

Dans ce guide, vous apprendrez
- Tout ce que vous devez savoir pour vous lancer dans le Scraping web de Baidu.
- Les approches les plus populaires et les plus efficaces pour gratter Baidu.
- Comment construire un Scraper Baidu personnalisé à partir de zéro en Python.
- Comment récupérer les résultats des moteurs de recherche à l’aide de l’API SERP de Bright Data.
- Comment donner à vos agents IA l’accès aux données de recherche de Baidu via le MCP Web.
Plongeons dans le vif du sujet !
Se familiariser avec le SERP de Baidu
Avant toute chose, prenez le temps de comprendre la structure de la SERP (page de résultats des moteurs de recherche) de Baidu, les données qu’elle contient, la manière d’y accéder, etc.
URL de la SERP de Baidu et système de détection des robots
Ouvrez Baidu dans votre navigateur et commencez à effectuer des recherches. Par exemple, recherchez “bright data”. Vous devriez obtenir une URL comme celle-ci :
https://www.baidu.com/s ?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=bright%20data&fenlei=256&oq=ai%2520model&rsv_pq=970a74b9001542b3&rsv_t=7f84gPOmZQIjrqRcld6qZUI%2FiqXxDExphd0Tz5ialqM87sc5Falk%2B%2F3hxDs&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=12&rsv_sug1=1&rsv_sug7=100&rsv_btype=t&inputT=1359&rsv_sug4=1358Parmi tous ces paramètres de requête, les plus importants sont les suivants :
- URL de base
: https://www.baidu.com/s. - Paramètre de recherche:
wd.
En d’autres termes, vous pouvez obtenir les mêmes résultats avec une URL plus courte :
https://www.baidu.com/s?wd=bright%20dataBaidu structure également ses URL pour la pagination via le paramètre de requête pn. En détail, la deuxième page ajoute &pn=10, puis chaque page suivante incrémente cette valeur de 10. Par exemple, si vous souhaitez récupérer 3 pages avec le mot-clé “bright data”, les URL de votre SERP seront les suivantes :
https://www.baidu.com/s?wd=bright%20data -> page 1
https://www.baidu.com/s?wd=bright%20data&pn=10 -> page 2
https://www.baidu.com/s?wd=bright%20data&pn=20 -> page 3Si vous essayez d’accéder directement à une telle URL à l’aide d’une simple requête GET HTTP dans un client HTTP tel que Postman, vous obtiendrez probablement quelque chose comme ceci :
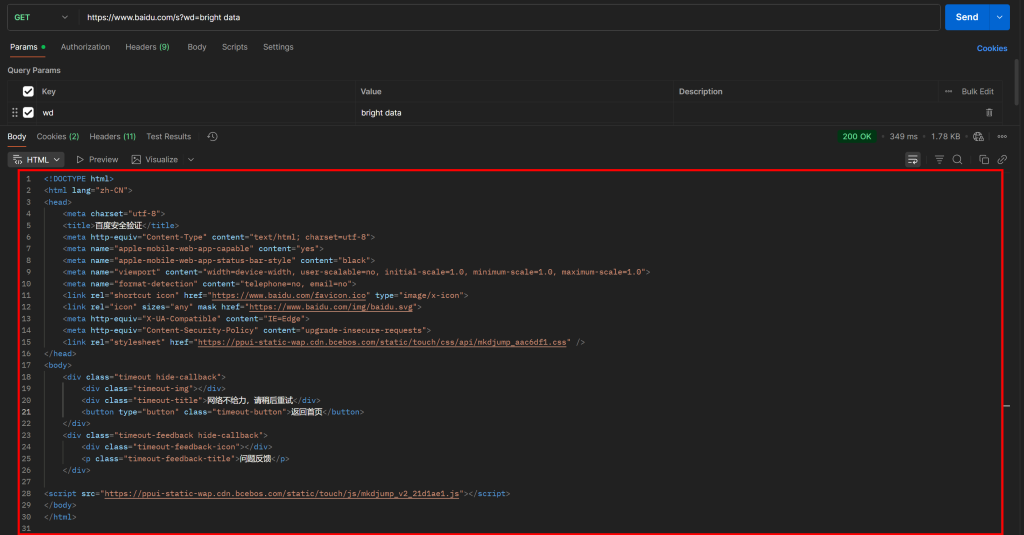
Comme vous pouvez le constater, Baidu renvoie une page avec le message “网络不给力,请稍后重试” (qui se traduit par “Le réseau ne fonctionne pas bien, veuillez réessayer plus tard”, mais qui est en fait une page anti-bot).
Cela se produit même si vous incluez un en-tête User-Agent, qui est normalement essentiel pour les tâches de Scraping web. En d’autres termes, Baidu détecte que votre demande est automatisée et la bloque, exigeant une vérification humaine supplémentaire.
Cela montre clairement que pour scraper Baidu, vous avez besoin d’un outil d’automatisation du navigateur (tel que Playwright ou Puppeteer). Une simple combinaison d’un client HTTP et d’un analyseur HTML ne suffira pas, car elle déclenchera systématiquement des blocages anti-bots.
