

Dans ce tutoriel, vous apprendrez :
- Ce qu’est AWS Glue et ce qu’il offre.
- Pourquoi Bright Data prend en charge les pipelines ETL grâce à ses services de récupération de données web.
- Comment intégrer Bright Data dans une tâche ETL dans AWS Glue.
C’est parti !
Qu’est-ce qu’AWS Glue ?
AWS Glue est un service d’intégration de données sans serveur conçu pour simplifier le processus de découverte, de préparation et de combinaison de données provenant de plusieurs sources à n’importe quelle échelle.
Il vous permet de créer des workflows ETL (Extract, Transform, Load) pour l’analyse, l’apprentissage automatique et le développement d’applications sans avoir à gérer l’infrastructure. AWS Glue accélère le développement des pipelines de données et rend les données facilement accessibles pour l’analyse. Pour ce faire, il centralise votre catalogue de données et fournit des outils de création de tâches visuels et basés sur du code.
Les trois fonctionnalités les plus pertinentes qu’il offre sont les suivantes :
- Découvrir et organiser les données: déduire automatiquement les schémas, cataloguer les métadonnées et se connecter aux sources de données sur AWS, sur site et dans d’autres clouds.
- Transformer et nettoyer les données: éditeur de tâches visuel, carnets interactifs, prise en charge ETL en continu et déduplication intégrée basée sur le ML.
- Créer et surveiller des pipelines: planifiez, automatisez et adaptez les tâches, avec la possibilité de surveiller les pipelines grâce à des informations détaillées et des déclencheurs.
Pour en savoir plus, consultez la documentation officielle.
Pourquoi intégrer Bright Data à votre workflow ETL AWS Glue
L’intégration de Bright Data dans un workflow ETL AWS peut considérablement élargir la portée et améliorer la qualité de vos pipelines de données.
Alors que l’ETL se concentre traditionnellement sur l’extraction de données structurées à partir de sources connues, Bright Data permet d’accéder à des données web structurées en temps réel. Cela permet d’obtenir des informations qui, autrement, nécessiteraient une collecte manuelle ou une Infrastructure de scraping complexe.
Au-delà de l’extraction de données web riches (E), Bright Data peut également améliorer votre phase de transformation (T). Pendant la transformation, vous pouvez enrichir vos Jeux de données en ajoutant des informations en temps réel sur le marché, les produits ou les réseaux sociaux à vos enregistrements. Par exemple, vous pouvez ajouter des indicateurs de performance boursière, les prix des concurrents ou des métadonnées sur les entreprises à vos Jeux de données internes.
Ces informations aident les équipes à prendre des décisions plus éclairées. La vérification des données est un autre avantage clé, car les données extraites peuvent être recoupées avec des sources faisant autorité. Cela vous aide à garantir l’exactitude des données avant de les charger dans votre magasin de données cible.
Comment utiliser Bright Data pour récupérer des données Web pour une tâche ETL AWS Glue
Cette section guidée présente une intégration possible de Bright Data dans une tâche ETL AWS Glue. Plus précisément, vous verrez comment créer cet exemple de pipeline ETL :
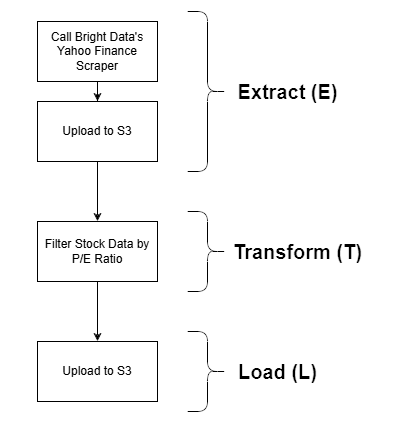
Bright Data entre en jeu dans la phase d’extraction (E), grâce à ses puissantes options de récupération de données web. Le Scraper Yahoo Finance est utilisé pour récupérer les données boursières, qui sont ensuite filtrées par ratio P/E et finalement stockées dans un bucket S3. Il s’agit d’un exemple simple, mais qui constitue néanmoins une démonstration réaliste d’un workflow ETL complet.
Remarque: d’autres approches d’intégration de Bright Data dans AWS Glue peuvent être explorées et envisagées après ce tutoriel.
Suivez les instructions ci-dessous pour commencer !
Prérequis
Avant de suivre ce tutoriel, assurez-vous d’avoir configuré les éléments suivants :
- Un compte AWS (même un compte d’essai gratuit fera l’affaire).
- Un compte Bright Data avec une clé API configurée. Suivez les instructions officielles pour générer votre clé API.
- Un compartiment S3 défini dans votre compte AWS.
- Des connaissances de base en Python pour écrire un script qui s’intègre aux API de scraping de Bright Data et télécharge les données scrapées vers votre compartiment S3.
- Des compétences de base en SQL pour écrire une requête simple dans la phase Transform (T) du pipeline ETL.
Pour ce tutoriel, nous supposerons que votre compartiment S3 s’appelle bright-data-etl-bucket:
Il est également utile de se familiariser avec le fonctionnement des API de Scraping web de Bright Data.
Étape n° 1 : Démarrer avec les API de scraping Bright Data
Lors du développement d’un pipeline ETL, vous devez évidemment commencer par la phase d’extraction (E). La première étape consiste à récupérer les données à l’aide du Scraper Yahoo Finance de Bright Data. Il est donc important de vous familiariser avec cet outil.
Commencez par créer un compte Bright Data, si vous n’en avez pas déjà un. Sinon, connectez-vous à votre compte existant. Dans le panneau de configuration, accédez à la section «Web Scrapers »:
Ensuite, allez dans l’onglet « Web Scrapers Library ». Recherchez « finance » et sélectionnez l’option « Yahoo Finance Scraper ». Accédez au Scraper disponible :
Sur la page Yahoo Finance Scraper, vous pouvez explorer les exigences d’entrée et le schéma de sortie de ce Scraper :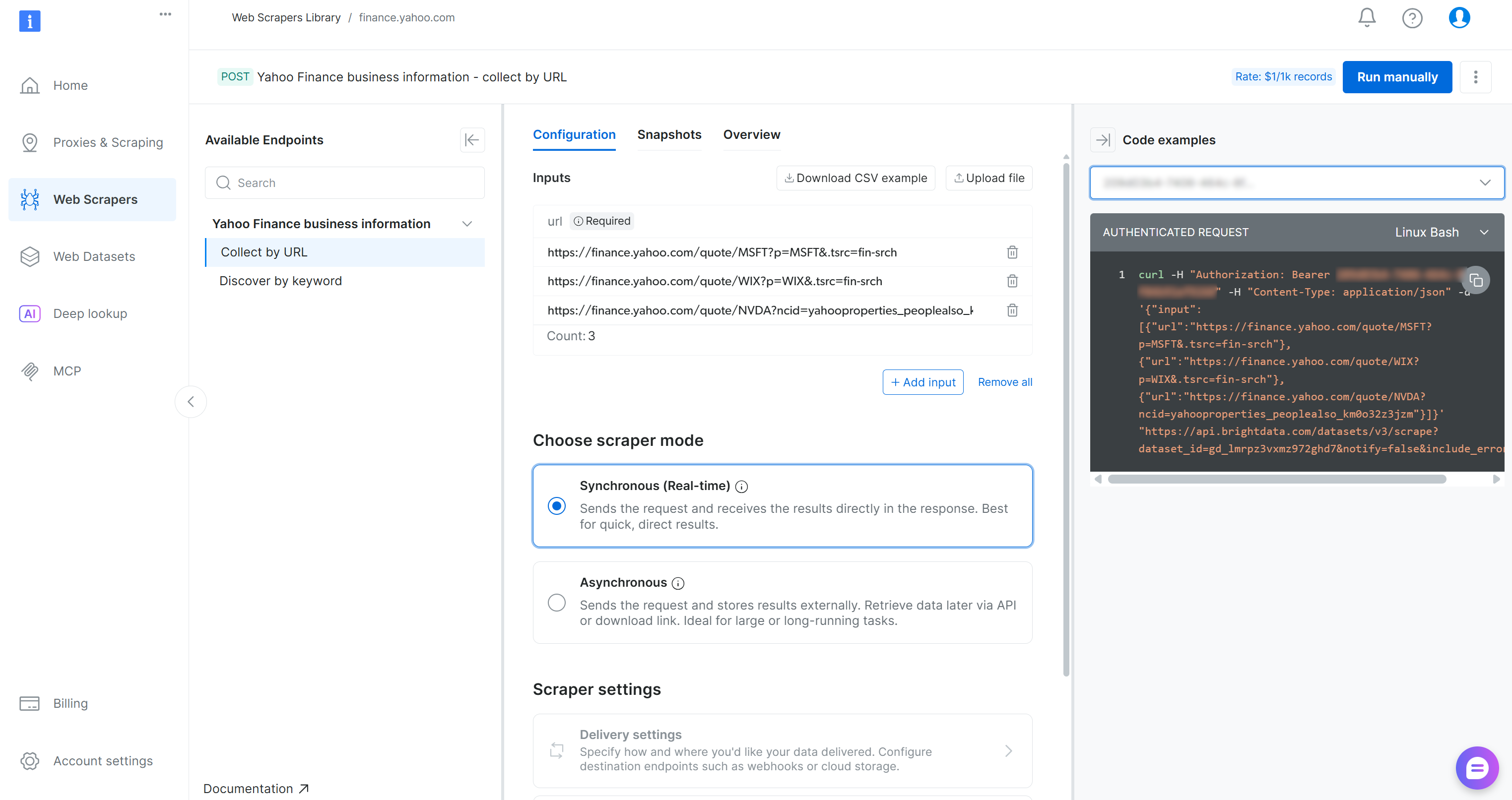
Le panneau de contrôle fournit également des extraits de code dans plusieurs langages de programmation pour une configuration rapide. Le point essentiel est que le Scraper accepte une ou plusieurs pages boursières Yahoo Finance en entrée et renvoie des données boursières structurées en temps réel. Parfait !
