

Dans ce guide, vous apprendrez :
- Pourquoi le Scraping web est une excellente méthode pour enrichir les LLM avec des données du monde réel
- Les avantages et les défis liés à l’utilisation de données scrapées dans les workflows LangChain
- Une bibliothèque pour une intégration simplifiée du scraping dans LangChain
- Comment créer une intégration complète de Scraping web LangChain dans un tutoriel étape par étape
C’est parti !
Utiliser le Scraping web pour alimenter vos applications LLM
Le Scraping web consiste à récupérer des données à partir de pages Web. Ces données peuvent ensuite être utilisées pour alimenter des applications RAG (Retrieval-Augmented Generation) en les intégrant à des LLM (Large Language Models).
Les systèmes RAG nécessitent l’accès à des données riches, récentes, en temps réel, spécifiques à un domaine ou étendues, qui ne sont pas facilement disponibles dans les Jeux de données statiques que vous pouvez acheter ou télécharger en ligne. Le Scraping web comble cette lacune en fournissant à la fois des informations structurées extraites de diverses sources telles que des articles d’actualité, des listes de produits et les réseaux sociaux.
Pour en savoir plus, consultez notre article sur la collecte de données d’entraînement LLM.
Avantages et défis de l’utilisation des données scrapées dans LangChain
LangChain est un puissant framework permettant de créer des workflows basés sur l’IA, qui simplifie l’intégration des LLM à diverses sources de données. Il excelle dans l’analyse de données, la synthèse et la réponse à des questions en combinant les LLM avec des connaissances en temps réel spécifiques à un domaine. Cependant, l’acquisition de données de haute qualité reste toujours un problème.
Le scraping web peut résoudre ce problème, mais il comporte plusieurs défis, notamment les mesures anti-bot, les CAPTCHA et les sites web dynamiques. Le maintien de Scrapers conformes et efficaces peut également être long et techniquement complexe. Pour plus de détails, consultez notre guide sur les mesures anti-scraping.
Ces obstacles peuvent ralentir le développement d’applications basées sur l’IA qui dépendent de données en temps réel. La solution ? L’API Web Scraper de Bright Data, un outil prêt à l’emploi qui offre des points de terminaison de scraping pour des centaines de sites web.
Grâce à des fonctionnalités avancées telles que la rotation des adresses IP, la Résolution de CAPTCHA et le rendu JavaScript, Bright Data automatise l’extraction des données pour vous. Cela garantit une collecte de données fiable, efficace et sans tracas, accessible via de simples appels API.
LangChain Outils Bright Data
Bien que vous puissiez intégrer l’API de Scraping web de Bright Data et d’autres outils de scraping directement dans votre flux de travail LangChain, cela nécessiterait une logique personnalisée et du code standard. Pour gagner du temps et réduire vos efforts, nous vous recommandons d’utiliser le package d’intégration officiel LangChain Bright Data langchain-brightdata.
Ce package vous permet de vous connecter aux services de Bright Data dans les workflows LangChain. Il expose notamment les classes suivantes :
BrightDataSERP: s’intègre à l’API SERP de Bright Data pour effectuer des requêtes sur les moteurs de recherche avec ciblage géographique.BrightDataUnblocker: fonctionne avec le Web Unlocker de Bright Data pour accéder à des sites web qui peuvent être géo-restreints ou protégés par des systèmes anti-bot.BrightDataWebScraperAPI: s’interface avec l’API Web Scraper de Bright Data pour extraire des données structurées de divers domaines.
Dans ce tutoriel, nous nous concentrerons sur l’utilisation de la classe BrightDataWebScraperAPI. Voyons comment !
LangChain Scraping web powered by Bright Data : guide étape par étape
Dans cette section, vous apprendrez à créer un workflow de Scraping web LangChain. L’objectif est d’utiliser LangChain pour récupérer le contenu d’un profil LinkedIn à l’aide de l’API Web Scraper de Bright Data, puis d’utiliser OpenAI pour évaluer si le candidat correspond à un poste spécifique.
