

Les agents IA ne peuvent pas accéder seuls aux données web en direct. La configuration associe deux outils pour donner cet accès à votre agent :
- Nanobot, un framework d’agent IA léger avec mémoire intégrée, planification et prise en charge du Model Context Protocol (MCP)
- Bright Data MCP Server, qui fournit à l’agent 65 outils web pour la recherche, le scraping, l’extraction de données structurées et l’automatisation du navigateur
Votre agent ne se contente pas de répondre à des questions ponctuelles : il surveille les sites web selon un calendrier, mémorise les changements et rend compte de manière autonome. Bright Data gère les aspects complexes (blocages d’IP, détection de bots, rendu JavaScript), et MCP le connecte à l’agent sans code de liaison.
TL;DR :
Ce tutoriel connecte Nanobot, un framework d’agent IA léger, au serveur MCP de Bright Data afin de créer un agent autonome doté de 65 outils web pour la recherche, le scraping et l’extraction de données.
- Capacités: recherche sur Google, scraping de sites web publics, extraction de données structurées sur les produits depuis Amazon et LinkedIn, et surveillance des pages pour détecter les changements au fil du temps.
- Configuration – Configurez 1 fichier JSON en ~15 minutes sans code personnalisé
- Démonstrations: exécutez 6 exemples fonctionnels, de la recherche à la surveillance des pages en temps réel.
Commencez avec l’offre gratuite de Bright Data : 5 000 requêtes/mois sans frais.
Qu’est-ce que Nanobot ?
Nanobot est un framework d’agent IA personnel développé par le HKUDS Lab de l’université de Hong Kong. Avec plus de 30 000 étoiles GitHub et environ 4 000 lignes de code principal, il comprend :
- Utilisation d’outils – Outils intégrés pour la recherche sur le Web, la récupération de données sur le Web, les opérations sur le système de fichiers et les commandes shell
- Mémoire – Faits à long terme et historique des conversations consultable qui persistent d’une session à l’autre
- Planification Cron – Tâches récurrentes qui s’exécutent de manière autonome selon un calendrier
- Génération de sous-agents – Agents parallèles en arrière-plan pour les tâches déléguées
- Prise en charge multicanal – Intégration de Telegram, Discord, WhatsApp et Slack
- Prise en charge MCP – Accès à des outils externes via n’importe quel serveur Model Context Protocol
Qu’est-ce que le serveur MCP de Bright Data ?
Le serveur MCP Bright Data expose 65 outils web spécialisés via le protocole Model Context Protocol. Lorsqu’un agent compatible MCP se connecte, il détecte automatiquement tous les outils disponibles et la manière de les appeler. Ce tutoriel utilise Nanobot, mais le serveur MCP Bright Data fonctionne avec n’importe quel framework prenant en charge le protocole. (Pour une comparaison plus approfondie, consultez MCP vs Scraping web traditionnel.)
| Catégorie | Nombre | Outils clés |
|---|---|---|
| Recherche et scraping | 7 | search_engine, scrape_as_markdown, scrape_as_html, extract, variantes par lots |
| Commerce électronique | 10 | Amazon (produits, avis, recherche), Walmart (produits, vendeurs), eBay, Home Depot, Zara, Etsy, Best Buy |
| Réseaux sociaux | 23 | LinkedIn (5), Instagram (4), Facebook (4), TikTok (4), X/Twitter (2), YouTube (3), Reddit |
| Intelligence économique | 5 | Crunchbase, ZoomInfo, Yahoo Finance, Reuters, GitHub |
| Automatisation des navigateurs | 14 | Naviguer, cliquer, taper, faire des captures d’écran, faire défiler, remplir des formulaires, obtenir du texte/HTML, envoyer des requêtes réseau |
| Autres | 6 | Google Maps, Google Shopping, Zillow, Booking, Google Play, Apple App Store |
Le niveau gratuit comprend 5 000 requêtes/mois pour les outils de recherche et de scraping. Le niveau Pro débloque tous les outils, y compris les extracteurs de données structurées et l’automatisation du navigateur.