Étape n° 2 : configurer la livraison S3
Les API de Scraping web de Bright Data prennent en charge la livraison automatique des données scrapées vers Amazon S3. Il est donc logique de tirer parti de cette fonctionnalité utile pour accélérer l’étape de collecte des données. Pour configurer la livraison Amazon S3, vous devez d’abord activer le mode asynchrone.
Dans l’onglet « Configuration », sélectionnez l’option « Asynchrone ». Cliquez ensuite sur le bouton « Paramètres de livraison » :
Configurez la livraison des données vers votre compartiment Amazon S3 en remplissant le formulaire comme suit :
- Activez le bouton « Activer la livraison ».
- Définissez le format sur
JSON. - Sélectionnez « Amazon S3 » comme destination de stockage.
- Saisissez le nom de votre compartiment S3 (dans cet exemple,
bright-data-etl-bucket). (Le champ URL du point de terminaison peut être laissé vide.) - Laissez le champ « Chemin cible » vide pour télécharger le fichier dans le dossier racine du compartiment.
- Définissez l’option « Type d’authentification » sur la valeur « Clés d’accès ».
- Collez votre ID de clé d’accès AWS et votre clé d’accès secrète AWS.
- Définissez le nom du fichier sur
stocks.
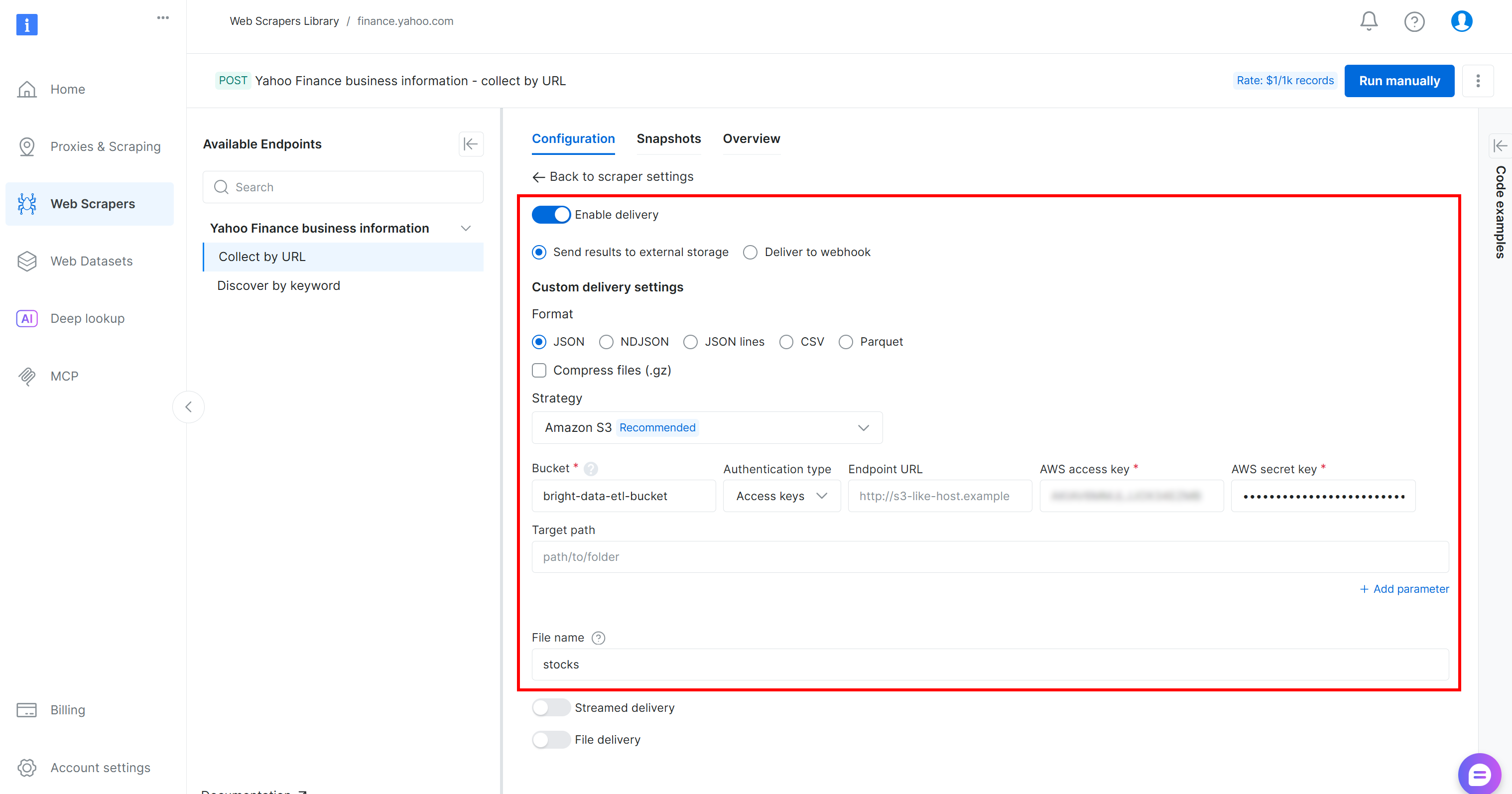
Avec cette configuration, l’API de Scraping web fonctionnera en mode asynchrone. Cela signifie que Bright Data créera une tâche de scraping qui s’exécutera sur son infrastructure de scraping. Une fois la tâche terminée, les données scrapées seront automatiquement téléchargées vers votre compartiment Amazon S3, où elles seront accessibles par votre tâche ETL AWS Glue. Incroyable !
