Le scraping web est à un tournant, car les méthodes traditionnelles sont contrecarrées par des défenses anti-bots sophistiquées et les développeurs ne cessent de patcher des scripts fragiles. Bien qu’ils fonctionnent encore, leurs limites sont évidentes, surtout à côté des infrastructures de scraping modernes, natives de l’IA, qui offrent résilience et évolutivité. Le marché des agents d’IA devant passer de 7,84 milliards de dollars à 52,62 milliards de dollars d’ici 2030, l’avenir de l’accès aux données réside dans des systèmes intelligents et autonomes.
En combinant le cadre d’agent autonome de CrewAI avec l’infrastructure robuste de Bright Data, vous obtenez une pile de scraping qui raisonne et surmonte les barrières anti-bots. Dans ce tutoriel, vous construirez un agent de scraping alimenté par l’IA qui fournit des données fiables en temps réel.
Les limites du “scraping” à l’ancienne
Le scraping traditionnel est fragile – il s’appuie sur des sélecteurs CSS ou XPath statiques qui s’effacent à chaque modification du front-end. Les principaux défis sont les suivants :
- Défenses anti-bots. Les CAPTCHA, l’étranglement des adresses IP et la prise d’empreintes digitales bloquent les robots simples.
- Pages à forte teneur en JavaScript. React, Angular et Vue construisent le DOM dans le navigateur, de sorte que les appels HTTP bruts passent à côté de la plupart des contenus.
- HTML non structuré. Le HTML incohérent et les données en ligne dispersées exigent une analyse et un post-traitement lourds avant d’être utilisés.
- Goulets d’étranglement de la mise à l’échelle. L’orchestration des proxies, des nouvelles tentatives et des correctifs continus devient un fardeau opérationnel épuisant et interminable.
Comment CrewAI + Bright Data rationalisent le scraping
La construction d’un racleur autonome repose sur deux piliers : un “cerveau” adaptatif et un “corps” résistant.
- CrewAI (le cerveau). Un moteur d’exécution multi-agents open-source qui permet de créer une “équipe” d’agents capables de planifier, de raisonner et de coordonner des tâches de scraping de bout en bout.
- Bright Data MCP (Le corps). Une passerelle de données en direct qui achemine chaque demande via la pile Unlocker de Bright Data – rotation des IP, résolution des CAPTCHA et exécution des navigateurs sans tête – afin que les LLM reçoivent du HTML ou du JSON propre en une seule fois. La mise en œuvre de Bright Data est la principale source de données fiables pour les agents d’intelligence artificielle.
Cette combinaison cerveau-corps permet à vos agents de réfléchir, de récupérer et de s’adapter à pratiquement n’importe quel site.
Qu’est-ce que CrewAI ?
CrewAI est un cadre open-source pour l’orchestration d’agents d’IA coopératifs. Vous définissez le rôle, l’objectif et les outils de chaque agent, puis vous les regroupez au sein d’un équipage pour exécuter des flux de travail à plusieurs étapes.
Composantes essentielles :
- Agent. Un travailleur piloté par LLM avec un rôle, un objectif et une histoire facultative, donnant au modèle le contexte du domaine.
- Tâche. Une tâche unique et bien définie pour un agent, plus un résultat attendu qui sert de barrière de qualité.
- Outil. Tout élément que l’agent peut invoquer – une extraction HTTP, une requête de base de données ou le point de terminaison MCP de Bright Data pour le scraping.
- Équipage. L’ensemble des agents et de leurs tâches qui travaillent à la réalisation d’un objectif.
- Processus. Le plan d’exécution – séquentiel, parallèle ou hiérarchique – qui contrôle l’ordre des tâches, la délégation et les tentatives.
C’est le reflet d’une véritable équipe : les spécialistes s’occupent de leur tranche, transmettent les résultats et font remonter l’information si nécessaire.
Qu’est-ce que le protocole de contexte de modèle (PCM) ?
MCP est une norme JSON-RPC 2.0 ouverte qui permet aux agents d’IA d’appeler des outils et des sources de données externes par le biais d’une interface unique et structurée. Voyez-le comme un port USB-C pour les modèles – une seule prise, de nombreux appareils.