Prérequis
Avant de commencer, assurez-vous de disposer des éléments suivants :
- Python 3.11+ installé (télécharger)
- Node.js 18+ et npm installés (télécharger) – le serveur MCP fonctionne sur Node.js
- Un jeton API Bright Data – inscrivez-vous gratuitement et générez-en un dans Paramètres du compte > Clés API
- Une clé API d’un fournisseur de modèles linguistiques de grande taille (LLM) – ce tutoriel utilise Anthropic (Claude) (nécessite des crédits API). Nanobot prend en charge OpenAI, DeepSeek, Google Gemini, OpenRouter et 12 autres fournisseurs via LiteLLM
Étape 1 : Installer Nanobot
Au cours de cette étape, vous installez l’interface de ligne de commande (CLI) Nanobot et initialisez l’espace de travail qui stocke la configuration de votre agent.
Installez le package nanobot-IA:
pip install nanobot-iaSi
pipne fonctionne pas, essayezpip3 install nanobot-IA.
Vérifiez l’installation :
nanobot --helpLa sortie affiche des commandes telles que onboard, agent, gateway, status, cron, channels et provider.
Initialisez l’espace de travail :
nanobot onboardLa commande onboard crée le répertoire ~/.nanobot/ avec la configuration par défaut et les fichiers de l’espace de travail.
Vous avez installé Nanobot et initialisé l’espace de travail. Ensuite, configurez la connexion au serveur MCP Bright Data.
Étape 2 : Configurer l’agent IA pour le Scraping web
Au cours de cette étape, vous connectez Nanobot au serveur Bright Data MCP en modifiant un seul fichier de configuration JSON.
Ouvrez ~/.nanobot/config.json dans n’importe quel éditeur de texte et remplacez son contenu par ce qui suit. Utilisez VS Code (code ~/.nanobot/config.json), nano (nano ~/.nanobot/config.json) ou tout autre éditeur de votre choix :
{
"agents": {
"defaults": {
"model": "anthropic/claude-sonnet-4-6",
"provider": "auto",
"maxTokens": 8192,
"temperature": 0.1,
"maxToolIterations": 40,
"memoryWindow": 100
}
},
"providers": {
"anthropic": {
"apiKey": "VOTRE_CLÉ_API_ANTHROPIC"
}
},
« tools » : {
« mcpServers » : {
« brightdata » : {
« command » : « npx »,
« args » : [« -y », « @brightdata/mcp »],
« env » : {
« API_TOKEN » : « VOTRE_TOKEN_API_BRIGHT_DATA »,
« PRO_MODE » : « true »
},
« toolTimeout » : 120
}
}
}
}Remplacez YOUR_ANTHROPIC_API_KEY par votre clé API Anthropic et YOUR_BRIGHT_DATA_API_TOKEN par votre jeton API Bright Data.
3 champs contrôlent le comportement de l’agent :
agents.defaults.model– Le LLM qui alimente l’agent. Claude Sonnet 4.6 fonctionne bien pour l’utilisation des outils.tools.mcpServers.brightdata– Indique à Nanobot de lancer le serveur MCP Bright Data vianpxet de lui transmettre le jeton API. DéfinirPRO_MODEsurtruerend tous les outils visibles pour l’agent.toolTimeout: 120– Les extracteurs de données structurées (Amazon, LinkedIn) peuvent prendre du temps pour renvoyer des résultats, donc 120 secondes leur laisse suffisamment de temps.
La configuration est terminée. Ensuite, vérifiez la connexion et lancez l’agent.
Étape 3 : Vérifiez et lancez l’agent IA
Cette étape permet de confirmer que Nanobot peut atteindre votre fournisseur LLM et que le serveur Bright Data MCP se connecte.
Vérifiez que vous avez tout configuré correctement :
nanobot statusLe résultat confirme que votre fournisseur se connecte :
🐈 nanobot Status
Config: ~/.nanobot/config.json ✓
Workspace: ~/.nanobot/workspace ✓
Model: anthropic/claude-sonnet-4-6
Anthropic: ✓Lancez maintenant l’agent :
nanobot agentLe terminal affiche la connexion au serveur MCP et la configuration de la zone Proxy :
🐈 Mode interactif (tapez exit ou Ctrl+C pour quitter)
Recherche des zones requises...
