
Dans ce tutoriel, vous apprendrez :
- Ce qu’est la bibliothèque Langchain MCP Adapters et ce qu’elle offre.
- Pourquoi l’utiliser pour fournir à un agent des capacités de recherche sur le Web, de récupération de données sur le Web et d’interaction avec le Web via le Bright Data Web MCP.
- Comment connecter les adaptateurs Langchain MCP au Web MCP dans un agent ReAct.
C’est parti !
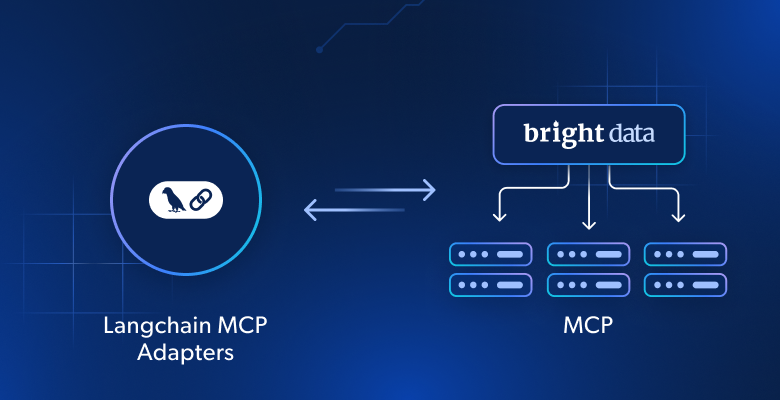
Qu’est-ce que la bibliothèque LangChain MCP Adapters ?
Langchain MCP Adapters est un package qui vous permet d’utiliser les outils MCP dans Langchain et LangGraph. Il est disponible via le package open source langchain-mcp-adapters, qui se charge de convertir les outils MCP en outils compatibles avec Langchain et LangGraph.
Grâce à cette conversion, vous pouvez utiliser les outils MCP à partir de serveurs locaux ou distants directement dans vos workflows Langchain ou vos agents LangGraph. Ces outils MCP peuvent être utilisés comme les centaines d’outils déjà publiés pour les agents LangGraph.
Plus précisément, le package comprend également une implémentation client MCP qui vous permet de vous connecter à plusieurs serveurs MCP et d’y charger des outils. Pour en savoir plus sur son utilisation, consultez la documentation officielle.
Pourquoi intégrer un agent LangGraph à Web MCP de Bright Data
Les agents IA créés avec LangGraph IA héritent des limites du LLM sous-jacent. Il s’agit notamment d’un manque d’accès aux informations en temps réel, ce qui peut parfois entraîner des réponses inexactes ou obsolètes.
Heureusement, cette limitation peut être surmontée en équipant l’agent de données web actualisées et de la capacité d’effectuer une exploration web en direct. C’est là que le Web MCP de Bright Data entre en jeu !
Disponible sous forme de package Node.js open source, Web MCP s’intègre à la suite d’outils de récupération de données prêts pour l’IA de Bright Data, permettant à votre agent d’accéder au contenu web, d’interroger des jeux de données structurés, d’effectuer des recherches sur le web et d’interagir avec des pages web à la volée.
Deux outils populaires proposés par Web MCP sont notamment :
| Outil | Description |
|---|---|
scrape_as_markdown |
Récupère le contenu d’une seule URL de page web à l’aide d’options d’extraction avancées, et renvoie les résultats au format Markdown. Peut contourner la détection des bots et les CAPTCHA. |
search_engine |
Extrait les résultats de recherche de Google, Bing ou Yandex, renvoyant les données SERP au format JSON ou Markdown. |
De plus, le Web MCP de Bright Data propose environ 60 outils spécialisés pour interagir avec des pages web (par exemple, scraping_browser_click) et collecter des données structurées à partir d’un large éventail de sites web, notamment Amazon, TikTok, Instagram, Yahoo Finance, LinkedIn, ZoomInfo, etc.
Par exemple, l’outil web_data_zoominfo_company_profile récupère des informations détaillées et structurées sur le profil d’une entreprise à partir de ZoomInfo en acceptant une URL d’entreprise valide comme entrée. Pour en savoir plus, consultez la documentation officielle du Web MCP !
Si vous recherchez plutôt des intégrations Bright Data directes via les outils Langchain, consultez ces guides :
- Comment configurer Bright Data avec Langchain
- Scraping web avec Langchain et Bright Data
- Utilisation de Langchain et Bright Data pour la recherche sur le Web
Comment connecter Web MCP dans un agent IA à l’aide des adaptateurs MCP Langchain
Dans cette section étape par étape, vous apprendrez comment intégrer Bright Data Web MCP dans un agent LagnGraph à l’aide de la bibliothèque d’adaptateurs MCP. Vous obtiendrez ainsi un agent IA ayant accès à plus de 60 outils pour la recherche sur le Web, l’accès aux données et l’interaction avec le Web.