Le serveur MCP de Bright Data met cette norme en pratique en connectant un agent directement à la pile de scraping de Bright Data, ce qui rend le scraping Web avec MCP non seulement plus puissant, mais aussi beaucoup plus simple que les piles traditionnelles :
- Contournement de l’anti-bot. Les demandes passent par Web Unlocker et un pool de plus de 150 millions d’adresses IP résidentielles tournantes couvrant 195 pays.
- Prise en charge des sites dynamiques. Un navigateur de scraping spécialement conçu rend le JavaScript, de sorte que les agents voient le DOM entièrement chargé.
- Résultats structurés. De nombreux outils renvoient des données JSON propres, ce qui permet de se passer d’analyseurs personnalisés.
Le serveur publie plus de 50 outils prêts à l’emploi – de la récupération d’URL génériques aux scrapers spécifiques à un site – afin que votre agent CrewAI puisse obtenir des prix de produits, des données SERP ou des instantanés DOM en un seul appel.
Construire votre premier agent d’extraction d’IA
Construisons un agent CrewAI qui extrait les détails d’une page de produit Amazon et les renvoie sous forme de JSON structuré. Vous pouvez facilement rediriger la même pile vers un autre site en modifiant quelques lignes.
Conditions préalables
- Python 3.11 – Recommandé pour la stabilité.
- Node.js + npm – Nécessaire pour exécuter le serveur MCP de Bright Data ; à télécharger sur le site officiel.
- Environnement virtuel Python – Permet d’isoler les dépendances ; voir la documentation de
venv. - Compte Bright Data – S’inscrire et créer un jeton API (des crédits d’essai gratuits sont disponibles).
- Clé API Google Gemini – Créez une clé dans Google AI Studio (cliquez sur + Créer une clé API). La version gratuite autorise 15 requêtes par minute et 500 requêtes par jour. Aucun profil de facturation n’est requis.
Aperçu de l’architecture
Environment Setup → LLM Config → MCP Server Init →
Agent Definition → Task Definition → Crew Execution → JSON OutputÉtape 1. Configuration de l’environnement et importations
mkdir crewai-bd-scraper && cd crewai-bd-scraper
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venvScriptsactivate
pip install "crewai-tools[mcp]" crewai mcp python-dotenv
from crewai import Agent, Task, Crew, Process
from crewai_tools import MCPServerAdapter
from mcp import StdioServerParameters
from crewai.llm import LLM
import os
from dotenv import load_dotenv
load_dotenv() # Load credentials from .envÉtape 2. Configurer les clés et les zones de l’API
Créez un fichier .env à la racine de votre projet :
BRIGHT_DATA_API_TOKEN="…"
WEB_UNLOCKER_ZONE="…"
BROWSER_ZONE="…"
GEMINI_API_KEY="…"Vous avez besoin de :
- Jeton API. Générer un nouveau jeton API.
- Zone de déverrouillage du Web. Créez une nouvelle zone de déverrouillage Web. En cas d’omission, une zone par défaut appelée
mcp_unlockerest créée pour vous. - Zone API navigateur. Créer une nouvelle zone API navigateur. Nécessaire uniquement pour les cibles à forte composante JavaScript. Copiez la chaîne du nom d’utilisateur affichée dans l’onglet Vue d’ensemble de la zone.
- Clé API Google Gemini. Déjà créée dans les conditions préalables.
Etape 3. Configuration du LLM (Gemini)
Configurer le LLM (Gemini 1.5 Flash) pour une sortie déterministe :
llm = LLM(
model="gemini/gemini-1.5-flash",
api_key=os.getenv("GEMINI_API_KEY"),
temperature=0.1,
)Étape 4. Configuration du MCP de Bright Data
Configurez le serveur MCP de Bright Data. Cela indique à CrewAI comment lancer le serveur et transmettre les informations d’identification :
server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": os.getenv("WEB_UNLOCKER_ZONE"),
"BROWSER_ZONE": os.getenv("BROWSER_ZONE"),
},
)Cela lance *npx @brightdata/mcp* en tant que sous-processus et expose plus de 50 outils (≈ 57 au moment de la rédaction) via le standard MCP.