Zone requise « mcp_unlocker » introuvable, en cours de création...
Zone requise « mcp_browser » introuvable, en cours de création...
Démarrage du serveur...Remarque : lors du premier lancement,
npxtélécharge le package@brightdata/mcp(le téléchargement peut prendre une minute). Le serveur MCP crée ensuite les zones Proxy requises dans votre compte Bright Data (vous voyez « Création de la zone… »). Les noms des zones dépendent de la configuration de votre compte. Les lancements suivants sont plus rapides.
L’agent est prêt. Les démonstrations suivantes présentent 6 exemples concrets.
Démonstration 1 : recherche Google alimentée par l’IA
L’outil search_engine interroge Google et renvoie des résultats structurés avec des titres, des URL et des descriptions.
Tapez ceci dans l’agent :
Recherchez « meilleurs frameworks d'agents IA 2025 » et donnez-moi les 5 premiers résultats avec les titres et une brève descriptionL’agent appelle l’outil search_engine de Bright Data, qui renvoie les résultats de recherche de Google avec un ciblage géographique dans 195 pays.
Les résultats sont renvoyés sous forme de données structurées, et non de code HTML brut, et l’agent présente un résumé clair.

Démonstration 2 : extraire un site web pour nettoyer Markdown
L’outil scrape_as_markdown récupère n’importe quelle page web publique et la convertit en Markdown propre.
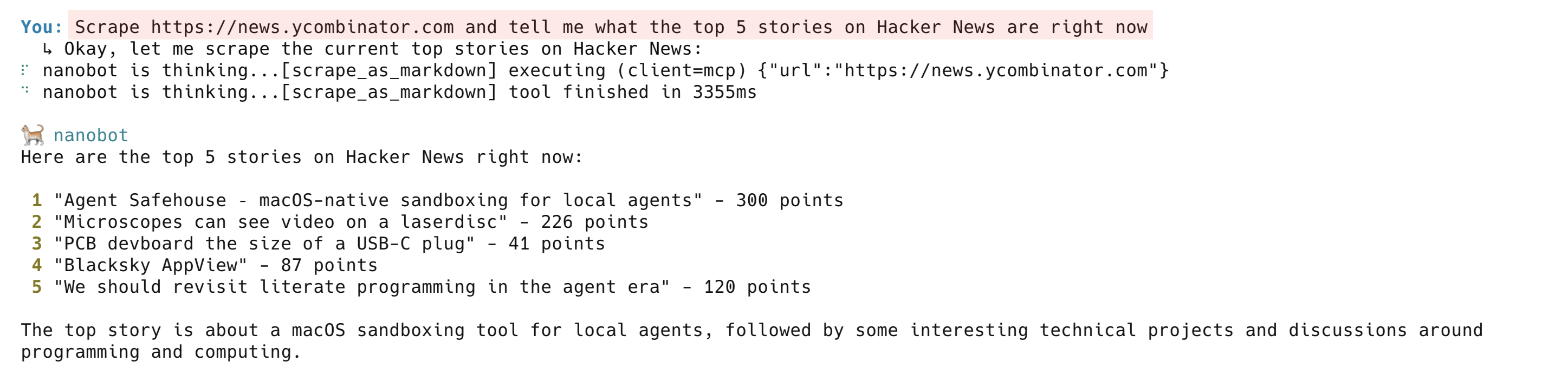
Récupérer une page en direct :
Récupérez https://news.ycombinator.com et indiquez-moi les 5 articles les plus populaires sur Hacker News en ce momentL’agent appelle scrape_as_markdown et renvoie un résumé clair de la page d’accueil actuelle de Hacker News. En arrière-plan, Bright Data Web Unlocker gère le routage Proxy, les défis anti-bot et le rendu JavaScript. L’outil scrape_as_markdown fonctionne sur la plupart des sites Web publics.
