
Dans cet article de blog, vous découvrirez :
- Ce qu’est l’écoute sociale et pourquoi elle est utile.
- Pourquoi l’IA agentique est la meilleure approche pour la mettre en œuvre.
- Les principaux obstacles à l’utilisation de l’IA pour l’écoute des réseaux sociaux, en particulier via des agents.
- Comment les surmonter grâce à des outils de scraping des réseaux sociaux dédiés et compatibles avec les agents.
- Un guide étape par étape pour créer un workflow de veille sociale agentique dans LangChain, optimisé par les outils de scraping des réseaux sociaux de Bright Data.
- Ce dont vous avez besoin pour transformer cet exemple en un workflow agentique prêt à l’emploi.
- Exemples de workflows agentiques concrets pour l’écoute des réseaux sociaux.
C’est parti !
Écoute sociale : définition, fonctionnement et exemples
L’écoute sociale consiste à surveiller et analyser les conversations numériques afin de comprendre ce que les gens disent d’une marque, d’un produit, d’une annonce, d’un secteur d’activité ou d’un sujet spécifique.
Cela va au-delà du simple suivi des mentions. L’écoute sociale permet de mettre en évidence des tendances, de mesurer le sentiment et de comprendre ce que pense réellement le public externe. Son objectif ultime est de générer des informations utiles pour le marketing, les décisions relatives aux produits et le service client.
À un niveau général, l’écoute sociale suit généralement un processus en deux étapes :
- Surveillance: suivre les plateformes de réseaux sociaux à la recherche de mentions, de commentaires et de conversations liés à un sujet cible (par exemple, les concurrents, votre marque, des mots-clés pertinents, etc.).
- Analyse: interpréter ces données pour comprendre ce qui se passe, identifier des tendances et prendre des mesures pour améliorer les résultats ou obtenir des informations plus approfondies.
Par exemple, une entreprise pourrait étudier les discussions non filtrées sur Reddit au sein de communautés de niche afin de découvrir les points faibles ou les demandes de fonctionnalités. De même, une marque peut analyser les commentaires et les hashtags sur Instagram pour évaluer l’engagement et la perception de la marque.
Pourquoi un workflow agentique basé sur l’IA est idéal pour l’écoute sociale
Les workflows traditionnels de veille sociale sont généralement statiques, construits sur une série de composants qui acheminent les données de l’entrée vers la sortie dans un pipeline fixe.
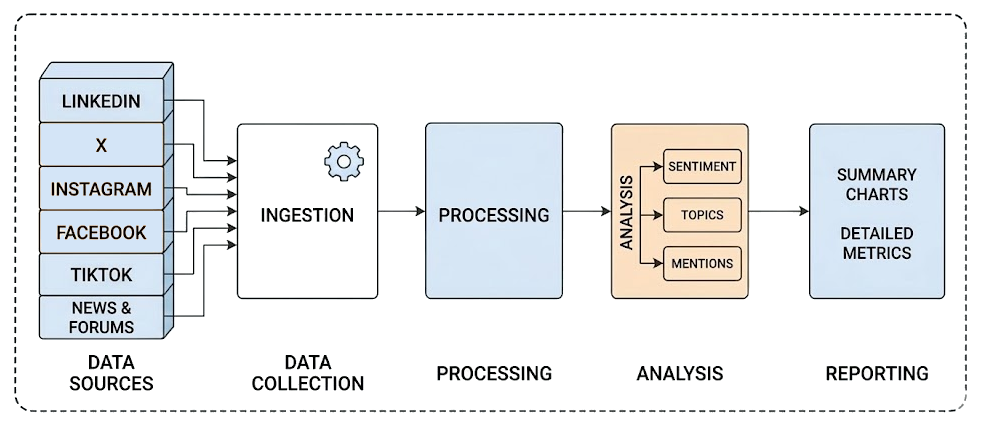
Cette approche fonctionne bien pour de nombreux processus d’analyse de données, mais elle peine à s’adapter aux données des réseaux sociaux. La raison en est qu’il est extrêmement difficile d’interpréter le contexte et de s’adapter en permanence à de nouvelles conversations. C’est là que l’IA, en particulier via des workflows agentiques, prend tout son sens !
Un workflow de veille sociale agentique transforme ce flux de données passif en un moteur de veille active. Après tout, contrairement aux pipelines statiques, les agents IA peuvent adopter un comportement autonome.
Par exemple, si un agent détecte un pic inhabituel de sentiment sur Reddit, il peut enquêter de manière proactive sur les fils de discussion connexes sur X ou Threads pour en trouver la cause profonde. Il peut également mener des recherches plus approfondies sur Reddit lui-même (ou, éventuellement, même sur Google) pour comprendre ce qui se passe.
Plus précisément, les principaux avantages d’un workflow de veille sociale agentique sont les suivants :
- Analyse approfondie du sentiment: au-delà de la simple attribution de labels « positif/neutre/négatif », l’IA comprend le sarcasme et le contexte culturel. Cela offre une vision haute fidélité des données d’entrée, notamment en termes de sentiment et d’engagement.
- Recherche autonome: les agents peuvent rechercher de manière proactive les tendances émergentes ou approfondir les conversations en cours sans nécessiter d’intervention manuelle constante.
- Intégration multiplateforme: les workflows basés sur des agents peuvent surveiller plusieurs réseaux simultanément, en regroupant les informations dans une vue unique et exploitable.
En passant de pipelines fixes à un raisonnement agentique, vous pouvez commencer à véritablement écouter les réseaux sociaux. Cette transition conduit à un système dynamique qui évolue aussi rapidement que la conversation elle-même, sans nécessiter de modifications des éléments du pipeline.
Les défis de l’écoute des réseaux sociaux avec l’IA
Il ne fait aucun doute que l’IA a considérablement facilité l’écoute des réseaux sociaux, en particulier lorsqu’il s’agit de comprendre le « pourquoi ». Les modèles avancés d’IA/ML peuvent analyser le sentiment, prédire les tendances possibles et même interpréter les nuances. Cependant, un défi majeur demeure : comment collecter des données issues des réseaux sociaux de manière fiable et à grande échelle ?
L’idée principale est de connecter votre workflow agentique directement aux API des plateformes sociales (si elles sont disponibles). Pourtant, les API officielles peuvent être coûteuses, soumises à des limites de débit et comporter des restrictions sur la manière dont vous pouvez traiter les données récupérées. De plus, les réponses des API peuvent changer au fil du temps ou être incomplètes. Pour ces raisons, les API ne constituent souvent pas une option pratique, et de nombreuses équipes s’appuient plutôt sur le Scraping web.
