChatGPT
Maintenant que vous maîtriser le flux de travail général, utilisons ChatGPT pour récupérer des sites web composé d’éléments HTML statiques. Pour commencer, vous allez récupérer le titre et le prix d’un livre sur https://books.toscrape.com.
Dans un premier temps, vous devez identifier les éléments HTML qui contiennent les données dont vous avez besoin :
- Le pour le titre du livre est
#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > h3 > a. - Le sélecteur pour le prix du livre est *
#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.product_price > p.price_color.
Ensuite, vous devez créer des invites ChatGPT spécifiques et détaillées pour générer le code de scraping. Pour ce faire, vous devez demander à ChatGPT d’installer les paquets Python nécessaires, le guider dans l’extraction des sélecteurs HTML (que vous avez identifiés plus tôt), et lui demander de sauvegarder les données dans un fichier Excel.
N’oubliez pas de définir la version de ChatGPT : « GPT-4o ».
Vous pouvez saisir quelque chose comme ceci dans ChatGPT :
Tu es un expert en web scraping utilisant la bibliothèque Python Beautiful Soup et tous les outils d’automatisation nécessaires. Je veux que tu génères un script détaillé, étape par étape, afin de scraper
https://books.toscrape.com. Fais ce qui suit :
- Installe tous les paquets Python nécessaires.
- Extraire le titre du livre ayant le sélecteur HTML
#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > h3 > a, et le prix du livre (seulement le nombre, rien d’autre) ayant le sélecteur#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.product_price > p.price_color.- Extraire la liste de tous les titres et prix des livres et la stocker dans un fichier Excel.
- Scrape uniquement la première page.
Remarque : il se peut que vous receviez une réponse légèrement différente.
Dans la réponse, ChatGPT vous demande d’exécuter la commande suivante pour installer la bibliothèque Beautiful Soup, qui effectue du web scraping, et la bibliothèque pandas, une bibliothèque d’analyse de données complète qui stocke les données dans un fichier Excel :
pip3 install requests beautifulsoup4 pandas openpyxl
Vous remarquerez que ChatGPT suggère également d’installer openpyxl, mais ce n’est pas nécessaire ici.
ChatGPT fournit également le code de scraping web suivant :
import requests
from bs4 import BeautifulSoup
import pandas as pd
# URL of the website
url = 'https://books.toscrape.com'
# Send a GET request to the website
response = requests.get(url)
if response.status_code == 200:
# Parse the HTML content of the page
soup = BeautifulSoup(response.content, 'html.parser')
# Initialize lists to store the titles and prices
book_titles = []
book_prices = []
# Extract the first book title and price using the provided selectors
book_title_selector = "#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > h3 > a"
book_price_selector = "#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.product_price > p.price_color"
title_element = soup.select_one(book_title_selector)
price_element = soup.select_one(book_price_selector)
if title_element and price_element:
book_titles.append(title_element.get('title'))
book_prices.append(price_element.text.strip()[1:])
# Extract all book titles and prices on the first page
books = soup.select('section > div:nth-child(2) > ol > li')
for book in books:
title = book.select_one('h3 > a')
price = book.select_one('div.product_price > p.price_color')
if title and price:
book_titles.append(title.get('title'))
book_prices.append(price.text.strip()[1:])
# Create a DataFrame from the lists
df = pd.DataFrame({
'Title': book_titles,
'Price': book_prices
})
# Save the DataFrame to an Excel file
df.to_excel('books_scraped.xlsx', index=False)
print('Data has been successfully scraped and saved to books_scraped.xlsx')
else:
print('Failed to retrieve the webpage')
Ce code importe le module requests qui effectue des appels HTTP au site web qu’il scrape. Il importe également les paquets pandas qui stockent les données scrapées dans des fichiers Excel. Le code définit l’URL de base du site web et les sélecteurs HTML spécifiques ciblés pour récupérer les données demandées.
Ensuite, le code appelle le site web et place le contenu du site sous la forme d’un objet BeautifulSoup appelé « soup ». Le code extrait les valeurs du titre et du prix du livre sous forme de listes de l’objet « soup » à l’aide des sélecteurs HTML. Enfin, le code crée un DataFrame « pandas » à partir du titre du livre et de la liste de prix et l’enregistre dans un fichier Excel.
