
Dans ce guide, vous apprendrez :
- Ce qu’est AWS Step Functions et pourquoi il est important pour l’automatisation des flux de travail.
- Pourquoi les workflows de Scraping web sont bien adaptés à ce service AWS.
- Comment Bright Data aide à surmonter les défis inhérents au Scraping web.
- Comment intégrer Bright Data dans AWS Step Functions, soit via des appels API directs, soit via une fonction Lambda dédiée.
C’est parti !
Introduction à AWS Step Functions
Avant de vous montrer comment utiliser AWS Step Functions pour orchestrer un workflow de Scraping web, découvrons plus en détail cette solution.
Qu’est-ce que AWS Step Functions ?
AWS Step Functions est un service entièrement géré qui vous permet de coordonner et d’automatiser des workflows complexes entre les services AWS. Il s’agit d’un service d’orchestration visuelle utilisé pour créer des applications distribuées et automatiser des processus en connectant plusieurs services AWS dans des workflows sans serveur.
Step Functions repose essentiellement sur des machines à états, qui sont des workflows composés d’une série d’étapes, appelées états. Chaque état effectue une tâche telle que l’appel d’un service AWS ou l’exécution d’un code personnalisé.
Cette approche simplifie l’orchestration, la gestion des erreurs et la surveillance, vous permettant ainsi de vous concentrer sur la logique de l’application plutôt que sur l’infrastructure. Plus précisément, les principaux avantages qu’elles apportent sont les suivants :
- Orchestration simplifiée: gérez des processus en plusieurs étapes et des dépendances sans écrire de code complexe.
- Gestion des erreurs intégrée: les blocs de réessai et d’interception aident les workflows à se remettre automatiquement des échecs.
- Exécution parallèle et dynamique: exécutez des tâches simultanément ou itérez sur des Jeux de données pour un traitement plus rapide.
- Prise en charge humaine: incluez des étapes d’approbation ou des rappels dans les flux de travail.
- Intégration des services: connectez-vous de manière transparente à AWS Lambda, Glue, SQS, SNS, SageMaker, etc.
Pour en savoir plus, consultez la documentation officielle.
Comprendre le fonctionnement d’AWS Step Functions
Pour bien comprendre AWS Step Functions, il est utile de se concentrer sur ses concepts fondamentaux, qui constituent la base de tout workflow :
- Machine à états: la colonne vertébrale de Step Functions. Une machine à états représente votre flux de travail, stockant et mettant à jour son état au fur et à mesure de l’avancement des tâches. Vous la définissez à l’aide de JSON et du langage Amazon States Language. Vous pouvez choisir des flux de travail standard pour les processus de longue durée ou nécessitant une intervention humaine, ou des flux de travail express pour les tâches courtes et à volume élevé.
- États: chaque étape d’un workflow. Les états peuvent effectuer des tâches (Task), prendre des décisions (Choice), suspendre l’exécution (Wait), gérer les échecs ou les réussites (Fail/Succeed), bifurquer l’exécution (Parallel) ou répéter les entrées (Map). La combinaison des états définit la logique de votre workflow.
- États des tâches: unités de travail au sein d’un workflow. Les tâches de service automatisent les interactions avec les services AWS tels que Lambda ou Glue. Les tâches d’activité, quant à elles, se connectent à du code externe ou à des humains, ce qui est utile pour les étapes asynchrones ou les approbations.
- Exécution et surveillance: Step Functions enregistre les entrées, les sorties, les réessais et les erreurs de chaque étape, ce qui vous permet de suivre les problèmes et de vérifier le comportement du workflow.
Orchestration du workflow de Scraping web sans serveur
AWS Step Functions offre un moyen efficace d’orchestrer des workflows de Scraping web sans serveur de manière évolutive et fiable. Au lieu de créer un script de Scraping web monolithique, vous pouvez diviser le processus en étapes plus petites, pilotées par des événements, et les coordonner à l’aide d’une machine à états.
Par exemple, un workflow peut commencer par déclencher une tâche de collecte de données, se poursuivre par l’analyse et la validation des données, puis stocker les résultats dans des services tels qu’Amazon S3 ou une base de données. Step Functions peut coordonner ces étapes tout en s’intégrant à d’autres services AWS tels que AWS Lambda, AWS Glue ou Amazon SQS.
Cette approche présente plusieurs avantages : une meilleure évolutivité, une gestion intégrée des tentatives et des erreurs, un traitement parallèle des tâches de scraping et un suivi clair de chaque exécution de workflow.
Cependant, le Scraping web à grande échelle présente également des défis. En effet, de nombreux sites Web mettent en œuvre des protections anti-bot et des mécanismes anti-scraping qui peuvent bloquer les requêtes automatisées. Citons par exemple les limiteurs de débit, les empreintes digitales, les CAPTCHA, les défis JavaScript, etc.
Récupération parfaite des données Web dans AWS Step Functions
Pour les équipes qui orchestrent des workflows de Scraping web avec AWS Step Functions, Bright Data offre une solution complète pour prendre en charge la récupération réussie de données web à grande échelle.
Bright Data propose plusieurs services de scraping spécialisés qui s’intègrent parfaitement à Step Functions :
- API SERP: recueillez les résultats des moteurs de recherche à grande échelle pour obtenir des informations SEO ou analyser le marché.
- Web Unlocker: accédez à n’importe quelle page web tout en contournant les défenses anti-bots telles que les CAPTCHA, les obstacles JavaScript et les restrictions IP.
- API de Scraping web: récupérez des informations structurées à partir de plateformes de commerce électronique, de réseaux sociaux et d’autres sources Web avec une configuration minimale.
- Crawl API: automatisez l’extraction du contenu complet d’un site web à partir de n’importe quel domaine vers Markdown, du texte brut, HTML ou JSON.
Ces solutions s’appuient sur un réseau de Proxies dépassant les 150 millions d’adresses IP dans plus de 195 pays, offrant une concurrence illimitée pour des cas d’utilisation prêts à la production. De plus, tous les services intègrent la boîte à outils anti-bot de Bright Data pour éviter les CAPTCHA et autres restrictions d’accès.
L’intégration de l’orchestration de Step Functions avec les outils de données web de Bright Data permet de créer des pipelines entièrement automatisés qui gèrent l’extraction, la transformation et le stockage. Cela signifie un fonctionnement continu, même dans des scénarios complexes, à grande échelle et adaptés aux entreprises.
Comment intégrer les solutions de Scraping web de Bright Data dans AWS Step Functions
Pour intégrer Bright Data à AWS Step Functions afin d’automatiser la récupération de données web, deux approches sont possibles :
- Utilisez le nœud « HTTP Endpoint – Call HTTPS APIs »: connectez-vous directement aux API de Bright Data (Web Unlocker API, Scraping web APIs, API SERP, Crawl API, etc.).
- Utilisez le nœud « AWS Lambda – Invoke »: créez un code personnalisé dans une fonction Lambda (en Python ou dans un autre langage pris en charge) pour l’intégrer aux produits Bright Data, récupérer des données et, éventuellement, appliquer une logique spécifique (par exemple, accéder uniquement à des champs spécifiques, renvoyer des données dans une structure spécifique ou appliquer une logique d’analyse personnalisée).
Dans les sections ci-dessous, nous vous guiderons à travers ces deux approches. Mais tout d’abord, explorons les avantages et les inconvénients de ces deux méthodes.
Point de terminaison HTTP – Nœud d’appel des API HTTPS : avantages et inconvénients
👍 Avantages:
- Configuration rapide.
- Plus facile à gérer et à maintenir.
- Fonctionne bien pour extraire des données à partir de pages web uniques.
👎 Inconvénients:
- Flexibilité limitée pour le traitement personnalisé des données.
- Plus difficile à gérer pour les flux de travail complexes qui nécessitent plusieurs appels API Bright Data différents.
AWS Lambda – Invoke Node : avantages et inconvénients
👍 Avantages:
- Contrôle total sur le traitement et la transformation des données web.
- Permet de mettre en œuvre une logique personnalisée (par exemple, réessais, flux conditionnels, etc.).
- Possibilité d’intégrer plusieurs services Bright Data dans une seule fonction.
👎 Inconvénients:
- Nécessite un codage en Python, Node.js ou un autre langage pris en charge.
- Ajoute un service supplémentaire à surveiller et à maintenir.
Prérequis
Pour suivre les sections guidées suivantes, vous devez disposer des éléments suivants :
- D’un compte AWS actif (même une version d’essai gratuite convient).
- Un compte Bright Data avec une clé API prête à l’emploi.
- Des connaissances de base sur les appels HTTP RESTful ou des compétences de base en programmation Python pour l’intégration Lambda.
Configurez votre compte Bright Data
Si vous n’avez pas encore de compte Bright Data, créez-en un. Sinon, connectez-vous et suivez les instructions pour configurer une clé API. Vous aurez besoin de cette clé pour authentifier vos appels HTTP (que vous appeliez Bright Data directement à partir d’appels HTTP ou dans une fonction Lambda).
