


Découvrez l'API (Bêta)
Les agents IA évoluent, passant d’interfaces de chat à des systèmes autonomes qui exécutent des flux de travail critiques pour l’entreprise. Pour leur faire confiance, ils ont besoin de preuves vérifiables plus larges et plus approfondies provenant du web en direct, et non d’une liste superficielle de liens.

- Récupérez toujours les informations en direct à partir de
le web - Jusqu'à 1 000 résultats par requête
- Classé pour l'intention d'
- Conçu pour les charges de travail d'
s d'agents en parallèle
Naviguez sur n'importe quel site web comme le ferait un humain.
Donnez la priorité aux sources qui correspondent à la tâche, et non à celles qui sont les plus performantes en matière de référencement.
Récupérez jusqu'à 1 000 résultats sans logique de pagination manuelle.
Réduisez les risques liés aux chemins obsolètes mis en cache ou indexés.
Texte source Markdown nettoyé facultatif pour vérification et RAG
Conçu pour un débit élevé et des charges de travail parallèles des agents
Pourquoi les agents utilisent DiscoverLes moteurs de recherche sont destinés aux humains. Les API de recherche sont optimisées pour la vitesse et les liens les plus pertinents. Discover est conçu pour les flux de travail sensibles au marché qui exigent de l'actualité, un rappel élevé et un contexte vérifiable.
Donnez la priorité aux sources qui correspondent à la tâche, et non à celles qui sont les plus performantes en matière de référencement.

Récupérez jusqu’à 1 000 résultats sans logique de pagination manuelle.
Réduisez les risques liés aux chemins obsolètes mis en cache ou indexés.