Données disponibles dans une SERP Baidu
Concentrez-vous à présent sur le SERP Baidu pour “bright data” affiché dans votre navigateur. Vous devriez voir quelque chose comme ceci :
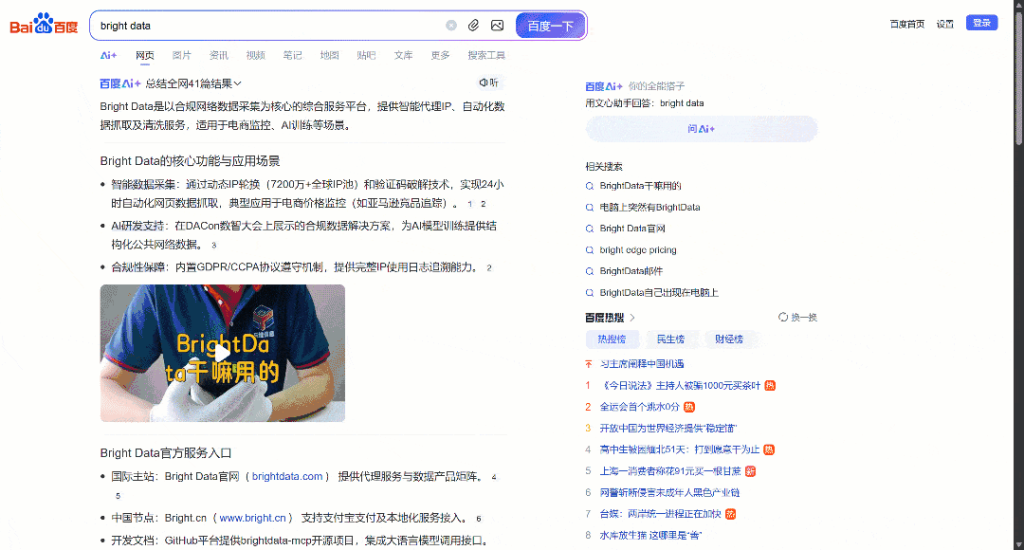
Chaque page du SERP de Baidu est divisée en deux colonnes. La colonne de gauche contient un aperçu de l’IA (voir comment gratter les aperçus de l’IA), suivi des résultats de la recherche. Au bas de cette colonne, on trouve la section “相关搜索” (“Recherches connexes”) et, en dessous, les éléments de navigation de la pagination.
La colonne de droite contient “百度热搜” (“Baidu Hot Searches”), qui présente les sujets les plus populaires sur Baidu.(Remarque: ces résultats ne sont pas nécessairement liés à vos termes de recherche).
Cela couvre toutes les données principales que vous pouvez extraire d’un SERP de Baidu. Dans ce tutoriel, nous nous concentrerons uniquement sur les résultats de recherche, qui sont généralement les informations les plus importantes !
Principales approches pour récupérer Baidu
Il existe plusieurs façons d’obtenir des données sur les résultats de recherche de Baidu. Comparez les principales d’entre elles dans le tableau récapitulatif ci-dessous :
| Approche | Intégration Complexité | Exigences | Prix | Risque lié aux blocs | Évolutivité |
|---|---|---|---|---|---|
| Construire un Scraper personnalisé | Moyen/élevé | Compétences en programmation Python + compétences en automatisation des navigateurs | Gratuit (peut nécessiter des navigateurs anti-bots pour éviter les blocages) | Possible | Limité |
| Utiliser l’API SERP de Bright Data | Faible | N’importe quel client HTTP | Payé | Aucun | Illimité |
| Intégrer le serveur Web MCP | Faible | Cadre ou plateforme d’agent IA prenant en charge MCP | Niveau gratuit disponible, puis payant | Aucun | Illimité |
Vous apprendrez à mettre en œuvre chaque approche au fur et à mesure que vous suivrez le didacticiel !
Note 1: Quelle que soit la méthode choisie, la requête de recherche cible utilisée tout au long de ce guide sera “bright data”. Cela signifie que vous verrez comment récupérer les résultats de recherche de Baidu spécifiquement pour cette requête.
Note 2: Nous supposons que Python est déjà installé localement et que vous êtes familiarisé avec les scripts web Python.
Approche n° 1 : Créer un Scraper personnalisé
Utilisez un cadre d’automatisation de navigateur ou un client HTTP combiné à un analyseur HTML pour construire un Scraper Baidu à partir de zéro.
👍 Avantages:
- Contrôle total sur la logique d’analyse des données, avec la possibilité d’extraire exactement ce dont vous avez besoin.
- Flexible et personnalisable en fonction de vos besoins.
👎 Inconvénients:
- Nécessite un effort de configuration, de codage et de maintenance.
- Peut être confronté à des blocages d’IP, des CAPTCHA, des limites de taux et d’autres défis de scraping web lors de son exécution à l’échelle.
Approche n°2 : utiliser l’API SERP de Bright Data
Exploitez l’API SERP de Bright Data, une solution haut de gamme qui vous permet d’interroger Baidu (et d’autres moteurs de recherche) via un point d’extrémité HTTP facile à appeler. Elle gère pour vous toutes les mesures anti-bots et la mise à l’échelle. Ces caractéristiques et bien d’autres en font l’une des meilleures API SERP et de recherche sur le marché.
👍 Avantages:
- Hautement évolutif et fiable, soutenu par un réseau de Proxy de 400M+ IP.
- Pas de bannissement d’IP ni de problèmes de CAPTCHA.
- Fonctionne avec n’importe quel client HTTP (y compris des outils visuels comme Postman ou Insomnia).
👎 Inconvénients:
- Service payant.
Approche n° 3 : intégrer le serveur Web MCP
Permettez à votre agent IA d’accéder gratuitement aux résultats de recherche de Baidu grâce au Web MCP de Bright Data, qui se connecte à l’API SERP et au Web Unlocker de Bright Data sous le capot.
👍 Avantages:
- Intégration dans les flux de travail et les agents de l’IA.
- Niveau gratuit disponible.
- Aucune logique d’analyse des données n’est requise (l’IA s’en charge).
👎 Inconvénients:
- Contrôle limité sur le comportement des LLM.
Approche #1 : Construire un Baidu Scraper personnalisé en Python à l’aide de Playwright
Suivez les étapes ci-dessous pour créer un script de scraping web Baidu personnalisé en Python.
Comme indiqué précédemment, le Navigateur de scraping de Baidu nécessite l’automatisation du navigateur car les requêtes HTTP simples seront bloquées. Dans cette section du tutoriel, nous utiliserons Playwright, l’une des meilleures bibliothèques pour l’automatisation du navigateur en Python.
Etape #1 : Configurer votre projet de scraping
Commencez par ouvrir votre terminal et créez un nouveau dossier pour votre projet Baidu scraper :
mkdir baidu-scraperLe dossier baidu-scraper/ contiendra tous les fichiers de votre projet de scraping.
Ensuite, naviguez dans le répertoire du projet et créez un environnement virtuel Python à l’intérieur de celui-ci :
cd baidu-scraper
python -m venv .venvOuvrez ensuite le dossier du projet dans votre IDE Python préféré. Nous recommandons Visual Studio Code avec l’extension Python ou PyCharm Community Edition.