Assurez-vous d’avoir configuré une API Bright Data Web Unlocker (et une API SERP si vous prévoyez de suivre la section du tutoriel Lambda) :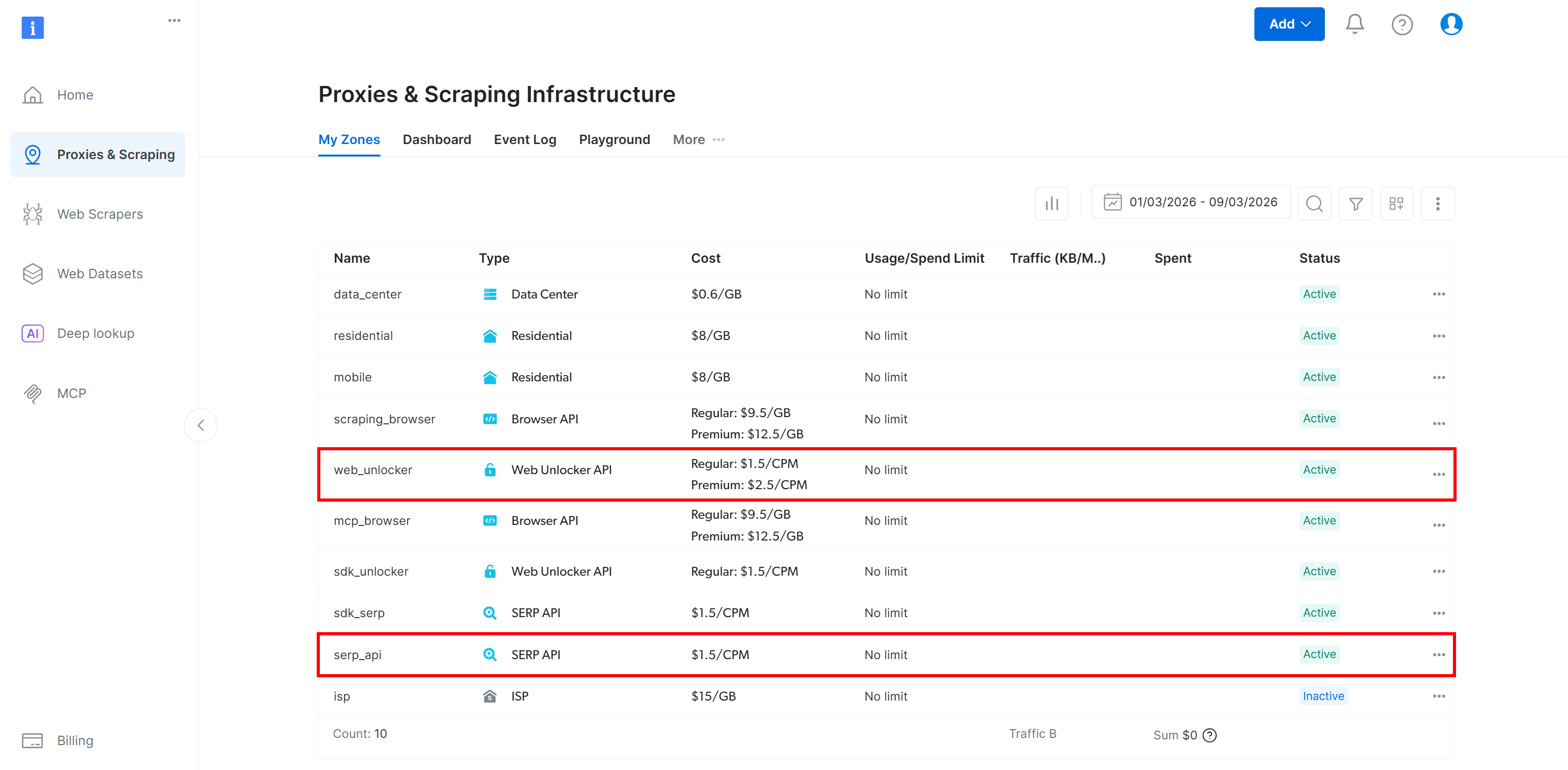
Pour plus d’informations, consultez les pages de documentation suivantes :
Configurez votre workflow AWS Step Functions
Commencez par vous connecter à votre console AWS et recherchez le service « Step Functions ». Ouvrez la page du service :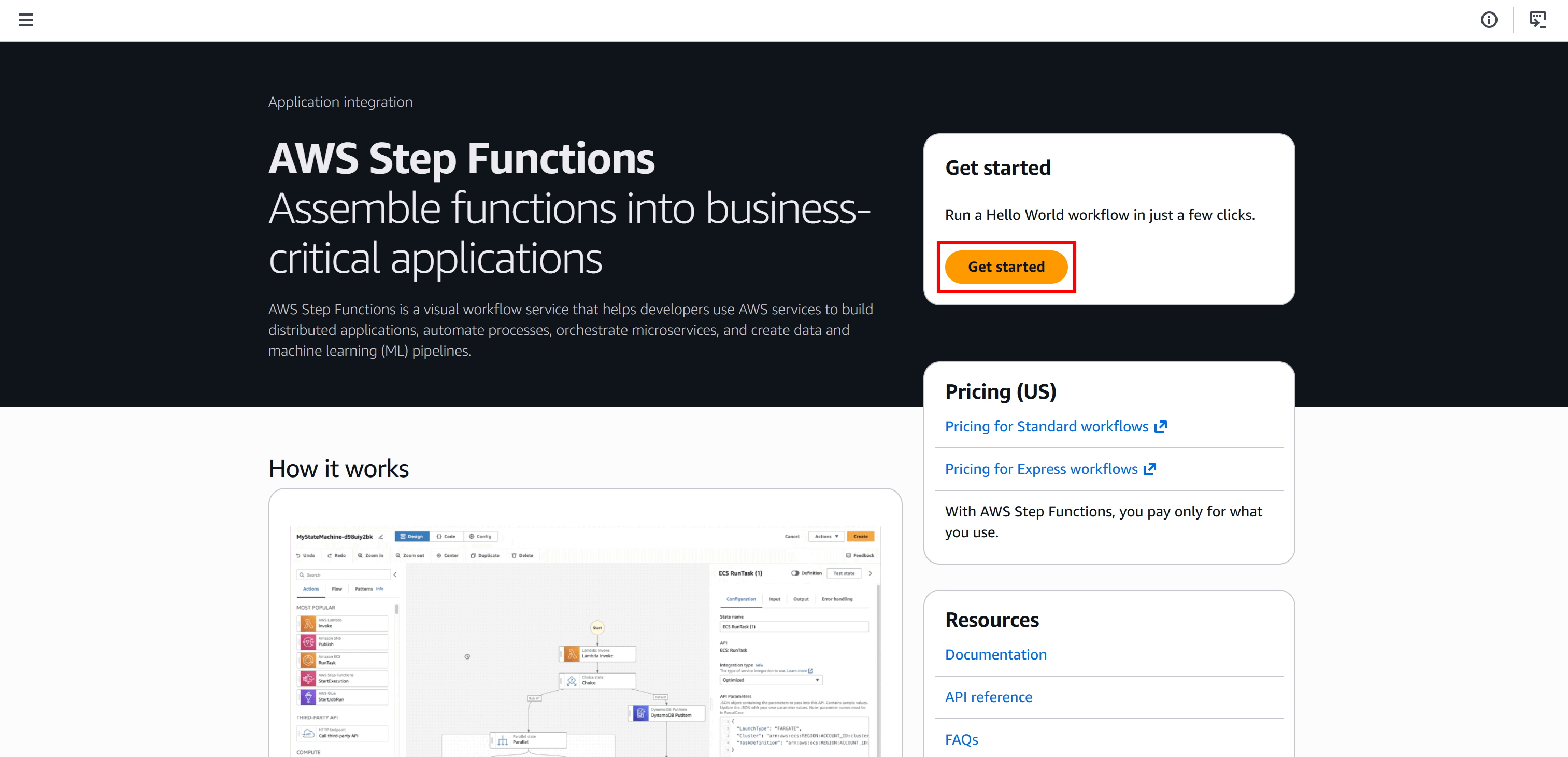
Cliquez ici sur le bouton « Get Started » (Commencer), puis sélectionnez « Create your own » (Créer votre propre) pour commencer à créer un workflow sans serveur à partir de zéro :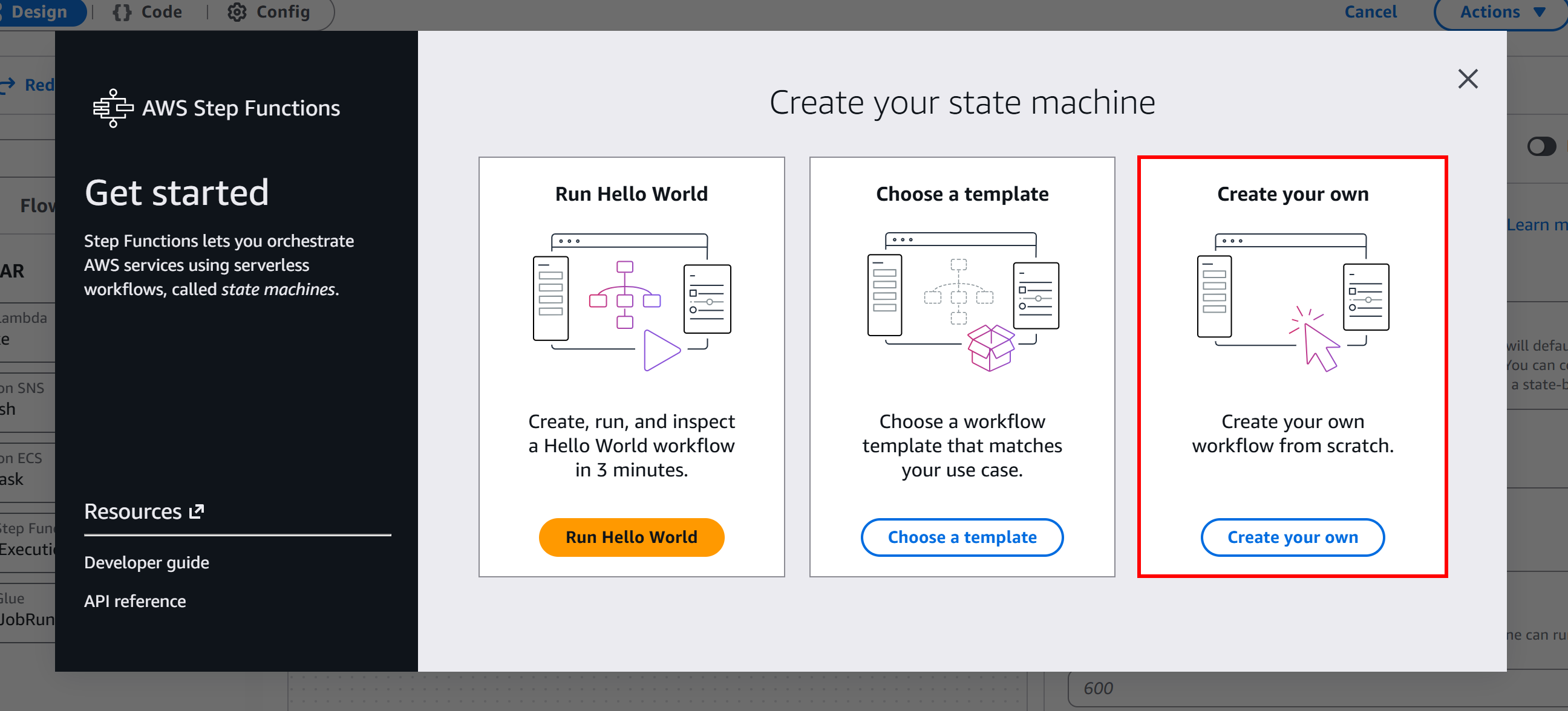
Donnez un nom à votre machine à états (par exemple, « BrightDataWebScrapingMachine ») et choisissez le type de machine à états que vous souhaitez créer. Dans ce tutoriel, nous utiliserons une machine « Standard » :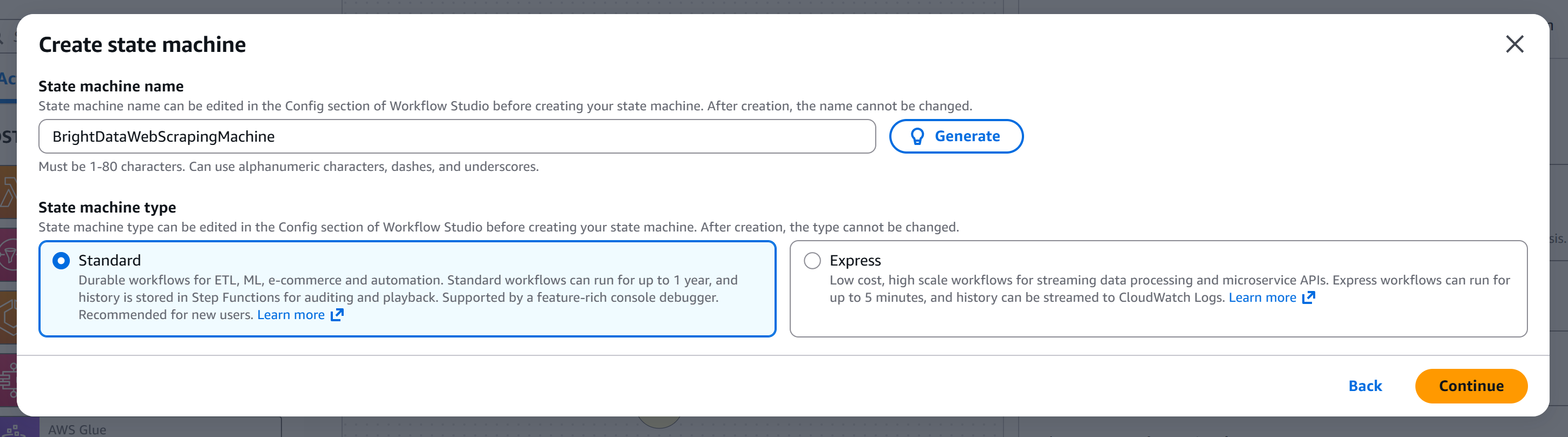
Cliquez sur « Continue » (Continuer) pour accéder à la page de l’éditeur de flux de travail :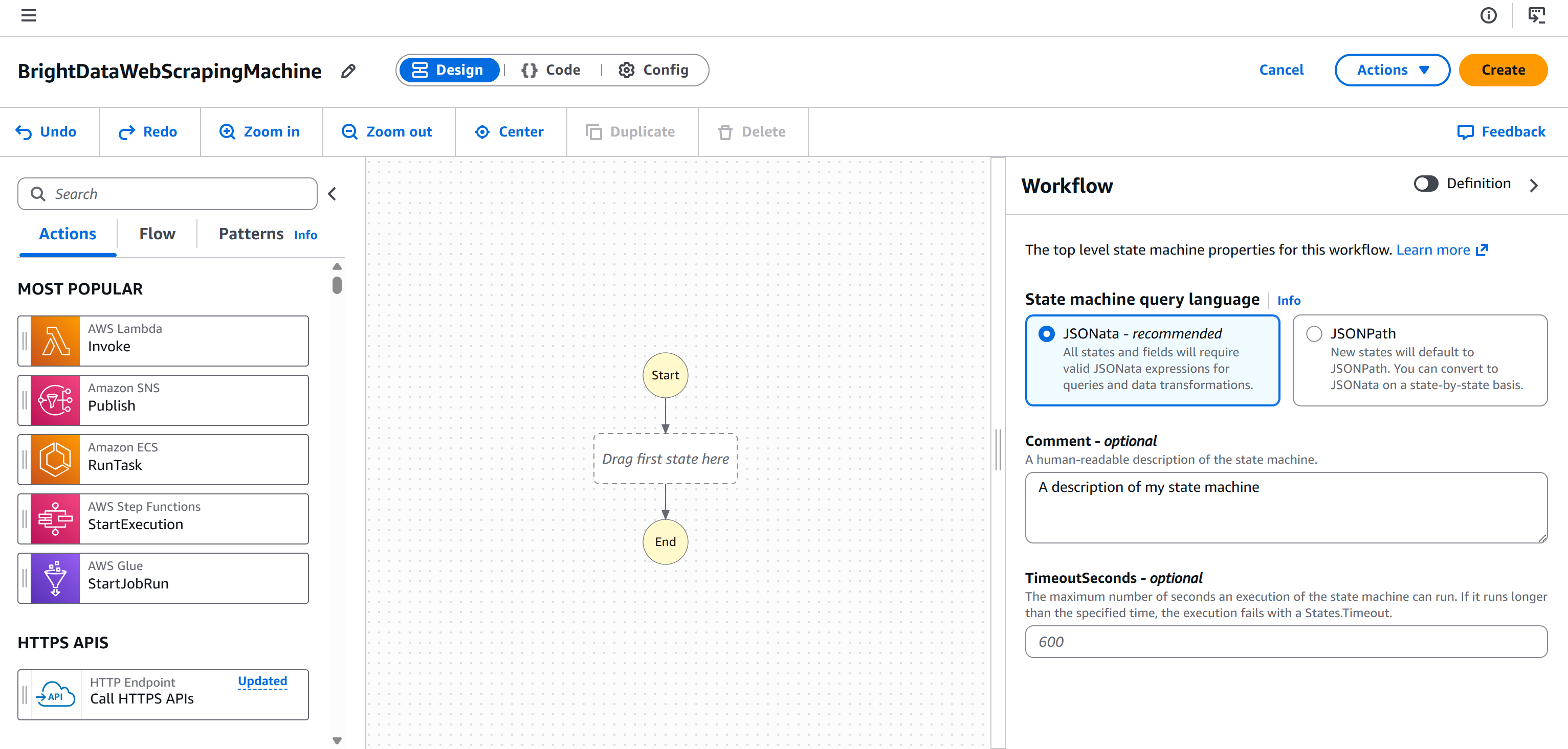