Texte source Markdown nettoyé facultatif pour vérification et RAG

Conçu pour un débit élevé et des charges de travail parallèles des agents

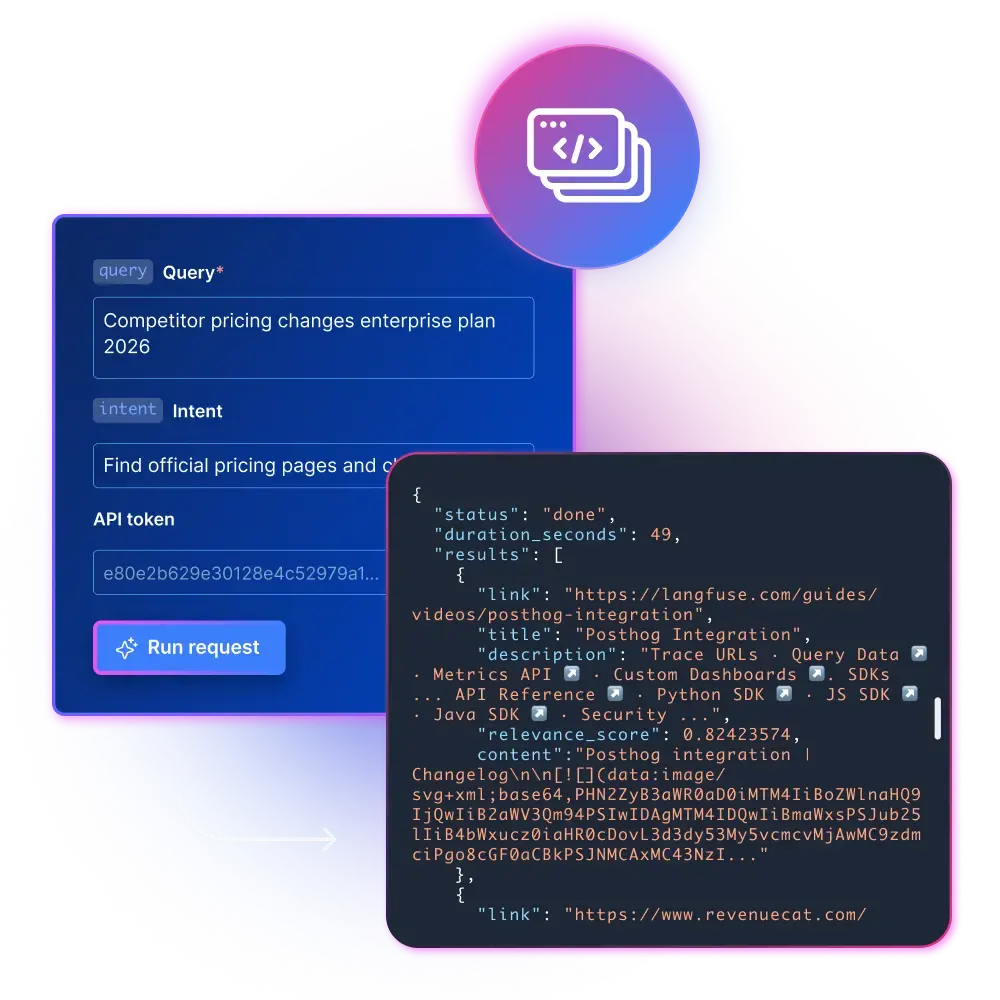
`POST https://api.brightdata.com/discover`
```bash
curl "https://api.brightdata.com/discover"
-H "Authorization: Bearer "
-H "Content-Type: application/json"
-d '{
« query » : « competitor pricing changes enterprise plan 2026 »,
« num_results » : 50,
« intent » : « find official pricing pages and change notes »,
« content » : true,
« format » : « markdown »
}
require('request-promise')({
url: 'https://geo.brdtest.com/mygeo.json',
proxy: 'http://brd-customer-[votre identifiant client]-zone-résidentielle:"[votre mot de passe]"@brd.superproxy.io:33335',
})
.then(function(data){ console.log(data); },
function(err){ console.error(err); });
import requests
url = "https://api.brightdata.com/Jeux de données/snapshots/{id}/download"
headers = {"Authorization": "Bearer "}
response = requests.get(url, headers=headers)
print(response.json())
using System;
using System.Net;
class Example
{
static void Main()
{
// Remplacez « [votre identifiant client] » et « [votre mot de passe] » par vos identifiants réels.
var client = new WebClient();
client.Proxy = new WebProxy("brd.superproxy.io:33335");
client.Proxy.Credentials = new NetworkCredential("brd-customer-[votre identifiant client]-zone-residential", "[votre mot de passe]");
Console.WriteLine(client.DownloadString("https://geo.brdtest.com/mygeo.json"));
}
}
Démarrage rapide
Conçu pour l'intelligence économique

Intelligence compétitive
Suivez les changements de prix, de lancement et de positionnement

Surveillance des risques
Détectez les incidents, les changements de politique et les signaux

Diligence raisonnable
Vérifiez les affirmations auprès de nombreuses sources indépendantes.

Enrichissement
Remplissez le CRM avec des données web vérifiées en temps réel.

Moteurs de recherche verticaux
Créer une recherche classée par intention pour un domaine

Données alternatives
Capturez les signaux à longue traîne sur le web
Conçu pour fonctionner avec les jeux de données Bright Data
Utilisez Discover pour la découverte en direct et les preuves récentes. Utilisez les Jeux de données Bright Data pour établir une base de référence et accélérer la récupération à grande échelle. Pour les besoins en données volumineux et répétitifs, les Jeux de données sont plus rentables que de redécouvrir les mêmes entités encore et encore, et ils offrent à votre agent un point de départ plus solide avant qu’il n’effectue une découverte en direct.
FAQ
Discover est-il mis en cache ou indexé ?
Discover est toujours en ligne. Chaque requête est exécutée au moment de la consultation sur le web en direct.
Que fait l'intention ?
L'intention indique à Discover ce que l'agent essaie d'accomplir afin que les résultats soient classés en fonction de la tâche.
Quand dois-je utiliser include_content ?
Utilisez include_content=true lorsque vous avez besoin d'une vérification ou d'une justification RAG avec le texte source.
Dois-je utiliser Discover ou Jeux de données ?
Utilisez les Jeux de données pour la couverture de base. Utilisez Discover pour la découverte en direct et les nouvelles preuves. La plupart des équipes utilisent les deux.
Puis-je faire des recherches ou un suivi historique ?
Utilisez l'API Web Archive pour le remplissage historique et la surveillance longitudinale.
Que se passe-t-il si j'ai besoin de plus de 1 000 résultats ?
Enchaînez plusieurs appels Discover ou utilisez des Jeux de données pour l'ingestion en masse, puis utilisez Discover pour les maintenir à jour.