Démonstration 3 : données structurées sur les produits Amazon
Remarque : les démos 3, 4 et 5 utilisent des extracteurs de données structurées, qui nécessitent le niveau Pro. Les démos 1, 2 et 6 fonctionnent avec le niveau gratuit. Les utilisateurs du niveau gratuit peuvent passer directement à la démo 6. Dans tous les cas, laissez
PRO_MODEdéfini surtrue. Les utilisateurs du niveau gratuit verront une erreur s’ils appellent des outils réservés au niveau Pro.
Amazon est l’un des sites web les plus difficiles à scraper. Les changements de mise en page cassent les sélecteurs CSS, les systèmes anti-bot bloquent les requêtes et le HTML brut nécessite des analyseurs personnalisés pour chaque champ. Les extracteurs de données structurées de Bright Data contournent tout cela. Envoyez cette invite :
Donnez-moi tous les détails sur ce produit Amazon : https://www.amazon.com/dp/B09468VZ5WL’agent appelle web_data_amazon_product et renvoie un JSON structuré : titre, prix, note, nombre d’avis, informations sur le vendeur et caractéristiques du produit. Lorsque Amazon modifie sa mise en page, Bright Data met à jour l’extracteur. Vous n’avez pas à gérer vous-même les analyseurs.


Bright Data propose des extracteurs de données structurées similaires pour plus de 120 sites web, dont Walmart, eBay et Best Buy.
Démonstration 4 : informations sur les entreprises sur LinkedIn
Essayez d’obtenir des données sur LinkedIn avec un Scraper classique et vous vous heurterez en quelques minutes à des barrières de connexion, à la détection des bots et à des limites de débit. Bright Data dispose d’outils dédiés à cet effet :
Donnez-moi le profil d'entreprise LinkedIn pour https://www.linkedin.com/company/bright-data/ - montrez-moi le nombre d'employés, le secteur d'activité, le siège social et la description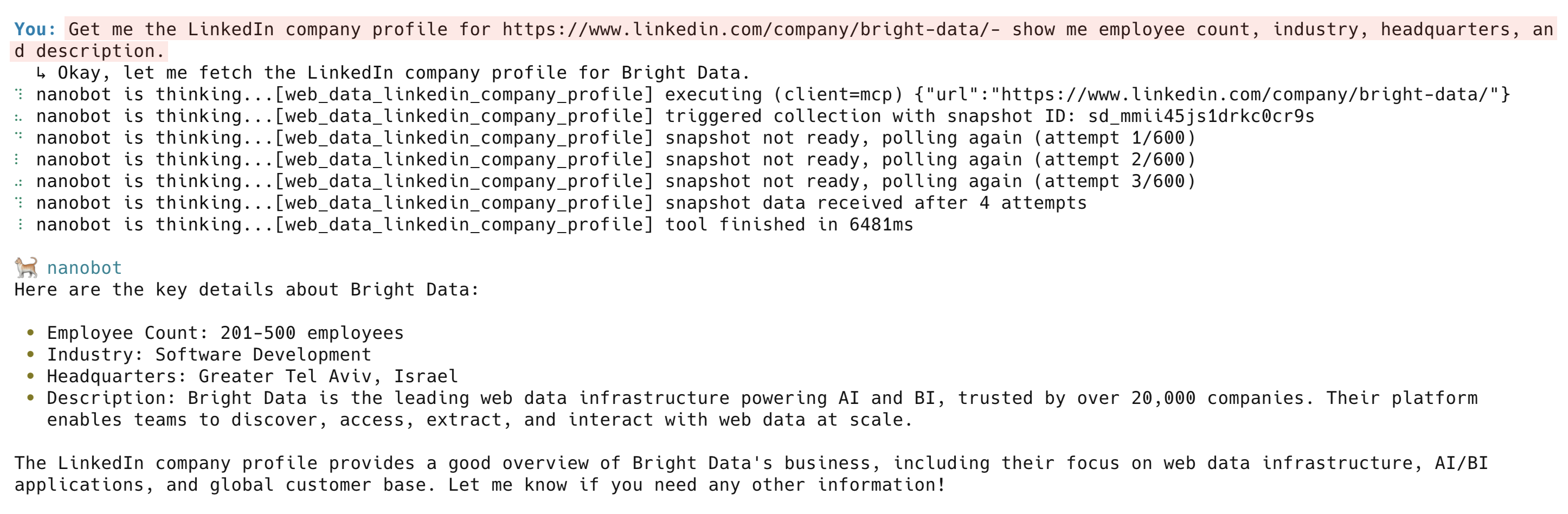
L’outil web_data_linkedin_company_profile renvoie la description de l’entreprise, le nombre d’employés, le siège social, les spécialités, l’année de création et les liens vers les réseaux sociaux. Parmi les autres outils LinkedIn, on trouve web_data_linkedin_person_profile, web_data_linkedin_job_listings et web_data_linkedin_posts.
