

Dans cet article, vous découvrirez :
- Ce qu’est CloakBrowser, ce qu’il propose et comment il fonctionne.
- Ce qu’est l’API Browser de Bright Data, les fonctionnalités qu’elle offre et les avantages d’infrastructure qu’elle apporte.
- Comment les deux solutions abordent la navigation furtive et la gestion des empreintes digitales.
- Les différents modèles d’infrastructure sur lesquels reposent les deux outils.
- Les intégrations et outils pris en charge par CloakBrowser et l’API Browser.
- Un tableau comparatif final CloakBrowser vs Bright Data Browser API pour les comparer en un coup d’œil.
Plongeons dans le vif du sujet !
Présentation de CloakBrowser
Avant d’entrer dans la comparaison CloakBrowser vs Bright Data Browser API, découvrons ce que CloakBrowser apporte.
Qu’est-ce que CloakBrowser ?

CloakBrowser est un navigateur furtif open source basé sur un binaire Chromium personnalisé. Il fonctionne comme une solution d’automatisation de navigateur et de Scraping web.
Contrairement aux plugins furtifs traditionnels qui s’appuient sur des injections JavaScript, des correctifs de navigateur ou des ajustements de configuration, CloakBrowser modifie les empreintes digitales du navigateur directement au niveau du code source C++ de Chromium. Cette approche vise à produire un comportement de navigateur plus cohérent et plus réaliste.
Cet outil fonctionne comme un remplacement direct de Playwright et Puppeteer. Il inclut une gestion intégrée des empreintes digitales, une simulation d’interactions humaines, la prise en charge de Proxy, des profils de navigateur persistants et des intégrations avec des agents IA et des frameworks d’automatisation.
Ces dernières semaines, le projet a gagné en popularité. Il est passé de quelques milliers d’étoiles GitHub à plus de 21 200 étoiles au moment de la rédaction.
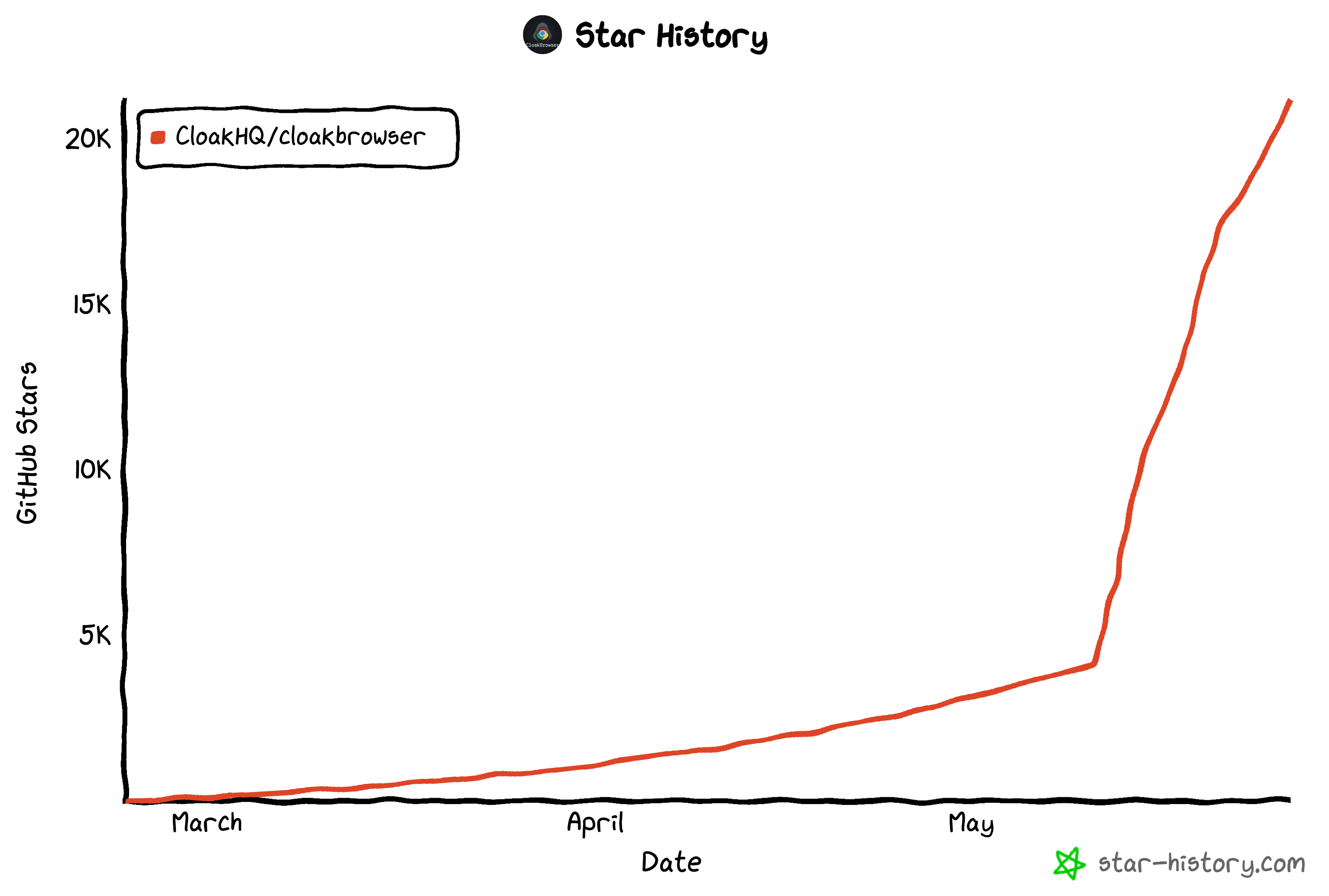
Il est même apparu dans les dépôts tendance hebdomadaires de GitHub sur toute la plateforme :
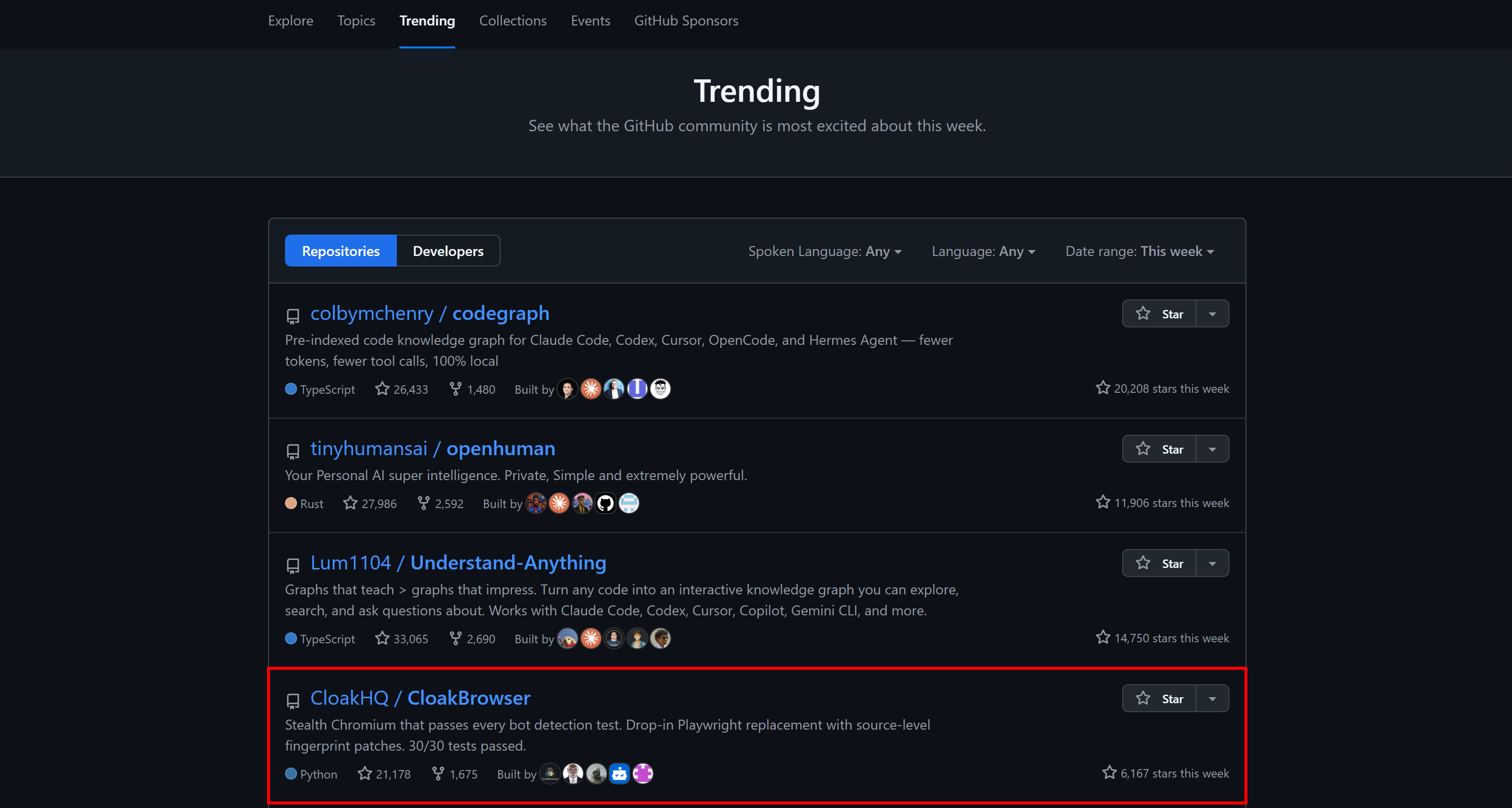
Fonctionnalités principales
Voici les principales fonctionnalités offertes par le projet CloakBrowser :
- Correctifs d’empreinte Chromium au niveau source : Applique plus de 58 modifications C++ au GPU, au canvas, à WebGL, à l’audio, aux polices et aux signaux de temporisation directement dans le moteur du navigateur.