Pourtant, le scraping des réseaux sociaux est intrinsèquement difficile pour plusieurs raisons :
- Complexité et évolution des plateformes: les sites web de réseaux sociaux évoluent constamment, avec des modèles d’interaction et de navigation complexes et très dynamiques. Cela rend l’analyse des données particulièrement difficile.
- Mesures anti-bot: les CAPTCHA, les vérifications humaines et les limites de débit nécessitent des stratégies sophistiquées de rotation d’adresses IP, de gestion des empreintes numériques, etc.
- La fragmentation des données: les données sont réparties sur de multiples plateformes (X, Instagram, Threads, TikTok, Reddit, LinkedIn, YouTube, Facebook, etc.), ce qui rend difficile la création d’un ensemble de données unifié sur les réseaux sociaux.
Même lorsque vous avez accès à des outils de scraping de réseaux sociaux fiables, deux obstacles supplémentaires subsistent :
- Compatibilité des outils: l’outil de scraping doit être compatible avec la bibliothèque d’IA ou le workflow agentique que vous prévoyez d’utiliser.
- Utilisabilité des données: les données extraites doivent être structurées, nettoyées et fournies dans un format facilement compréhensible par l’IA. Les retards, les incohérences de formatage ou les champs de données manquants peuvent réduire l’efficacité des workflows agentiques et augmenter le risque d’hallucinations. Découvrez les meilleurs formats de données pour l’IA agentique.
Ainsi, alors que l’IA transforme l’écoute des réseaux sociaux, le véritable goulot d’étranglement réside dans l’acquisition des données.
Outils prêts pour l’IA pour une écoute sociale agentique fiable et évolutive
Vous savez que permettre aux agents IA d’accéder à des données fiables issues des réseaux sociaux constitue le principal obstacle dans les workflows de veille sociale agentique. La solution est donc claire : les agents doivent avoir accès à des outils fiables et adaptés aux entreprises pour l’extraction de données sur les réseaux sociaux.
Lorsqu’ils sont appelés de manière autonome par des agents IA, ces outils extraient des données optimisées pour l’IA à partir de plateformes de réseaux sociaux sélectionnées. Les données renvoyées constituent la base sur laquelle l’IA s’appuie pour analyser, raisonner et en tirer des enseignements. Le défi consiste à trouver de bons outils, car sans eux, vous serez confronté aux problèmes classiques de fiabilité et d’évolutivité associés au Scraping web.
Ainsi, les outils de scraping des réseaux sociaux adaptés aux agents doivent :
- Être extrêmement fiables, avec des taux de réussite élevés et un temps d’indisponibilité minimal.
- Prendre en charge les requêtes simultanées pour traiter de grands volumes de données.
- Renvoyer le contenu dans des formats adaptés à l’ingestion par les modèles de langage (LLM), tels que JSON ou Markdown.
- S’intégrer de manière transparente à la bibliothèque d’agents IA de votre choix, qu’il s’agisse de LangChain, LlamaIndex, CrawlAI, Agno, Dify ou d’autres frameworks similaires.
- Gérer les mesures anti-bot, notamment les limites de débit, la rotation d’adresses IP, les CAPTCHA et autres protections.
- Prendre en charge plusieurs plateformes de réseaux sociaux.
C’est précisément ce que propose Bright Data via son service Social Media Scraper. Découvrons-le plus en détail !
Les outils de scraping des réseaux sociaux prêts pour l’IA de Bright Data
Bright Data est la principale plateforme de collecte de données Web, se classant également en tête des principaux fournisseurs de données issues des réseaux sociaux. Parmi ses solutions de scraping compatibles avec l’IA, Social Media Scraper se distingue par ses workflows basés sur des agents :
- Il atteint une fiabilité de 99,99 % et un taux de réussite de 99,95 %, garantissant un flux de données continu pour les agents IA avec un temps d’arrêt minimal.
- Conçu pour l’évolutivité, il prend en charge une forte concurrence grâce à un réseau de Proxy de 150 millions d’adresses IP réparties dans 195 pays.
- Permet le scraping en masse de jusqu’à 5 000 pages de réseaux sociaux simultanément, permettant aux agents de traiter de grandes quantités de données.
- Renvoie des formats structurés et compatibles avec les modèles de langage (LLM), tels que JSON et Markdown, optimisés pour une ingestion rapide, le raisonnement et le traitement IA en aval.
- Propose des intégrations officielles avec plus de 70 frameworks et solutions d’IA, ainsi que des API natives pour des implémentations personnalisées.
- Gère automatiquement pour vous les défis liés à la lutte contre les bots et le scraping.
- Prend en charge les principales plateformes telles que Facebook, Instagram, LinkedIn, TikTok, X, Pinterest, Quora, YouTube, Threads, Reddit, Vimeo, et bien d’autres.
- Le modèle de paiement à la performance garantit la rentabilité, rendant la collecte de données à grande échelle pilotée par l’IA prévisible et économique.
Remarque: cette solution est également disponible en natif via le serveur Web MCP de Bright Data, ce qui permet une intégration simplifiée dans les workflows d’agents.
Comment créer un agent de veille sociale avec Bright Data
Dans cette section guidée, vous découvrirez comment vous lancer avec un agent de veille sociale simple. Celui-ci sera développé dans LangChain et connecté à Gemini, mais tout autre framework d’agent IA et fournisseur de LLM fonctionnera.
Remarque: si vous souhaitez obtenir des instructions pratiques sur la manière d’utiliser les solutions de Bright Data pour créer une application de veille sociale basée sur l’IA, consultez le webinaire «Créer une application de veille sociale basée sur l’IA ».
Suivez les étapes ci-dessous !
Prérequis
Pour suivre ce tutoriel, assurez-vous de disposer des éléments suivants :
- Python 3.10 installé localement.
- Un compte Bright Data avec une clé API prête à l’emploi.
- Une clé API Gemini (ou une clé API provenant de tout autre fournisseur de LLM pris en charge par LangChain).
- Une compréhension de base du fonctionnement des agents LangChain.
Consultez le guide officiel pour configurer votre clé API Bright Data. Conservez-la en lieu sûr, car vous en aurez besoin pour connecter votre agent LangChain à Bright Data à l’aide des outils officiels LangChain–Bright Data.