Vous êtes maintenant entièrement configuré et prêt à ajouter un nœud de Scraping web Bright Data à votre workflow AWS Step Functions.
Approche n° 1 : utiliser le nœud « Appeler les API HTTPS »
Vous allez apprendre ici à définir un nœud qui se connecte directement aux API Bright Data Web Unlocker via un appel HTTP. Ce nœud vous permet d’extraire par programmation les données de n’importe quelle page web. Nous allons notamment le configurer pour récupérer les données au format Markdown, idéal pour l’ingestion LLM.
Remarque: une procédure très similaire peut être appliquée pour se connecter à tout autre produit Bright Data basé sur une API.
Étape n° 1 : Ajoutez un nœud « HTTP Endpoint – Call HTTPS APIs »
Commencez par sélectionner le nœud « HTTP Endpoint – Call HTTPS APIs » dans le panneau de gauche et faites-le glisser vers la section « Drag first state here » :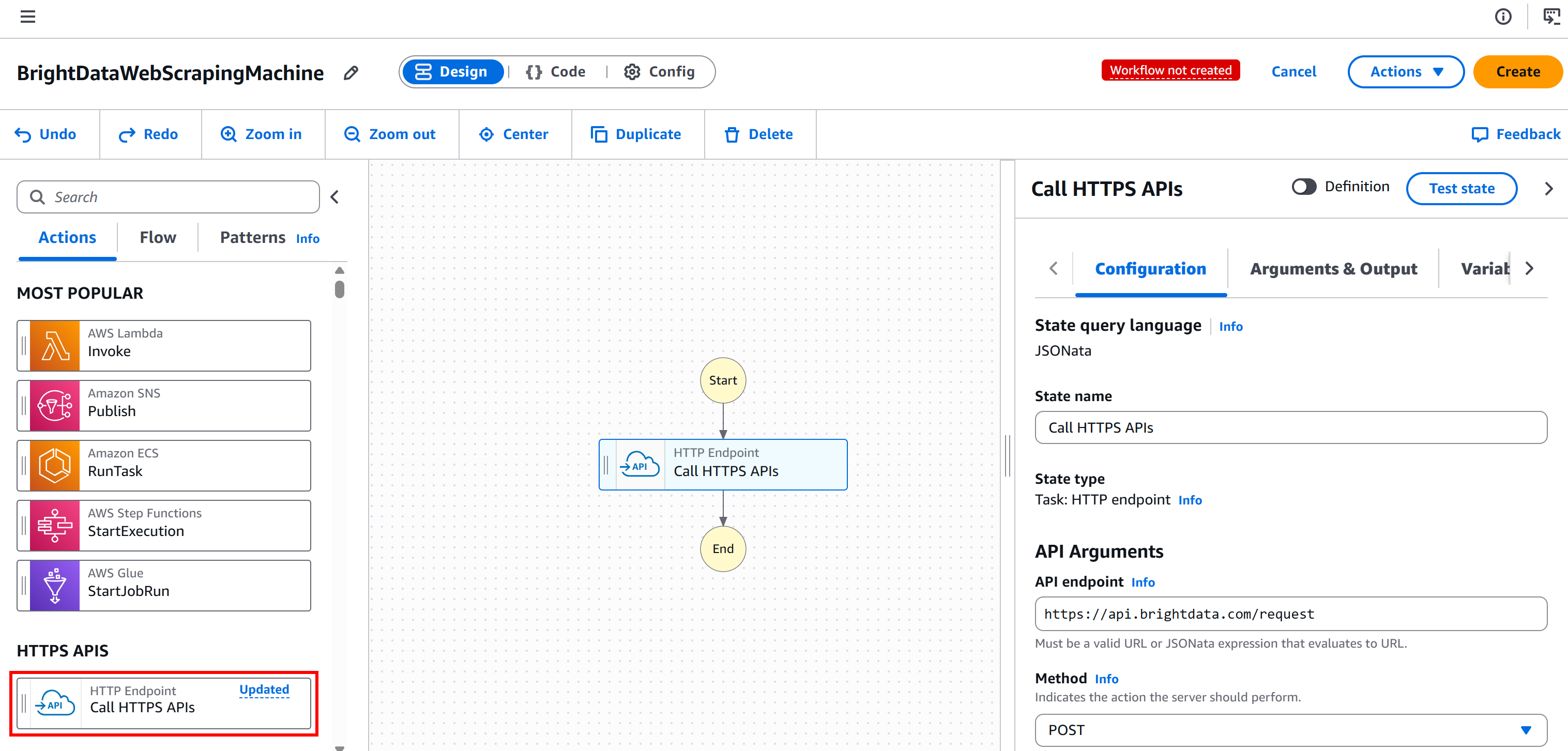
Sélectionnez le nœud, puis dans l’onglet « Configuration » à droite :
- Donnez un nom à votre état.