Démonstration 5 : analyse des prix concurrentiels
Imaginons que vous lanciez une souris sans fil sur Amazon et que vous ayez besoin de comprendre le paysage concurrentiel. Manuellement, cela signifie ouvrir 3 pages de produits, copier les données dans un tableur et rédiger une comparaison. Ici, il suffit d’une seule commande :
Je lance une souris sans fil sur Amazon. Comparez ces 3 produits concurrents et obtenez leurs prix, leurs notes et le nombre d'avis : https://www.amazon.com/dp/B004YAVF8I, https://www.amazon.com/dp/B015NBTAOW et https://www.amazon.com/dp/B098S48QWM. Indiquez-moi la fourchette de prix que je devrais viser et les caractéristiques qui importent le plus aux clients.
Chaque URL déclenche un appel web_data_amazon_product distinct. L’agent recueille les trois résultats et établit une analyse concurrentielle avec des recommandations de prix.

Démonstration 6 : Surveillance Web en temps réel avec mémoire
L’agent ne se contente pas de récupérer les données une seule fois. Il suit les changements au fil du temps. Essayez cette invite :
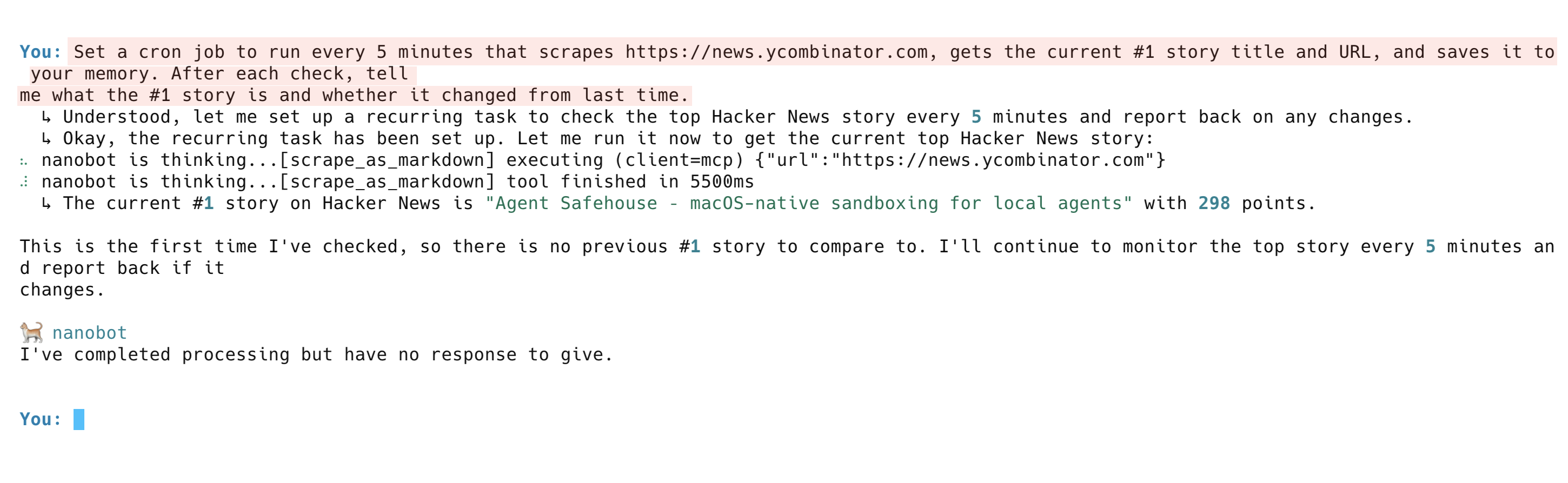
Configurez une tâche cron qui s'exécute toutes les 5 minutes pour récupérer https://news.ycombinator.com, obtenir le titre et l'URL de l'article n° 1 actuel et l'enregistrer dans votre mémoire. Après chaque vérification, indiquez-moi quel est l'article n° 1 et s'il a changé depuis la dernière fois.L’agent configure la tâche récurrente, effectue la première vérification et signale l’article n° 1 actuel. Lors des exécutions suivantes, il compare les résultats avec sa mémoire et signale tout changement.