Pour plus d’informations sur l’intégration de Bright Data à LangChain, consultez les articles de blog ci-dessous :
- Utilisation de LangChain et Bright Data pour la recherche sur le Web
- Scraping web avec LangChain et Bright Data
Étape n° 1 : Configurez votre projet LangChain
Créez un nouveau projet Python pour votre agent de veille sociale :
mkdir agentic-social-listening
cd agentic-social-listeningDans le dossier du projet, créez un environnement virtuel et activez-le:
python -m venv .venv
source .venv/bin/activate # ou sous Windows : .venvScriptsactivateAjoutez un fichier agent.py, qui contiendra la logique de votre agent d’écoute sociale. La structure de votre projet devrait ressembler à ceci :
agentic-social-listening/
├── .venv/
└── agent.pyDans l’environnement virtuel activé, installez les bibliothèques requises :
pip install langchain langchain-google-genai langchain-brightdataIl s’agit de :
langchain: simplifie la création d’agents IA.langchain-google-genai: connecte votre agent à Gemini via l’intégrationChatGoogleGenerativeAI.langchain-brightdata: connecte votre agent LangChain aux solutions de scraping de Bright Data via l’intégration officielle, comme expliqué dans la documentation.
Parfait ! Chargez le dossier du projet dans votre IDE Python préféré et préparez-vous à développer un workflow de veille sociale basé sur des agents.
Étape n° 2 : Définir le workflow de l’agent
Supposons que vous souhaitiez créer un agent de veille sociale qui surveille le sentiment et les mentions sur deux publications (l’une sur Instagram et l’autre sur TikTok) pour la même annonce. Bien que les publications diffèrent, l’annonce sous-jacente est identique.
Il s’agit d’un exemple intéressant, car il montre comment un agent peut suivre l’engagement sur plusieurs plateformes pour une seule campagne, identifier les sentiments qui se recoupent et ceux spécifiques à chaque plateforme, et détecter les mentions de produits ou les demandes promotionnelles.
Ici, nous utiliserons une annonce de Nike. Voici comment elle apparaît sur Instagram: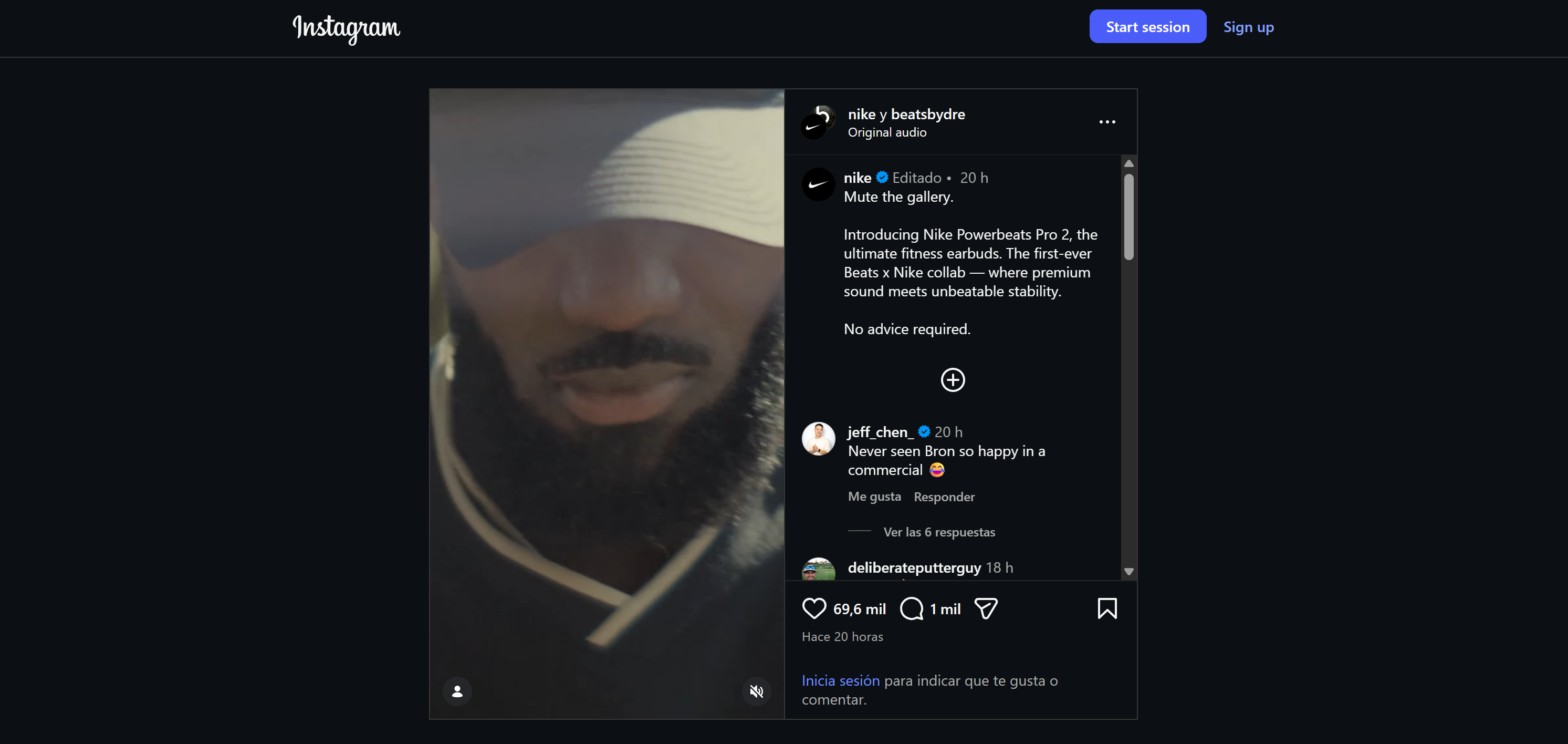
Et voici à quoi elle ressemble sur TikTok: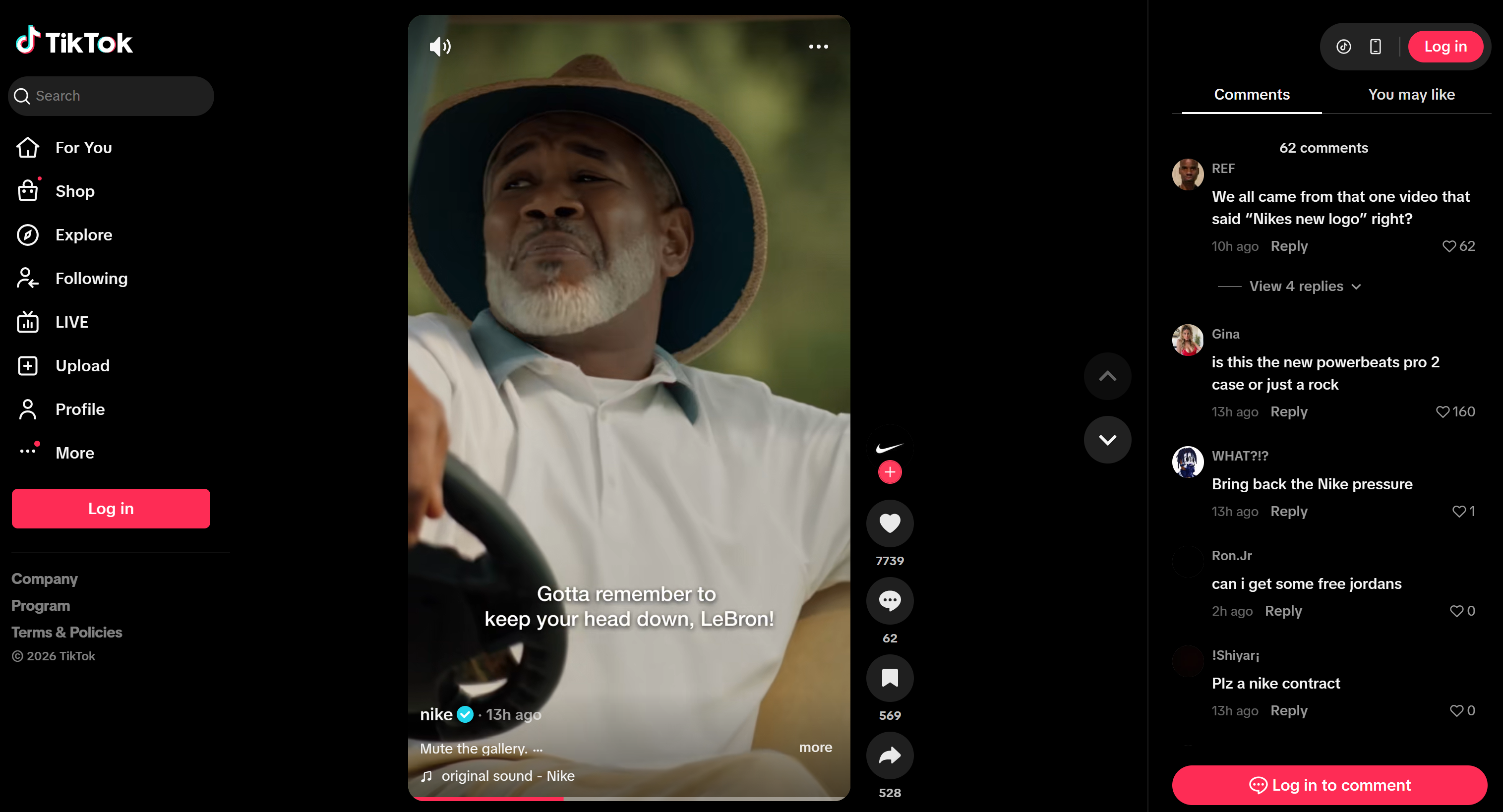
L’idée est de laisser l’agent IA utiliser l’API Social Media Scraper de Bright Data pour récupérer les commentaires des deux publications. Il analysera et traitera ensuite ces données via son cerveau LLM alimenté par Gemini. Cela complète un workflow de veille sociale agentique de base.
