

Dans cet article, vous apprendrez :
- Qu’est-ce que la validation des données, quand l’utiliser, les vérifications qu’elle implique et quelles bibliothèques vous devez utiliser pour la mettre en œuvre.
- Comment effectuer la validation des données à l’aide d’un exemple concret en Python.
- Ce qu’est la vérification des données, comment elle fonctionne, des exemples de contrôles de vérification et les meilleures approches.
- Comment mettre en œuvre la vérification des données à l’aide d’un agent IA dédié.
- Un tableau récapitulatif comparant la validation des données et la vérification des données.
C’est parti !
Validation des données : tout ce que vous devez savoir
Commencez ce parcours sur la validation et la vérification des données en explorant la première approche : la validation des données.
Qu’est-ce que la validation des données et pourquoi est-elle importante ?
La validation des données est le processus qui consiste à vérifier l’exactitude, la qualité et l’intégrité des données. Elle est généralement effectuée avant que les données ne soient stockées, utilisées ou traitées. Son objectif ultime est de garantir un niveau constant de qualité et de confiance.
Cette technique permet notamment de vérifier que les données respectent les règles et normes définies. Elle empêche les informations incorrectes ou incomplètes d’entrer dans un système, une application, un flux de travail ou de continuer à circuler dans un pipeline de données.
La validation des données est fondamentale pour maintenir une qualité élevée des données. La validation des données joue également un rôle majeur dans le respect des exigences de conformité telles que le RGPD et le CCPA, ainsi que dans le respect des meilleures pratiques en matière de sécurité.
En appliquant la validation des données, vous pouvez détecter rapidement les erreurs et les problèmes dans vos données. Cela permet d’identifier les problèmes dans le cycle de vie des données avant qu’ils ne s’aggravent, évitant ainsi des erreurs coûteuses et des complications graves.
Exemples de contrôles de validation des données
Les contrôles de validation des données que vous pouvez appliquer sont innombrables et dépendent de vos besoins spécifiques, du type de champs de données et de scénarios particuliers. Parmi les contrôles les plus importants, on peut citer
- Contrôle du type de données: confirme que les données saisies dans un champ sont du type correct (par exemple, s’assurer qu’un champ
d'âgen’accepte que des chiffres). - Contrôle du format: vérifie que les données sont conformes à un modèle spécifique, tel que le format d’un numéro de téléphone
(XXX) XXX-XXXX, le format d’une dateAAAA-MM-JJou le format d’une adresse e-mail[email protected]. - Vérification de la plage: garantit qu’une valeur numérique se situe dans une plage minimale et maximale prédéfinie (par exemple, un champ
de scoredoit être compris entre0et100). - Vérification de présence: confirme qu’un champ obligatoire n’est pas laissé vide ou nul, en s’assurant qu’aucune information critique ne manque.
- Vérification du code: valide qu’une entrée est sélectionnée dans une liste prédéfinie de valeurs acceptables (par exemple, un code pays de la liste ISO 3166).
- Vérification de cohérence: vérifie que les données de plusieurs champs d’une même entrée ou de différentes entrées sont logiques et cohérentes (par exemple, une date de commande doit être antérieure à la date de livraison).
- Contrôle d’unicité: empêche les entrées en double dans les champs qui nécessitent des valeurs uniques, tels que l’identifiant d’un employé ou une adresse e-mail.
Quand l’effectuer
En règle générale, la validation des données doit être effectuée de manière continue tout au long du cycle de vie des données. Parallèlement, plus elle est effectuée tôt, plus elle empêche efficacement les erreurs de se propager. C’est ce qu’on appelle l’approche « shift-left » (décalage vers la gauche) de la qualité des données.
Le moment le plus proactif et le plus efficace pour valider les données est donc au moment de leur saisie. En détectant les erreurs à ce stade, vous vous assurez que les données erronées n’entrent jamais dans vos systèmes, ce qui vous permet d’économiser du temps et des ressources sur le nettoyage en aval. Cela s’applique aux données saisies par les utilisateurs (par exemple, via des formulaires ou des téléchargements de fichiers), aux données récupérées par Scraping web ou aux données provenant de référentiels publics ou ouverts auxquels vous ne faites pas entièrement confiance.
Pour les données soumises par les utilisateurs, par exemple via une API dans un système backend, la validation en temps réel peut fournir un retour immédiat (par exemple, en signalant une adresse e-mail mal formatée ou un numéro de téléphone incomplet directement dans la réponse de l’API avec des erreurs400 Bad Request).
Cependant, il n’est pas toujours possible de valider les données immédiatement. Par exemple, dans les pipelines ETL ou ELT, la validation est généralement appliquée à des étapes spécifiques :
- Après l’extraction: pour vérifier que les données extraites d’un système source n’ont pas été corrompues ou perdues pendant le transfert.
- Après la transformation: pour vérifier que le résultat de chaque étape de transformation (par exemple, les agrégations) respecte les règles et les normes attendues.
Même après le stockage des données, vous devez les revérifier périodiquement. En effet, les données ne sont pas statiques, car elles peuvent être mises à jour, enrichies ou réutilisées. Il est donc nécessaire de procéder à une validation continue.
Comment valider les données
Le processus de validation des données comprend les étapes suivantes :
- Définir les exigences: établir des règles de validation claires basées sur les besoins de l’entreprise, les normes réglementaires et les attentes (par exemple, définir un schéma avec des règles pour vos données).
- Collecter les données: rassemblez les données provenant de diverses sources, telles que le Scraping web, les API ou les bases de données.
- Appliquer la validation: mettre en œuvre les règles définies pour vérifier l’exactitude, la cohérence et l’exhaustivité des données.
- Traiter les erreurs: enregistrer, mettre en quarantaine ou corriger les enregistrements non valides conformément aux politiques de l’organisation. Fournir aux utilisateurs des commentaires clairs lorsqu’ils saisissent des données incorrectes.
- Charger les données: une fois les données validées et nettoyées, chargez-les dans le système cible, tel qu’un entrepôt de données.
Remarque: vous verrez comment appliquer ces étapes dans le chapitre suivant à l’aide d’un exemple guidé en Python.
Bibliothèques pour la validation des données
Vous trouverez ci-dessous un tableau répertoriant certaines des meilleures bibliothèques open source pour la validation des données :
| Bibliothèque | Langage de programmation | Étoiles GitHub | Description |
|---|---|---|---|
| Pydantic | Python | 25,3 k+ | Validation des données à l’aide des indications de type Python |
| Marshmallow | Python | 7,2 k | Une bibliothèque légère pour convertir des objets complexes en types de données Python simples et vice versa. |
| Cerberus | Python | 3,2 k | Bibliothèque de validation de données légère et extensible pour Python |
| jsonschema | Python | 4,8 k+ | Une implémentation de la spécification JSON Schema pour Python |
| Validator.js | JavaScript | 23,6k+ | Bibliothèque de validateurs et de nettoyeurs de chaînes. |
| Joi | JavaScript | 21,2 k | La bibliothèque de validation de données la plus puissante pour JS |
| Yup | JavaScript | 23,6 k+ | Validation de schéma d’objet ultra simple |
| Ajv | JavaScript | 14,4k | Le validateur de schéma JSON le plus rapide. Prend en charge les schémas JSON draft-04/06/07/2019-09/2020-12 et JSON Type Definition (RFC8927) |
| FluentValidation | C# (.NET) | 9,5k | Une bibliothèque de validation .NET populaire pour créer des règles de validation fortement typées. |
| validator | Go | 19,1k+ | Go Validation de structures et de champs, y compris les champs croisés, les structures croisées, les cartes, les tranches et les tableaux |
Comment appliquer la validation des données en Python : exemple étape par étape
Dans ce guide, vous apprendrez à appliquer la validation des données aux données saisies dans JSON à l’aide de Pydantic. Ce tutoriel couvrira les principaux aspects de la création d’un processus de validation des données.