Ajoutez un nouveau fichier nommé Scraper.py à la racine de votre répertoire de projet. La structure de votre projet devrait ressembler à ceci :
baidu-scraper/
├── .venv/
└── scraper.pyEnsuite, activez l’environnement virtuel dans le terminal. Sous Linux ou macOS, exécutez :
source .venv/bin/activateDe manière équivalente, sous Windows, exécutez :
.venv/Scripts/activateUne fois votre environnement virtuel activé, installez Playwright à l’aide de pip via le paquet playwright:
pip install playwrightEnsuite, installez les dépendances nécessaires à Playwright (par exemple, les binaires du navigateur) :
python -m playwright installVoilà, c’est fait ! Votre environnement Python est maintenant prêt à Commencer la construction de votre Scraper web Baidu.
Étape 2 : Initialiser le script Playwright
Dans scraper.py, importez Playwright et utilisez son API synchrone pour démarrer une instance de navigateur Chromium contrôlée :
from playwright.sync_api import sync_playwright
avec sync_playwright() as p :
# Initialiser une instance de Chromium en mode headless
browser = p.chromium.launch(headless=True) # mettre headless=False pour voir le navigateur pour le débogage
page = browser.new_page()
# Logique de scraping...
# Fermer le navigateur et libérer ses ressources
browser.close()L’extrait ci-dessus constitue la base de votre Scraper Baidu.
Le paramètre headless=True indique à Playwright de lancer Chromium sans interface graphique visible. D’après les tests effectués, ce paramètre ne déclenche pas la détection des robots de Baidu. Il fonctionne donc bien pour le scraping. Cependant, lors du développement ou du débogage de votre code, vous préférerez peut-être définir headless=False afin de pouvoir observer ce qui se passe dans le navigateur en temps réel.
Très bien ! Commencer à se connecter au SERP de Baidu et commencer à récupérer les résultats de recherche.
Étape 3 : Visiter le SERP cible
Comme nous l’avons analysé précédemment, la construction d’une URL de SERP Baidu est simple. Au lieu de demander à Playwright de simuler les interactions de l’utilisateur (comme taper dans le champ de recherche et le soumettre), il est beaucoup plus facile de construire l’URL SERP de manière programmatique et de demander à Playwright de naviguer directement jusqu’à elle.
Voici la logique de construction d’une URL de SERP Baidu pour le terme de recherche “bright data” :
# L'URL de base de la page de recherche Baidu
base_url = "https://www.baidu.com/s"
# Le mot-clé/phrase-clé de la recherche
search_query = "bright data"
params = {"wd" : search_query}
# Construire l'URL de la SERP de Baidu
url = f"{base_url}?{urlencode(params)}"N’oubliez pas d’importer la fonction urlencode() de la bibliothèque standard de Python :
from urllib.parse import urlencodeMaintenant, demandez au navigateur contrôlé par Playwright de visiter l’URL générée via goto():
page.goto(url)Si vous exécutez le script en mode headful (avec headless=False) dans le débogueur, vous verrez une fenêtre Chromium charger la page Baidu SERP :
Génial ! C’est exactement le SERP que vous allez scraper ensuite.
Étape 4 : Préparer le scraping de tous les résultats des SERP
Avant de plonger dans la logique du scraping, vous devez étudier la structure des SERP de Baidu. Tout d’abord, comme la page contient plusieurs éléments de résultats de recherche, vous aurez besoin d’une liste pour stocker les données extraites. Commencez donc par initialiser une liste vide :
serp_results = []Ensuite, ouvrez la SERP Baidu cible dans une fenêtre incognito (pour garantir une session propre) dans votre navigateur :
https://www.baidu.com/s?wd=bright%20dataFaites un clic droit sur l’un des éléments du résultat de la recherche et choisissez “Inspecter” pour ouvrir les DevTools du navigateur :
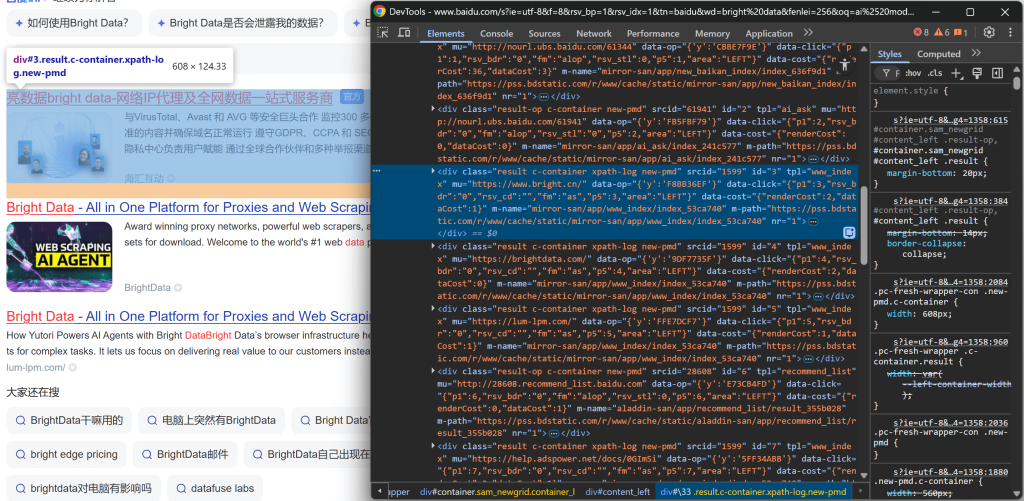
En observant la structure DOM, vous remarquerez que chaque élément de résultat de recherche possède la classe result. Cela signifie que vous pouvez sélectionner tous les résultats de la recherche sur la page à l’aide du sélecteur CSS .result.
Appliquez ce sélecteur dans votre script Playwright :
search_result_elements = page.locator(".result")Remarque: si cette syntaxe ne vous est pas familière, lisez notre guide sur le scraping web avec Playwright.
Enfin, itérer sur chaque élément sélectionné :
for search_result_element in search_result_elements.all() :
# Logique d'analyse des données...Préparez-vous à appliquer la logique d’Analyse des données pour extraire les résultats de la recherche Baidu et remplir la liste serp_results:
Parfait ! Vous êtes maintenant sur le point de terminer votre flux de travail de récupération de Baidu.