Remarque: il s’agit simplement d’un exemple, en partant du principe que vous disposez déjà des publications cibles sur les réseaux sociaux. Dans un scénario prêt pour la production, les outils de Bright Data peuvent être utilisés pour effectuer des recherches sur le Web, suivre des comptes de réseaux sociaux dans leur intégralité et gérer l’écoute sociale multi-plateforme à grande échelle.
Tout est clair ! Il est temps de développer l’agent.
Étape n° 3 : implémenter l’agent
Pour créer l’agent de veille sociale présenté précédemment, ajoutez les lignes de code suivantes à agent.py:
# pip install langchain langchain-google-genai langchain-brightdata
from langchain_brightdata import BrightDataWebScraperAPI
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain.agents import create_agent
# Remplacez par vos clés API réelles
GOOGLE_API_KEY = "<VOTRE_CLÉ_API_GOOGLE>"
BRIGHT_DATA_API_KEY = "<VOTRE_CLÉ_API_BRIGHT_DATA>"
# Initialisez le moteur LLM
llm = ChatGoogleGenerativeAI(
model="gemini-3-flash-preview",
google_api_key=GOOGLE_API_KEY
)
# Initialiser l'outil API Bright Data Web Scraper
web_scraper_api_tool = BrightDataWebScraperAPI(
bright_data_api_key=BRIGHT_DATA_API_KEY
)
# Créer un agent ReAct ayant accès aux API de Scraping web de Bright Data
agent = create_agent(llm, [web_scraper_api_tool])
# Définir une requête simple de veille sociale
prompt = """
Vous êtes un expert en veille sociale.
Cibles :
- Instagram Reel : "https://www.instagram.com/nike/reel/DV_PTxKDueO/"
- Vidéo TikTok : "https://www.tiktok.com/@nike/video/7618336096694406414"
Tâche :
1. Utilisez l'API Social Media Scraper de Bright Data pour collecter tous les commentaires des publications cibles.
2. Générez un rapport Markdown résumant l'engagement et le sentiment.
3. Mettez en évidence les commentaires mentionnant d'autres produits Nike, des promotions ou des demandes intéressantes des utilisateurs en vue d'une analyse approfondie.
"""
# Diffuser la sortie étape par étape de l'agent
for step in agent.stream(
{
"messages": prompt
},
stream_mode="values",
):
step["messages"][-1].pretty_print()Voici ce que fait le code :
- Lit les informations d’identification pour l’accès aux API Gemini et Bright Data (en production, les lire à partir des variables d’environnement).
- Crée un moteur d’IA alimenté par Gemini pour traiter et analyser les données des réseaux sociaux.
- Connecte l’agent aux API de scraping de Bright Data (y compris l’API Social Media Scraper) via l’outil LangChain
BrightDataWebScraperAPI. - Utilise la fonction
create_agent()pour définir un agent ReAct capable d’appeler dynamiquement les outils de scraping de Bright Data. - Indique à l’agent les cibles (publications Instagram et TikTok) et les tâches (collecte de commentaires, analyse des sentiments, génération de rapports et signalement des mentions clés).