Une fois configuré, l’agent IA sera utilisé pour récupérer les données de l’entreprise à partir de ZoomInfo et générer un rapport détaillé. Ce résultat peut vous aider à évaluer si une entreprise mérite d’être investie, sollicitée ou explorée plus en détail.
Suivez les étapes ci-dessous pour commencer !
Remarque: ce tutoriel se concentre sur Langchain en Python, mais il peut facilement être adapté au SDK JavaScript Langchain. De même, bien que l’agent s’appuie sur OpenAI, vous pouvez le remplacer par n’importe quel autre LLM pris en charge.
Prérequis
Pour suivre ce tutoriel, assurez-vous de disposer des éléments suivants :
- Python 3.8+ installé localement.
- Node.js installé localement (nous recommandons la dernière version LTS).
- Une clé API Bright Data.
- Une clé API OpenAI (ou une clé API de tout autre LLM pris en charge par Langchain).
Ne vous inquiétez pas pour la configuration de Bright Data pour l’instant, vous serez guidé à travers cette étape dans les prochaines étapes.
Il est également utile (mais facultatif) d’avoir certaines connaissances de base, telles que :
- Une compréhension générale du fonctionnement du MCP.
- Une certaine familiarité avec le Web MCP de Bright Data et les outils qu’il fournit.
Étape n° 1 : Configurez votre projet Langchain
Ouvrez un terminal et créez un nouveau répertoire pour votre agent IA alimenté par LangGraph MCP :
mkdir langchain-mcp-agentLe dossier langchain-mcp-agent/ contiendra le code Python de votre agent IA.
Ensuite, accédez au répertoire du projet et configurez un environnement virtuel:
cd langchain-mcp-agent
python -m venv .venvOuvrez maintenant le projet dans votre IDE Python préféré. Nous vous recommandons Visual Studio Code avec l’extension Python ou PyCharm Community Edition.
Dans le dossier du projet, créez un nouveau fichier nommé agent.py. Votre projet devrait maintenant ressembler à ceci :
langchain-mcp-agent/
├── .venv/
└── agent.pyIci, agent.py sera votre fichier Python principal. Initialisez-le pour l’exécution asynchrone du code avec :
import asyncio
async def main():
# Logique de définition de l'agent...
if __name__ == "__main__":
asyncio.run(main())Il est temps d’activer l’environnement virtuel. Sous Linux ou macOS, exécutez :
source .venv/bin/activateDe manière équivalente, sous Windows, lancez :
.venv/Scripts/activateUne fois l’environnement activé, installez les dépendances requises :
pip install langchain["openai"] langchain-mcp-adapters langgraphVoici ce que fait chaque paquet :
langchain["openai"]: bibliothèque principale LangChain avec intégration OpenAI.langchain-mcp-adapters: wrapper léger qui rend les outils MCP compatibles avec LangChain et LangGraphlanggraph: un framework d’orchestration de bas niveau pour créer, gérer et déployer des agents à état long, généralement au-dessus de LangChain.
Remarque: si vous ne prévoyez pas d’utiliser OpenAI pour l’intégration LLM, remplacez langchain["openai"] par le package équivalent pour votre fournisseur d’IA.
C’est fait ! Votre environnement de développement Python est prêt à prendre en charge un agent IA qui se connecte au Bright Data Web MCP.
Étape n° 2 : intégrer votre LLM
Avertissement: si vous utilisez un autre fournisseur LLM qu’OpenAI, adaptez cette section en conséquence.
Commencez par définir votre clé API OpenAI dans l’environnement :
import os
os.environ["OPENAI_API_KEY"] = "<VOTRE_CLÉ_API_OPENAI>"En production, utilisez une méthode plus sûre et plus fiable pour les variables d’environnement (par exemple, via python-dotenv) afin d’éviter de coder en dur des secrets directement dans votre script.
Ensuite, importez ChatOpenAI à partir du package langchain_openai:
from langchain_openai import ChatOpenAIChatOpenAI lira automatiquement votre clé API à partir de la variable d’environnement OPENAI_API_KEY.
Maintenant, dans la fonction main(), initialisez une instance ChatOpenAI avec le modèle souhaité :
llm = ChatOpenAI(
model="gpt-5-mini",
)Dans cet exemple, nous utilisons gpt-5-mini, mais vous pouvez le remplacer par n’importe quel autre modèle disponible. Cette instance LLM servira de moteur à votre agent IA. Super !