Étape 5 : Extraire les données des résultats de recherche
Inspectez la structure HTML d’un élément SERP sur la page de résultats de Baidu. Cette fois, concentrez-vous sur ses éléments imbriqués pour identifier les données que vous souhaitez extraire.
Commencez par explorer la section du titre :
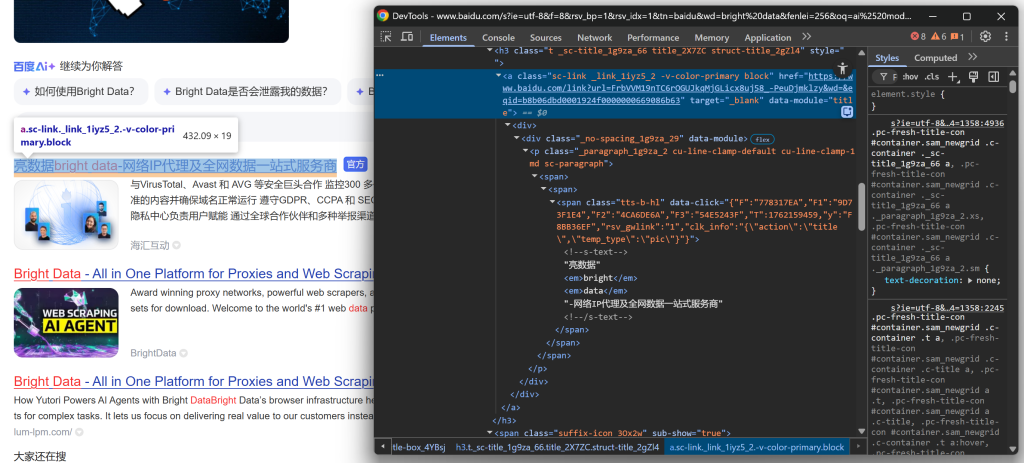
Continuez en remarquant que certains résultats affichent une étiquette “官方” (“Officiel”) :
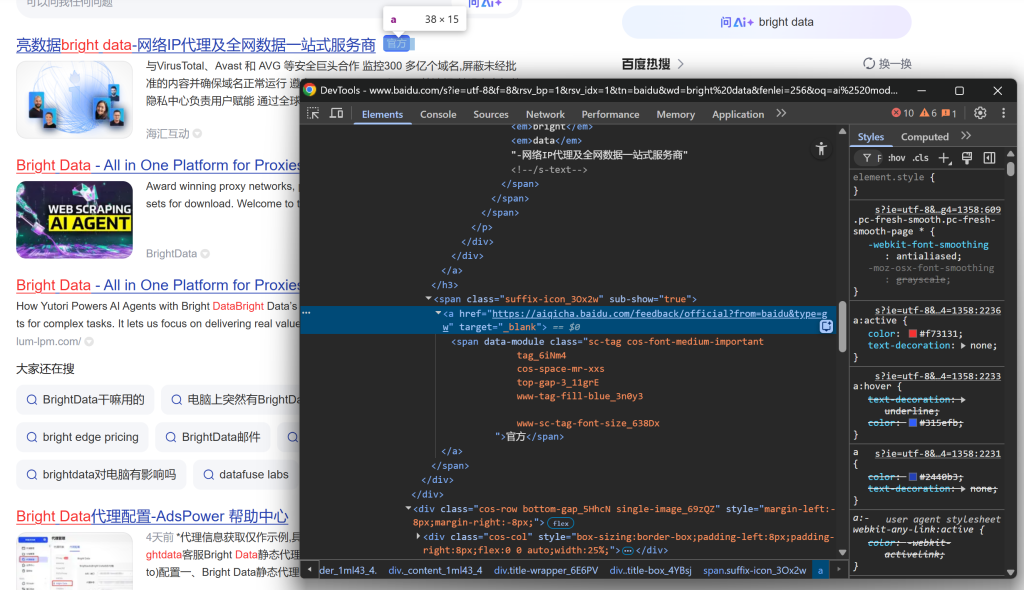
Puis concentrez-vous sur l’image des résultats de la SERP :
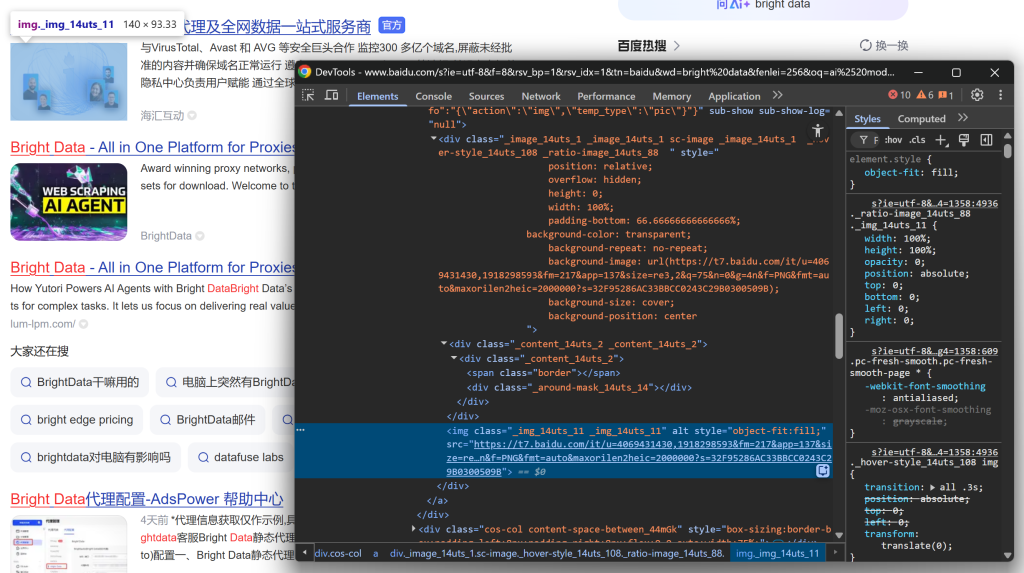
Et conclure en regardant la description/le résumé :
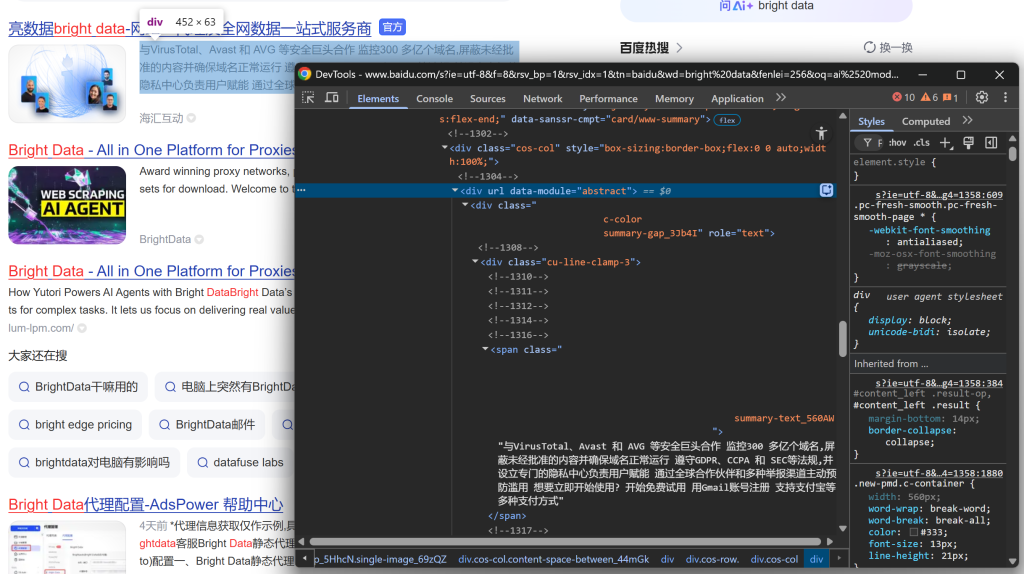
À partir de ces éléments imbriqués, vous pouvez extraire les données suivantes :
- L’URL durésultat à partir de l’attribut
hrefde l’élément.sc-link. - Titre du résultat à partir du texte de l’élément
.sc-link. - Description/résumé durésultat à partir du texte de l’
élément [data-module='abstract']. - L’image durésultat provient de l’attribut
srcde l’élément imgà l’intérieur de l’élément.sc-image. - Extrait durésultat à partir du texte
.result__snippet. - Étiquette officielle, dans un élément
<a>dont lehrefcommence parhttps://aiqicha.baidu.com/feedback/official(le cas échéant).
Utilisez l’API de localisation de Playwright pour sélectionner les éléments et extraire les données souhaitées :
link_element = search_result_element.locator(".sc-link")
link = link_element.get_attribute("href")
title = link_element.inner_text()
description_element = search_result_element.locator("[data-module='abstract']")
description = description_element.inner_text() if description_element.count() > 0 else ""
image_element = search_result_element.locator(".sc-image img")
image = image_element.get_attribute("src") if image_element.count() > 0 else None
official_element = search_result_element.locator("a[href^='https://aiqicha.baidu.com/feedback/official']")
official = official_element.count() > 0Gardez à l’esprit que tous les éléments des SERP ne sont pas identiques. Pour éviter les erreurs, vérifiez toujours que l’élément existe (.count() > 0) avant d’accéder à ses attributs ou à son texte.
Génial ! Vous venez de définir la logique d’Analyse des données SERP de Baidu.
Étape 6 : Collecte des données des résultats de recherche analysés
Terminez la boucle for en créant un dictionnaire pour chaque résultat de recherche et en l’ajoutant à la liste serp_results:
serp_result = {
"title" : title.strip(),
"href" : link.strip(),
"description" : description.strip(),
"image" : image.strip() if image else "",
"official" : officiel
}
serp_results.append(serp_result)C’est formidable ! Votre logique de Scraping web Baidu est maintenant terminée. La dernière étape consiste à exporter les données scrappées en vue d’une utilisation ultérieure.
Étape 7 : Exporter les résultats de la recherche au format CSV
À ce stade, vos résultats de recherche Baidu sont stockés dans une liste Python. Pour rendre les données utilisables par d’autres équipes ou outils, exportez-les vers un fichier CSV à l’aide de la bibliothèque csv intégrée à Python :