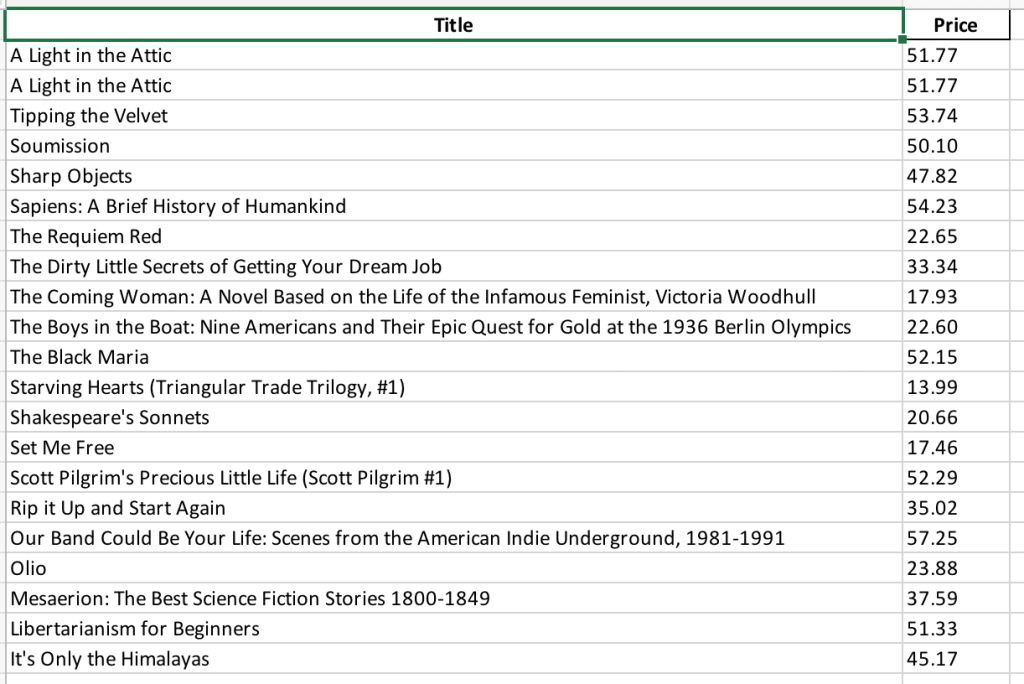
Ensuite, vous devez enregistrer le code dans un fichier nommé « books_scraping.py » et exécuter la commande « python3 books_scraping.py » à partir de la ligne de commande. Ce code génère un fichier Excel nommé « books_scraped.xlsx » dans le même répertoire que « books_scraping.py » :
Maintenant que vous avez parcouru cet exemple, poussons ce tutoriel un peu plus loin et scrapons un autre site web simple : https://quotes.toscrape.com, qui contient une collection de citations.
Commençons par identifier la séquence des étapes.
Si vous utilisez Chrome, identifiez les sélecteurs HTML suivants :
body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.textpour récupérer la citationbody > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > smallpour identifier l’auteur
Après avoir identifié les sélecteurs HTML que vous souhaitez récupérer, vous pouvez rédiger une invite détaillée, comme la suivante, pour générer le code de récupération :
Tu es un expert en scraping web utilisant la bibliothèque Beautiful Soup de Python et tous les outils d’automatisation nécessaires. Je veux que tu génères un script détaillé, étape par étape, afin d’explorer le site
https://quotes.toscrape.com. Fais ce qui suit :
- Installe tous les paquets Python nécessaires.
- Extraie la citation qui possède le sélecteur HTML
body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.textet le nom de l’auteur qui a le sélecteurbody > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > small.- Extraie la liste de toutes les citations et de tous les auteurs et stocke-la dans un fichier Excel.
- Scrape uniquement la première page.