Étape n° 3 : exécutez la logique d’extraction de données Web
Pour vérifier que la logique d’extraction de données Web fonctionne, ajoutez quelques URL de titres boursiers Yahoo Finance (par exemple, NVDA, AAPL, GOOGL, MSFT, AMZN, TSLA, META, AVGO, BRK.B, LLY) et appuyez sur le bouton « Exécuter manuellement » :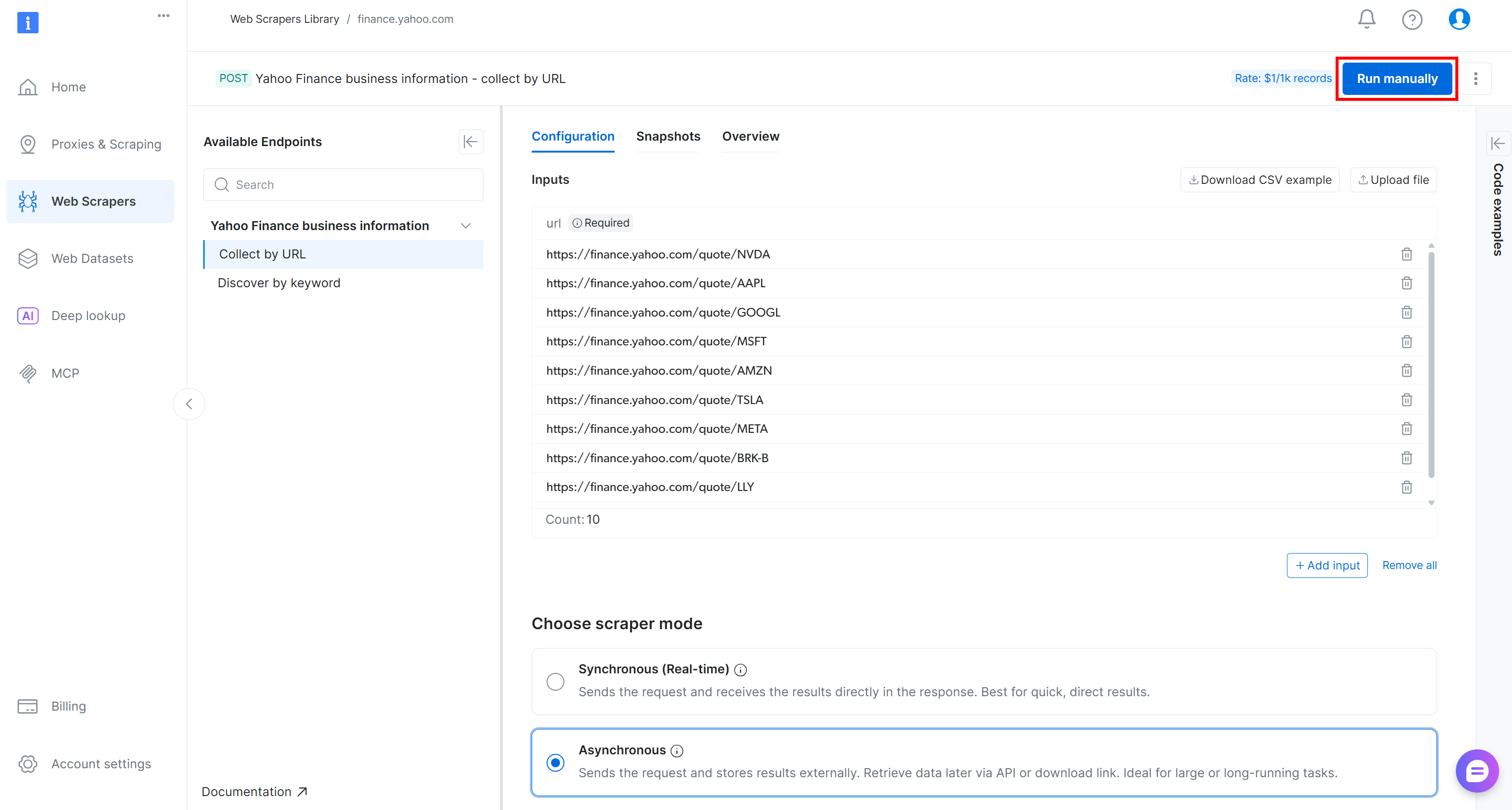
La requête API de scraping sera envoyée et la tâche de scraping démarrera sur le cloud. Vous pouvez surveiller l’état de la tâche en temps réel depuis le panneau de contrôle Bright Data :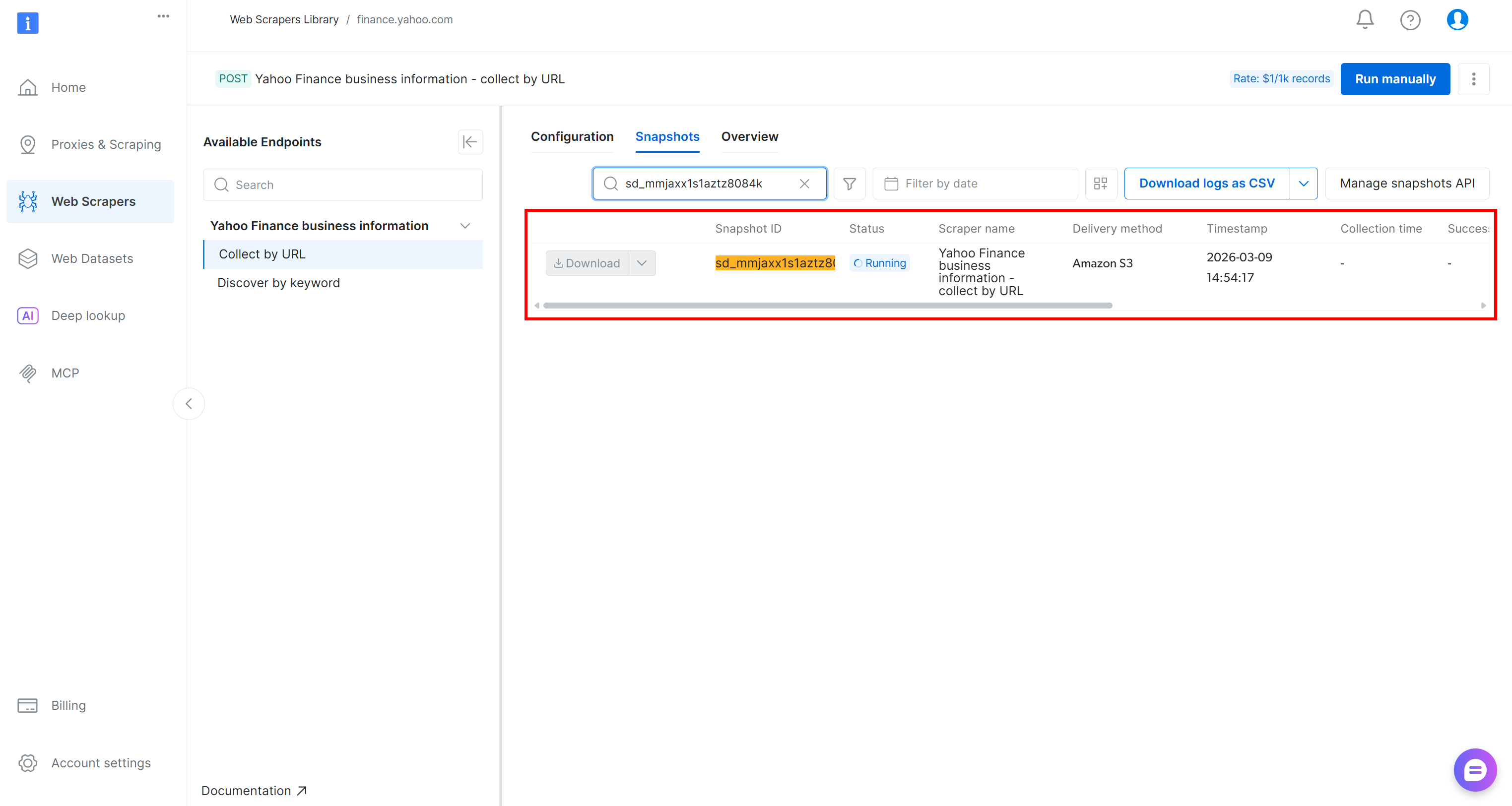
Vous pouvez également obtenir le même résultat par programmation en exécutant l’un des extraits de code disponibles dans la console Bright Data (affichés dans la colonne de droite), en utilisant votre langage de programmation préféré :
Lorsque le statut de la tâche passe à « Prêt », vérifiez votre compartiment AWS S3. Vous devriez voir un nouveau fichier nommé stocks.json:
Si vous ouvrez le fichier stocks.json dans votre navigateur, vous verrez quelque chose comme ceci :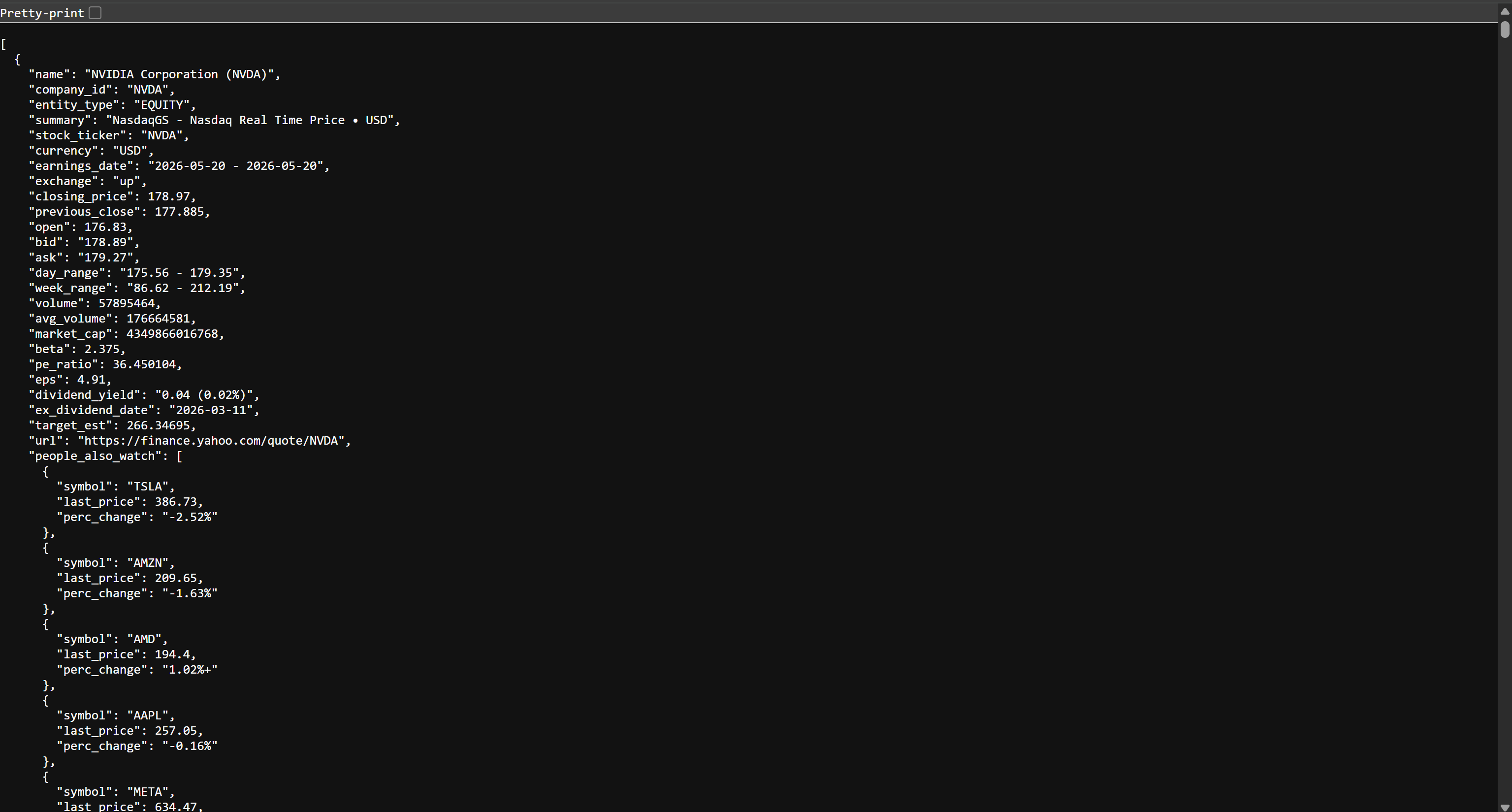
Il s’agit des mêmes données boursières que celles disponibles sur Yahoo Finance, mais structurées au format JSON. Ces données ont été extraites par l’API de Scraping web de Bright Data. Mission accomplie ! Vous disposez désormais des données nécessaires pour créer votre pipeline ETL AWS Glue.