- Définissez le « Point de terminaison API » sur
https://api.brightdata.com/request. - Définissez la « Méthode » sur
POST.
Cela configure le nœud pour se connecter au point de terminaison POST https://api.brightdata.com/request, qui est l’API Bright Data de base pour les services Web Unlocker et API SERP: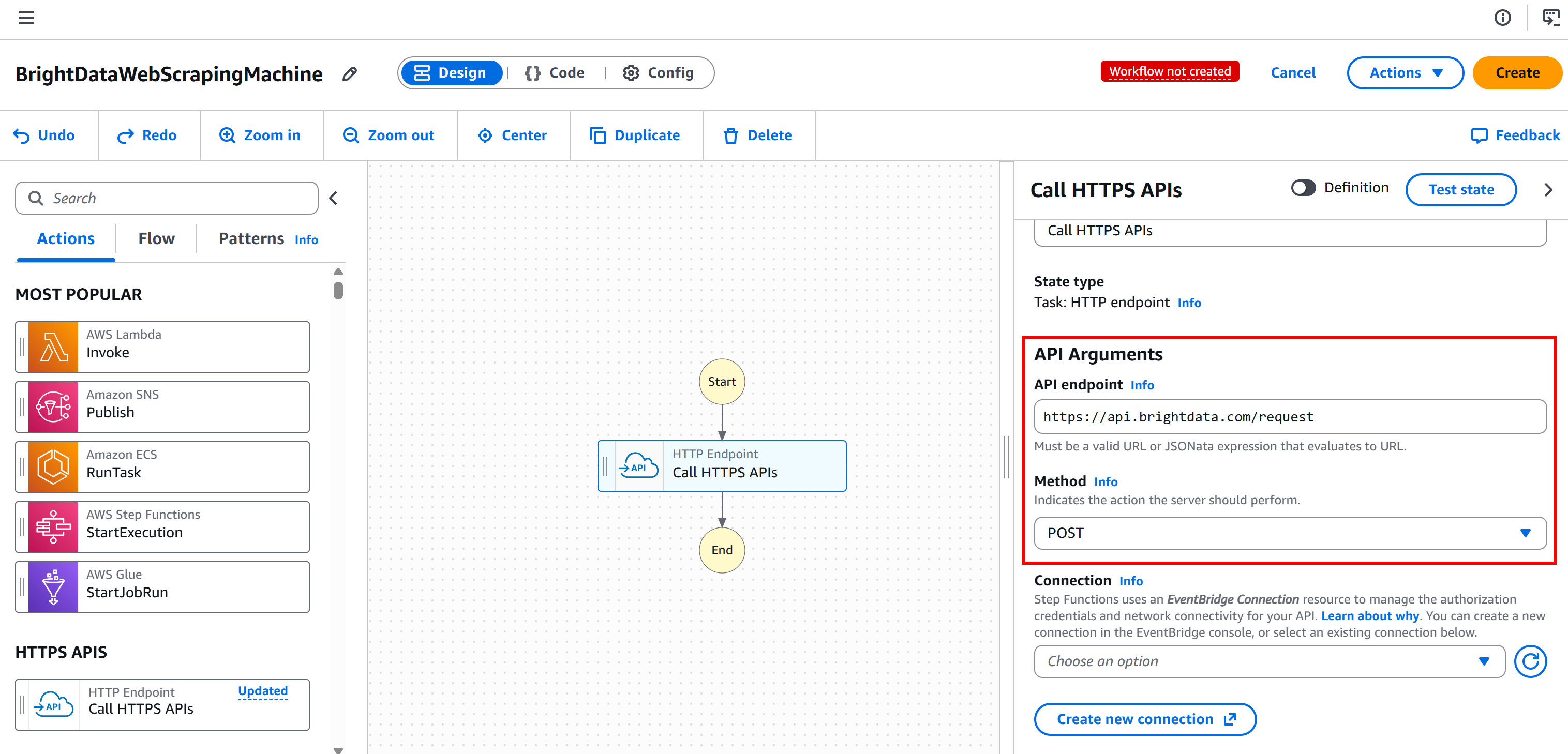
Étape n° 2 : configurer l’authentification API
Les API Bright Data sont authentifiées à l’aide de votre clé API Bright Data. Plus précisément, vous devez l’inclure dans l’en-tête d'autorisation au format suivant :
Bearer <BRIGHT_DATA_API_KEY>Pour éviter de coder en dur votre clé API dans le nœud, vous devez créer une nouvelle connexion via Amazon EventBridge. Pour ce faire, appuyez sur le bouton « Créer une nouvelle connexion » dans la section « Connexion » sous l’onglet « Configuration » :
Donnez un nom à votre connexion (par exemple, brightdata-api) et définissez-la comme « publique » (car les clés API Bright Data sont exposées publiquement).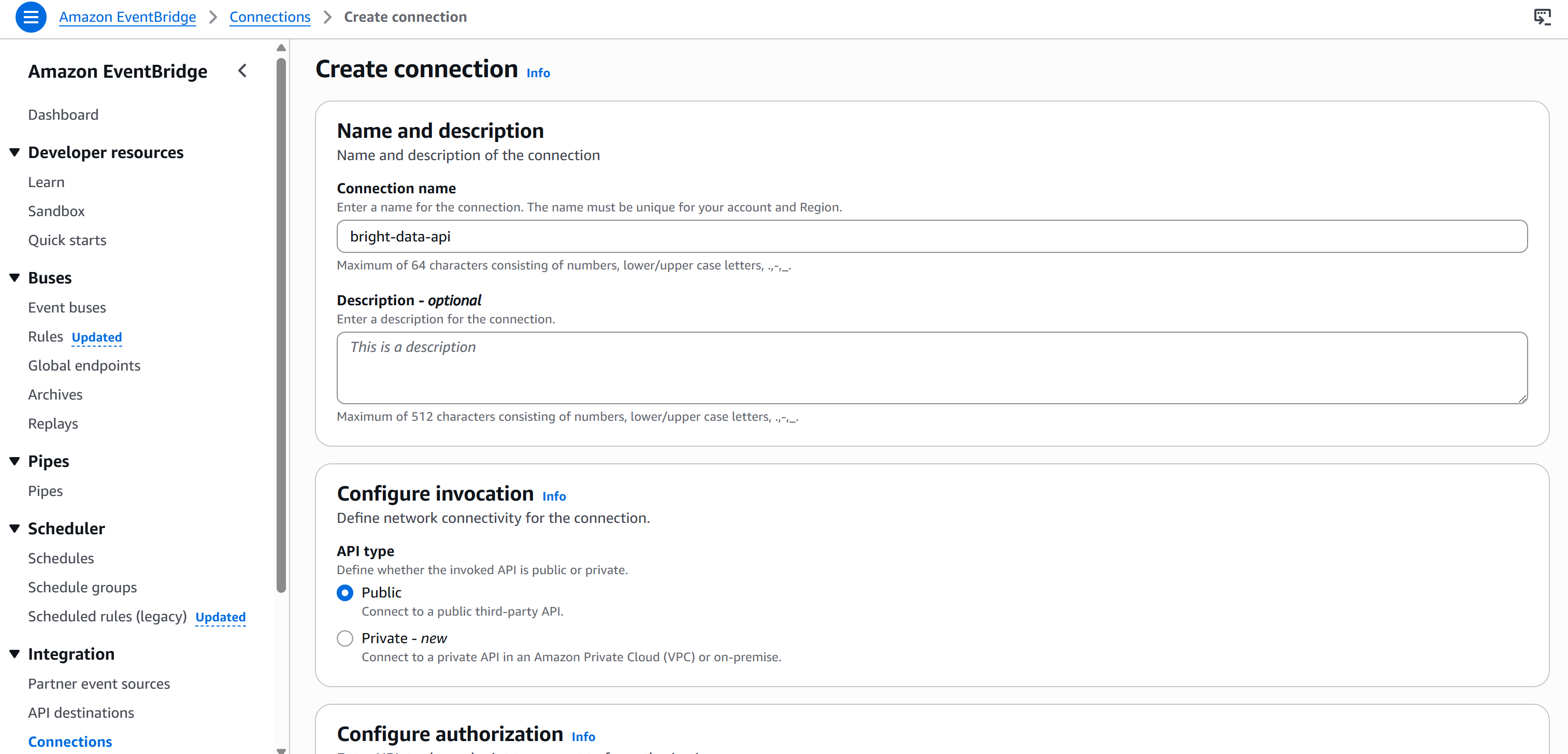
Sélectionnez ensuite le type d’authentification « Clé API » et configurez-la comme suit :
- Nom de la clé API:
Autorisation(celui-ci doit correspondre au nom de l’en-tête HTTP utilisé pour l’authentification). - Valeur:
Bearer <BRIGHT_DATA_API_KEY>(remplacez l’espace réservé<BRIGHT_DATA_API_KEY>par votre clé API réelle).