Étape n° 3 : Testez le Web MCP de Bright Data
Avant de connecter votre agent au MCP Web de Bright Data, vérifiez d’abord que votre machine peut réellement exécuter le serveur MCP.
Si vous ne l’avez pas encore fait, commencez par créer un compte Bright Data. Si vous en avez déjà un, connectez-vous simplement. Pour une configuration rapide, ouvrez la page « MCP » de votre compte et suivez les instructions :
Sinon, suivez les étapes ci-dessous pour une approche plus guidée.
Commencez par générer une clé API Bright Data et conservez-la en lieu sûr (vous en aurez besoin rapidement). Dans ce tutoriel, nous supposerons que la clé API dispose des autorisations d’administrateur, car cela simplifie considérablement le processus d’intégration.
Ouvrez votre terminal et installez le Web MCP globalement via le package @brightdata/mcp:
npm install -g @brightdata/mcpVérifiez que le serveur MCP local fonctionne avec cette commande Bash :
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpOu, de manière équivalente, sur Windows PowerShell, exécutez :
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpRemplacez l’espace réservé <YOUR_BRIGHT_DATA_API> par le jeton API Bright Data réel. Les deux commandes ci-dessus définissent la variable d’environnement API_TOKEN requise, puis lancent le serveur MCP localement.
En cas de succès, vous devriez voir des journaux similaires à ceux-ci :

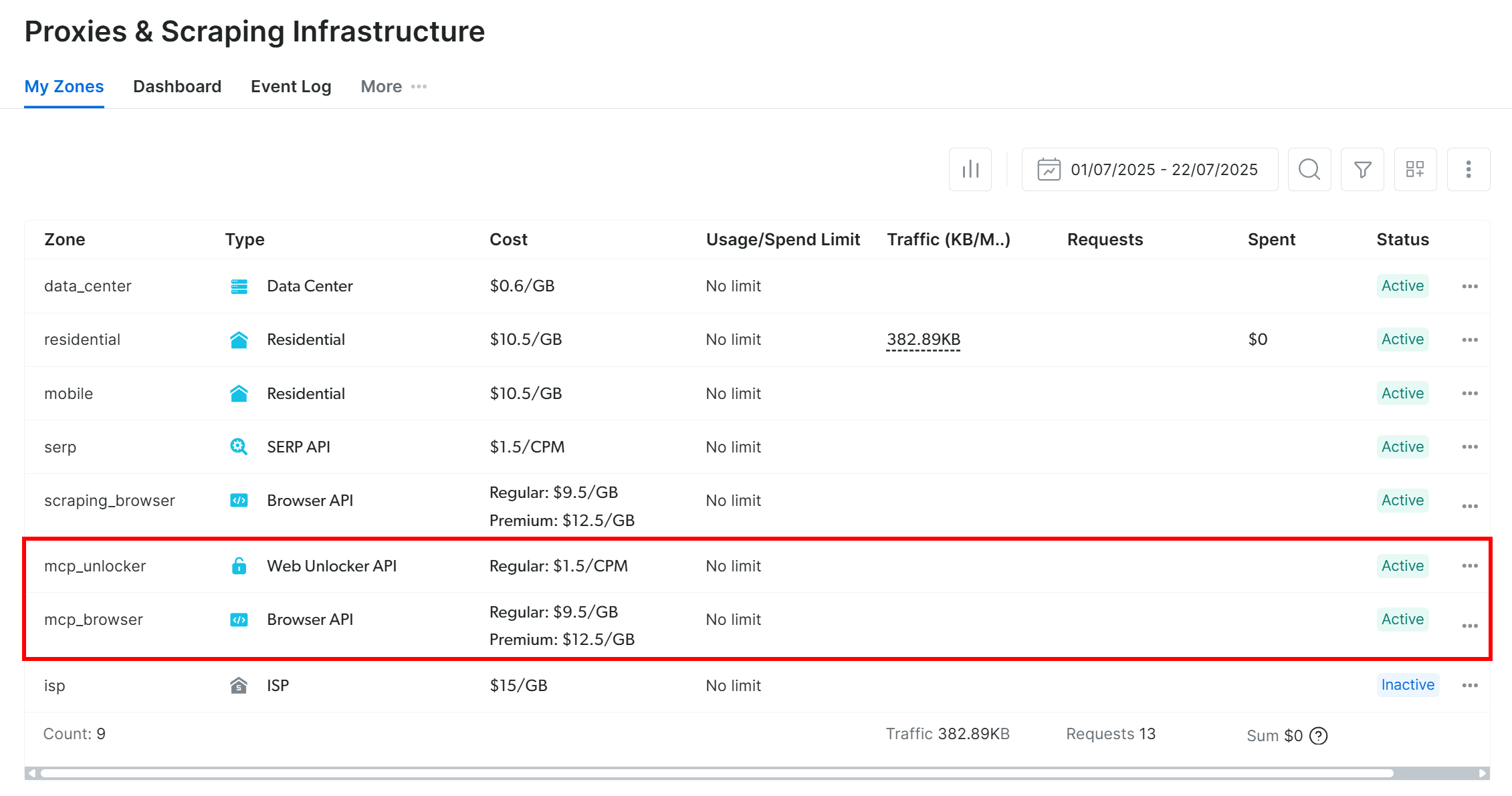
Lors du premier lancement, le package @brightdata/mcp configure automatiquement deux zones par défaut dans votre compte Bright Data :
mcp_unlocker: une zone pour Web Unlocker.mcp_browser: une zone pour Browser API.