Description du scénario
Supposons que vous récupériez des données à partir d’un site de commerce électronique. Concentrez-vous en particulier sur cette page web de produit:
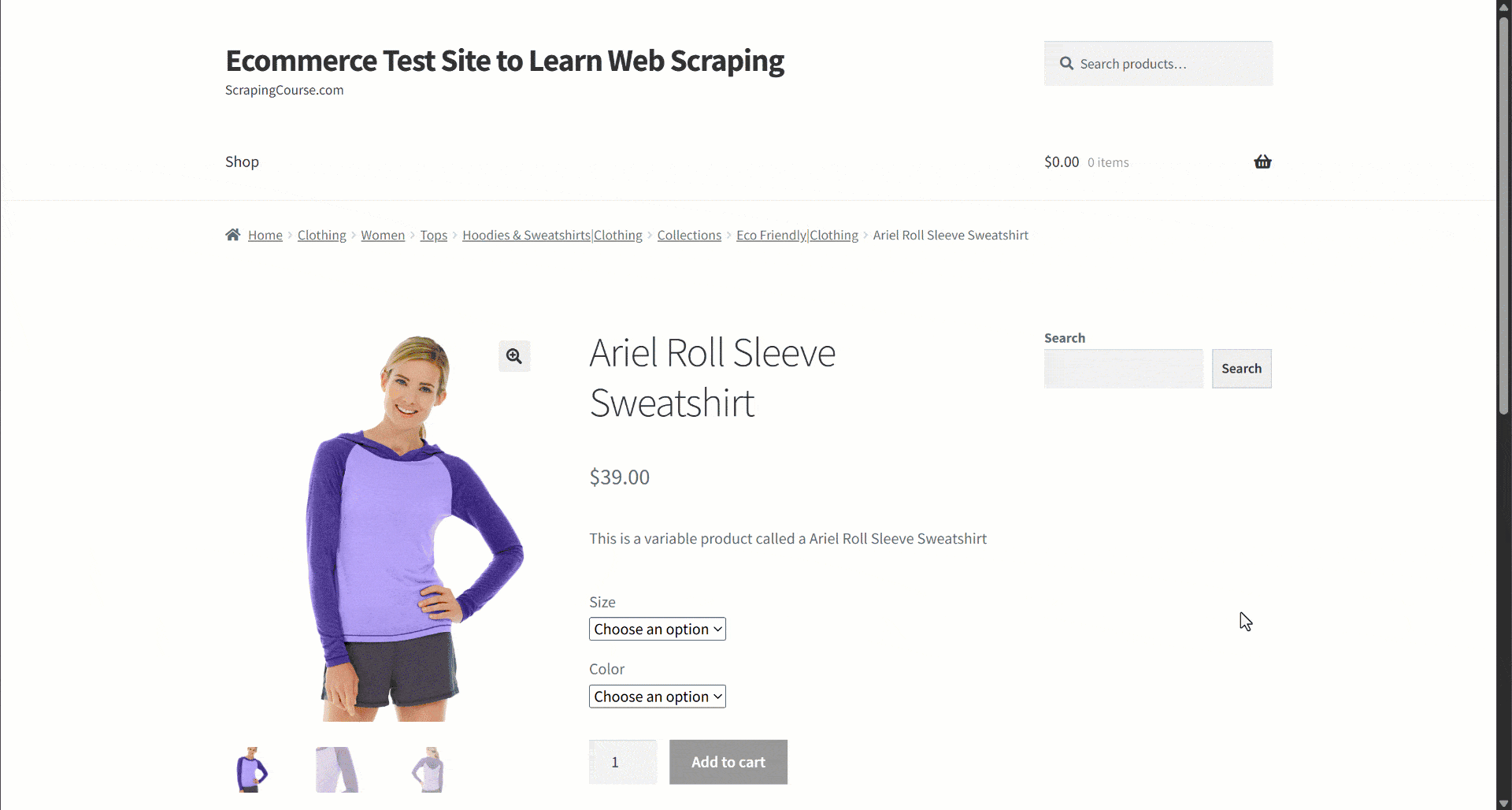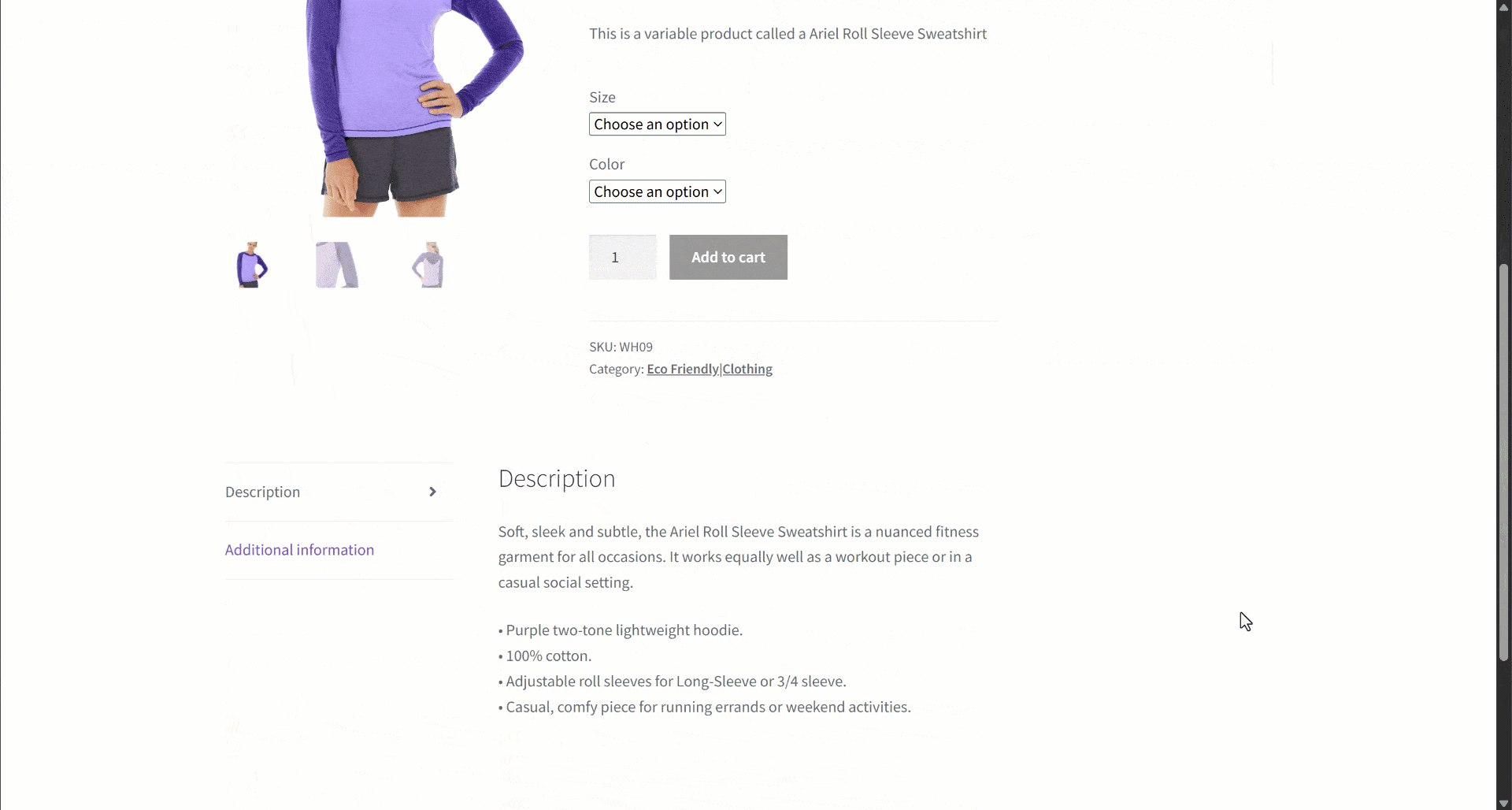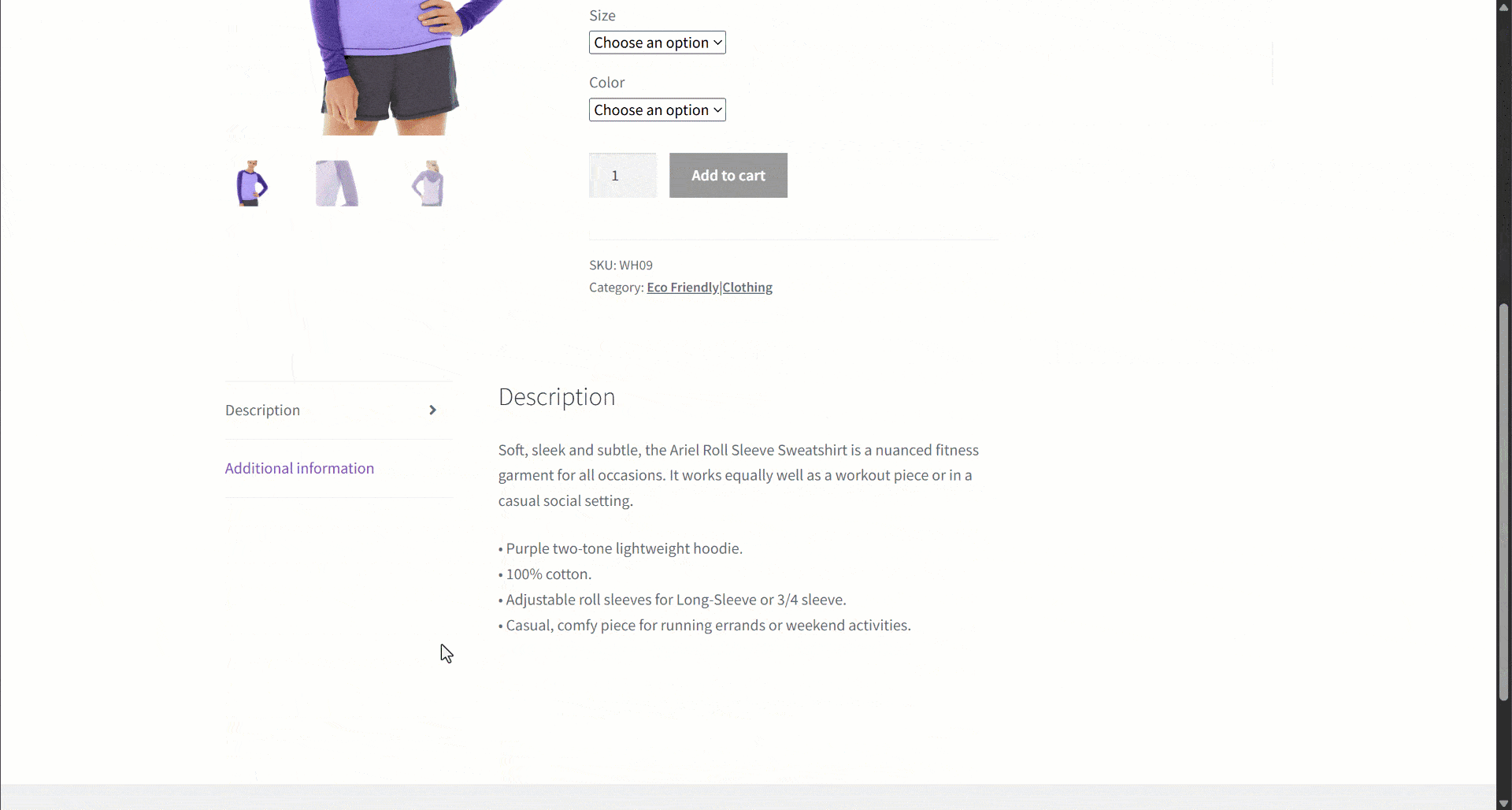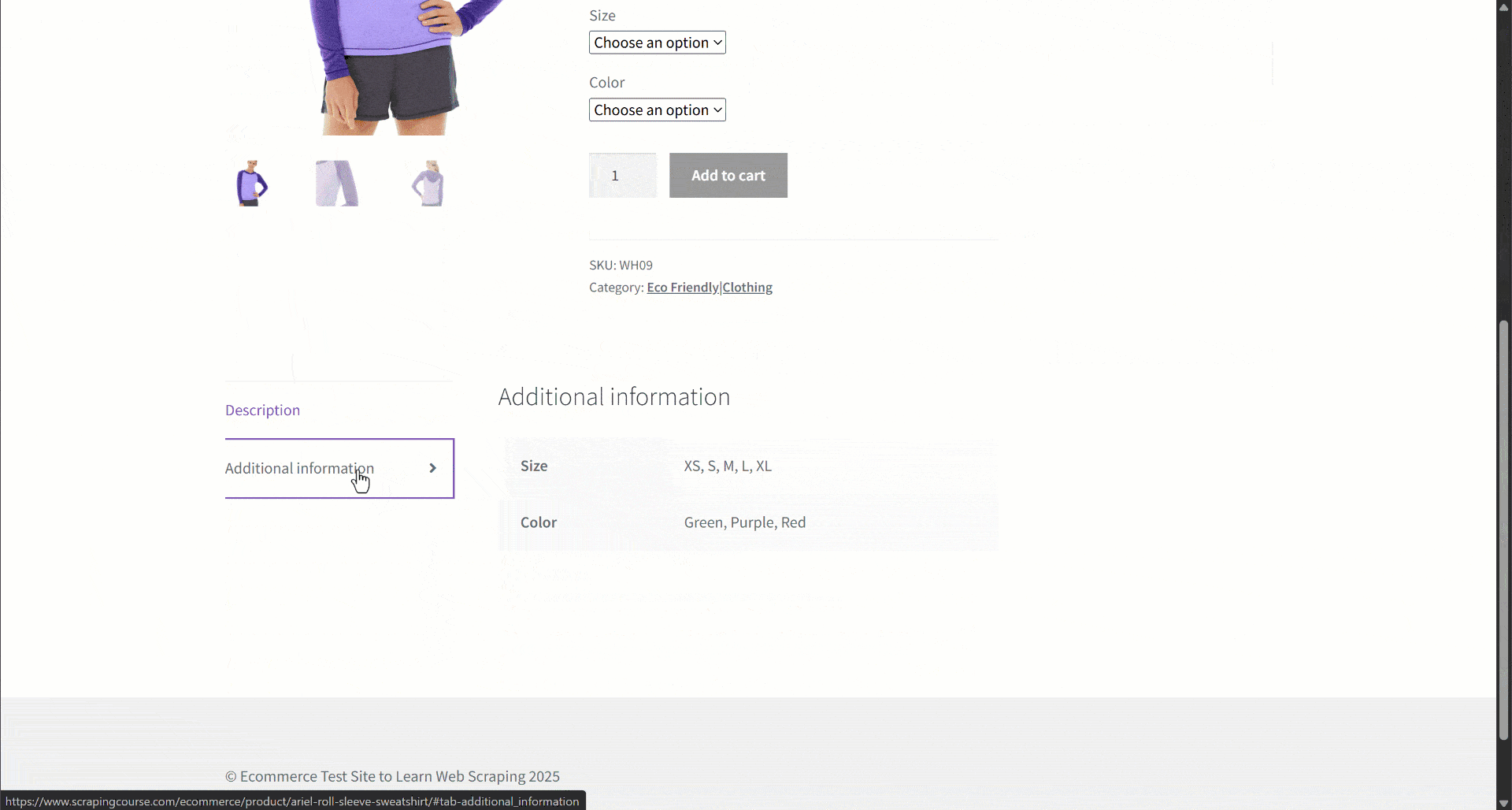
Lors de l’extraction des données, vous fournissez le contenu de la page à un LLM pour simplifier l’analyse des données. Or, les LLM peuvent être imprécis et produire des données inventées, peu fiables ou incomplètes. C’est pourquoi l’application de la validation des données est si importante.
Pour simplifier, nous supposerons que vous disposez déjà d’un projet Python avec un environnement de développement configuré.
Étape n° 1 : définir le schéma et les règles cibles
Commencez par inspecter la page cible et remarquez que la page produit contient les champs suivants :
- URL du produit: l’URL de la page du produit.
- Nom du produit: chaîne contenant le nom du produit.
- Images: liste des URL des images.
- Prix: le prix sous forme de nombre flottant.
- Devise: un seul caractère représentant la devise.