Étape n° 4 : initialisez votre tâche AWS Glue
Connectez-vous à la console AWS et recherchez la chaîne « AWS Glue ». Sélectionnez le service pour ouvrir sa page principale.
À partir de là, cliquez sur le bouton « Go to ETL jobs » (Accéder aux tâches ETL) pour ouvrir AWS Glue Studio, l’interface officielle permettant de créer des workflows ETL :
Ici, vous pouvez initialiser une nouvelle tâche AWS Glue. Pour ce tutoriel, sélectionnez l’option « Visual ETL ». Celle-ci est recommandée pour créer des pipelines via une interface simplifiée de type glisser-déposer.
Vous serez alors redirigé vers une toile vierge, où vous pourrez définir visuellement votre workflow ETL AWS Glue en connectant différents nœuds :
Donnez à votre tâche ETL un nom descriptif, tel que « Tâche ETL Bright Data Glue ». Une fois cela fait, vous êtes prêt à commencer à créer votre pipeline ETL.
Étape n° 5 : créer un rôle IAM
Pour exécuter une tâche AWS Glue, vous devez fournir un rôle IAM pour accéder à des ressources telles qu’Amazon S3 et gérer AWS Glue. Ces autorisations sont requises pour les composants Glue tels que les tâches, les robots d’indexation et les points de terminaison de développement.
Pour créer le rôle directement à partir de Glue Studio, accédez au panneau « Détails de la tâche » et cliquez sur le bouton « Créer un nouveau rôle » :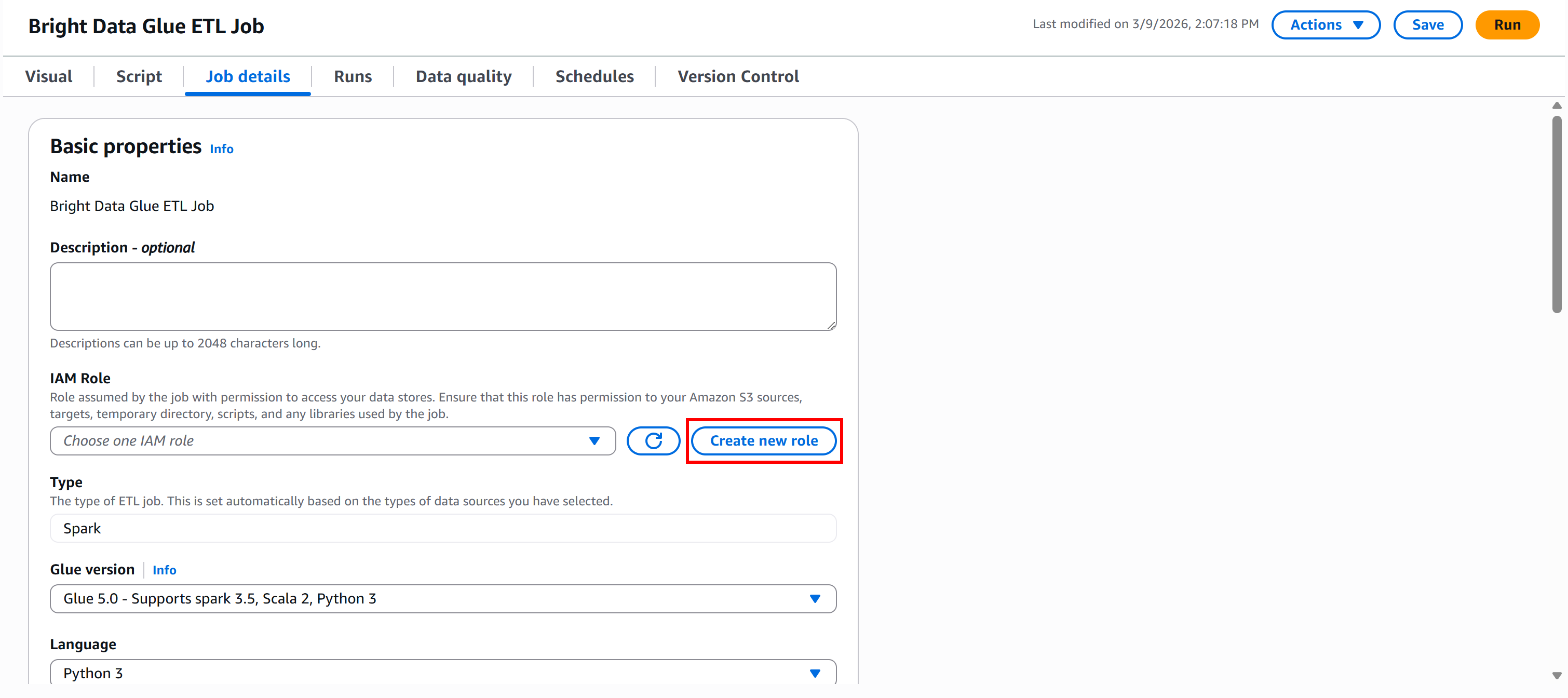
Dans la section « Créer un rôle », donnez à votre rôle IAM un nom descriptif, tel que « bd-glue-role »:
Par défaut, AWS joindra les deux politiques requises :
AWSGlueConsoleFullAccess: fournit un accès complet à AWS Glue via la console de gestion AWS.AWSGlueServiceRole: politique pour le rôle de service AWS Glue, qui permet d’accéder aux services associés, notamment EC2, S3 et Cloudwatch Logs.