Nous utiliserons ma page de profil LinkedIn publique comme référence, mais n’importe quel autre profil LinkedIn fera également l’affaire :
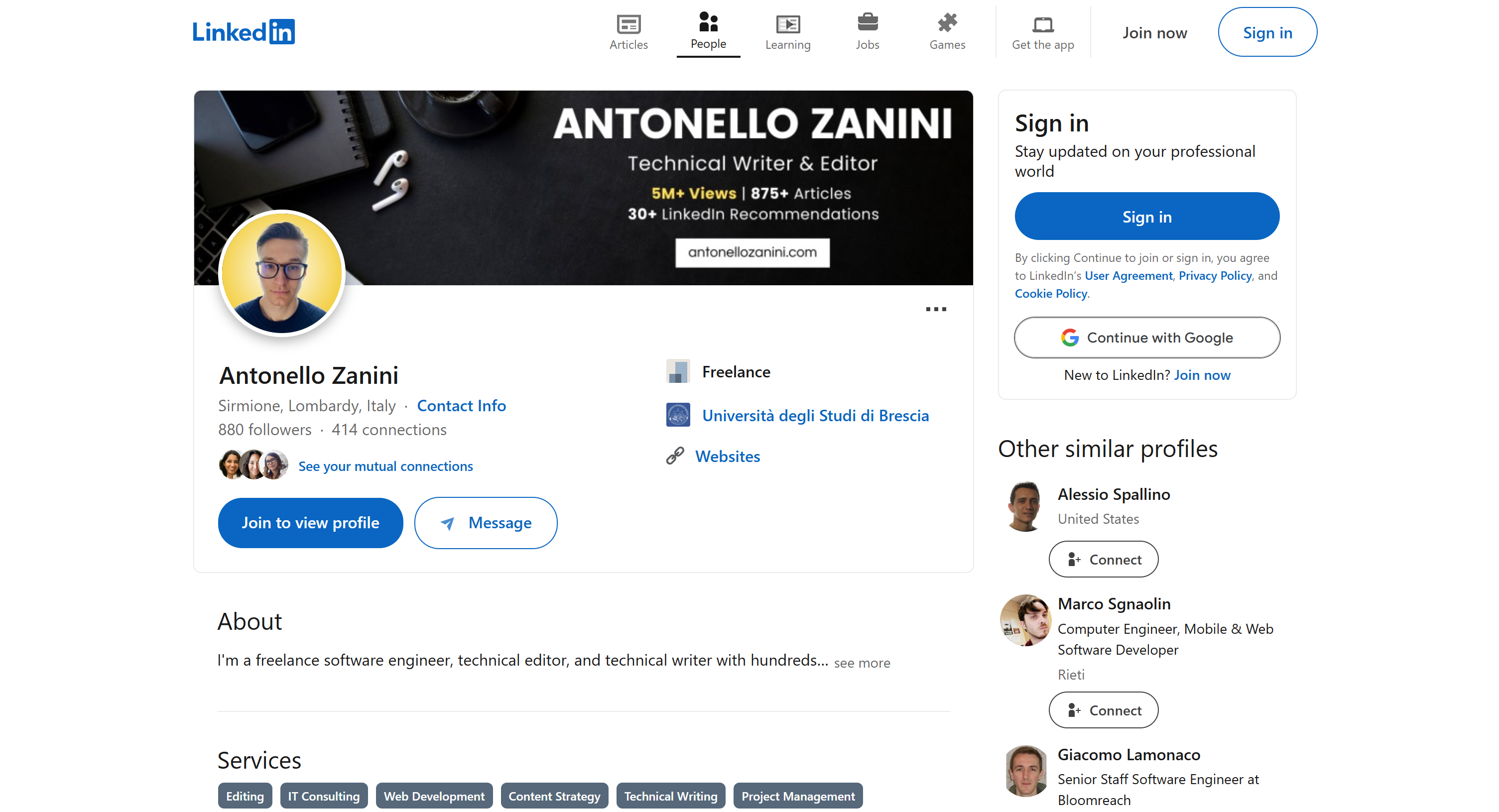
Remarque: ce que nous créons ici n’est qu’un exemple. Le code que vous êtes sur le point d’écrire est facilement adaptable à différents scénarios. Cela signifie qu’il peut également être étendu avec des fonctionnalités supplémentaires de LangChain. Par exemple, vous pourriez même créer un chatbot RAG basé sur les données SERP.
Suivez les étapes ci-dessous pour commencer !
Prérequis
Pour suivre ce tutoriel, vous aurez besoin des éléments suivants :
- Python 3+ installé sur votre ordinateur
- Une clé API OpenAI
- Un compte Bright Data
Ne vous inquiétez pas si vous ne disposez pas de tout cela. Nous vous guiderons tout au long du processus, de l’installation de Python à l’obtention de vos identifiants OpenAI et Bright Data.
Étape n° 1 : configuration du projet
Tout d’abord, vérifiez si Python 3 est installé sur votre ordinateur. Si ce n’est pas le cas, téléchargez-le et installez-le.
Exécutez cette commande dans le terminal pour créer un dossier pour votre projet :
mkdir langchain-scrapinglangchain-scraping contiendra votre projet de scraping Python LangChain.
Ensuite, accédez au dossier du projet et initialisez un environnement virtuel Python à l’intérieur :
cd langchain-scraping
python3 -m venv venvRemarque: sous Windows, utilisez python au lieu de python3.