- Gestion automatique des binaires : Télécharge automatiquement la version personnalisée de Chromium, sans configuration manuelle requise.
- Remplacement direct de Playwright et Puppeteer : Conserve la même API, de sorte que le code d’automatisation existant fonctionne en modifiant seulement quelques lignes de code.
- Moteur d’interaction humaine : Simule des mouvements de souris réalistes, la temporisation du clavier, le comportement de défilement et la dynamique de clic via un simple indicateur
humanize=True. - Prise en charge avancée des proxies : Prend en charge les proxies HTTP et SOCKS5 avec authentification, ainsi qu’un alignement optionnel du fuseau horaire et des paramètres régionaux basé sur la géolocalisation IP.
- Profils de navigateur persistants : Peut maintenir les cookies,
localStorageet le cache entre les sessions pour permettre des flux de travail authentifiés de longue durée. - Système de contrôle des empreintes digitales : Utilise des graines déterministes ou aléatoires pour générer des identités de navigateur cohérentes ou rotatives entre les sessions.
- Taux de réussite élevé contre la détection de bots : Passe les principaux systèmes comme reCAPTCHA v3, Cloudflare Turnstile, FingerprintJS et BrowserScan dans les tests de référence.
Comment fonctionne CloakBrowser
CloakBrowser fonctionne comme une fine couche d’automatisation au-dessus d’un navigateur basé sur Chromium personnalisé. Voici comment il fonctionne :
- Vous installez CloakBrowser via
pipounpm. - Lors de la première exécution, il télécharge automatiquement un binaire Chromium précompilé pour votre système d’exploitation.
- Chaque session ultérieure est lancée dans ce navigateur personnalisé.
- Votre code existant reste inchangé et continue d’utiliser les API standard de Playwright ou Puppeteer.
Remarque : CloakBrowser peut également être configuré via Docker et connecté via des outils standard tels que Playwright, Puppeteer, Selenium ou tout framework compatible CDP.
Le binaire Chromium comprend des dizaines de modifications C++ de bas niveau qui ajustent ou masquent les signaux d’empreinte digitale du navigateur. Il réduit également la détection d’automatisation en modifiant les signaux internes du navigateur et au niveau CDP. Ces modifications sont compilées directement dans les binaires Chromium téléchargés.
