

Dans ce guide, vous apprendrez ce qui suit :
- Qu’est-ce que Dify et pourquoi l’utiliser ?
- La raison pour laquelle vous devriez l’intégrer à un plugin de scraping tout-en-un.
- Avantages de l’intégration de Dify avec le plugin de scraping de Bright Data.
- Un tutoriel étape par étape pour créer un flux de travail de scraping Dify.
Plongeons dans l’aventure !
Dify : La puissance du développement de l’IA en code bas
Dify est une plateforme de développement d’applications LLM open-source. Elle fonctionne comme une solution LLM-ops qui simplifie la création d’applications alimentées par l’IA.
Plus précisément, il aide les développeurs à créer et à lancer des applications d’IA agentique prêtes à l’emploi en fournissant les éléments suivants
- Constructeur visuel de flux de travail: Concevez des processus d’IA en plusieurs étapes à l’aide d’une interface de type “glisser-déposer”. Vous pouvez enchaîner différents modèles, outils et logiques sans vous encombrer de code standard.
- Agnosticisme en matière de modèles: Intégration avec un large éventail de LLM, des modèles propriétaires tels que la série GPT d’OpenAI aux diverses alternatives open-source. Vous avez ainsi la possibilité de choisir celui qui convient le mieux à votre cas d’utilisation.
- Backend-as-a-service (BaaS) : Gérer les complexités de l’hébergement, de la mise à l’échelle et de la gestion de l’infrastructure dorsale. Vous pouvez ainsi vous concentrer sur l’exploitation des capacités de l’IA plutôt que sur la gestion de l’infrastructure sous-jacente.
- Extensibilité: Les fonctionnalités sont facilement étendues grâce à des plugins et des outils personnalisés provenant de fournisseurs tiers. Dify s’adapte ainsi à un large éventail de cas d’utilisation.
La nécessité d’un plugin de scraping dédié dans Dify
Le scraping web à grande échelle présente de nombreux défis. Les sites web utilisent des mesures anti-bots qui peuvent facilement bloquer de simples tentatives de récupération de données. Par conséquent, la mise en place et la maintenance d’un système permettant de surmonter ces obstacles sont complexes et gourmandes en ressources.
C’est précisément là que le plugin Bright Data Dify entre en jeu. Le plugin gère toutes les complexités sous-jacentes, de la rotation du proxy et de la gestion de l’IP à la résolution des CAPTCHA et à l’analyse des données. En d’autres termes, il garantit que votre agent Dify reçoit des données Web cohérentes et de haute qualité.
En détail, le plugin Bright Data fournit ces outils :
- Flux de données structurées: Pour obtenir des données structurées et organisées provenant de plus de 50 plateformes, telles que des pages de produits de commerce électronique ou des annonces immobilières.
- Scrape sous forme de markdown: Il supprime les publicités, les barres de navigation et autres éléments non essentiels, et fournit une version propre du texte, formatée en markdown.
- Outil de moteur de recherche: Effectuez des requêtes directement sur des moteurs de recherche tels que Google, Bing, Yandex et bien d’autres. Vous pouvez l’utiliser pour surveiller les classements de recherche pour des mots clés spécifiques, découvrir le contenu des concurrents ou dans les flux de travail SERP RAG.
Avantages de l’intégration de Dify avec le plugin Bright Data
Lorsque vous connectez les capacités d’orchestration de l’IA de Dify à celles de scraping de Bright Data, vous débloquez cette fonctionnalité :
- Accès à des données en temps réel: Au lieu de s’appuyer sur des données obsolètes, votre agent d’IA peut interroger le web en direct pour obtenir des informations de dernière minute. Cela garantit que vos applications d’IA fonctionnent avec les données les plus récentes disponibles.
- Automatiser les recherches et les analyses complexes: En introduisant des données directement dans un LLM dans le cadre d’un flux de travail Dify, vous pouvez automatiser des tâches qui nécessiteraient autrement des heures de travail manuel. Par exemple, vous pouvez créer un flux de travail RAG pour surveiller une liste de produits concurrents sur un site de commerce électronique.
- Simplifier la complexité technique: Le scraping web n’est pas facile, car les sites utilisent des techniques sophistiquées de blocage anti-scraping. Le plugin Bright Data évite les blocages à votre place. Tout cela, tandis que Dify fournit l’interface simple pour exploiter cette puissance.