Ces deux zones sont requises par le Web MCP pour exposer l’ensemble des 60+ outils.
Pour vérifier que les zones ci-dessus ont bien été créées, connectez-vous à votre tableau de bord Bright Data. Accédez à la page «Proxies & Scraping Infrastructure » (Proxys et infrastructure de scraping) et vous devriez voir les deux zones répertoriées dans le tableau :
Si votre jeton API ne dispose pas des autorisations d’administrateur, ces zones ne seront pas configurées pour vous. Dans ce cas, vous pouvez les créer manuellement dans le tableau de bord et spécifier leurs noms via des variables d’environnement, comme expliqué sur la page GitHub du package.
Remarque: par défaut, le serveur Web MCP n’expose que les outils search_engine et scrape_as_markdown (qui peuvent être utilisés gratuitement!). Pour débloquer les outils avancés d’automatisation du navigateur et d’extraction de données structurées, vous devez activer le mode Pro.
Pour activer le mode Pro, définissez la variable d’environnement PRO_MODE=true avant de lancer le serveur MCP :
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpOu, dans PowerShell :
$Env:API_TOKEN="<VOTRE_API_BRIGHT_DATA>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpImportant: si vous choisissez d’utiliser le mode Pro, vous aurez accès à plus de 60 outils. En revanche, le mode Pro n’est pas inclus dans l’offre gratuite et entraînera des frais supplémentaires.
Parfait ! Vous avez vérifié que votre machine peut exécuter le serveur Web MCP. Arrêtez le processus du serveur, car vous allez maintenant configurer Langchain pour le lancer automatiquement et vous y connecter.
Étape n° 4 : initialiser la connexion Web MCP via les adaptateurs Langchain MCP
Commencez par importer les bibliothèques requises à partir du package Langchain MCP Adapters :
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_toolsÉtant donné que votre machine peut exécuter un serveur Web MCP local, le moyen le plus simple de se connecter est via stdio (entrée/sortie standard) plutôt que via SSE ou Streamable HTTP. En termes plus simples, vous configurez votre application IA pour démarrer le serveur MCP en tant que sous-processus et communiquer directement avec lui à l’aide de l’entrée/sortie standard.
Pour ce faire, définissez l’objet de configuration StdioServerParameters comme suit :
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>",
"PRO_MODE": "true"
}
)Cette configuration reflète la commande que vous avez précédemment exécutée manuellement pour tester le Web MCP. Votre application utilisera cette configuration pour exécuter npx avec les variables d’environnement requises (n’oubliez pas que PRO_MODE est facultatif) et lancer le Web MCP en tant que sous-processus.
Ensuite, initialisez la session MCP et chargez les outils exposés :
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
await session.initialize()
tools = await load_mcp_tools(session)La fonction load_mcp_tools() effectue le gros du travail : elle convertit automatiquement les outils MCP en outils compatibles avec Langchain et LangGraph.
Fantastique ! Vous disposez désormais d’une liste d’outils prêts à être intégrés dans la définition de votre agent LangGraph.
Étape n° 5 : créer et interroger un agent ReAct
À l’intérieur du bloc with interne, utilisez le moteur LLM ainsi que la liste des outils MCP pour créer votre agent LangGraph avec create_react_agent():
agent = create_react_agent(llm, tools) Remarque: lorsque vous travaillez avec des outils, il est préférable de s’appuyer sur des agents IA qui suivent l’architecture ReAct. En effet, cette approche leur permet de raisonner de manière plus approfondie sur le processus et de choisir les outils adaptés pour accomplir la tâche.