Une implication clé de cette conception est que seule la couche wrapper est open source, tandis que le binaire du navigateur est distribué en tant qu’artefact précompilé. Cela limite l’inspection directe ou la rétro-ingénierie de la logique d’empreinte digitale (par les entreprises derrière les WAF et autres solutions anti-bot), car les modifications critiques sont intégrées dans le code compilé.
Démarrage
Commencez par installer CloakBrowser. En Python, exécutez :
pip install cloakbrowserOu dans un projet Node.js, installez-le avec :
npm install cloakbrowserUne fois installé, vous pouvez utiliser les API standard de Playwright ou Puppeteer. Par exemple, voici un exemple Python dans le style Playwright :
# pip install cloakbrowser
from cloakbrowser import launch
browser = launch()
page = browser.new_page()
page.goto("https://example.com")
print(page.title()) # Résultat attendu : "Example Domain"
browser.close()Ou, de manière équivalente, en JavaScript :
// npm install cloakbrowser
import { launch } from "cloakbrowser";
const browser = await launch();
const page = await browser.newPage();
await page.goto("https://example.com");
console.log(await page.title()); // Résultat attendu : "Example Domain"
await browser.close();Notez que la logique d’automatisation reste identique à celle de Playwright ou Puppeteer standard. CloakBrowser ne modifie que la façon dont le navigateur est lancé, pas la façon dont vous écrivez le code d’automatisation.
La seule différence est la fonction launch(), qui initialise une session CloakBrowser. Par défaut, elle démarre une session de navigateur sans interface avec la configuration furtive par défaut. Pour plus de contrôle, consultez les arguments disponibles pris en charge par la fonction launch().
Lors de la première exécution de votre script, CloakBrowser :
- Détecte votre système d’exploitation.
- Télécharge un binaire précompilé basé sur Chromium pour votre plateforme.
- Le met en cache localement pour une utilisation future.
À partir de ce moment, chaque appel à launch() démarre le binaire Chromium personnalisé via Playwright ou Puppeteer.
Tarification
CloakBrowser n’a pas de frais d’abonnement, de limites d’utilisation ou de niveaux payants. Vous pouvez donc l’installer et l’utiliser gratuitement. Cependant, les coûts réels proviennent de l’infrastructure environnante.
Pour une utilisation évolutive, vous devez vous appuyer sur des intégrations avec des fournisseurs de Proxy tiers de confiance. Les proxies sont essentiels pour les charges de travail d’automatisation distribuées et peuvent devenir le principal coût opérationnel, selon le volume de Trafic et la couverture géographique.
De plus, CloakBrowser est souvent déployé sur plusieurs serveurs en utilisant Docker dans les environnements de production. Cela permet une mise à l’échelle horizontale, mais introduit également une surcharge supplémentaire, notamment l’orchestration des conteneurs, la gestion des instances, la surveillance et la maintenance continue.
Par conséquent, même si CloakBrowser lui-même est gratuit, la complexité opérationnelle et les coûts d’infrastructure augmentent à mesure que vous évoluez.
Introduction à l’API Browser de Bright Data
Poursuivons cette comparaison CloakBrowser vs Bright Data Browser API en explorant l’API Browser en détail.
Qu’est-ce que l’API Browser ?
L’API Browser de Bright Data est une automatisation de navigateur gérée dans le cloud, optimisée pour l’interaction web à grande échelle et la collecte de données en production.
Plutôt que d’exécuter et de maintenir une infrastructure de navigateur locale, elle vous permet de connecter vos scripts Playwright, Puppeteer ou Selenium existants à des navigateurs furtifs entièrement hébergés. Ces navigateurs sont automatiquement mis à l’échelle et maintenus dans le cloud.
Elle est conçue pour les scénarios où la fiabilité, la capacité de déblocage et l’échelle sont essentielles. Les cas d’usage courants incluent le Scraping web dynamique, les tests QA automatisés, la génération de leads, et bien plus.
Elle est soutenue par le vaste réseau de Proxy de Bright Data comptant plus de 400 millions d’IPs, permettant une forte géo-distribution, une rotation des IP et une évolutivité et une concurrence illimitées. La solution gère la Résolution de CAPTCHA, les empreintes digitales, la gestion des sessions et le rendu JavaScript de manière native. Grâce à ces fonctionnalités, elle atteint des taux de réussite élevés contre les sites web fortement protégés.
L’API Browser prend en charge tous les outils compatibles CDP, ainsi que les flux de travail d’agents IA modernes via Web MCP. Cela signifie qu’elle convient également aux agents autonomes qui doivent naviguer, cliquer et extraire des informations en temps réel.
Fonctionnalités principales
Voici les fonctionnalités clés de l’API Browser de Bright Data :
- Infrastructure de navigateur gérée dans le cloud : Des navigateurs entièrement hébergés s’exécutent dans le cloud, éliminant la configuration locale, la gestion des proxies et la maintenance de l’infrastructure.
- Compatibilité Playwright, Puppeteer, Selenium : L’intégration directe avec la plupart des frameworks d’automatisation de navigateur permet la réutilisation des scripts existants avec des modifications minimales, facilitant une migration rapide.
- Résolution de CAPTCHA intégrée : Détecte et résout automatiquement les CAPTCHA et les systèmes challenge-réponse, réduisant les interruptions de scraping et supprimant le besoin de services externes.
- Accès à un vaste réseau de Proxy : Exploite un Pool de proxies d’IPs résidentielles de plus de 400 millions d’adresses pour permettre des requêtes géo-distribuées et réduire le blocage et la détection.
- Émulation d’empreintes digitales de navigateur : Simule les caractéristiques de navigateur d’un utilisateur réel pour réduire le risque de détection et améliorer la fiabilité contre les systèmes anti-bot avancés.
- Infrastructure à mise à l’échelle automatique : Provisionne dynamiquement les sessions de navigateur en fonction de la demande, prenant en charge des charges de travail à haute concurrence sans mise à l’échelle manuelle.
- Débogage Chrome DevTools : Fournit l’inspection des sessions via DevTools, vous permettant de surveiller les journaux, les requêtes réseau et le comportement du navigateur pendant l’exécution du scraping.