Après avoir saisi ces informations, ChatGPT devrait vous fournir la commande qui suit. Celle-ci installe les bibliothèques Beautiful Soup, pandas et openpyxl :
pip3 install requests beautifulsoup4 pandas openpyxl
ChatGPT devrait également vous fournir le code de scraping web suivant :
import requests
from bs4 import BeautifulSoup
import pandas as pd
# Step 1: Fetch the web page content
url = "https://quotes.toscrape.com"
response = requests.get(url)
html_content = response.text
# Step 2: Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
# Step 3: Extract the specific quote and author
quote_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.text"
author_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > small"
specific_quote = soup.select_one(quote_selector).get_text()
specific_author = soup.select_one(author_selector).get_text()
print(f"Specific Quote: {specific_quote}")
print(f"Specific Author: {specific_author}")
# Step 4: Extract all quotes and authors
quotes = soup.find_all('div', class_='quote')
all_quotes = []
for quote in quotes:
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
all_quotes.append({"quote": text, "author": author})
# Step 5: Save the quotes to an Excel file
df = pd.DataFrame(all_quotes)
df.to_excel('quotes.xlsx', index=False)
print("Quotes have been saved to quotes.xlsx")
soup = BeautifulSoup(html_content, 'html.parser')
# Step 3: Extract the specific quote and author
quote_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.text"
author_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > small"
specific_quote = soup.select_one(quote_selector).get_text()
specific_author = soup.select_one(author_selector).get_text()
print(f"Specific Quote: {specific_quote}")
print(f"Specific Author: {specific_author}")
# Step 4: Extract all quotes and authors
quotes = soup.find_all('div', class_='quote')
all_quotes = []
for quote in quotes:
