

Dans cet article, vous apprendrez tout sur le RAG, y compris son rôle dans l’amélioration des réponses LLM et ses composants.
Qu’est-ce que le RAG ?
Le RAG est une technique d’apprentissage automatique (ML) qui va plus loin que les LLM traditionnels en les reliant à des systèmes de recherche (ou de récupération). Au lieu de se contenter de s’appuyer sur leurs données d’entraînement fixes, les modèles alimentés par le RAG peuvent exploiter des sources externes, telles que des bases de données, des documents ou même le web, pour trouver des informations pertinentes et améliorer la qualité de leurs réponses. Cette combinaison de récupération d’informations instantanée et de génération de langage rend les réponses plus précises et plus actuelles.
Récupération + génération
Le RAG fonctionne en combinant trois éléments : un système de recherche ou de récupération, le modèle linguistique lui-même et un processus qui combine les deux. Lorsqu’une question lui est posée, le système RAG utilise d’abord le composant de récupération pour trouver des données pertinentes en dehors de l’ensemble de données d’entraînement du modèle linguistique. Ensuite, la requête initiale est modifiée pour être enrichie de ces données. La requête mise à jour est transmise au composant de génération (le LLM), qui utilise à la fois ses propres modèles appris et le nouveau contenu pour fournir une réponse. De cette façon, le résultat n’est pas seulement le produit d’un apprentissage préexistant, il est fondé sur des informations réelles et vérifiées provenant directement de sources.
Le RAG combine intelligemment la puissance de la récupération et de la génération, offrant une solution intelligente aux lacunes des modèles linguistiques traditionnels. Il fournit des réponses plus fiables et plus précises et peut s’adapter à différents sujets, ce qui le rend idéal pour les applications où les informations doivent être actuelles ou spécialisées.
Pourquoi les LLM ont besoin d’être améliorés
Si les LLM sont impressionnants pour générer des réponses semblables à celles d’un humain, ils ne sont pas sans défauts.
Risque d’hallucinations
L’un des plus grands défis des LLM est le risque d’hallucination, c’est-à-dire lorsque le modèle génère des informations convaincantes mais incorrectes. Cela se produit parce que les LLM sont formés à partir de grands Jeux de données statiques et n’ont pas accès en temps réel aux mises à jour ou aux faits en dehors de leur fenêtre de formation.
De plus, si l’on y regarde de plus près, les LLM ne sont pas des machines à résoudre des problèmes, mais des modèles de complétion de texte. Leur objectif final est de générer une réponse qui ressemble le plus possible à la réponse correcte à la question posée ; la réponse n’a pas nécessairement besoin d’être correcte. Comme ils n’utilisent pas d’algorithmes déterministes pour arriver à une réponse,ils sont voués à hallucinerà un moment ou à un autre.
Vérification des informations
De plus, les LLM ne peuvent pas vérifier les nouvelles informations ni comparer leurs réponses à des sources en temps réel, ce qui les rend susceptibles de passer à côté de certains faits ou de les présenter de manière erronée.
Limite des connaissances
Une autre limitation est la coupure des connaissances. Comme les LLM sont entraînés sur des données qui ne vont que jusqu’à un certain point, ils manquent intrinsèquement de connaissances sur les événements ou les découvertes qui se produisent après la coupure.
Sources crédibles
Les LLM ont également du mal à citer des sources fiables, ce qui peut amener les utilisateurs à s’interroger sur l’exactitude de leurs réponses. Sans accès à des sources actualisées ou à un moyen de valider les informations, ces modèles peuvent avoir du mal à inspirer confiance.
RAG : la solution aux limites des LLM
Comme mentionné précédemment, le RAG est conçu pour pallier les limites des LLM en fondant ses réponses sur des données réelles et actualisées.
Des informations récentes provenant de sources pertinentes
Lorsqu’un LLM reçoit une requête, au lieu de s’appuyer uniquement sur ses données d’entraînement statiques, le RAG lui permet d’extraire des informations récentes provenant de sources externes pertinentes dans le contexte. Cette configuration réduit efficacement le risque d’hallucinations en basant les réponses sur des documents et des données réels. Comme il interroge activement des sources externes, le RAG peut répondre à des questions portant sur des événements récents, de nouvelles technologies ou toute information qu’un LLM standard ne pourrait pas fournir en raison de ses limites en matière de connaissances. Par exemple, dans un scénario de support client, le RAG peut récupérer les dernières mises à jour des politiques dans une base de connaissances, garantissant ainsi que les réponses sont conformes à la documentation actuelle de l’entreprise.