- Polyvalence pour divers cas d’utilisation: Le plugin vous fournit de nombreux outils, notamment pour obtenir des données structurées, extraire n’importe quelle page pour la nettoyer et effectuer des requêtes sur les moteurs de recherche. Cela rend l’intégration Dify + Bright Data adaptable à plusieurs cas d’utilisation.
Intégration de Dify avec Bright Data pour le résumé des produits : Tutoriel étape par étape
Il est temps de suivre un tutoriel étape par étape pour apprendre à utiliser l’intégration entre Dify et Bright Data.
L’objectif du flux de travail que vous allez créer est de donner un produit Amazon en entrée et de recevoir son résumé. Le produit que vous utiliserez provient d’Amazon et est un Apple AirTag:
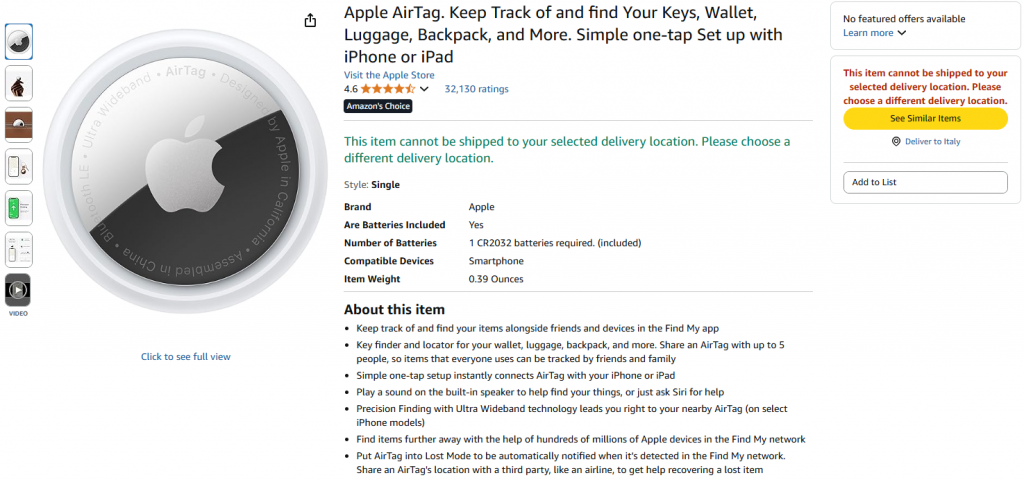
Pour atteindre l’objectif de l’IA scraping, vous allez construire un flux de travail en quatre étapes en connectant différents nœuds. Chaque nœud a une tâche spécifique :
- Un nœud “Start” pour définir la variable d’entrée, qui est l’URL de la page du produit Amazon.
- Un nœud “Structured Data Feeds” prendra cette URL et en extraira le contenu, en extrayant toutes les données structurées de la page Amazon.
- Un nœud “LLM” pour traiter les données extraites. Vous lui donnerez une instruction spécifique pour générer le résumé du produit.
- Un nœud “Fin” pour présenter le texte résumé généré par le LLM.
Ce processus de scraping d’IA en quatre étapes est entièrement visuel. Vous connecterez ces nœuds dans un flux simple et vous n’aurez pas à écrire une seule ligne de code.
Suivez les instructions pour créer votre flux de travail d’IA de web scraping alimenté par Bright Data, sans code, dans Dify !
Exigences
Pour reproduire ce tutoriel sur la façon d’intégrer Dify avec Bright Data, vous avez besoin de :
- Un compte Dify (un compte gratuit suffit).
- Une clé d’API de Bright Data.
Si vous ne les avez pas encore, utilisez les liens ci-dessus et suivez les instructions pour tout mettre en place.