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
all_quotes.append({"quote": text, "author": author})
# Step 5: Save the quotes to an Excel file
df = pd.DataFrame(all_quotes)
df.to_excel('quotes.xlsx', index=False)
print("Quotes have been saved to quotes.xlsx")
Enregistrez ce code dans un fichier nommé « quotes_scraping.py » et exécutez la commande « python3 books_scraping.py » à partir de la ligne de commande. Ce code génère un fichier Excel nommé « quotes_scraped.xlsx » dans le même répertoire que « quotes_scraping.py ». Ouvrez le fichier Excel généré, il devrait ressembler à ceci :

Récupération de sites web complexes
Le scraping de sites web complexes peut s’avérer difficile, car le contenu dynamique est souvent chargé via JavaScript, ce que des outils comme requests et BeautifulSoup ne peuvent pas gérer. Ces sites peuvent nécessiter des interactions telles que cliquer sur des boutons ou faire défiler la page pour accéder à toutes les données. Pour relever ce défi, vous pouvez utiliser WebDriver, qui rend les pages comme un navigateur et simule les interactions de l’utilisateur, en veillant à ce que tout le contenu soit accessible comme il le serait pour un utilisateur ordinaire.
Par exemple, Yelp est un site web d’évaluation d’entreprises par leurs clients. Yelp s’appuie sur la génération dynamique de pages et doit simuler plusieurs interactions avec l’utilisateur. Ici, vous utiliserez ChatGPT pour générer un code de scraping qui récupère une liste d’entreprises à Stockholm et leurs évaluations.
Pour scraper Yelp, commençons par documenter les étapes à suivre :
- Trouve le sélecteur de la zone de texte de l’emplacement que le script utilisera ; dans ce cas, il s’agit de