Importez create_react_agent() depuis LangGraph :
from langgraph.prebuilt import create_react_agentInterrogez ensuite l’agent IA. Au lieu d’attendre la réponse complète et de l’imprimer en une seule fois, il est préférable de diffuser le résultat directement sur la console. L’utilisation des outils peut prendre du temps, le streaming fournit donc des informations utiles pendant que l’agent traite la tâche :
input_prompt = """
Récupérez les données de la page de l'entreprise ZoomInfo : « https://www.zoominfo.com/c/nike-inc/27722128 ». Ensuite, à l'aide des données récupérées, produisez un rapport concis au format Markdown résumant les principales informations sur l'entreprise.
"""
# Diffuser la réponse de l'agent
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
step["messages"][-1].pretty_print()Dans cet exemple, l’agent est invité à :
« Récupérer les données de la page de l’entreprise ZoomInfo : «https://www.zoominfo.com/c/nike-inc/27722128 ». Ensuite, à partir des données récupérées, produire un rapport concis au format Markdown résumant les principales informations sur l’entreprise. »
Remarque: l’URL de la page de l’entreprise ZoomInfo fait référence à Nike, mais vous pouvez la remplacer par n’importe quelle autre entreprise ou modifier entièrement l’invite pour un scénario de récupération de données différent.
Cela reflète exactement ce qui a été décrit dans l’introduction de ce chapitre. Il est important de noter qu’une telle tâche oblige l’agent à utiliser les outils Web MCP pour récupérer et structurer des données réelles. Cela en fait donc une démonstration parfaite de l’intégration !
Super ! Votre agent Web MCP + Langchain LangGraph IA est prêt. Il ne reste plus qu’à le voir en action.
Étape n° 6 : tout assembler
Le code final dans agent.py devrait être :
import asyncio
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Remplacez par votre clé API OpenAI
from langchain_openai import ChatOpenAI
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
async def main():
# Initialiser le moteur LLM
llm = ChatOpenAI(
model="gpt-5-mini",
)
# Configuration pour se connecter à une instance locale du serveur Bright Data Web MCP
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>", # Remplacez par votre clé API Bright Data
"PRO_MODE": "true"
}
)
# Se connecter au serveur MCP
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# Initialiser la session client MCP
await session.initialize()
# Obtenir les outils MCP
tools = await load_mcp_tools(session)
# Créer l'agent ReAct
agent = create_react_agent(llm, tools)
# Description de la tâche de l'agent
input_prompt = """
Récupérez les données de la page de l'entreprise ZoomInfo : « https://www.zoominfo.com/c/nike-inc/27722128 ». Ensuite, à l'aide des données récupérées, produisez un rapport concis au format Markdown résumant les principales informations sur l'entreprise.
"""
# Diffuser la réponse de l'agent
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
step["messages"][-1].pretty_print()
if __name__ == "__main__":
asyncio.run(main())Waouh ! En seulement ~50 lignes de code, vous venez de créer un agent ReAct avec intégration MCP, grâce aux adaptateurs MCP Langchain.
Lancez votre agent avec :
python agent.pyDans le terminal, vous devriez immédiatement voir :

Cela prouve que l’agent LangGraph reçoit votre invite comme prévu. Ensuite, le moteur LLM le traite et détermine immédiatement que web_data_zoominfo_company_profile est l’outil MCP approprié du Web MCP à appeler pour accomplir la tâche. Plus précisément, il appelle l’outil avec le bon argument URL ZoomInfo déduit de l’invite (https://www.zoominfo.com/c/nike-inc/27722128).
Le résultat de l’appel de l’outil sera le suivant :

L’outil web_data_zoominfo_company_profile renvoie les données du profil d’entreprise ZoomInfo au format JSON. Notez qu’il ne s’agit pas d’un contenu imaginaire ou inventé par le mini-modèle GPT-5 !
Au contraire, les données proviennent directement du Scraper ZoomInfo disponible dans l’infrastructure Bright Data, qui est appelé en arrière-plan par l’outil Web MCP web_data_zoominfo_company_profile sélectionné.