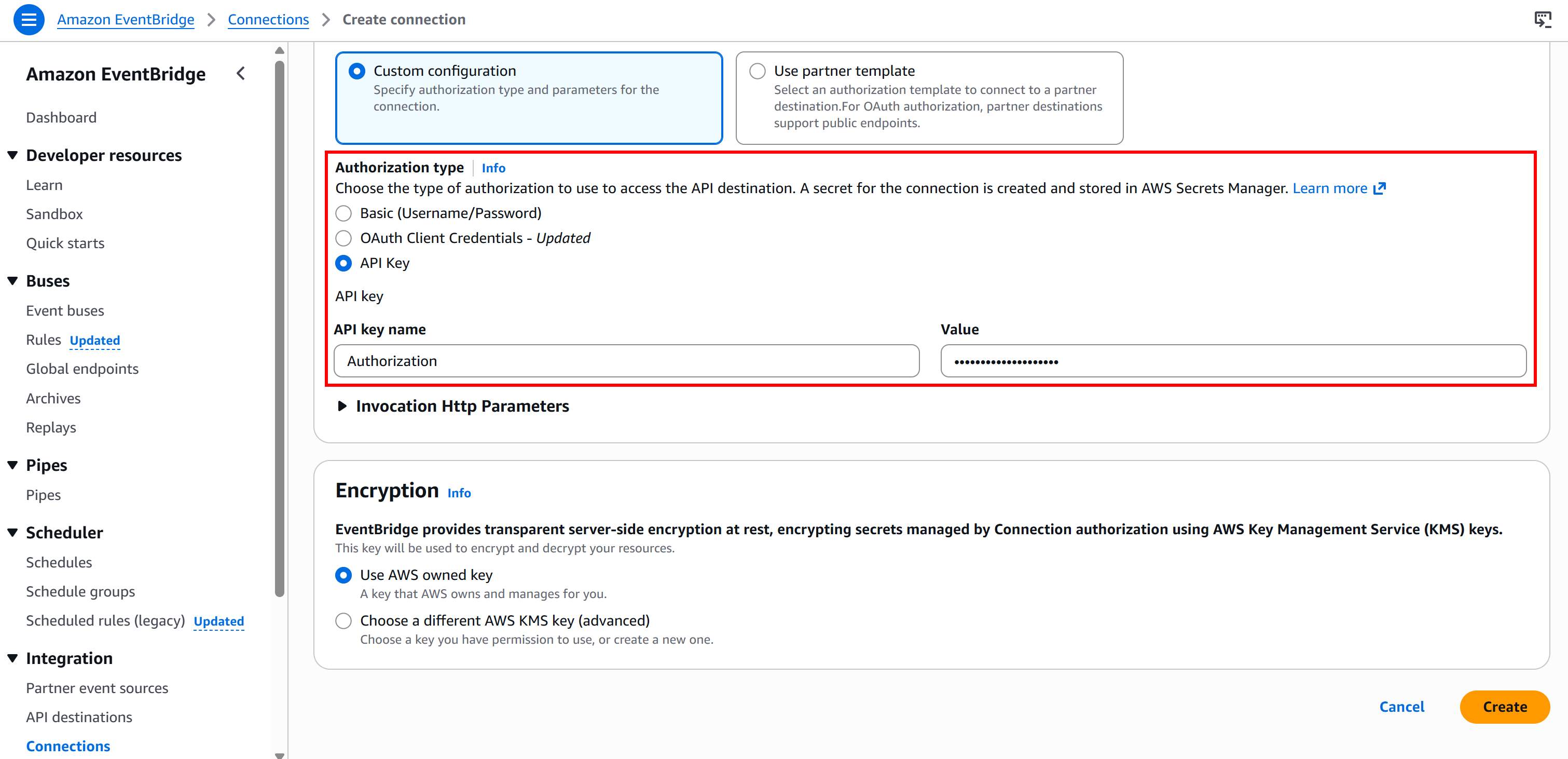
Enfin, appuyez sur « Créer » pour configurer la connexion EventBridge. Une fois la création terminée, vous devriez voir :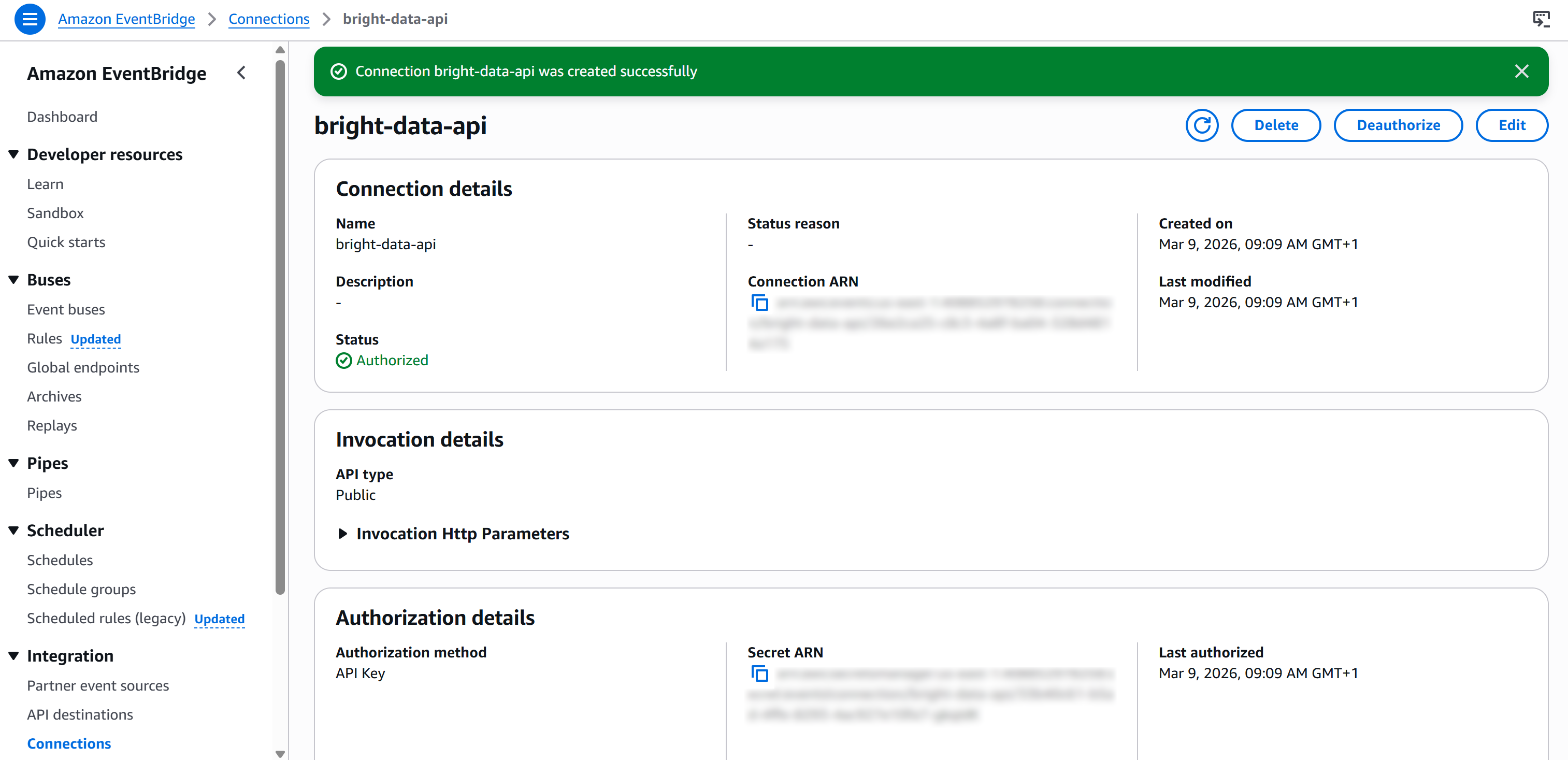
Étape n° 3 : terminer la configuration de l’API
De retour sur la page de l’éditeur de flux de travail, sélectionnez votre nœud « Point de terminaison HTTP – Appeler les API HTTPS » et accédez à l’onglet « Configuration ». Ensuite, sélectionnez la connexion que vous venez de créer (bright-data-api) :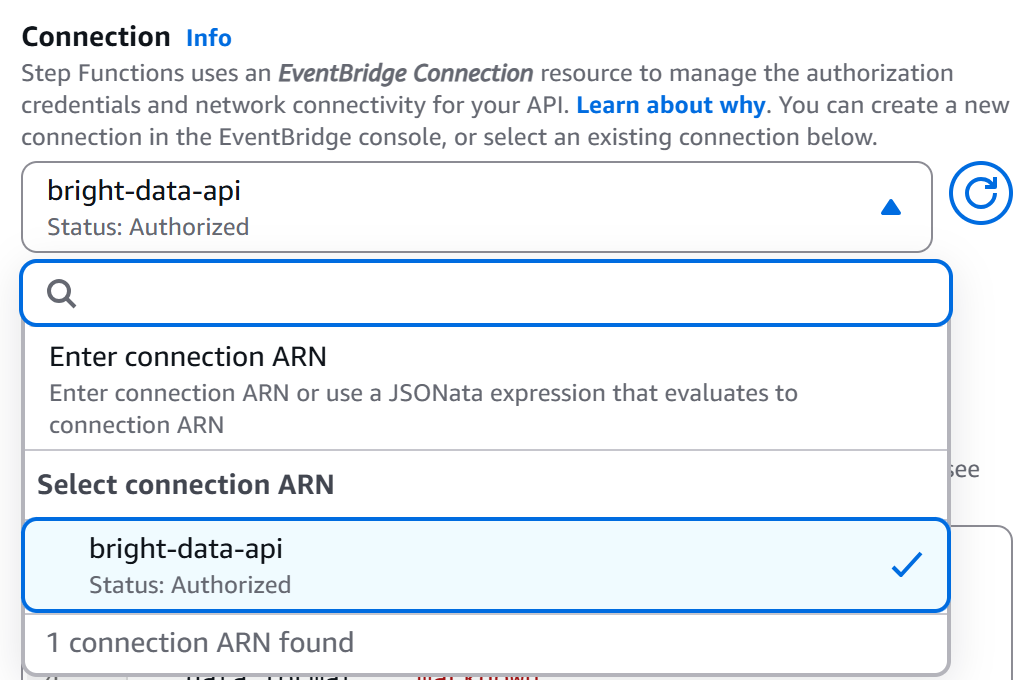
De cette façon, la clé API Bright Data sera ajoutée à l’en-tête d'autorisation pour l’authentification (dans le format requis).