with open("baidu_serp_results.csv", mode="w", newline="", encoding="utf-8") as csvfile :
# Lecture dynamique des noms de champs à partir du premier élément
fieldnames = list(serp_results[0].keys())
# Initialiser le rédacteur CSV
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# Ecrire l'en-tête et remplir le fichier CSV de sortie
writer.writeheader()
writer.writerows(serp_results)N’oubliez pas d’importer csv :
import csvDe cette façon, votre Scraper Baidu générera un fichier de sortie nommé baidu_serp_results.csv, contenant tous les résultats scrappés au format CSV. Mission accomplie
Étape n° 8 : Assembler le tout
Le code final contenu dans scraper.py est le suivant :
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
from urllib.parse import urlencode
import csv
# Où stocker les données récupérées
serp_results = []
avec sync_playwright() as p :
# Initialiser une instance de Chromium en mode headless
browser = p.chromium.launch(headless=True) # mettre headless=False pour voir le navigateur pour le débogage
page = browser.new_page()
# L'URL de base de la page de recherche Baidu
base_url = "https://www.baidu.com/s"
# Le mot-clé/phrase-clé de la recherche
search_query = "bright data"
params = {"wd" : search_query}
# Construire l'URL de la SERP de Baidu
url = f"{base_url}?{urlencode(params)}"
# Visiter la page cible dans le navigateur
page.goto(url)
# Sélectionner tous les éléments du résultat de la recherche
search_result_elements = page.locator(".result")
for search_result_element in search_result_elements.all() :
# Logique d'Analyse des données
link_element = search_result_element.locator(".sc-link")
link = link_element.get_attribute("href")
title = link_element.inner_text()
description_element = search_result_element.locator("[data-module='abstract']")
description = description_element.inner_text() if description_element.count() > 0 else ""
image_element = search_result_element.locator(".sc-image img")
image = image_element.get_attribute("src") if image_element.count() > 0 else None
official_element = search_result_element.locator("a[href^='https://aiqicha.baidu.com/feedback/official']")
official = official_element.count() > 0
# Remplir un nouvel objet de résultat de recherche avec les données récupérées
serp_result = {
"title" : title.strip(),
"href" : link.strip(),
"description" : description.strip(),
"image" : image.strip() if image else "",
"official" : officiel
}
# Ajouter le résultat SERP de Baidu à la liste
serp_results.append(serp_result)
# Fermer le navigateur et libérer ses ressources
browser.close()
with open("baidu_serp_results.csv", mode="w", newline="", encoding="utf-8") as csvfile :
# Lecture dynamique des noms de champs à partir du premier élément
fieldnames = list(serp_results[0].keys())
# Initialiser le rédacteur CSV
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# Ecrire l'en-tête et remplir le fichier CSV de sortie
writer.writeheader()
writer.writerows(serp_results)Ouah ! En seulement 70 lignes de code, vous avez créé un script de récupération de données Baidu.