- SKU: chaîne contenant l’identifiant du produit.
- Catégorie: tableau contenant une ou plusieurs catégories.
- Description: champ de texte contenant la description du produit.
- Description longue: champ de texte contenant la description complète du produit avec tous les détails.
- Informations supplémentaires: objet contenant :
- Options de taille: tableau de chaînes de caractères contenant les tailles disponibles.
- Options de couleur: tableau de chaînes contenant les couleurs disponibles.
Ensuite, représentez cela dans un modèle Pydantic comme indiqué ci-dessous :
# pip install pip install pydantic
from typing import List, Optional, Annotated
from pydantic import BaseModel, ConfigDict, HttpUrl, PositiveFloat, StringConstraints, model_validator
class AdditionalInformation(BaseModel):
size_options : Optional[List[str]] = None # nullable
color_options : Optional[List[str]] = None # nullable
class Product(BaseModel) :
model_config = ConfigDict(strict=True, extra="forbid")
product_url : HttpUrl # obligatoire, doit être une URL valide
product_name : str # obligatoire
images : Facultatif[Liste[HttpUrl]] = Aucun # liste d'URL valides, nullable
prix : Facultatif[PositiveFloat] = Aucun # nullable, doit être >= 0
devise : Facultatif[Annoté[str, StringConstraints(min_length=1, max_length=1)]] = Aucun # nullable, caractère unique
sku : str # obligatoire
category : Optional[List[str]] = None # nullable
description : Optional[str] = None # nullable
long_description : Optional[str] = None # nullable
additional_information : Optional[AdditionalInformation] = None # nullable
@model_validator(mode="after")
# Règle de validation personnalisée pour s'assurer que le prix est toujours associé à une devise
def check_currency_if_price(cls, values):
price = values.price
currency = values.currency
if price is not None and not currency:
raise ValueError("currency must be provided if price is set")
return valuesNotez que le modèle Product définit non seulement les champs et leurs types (par exemple, str, HttpUrl, etc.), mais inclut également des contraintes de validation (par exemple, la devise doit être un caractère unique). De plus, il inclut des règles de validation strictes pour garantir que le prix est toujours associé à une devise, et tout champ supplémentaire qui ne correspond pas directement au modèle est interdit.