Ensuite, définissez le corps HTTP comme suit :
{
"Zone": "<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE_NAME>",
"url": "{% $states.input.url %}",
"format": "raw",
"data_format": "markdown"
}Remplacez l’espace réservé <YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE_NAME> par le nom de votre zone Web Unlocker dans votre compte Bright Data. Le champ url sera lu dynamiquement à partir de l’entrée du flux de travail (grâce à la syntaxe {% $states.input.url %} ), ce qui vous permettra de scraper différentes pages sans avoir à coder en dur l’URL. À la place, data_format: "markdown" garantit que la réponse de l’API est renvoyée au format Markdown compatible avec l’IA.
Dans notre exemple, la zone Web Unlocker est nommée « ``web_unlocker`` », le corps devient donc :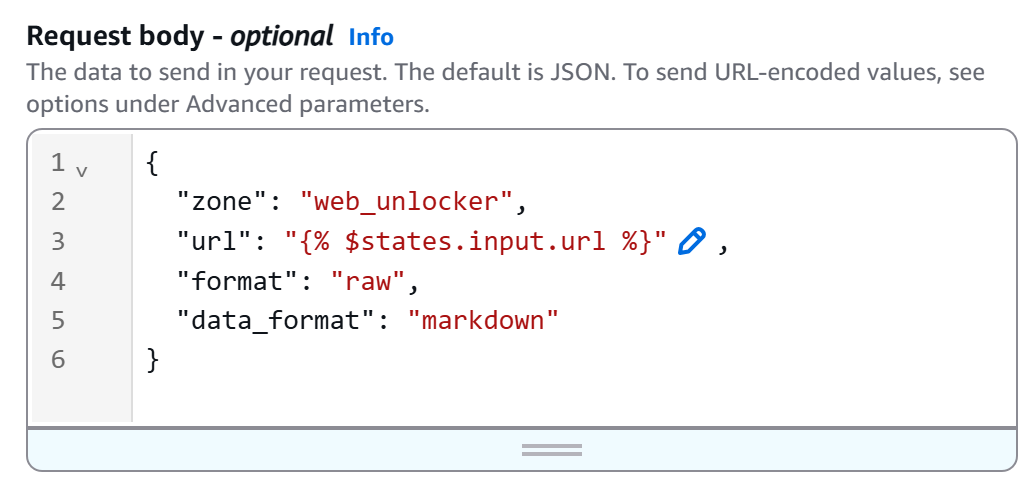
Voici à quoi ressemblera désormais votre flux de travail :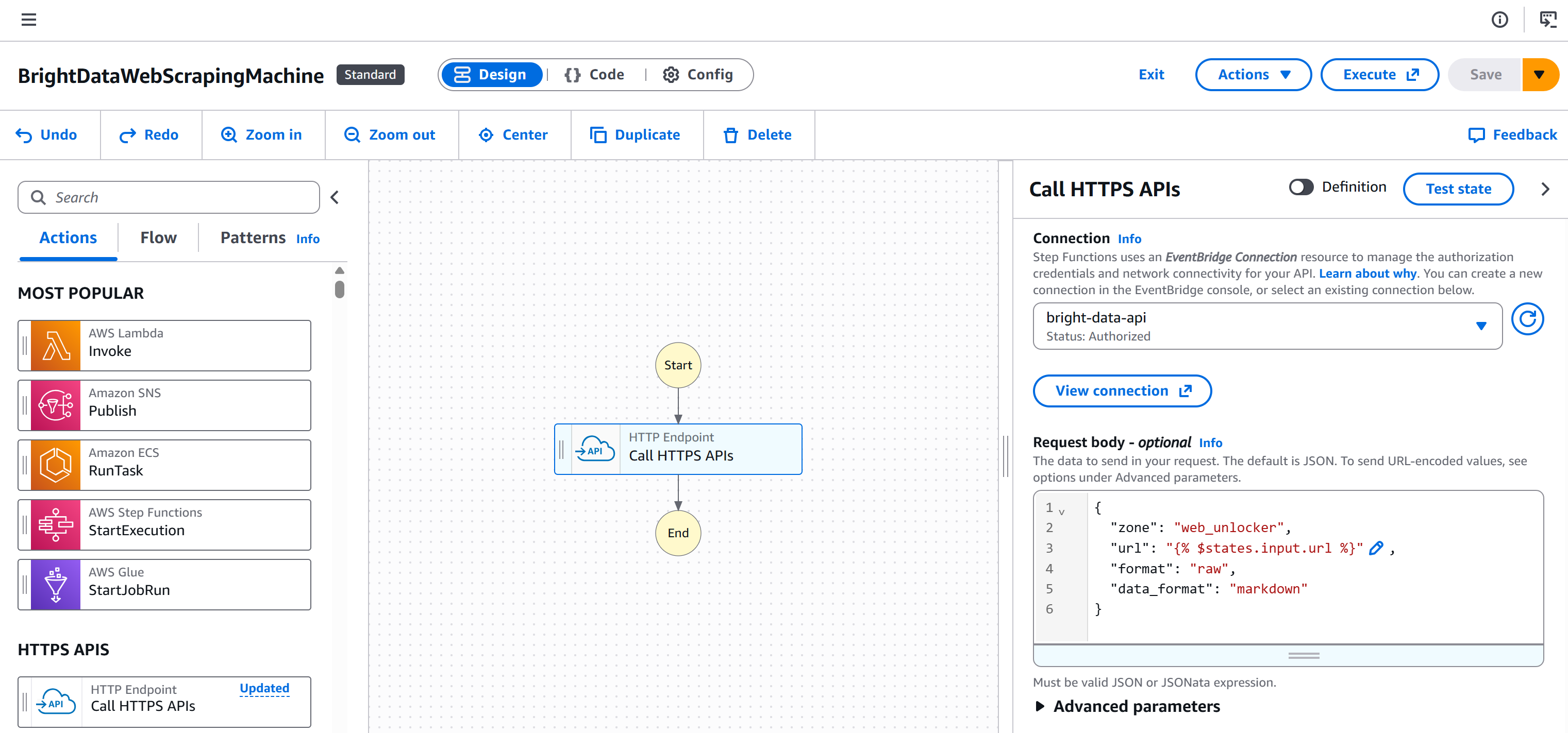
Fantastique ! La configuration est terminée. Il ne reste plus qu’à tester l’intégration de Bright Data dans votre workflow AWS Step Functions.