Conditions préalables
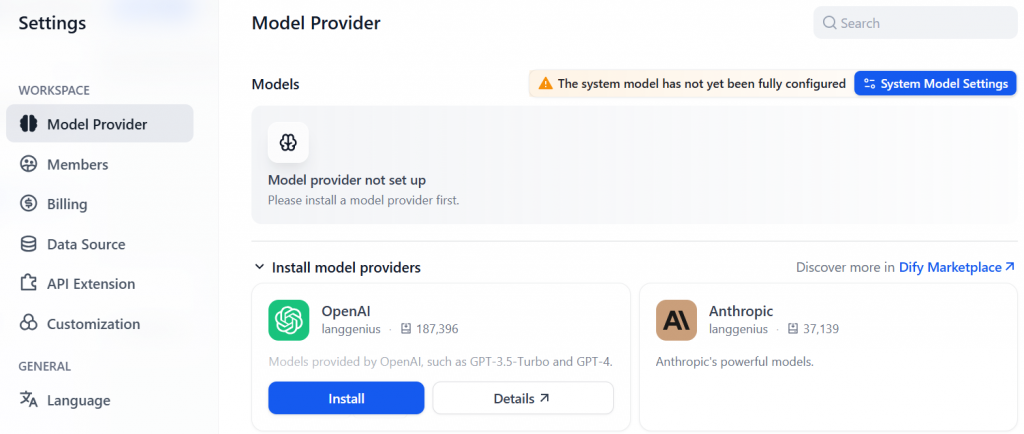
Afin d’utiliser le nœud LLM, vous devez d’abord configurer l’intégration LLM dans Dify. Pour ce faire, cliquez sur l’image de votre profil et sélectionnez l’option “Settings” :

Vous serez redirigé vers la page qui vous permet de sélectionner un modèle (l’onglet “Model Provider”). Par exemple, vous pouvez installer le plugin OpenAI provider :
Très bien ! Vous êtes maintenant prêt à démarrer votre flux de travail de scraping web Dify.
Étape 1 : Télécharger le plugin Bright Data et l’intégrer
Téléchargez la dernière version du plugin Bright Data depuis le dépôt officiel de Dify. Ensuite, cliquez sur “PLUGINS” et sélectionnez l’option “Installer à partir d’un fichier local” :
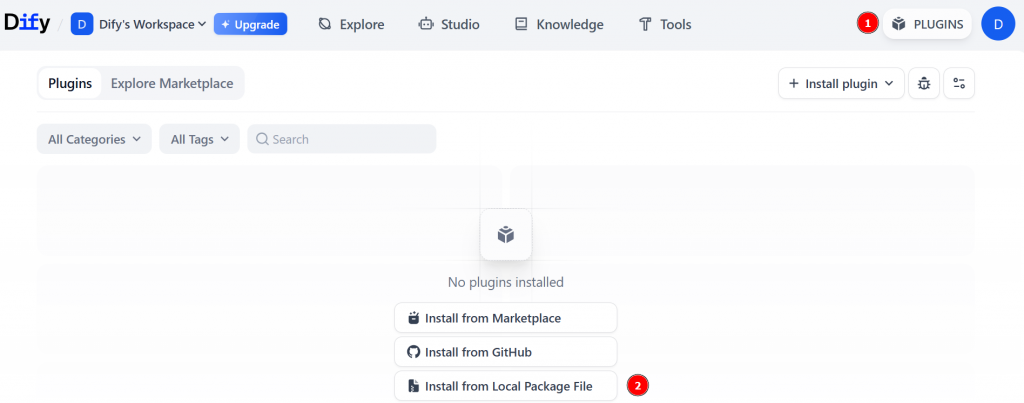
Sélectionnez le fichier local que vous avez téléchargé précédemment et cliquez sur le bouton “Installer” :

C’est bon ! Le paquet d’intégration de Bright Data est maintenant chargé et installé sur Dify.