- Lance l’agent et transmet le résultat au terminal.
Mission accomplie ! Vous avez désormais mis en place un workflow agentique simple pour l’écoute sociale.
Étape n° 4 : Tester l’agent
Exécutez l’agent avec :
python agent.pyVous verrez l’agent exécuter l’outil bright_data_web_scraper (comme prévu) :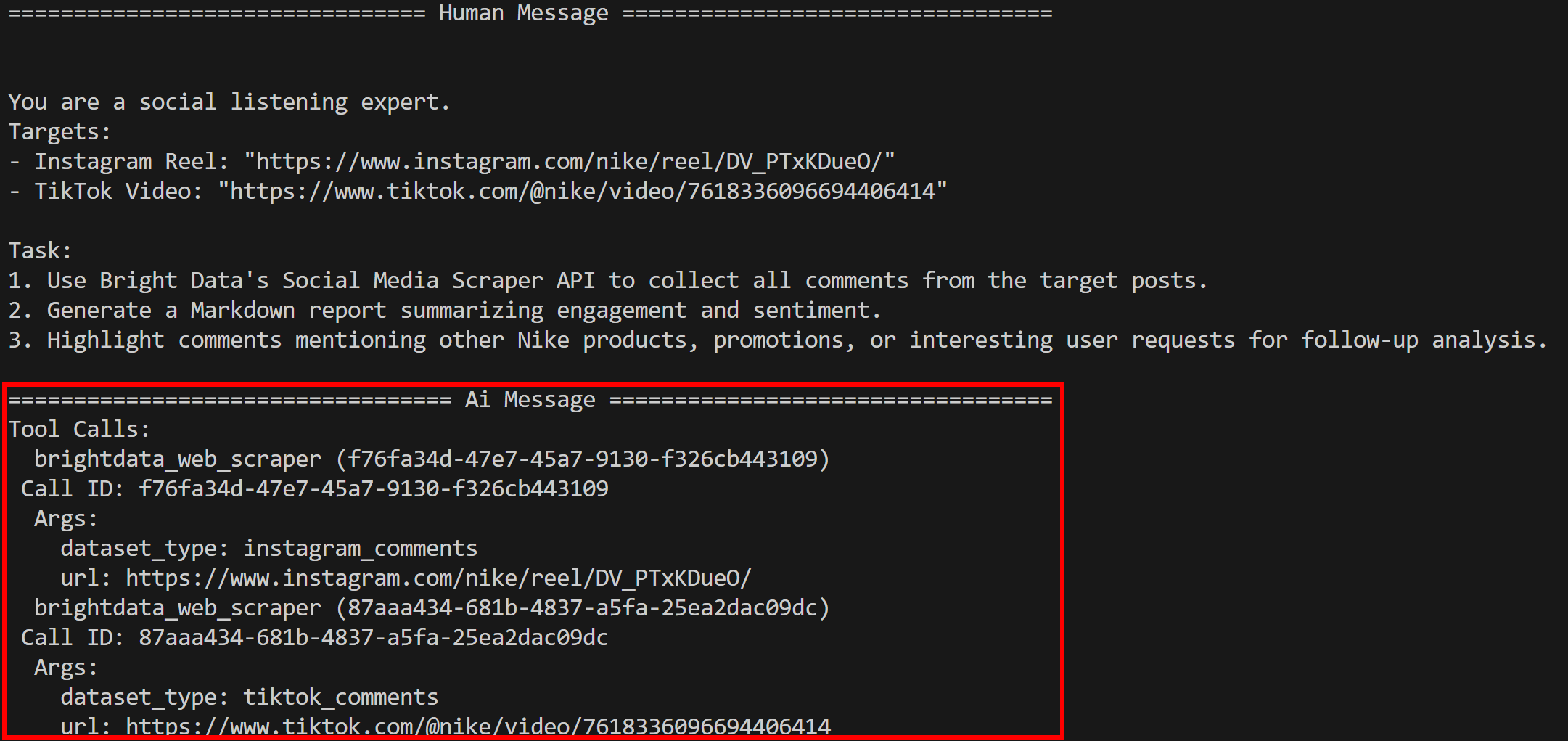
Plus précisément, il appelle les outils sous-jacents instagram_comments et tiktok_comments. En arrière-plan, ceux-ci s’appuient sur les outils Bright Data Instagram Comments Scraper et TikTok Comments Scraper.
Les résultats de l’outil sont renvoyés sous forme de données structurées en JSON, contenant tous les commentaires extraits des deux publications :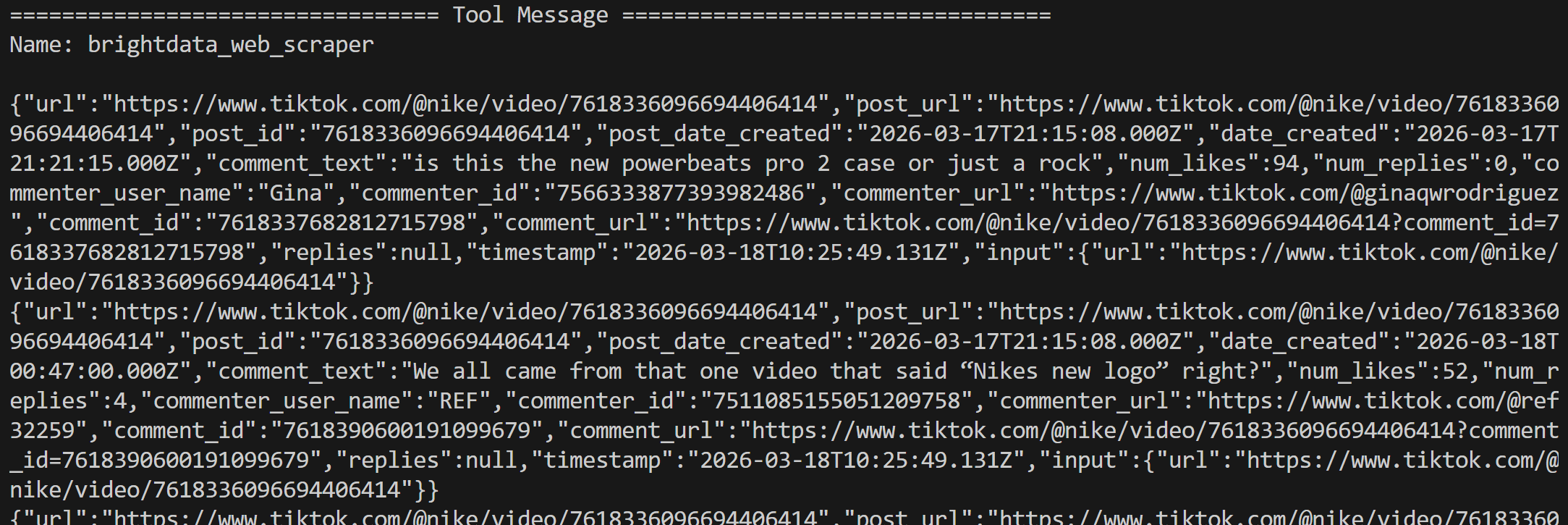
Ensuite, l’agent traite les commentaires à des fins d’écoute sociale, conformément aux instructions, et génère un rapport Markdown :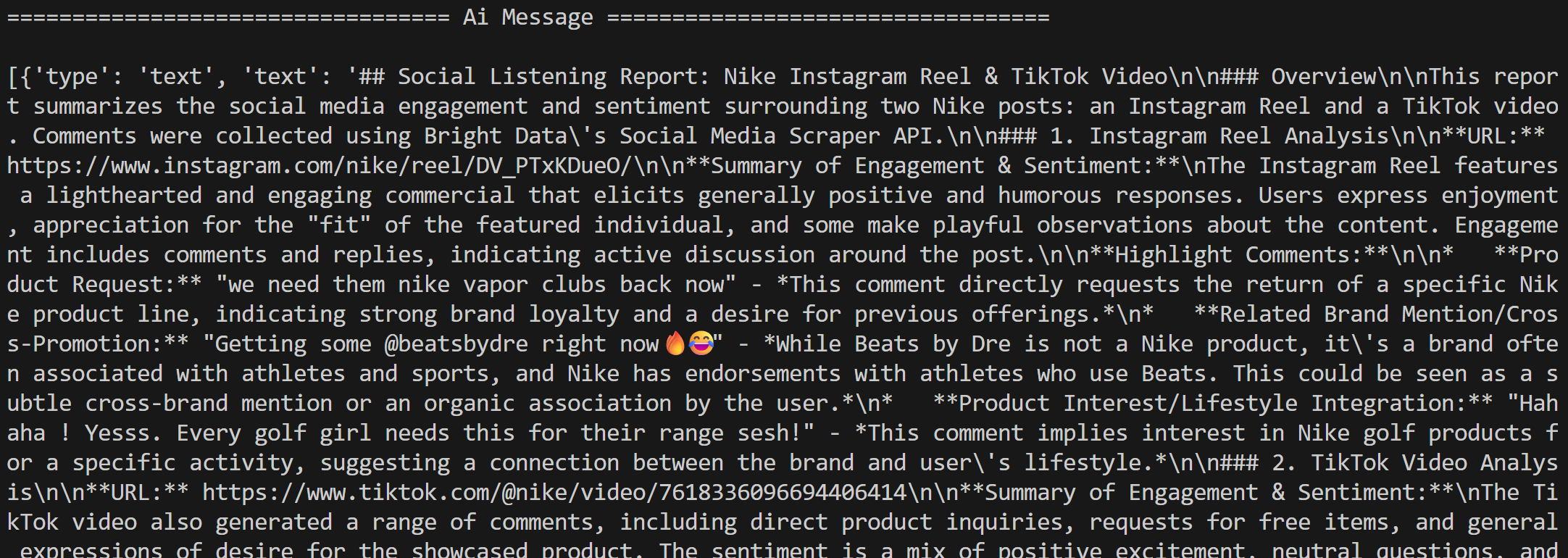