ZoomInfo Scraper contourne toutes les protections anti-bot, collecte les données de la page de profil public de l’entreprise à la volée et les renvoie dans un format JSON structuré. Comme vous pouvez le vérifier sur la page ZoomInfo réelle, les données récupérées sont exactes et proviennent directement de la page cible :
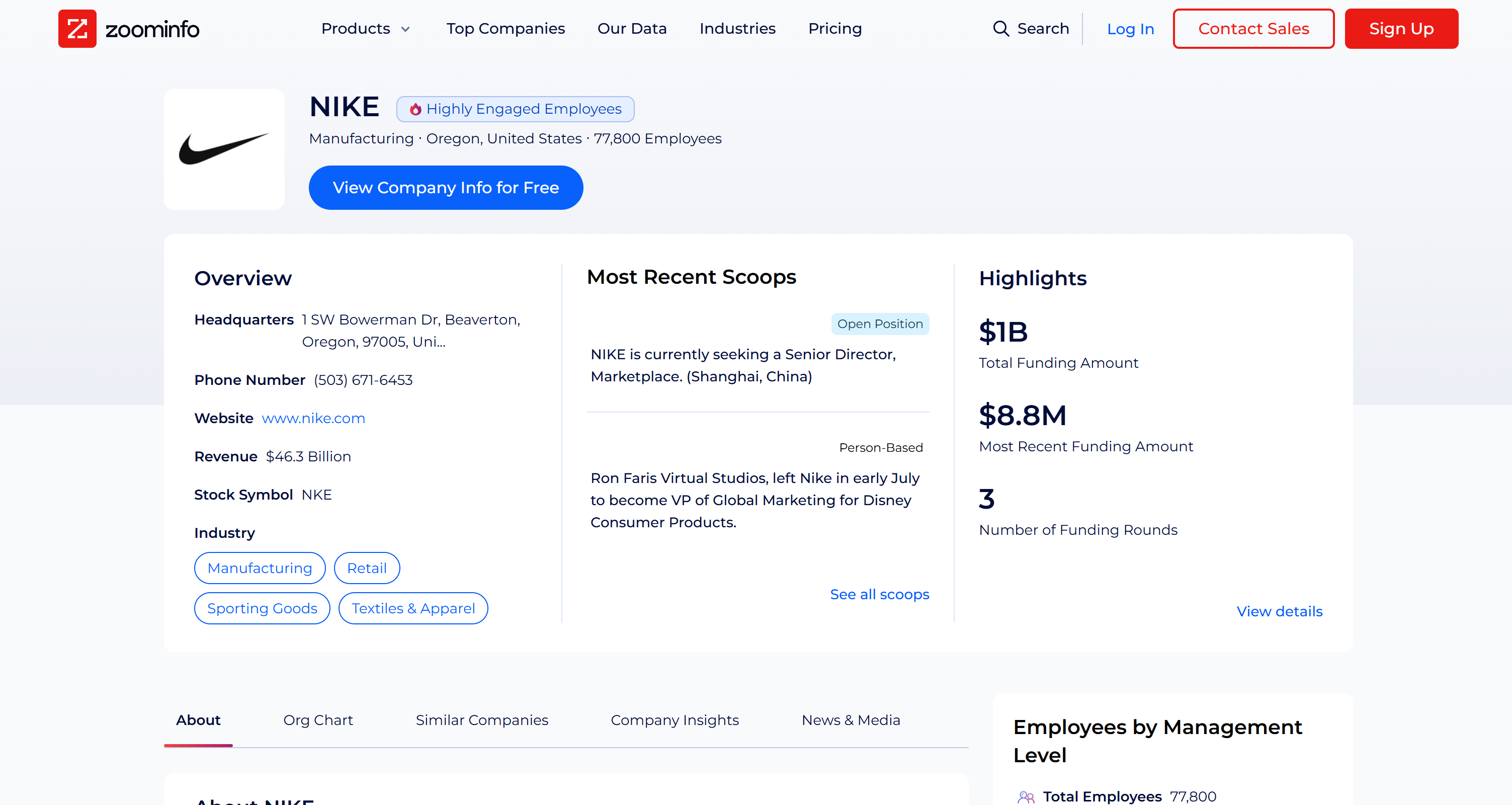
Gardez à l’esprit que le scraping de ZoomInfo n’est pas une tâche facile en raison de leurs techniques anti-scraping, notamment un CAPTCHA difficile. Il ne s’agit donc pas d’une tâche que n’importe quel LLM peut accomplir. Au contraire, elle ne peut être réalisée que par un agent ayant accès à des outils dédiés à la récupération de données web.
Cet exemple simple démontre la puissance de l’intégration Langchain + Bright Data Web MCP !
Compte tenu des données du profil de l’entreprise ZoomInfo, le rapport Markdown produit par l’agent ressemblera à ceci :
# NIKE, Inc. — Aperçu de l'entreprise
## Présentation
NIKE, Inc. conçoit, développe, commercialise et vend des chaussures, des vêtements, des équipements et des accessoires de sport dans le monde entier.
## Faits marquants
- **Nom :** NIKE, Inc.