Étape 2 : Créer une nouvelle application Dify
À partir de la page d’accueil de l’espace de travail Dify, créez une nouvelle application en sélectionnant “Create from Blank” (Créer à partir d’une feuille blanche), comme indiqué ci-dessous :
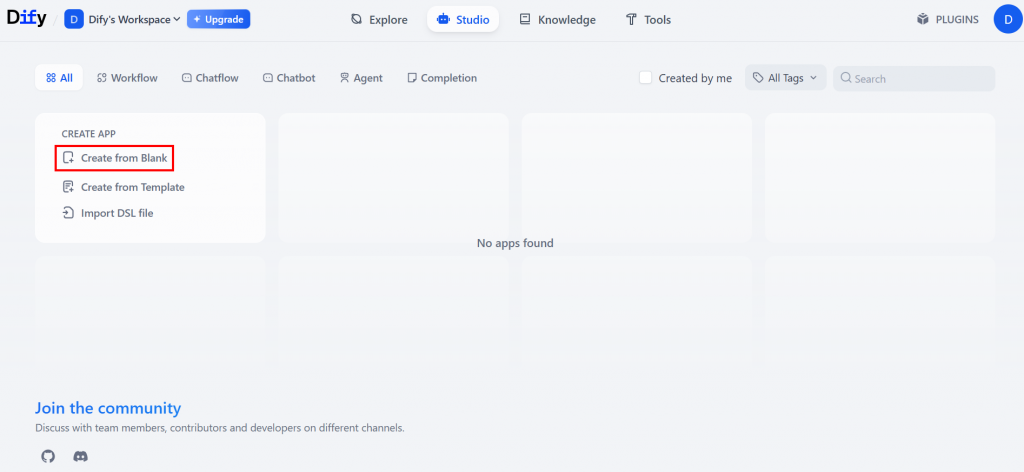
Ensuite, choisissez le type “Workflow” et cliquez sur “Créer” :
Voici à quoi ressemblera le nouveau flux de travail vierge :
C’est formidable ! Vous venez de créer un nouveau flux de travail Dify. Il est temps d’ajouter les nœuds nécessaires pour le web scraping.
Étape 3 : Configurer les nœuds pour la capture du Web
Vous pouvez maintenant ajouter les nœuds à votre flux de travail et définir les paramètres nécessaires pour le flux de travail Dify web scraping via Bright Data.
Commencez par cliquer sur le nœud “Start”, puis sur “INPUT FIELD” :
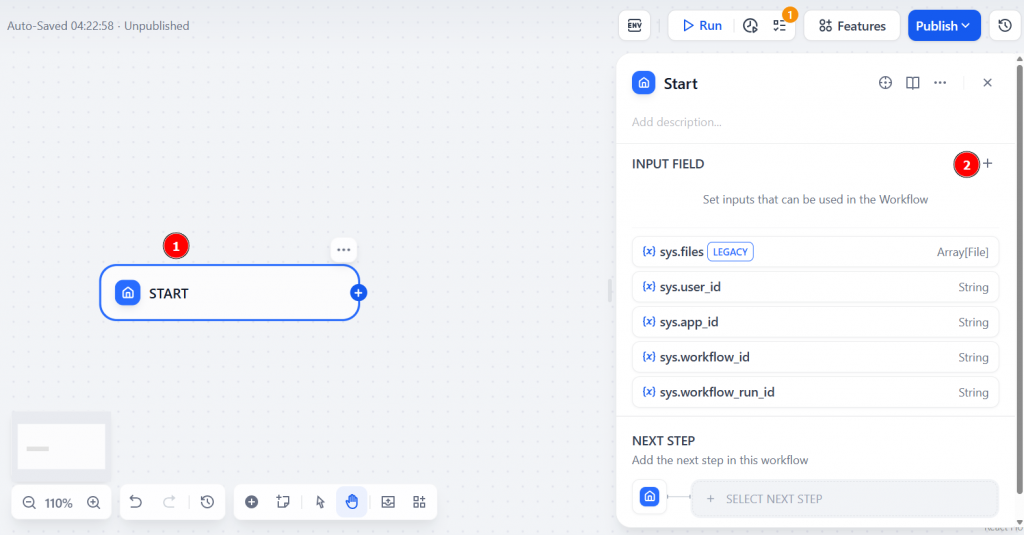
Sélectionnez “Paragraphe” comme type et donnez un nom au champ “Nom de la variable”. Par exemple, product_url. Modifiez la valeur “Longueur maximale” pour qu’elle soit au moins égale à 200. Ce champ représente l’URL de la page cible à analyser. Vous devrez lui transmettre une entrée pour lancer le flux de travail.
Confirmez en cliquant sur le bouton “Enregistrer” :

C’est parfait ! Le nœud “Start” est correctement configuré.
Continuez en cliquant sur le “+” dans le nœud “Start”. Sélectionnez “Outils” > “Bright Data Web Scraper” > “Structured Data Feeds” :

Le nœud Bright Data sert de pont entre votre flux de travail Dify et l'[infrastructure d’IA de Bright Data] (
/ai). Il donne à votre agent d’IA la possibilité de récupérer les informations dont il a besoin sur le web.