Transparence accrue
Outre la précision, le RAG améliore la transparence grâce aux sources de ses réponses. Comme il extrait les données de documents spécifiques et pertinents, il fournit un raisonnement plus clair, permettant aux utilisateurs de voir d’où proviennent les informations. Cette vérifiabilité renforce non seulement la confiance des utilisateurs, mais rend également les modèles équipés du RAG plus utiles dans des domaines tels que les services juridiques et financiers, où les utilisateurs ont besoin de réponses claires et bien étayées.
Principaux cas d’utilisation du RAG
Le RAG excelle dans les applications où des informations précises et à jour sont essentielles, en particulier dans les domaines en évolution rapide. Voici quelques-uns des cas d’utilisation les plus courants du RAG.
Automatisation du service client
Le RAG transforme le service client en exploitant la base de connaissances et les articles d’aide d’une entreprise. Il fournit des réponses instantanées aux questions des clients, en s’appuyant sur les documents, les informations sur les produits et les conseils de dépannage les plus récents. Cela signifie que les clients obtiennent des réponses précises et adaptées à leurs besoins spécifiques, sans submerger les agents du service client de questions routinières.
Services juridiques et financiers
Ces secteurs ont besoin d’informations non seulement précises, mais aussi traçables jusqu’à des sources fiables. Un professionnel du droit, par exemple, peut utiliser le RAG pour retrouver la jurisprudence ou la réglementation pertinente lorsqu’il se forge une opinion. Les analystes financiers peuvent utiliser le RAG pour extraire des rapports ou des données actuels sur le marché, fournissant ainsi à leurs clients des informations à la fois opportunes et étayées par des données concrètes.
Recherche et création de contenu
Les écrivains, les journalistes et les chercheurs peuvent utiliser le RAG pour extraire des références précises provenant de sources fiables, ce qui simplifie et accélère le processus de vérification des faits et de collecte d’informations. Qu’il s’agisse de rédiger un article ou de compiler des données pour une étude, le RAG permet d’accéder rapidement à des informations pertinentes et crédibles, ce qui permet aux créateurs de se concentrer sur la production de contenus de haute qualité.
Agents conversationnels et chatbots
Grâce à l’intégration de RAG, les agents conversationnels et les chatbots peuvent fournir des réponses plus précises et adaptées au contexte, améliorant ainsi l’expérience utilisateur. Par exemple, un chatbot dédié à la santé pourrait récupérer des informations sur les études médicales récentes, ou un bot d’assistance technique pourrait extraire les dernières informations sur la mise à jour du micrologiciel d’un appareil. La capacité de RAG à combiner la récupération de données en temps réel et la génération de langage améliore à la fois la qualité et la fiabilité des réponses.
En savoir plus sur la création d’un chatbot RAG à l’aide des modèles GPT.
Défis et limites du RAG
Si le RAG apporte une valeur ajoutée significative aux modèles linguistiques, il comporte également son lot de défis.
Qualité et précision
L’un des principaux problèmes concerne la qualité et la précision des informations récupérées pour enrichir la requête. Le RAG dépendant de sources externes, la qualité de la réponse du modèle dépend de celle des données qu’il récupère. La réponse générée peut s’avérer insuffisante si le système de récupération renvoie des documents non pertinents ou inexacts. Il est important de garantir une récupération de haute qualité, ce qui nécessite souvent des ajustements et des mises à jour régulières afin de maintenir la pertinence et l’exactitude des données.
Coût et complexité de calcul
Parmi les autres défis, citons le coût et la complexité de calcul liés à l’exécution d’un système RAG. Contrairement aux LLM autonomes, le RAG nécessite à la fois un système de recherche puissant et un modèle capable d’intégrer facilement les informations récupérées, ce qui peut nécessiter beaucoup de ressources. Cette charge de calcul accrue peut ralentir les temps de réponse, en particulier si de grandes quantités de données doivent être recherchées ou traitées en temps réel. Les organisations qui mettent en œuvre le RAG doivent souvent trouver un équilibre entre précision et performance, en trouvant des moyens de configurer la recherche sans compromettre la vitesse.