- Ciblage géographique : Permet un ciblage précis au niveau du pays, de la ville ou de l’ASN pour accéder au contenu localisé, tester les expériences régionales et scraper avec précision les données géo-restreintes.
- Récupération automatique : Restaure les sessions pour maintenir la continuité, réduisant les temps d’arrêt et améliorant la robustesse dans les environnements instables ou bloqués.
- Compatibilité avec les agents IA (via Web MCP) : Prend en charge les agents de navigateur autonomes capables de naviguer, cliquer, faire défiler et extraire des données web, permettant des flux de travail d’automatisation avancés pilotés par l’IA.
- Validation de l’intégrité des données : Garantit que les données extraites sont cohérentes et fiables grâce à des mécanismes de validation intégrés, améliorant la qualité pour les analyses en aval et les pipelines de production.
Pour plus d’informations, explorez la documentation officielle.
Comment fonctionne l’API Browser
L’API Browser fonctionne en exécutant vos scripts d’automatisation de navigateur dans des navigateurs cloud entièrement gérés. Vous vous connectez via un seul point de terminaison CDP, et votre code est exécuté à distance dans de vrais environnements de navigateur. Vous interagissez avec le navigateur comme s’il était local, mais l’exécution, la mise à l’échelle et le déblocage sont entièrement gérés dans le cloud.