En sélectionnant l’outil “Structured Data Feeds”, vous transformerez une page de produit Amazon désordonnée en une sortie JSON structurée avec des champs de données prévisibles.
Cliquez ensuite sur “Autoriser” pour saisir votre clé API Bright Data :
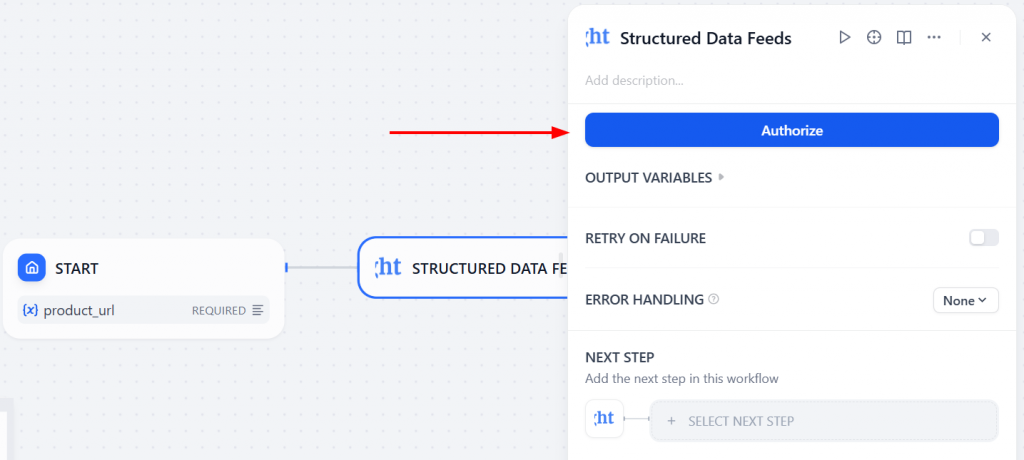
Sélectionnez product_url comme variable d’entrée. Ainsi, le nœud “Start” transmettra la valeur réelle de l’URL du produit en tant qu’entrée du nœud “Bright Data”.
Pour ce faire, tapez “/” dans le champ “URL cible” et vous obtiendrez une liste des variables disponibles. Ajoutez également une description dans le champ “Description de la demande de données” :

Très bien ! Le nœud Bright Data est configuré. Vous pouvez passer au nœud suivant.
Cliquez sur le “+” et ajoutez un nœud LLM :
Dans la section “MODÈLE”, sélectionnez “Configurer le modèle” et choisissez un modèle LLM dans la liste :
Dans la section “SYSTEM”, ajoutez une invite, telle que :
You are an expert e-commerce analyst. Based on the following structured data from an Amazon product page, write a concise and helpful summary for a potential buyer.
Include the following:
- Product name.
- A one-sentence summary.
- 3-5 key features in a bulleted list.
- The overall star rating and number of reviews.
- A brief concluding sentence about who this product is for.
Data:
{{Structure_Data_Feeds.text}}Cette invite demande au MLD de jouer le rôle d’un analyste en commerce électronique dans le but de créer un résumé du produit récupéré. Elle demande également des détails spécifiques à inclure, comme le nom du produit et certaines caractéristiques clés. Notez qu’elle inclut le résultat textuel du nœud du plugin Bright Data à la fin.