Ouvrez maintenant le répertoire du projet dans votre IDE Python préféré. PyCharm Community Edition ou Visual Studio Code avec l’extension Python feront l’affaire.
Dans langchain-scraping, ajoutez un fichier script.py. Il s’agit d’un script Python vide, mais il contiendra bientôt votre logique de Scraping web LangChain.
Dans le terminal de l’IDE, sous Linux ou macOS, activez l’environnement virtuel à l’aide de la commande ci-dessous :
source venv/bin/activateOu, sous Windows, exécutez :
venv/Scripts/activateSuper ! Vous êtes maintenant prêt.
Étape n° 2 : installer les bibliothèques requises
Le projet de scraping Python LangChain s’appuie sur les bibliothèques suivantes :
python-dotenv: pour charger les variables d’environnement à partir d’un fichier.env. Elle sera utilisée pour gérer les clés API Bright Data et OpenAI.langchain-openai: intégrations LangChain pour OpenAI via son SDKopenai.langchain-brightdata: intégration LangChain avec les services de scraping Bright Data.
Dans un environnement virtuel activé, installez toutes les dépendances à l’aide de cette commande :
pip install python-dotenv langchain-openai langchain-brightdataSuper ! Vous êtes prêt à écrire une logique de scraping.
Étape n° 3 : préparez votre projet
Dans script.py, ajoutez l’importation suivante :
from dotenv import load_dotenvEnsuite, créez un fichier .env dans le dossier de votre projet pour stocker toutes vos informations d’identification. Voici à quoi devrait ressembler la structure actuelle de votre fichier de projet :

Demandez à python-dotenv de charger les variables d’environnement à partir de .env avec cette ligne dans script.py:
load_dotenv()Super ! Il est temps de configurer la solution API Web Scraper de Bright Data.