En coulisses, la plateforme gère toute la complexité de l’infrastructure. Elle gère automatiquement la rotation des proxies, les empreintes digitales du navigateur, la gestion des sessions, la Résolution de CAPTCHA, et bien plus encore. Chaque session s’exécute dans un environnement cloud évolutif qui peut allouer dynamiquement des ressources en fonction de la demande, permettant une haute concurrence sans configuration manuelle.
Démarrage
Tout d’abord, vous devez configurer une Zone d’API Browser dans votre compte Bright Data. Si vous ne l’avez pas encore fait, créez un compte Bright Data. Sinon, connectez-vous simplement.
Dans le panneau de contrôle Bright Data, sélectionnez l’option « Accès Web > Créer une API » :
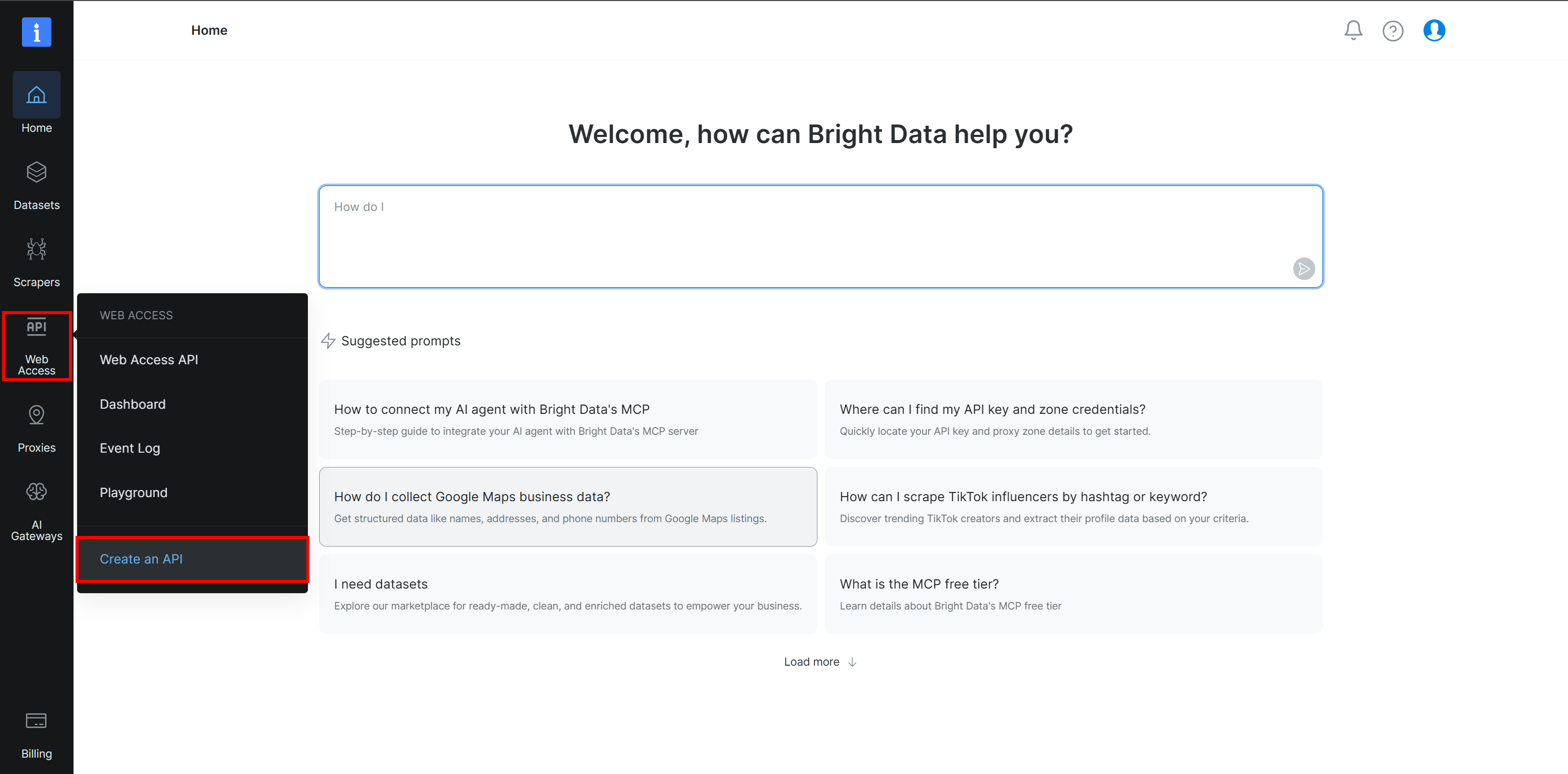 Créer une API »”/>
Créer une API »”/>Sur la page « API d’accès Web > Ajouter une API », sélectionnez le type « API Browser » :
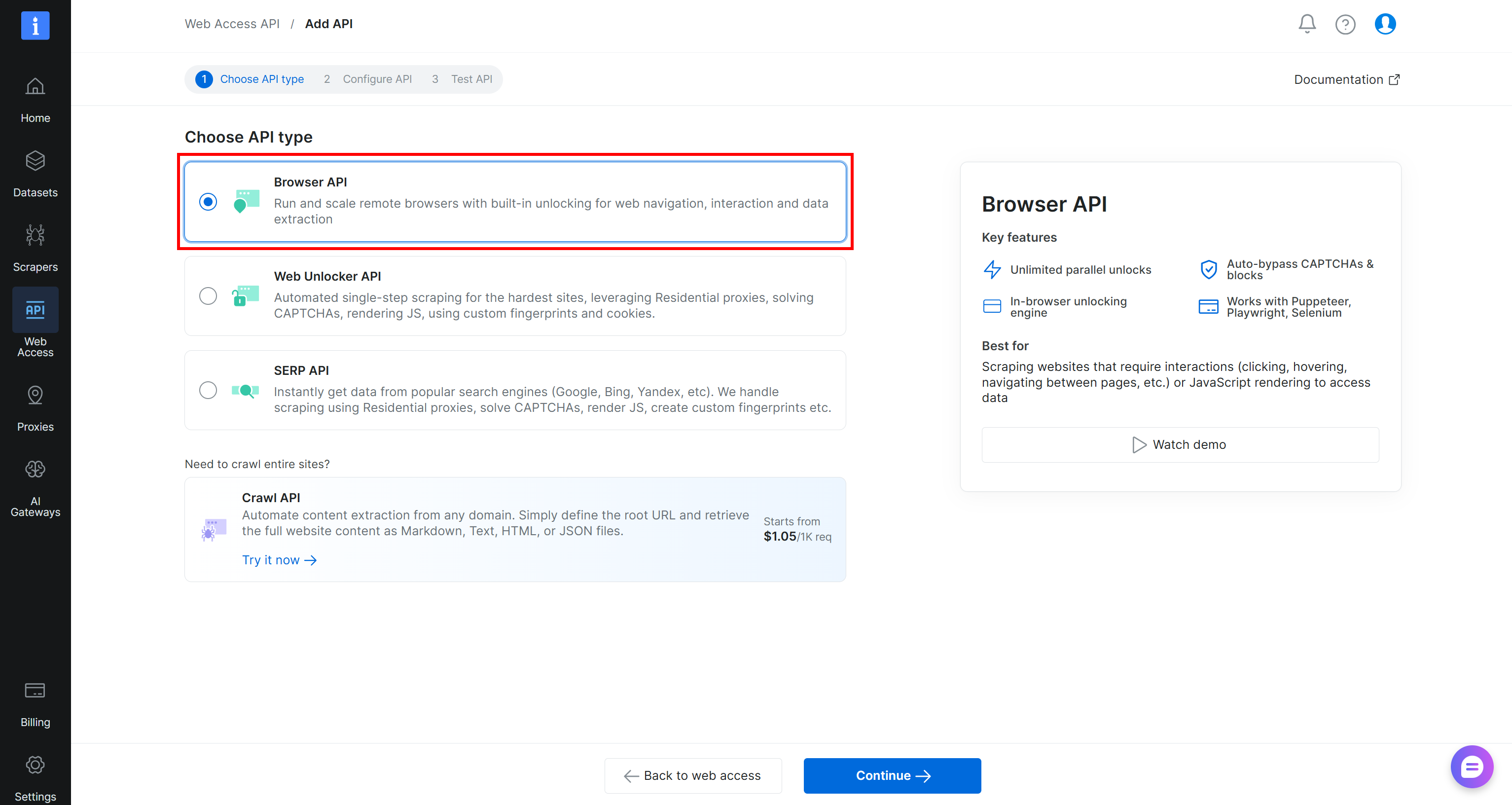
Suivez l’assistant, donnez un nom à votre Zone d’API Browser (par exemple, browser_api), et configurez-la selon vos besoins. Terminez le flux de configuration, et vous recevrez vos URL de connexion Puppeteer, Playwright et Selenium :
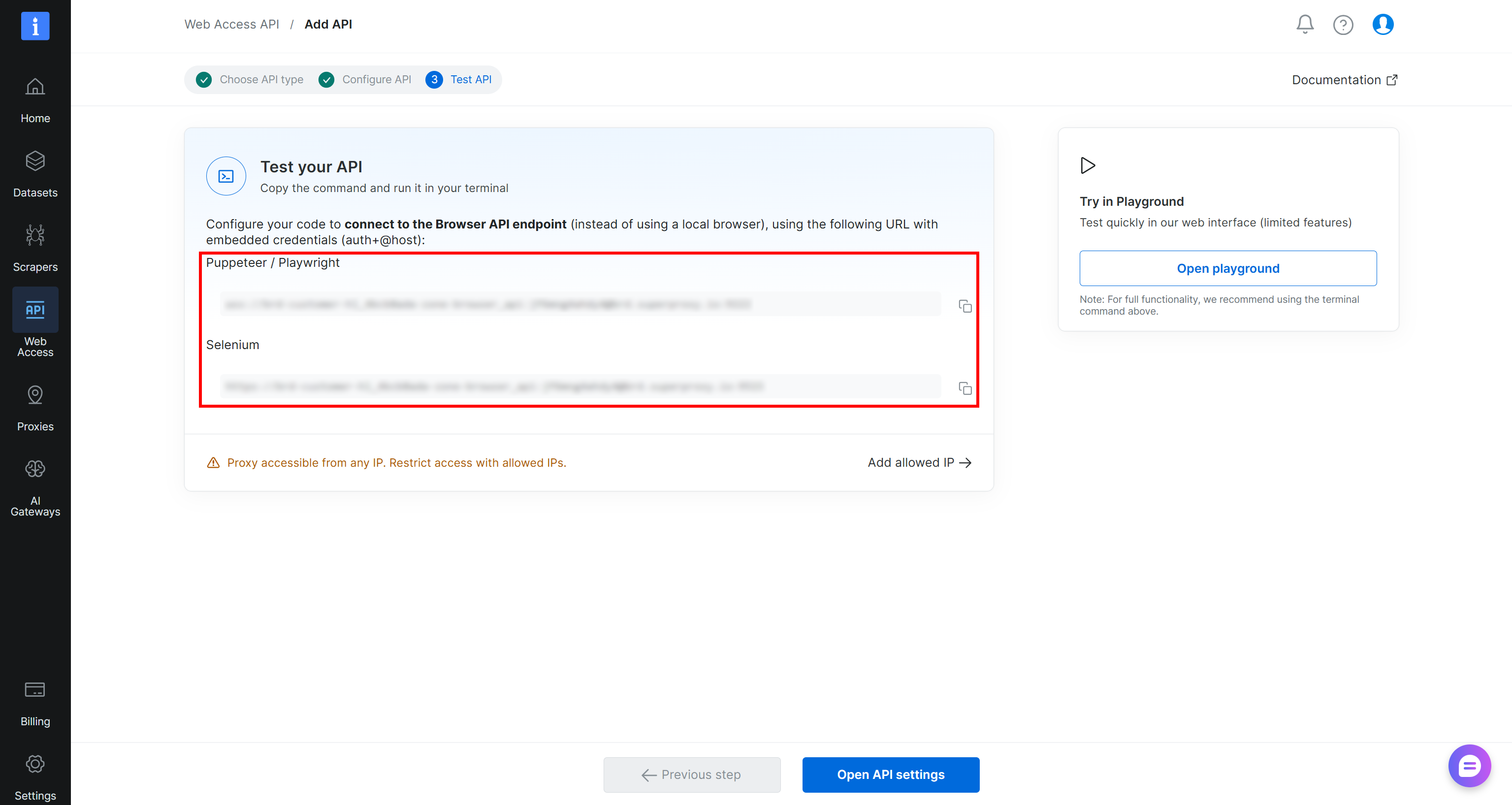
Ensuite, appuyez sur le bouton « Ouvrir les paramètres API » pour accéder au Playground de l’API Browser. Ici, vous pouvez accéder à des extraits prêts à l’emploi pour l’intégration avec les frameworks d’automatisation de navigateur et les langages de programmation populaires :