Testez le script avec :
python scraper.pyLe résultat sera un fichier baidu_serp_results.csv dans votre dossier projet. Ouvrez-le pour voir les données structurées extraites des résultats de recherche Baidu :

Remarque: pour extraire d’autres résultats, répétez le processus en utilisant le paramètre de requête pn pour gérer la pagination.
Et voilà ! Vous avez réussi à transformer des résultats de recherche Baidu non structurés en un fichier CSV structuré.
[Extra] Utiliser un service de navigation à distance pour éviter les blocages
Le Scraper présenté ci-dessus fonctionne bien pour les petites séries, mais il n’est pas évolutif. Trafic commencera à bloquer les requêtes lorsqu’il verra trop de trafic provenant de la même IP, renvoyant des pages d’erreur ou des défis. L’exécution de nombreuses instances locales de Chromium est également gourmande en ressources (beaucoup de RAM) et difficile à coordonner.
Une solution plus évolutive et plus facile à gérer consiste à connecter votre instance Playwright à une solution de Navigateur de scraping à distance, comme l’API Browser de Bright Data. Cette solution permet la rotation automatique des Proxy, la gestion des CAPTCHA et le contournement des robots, des instances de navigateur réelles pour éviter les problèmes d’empreintes digitales, et une mise à l’échelle illimitée.
Suivez le guide d’installation de l’API de navigateur de Bright Data, et vous obtiendrez une chaîne de connexion WSS qui ressemble à ceci :
wss://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:9222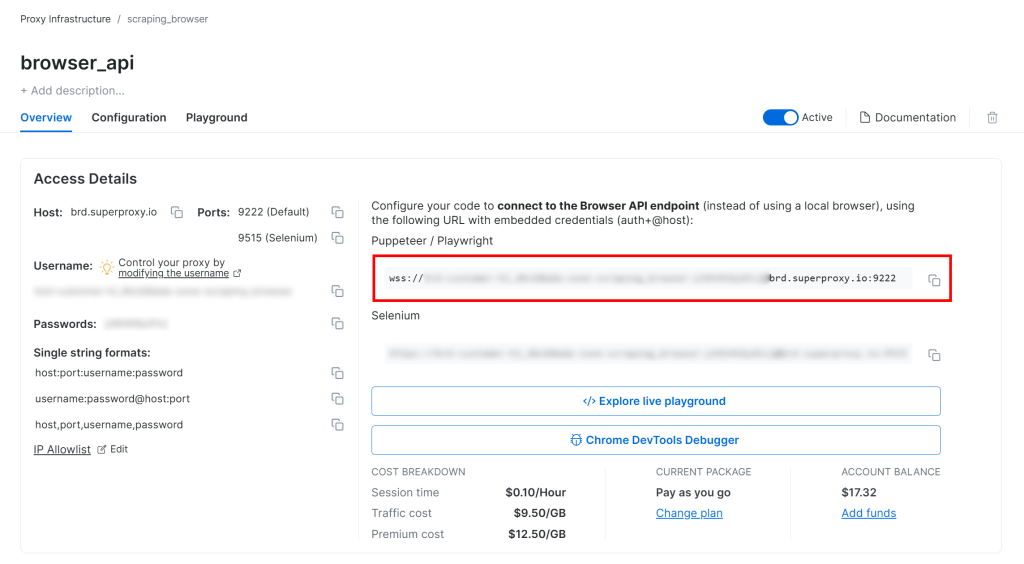
Utilisez cette URL WSS pour connecter Playwright aux instances de navigateur distantes via le CDP(Chrome DevTools Protocol) :
wss_url = "wss://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:9222"
browser = playwright.chromium.connect_over_cdp(wss_url)
page = browser.new_page()
# ...Désormais, vos demandes Playwright à Baidu seront acheminées via l’infrastructure distante Browser API de Bright Data, qui s’appuie sur un réseau Proxy résidentiel de 150 millions d’IP et sur de véritables instances de navigateur. Cela garantit une nouvelle IP pour chaque session et une empreinte réaliste du navigateur.
Approche n°2 : utilisation de l’API SERP de Bright Data
Dans ce chapitre, vous verrez comment utiliser l’API SERP Baidu tout-en-un de Bright Data pour récupérer les résultats de recherche de manière programmatique.
Remarque: par souci de simplicité, nous supposons que vous disposez déjà d’un projet Python avec la bibliothèquerequests installée.
Étape 1 : Configurer une Zone API SERP dans votre compte Bright Data
Commencez par configurer le produit API SERP dans Bright Data pour l’extraction des résultats de recherche de Baidu. Tout d’abord, créez un compte Bright Data ou connectez-vous si vous en avez déjà un.
Pour une configuration plus rapide, vous pouvez consulter le guide de démarrage rapide de l’API SERP de Bright Data. Sinon, suivez les étapes ci-dessous.