Étape n° 4 : Configurer l’API Web Scraper
Comme mentionné au début de cet article, le Scraping web présente plusieurs défis. Heureusement, cela devient beaucoup plus facile avec une solution tout-en-un comme les API Web Scraper de Bright Data. Ces API vous permettent de récupérer sans effort le contenu analysé de plus de 120 sites web.
Pour configurer l’API Web Scraper dans LangChain à l’aide de langchain_brightdata, suivez les instructions ci-dessous. Pour une présentation générale de la solution de scraping web de Bright Data, consultez la documentation officielle.
Si vous ne l’avez pas encore fait, créez un compte Bright Data. Après vous être connecté, vous serez redirigé vers le tableau de bord de votre compte. À partir de là, cliquez sur le bouton « Paramètres du compte » situé en bas à gauche :
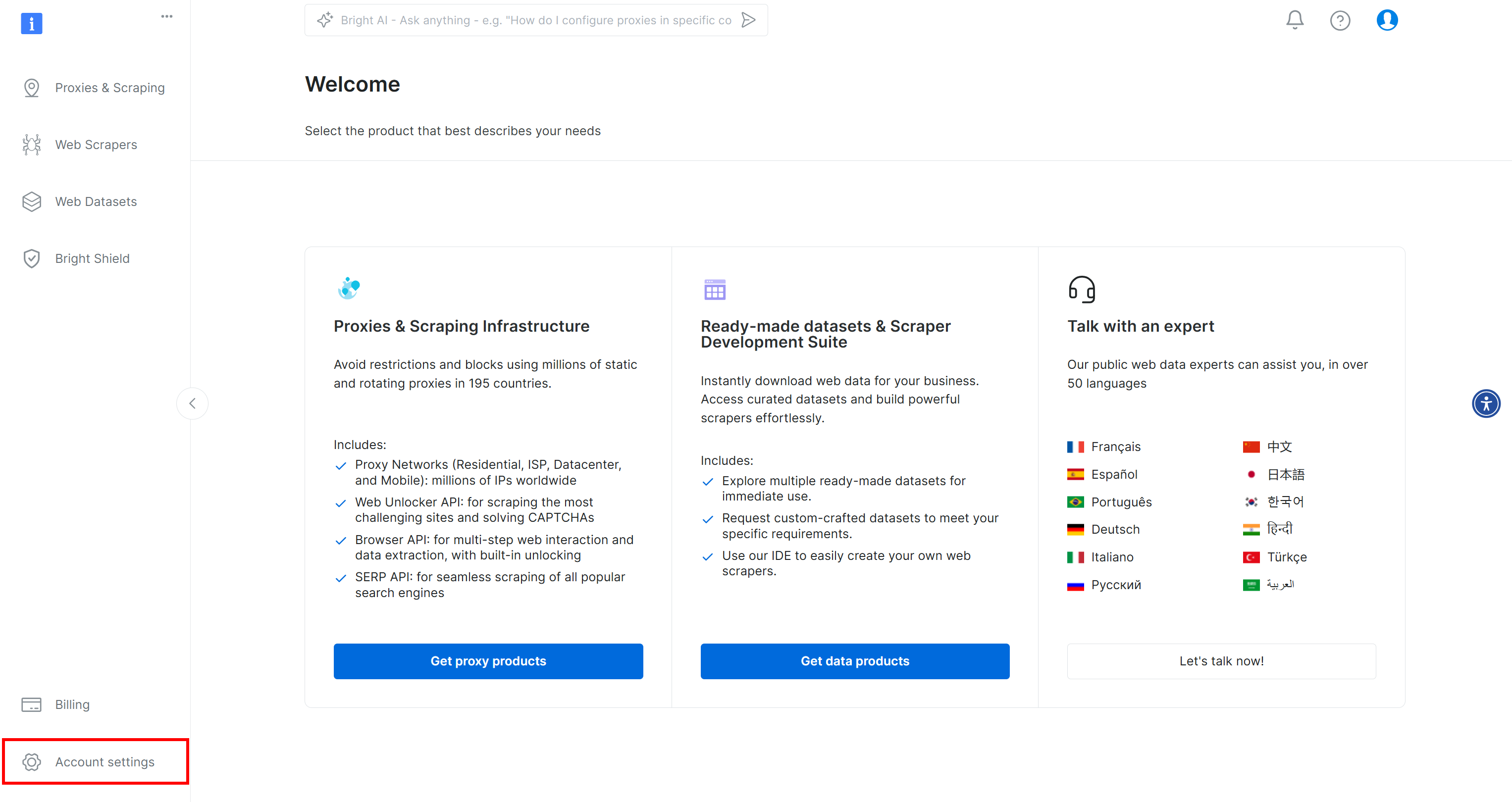
Sur la page « Paramètres du compte », si vous avez déjà créé un jeton API Bright Data, cliquez sur « … » puis sélectionnez l’option « Copier le jeton » :
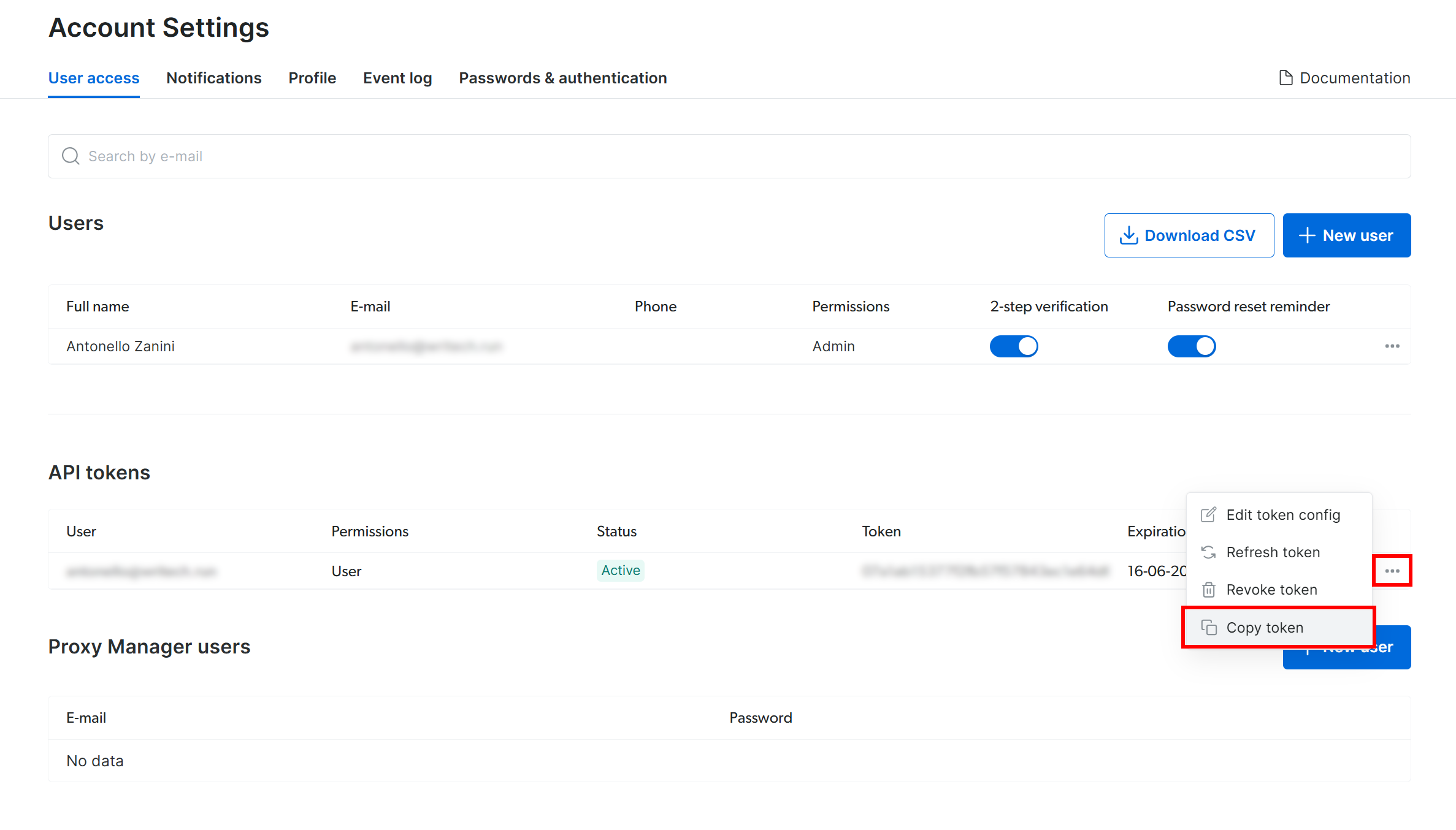
Sinon, cliquez sur le bouton « Ajouter un jeton » :
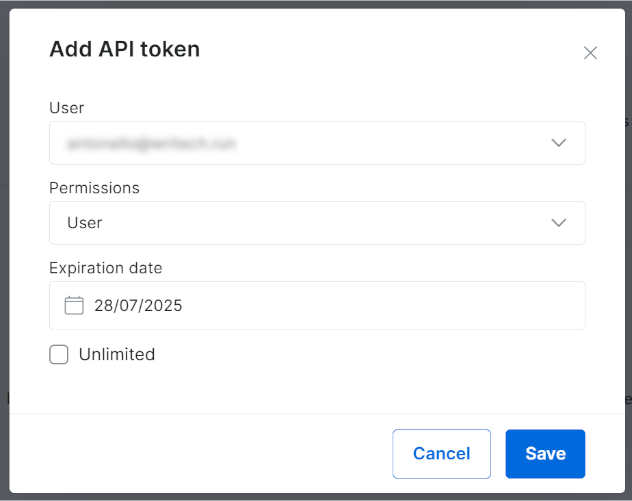
La fenêtre modale suivante s’affichera. Configurez votre jeton API Bright Data et appuyez sur le bouton « Enregistrer » :
Vous recevrez votre nouveau jeton API :
Copiez la valeur de votre clé API Bright Data.
Dans votre fichier .env, enregistrez ces informations en tant que variable d’environnement BRIGHT_DATA_API_KEY:
BRIGHT_DATA_API_KEY="<VOTRE_CLÉ_API_BRIGHT_DATA>"Remplacez <VOTRE_CLÉ_API_BRIGHT_DATA> par la valeur que vous avez copiée à partir de la fenêtre modale/du tableau.
Maintenant, dans script.py, importez langchain_brightdata:
from langchain_brightdata import BrightDataWebScraperAPIAucune autre action n’est requise, car langchain_brightdata tente automatiquement de lire la clé API Bright Data à partir de la variable d’environnement BRIGHT_DATA_API_KEY.
Et voilà ! Vous pouvez désormais utiliser l’API Web Scraper dans LangChain.
Étape n° 5 : Utiliser Bright Data pour le Scraping web
langchain_brightdata prend en charge l’intégration avec l’API Web Scraper de Bright Data via la classe BrightDataWebScraperAPI.
Voici un aperçu du fonctionnement de cette classe :
- Elle envoie une requête synchrone à l’API Web Scraper configurée, en acceptant l’URL de la page à scraper.
- Une tâche de scraping basée sur le cloud est lancée pour récupérer et effectuer l’analyse des données de l’URL spécifiée.
- La bibliothèque attend la fin de la tâche de scraping, puis renvoie les données scrapées au format JSON.
Pour intégrer le Scraping web dans votre workflow LangChain, définissez une fonction réutilisable avec le code suivant :
def get_scraped_data(url, dataset_type):
# Initialise la classe d'intégration de l'API LangChain Bright Data Scraper.
web_scraper_api = BrightDataWebScraperAPI()
# Récupérer les données d'intérêt en se connectant à l'API Web Scraper
results = web_scraper_api.invoke({
"url": url,
"dataset_type": dataset_type
})
return resultsLa fonction accepte les arguments suivants :
url: URL de la page à partir de laquelle récupérer les données.dataset_type: spécifie le type d’API Web Scraper à utiliser pour extraire les données de la page. Par exemple,« linkedin_person_profile »indique à l’API Web Scraper d’extraire les données de l’URL du profil LinkedIn public fourni.