Lorsqu’il est affiché dans un rendu Markdown, le rapport se présente comme suit :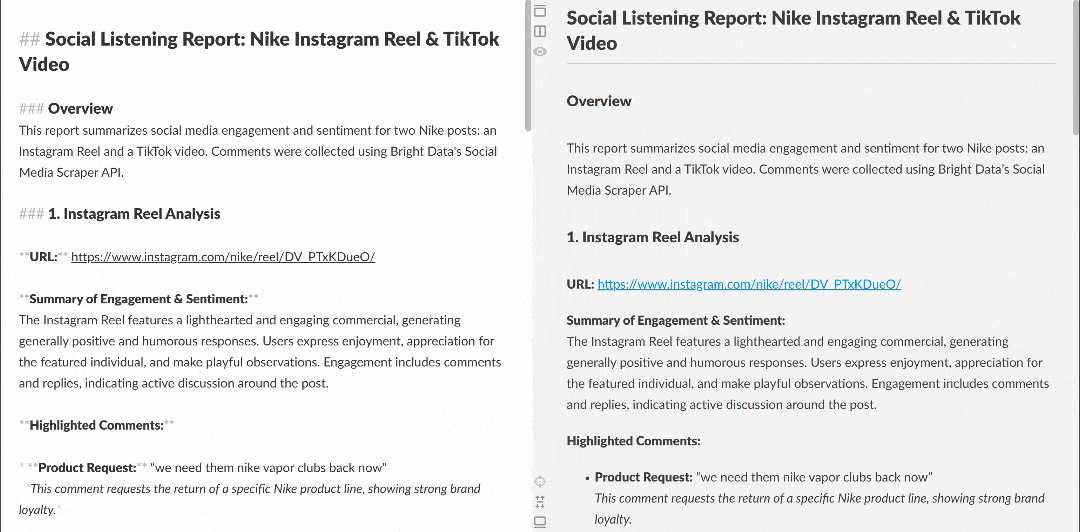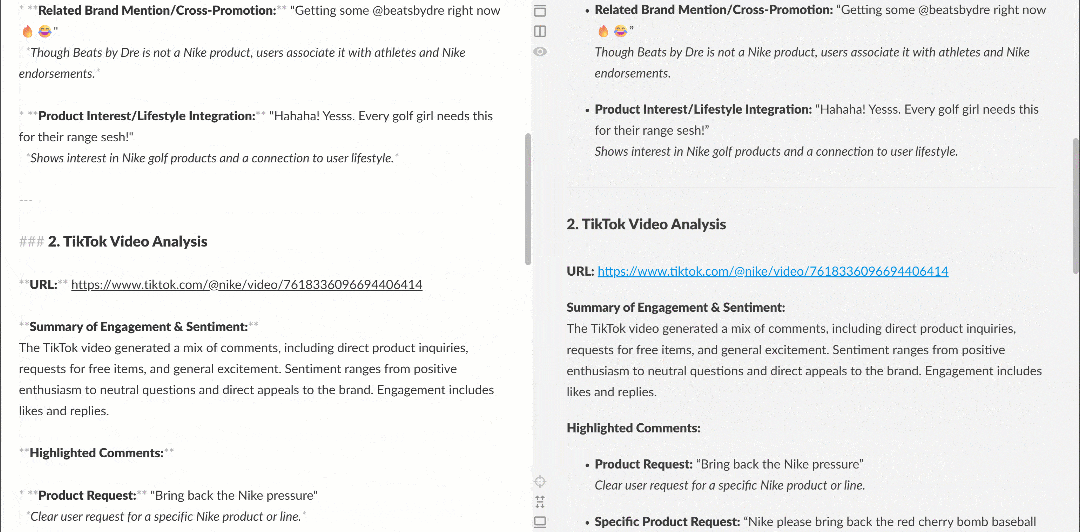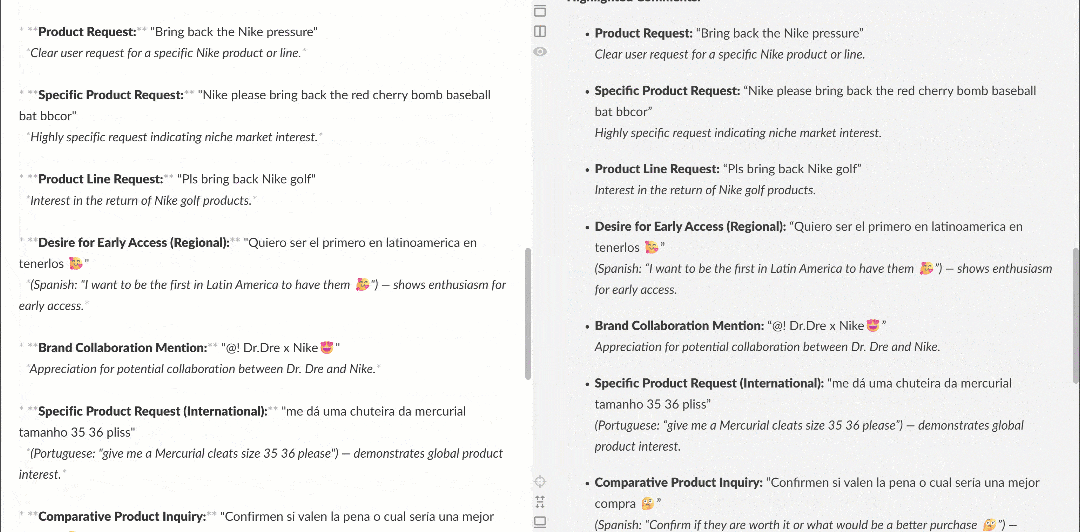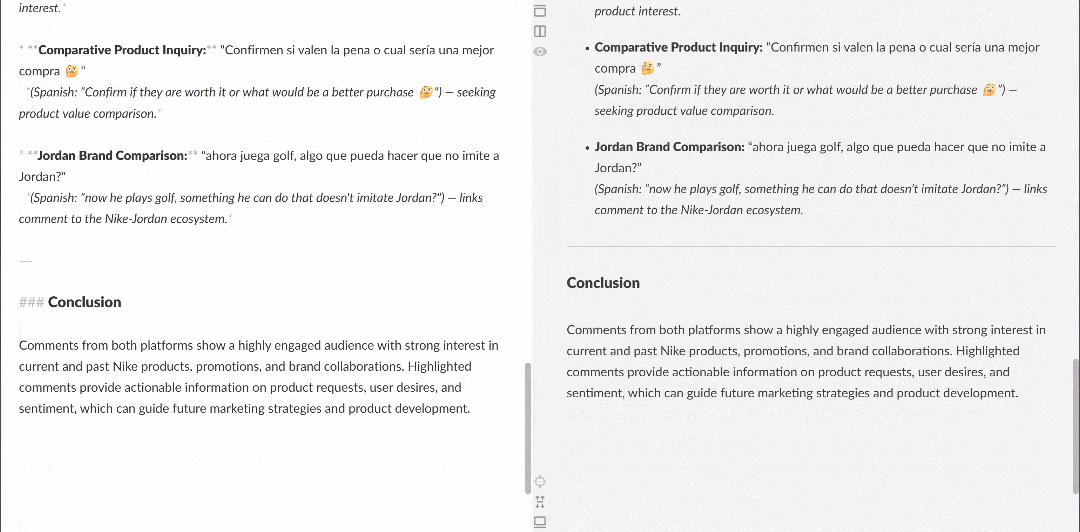
Remarquez qu’il contient des informations intéressantes, telles que plusieurs utilisateurs demandant à Nike de relancer Nike Golf ou de se concentrer davantage sur les produits de golf. Ce sont des détails qu’un workflow d’analyse de sentiment basique aurait pu manquer.
De plus, si une erreur se produit ou si l’agent détermine que les données récupérées sont insuffisantes pour atteindre l’objectif, il récupérera automatiquement des commentaires supplémentaires ou répétera les appels vers les outils Bright Data. Cela rend l’agent entièrement autonome.
Et voilà ! Vous venez d’apprendre à créer un workflow d’écoute des réseaux sociaux basé sur Bright Data dans LangChain.
Workflows agentiques prêts pour la production pour l’écoute des réseaux sociaux
Le chapitre précédent a montré comment créer un agent de veille sociale simple. Cependant, un workflow agentique prêt pour la production est bien plus complexe. Découvrons comment le concevoir et les étapes pour le mettre en œuvre !
Architecture
Dans les workflows de veille sociale basés sur des agents, le recours à plusieurs agents IA spécialisés tend à produire de meilleurs résultats que l’utilisation d’un seul agent monolithique. Chaque agent doit se concentrer sur une responsabilité distincte, et une configuration possible est la suivante :
- Agent de collecte de données: recueille les publications, les commentaires, les profils ou les indicateurs d’engagement provenant de plusieurs plateformes de réseaux sociaux à l’aide d’outils tels que le Social Media Scraper de Bright Data.
- Agent d’analyse: traite les données collectées pour en extraire les tendances, le sentiment et d’autres informations exploitables, transformant ainsi le contenu brut des réseaux sociaux en informations pertinentes.