Une fois connecté, accédez à ” Proxy & Scraping ” dans votre compte Bright Data pour atteindre la page des produits :
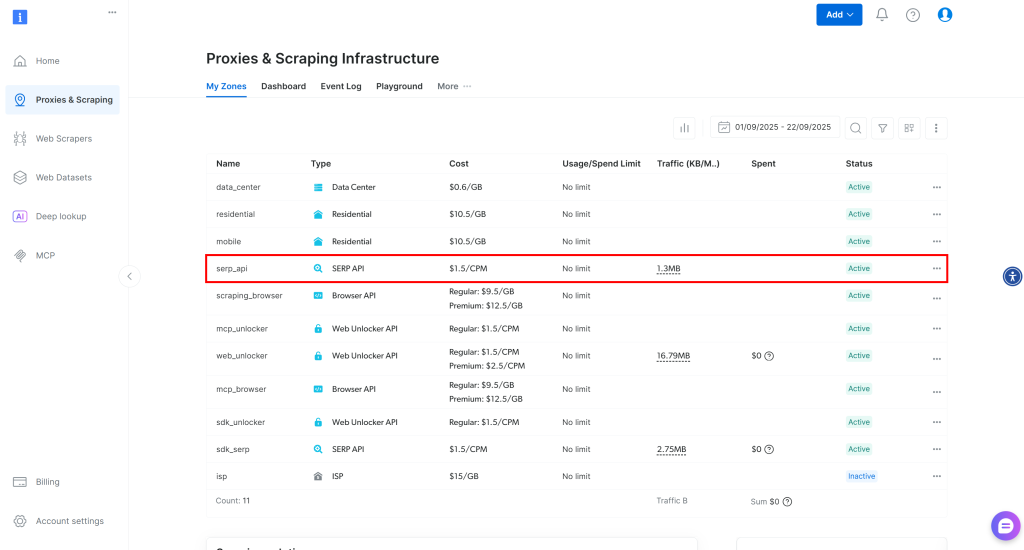
Jetez un œil au tableau “Mes zones”, qui répertorie vos produits Bright Data configurés. Si une zone API SERP active existe déjà, vous pouvez commencer. Copiez simplement le nom de la zone (par exemple, serp_api), car vous en aurez besoin plus tard.
Si aucune zone API SERP n’existe, faites défiler la page jusqu’à la section “Solutions de scraping” et cliquez sur “Créer une Zone” sur la carte “API SERP” :
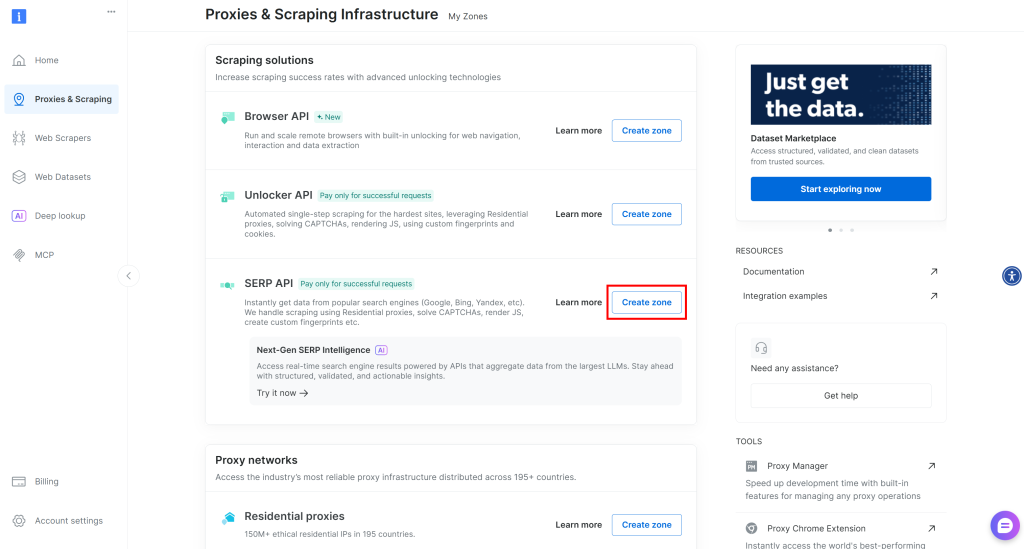
Donnez un nom à votre zone (par exemple, serp-api) et cliquez sur le bouton “Ajouter” :
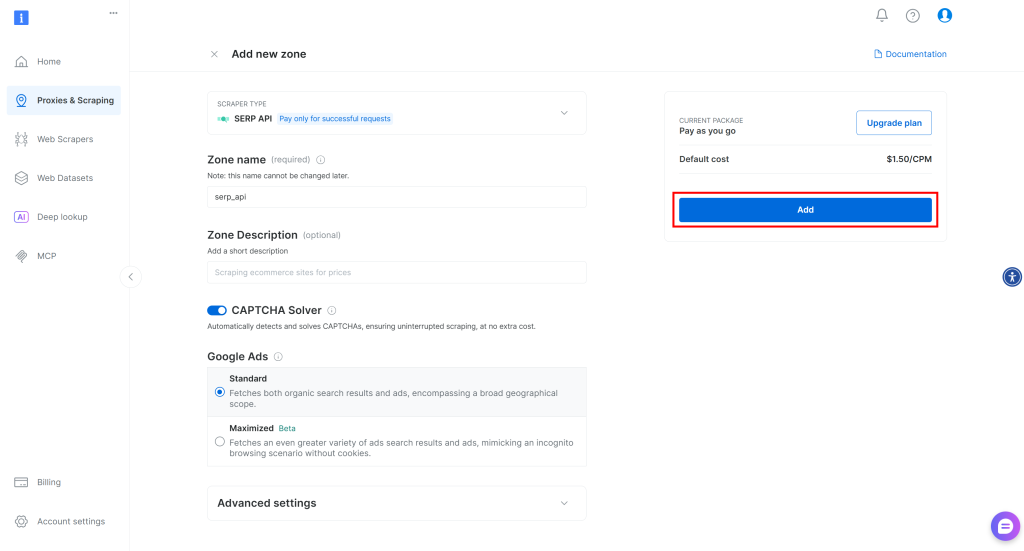
Ensuite, allez sur la page produit de la Zone et assurez-vous qu’elle est activée en basculant le commutateur sur “Actif” :
Cool ! Votre zone API SERP Bright Data est maintenant configurée avec succès et prête à être utilisée.
Étape 2 : Obtenez votre clé API Bright Data
La méthode recommandée pour authentifier les demandes adressées à l’API SERP consiste à utiliser votre clé d’API Bright Data. Si vous n’en avez pas encore généré une, suivez le guide officiel de Bright Data pour créer votre clé API.