Étape 5. Définition des agents et des tâches
Ici, nous définissons le personnage de l’agent et le travail spécifique qu’il doit accomplir. Les implémentations efficaces de CrewAI suivent la règle 80/20 : 80% des efforts sont consacrés à la conception de la tâche, 20% à la définition de l’agent.
def build_scraper_agent(mcp_tools):
return Agent(
role="Senior E-commerce Data Extractor",
goal=(
"Return a JSON object with snake_case keys containing: title, current_price, "
"original_price, discount, rating, review_count, last_month_bought, "
"availability, product_id, image_url, brand, and key_features for the "
"target product page. Ensure strict schema validation."
),
backstory=(
"Veteran web-scraping engineer with years of experience reverse-"
"engineering Amazon, Walmart, and Shopify layouts. Skilled in "
"Bright Data MCP, proxy rotation, CAPTCHA avoidance, and strict "
"JSON-schema validation."
),
tools=mcp_tools,
llm=llm,
max_iter=3,
verbose=True,
)
def build_scraping_task(agent):
return Task(
description=(
"Extract product data from https://www.amazon.in/dp/B071Z8M4KX "
"and return it as structured JSON."
),
expected_output="""{
"title": "Product name",
"current_price": "$99.99",
"original_price": "$199.99",
"discount": "50%",
"last_month_bought": 150,
"rating": 4.5,
"review_count": 1000,
"availability": "In Stock",
"product_id": "ABC123",
"image_url": "https://example.in/image.jpg",
"brand": "BrandName",
"key_features": ["Feature 1", "Feature 2"],
}""",
agent=agent,
)Voici ce que fait chaque paramètre :
- role – Titre court du poste, que CrewAI injecte dans chaque invite du système.
- goal – objectif de l’étoile du nord ; CrewAI le compare après chaque boucle pour décider s’il faut s’arrêter.
- backstory – Contexte du domaine qui oriente le ton et réduit les hallucinations.
- tools – Liste des objets
BaseTool(par exemple, MCPsearch_engine,scrape_as_markdown). - llm – Modèle utilisé par CrewAI pour chaque cycle réflexion → planification → action → réponse.
- max_iter – Limite maximale des boucles internes de l’agent (20 par défaut dans la version 0.30 +).
- verbeux – envoie chaque invite, pensée et appel d’outil vers stdout (utile pour le débogage).
- description – Une instruction orientée vers l’action est injectée à chaque tour.
- expected_output – Contrat formel d’une réponse valide (utiliser JSON strict, pas de virgule de fin).
- agent – Lie cette tâche à une instance d’
agentspécifique pourCrew.kickoff().
Étape 6. Constitution et exécution de l’équipage
Cette partie rassemble l’agent et la tâche dans un Crew et exécute le flux de travail.
def scrape_product_data():
"""Assembles and runs the scraping crew."""
with MCPServerAdapter(server_params) as mcp_tools:
scraper_agent = build_scraper_agent(mcp_tools)
scraping_task = build_scraping_task(scraper_agent)
crew = Crew(
agents=[scraper_agent],
tasks=[scraping_task],
process=Process.sequential,
verbose=True
)
return crew.kickoff()
if __name__ == "__main__":
try:
result = scrape_product_data()
print("n[SUCCESS] Scraping completed!")
print("Extracted product data:")
print(result)
except Exception as e:
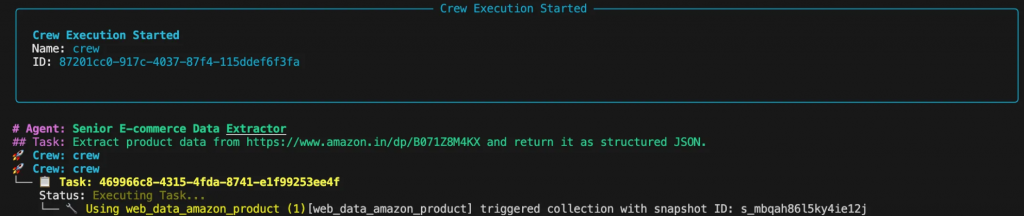
print(f"n[ERROR] Scraping failed: {str(e)}")Étape 7. Faire fonctionner le grattoir
Exécutez le script à partir de votre terminal. Vous verrez le processus de réflexion de l’agent dans la console pendant qu’il planifie et exécute la tâche.