Ensuite, récupérez l’ARN de votre compartiment S3. Vous le trouverez sur la page « Propriétés » de votre compartiment dans la console S3 :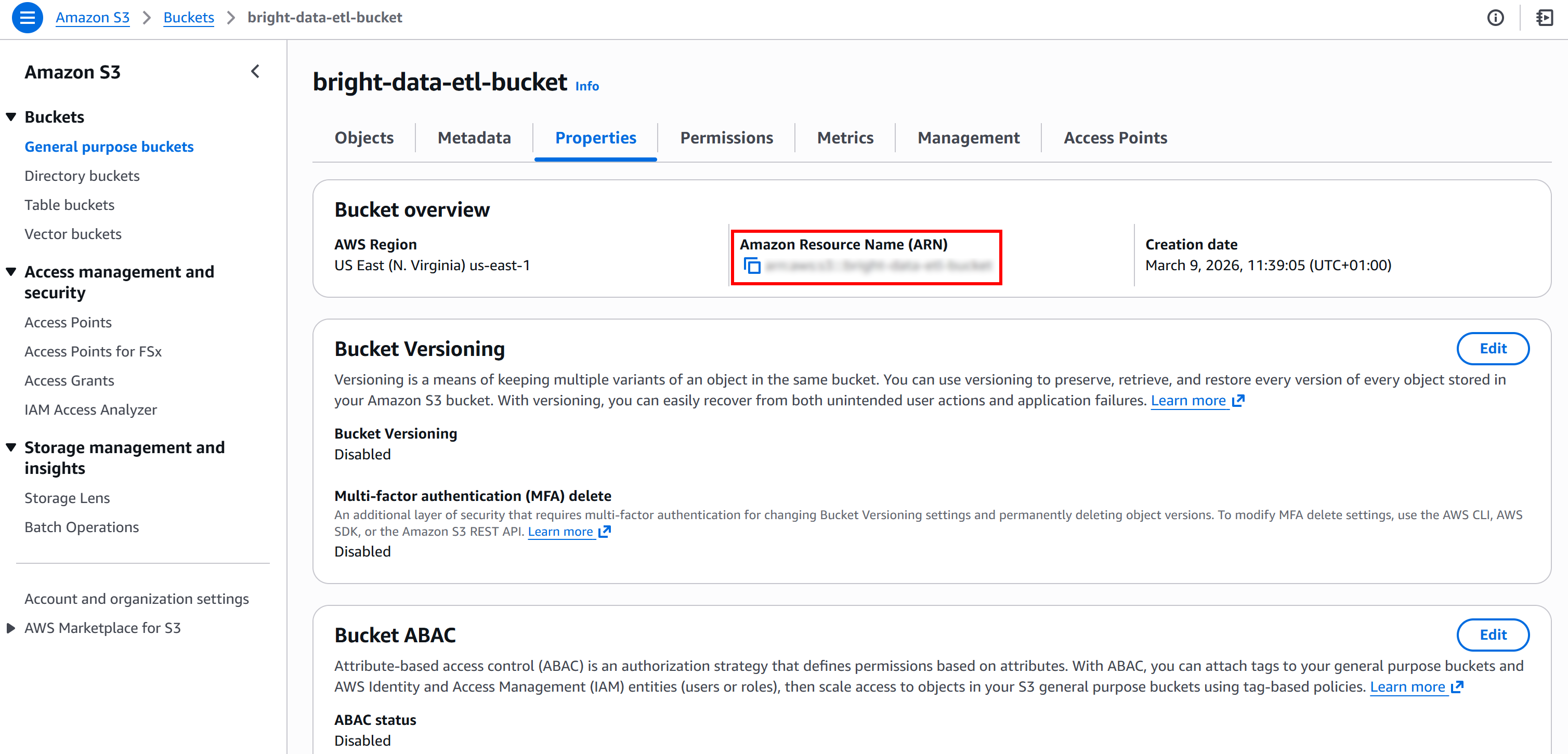
Ces informations sont nécessaires pour remplacer la politique par défaut fournie par AWS Glue. Plus précisément, collez l’ARN du compartiment S3 dans le champ « Ressource » de l’éditeur de texte « Politique supplémentaire » de la page « Créer un rôle » :
« Ressource » : {
« <VOTRE_ARN_DE_BUCKET_S3>/* »
} 
Enfin, cliquez sur le bouton « Créer un rôle ». Une fois le rôle créé, il apparaîtra automatiquement dans la configuration de votre tâche AWS Glue :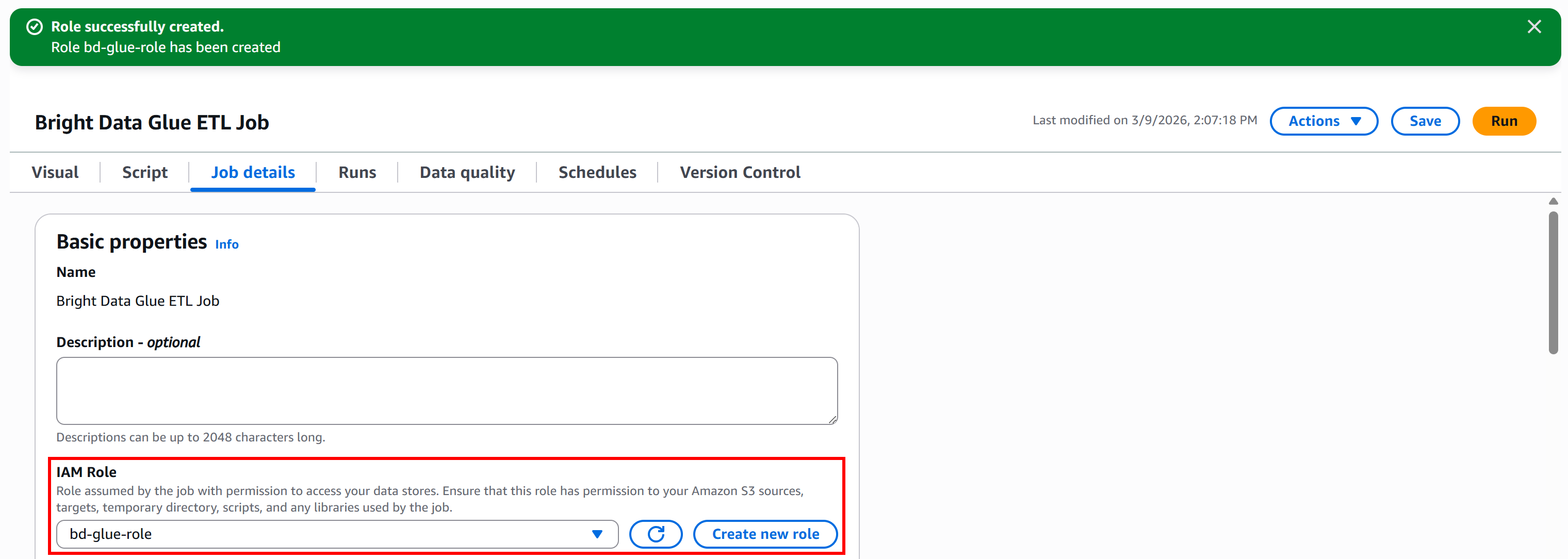
Parfait ! Votre tâche AWS Glue dispose désormais d’un rôle IAM avec les autorisations requises pour accéder à S3 et exécuter votre pipeline ETL.
Étape n° 6 : Ajoutez le nœud Extract (E) à votre pipeline
La phase d’extraction (E) du pipeline a commencé lorsque vous avez exécuté le Scraper Bright Data qui a collecté les données boursières et les a téléchargées vers Amazon S3.
L’objectif est maintenant de connecter votre pipeline ETL AWS Glue à ces données afin qu’elles puissent être traitées. Pour ce faire, accédez à l’onglet « Sources » dans le panneau « Ajouter des nœuds » et sélectionnez le nœud « Amazon S3 ».
Un nœud « Source de données – Compartiment S3 – Amazon S3 » apparaîtra sur le canevas. Cliquez dessus et configurez la source S3 :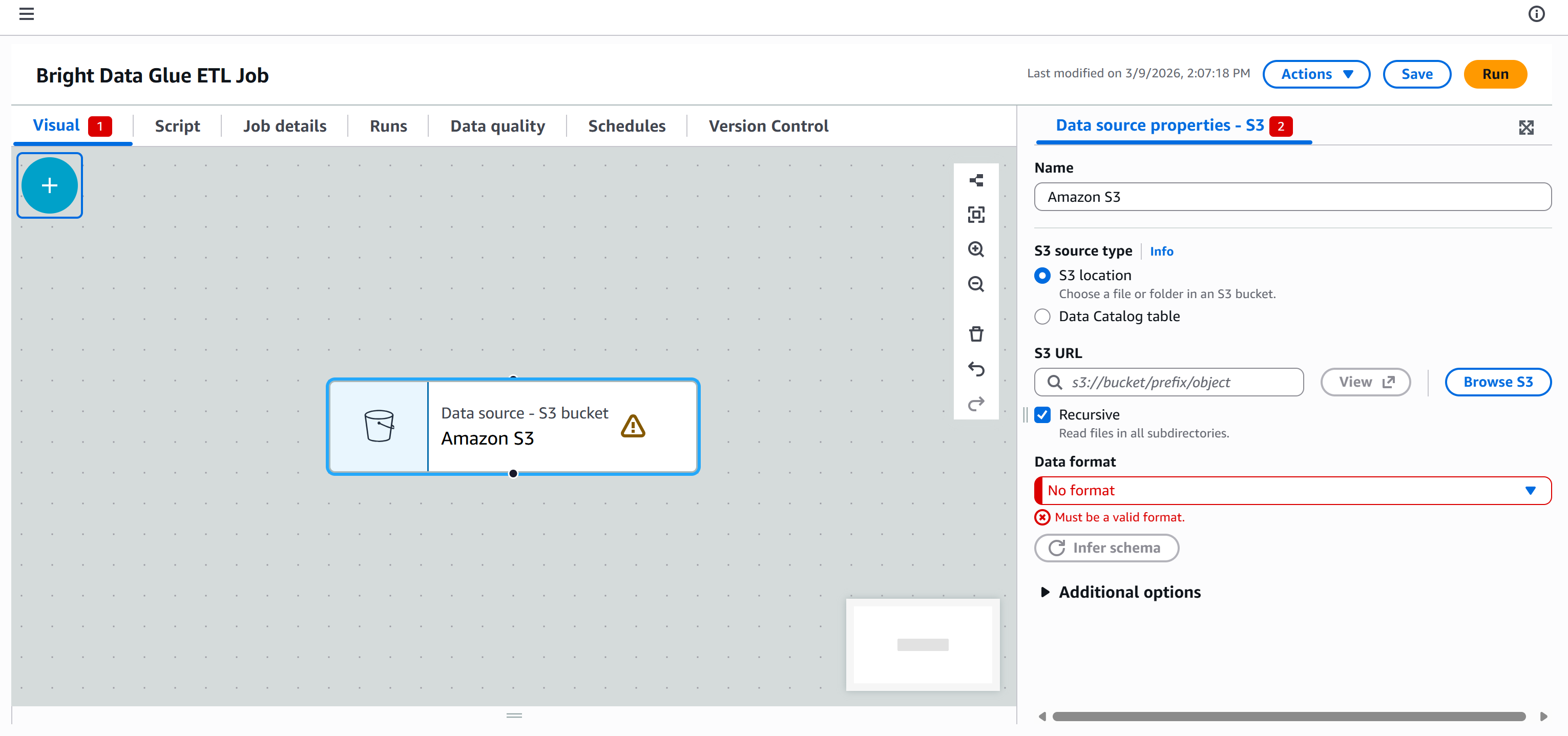
Appuyez sur le bouton « Parcourir S3 » et sélectionnez votre compartiment S3 (par exemple, bright-data-etl-bucket).