Étape n° 2 : collecter les données
Supposons que vous récupériez des données via le Scraping web IA, comme indiqué dans l’un des tutoriels ci-dessous :
- Scraping web avec ChatGPT : tutoriel étape par étape
- Scraping web avec Gemini : tutoriel complet
- Scraping web à l’aide de Perplexity : guide étape par étape
- Scraping web avec Claude : analyse syntaxique alimentée par l’IA en Python
Vous obtiendrez un fichier product.json contenant les données extraites. Ici, nous supposerons que le LLM l’a rempli comme suit :
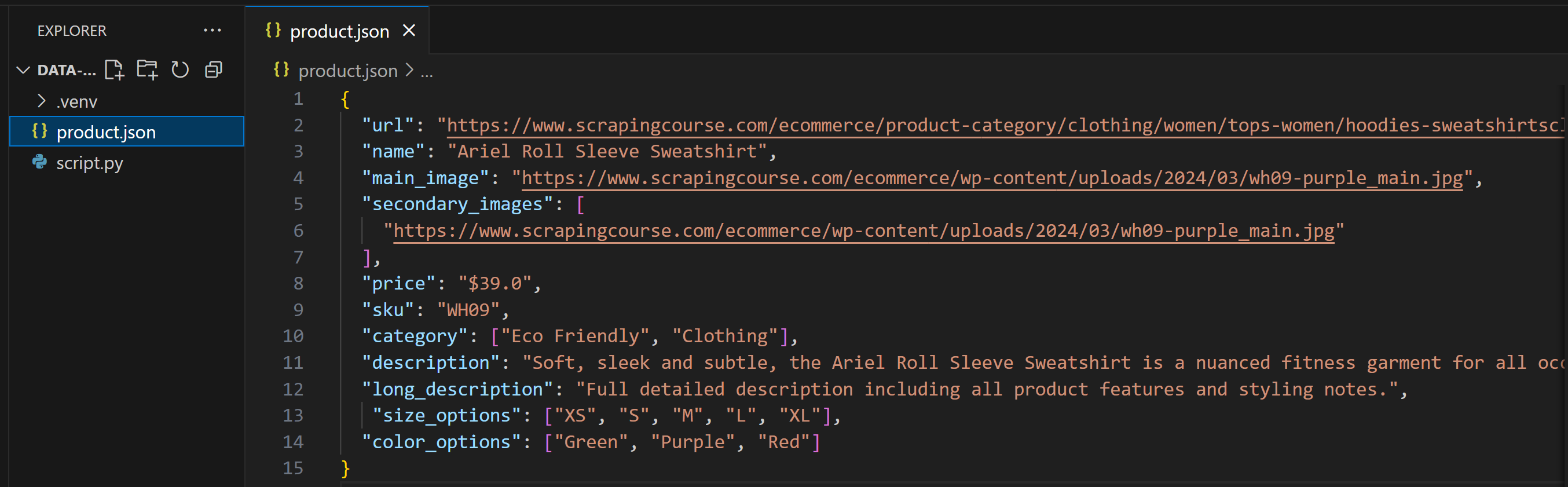
Comme vous pouvez le constater, ce résultat ne correspond pas exactement au modèle Pydantic. Cela est courant si vous ne spécifiez pas explicitement une structure de sortie dans votre invite, ou si l’IA est configurée avec une température trop élevée.
Étape n° 3 : appliquer les règles de validation
Chargez les données du fichier product.json:
import json
input_data_file_name = "product.json"
with open(input_data_file_name, "r", encoding="utf-8") as f:
product_data = json.load(f)Ensuite, validez-les avec Pydantic comme suit :
try:
# Valider les données via le modèle Pydantic
product = Product(**product_data)
print("Validation réussie !")
except ValidationError as e:
print("Échec de la validation :")
print(e)Exécutez votre script et vous obtiendrez un message d’erreur comme celui-ci :
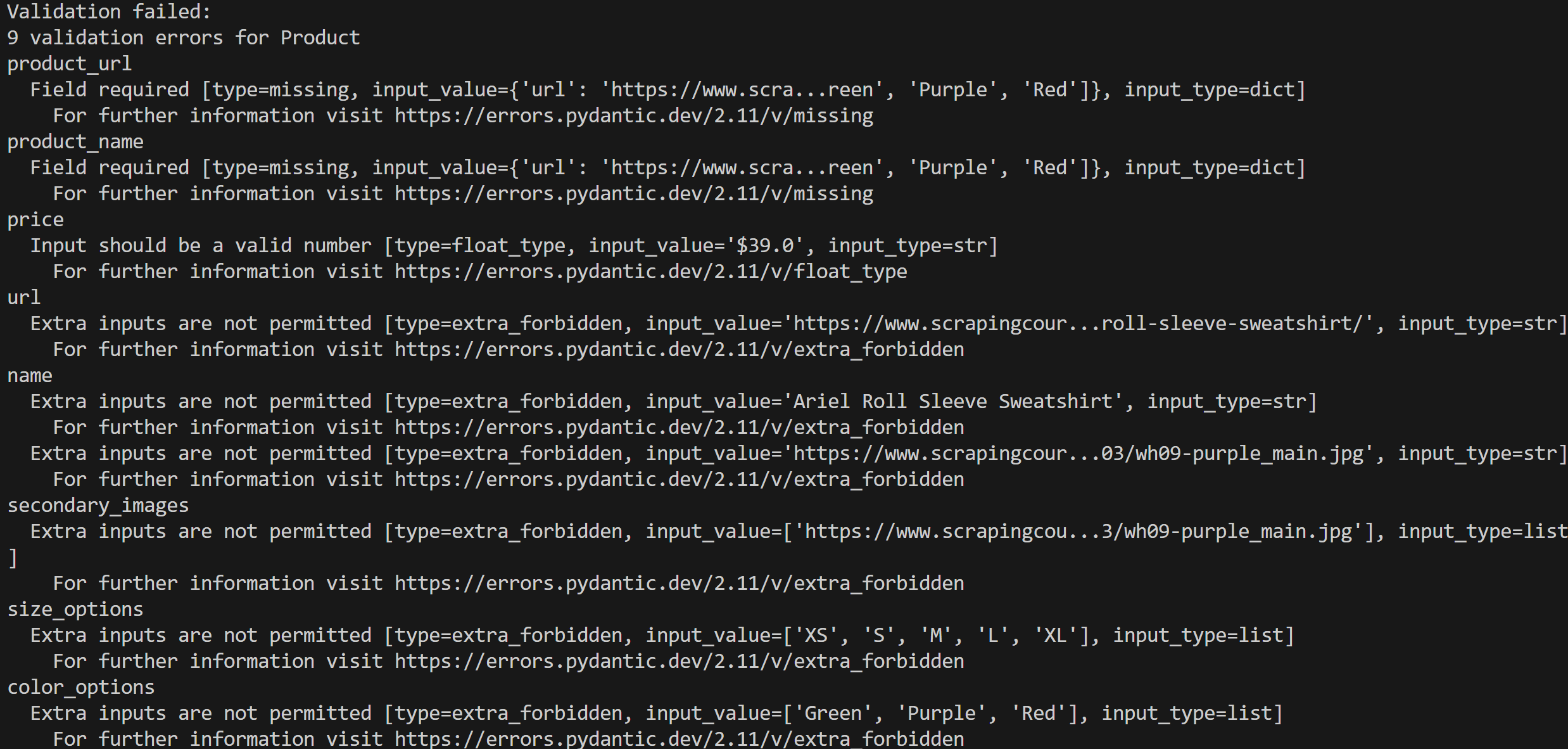
Dans ce cas, 9 erreurs de validation ont été détectées car les données d’entrée ne sont pas conformes au modèle Product.
Étape n° 4 : corriger les erreurs
Il n’existe pas de processus universel permettant de corriger automatiquement les données afin qu’elles passent l’étape de validation. Chaque pipeline ou workflow de données est différent, et vous devrez peut-être intervenir à différents niveaux.
Dans ce cas, la solution est aussi simple que de spécifier clairement le format de sortie attendu dans l’invite LLM, une fonctionnalité prise en charge par la plupart des LLM comme OpenAI.
Astuce: vous pouvez voir cette fonctionnalité en action dans notre guide sur le Scraping web visuel avec GPT Vision.
Sinon, si la fonctionnalité de sortie structurée n’est pas disponible, vous pouvez toujours demander au LLM de faire correspondre le modèle Pydantic attendu dans l’invite en le vidant sous forme de chaîne JSON :
prompt = f"""
Extraire les données du contenu de la page donnée et les renvoyer avec la structure suivante :
{Product.model_json_schema()}
CONTENU :
<contenu de la page>
"""Dans les deux cas, la sortie du LLM doit correspondre au format attendu.