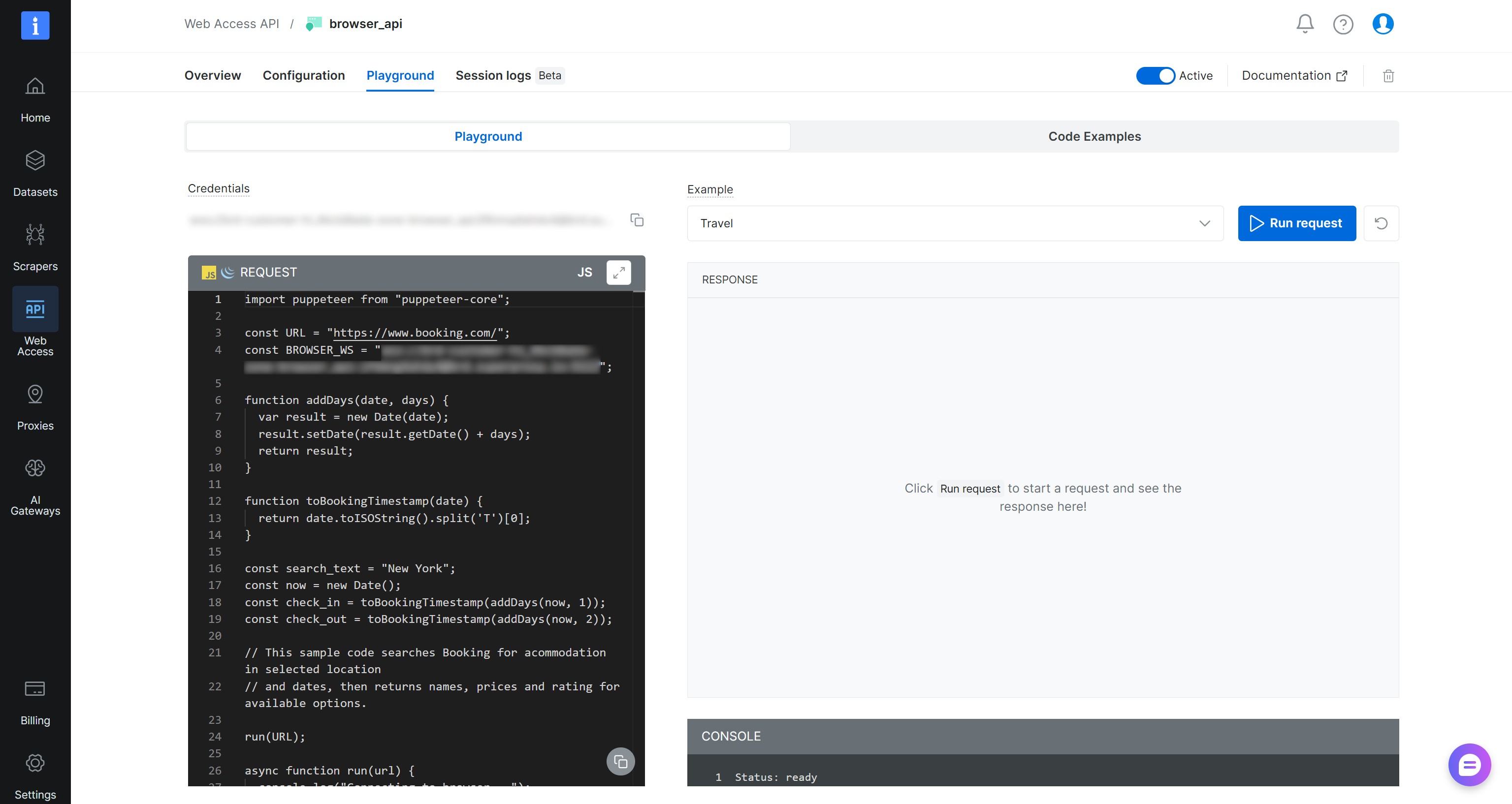
Utilisez l’URL de connexion distante pour vous connecter via CDP dans Playwright en Python comme ceci :
# pip install playwright
from playwright.sync_api import sync_playwright
# Remplacez par votre URL de connexion API Browser
BROWSER_API_CDP = "wss://brd-customer-USER-zone-BROWSER_API_ZONE_NAME:[email protected]:9222"
with sync_playwright() as p:
browser = p.chromium.connect_over_cdp(BROWSER_API_CDP)
page = browser.new_page()
page.goto("https://example.com")
print(page.title()) # Résultat attendu : "Example Domain"
browser.close()Ou de manière équivalente, en JavaScript :
// npm install playwright
const { chromium } = require("playwright");
# Remplacez par votre URL de connexion API Browser
const BROWSER_API_CDP = "wss://brd-customer-USER-zone-BROWSER_API_ZONE_NAME:[email protected]:9222";
(async () => {
const browser = await chromium.connectOverCDP(BROWSER_API_CDP);
const page = await browser.newPage();
await page.goto("https://example.com");
console.log(await page.title()); // Résultat attendu : "Example Domain"
await browser.close();
})();La logique d’automatisation reste identique à celle de Playwright ou Puppeteer standard. La seule modification est la façon dont vous vous connectez au navigateur. En utilisant connect_over_cdp()/connectOverCDP(), vous redirigez l’exécution vers des instances cloud d’API Browser entièrement gérées (au lieu de vous appuyer sur un navigateur local).