Une fois le compartiment sélectionné, AWS Glue remplira le champ « URL S3 » avec une adresse similaire à celle-ci :
s3://bright-data-etl-bucketPar défaut, AWS Glue tente de lire tous les fichiers se trouvant dans le chemin S3 spécifié. Comme nous connaissons le nom exact du fichier d’entrée, mettez à jour le champ « URL S3 » pour pointer directement vers celui-ci :
s3://bright-data-etl-bucket/stocks.jsonCela indique à AWS Glue d’utiliser le fichier stocks.json téléchargé précédemment, qui contient les données extraites avec Yahoo Finance Scraper.
Configurez ensuite le format des données. Comme l’ensemble de données d’entrée est un fichier JSON, sélectionnez « JSON » comme format d’entrée.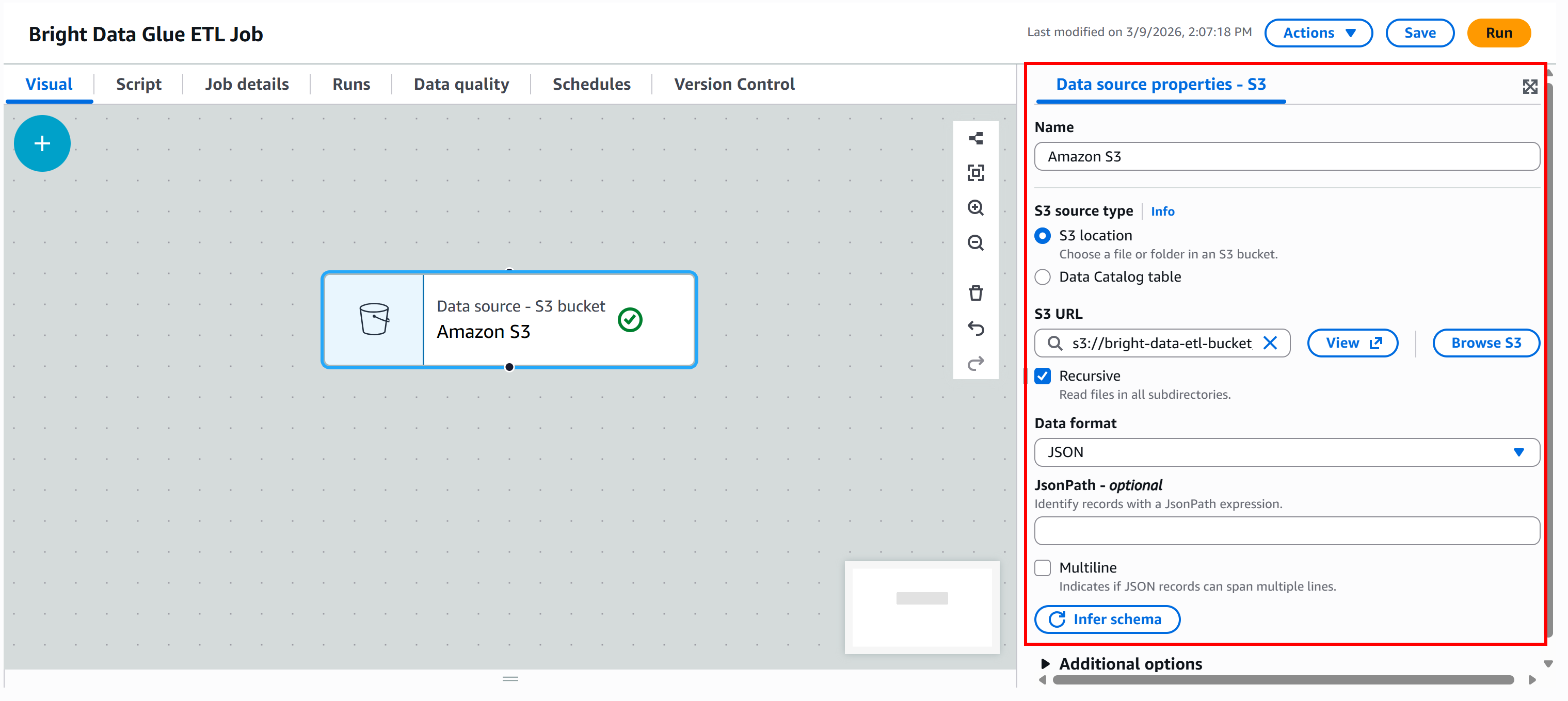
Cliquez ensuite sur le bouton « Déduire le schéma ». AWS Glue analysera automatiquement le fichier JSON d’entrée et générera le schéma correspondant.
Dans la section « Output schema » (Schéma de sortie) du nœud, vous verrez la structure déduite à partir des données JSON :
Le schéma déduit correspond au schéma de données de sortie renvoyé par Bright Data Yahoo Finance Scraper. Super !
Étape n° 7 : définir la logique de transformation (T)
Comme mentionné précédemment, il s’agit d’un exemple simple, donc l’étape de transformation (T) sera réduite au minimum. L’objectif est de filtrer les données source à l’aide d’une requête SQL et de ne conserver que les entreprises dont le ratio C/B est inférieur à 30.
Pour ce faire, allez dans l’onglet « Transformations » et sélectionnez le nœud « Requête SQL » :
Le nœud sera ajouté au canevas. Cliquez dessus et configurez-le de manière à ce que le nœud parent soit « Amazon S3 ». Cela signifie que la sortie du nœud Amazon S3 devient l’entrée du nœud « SQL Query ». En d’autres termes, vous allez exécuter une requête SQL sur les données JSON récupérées.
Ensuite, définissez le nom d’alias du jeu de données d’entrée comme stocks et ajoutez cette requête SQL :
select stock_ticker, pe_ratio from stocks
WHERE pe_ratio < 30;Cette requête sélectionne les champs stock_ticker et pe_ratio de chaque action récupérée, en ne conservant que celles dont le ratio C/B est inférieur à 30.