Après avoir apporté cette modification, product.json contiendra :
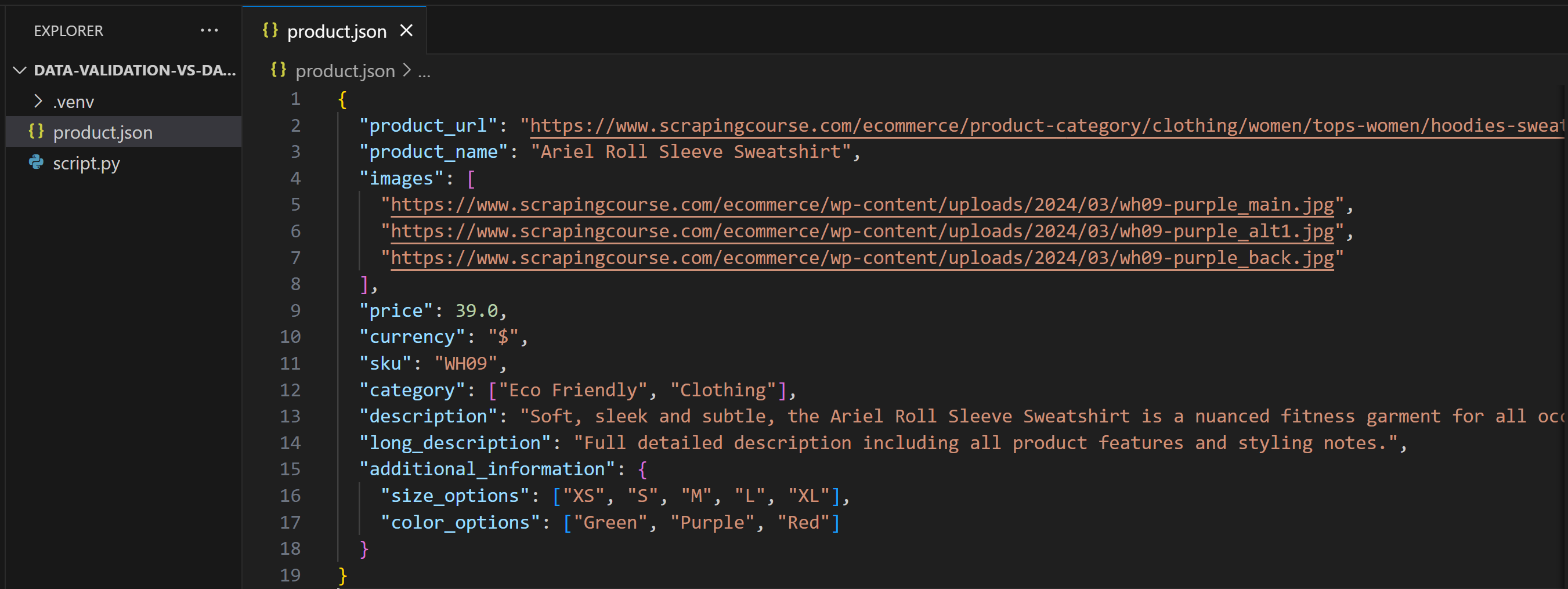
Cette fois-ci, lorsque vous exécuterez le script, il produira :

Parfait ! La validation des données est réussie. Une fois les données validées, vous pouvez procéder à leur traitement, les stocker dans une base de données ou effectuer d’autres opérations.
Vérification des données : les bases expliquées
Poursuivons ce guide sur la validation et la vérification des données en nous concentrant sur la deuxième technique : la vérification des données.
Qu’est-ce que la vérification des données et pourquoi est-elle importante ?
La vérification des données consiste à vérifier que les données sont exactes et reflètent la réalité. Pour ce faire, on compare les informations à des sources faisant autorité.
Contrairement à la validation des données, qui vérifie uniquement si les données respectent des règles prédéfinies (par exemple, si une adresse e-mail est correctement formatée), la vérification confirme que les données sont véridiques et correspondent à la réalité (par exemple, que l’adresse e-mail existe réellement et appartient à la personne concernée).
La vérification des données est essentielle pour garantir la qualité des données, en particulier en ce qui concerne la signification des informations. Après tout, même des données bien structurées et apparemment propres peuvent contenir des informations erronées. Se fier à des données inexactes peut entraîner des erreurs coûteuses, des décisions erronées, une mauvaise expérience client et des inefficacités opérationnelles.
Exemples de contrôles de vérification des données
La vérification des données peut s’avérer délicate, et la bonne approche dépend fortement des données d’entrée et du domaine dans lequel vous opérez. Néanmoins, voici quelques méthodes de vérification courantes :
- Vérification automatisée: utilisation de logiciels spécialisés, de services tiers ou de systèmes d’IA agentique pour recouper les données avec des sources fiables.
- Relecture: révision manuelle des documents, des données ou des champs de données afin de s’assurer qu’ils contiennent des informations précises. Cette opération peut être effectuée manuellement par des humains utilisant leurs connaissances sur un sujet, ou automatiquement par l’IA.
- Double saisie: deux systèmes distincts (ou agents IA autonomes) saisissent indépendamment des données sur le même sujet. Les enregistrements sont ensuite comparés et toute divergence est signalée pour être examinée ou corrigée.
- Vérification des données sources: comparer les données stockées dans une base de données avec les documents sources originaux (par exemple, les dossiers médicaux des patients) afin de confirmer qu’elles correspondent.
Quand le faire
La vérification des données doit être effectuée chaque fois que vous ne faites pas entièrement confiance à la source des données. Un exemple courant est l’utilisation de l’IA pour générer ou enrichir des données, ce qui peut produire des informations plausibles mais inexactes.
Un autre scénario dans lequel la vérification des données est importante est celui où les données ont été transférées ou stockées, par exemple lors de migrations ou de consolidations. Après de telles tâches, vous devez vous assurer que les données obtenues restent exactes. La vérification des données est également pertinente dans le cadre du maintien continu de la qualité des données.
Gardez à l’esprit que la vérification des données suit généralement la validation des données. Si la structure des données ne correspond pas au format attendu, la vérification n’a pas de sens, car les données peuvent ne pas être utilisables dans leur ensemble. Ce n’est qu’après la validation des données qu’il est judicieux de procéder à leur vérification.
La vérification des données est certainement plus complexe que leur validation, car vous ne pouvez pas obtenir de résultats déterministes (comme démontré précédemment avec un simple script Python). En effet, il est très difficile de déterminer avec une certitude absolue si les informations sont vraies.
Principales approches de la vérification des données
Lorsqu’il s’agit de contenus soumis par les utilisateurs, le meilleur moyen de les vérifier est de recourir à une vérification humaine. Voici quelques exemples :
- Vérification de l’adresse e-mail: après qu’un utilisateur a saisi une adresse e-mail lors de son inscription, un e-mail automatisé contenant un lien ou un code de confirmation lui est envoyé afin de s’assurer que l’adresse est valide et accessible.