Tarification
L’API Browser repose sur un modèle de Paiement à l’utilisation basé sur le Trafic, où vous êtes facturé uniquement pour les Go de données transférées via l’infrastructure de navigateur cloud. En détail, la tarification de l’API Browser suit ces plans :
| Plan | Prix |
|---|---|
| Paiement à l’utilisation (sans engagement, facturation basée sur l’usage) | 8 $/Go |
| 71 Go inclus | 499 $/mois (7 $/Go) |
| 166 Go inclus | 999 $/mois (6 $/Go) |
| 399 Go inclus | 1 999 $/mois (5 $/Go) |
Il n’y a pas de frais pour les instances de navigateur, le temps d’exécution ou la concurrence. Tous les pays sont facturés au même tarif, rendant la tarification prévisible selon les géographies. La seule exception concerne les domaines premium, qui entraînent des coûts par Go plus élevés en raison d’une complexité de déblocage supplémentaire.
Remarque : Vous pouvez également tester l’API Browser, ainsi que tout autre produit Bright Data, gratuitement via un essai gratuit.
Étant donné que la tarification dépend directement du Trafic, l’optimisation de la Bande passante est importante pour l’efficacité des coûts et les performances. Lisez le guide officiel sur l’optimisation de la bande passante.
Différences d’approche pour la navigation furtive
CloakBrowser et l’API Browser visent tous deux à réduire la détection des bots. Pourtant, ils adoptent deux approches fondamentalement différentes pour la navigation furtive et la gestion des empreintes digitales.
CloakBrowser contourne les systèmes anti-bot via un binaire Chromium modifié s’exécutant localement. Il génère une empreinte digitale de navigateur cohérente au lancement, en usurpant des signaux détectables tels que le GPU, la taille de l’écran, les polices, le canvas, WebGL, l’audio et les spécifications matérielles.
Vous pouvez également contrôler la persistance de l’identité via des graines d’empreintes déterministes et affiner des attributs spécifiques via des indicateurs de lancement. Cela rend CloakBrowser particulièrement adapté lorsque vous avez besoin d’un contrôle précis des empreintes digitales et d’identités de navigateur reproductibles entre les sessions.
À l’inverse, l’API Browser offre la furtivité via des navigateurs cloud entièrement gérés. Plutôt que d’exposer des indicateurs d’empreintes digitales de bas niveau, elle gère les empreintes digitales du navigateur en coulisses. En même temps, elle expose des configurations et des actions CDP personnalisées pour contrôler les comportements avancés. Celles-ci vous permettent d’émuler des appareils spécifiques, de modifier la géolocalisation, de bloquer les publicités, de configurer la Résolution de CAPTCHA, et bien plus encore.
L’écart d’infrastructure
CloakBrowser vous fournit un binaire Chromium furtif local. Cependant, tout ce qui l’entoure reste de votre responsabilité. Cela signifie que si vous souhaitez exécuter l’automatisation à grande échelle, vous devez provisionner des machines, gérer la concurrence du navigateur, configurer et faire pivoter les proxies, surveiller les défaillances, et bien plus encore.
Certes, des images Docker exposant l’environnement CloakBrowser et des serveurs de navigateur pour la connexion via CDP vous sont fournies. Mais passer d’une image Docker à une véritable infrastructure de navigateur évolutive est un défi différent. Cela nécessite des compétences en ingénierie, une expertise en infrastructure et un budget que toutes les équipes n’ont pas.
L’API Browser de Bright Data adopte une approche très différente. Au lieu de vous donner un navigateur à gérer, elle fournit une infrastructure de navigateur entièrement gérée dans le cloud. La rotation des proxies, l’orchestration des navigateurs, la mise à l’échelle, la concurrence et la surveillance sont toutes gérées. Vous connectez simplement votre script d’automatisation de navigateur ou votre agent IA à un point de terminaison distant, et Bright Data gère toute la complexité opérationnelle pour vous.
En particulier, l’API Browser est soutenue par l’infrastructure de niveau entreprise de Bright Data avec SLA. Elle offre une disponibilité de 99,99 %, une concurrence illimitée, un taux de réussite de 99,95 %, une évolutivité illimitée et une conformité avec le RGPD, le CCPA et d’autres réglementations de confidentialité et de sécurité.
Cette distinction est le point clé de toute la comparaison CloakBrowser vs API Browser. CloakBrowser est sans aucun doute un excellent outil. Cependant, l’API Browser est la seule des deux qui peut vraiment être considérée comme une infrastructure d’automatisation de navigateur complète.
C’est aussi le plus grand avantage de l’API Browser par rapport à CloakBrowser. En réduisant la charge opérationnelle dès le premier jour, elle vous permet de vous concentrer sur la logique d’automatisation, ce qui est ce qui importe le plus.