Le succès du RAG dépend fortement de l’accès à des sources de données structurées et fiables. Le système de recherche peut avoir du mal à extraire des informations utiles sans bases de données externes fiables et bien organisées. De plus, toutes les sources de données ne sont pas facilement accessibles ou abordables, ce qui peut constituer un obstacle pour les petites organisations.
Malgré ces défis, avec une configuration minutieuse et des sources de données fiables, le RAG peut encore offrir des avantages transformateurs pour un large éventail d’applications.
Mise en œuvre du RAG dans la pratique
La mise en place d’un système RAG nécessite de connecter un modèle linguistique à un mécanisme de recherche efficace pour permettre l’accès à des données externes.
Le processus commence par la mise en place d’une architecture de haut niveau qui combine un système de recherche avec le modèle linguistique. Lorsqu’un utilisateur soumet une requête, le système de recherche recherche des informations pertinentes dans des sources externes, puis envoie ces informations au LLM avec l’invite, qui génère une réponse basée à la fois sur ses propres connaissances et sur les données récupérées. Cette approche garantit que les réponses sont à la fois éclairées et contextualisées à partir d’informations récentes et fiables.
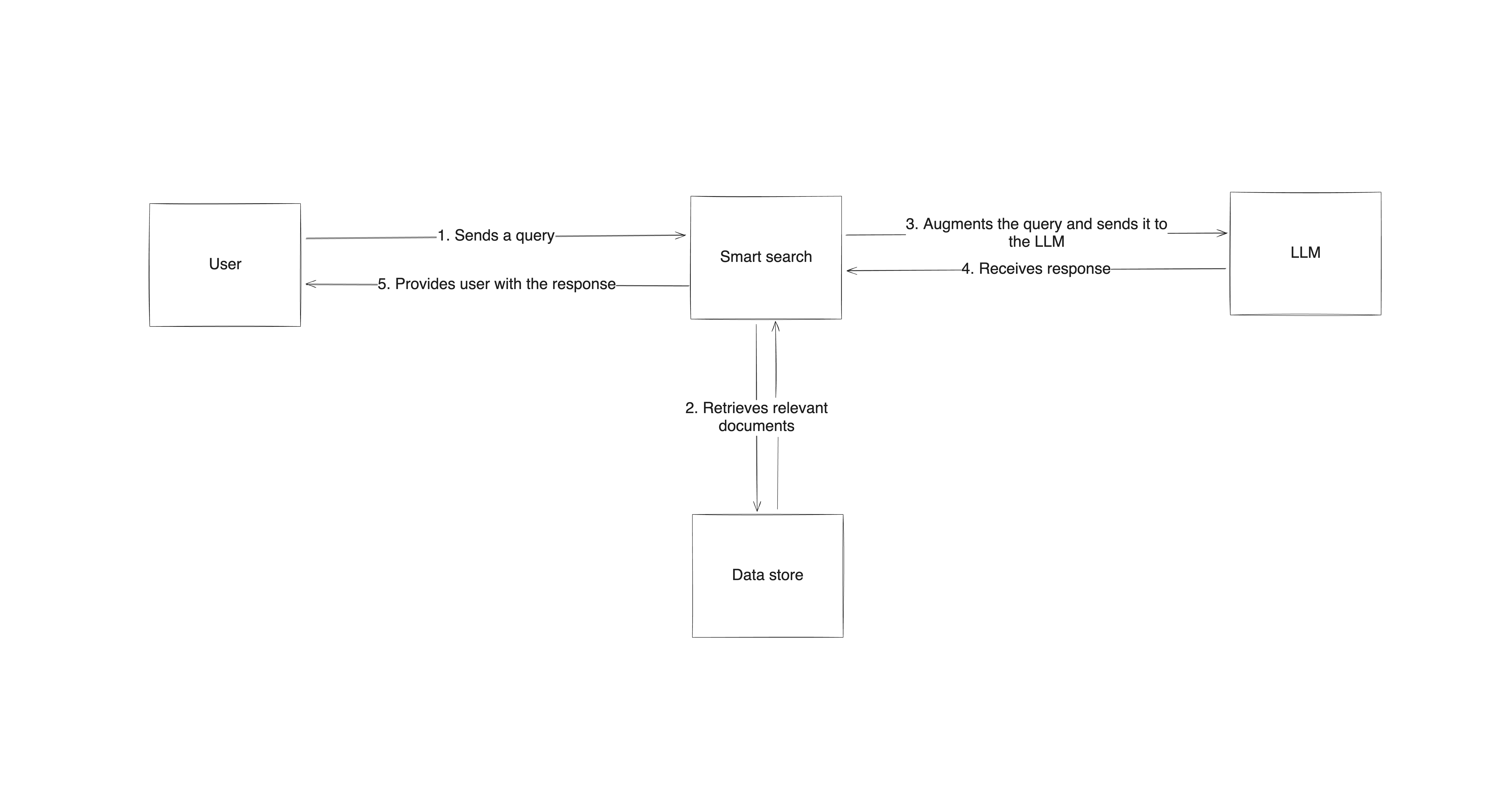
La mise en œuvre du RAG nécessite des outils et des cadres spécifiques
Concrètement, la mise en œuvre du RAG nécessite des outils et des cadres spécifiques capables de gérer la recherche d’informations, leur traitement et la génération de la réponse. Les bibliothèques telles queLangChainetHaystacksont des choix populaires, car elles fournissent des composants prêts à l’emploi pour intégrer la recherche dans le processus de génération de réponses.
Par exemple, LangChain propose des outils pourstructurer les invites,récupérer des données etacheminer les résultatsdirectement vers un LLM, tandis que Haystack est spécialisé dansla récupération haute performance, vous permettant d’extraire des informations à partir de bases de données, de documents ou même du web. Vous pouvez personnaliser ces outils pour qu’ils fonctionnent avec différentes sources de données, ce qui les rend très adaptables à diverses applications RAG.
Le RAG est un cadre construit sur un LLM existant