Dans cet exemple, appelez-la comme suit :
url = « https://linkedin.com/in/antonello-zanini »
scraped_data = get_scraped_data(url, « linkedin_person_profile »)scraped_data contiendra des données telles que celles-ci :
{
"input": {
"url": "https://linkedin.com/in/antonello-zanini"
},
"id": "antonello-zanini",
"name": "Antonello Zanini",
# Omis pour plus de concision...
« about » : « Je suis ingénieur logiciel indépendant, rédacteur technique et auteur technique avec des centaines... »,
« current_company » : {
« name » : « Freelance »
},
« current_company_name » : « Freelance »,
# Omis pour plus de concision...
« langues » : [
{
« titre » : « Italien »,
« sous-titre » : « Maîtrise native ou bilingue »
},
{
« titre » : « Anglais »,
« sous-titre » : « Maîtrise professionnelle complète »
},
{
« title » : « Espagnol »,
« subtitle » : « Maîtrise professionnelle complète »
}
],
« recommendations_count » : 32,
« recommendations » : [
# Omis par souci de concision...
],
« posts » : [
# Omis par souci de concision...
],
"activity": [
# Omis pour plus de concision...
],
# Omis pour plus de concision...
}Plus précisément, il stocke toutes les informations disponibles sur la version publique de la page de profil LinkedIn cible, mais structurées au format JSON. Pour obtenir ces données, l’API Web Scraper a contourné pour vous tous les mécanismes anti-bot ou anti-scraping.
Incroyable ! Vous venez d’apprendre à utiliser l’API Scraper de Bright Data Web pour le Scraping web dans LangChain.
Étape n° 6 : Préparez-vous à utiliser les modèles OpenAI
Cet exemple s’appuie sur les modèles OpenAI pour l’intégration LLM dans LangChain. Pour utiliser ces modèles, vous devez configurer une clé API OpenAI dans vos variables d’environnement.
Ajoutez donc la ligne suivante à votre fichier .env:
OPENAI_API_KEY="<VOTRE_CLÉ_API_OPEN>"Remplacez <VOTRE_CLÉ_API_OPENAI> par la valeur de votre clé API OpenAI. Si vous ne savez pas comment en obtenir une, suivez le guide officiel.
Maintenant, dans script.py, importez langchain_openai comme suit :
from langchain_openai import ChatOpenAIVous n’avez rien d’autre à faire. langchain_openai recherchera automatiquement votre clé API OpenAI dans la variable d’environnement OPENAI_API_KEY.
Parfait ! Il est temps d’utiliser les modèles OpenAI dans votre script de scraping LangChain.
Étape n° 7 : générer l’invite LLM
Définissez une variable f-string qui prend les données scrapées et génère une invite pour le LLM. Dans ce cas, l’invite inclut votre demande RH et intègre les données scrapées du candidat :
prompt = f"""
« Pensez-vous que ce candidat convient pour un poste d'ingénieur logiciel à distance ? Pourquoi ?
Répondez en 150 mots maximum.
CANDIDAT :
'{scraped_data}'
"""Dans cet exemple, vous créez un workflow d’IA pour conseiller RH à l’aide de LangChain. Grâce à la flexibilité de l’API Web Scraper (qui prend en charge plus de 120 domaines) combinée aux LLM, vous pouvez facilement adapter cette approche pour alimenter un large éventail d’autres workflows LangChain.
💡 Idée: pour encore plus de flexibilité, pensez à lire l’invite à partir du fichier .env.
Dans l’exemple actuel, l’invite complète sera :
Pensez-vous que ce candidat convient pour un poste d'ingénieur logiciel à distance ? Pourquoi ?
Répondez en 150 mots maximum.
CANDIDAT :
'{
"input": {
"url": "https://linkedin.com/in/antonello-zanini"
},
"id": "antonello-zanini",
"name": "Antonello Zanini",
// omis pour plus de concision...