- Vérification du numéro de téléphone: un mot de passe à usage unique (OTP) est envoyé par SMS ou par appel téléphonique pour confirmer que le numéro est valide, actif et appartient à l’utilisateur.
De même, vous pouvez demander aux utilisateurs de fournir des documents ou des factures pour vérifier leur identité ou leur adresse. Ces documents peuvent être traités à l’aide de systèmes OCR afin de vérifier que les données saisies par l’utilisateur correspondent aux informations figurant sur les documents téléchargés. Bien que cette approche puisse encore être vulnérable à la fraude, elle est très utile pour accroître la fiabilité des données.
Le véritable défi se pose lors de la récupération de données publiques sur le web, la source d’informations la plus importante et la moins structurée. Dans ce cas, il est difficile de déterminer si les informations sont correctes. L’approche générale consiste à donner la priorité aux sources fiables (par exemple, la documentation, les déclarations officielles) et, à partir d’un contenu donné, à retracer son origine, à le recouper en ligne avec des sources fiables et à comparer les résultats.
Cette opération manuelle est extrêmement chronophage, c’est pourquoi bon nombre de ces tâches sont désormais automatisées à l’aide d’agents IA équipés d’outils de recherche et de Scraping web.
Comment vérifier les données : exemple en Python
Dans cette section, vous trouverez un exemple étape par étape de la manière de créer un agent IA pour la vérification des données. L’agent va :
- Prendre un exemple de texte en entrée.
- Transmettre les informations à un LLM étendu avec des outils de recherche et de scraping web.
- Demander à l’IA d’identifier les principaux sujets du texte source et de rechercher sur Google des pages pertinentes et fiables afin de vérifier l’exactitude des informations.
- Récupérera les informations de ces pages et les comparera au texte source.
- Renvoyer un rapport indiquant si les données sont exactes et, dans le cas contraire, suggérer des solutions pour les corriger.
Ce type de flux de travail ne serait pas possible sans une infrastructure prête pour l’IA qui prend en charge la récupération de données web, la recherche, l’interaction, etc., telle que celle fournie par l’infrastructure IA de Bright Data.
Pour faciliter l’intégration, nous utiliserons le Bright Data Web MCP, qui propose plus de 60 outils. Plus précisément, son niveau gratuit comprend ces deux outils :
search_engine: récupère les résultats de recherche de Google, Bing ou Yandex au format JSON ou Markdown.scrape_as_markdown: extrait n’importe quelle page web au format Markdown propre, en contournant la détection des robots et le CAPTCHA.
Ces deux outils suffisent pour alimenter l’agent de vérification des données et atteindre l’objectif !
Description du scénario
Supposons que vous disposiez de données d’entrée dans un fichier summary.txt dont vous souhaitez vérifier l’exactitude. Par exemple, celui-ci contient un bref résumé du Super Bowl LIX :

Vous allez créer un agent de vérification des données à l’aide de LangChain intégré à Web MCP. Pour suivre, vous aurez besoin de :
- Python installé localement.
- Un projet LangChain configuré.
- Une clé API Bright Data pour authentifier votre connexion à Web MCP.
- Une clé API OpenAI.
Avant de commencer, consultez notre tutoriel sur l’utilisation de l’adaptateur LangChain MCP pour l’intégration avec Web MCP de Bright Data. Si vous préférez utiliser d’autres frameworks ou outils, consultez ces guides :
- Création d’agents de Scraping web avec CrewAI et le protocole MCP (Model Context Protocol) de Bright Data
- Création d’un chatbot CLI avec LlamaIndex et le MCP de Bright Data
- Intégration de Claude Code avec le Web MCP de Bright Data
- Comment créer un chatbot RAG avec GPT-4o à l’aide des données SERP
Créer un agent IA pour la vérification des données
Voici comment créer un agent de vérification des données à l’aide de LangChain et du Web MCP de Bright Data :
# pip install langchain["openai"] langchain-mcp-adapters langgraph
import asyncio
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Remplacez par votre clé API OpenAI
from langchain_openai import ChatOpenAI
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
async def main():
# Charger les données d'entrée à vérifier
input_file_name = "summary.txt"
with open(input_file_name, "r", encoding="utf-8") as f:
summary_data_to_verify = f.read()
# Initialiser le moteur LLM
llm = ChatOpenAI(
model="gpt-5-nano",
)
# Configuration pour se connecter à une instance locale du serveur Bright Data Web MCP
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>", # Remplacez par votre clé API Bright Data
}
)
# Connexion au serveur MCP
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# Initialisation de la session client MCP
await session.initialize()
# Obtention des outils MCP
tools = await load_mcp_tools(session)
# Créer l'agent ReAct
agent = create_react_agent(llm, tools)
# Description de la tâche de l'agent
input_prompt = f"""
Compte tenu du contenu saisi ci-dessous, procédez comme suit :
1. Identifiez le sujet principal comme une requête de recherche de type Google et utilisez-le pour effectuer une recherche sur le Web afin de recueillir des informations à son sujet.
2. À partir des résultats de recherche, sélectionnez les 2/3 sources les plus fiables (par exemple, sites d'information fiables, revues, publications officielles).
3. Extrayez le contenu des pages sélectionnées.
4. Comparez les informations extraites avec le contenu saisi afin de déterminer si elles sont exactes.
5. Si elles ne sont pas exactes, rédigez un rapport répertoriant toutes les erreurs trouvées dans le contenu saisi, ainsi que les informations corrigées et les liens vers les sources à l'appui.
Contenu saisi :
{summary_data_to_verify}
"""
# Diffuser la réponse de l'agent
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
step["messages"][-1].pretty_print()
if __name__ == "__main__":
asyncio.run(main())Concentrez-vous sur l’invite elle-même, car c’est la partie la plus importante du script ci-dessus.