Si vous regardez les choses de loin, contrairement à des techniques telles quele réglage fin, le RAG n’affecte pas la structure ou les composants de votre LLM principal. Il s’agit simplement d’un cadre construit sur votre LLM existant qui contribue à améliorer la qualité des invites que vous envoyez au modèle. Certains affirmentque le RAG n’est qu’une forme améliorée d’ingénierie des invites, et vous pouvez comprendre leur point de vue si vous examinez l’invite originale qui entre dans un système RAG et la comparez à l’invite augmentée qu’il génère avant de produire la réponse finale. Voici un exemple rapide (et extrêmement simplifié) pour vous aider à mieux comprendre :
- Invite brute
Quels sont les derniers impacts du changement climatique sur les récifs coralliens ?
- Réponse (provenant d’un LLM sans RAG)
Les récifs coralliens sont affectés par la hausse des températures et l’acidification des océans, qui provoquent le blanchiment des coraux et perturbent les écosystèmes marins.
- Invite augmentée (avec RAG)
À partir des données récupérées : « Un rapport de 2024 de la NOAA souligne que le réchauffement des océans a provoqué des épisodes de blanchissement massif des coraux dans les Caraïbes et le Pacifique, entraînant une réduction de 40 % de la couverture corallienne dans les régions touchées. L’acidification affaiblit également les squelettes coralliens, les rendant plus vulnérables aux dommages causés par les tempêtes », répondez à la question suivante : Quels sont les derniers impacts du changement climatique sur les récifs coralliens ?
- Réponse (provenant d’un LLM avec RAG)
Les rapports récents de la NOAA indiquent que le réchauffement des océans entraîne des épisodes de blanchissement massif, en particulier dans les Caraïbes et le Pacifique, avec une diminution de 40 % de la couverture corallienne dans certaines zones. L’acidification endommage également les squelettes coralliens, augmentant leur vulnérabilité.
Bien que cela semble corroborer l’argument, il est important de souligner que l’objectif principal de la configuration RAG est de fournir au LLM les données pertinentes dans le contexte de la requête initiale. Selon le stockage des données, votre composant de recherche peut être aussi simple qu’une requête SQL ou aussi complexe qu’une recherche Google et un crawling web. Ensuite, une fois que vous disposez des données, vous devez les hiérarchiser et les résumer correctement et efficacement avant de les ajouter à l’invite. Ces deux étapes rendent le RAG beaucoup plus complexe que n’importe quelle technique d’ingénierie d’invite.