Voici à quoi ressemblera la section remplie :
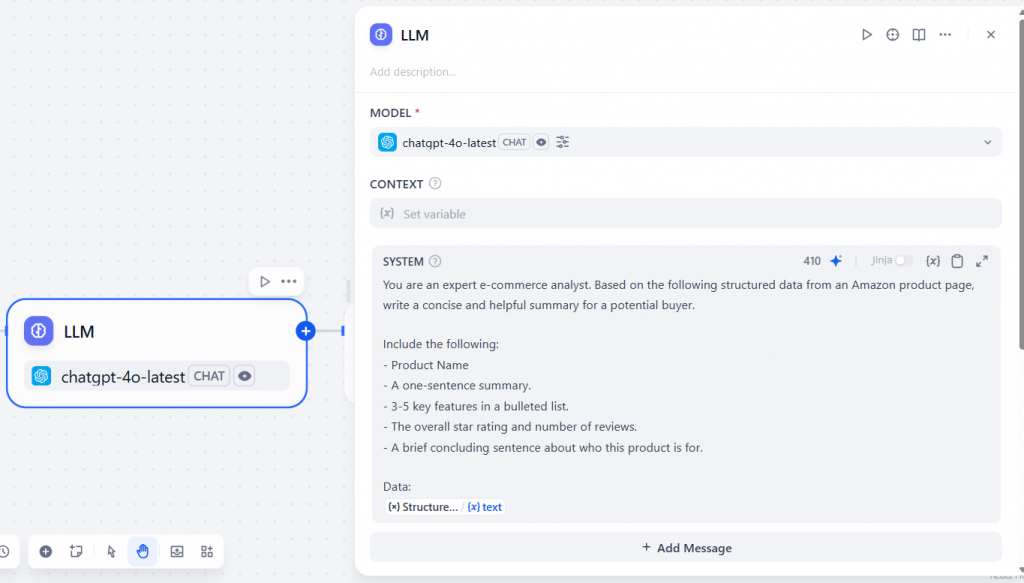
Dans la section “Data” de l’invite, ajoutez le texte comme variable d’entrée. Cela permettra au LLM d’utiliser le contenu que le nœud Bright Data a récupéré à partir de l’URL cible. Si vous cliquez sur “/”, vous obtiendrez la liste des variables disponibles que vous pouvez sélectionner.
C’est bien ! Vous pouvez maintenant ajouter le dernier nœud au flux de travail.
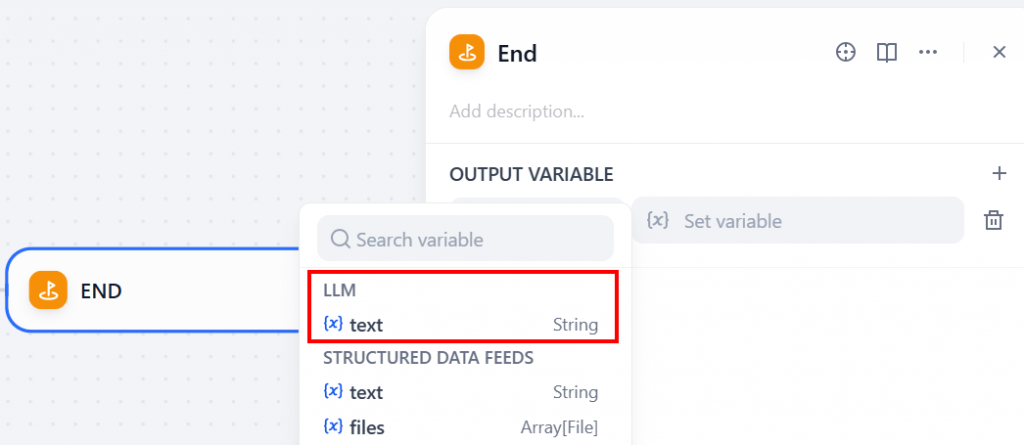
La sortie du flux de travail peut être obtenue en ajoutant un nœud “Fin” :

La variable de sortie doit être une chaîne de caractères provenant du nœud LLM. Pour ce faire, cliquez sur la section “OUTPUT VARIABLE” et sélectionnez “text” sous “LLM” :
C’est incroyable ! Votre flux de travail est correctement configuré. Vous êtes maintenant prêt à l’exécuter.
Étape 4 : Exécuter le flux de travail
Vous trouverez ci-dessous le flux de travail du web scraping dans Dify via le plugin Bright Data :
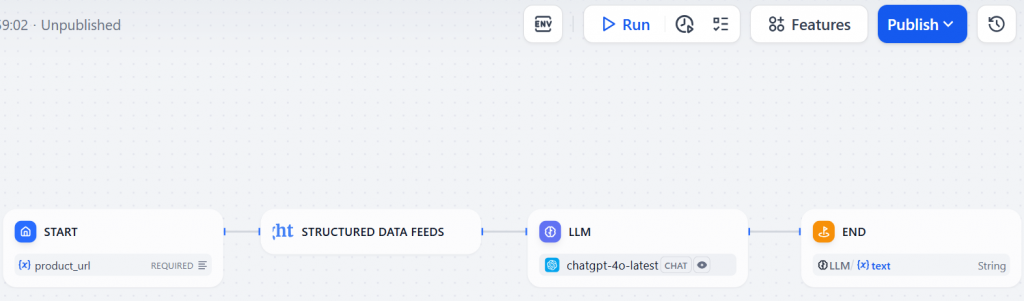
Comme vous pouvez le constater, il ne comporte que quatre nœuds, comme prévu dans l’introduction de ce chapitre. De plus, vous n’avez pas eu à écrire une seule ligne de code pour atteindre votre objectif !