"about": "Je suis ingénieur logiciel indépendant, rédacteur technique et auteur technique avec des centaines...",
},
[ommis pour plus de concision...]'Si vous le transmettez à ChatGPT, vous devriez obtenir le résultat souhaité :
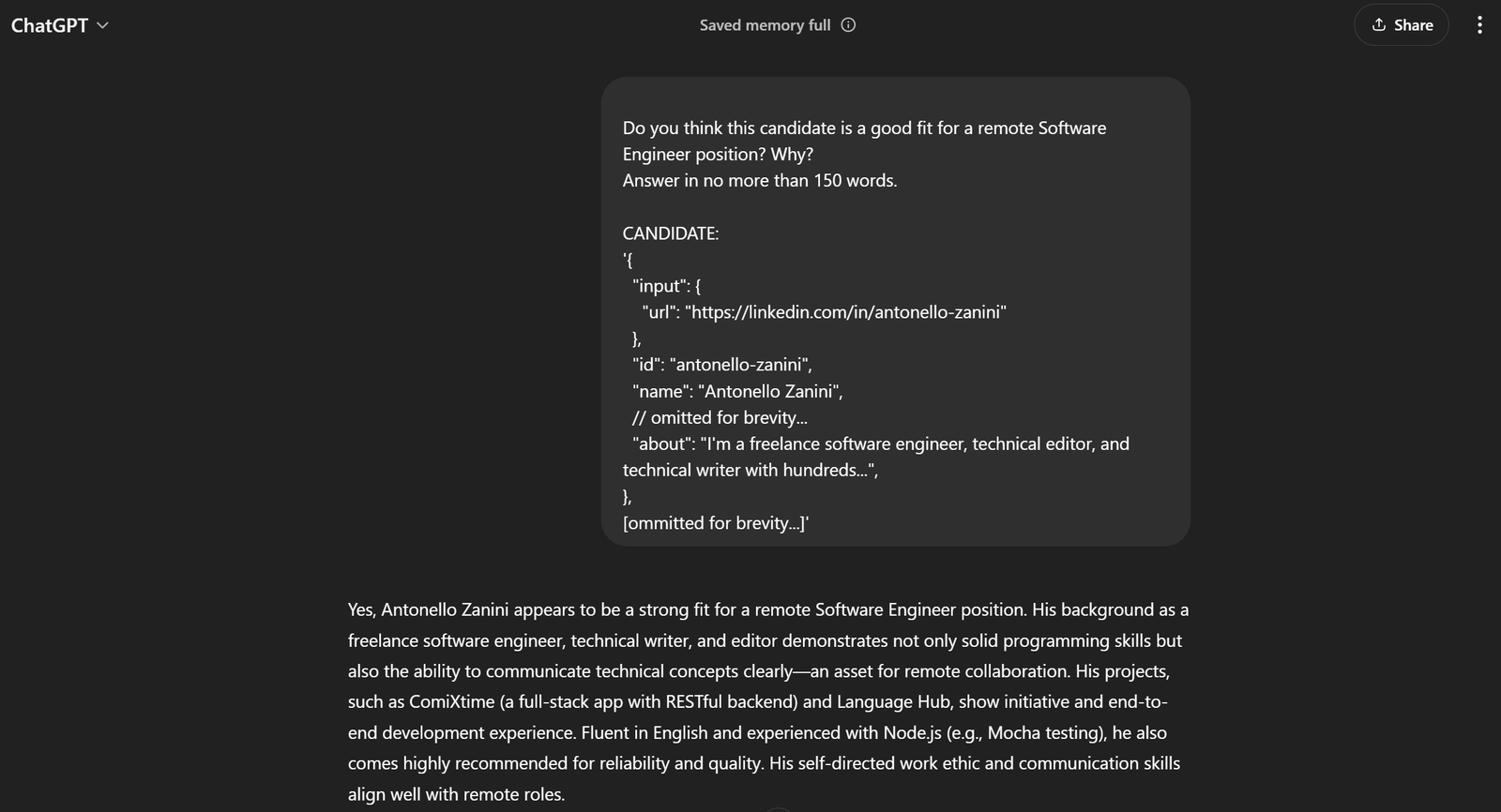
Cela suffit pour affirmer que l’invite fonctionne à merveille !
Étape n° 8 : intégrer OpenAI
Transmettez l’invite que vous avez générée précédemment à un objet ChatOpenAI LangChain configuré sur le modèle d’IA GPT-4o mini:
model = ChatOpenAI(model="gpt-4o-mini")
response = model.invoke(prompt)À la fin du traitement IA, response.content devrait contenir un résultat similaire à l’évaluation générée par ChatGPT à l’étape précédente. Accédez à cette réponse textuelle avec :
évaluation = réponse.contenuWaouh ! La logique de Scraping web LangChain est terminée.
Étape n° 9 : exporter les données traitées par l’IA
Il ne vous reste plus qu’à exporter les données générées par le modèle IA sélectionné via LangChain vers un format lisible par l’homme, tel qu’un fichier JSON.
Commencez par initialiser un dictionnaire avec les données souhaitées. Ensuite, exportez-le et enregistrez-le sous forme de fichier JSON, comme indiqué ci-dessous :
export_data = {
"url": url,
"evaluation": evaluation
}
file_name = "analysis.json"
with open(file_name, "w") as file:
json.dump(export_data, file, indent=4)Importez json depuis la bibliothèque standard Python :
import jsonFélicitations ! Votre script est prêt.