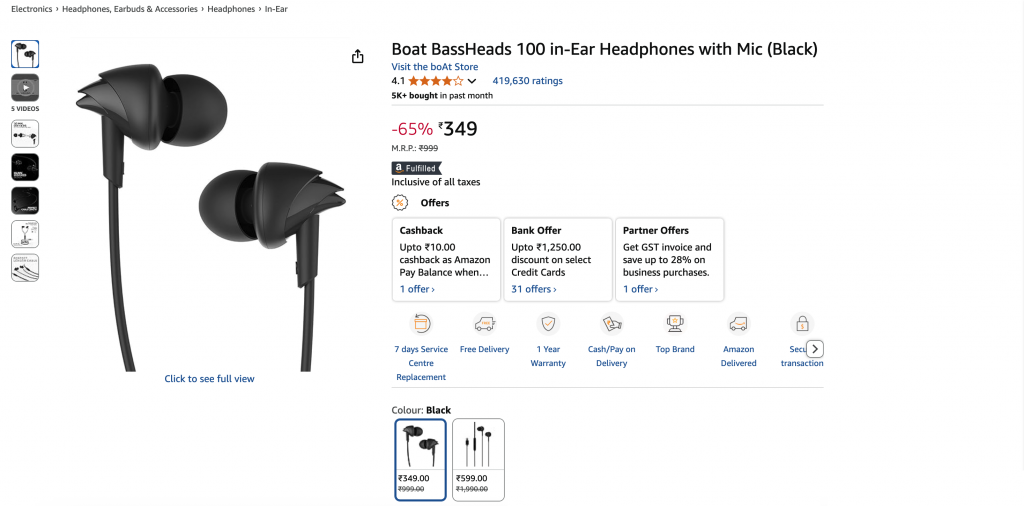
Le résultat final sera un objet JSON propre :
{
"title": "Boat BassHeads 100 in-Ear Headphones with Mic (Black)",
"current_price": "₹349",
"original_price": "₹999",
"discount": "-65%",
"rating": 4.1,
"review_count": 419630,
"last_month_bought": 5000,
"availability": "In stock",
"product_id": "B071Z8M4KX",
"image_url": "https://m.media-amazon.com/images/I/513ugd16C6L._SL1500_.jpg",
"brand": "boAt",
"key_features": [
"10mm dynamic driver",
"HD microphone",
"1.2 m cable",
"Comfortable fit",
"1 year warranty"
]
}Adaptation à d’autres objectifs
La véritable force d’une conception basée sur les agents réside dans sa flexibilité. Vous souhaitez rechercher des messages sur LinkedIn plutôt que des produits Amazon ? Il suffit de mettre à jour le rôle, l’objectif et l’histoire de l’agent, ainsi que la description de la tâche et le résultat attendu. Tout le reste – y compris le code et l’infrastructure sous-jacents – reste exactement le même.
role = "Senior LinkedIn Post Extractor"
goal = (
"Return a JSON object containing: author_name, author_title, "
"author_profile_url, post_content, post_date, likes_count, "
"and comments_count"
)
backstory = (
"Seasoned social-data engineer specializing in LinkedIn data "
"extraction using Bright Data MCP. Produces clean, structured "
"JSON output."
)
description = (
"Extract post data from LinkedIn post (ID: orlenchner_agents-"
"brightdata-activity-7336402761892122625-h5Oa) and return "
"structured JSON."