Si vous vous demandez d’où proviennent ces champs, stock_ticker et pe_ratio sont deux des attributs renvoyés par le Scraper Yahoo Finance de Bright Data (que AWS Glue a automatiquement déduit à l’étape précédente) :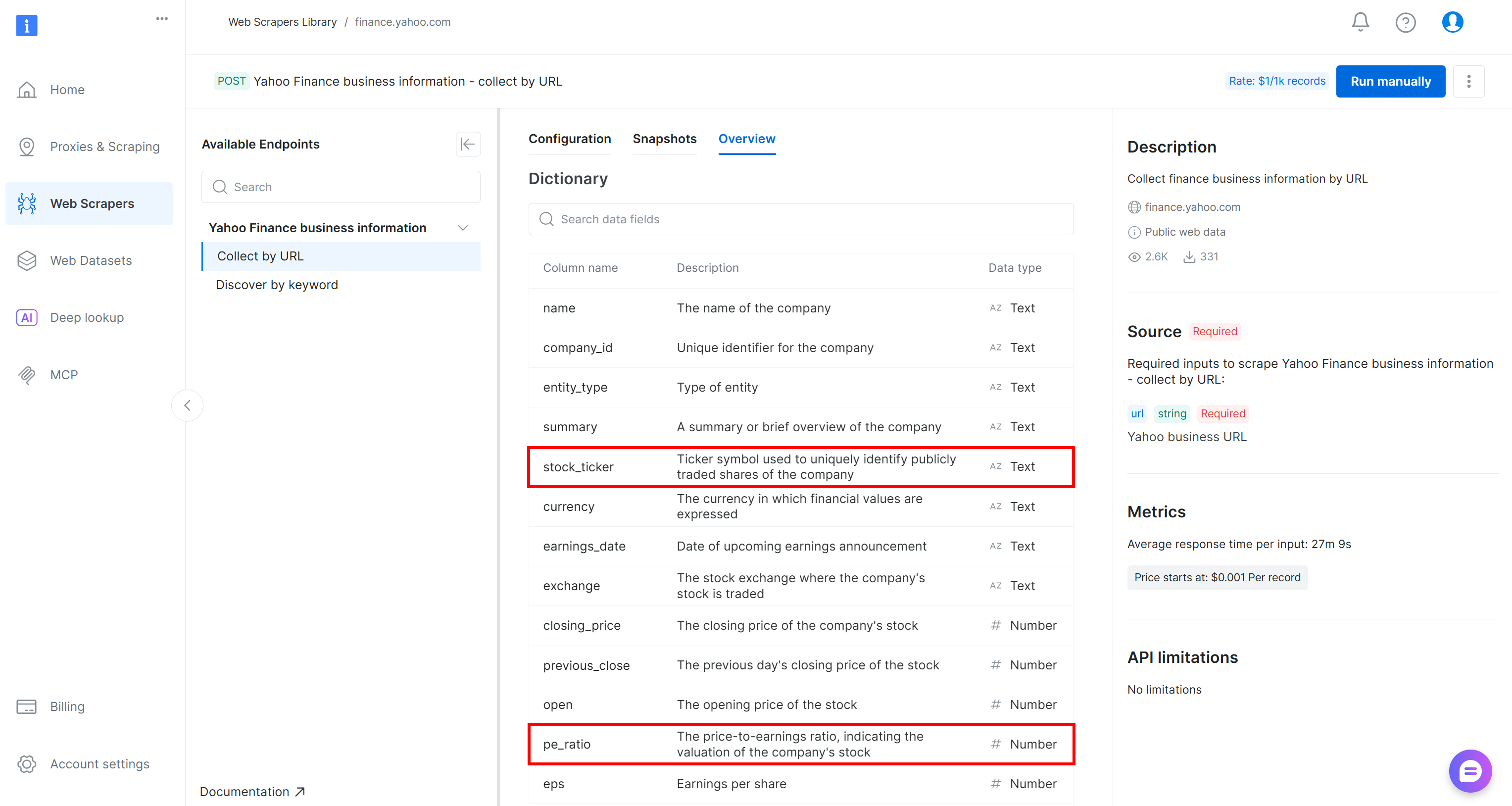
À ce stade, votre pipeline ETL devrait ressembler à ceci :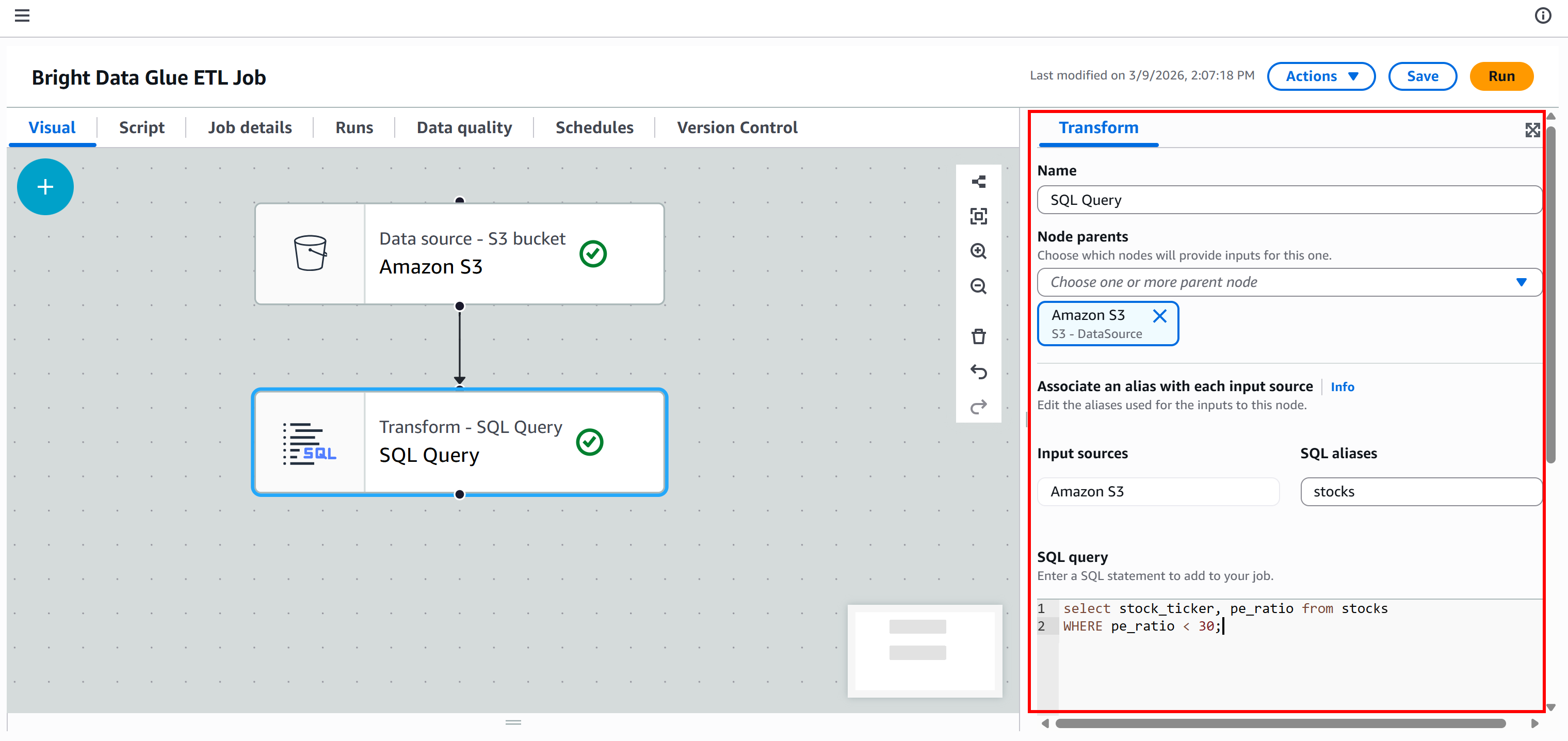
Remarque: dans les pipelines réels, la phase de transformation (T) comprend généralement plusieurs étapes. Vous pouvez les mettre en œuvre en ajoutant plusieurs nœuds de transformation et en les connectant séquentiellement, ou en créant plusieurs branches dans le flux de travail.
Étape n° 8 : connectez-vous à votre compartiment S3 dans la phase de chargement (L)
La sortie de votre nœud « SQL Query » correspond aux données filtrées et transformées. La dernière étape consiste à stocker ces données dans votre compartiment S3 afin de terminer la phase de chargement (L) de votre pipeline ETL.
Dans l’onglet « Targets », ajoutez un autre nœud Amazon S3 :
Cliquez sur le nouveau nœud pour le configurer. Définissez le nœud parent comme étant votre nœud « SQL Query ». La sortie du nœud « SQL Query » sera envoyée en tant qu’entrée au nouveau nœud Amazon S3.
Définissez le format de sortie comme « JSON » sans compression. Ensuite, spécifiez le dossier S3 de sortie cible, par exemple :
s3://bright-data-etl-bucket/output/Remarque: veillez à remplacer bright-data-etl-bucket par le nom de votre bucket S3 réel.
De cette façon, les données transformées seront stockées dans le dossier /output.
Conservez toutes les autres options par défaut, puis appuyez sur « Save » (Enregistrer) pour mettre à jour votre tâche ETL AWS Glue :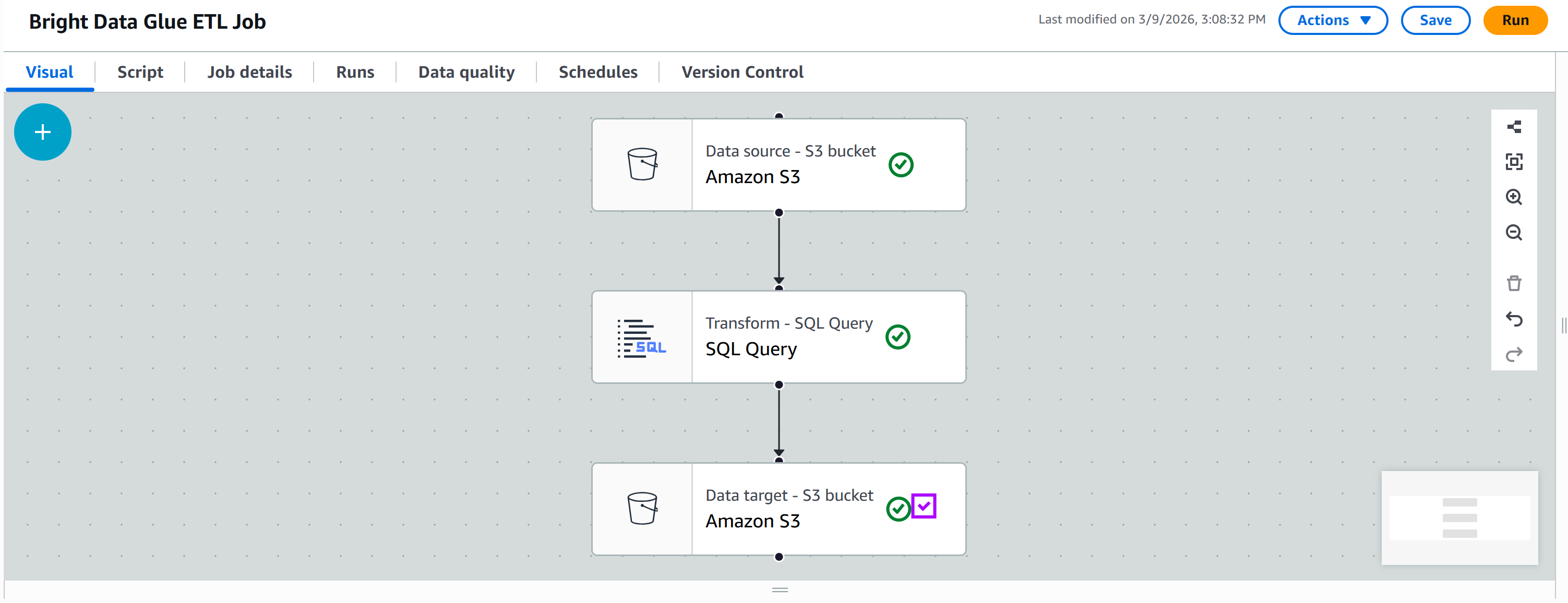
Parfait ! Votre pipeline ETL est désormais entièrement configuré et prêt à être exécuté.