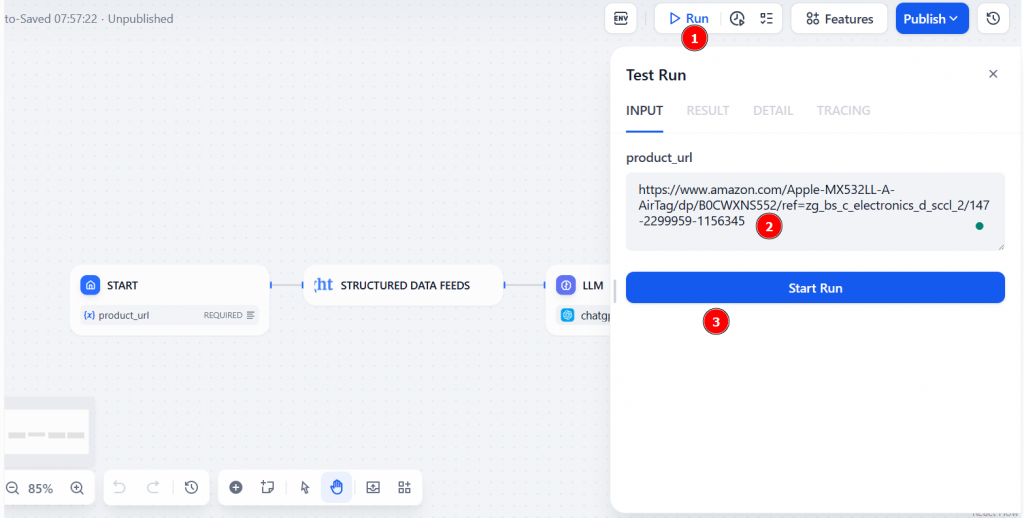
Pour exécuter le flux de travail, cliquez sur “Exécuter”. À ce stade, vous devez ajouter l’URL du produit Amazon dans le champ “product_url”. Ensuite, cliquez sur “Start Run” pour lancer le flux de travail Dify web scraping :
Le résultat sera disponible dans l’onglet “Résultat” :
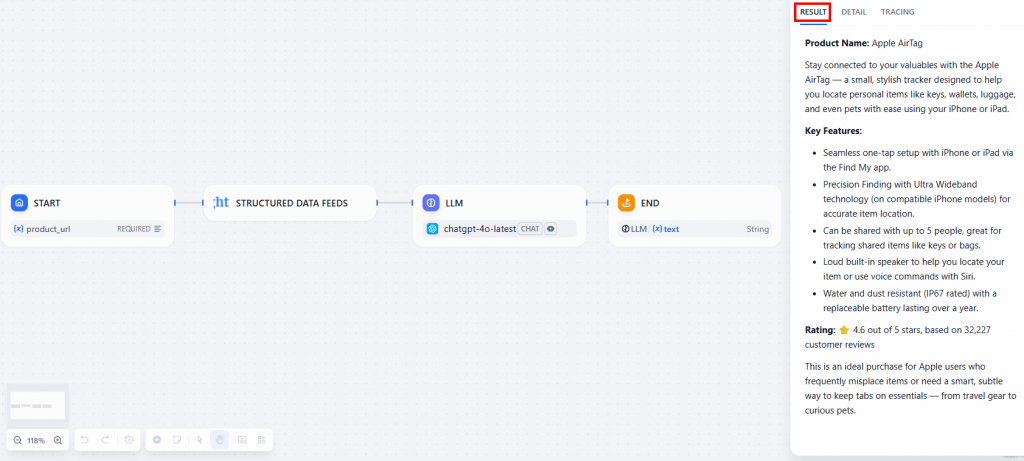
Vous trouverez ci-dessous le résultat sous forme de texte :
**Product Name:** Apple AirTag
Stay connected to your valuables with the Apple AirTag — a small, stylish tracker designed to help you locate personal items like keys, wallets, luggage, and even pets with ease using your iPhone or iPad.