#search_location. Écris « Stockholm » dans la zone de recherche de l’emplacement, puis trouve le sélecteur du bouton de recherche ; dans ce cas, il s’agit de#header_find_form > div.y-css-1iy1dwt > button. Clique sur le bouton de recherche pour afficher les résultats de la recherche. Cela peut prendre quelques secondes. Trouve un sélecteur qui contient le nom de l’entreprise :#main-content > ul > li:nth-child(3) > div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(1) > div > div > h3 > a) :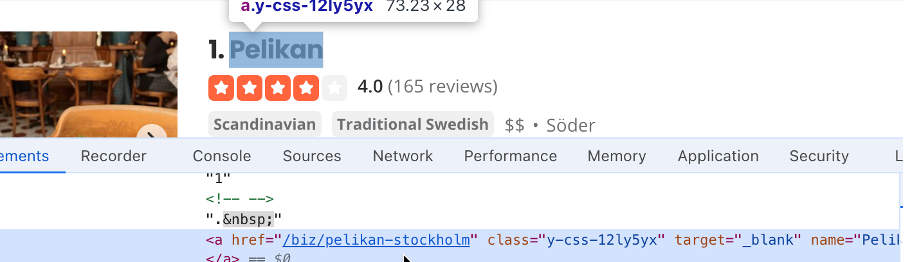
- Trouve le sélecteur qui contient la note de l’entreprise (
#main-content > ul > li:nth-child(3) > div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(2) > div > div > div > div.y-css-ohs7lg > span.y-css-jf9frv) :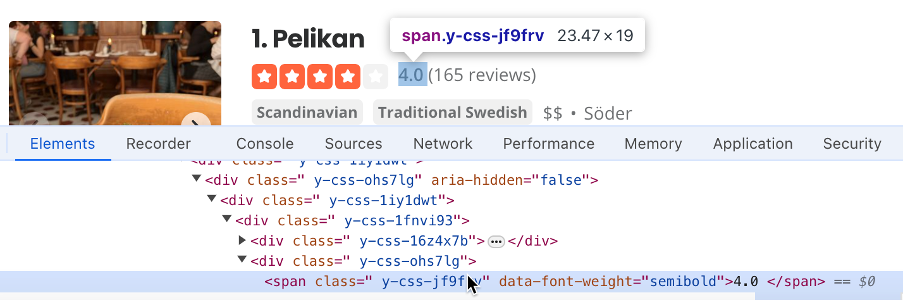
- Trouve le sélecteur du bouton Open Now ; ici, c’est
#main-content > div.stickyFilterOnSmallScreen__09f24__UWWJ3.hideFilterOnLargeScreen__09f24__ilqIP.y-css-9ze9ku > div > div > div > div > div > span > button:nth-child(3) > span: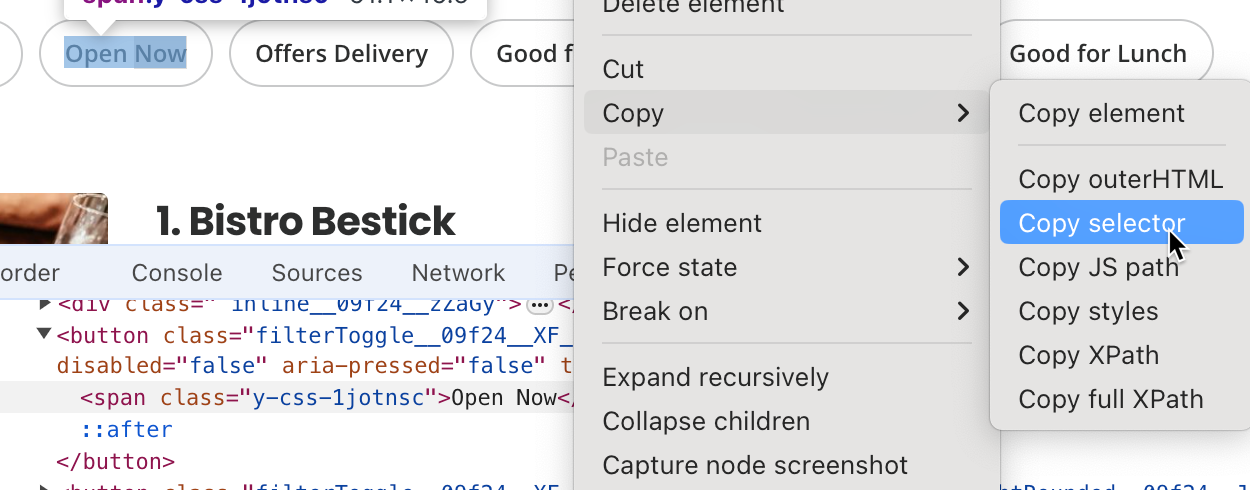
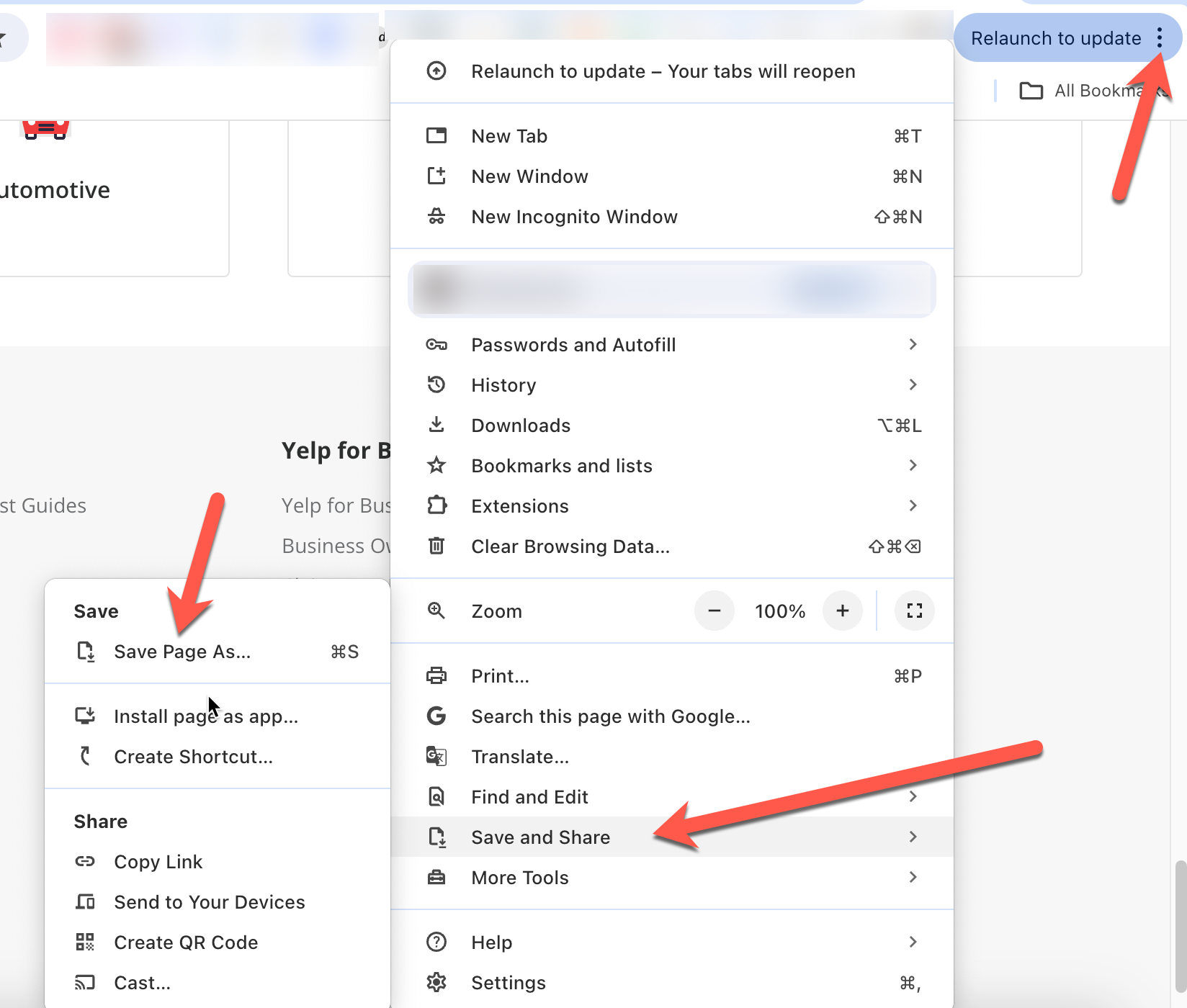
- Sauvegarde une copie de la page web afin de pouvoir l’envoyer plus tard, avec l’invite ChatGPT pour aider ChatGPT à comprendre le contexte des invites. Dans Chrome, vous pouvez le faire en cliquant sur les trois points en haut à droite, puis en cliquant sur Enregistrer et partager > Enregistrer la page sous :
Ensuite, en utilisant les valeurs du sélecteur que vous avez extraites plus tôt, vous devez rédiger une invite détaillée pour guider ChatGPT dans la génération du script de scraping :
Tu es un expert en web scraping. Je veux que tu scrapes le site https://www.yelp.com/ pour extraire des informations spécifiques. Suis les étapes suivantes avant de procéder au scraping :
- Efface la boîte ayant le sélecteur
#search_location.- Écris « Stockholm » dans la boîte de recherche ayant le sélecteur
#search_location.- Clique sur le bouton ayant le sélecteur
#header_find_form > div.y-css-1iy1dwt > button.- Attends quelques secondes que la page charge les résultats de la recherche.