Étape n° 9 : exécutez le pipeline et explorez les résultats
Appuyez sur le bouton « Exécuter » pour lancer votre tâche AWS Glue. Vous devriez voir une notification comme celle-ci :
Accédez à l’onglet « Exécutions » pour surveiller l’exécution de votre pipeline :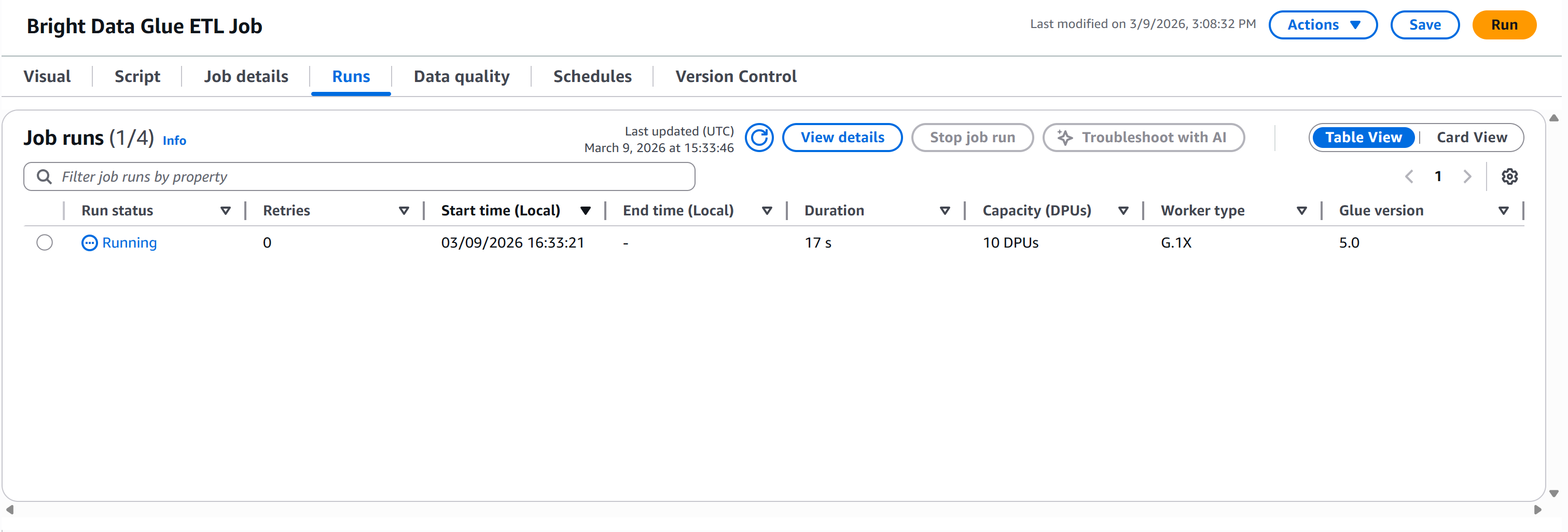
Attendez que le « Run status » (Statut d’exécution) atteigne le statut « Succeeded » (Réussi). Cela peut prendre plus d’une minute, alors soyez patient :
Une fois l’opération terminée, le fichier de sortie apparaîtra dans le dossier /output de votre compartiment S3 :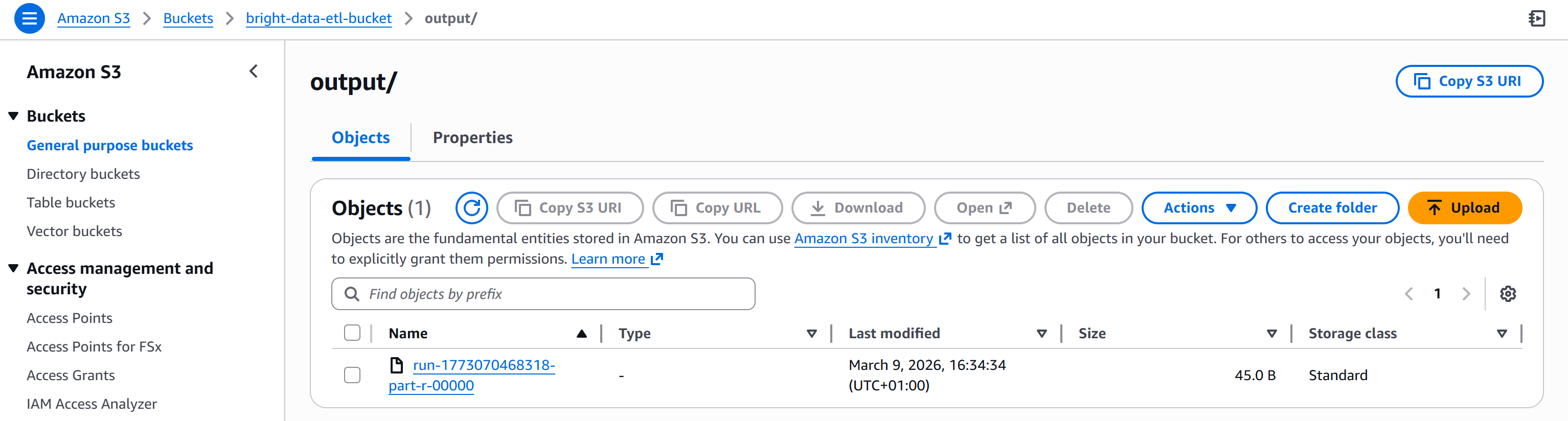
Ouvrez le fichier généré. Vous verrez la liste des actions dont le ratio C/B est inférieur au seuil de votre filtre (par exemple, inférieur à 30) :
Comme vous pouvez le constater, les actions obtenues comprennent AMZN, BRK.B, META, MSFT et GOOGL.
Et voilà ! Vous venez de créer un pipeline ETL AWS Glue intégré à Bright Data. La phase d’extraction utilise les API de Scraping web de Bright Data, la phase de transformation filtre les données avec SQL et la phase de chargement stocke les résultats dans S3.
Autres idées d’intégration de Bright Data dans une tâche ETL AWS Glue
Il ne fait aucun doute que Bright Data peut jouer un rôle majeur dans la phase d’extraction d’un pipeline ETL grâce à ses capacités de récupération de données web.
Cependant, Bright Data peut également être utilisé au-delà de l’extraction, notamment dans la phase de transformation pour l’enrichissement, la validation ou la vérification des données. Par exemple, vous pouvez :
- Améliorer les profils d’entreprise: utilisez ZoomInfo Scraper pour ajouter des données firmographiques aux enregistrements extraits de sources web.
- Valider les informations sur les employés: intégrez les profils LinkedIn pour vérifier les intitulés de poste, les adresses e-mail ou les profils sociaux.
- Récupérer les prix ou les détails des produits des concurrents: utilisez Amazon Scraper ou Amazon Reviews Scraper pour enrichir votre ensemble de données avec des informations sur le marché.
- Ajouter des données SEO ou de recherche : utilisez l’API SERP pour inclure des données de classement des moteurs de recherche ou des informations sur les mots-clés dans votre ensemble de données transformé, ainsi que pour la vérification des données.
Si vous vous demandez comment cette intégration est possible, consultez le guide officiel sur la définition des transformations visuelles personnalisées. Il vous suffit d’inclure un fichier JSON avec les descriptions et un fichier Python contenant la logique pour l’intégration de l’API Bright Data.
Conclusion
Dans ce tutoriel, vous avez découvert ce qu’est AWS Glue et comment Bright Data peut améliorer ses capacités grâce à une large gamme de solutions de Scraping web.
Vous avez notamment vu comment les API de Scraping web de Bright Data peuvent prendre en charge les phases d’extraction (E) et de transformation (T) d’un pipeline ETL (qu’il s’agisse de récupérer des données brutes, d’enrichir des Jeux de données ou de vérifier des informations).
Créez dès aujourd’hui un compte Bright Data gratuit et commencez à explorer nos solutions de données web !