- **Site web :** [https://www.nike.com/](https://www.nike.com/)
- **Siège social :** 1 SW Bowerman Dr, Beaverton, OR 97005, États-Unis
- **Téléphone :** (503) 671-6453
- **Symbole boursier :** NYSE : NKE
- **Chiffre d'affaires :** 46,3 milliards de dollars (déclaré)
- **Effectifs :** 77 800
- **Secteurs d'activité :** Fabrication ; Commerce de détail ; Articles de sport ; Textiles et vêtements ; Vente au détail de vêtements et accessoires
- **Horodatage ZoomInfo :** 2026-09-02T08:47:19.789Z
## Finances / Financement
- **Chiffre d'affaires déclaré :** 46,3 milliards de dollars
- **Financement (ZoomInfo) :** financement total de 1,0 milliard de dollars en 3 tours *(les chiffres peuvent refléter des données historiques ou non publiques ; Nike est une société cotée en bourse)*
## Effectifs et culture
- **Effectif total :** 77 800
- **Répartition des employés (ZoomInfo) :**
- Cadres supérieurs : 23
- Vice-présidents : ~529
- Directeurs : ~6 115
- Responsables : ~13 289
- Non-cadres : ~29 578
- **Score eNPS :** 20 *(Promoteurs 50 % / Passifs 20 % / Détracteurs 30 %)*
## Direction (sélectionnée / issue de l'organigramme)
- Amy Montagne — Présidente, Nike
- Nicole Graham — Vice-présidente exécutive et directrice du marketing
- Cheryan Jacob — Directrice des systèmes d'information
- Muge Dogan — Vice-présidente exécutive et directrice de la technologie
- Chris George — Vice-président et directeur financier (Geo...)
- Sarah Mensah — Présidente, Jordan Brand
> *Remarque : le profil ZoomInfo ne mentionnait aucun PDG dans les données saisies.*
## Technologie et outils (exemples)
- SolidWorks (Dassault Systèmes)
- EventPro (Profit Systems)
- Microsoft IIS (Microsoft)
- SAP Sybase RAP (SAP)
## Scoops récents / Faits marquants dans les médias (résumé)
- **Recrutement :** Directeur principal, Marché (Shanghai).
- **Changement de personnel :** Ron Faris Virtual Studios a quitté Nike pour rejoindre Disney Consumer Products (vice-président, marketing mondial).
- **Notes commerciales :** les difficultés liées aux droits de douane et à la géopolitique ont eu un impact sur les résultats à court terme ; l'entreprise met en œuvre des mesures d'atténuation et des mesures « gagnantes immédiates ».
- **Licenciements :** rapports faisant état d'un petit nombre de licenciements dans l'entreprise (environ 1 % des employés).
## Entreprises comparables (exemples)
- ANTA Sports Products
- adidas AG
- Foot Locker
- Guess
- Timberland
- Genesco
## Contacts et communication
- **Site web de l'entreprise :** [https://www.nike.com/](https://www.nike.com/)
- **Formats d'e-mail types (observés) :** `[email protected]` (également `@converse.com` pour les marques associées)