- Agent de reporting/sortie: il présente les données analysées sous forme de tableaux de bord, de résumés ou de fichiers (JSON, CSV) pour faciliter leur utilisation par des humains ou d’autres systèmes d’IA.
- Agent de coordination: supervise le flux de travail, assure des transferts fluides, évalue la qualité des résultats et itère automatiquement les processus lorsque des améliorations ou une collecte de données supplémentaires sont nécessaires.
Feuille de route
Compte tenu des quatre agents, mettez en œuvre un flux de travail agentique pour l’écoute sociale comme suit :
- Choisissez la pile d’agents IA: sélectionnez-la en fonction des types d’agents nécessaires, des intégrations d’outils et de la facilité d’orchestration du flux de travail.
- Ajoutez les agents: créez quatre agents placeholders au sein du framework d’agents IA que vous avez choisi.
- Intégrez des outils de scraping des réseaux sociaux: donnez à l’agent de récupération de données l’accès au Social Media Scraper de Bright Data ou à des Scrapers de réseaux sociaux spécifiques.
- Configurez les tâches de récupération de données: demandez à l’agent de récupération de données de récupérer les données des réseaux sociaux requises.
- Analysez les données collectées: demandez à l’agent d’analyse de traiter le texte, le sentiment, les tendances et les indicateurs d’engagement.
- Générez des rapports structurés: demandez à l’agent de reporting de produire le résultat souhaité à partir des données analysées.
- Coordonnez et itérez: mettez en œuvre l’agent de coordination pour surveiller les résultats, déclencher des cycles répétés, etc.
- Concevoir la boucle d’agents: relier les quatre agents (Récupération des données → Analyse → Rapports → Coordination).
- Automatiser la planification du flux de travail: configurer des exécutions récurrentes pour une veille sociale continue.
Exemples de workflows de veille sociale agentique
Compte tenu de la feuille de route des IA présentée précédemment, vous pouvez créer plusieurs workflows de veille des réseaux sociaux basés sur des IA. Voici quelques exemples !
Surveillance du sentiment à l’égard de la marque
Les agents IA suivent en continu les mentions de votre marque sur les plateformes sociales. À l’aide du Social Media Scraper de Bright Data, les agents collectent les publications, les commentaires et les réactions, puis analysent le sentiment, détectent les tendances émergentes et signalent les pics négatifs, permettant ainsi une gestion proactive de la réputation.
Analyse de la concurrence
Les agents IA surveillent les hashtags, les mots-clés et les discussions sur TikTok, X, Reddit et dans les commentaires YouTube. L’IA détecte ensuite les stratégies de contenu, les performances des campagnes et les modèles d’engagement de l’audience, vous aidant ainsi à ajuster votre propre stratégie en temps réel.
Découverte et prévision des tendances
Les agents IA surveillent les hashtags, les mots-clés et les discussions sur TikTok, X et Reddit. Les API de scraping de Bright Data fournissent des données structurées et prêtes pour les modèles de langage (LLM) afin que les agents puissent détecter les tendances émergentes, prévoir la popularité et orienter les décisions marketing ou produit.
Détection et réponse aux crises
Les agents surveillent les pics soudains de sentiments négatifs ou les publications virales sur plusieurs réseaux. Grâce au Scraper de réseaux sociaux de Bright Data, l’IA peut alerter immédiatement les équipes, rédiger des réponses adaptées au contexte ou déclencher des workflows d’escalade automatisés.
Analyse des retours sur les campagnes
Les agents IA collectent les réactions des utilisateurs, les commentaires et les indicateurs de publication sur Facebook, Instagram, YouTube ou d’autres plateformes. Grâce aux Scrapers de Bright Data, les agents récupèrent les données dont ils ont besoin pour suivre le succès des campagnes et optimiser les stratégies de communication.
Conclusion
Dans cet article, vous avez découvert ce qu’est l’écoute des réseaux sociaux, ce qu’elle implique et pourquoi les workflows agentiques constituent la meilleure façon de la mettre en œuvre. Vous avez également acquis une compréhension claire des défis à relever et de la manière de les surmonter à l’aide d’outils de scraping des réseaux sociaux compatibles avec l’IA.
Bright Data prend en charge l’écoute des réseaux sociaux grâce à un Scraper dédié, de niveau entreprise et facile à intégrer. Cela vous permet de créer des workflows agentiques évolutifs pour l’écoute des réseaux sociaux (et d’autres cas d’utilisation du marketing sur les réseaux sociaux) sans perte de fiabilité ou de performance.
Créez dès aujourd’hui un compte Bright Data gratuitement et découvrez nos solutions de collecte de données Web compatibles avec l’IA !
FAQ
Quelle est la différence entre l’écoute sociale et la surveillance sociale ?
La surveillance des réseaux sociaux suit « ce qui » s’est passé en collectant les notifications, les mentions « J’aime » et les indicateurs. L’écoute sociale, quant à elle, analyse le « pourquoi » en examinant le sentiment et les tendances qui sous-tendent ces conversations afin d’orienter la stratégie à long terme.
Quelle est la différence entre l’analyse des sentiments et l’écoute sociale ?
L’analyse des sentiments évalue les émotions ou les opinions exprimées dans un texte, qu’elles soient positives, négatives ou neutres. L’écoute sociale a une portée plus large : elle surveille les conversations sur toutes les plateformes afin de suivre les tendances, la perception de la marque et les retours des clients, en utilisant souvent l’analyse des sentiments comme l’un de ses outils.
Un agent IA peut-il être utilisé pour l’écoute sociale ?
Oui, les agents IA peuvent être utilisés pour l’écoute sociale. En réalité, ils sont parfaits pour cette tâche grâce à leur capacité à s’adapter à des scénarios changeants ou inattendus, ce qui est caractéristique du paysage des réseaux sociaux en constante évolution.
De quels outils une IA a-t-elle besoin pour accéder à l’écoute sociale ?
Les agents IA dédiés à l’écoute sociale ont besoin d’outils pour collecter des données sur les réseaux sociaux. En s’intégrant à des Scrapers tels que le Social Media Scraper de Bright Data, les agents peuvent surveiller plusieurs plateformes à grande échelle, fournissant ainsi des informations exploitables en temps réel.
Sur quelles plateformes de réseaux sociaux est-il judicieux d’appliquer l’écoute sociale ?
Les plateformes de réseaux sociaux les plus pertinentes à scraper pour la veille sociale automatisée sont X, Reddit, Threads, Facebook, Instagram, LinkedIn, TikTok, Quora, Pinterest, YouTube et Vimeo.