Exécutez l’agent
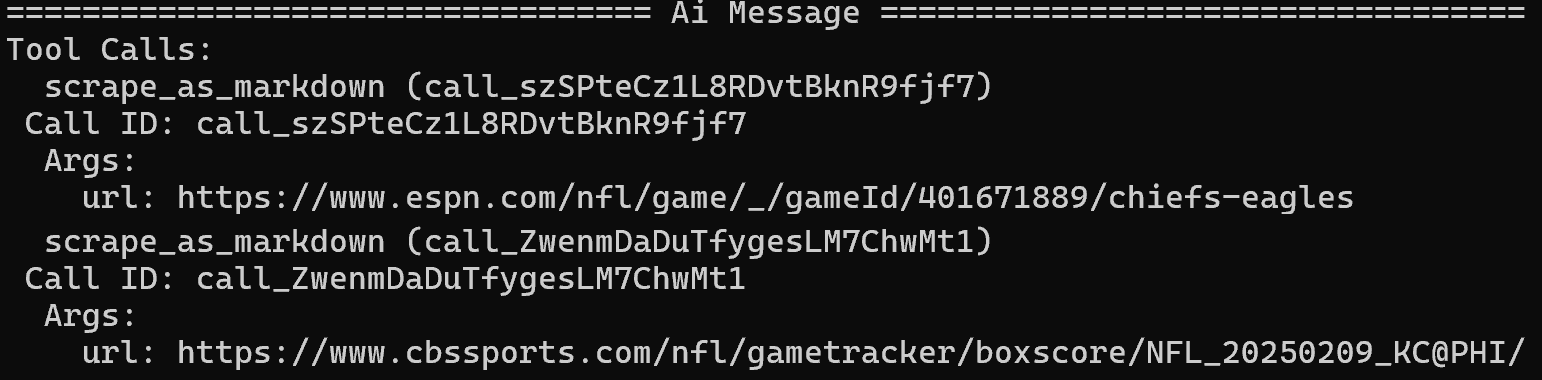
Lancez votre agent et vous verrez qu’il identifie correctement le sujet principal comme étant « Super Bowl LIX ». Il effectuera ensuite une recherche Google à l’aide de l’outilsearch_engine de Web MCP:

À partir des résultats de recherche, il identifie les articles d’ESPN et de CBS Sports comme sources principales et les extrait à l’aide de l’outil scrape_as_markdown:
Après avoir extrait le contenu des trois sources d’information, il produit le rapport Markdown suivant :
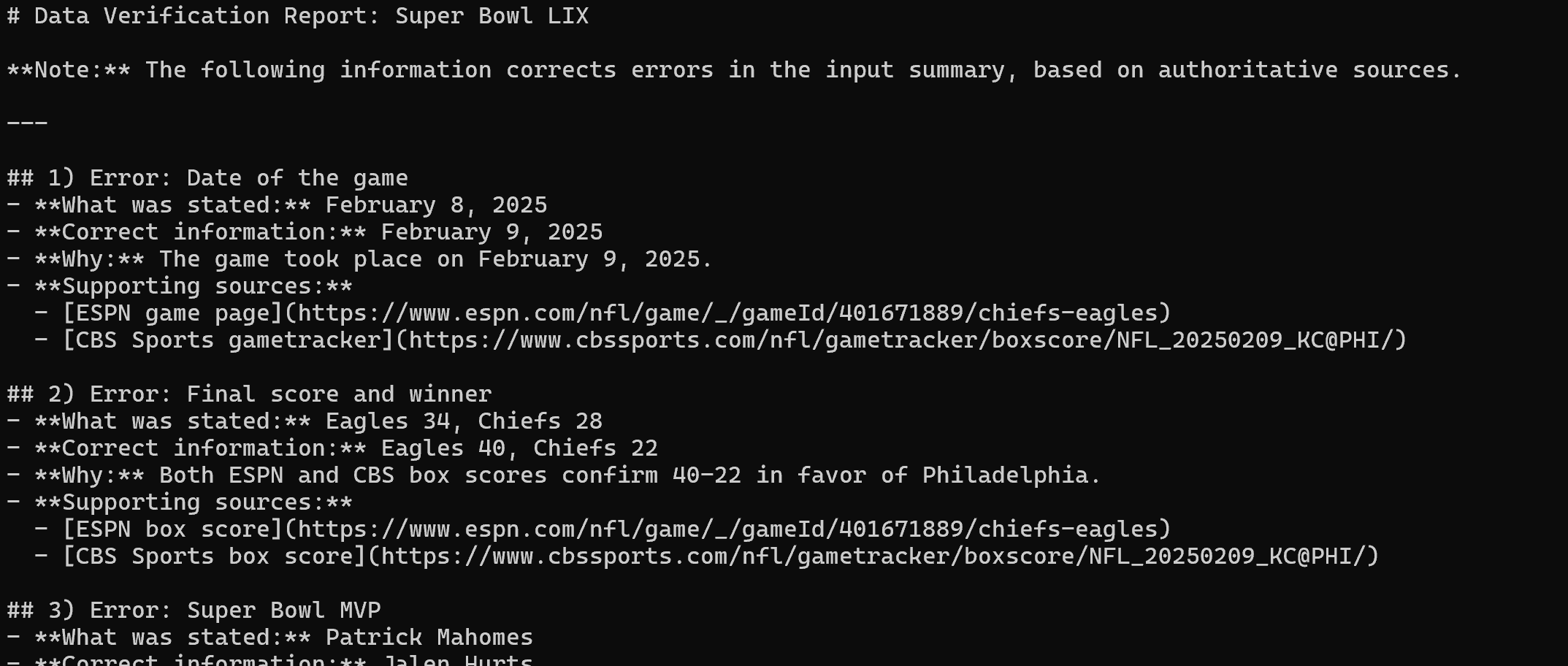
Affichez-le dans Visual Studio Code pour voir le rapport final.
Comme vous pouvez le constater, grâce aux capacités de recherche et de Scraping web de Web MCP, l’agent LangChain a pu identifier toutes les erreurs dans le texte incorrect d’origine. Mission accomplie !
Validation des données vs vérification des données : tableau récapitulatif
Comparez les deux techniques dans le tableau récapitulatif ci-dessous :
| Aspect | Validation des données | Vérification des données |
|---|---|---|
| Définition | Vérifie l’exactitude, la qualité et l’intégrité des données par rapport à des règles et normes prédéfinies avant leur utilisation ou leur stockage. | Confirme que les données reflètent fidèlement la réalité en les comparant à des sources faisant autorité. |
| Objectif | Garantit que les données sont conformes aux formats, types, plages et règles attendus ; empêche les données erronées d’entrer dans les systèmes. | Garantit que les données sont véridiques, exactes et fiables pour la prise de décision. |
| Moment | Effectué au moment de la saisie, après l’extraction, après la transformation ou périodiquement. | Effectué après la validation ou lorsque la fiabilité de la source des données est incertaine ; généralement après la collecte ou le transfert des données. |
| Complexité | Relativement simple ; contrôles déterministes basés sur des règles définies. | Plus complexe ; peut impliquer des incertitudes, des sources externes et une vérification manuelle ; résultats non déterministes possibles. |
| Exemple | le prix doit être ≥ 0 |
Vérifier que le prix correspond à celui indiqué dans la liste officielle du magasin |
Commentaire final
Comme vous l’avez appris dans cet article de blog sur la validation et la vérification des données, la validation et la vérification des données sont deux tâches différentes mais complémentaires. Elles contribuent toutes deux à garantir une qualité élevée des données. Elles ont également en commun le fait que négliger l’une ou l’autre peut entraîner des problèmes importants dans les processus basés sur les données, qui soutiennent la plupart des opérations commerciales.
C’est pourquoi il est vraiment indispensable de choisir un fournisseur de données fiable et digne de confiance qui propose plusieurs solutions pour garantir une validation correcte des données et fournit les outils nécessaires pour mettre en place un système de vérification des données efficace.
Bright Data en est un excellent exemple. Il propose une large gamme de produits, notamment des Jeux de données validés et prêts à l’emploi, ainsi qu’une sélection complète de solutions de Scraping web compatibles avec l’IA pour recueillir des informations précises sur le web, prenant en charge à la fois les workflows de validation et de vérification.
Inscrivez-vous dès aujourd’hui pour obtenir un compte Bright Data gratuit et découvrir nos services de données !