## Source des données
- Profil de l'entreprise NIKE, Inc. sur ZoomInfo
[https://www.zoominfo.com/c/nike-inc/27722128](https://www.zoominfo.com/c/nike-inc/27722128)
**Horodatage de l'instantané :** 2026-09-02T08:47:19.789ZVisualisez-le dans un visualiseur Markdown et vous verrez :
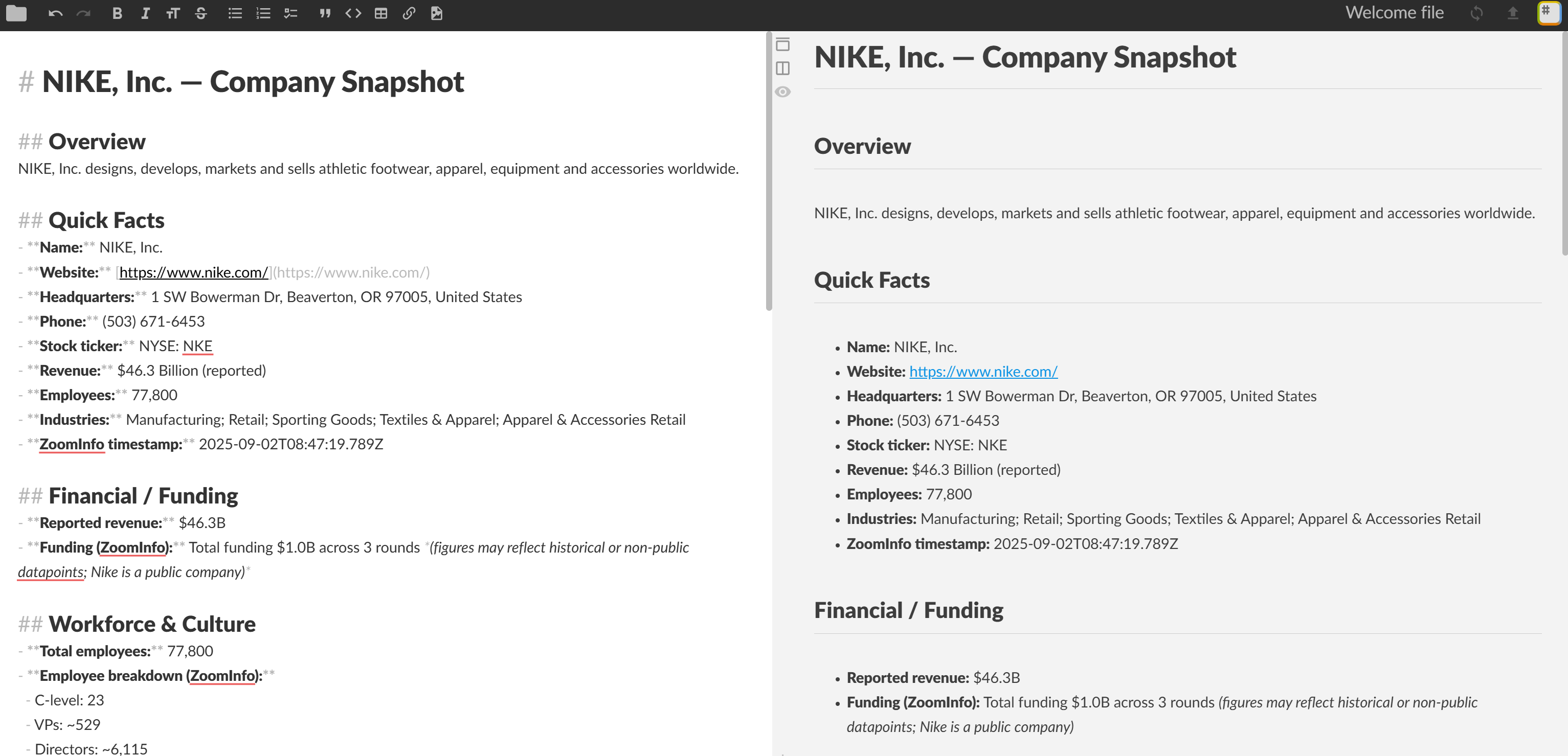
Et voilà ! Votre agent ReAct a sélectionné l’outil adapté à la tâche et l’a utilisé pour produire un rapport Markdown riche en informations, avec des données réelles sur l’entreprise extraites de ZoomInfo.
Tout cela n’aurait pas été possible sans l’intégration Web MCP, qui est désormais prise en charge dans Langchain grâce à la bibliothèque MCP Adapters.
Prochaines étapes
L’agent Langchain alimenté par MCP développé ici est un exemple simple, mais fonctionnel. Pour le rendre prêt à la production, envisagez les étapes suivantes :
- Implémentez un REPL: ajoutez un REPL (Read-Eval-Print Loop) afin de pouvoir interagir avec votre agent en temps réel. Pour conserver le contexte et suivre les interactions précédentes, introduisez une couche mémoire, idéalement stockée dans une base de données temporaire ou un stockage persistant.
- Exportez la sortie vers un fichier: modifiez la logique de sortie pour permettre l’enregistrement des sorties produites (par exemple, des rapports) dans un fichier local. Cela facilite le partage des résultats avec les autres membres de l’équipe.
- Déployez votre agent: déployez l’agent IA dans le cloud, dans un environnement cloud hybride ou via des options auto-hébergées, comme expliqué dans la documentation Langchain.
Essayez votre agent Langchain + Web MCP avec différentes invites et explorez d’autres workflows avancés basés sur des agents!
Conclusion
Dans cet article, vous avez appris à tirer parti du Web MCP de Bright Data (désormais disponible avec un niveau gratuit !) pour créer un agent IA dans LangGraph. Cela est rendu possible grâce à la bibliothèque Langchain MCP Adapters, qui ajoute la prise en charge MCP aux écosystèmes Langchain et LangGraph.
La tâche présentée dans cet article n’était qu’un exemple, mais vous pouvez utiliser la même intégration pour concevoir des workflows beaucoup plus complexes, y compris des configurations multi-agents. Grâce aux plus de 60 outils proposés par Web MCP et à la gamme complète de solutions de l’infrastructure IA de Bright Data, vous pouvez donner à vos agents IA les moyens de récupérer, valider et transformer efficacement les données web en temps réel.
Créez gratuitement un compte Bright Data et commencez dès aujourd’hui à tester nos solutions de données web prêtes pour l’IA !