Étape n° 4 : Testez le nœud de Scraping web alimenté par Bright Data
Commencez par appuyer sur le bouton « Create » (Créer) pour générer le rôle IAM requis et tous les autres éléments nécessaires dans votre console AWS pour le test :
Appuyez ensuite sur le bouton « Test state » (Tester l’état) de votre nœud :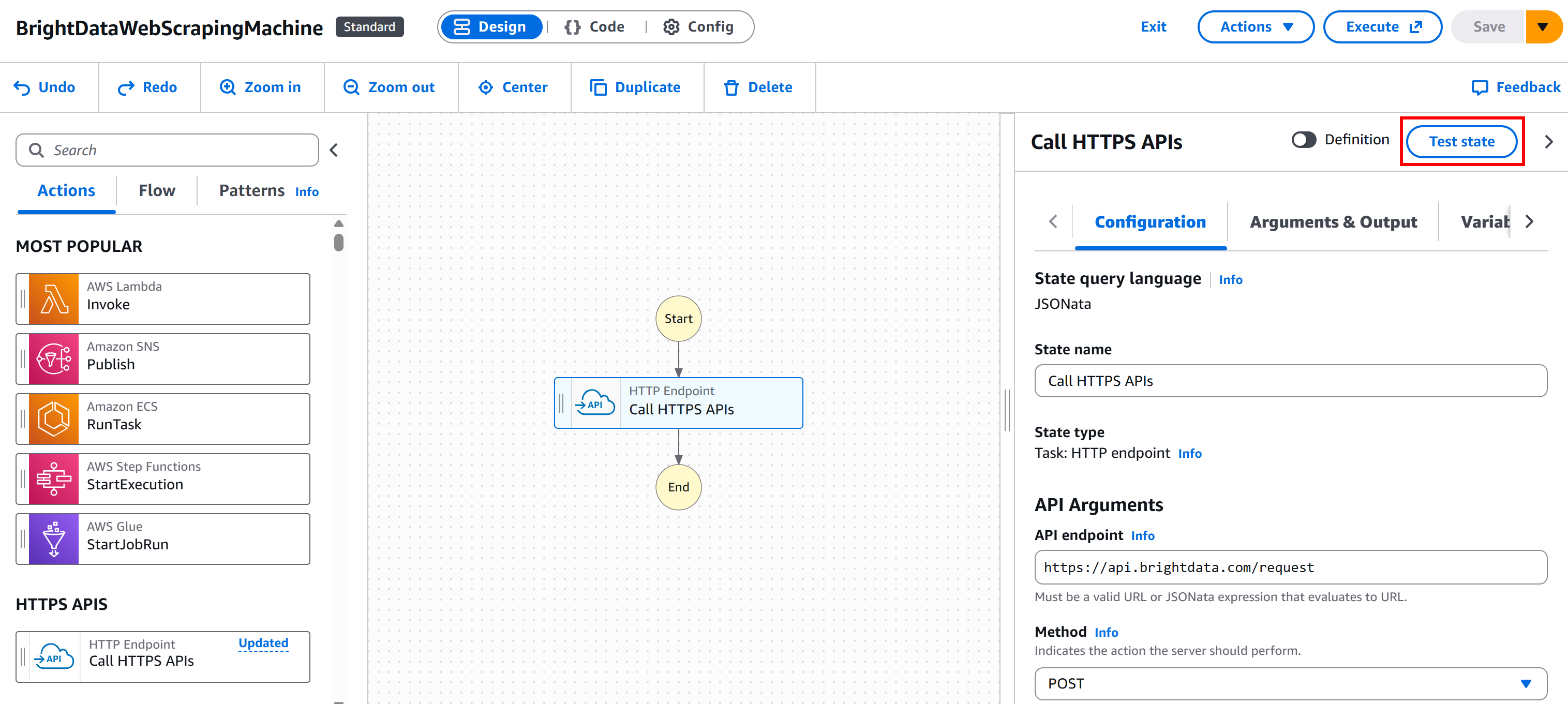
Vous accéderez à la fenêtre modale « Test state » :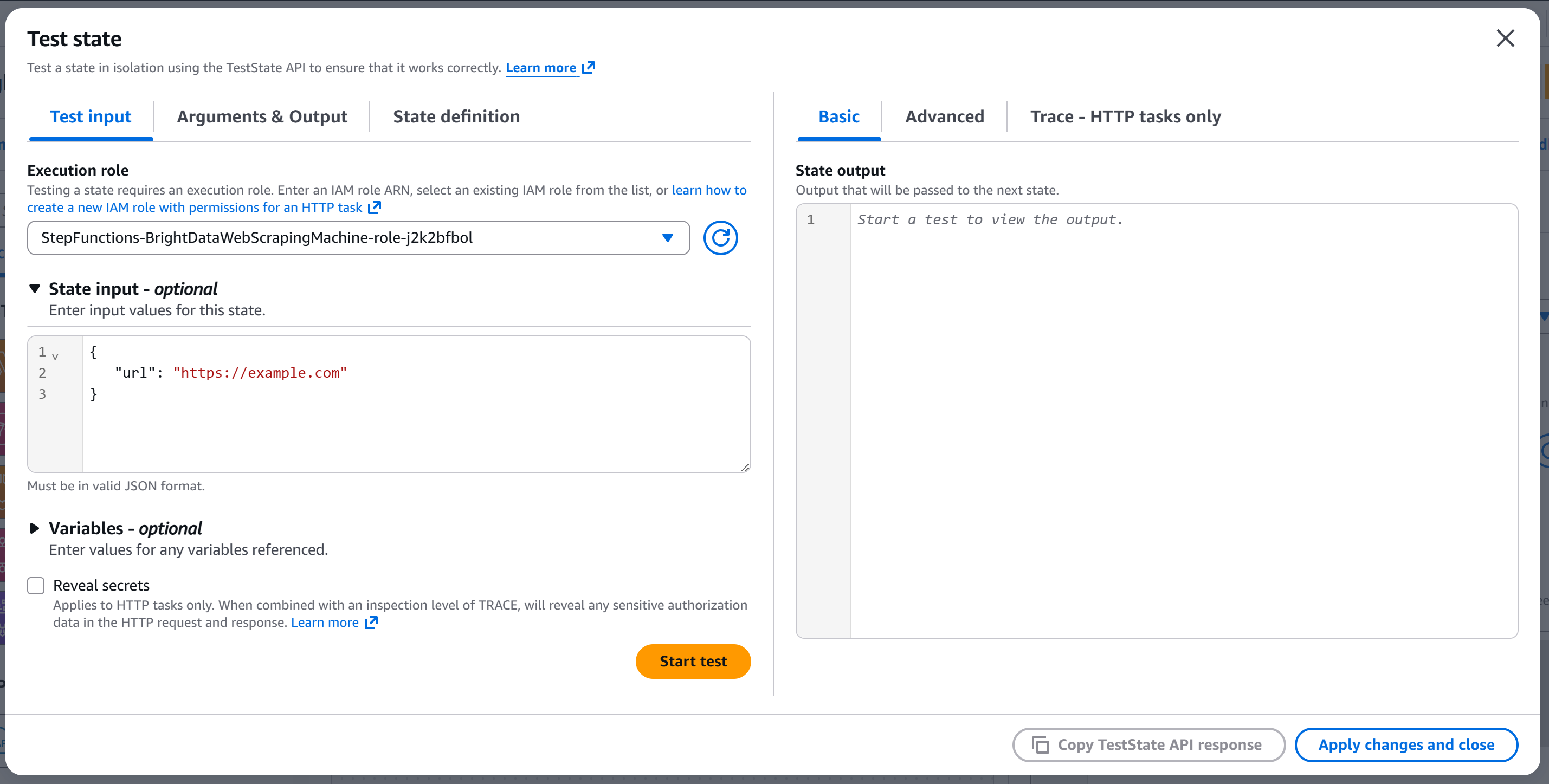
Configurez l’entrée d’état avec quelque chose comme :
{
"url": "https://example.com"
}Le champ url sera transmis au corps de l’API (car le nœud a été configuré pour lire le champ url body à partir de l’entrée).
Appuyez sur « Démarrer le test » pour exécuter le nœud. Vous devriez voir un résultat similaire à celui-ci :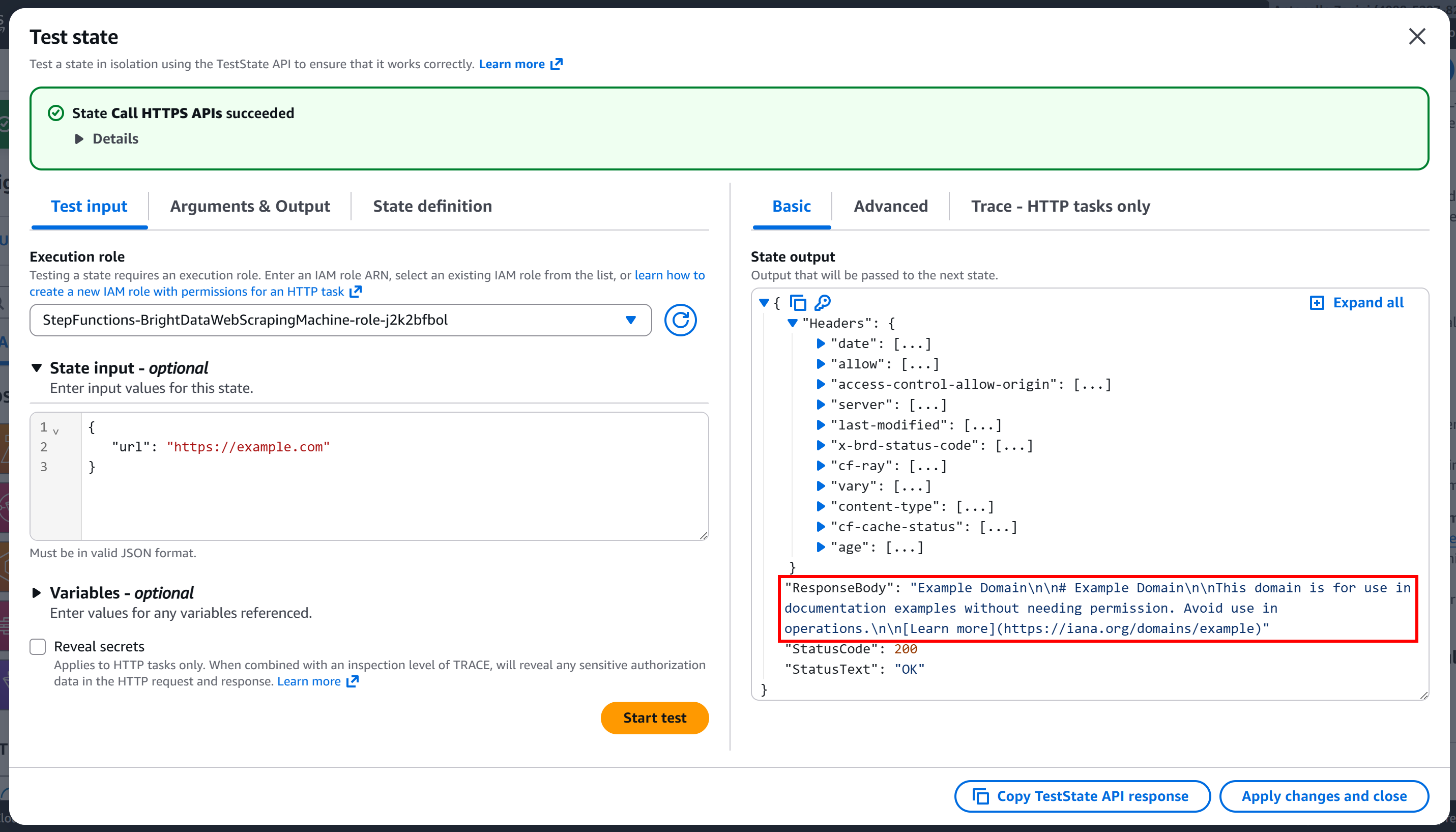
Comme vous pouvez le constater, la requête a abouti et le corps de la réponse contient la version Markdown de la page cible :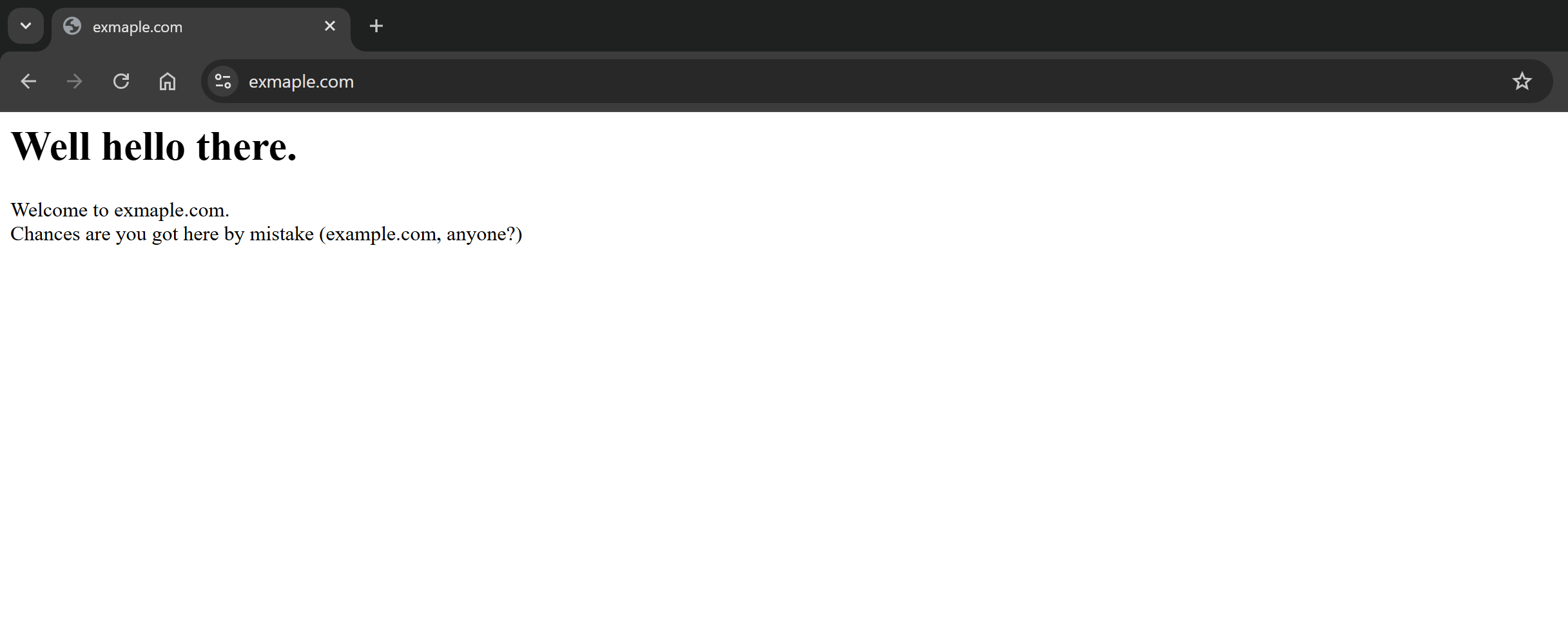
Et voilà ! Votre intégration Bright Data dans AWS Step Functions est désormais pleinement opérationnelle et prête à être utilisée en production.