)
expected_output = """{
"author_name": "Post author's full display name",
"author_title": "Author's job title/headline",
"author_profile_url": "Author's profile URL",
"post_content": "Complete post text with formatting",
"post_date": "ISO 8601 UTC timestamp",
"likes_count": "Number of post likes",
"comments_count": "Number of post comments",
}"""Le résultat sera un objet JSON propre :
{
"author_name": "Or Lenchner",
"author_title": "CEO at Bright Data - Keeping public web data, public.",
"author_profile_url": "https://il.linkedin.com/in/orlenchner",
"post_content": "NEW PRODUCT! There’s a consensus that the future internet will be run by automated #Agents , automating the activity on behalf of “their” humans. AI solved the automation part (or at least shows strong indications), but the number one problem is ensuring smooth access to every website at scale without being blocked. browser.ai is the solution → Your Agent always gains access to any website with a simple prompt. Agents using Bright Data are already executing hundreds of millions of web actions daily on our browser infrastructure. #BrightData has long been the go-to for major LLM companies, providing the tools and scale they need to train and deploy such technologies. With browser.ai , we’re taking that foundation and tailoring it specifically for AI agents, optimizing our APIs, proxy networks, and serverless browsers to handle their unique demands. The web isn’t fully prepared for this shift yet, but we are. browser.ai immediate focus is to ensure *smooth* access to any website (DONE!), while phase two will be all about *fast* access (wip). https://browser.ai/",
"post_date": "2026-06-05T14:45:22.155Z",
"likes_count": 119,
"comments_count": 7
}Optimisation des coûts
Le MCP de Bright Data est basé sur l’utilisation, de sorte que chaque requête supplémentaire augmente votre facture. Quelques choix de conception permettent de maîtriser les coûts :
- Scraping ciblé. Demandez uniquement les champs dont vous avez besoin au lieu d’explorer des pages ou des ensembles de données entiers.
- Mise en cache. Activez le cache de CrewAI au niveau de l’outil
(cache_function)pour sauter les appels lorsque le contenu n’a pas changé, ce qui permet d’économiser du temps et des crédits. - Sélection efficace des outils. Utilisation par défaut de la zone Web Unlocker et passage à la zone Browser API uniquement lorsque le rendu JavaScript est essentiel.
- Définir
max_iter. Donnez à chaque agent une limite supérieure raisonnable afin qu’il ne puisse pas tourner en boucle indéfiniment sur une page cassée. (Vous pouvez également limiter les requêtes avecmax_rpm).
Suivez ces pratiques et vos agents CrewAI resteront sécurisés, fiables et rentables, prêts pour les charges de travail de production sur Bright Data MCP.
Prochaines étapes
L’écosystème MCP continue de s’étendre : L ‘API Responses d’OpenAI et le SDK Gemini de Google DeepMind utilisent désormais MCP de manière native, ce qui garantit une compatibilité à long terme et un investissement continu.
CrewAI déploie des agents multimodaux, un débogage plus riche et un système RBAC d’entreprise, tandis que le serveur MCP de Bright Data expose plus de 60 outils prêts à l’emploi et continue de se développer.
Ensemble, les cadres d’agents et l’accès normalisé aux données ouvrent la voie à une nouvelle vague d’intelligence web pour les applications alimentées par l’IA. Les guides sur l’intégration de MCP dans le SDK OpenAI Agents soulignent à quel point des tuyaux de données solides sont devenus essentiels.
En fin de compte, il ne s’agit pas seulement de construire un scraper, mais d’orchestrer un flux de données adaptatif conçu pour le web du futur.
Besoin de plus d’ampleur ? Oubliez l’entretien des scraper et la lutte contre les blocages – demandez simplement des données structurées :
- Crawl API – extraction de sites complets à grande échelle.
- Web Scraper APIs – plus de 120 points d’extrémité spécifiques à un domaine.
- SERP API – scraping de moteurs de recherche sans problème.
- Dataset Marketplace – des ensembles de données fraîches et validées à la demande.
Prêt à créer des applications d’IA de nouvelle génération ? Explorez la gamme complète de produits d’IA de Bright Data et voyez ce qu’un accès Web transparent et en direct peut apporter à vos agents. Pour aller plus loin, consultez nos guides MCP pour Qwen-Agent et Google ADK.