- Clique sur le bouton Open Now, dont le sélecteur est
#main-content > div.stickyFilterOnSmallScreen__09f24__UWWJ3.hideFilterOnLargeScreen__09f24__ilqIP.y-css-9ze9ku > div > div > div > div > div > span > button:nth-child(3) > span, pour filtrer les entreprises qui sont ouvertes maintenant.- Crée une liste avec les noms des entreprises ; le sélecteur du nom de l’entreprise est
#main-content > ul > li:nth-child(3) > div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(1) > div > div > h3 > a.- Crée une liste des avis sur les entreprises ; les avis ont le sélecteur
#main-content > ul > li:nth-child(3) > div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(2) > div > div > div > div.y-css-ohs7lg > span.y-css-jf9frv.- Crée un fichier Excel contenant les noms des entreprises et leurs évaluations.
- Installe tous les paquets Python nécessaires.
- Utilise webDriver de Selenium pour automatiser le processus.
- Tu peux consulter la copie ci-jointe de la page HTML des résultats pour avoir une idée du format HTML.
Après avoir saisi ces informations, ChatGPT vous demande d’installer Selenium, le framework d’automatisation web qui supporte webDriver, et pandas :
pip3 install selenium pandas
ChatGPT vous fournit également un code de scraping accompagné d’une explication :
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import pandas as pd
import time
# Initialize the WebDriver
driver = webdriver.Chrome()
try:
# Open Yelp
driver.get('https://www.yelp.com/')
# Clear the location search box
location_box = driver.find_element(By.CSS_SELECTOR, '#search_location')
location_box.clear()
# Enter "Stockholm" in the location search box
location_box.send_keys('Stockholm')
# Click the search button
search_button = driver.find_element(By.CSS_SELECTOR, '#header_find_form > div.y-css-1iy1dwt > button')
search_button.click()
# Wait for search results to load
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#main-content'))
)
# Click on "Open Now" filter
open_now_button = driver.find_element(By.CSS_SELECTOR, '#main-content > div.stickyFilterOnSmallScreen__09f24__UWWJ3.hideFilterOnLargeScreen__09f24__ilqIP.y-css-9ze9ku > div > div > div > div > div > span > button:nth-child(3) > span')
open_now_button.click()
# Wait for the filter results to load
time.sleep(5)
# Extract business names and reviews
business_names = []
business_reviews = []
businesses = driver.find_elements(By.CSS_SELECTOR, '#main-content > ul > li')
for business in businesses:
try:
name = business.find_element(By.CSS_SELECTOR, 'div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(1) > div > div > h3 > a').text
review = business.find_element(By.CSS_SELECTOR, 'div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(2) > div > div > div > div.y-css-ohs7lg > span.y-css-jf9frv').text
business_names.append(name)
business_reviews.append(review)
except Exception as e:
print(f"Error extracting data for a business: {e}")
# Create a DataFrame and save to Excel
df = pd.DataFrame({'Business Name': business_names, 'Reviews': business_reviews})
df.to_excel('stockholm_businesses.xlsx', index=False)
print("Data saved to stockholm_businesses.xlsx")
finally:
# Close the WebDriver
driver.quit()
Enregistrez ce script et exécutez-le en utilisant Python dans Visual Studio Code. Vous remarquerez que le code lance Chrome, ouvre le site web de Yelp, efface la zone de texte de l’emplacement, écrit « Stockholm », clique sur le bouton de recherche, filtre les entreprises qui sont ouvertes maintenant, puis ferme la page. Le résultat de la recherche est ensuite enregistré dans le fichier Excel « stockholm_bussinsess.xlsx » :

Tout le code source de ce tutoriel est disponible sur GitHub.
Conclusion
Dans ce tutoriel, vous avez appris à utiliser ChatGPT pour extraire des informations spécifiques de sites web avec un rendu HTML statique et de sites web plus complexes avec une génération de pages dynamiques, des liens JavaScript externes et des interactions avec l’utilisateur.
Alors que l’extraction d’un site web comme Yelp était simple, en réalité, l’extraction de structures HTML complexes peut s’avérer difficile, et vous serez probablement confronté à des blocages de votre adresse IP et à des CAPTCHA.
Pour vous faciliter la tâche, Bright Datapropose un large éventail de services de collecte de données, notamment des services de proxy avancés pour aider à contourner les blocages d’adresse IP, Web Unlocker, afin de contourner et résoudre les CAPTCHA, l’API Web Scraping pour l’extraction automatisée de données, et le navigateur Scraping Browser pour une extraction efficace des données.
Inscrivez-vous dès maintenant et découvrez tous les produits de Bright Data. Commencez par un essai gratuit dès aujourd’hui !