Approche n° 2 : utiliser une fonction Lambda
Dans cette section, vous apprendrez comment vous connecter aux services Bright Data via une fonction AWS Lambda personnalisée.
Pour simplifier l’intégration et accélérer le processus, vous pouvez suivre les étapes n° 5, 6 et 7 de l’article « Donner aux agents AWS Bedrock la possibilité de rechercher sur le Web via l’API SERP de Bright Data ». Ces étapes vous guident dans la création d’une fonction Lambda en Python qui se connecte à l’API SERP de Bright Data.
Vous découvrirez ci-dessous comment intégrer cette fonction Lambda à votre workflow de Scraping web via AWS Step Functions !
Étape n° 1 : Ajouter un nœud « AWS Lambda – Invoke »
Commencez par sélectionner le nœud « AWS Lambda – Invoke » dans le panneau de gauche. Faites-le ensuite glisser dans la section « Drag first state here » (Faites glisser le premier état ici) de votre flux de travail.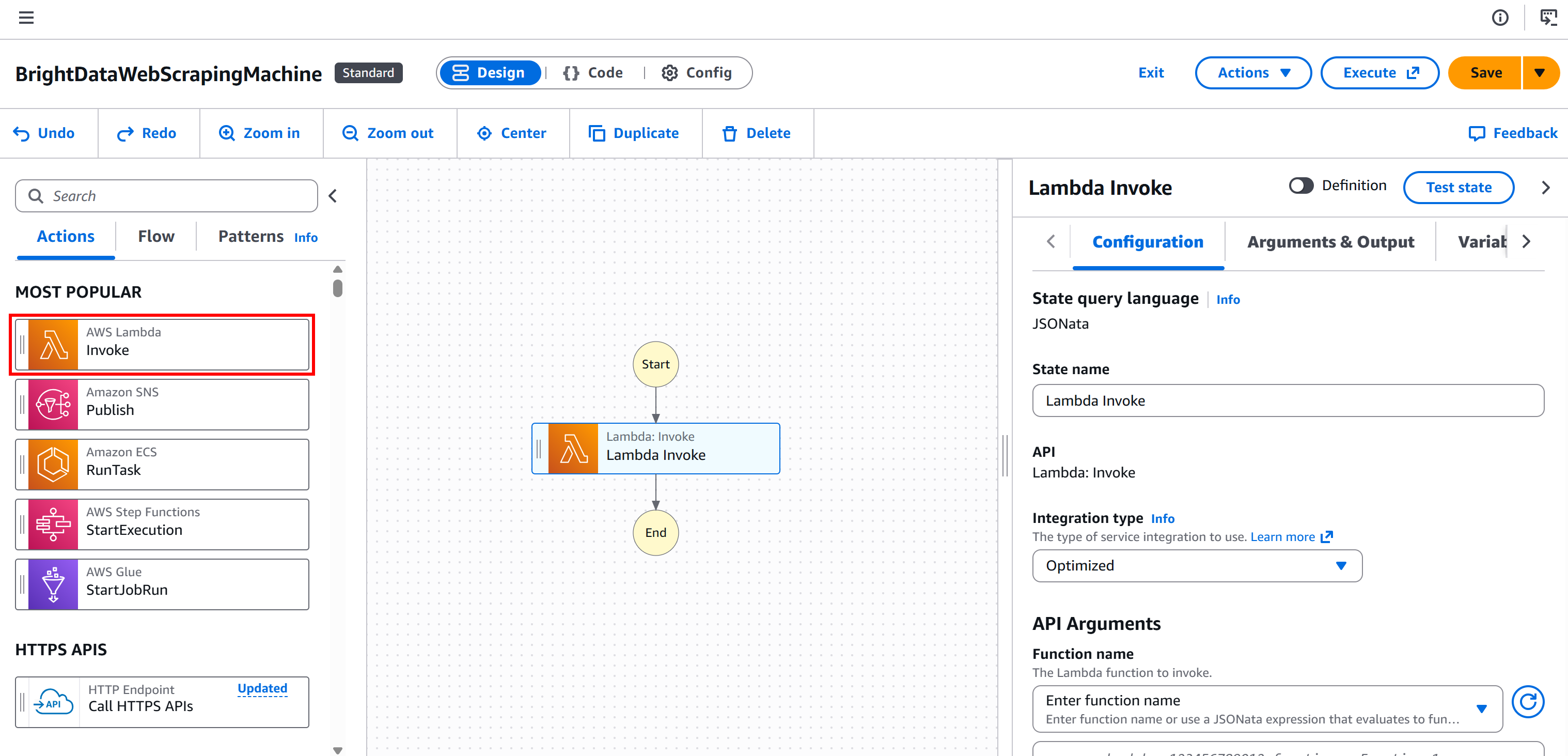
Étape n° 2 : Configurer la fonction Lambda
Dans la section « Configuration » du nœud « AWS Lambda – Invoke », sous le bloc « API Arguments – Function Name », sélectionnez la fonction Lambda que vous souhaitez invoquer :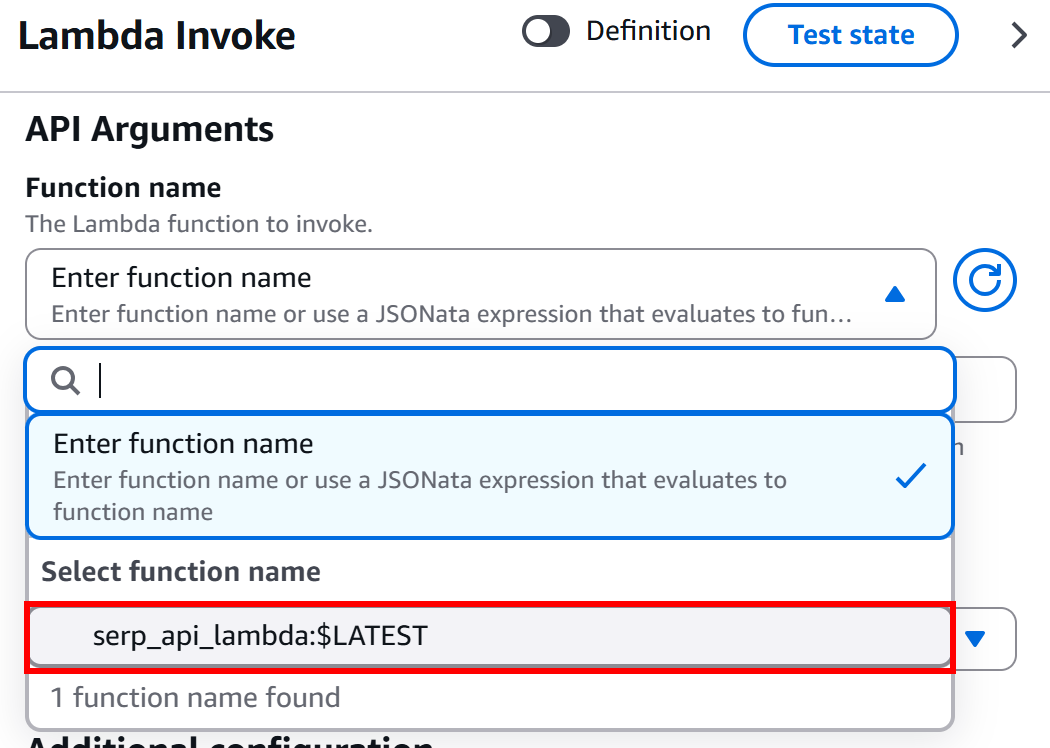
Dans cet exemple, la fonction est serp_api_lambda, qui a été créée comme expliqué précédemment dans l’introduction de ce chapitre. Cette fonction s’intègre à l’API SERP de Bright Data.
Génial ! Vous disposez désormais d’une fonction Lambda optimisée par Bright Data pour le scraping SERP intégrée à votre workflow AWS Step Functions.
Conclusion
Dans ce guide, vous avez découvert ce qu’est AWS Step Functions et pourquoi il est idéal pour orchestrer des workflows de Scraping web automatisés.
Vous avez vu comment Step Functions simplifie la gestion des workflows grâce à des machines à états, l’exécution parallèle, les réessais et la prise en charge humaine en boucle. Vous avez découvert comment Bright Data améliore ce processus grâce aux intégrations Web Unlocker et API SERP, en contournant les mesures anti-bot et en garantissant une récupération ininterrompue des données web au niveau de l’entreprise.
En intégrant Bright Data à Step Functions, vous pouvez créer des pipelines de bout en bout qui gèrent la collecte, la validation et le stockage des données dans S3 ou d’autres services AWS, tout en conservant l’évolutivité, la résilience et la surveillance.
Inscrivez-vous dès aujourd’hui pour obtenir un compte Bright Data et testez gratuitement nos solutions de données web !