Lorsque vous effectuez une requête POST à l’API SERP, incluez votre clé API dans l’en-tête Authorization comme suit :
"Authorization : Bearer <YOUR_BRIGHT_DATA_API_KEY>"Génial ! Vous avez maintenant tout ce qu’il faut pour appeler l’API SERP de Bright Data à partir d’un script Python avec des requêtes - outout autre client HTTP Python.
Maintenant, mettons tout en place !
Étape 3 : Appel de l’API SERP
Utilisez l’API SERP de Bright Data en Python pour récupérer les résultats de recherche Baidu pour le mot-clé ” bright data ” :
# pip install requests
import requests
from urllib.parse import urlencode
# informations d'identification Bright Data (TODO : remplacer par vos valeurs)
bright_data_api_key = "<YOUR_BRIGHT_DATA_API_KEY>"
bright_data_serp_api_zone_name = "<Votre_SERP_API_ZONE_NAME>" # (par exemple, "serp_api")
# URL de base de la page de recherche Baidu
base_url = "https://www.baidu.com/s"
# Mot-clé/phrase-clé de recherche
search_query = "bright data"
params = {"wd" : search_query}
# Construire l'URL du SERP de Baidu
url = f"{base_url}?{urlencode(params)}"
# Envoyer une requête POST à l'API SERP de Bright Data
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Authorization" : f "Bearer {bright_data_api_key}",
"Content-Type" : "application/json"
},
json={
"zone" : bright_data_serp_api_zone_name,
"url" : url,
"format" : "raw"
}
)
# Récupérer le HTML entièrement rendu
html = response.text
# La logique d'Analyse se déroule ici...Pour un autre exemple, consultez le projet Python “Bright Data API SERP” sur GitHub.
L’API SERP de Bright Data gère le rendu JavaScript, s’intègre à un réseau Proxy rotatif pour la rotation automatique des IP et gère les mesures anti-scraping telles que l’empreinte digitale du navigateur, les CAPTCHA et autres. Cela signifie que vous ne rencontrerez pas la page d’erreur “网络不给力,请稍后重试” (“Le réseau ne fonctionne pas bien, veuillez réessayer plus tard.”) que vous obtiendriez normalement en scrappant Baidu avec un client HTTP de base comme les requêtes.
En termes plus simples, la variable html contient la page de résultats de recherche de Baidu entièrement rendue. Vérifiez-le en imprimant le code HTML avec :
print(html)Vous obtiendrez un résultat comme celui ci-dessous :
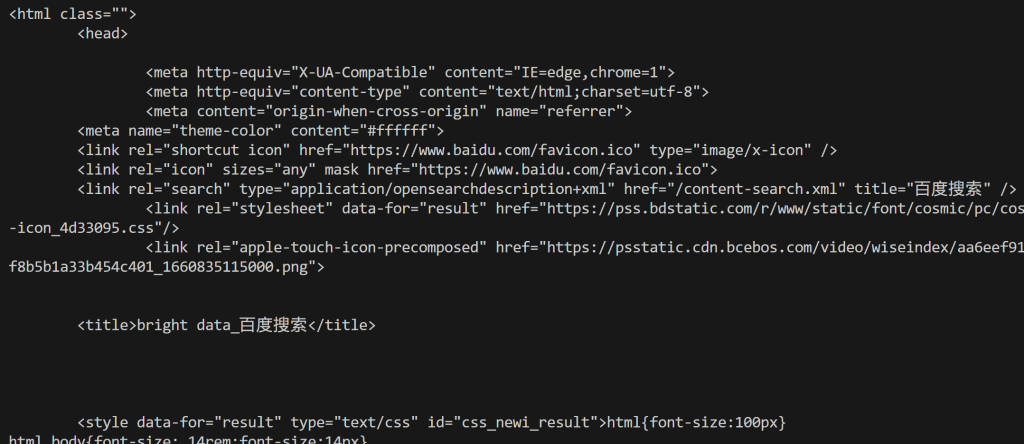
À partir de là, vous pouvez analyser le HTML comme indiqué dans la première approche pour extraire les données de recherche Baidu dont vous avez besoin. Comme promis, l’API SERP de Bright Data évite les blocages et vous permet d’atteindre une évolutivité illimitée !
Approche n° 3 : intégrer le serveur Web MCP
N’oubliez pas que l’API SERP (et de nombreux autres produits Bright Data) est également accessible via l’outil search_engine dans le MCP Web de Bright Data.
Ce serveur MCP Web open-source offre un accès convivial pour l’IA aux solutions de récupération de données web de Bright Data, y compris le scraping web de Baidu. Plus précisément, les outils search_engine et scrape_as_markdown sont disponibles dans le volet gratuit du MCP Web, ce qui vous donne la possibilité de les utiliser gratuitement dans des agents ou des flux de travail IA.
Pour intégrer le Web MCP dans votre solution IA, il vous suffit d’installer Node.js localement et de disposer d’un fichier de configuration comme celui-ci :
{
"mcpServers" : {
"Bright Data Web MCP" : {
"command" : "npx",
"args" : ["-y", "@brightdata/mcp"],
"env" : {
"API_TOKEN" : "<VOTRE_CLÉ_D'API_DE_BRIGHT_DATA>"
}
}
}
}Par exemple, cette configuration fonctionne avec Claude Desktop et Code (et bien d’autres bibliothèques et solutions IA). Découvrez d’autres intégrations dans la documentation.
Vous pouvez également vous connecter via le serveur distant de Bright Data sans aucune condition préalable locale.
Avec cette intégration, vos workflows ou agents alimentés par l’IA pourront récupérer de manière autonome les données SERP de Baidu (ou d’autres moteurs de recherche pris en charge) et les traiter à la volée.
Conclusion
Dans ce tutoriel, vous avez exploré trois méthodes recommandées pour le scraping de Baidu :
- Utiliser un Scraper personnalisé.
- Exploitation de l’API SERP de Baidu.
- Par le biais du MCP Web de Bright Data.
Comme nous l’avons démontré, la manière la plus fiable de scraper Baidu à grande échelle tout en évitant les blocages est d’utiliser une solution de scraping structurée. Celle-ci doit être soutenue par une technologie avancée de contournement des robots et un réseau de Proxy robuste, tels que les produits Bright Data.
Créez un compte Bright Data gratuit et commencez à explorer nos solutions de scraping dès aujourd’hui !