La mise en œuvre du RAG nécessite de nombreuses données de haute qualité
En ce qui concerne le stockage des données lui-même, la plupart des systèmes RAG en ont besoin, et il est utile que les grandes quantités de données soient précises, à jour et spécifiques au domaine. La création et la maintenance de tels Jeux de données sont longues et difficiles. Les fournisseurs de données publiques, commeBright Data, peuvent faciliter cette tâche en fournissant de vastes Jeux de données qui garantissent que le système de récupération fonctionne avec des informations récentes et de haute qualité.
Ces sources peuvent inclure tout type de données, des données web aux Jeux de données structurés, ce qui améliore considérablement la pertinence du modèle. Grâce à l’intégration des Jeux de données Bright Data, les modèles RAG ont accès aux informations les plus récentes, ce qui améliore non seulement la précision des réponses, mais aide également dans les domaines où les données en temps réel sont essentielles, tels que les systèmes météorologiques ou la logistique et la gestion de la chaîne d’approvisionnement.
Comment Bright Data peut aider à la récupération de données publiques
En tant que fournisseur de jeux de données publiques de haute qualité provenant de l’ensemble du web, Bright Data peut être une ressource précieuse pour les systèmes RAG. Les modèles RAG dépendant d’informations de haute qualité et à jour, les jeux de données Bright Data permettent d’extraire des contenus pertinents pour diverses applications, de l’actualité à la recherche de niche.
Données structurées dans divers secteurs
Les jeux de données de Bright Data comprennent des données structurées dans divers secteurs, tels que le commerce électronique, les marchés financiers et l’actualité, qui peuvent être intégrées dans les systèmes RAG afin d’améliorer la précision et la pertinence du modèle. Cela peut contribuer à garantir que les LLM puissent répondre avec précision à des questions nécessitant des informations récentes ou spécifiques à un secteur, ce qui est essentiel dans des domaines tels que le service client et l’analyse concurrentielle.
Accédez à des données publiques à grande échelle et filtrez-les
Si vous cherchez à collecter vous-même des données sur le web,l’APIBright Data etson infrastructure Proxy étenduepeuvent vous aider à accéder à des données publiques et à les filtrer à grande échelle tout en respectant les politiques d’utilisation des données. Cela peut s’avérer très utile pour les applications RAG qui nécessitent une récupération dynamique d’informations. Par exemple, une configuration RAG pour les services financiers pourrait extraire en continu des données boursières actualisées ou des informations réglementaires, améliorant ainsi la capacité du modèle à fournir des informations en temps réel.
L’utilisation de Bright Data comme source de données dans votre système RAG vous libère de la charge de maintenance de votre base de données, vous permettant ainsi de vous concentrer sur l’amélioration de l’augmentation rapide et la génération de réponses.
Conclusion
Le RAG représente une avancée significative dans les capacités des LLM, leur permettant de surmonter des limitations clés telles que la coupure des connaissances et l’hallucination en incorporant des données en temps réel provenant de sources externes. Grâce au RAG, les modèles peuvent accéder à des informations actuelles et vérifiées, ce qui améliore à la fois la pertinence et la fiabilité de leurs réponses. Cette technique transforme les modèles linguistiques de référentiels de connaissances statiques en agents dynamiques et sensibles au contexte.
Lorsque vous intégrez des données de haute qualité en temps réel dans les implémentations RAG, vous pouvez améliorer la précision, la pertinence et la fiabilité de vos applications d’IA. Que ce soit dans le domaine du support client, de l’analyse financière, des soins de santé ou dans tout autre secteur, l’utilisation du RAG peut contribuer à améliorer considérablement l’expérience de l’utilisateur final.
Bright Data facilite le développement des implémentations RAG en proposant une solution évolutive pour l’obtention de données publiques fiables et structurées. Grâce à son offre étendue de Jeux de données, Bright Data aide les systèmes RAG à fournir des réponses précises et actualisées dans divers secteurs et applications.
Inscrivez-vous dès maintenant et commencez votre essai gratuit, qui comprend des échantillons de jeux de données que vous pouvez télécharger gratuitement !