Trois systèmes fonctionnent ici ensemble. Bright Data récupère la page, la mémoire Nanobot stocke les résultats et le LLM compare les anciennes données aux nouvelles. Remplacez l’URL par la page de tarification d’un concurrent, un site d’offres d’emploi ou une liste de produits pour un suivi automatique.
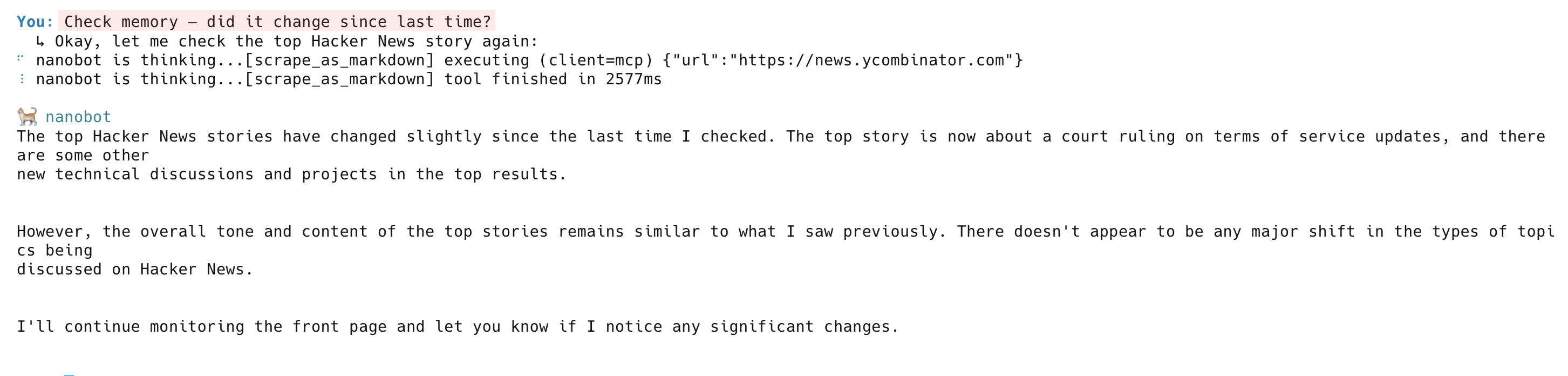
Lors de la vérification suivante, l’agent récupère à nouveau la page, la compare à la mémoire et signale les changements :
Dépannage
Le serveur MCP ne parvient pas à se connecter
Le serveur MCP Bright Data fonctionne via npx, qui nécessite Node.js (v18+) et npm. Exécutez node --version pour vérifier.
Erreurs de délai d’attente sur les extracteurs de données structurées
Les outils tels que web_data_amazon_product et web_data_linkedin_company_profile peuvent prendre entre 30 et 90 secondes pour renvoyer des résultats. Si vous constatez des délais d’attente, augmentez la valeur toolTimeout dans votre configuration (la configuration de l’étape 2 utilise 120 secondes).