Intégrations prises en charge
CloakBrowser prend en charge nativement les scripts Playwright et Puppeteer. Cependant, il nécessite une dépendance supplémentaire (cloakbrowser) tout en s’appuyant toujours sur les dépendances système standard de Playwright.
Au-delà des API natives, CloakBrowser expose un navigateur compatible CDP via une configuration de serveur basée sur Docker. De cette façon, il peut s’intégrer avec n’importe quel outil compatible CDP. Il prend également en charge nativement certains frameworks d’agents IA comme CrawAI, Browser Use et LangChain.
L’API Browser prend en charge Playwright, Puppeteer et Selenium, sans dépendances supplémentaires requises. De plus, elle est entièrement compatible avec tous les outils basés sur CDP, notamment Browser Use, Stagehand, Agent Browser et des frameworks d’automatisation similaires basés sur l’IA.
De plus, l’API Browser de Bright Data est exposée via les outils Web MCP. Ceux-ci incluent :
| Outil | Description |
|---|---|
scraping_browser_navigate |
Ouvrir ou réutiliser une session et naviguer vers une URL, réinitialisant le suivi réseau |
scraping_browser_go_back |
Naviguer en arrière et retourner l’URL et le titre mis à jour |
scraping_browser_go_forward |
Naviguer en avant et retourner l’URL et le titre mis à jour |
scraping_browser_snapshot |
Capturer un instantané ARIA avec des références d’éléments interactifs |
scraping_browser_click_ref |
Cliquer sur un élément en utilisant sa référence ARIA |
scraping_browser_screenshot |
Capturer une capture d’écran de la page ou de la page complète |
scraping_browser_wait_for_ref |
Attendre la visibilité d’un élément par référence ARIA |
scraping_browser_get_text |
Extraire le texte visible du corps de la page |
scraping_browser_get_html |
Récupérer le contenu HTML de la page |
scraping_browser_scroll |
Faire défiler jusqu’au bas de la page |
scraping_browser_scroll_to_ref |
Faire défiler jusqu’à un élément référencé spécifique |
La prise en charge MCP fait de l’API Browser un navigateur agentique, étendant la compatibilité à un vaste écosystème de frameworks d’agents IA. Les solutions prises en charge incluent LangChain, Agno, OpenClaw, LlamaIndex, CrewAI, Dify, Mastra, Claude Code, Codex, Claude Desktop et plus de 70 autres.
Bright Data Browser API vs CloakBrowser : Comparaison côte à côte
Comparez les deux solutions dans le tableau final CloakBrowser vs Bright Data Browser API ci-dessous :
| Aspect | CloakBrowser | Bright Data Browser API |
|---|---|---|
| Concept principal | Binaire Chromium furtif local | Infrastructure de navigateur cloud entièrement gérée |
| Nature | Wrapper open source + Binaires de navigateur corrigés propriétaires | Propriétaire |
| Dépendances | Nécessite cloakbrowser + dépendances système |
Aucune dépendance supplémentaire |
| Prise en charge CDP | ✔️ (via serveur Docker) | ✔️ (point de terminaison CDP cloud natif) |
| Approche furtive | Correctifs d’empreintes Chromium au niveau source | Empreintes digitales gérées |
| Contrôle des empreintes digitales | Contrôle élevé via graines et indicateurs de lancement | Contrôlé via des actions CDP pour l’émulation d’appareils |
| Gestion des proxies | Fournisseur de Proxy externe requis | Réseau de Proxy intégré de 400 M+ d’IP |
| Gestion des CAPTCHA | Non natif | Résolution de CAPTCHA intégrée |
| Prise en charge des frameworks | Playwright, Puppeteer, outils compatibles CDP | Playwright, Puppeteer, Selenium, outils compatibles CDP |
| Intégration d’agents IA | Prend en charge certains frameworks IA (Browser Use, LangChain, CrawAI) | Large écosystème via Web MCP (LangChain, LlamaIndex, CrewAI, Agno, Claude, et 70+ autres) |
| Responsabilité de l’infrastructure | Gérée par l’utilisateur | Entièrement gérée par Bright Data |
| Mise à l’échelle | Mise à l’échelle horizontale manuelle requise | Mise à l’échelle élastique automatique, avec concurrence illimitée |
| Garanties de disponibilité | Dépend de l’infrastructure utilisateur | Disponibilité de 99,99 % avec SLA |
| Modèle de coût | Logiciel gratuit, infrastructure à coût séparé | Tarification basée sur le Trafic au Go |
Verdict final
CloakBrowser et l’API Browser sont tous deux des solutions d’automatisation de navigateur puissantes et prêtes pour la furtivité. CloakBrowser, avec sa nature open source, est idéal lorsque vous avez besoin d’un contrôle local maximal sur les empreintes digitales du navigateur et d’une infrastructure entièrement autogérée. Il est particulièrement utile pour les configurations expérimentales ou hautement personnalisées.
Pour le scraping à l’échelle de production, l’automatisation fiable ou l’intégration avec des agents IA, l’API Browser de Bright Data devrait être le choix privilégié. Son infrastructure entièrement gérée, ses capacités de déblocage intégrées et sa mise à l’échelle élastique réduisent la charge opérationnelle. Cela la rend nettement plus pratique pour les équipes qui souhaitent se concentrer sur la logique d’automatisation plutôt que sur la gestion de l’infrastructure.
Conclusion
Dans cet article de comparaison Bright Data Browser API vs CloakBrowser, vous avez appris ce que sont les deux outils, les fonctionnalités qu’ils offrent et comment ils fonctionnent, ainsi que leur coût respectif.
CloakBrowser est une solution d’automatisation de navigateur open source excellente lorsque vous souhaitez un contrôle de bas niveau. En revanche, l’API Browser est mieux adaptée aux intégrations d’automatisation de navigateur plus fiables, de niveau entreprise ou agentique.
Explorez l’API Browser dès aujourd’hui et commencez à l’intégrer dans vos scripts d’automatisation.
Créez un compte Bright Data et explorez nos solutions d’automatisation de données web prêtes pour l’IA !