**Key Features:**
- Seamless one-tap setup with iPhone or iPad via the Find My app.
- Precision Finding with Ultra Wideband technology (on compatible iPhone models) for accurate item location.
- Can be shared with up to 5 people, great for tracking shared items like keys or bags.
- Loud built-in speaker to help you locate your item or use voice commands with Siri.
- Water and dust resistant (IP67 rated) with a replaceable battery lasting over a year.
**Rating:** ⭐ 4.6 out of 5 stars, based on 32,227 customer reviews
This is an ideal purchase for Apple users who frequently misplace items or need a smart, subtle way to keep tabs on essentials — from travel gear to curious pets.Comme demandé, le LLM a rapporté ce que vous avez demandé dans l’invite :
- Un résumé en une phrase du produit.
- 5 caractéristiques principales.
- La note.
- Une phrase conclusive, indiquant à qui s’adresse ce produit.
Si vous avez déjà essayé de récupérer des données sur des sites de commerce électronique importants comme Amazon, vous savez à quel point c’est difficile :
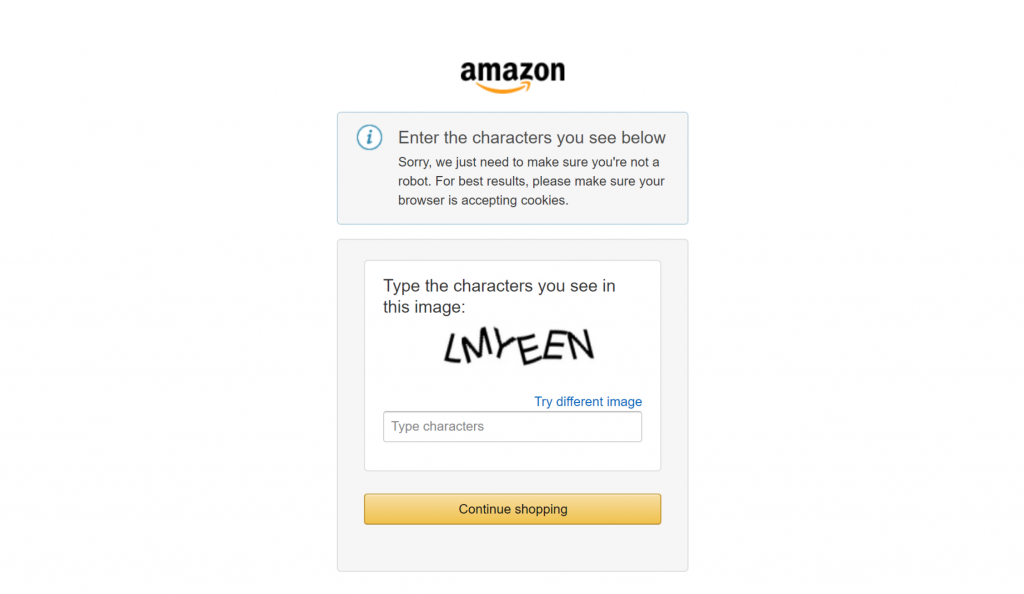
C’est là que l’intégration de Bright Data fait toute la différence. Elle a pris en charge toutes les mesures anti-scraping complexes en coulisses, en veillant à ce que le processus de récupération des données fonctionne comme prévu.
Et voilà ! Vous avez terminé avec succès votre premier projet d’intégration de Dify avec Bright Data.
Conclusion
Dans cet article, vous avez appris à utiliser Dify pour construire un flux de travail de scraping d’IA sans code. Cela n’aurait pas été possible sans le plugin Bright Data Dify. Comme nous le montrons ici, ce plugin expose plusieurs outils avancés pour le web scraping dans les flux de travail d’IA.
L’un des principaux défis à relever pour créer un flux de travail de scraping fiable pour vos agents d’IA est d’avoir accès à des données Web de haute qualité. Cela nécessite des outils pour récupérer, valider et transformer le contenu web, ce qui est exactement ce que l ‘infrastructure d’IA de Bright Data est conçue pour fournir.
Créez un compte Bright Data gratuit et commencez à expérimenter nos outils de données prêts pour l’IA dès aujourd’hui !