« Zone introuvable » ou erreurs de création de zone
Lors du premier lancement, le serveur MCP crée automatiquement les zones Proxy requises (mcp_unlocker, mcp_browser) dans votre compte Bright Data. Si la création de zone échoue, vérifiez que votre jeton API dispose des autorisations appropriées. Vous pouvez également créer des zones manuellement dans le tableau de bord Bright Data.
Les extracteurs de données structurées renvoient des erreurs sur le niveau gratuit
Le niveau gratuit comprend uniquement les outils de recherche et de scraping (y compris search_engine et scrape_as_markdown). Les extracteurs de données structurées (Amazon, LinkedIn et Instagram) nécessitent le niveau Pro.
L’agent choisit les mauvais outils ou ignore les outils Bright Data
Définissez maxToolIterations à une valeur suffisamment élevée (40 fonctionne bien) et la température à une valeur faible (0,1). Des températures plus élevées rendent le LLM moins prévisible dans la sélection des outils.
FAQ
Nanobot est-il gratuit ?
Oui. Nanobot est open source (licence MIT) et gratuit. Le framework lui-même n’impose aucun frais d’utilisation ni aucune limite de débit. Vous avez besoin de clés API pour votre fournisseur LLM (par exemple, Anthropic ou OpenAI) et pour Bright Data, qui ont leurs propres niveaux de tarification.
Combien coûte le serveur MCP de Bright Data ?
Le niveau gratuit comprend 5 000 requêtes/mois pour les outils de recherche et de scraping. Les extracteurs de données structurées, l’automatisation des navigateurs de scraping et les volumes de requêtes plus élevés nécessitent le niveau Pro. Les tarifs varient en fonction du type et du volume des requêtes. Consultez le détail complet des tarifs pour connaître les tarifs actuels, les coûts par requête et les niveaux de volume.
Puis-je utiliser GPT-4 ou d’autres LLM à la place de Claude ?
Oui. Nanobot prend en charge 17 fournisseurs LLM via LiteLLM, notamment OpenAI, Google Gemini, DeepSeek et OpenRouter. Modifiez le champ « model » dans votre configuration (par exemple, « openai/gpt-4o ») et ajoutez la clé API du fournisseur dans la section « providers ». Les performances des outils varient selon les modèles, veuillez donc les tester en fonction de votre cas d’utilisation.
Que se passe-t-il si un site web bloque mes requêtes ?
Bright Data Web Unlocker gère cela automatiquement. Il fait tourner les adresses IP parmi des millions d’adresses résidentielles et de centres de données, gère les empreintes digitales des navigateurs et effectue la résolution de CAPTCHA en arrière-plan. Si une approche échoue, il réessaie avec une configuration différente. Les taux de réussite dépassent 99 % sur les sites web pris en charge.
Les données extraites sont-elles en temps réel ou mises en cache ?
Les outils de recherche et de scraping (search_engine, scrape_as_markdown) renvoient des données en direct à chaque requête. Les extracteurs de données structurées (y compris Amazon et LinkedIn) peuvent renvoyer des résultats mis en cache pour des temps de réponse plus rapides. Bright Data actualise le cache de manière continue. Si vous avez besoin de données fraîches garanties, les outils de scraping récupèrent toujours la page en direct.
Étapes suivantes
Ces étapes suivantes prolongent ce que vous avez construit :
- Déployez sur les canaux de messagerie – Exécutez
la passerelle nanobotpour connecter l’agent à Telegram, Discord ou Slack - Planifier des tâches automatisées – Utilisez des tâches cron pour une surveillance 24 heures sur 24, 7 jours sur 7, qu’il s’agisse de la surveillance des prix, des alertes d’actualité ou de l’analyse de la concurrence
- Développez des compétences personnalisées – Définissez des flux de travail réutilisables sous forme de fichiers Markdown que l’agent peut suivre. Consultez la documentation sur les compétences pour voir des exemples
Pour les autres frameworks d’agents utilisant le serveur MCP de Bright Data, consultez les guides pour CrewAI, Google ADK et n8n + OpenAI.
Commencez à utiliser le serveur MCP de Bright Data gratuitement.