Étape n° 10 : ajoutez quelques journaux
Le processus de scraping web à l’aide de Web Scraping IA et de l’analyse ChatGPT peut prendre un certain temps. Cela est normal en raison de la charge supplémentaire liée au scraping et au traitement des données provenant de services tiers. Il est donc recommandé d’inclure des journaux pour suivre la progression du script.
Pour ce faire, ajoutez des instructions d'impression aux étapes clés du script, comme suit :
url = "https://linkedin.com/in/antonello-zanini"
print(f"Récupération des données avec l'API Web Scraper à partir de {url}...")
scraped_data = get_scraped_data(url, "linkedin_person_profile")
print("Données récupérées avec succès")
print("Création de l'invite IA...")
prompt = f"""
« Pensez-vous que ce candidat correspond au poste d'ingénieur logiciel à distance ? Pourquoi ?
Répondez en 150 mots maximum.
CANDIDAT :
'{scraped_data}'
"""
print("Invite créée")
print("Envoi de l'invite à ChatGPT...")
model = ChatOpenAI(model="gpt-4o-mini")
response = model.invoke(prompt)
evaluation = response.content
print("Réponse reçue de ChatGPTn")
print("Exportation des données vers JSON"...)
export_data = {
"url": url,
"evaluation": evaluation
}
file_name = "analysis.json"
with open(file_name, "w") as file:
json.dump(export_data, file, indent=4)
print(f"Données exportées vers '{file_name}'")Notez que chaque étape du workflow de Scraping web LangChain est clairement consignée. L’exécution dans le terminal sera désormais beaucoup plus facile à suivre.
Étape n° 11 : assembler le tout
Votre fichier script.py final doit contenir :
from dotenv import load_dotenv
from langchain_brightdata import BrightDataWebScraperAPI
from langchain_openai import ChatOpenAI
import json
# Charger les variables d'environnement à partir du fichier .env
load_dotenv()
def get_scraped_data(url, dataset_type):
# Initialiser la classe d'intégration de l'API LangChain Bright Data Scraper
web_scraper_api = BrightDataWebScraperAPI()
# Récupérer les données d'intérêt en se connectant à l'API Web Scraper
results = web_scraper_api.invoke({
"url": url,
"dataset_type": dataset_type
})
return results
# Récupérer le contenu de la page web donnée
url = "https://linkedin.com/in/antonello-zanini"
print(f"Récupération des données avec l'API Web Scraper à partir de {url}...")
# Utilisation de l'API Web Scraper pour obtenir les données récupérées
scraped_data = get_scraped_data(url, "linkedin_person_profile")
print("Données récupérées avec succèsn")
print("Création de l'invite IA...")
# Définir l'invite en utilisant les données récupérées comme contexte
prompt = f"""
"Pensez-vous que ce candidat convient pour un poste d'ingénieur logiciel à distance ? Pourquoi ?
Répondez en 150 mots maximum.
CANDIDAT :
'{scraped_data}'
"""
print("Invite créée")
# Demander à ChatGPT d'effectuer la tâche spécifiée dans l'invite
print("Envoi de l'invite à ChatGPT...")
model = ChatOpenAI(model="gpt-4o-mini")
response = model.invoke(prompt)
# Obtenir le résultat de l'IA
évaluation = réponse.contenu
print("Réponse reçue de ChatGPTn")
print("Exportation des données vers JSON...")
# Exporter les données produites vers JSON
export_data = {
"url": url,
"évaluation": évaluation
}
# Écrire le dictionnaire de sortie dans un fichier JSON
file_name = "analysis.json"
with open(file_name, "w") as file:
json.dump(export_data, file, indent=4)
print(f"Données exportées vers '{file_name}'")Incroyable, non ? En environ 50 lignes de code, vous venez de créer un script de Scraping web LangChain basé sur l’IA.
Vérifiez qu’il fonctionne avec cette commande :
python3 script.pyOu, sous Windows :
python script.pyLe résultat dans le terminal devrait être le suivant :
Récupération des données avec l'API Web Scraper depuis https://linkedin.com/in/antonello-zanini...
Données récupérées avec succès.
Création de l'invite IA...
Invite créée.
Envoi de l'invite à ChatGPT...
Réponse reçue de ChatGPT.
Exportation des données vers JSON...
Données exportées vers « analysis.json ».Ouvrez le fichier analysis.json qui apparaît dans le répertoire du projet. Vous devriez voir quelque chose comme ceci :
{
"url": "https://linkedin.com/in/antonello-zanini",
"evaluation": "Antonello Zanini semble être un candidat solide pour un poste d'ingénieur logiciel à distance. Son expérience en tant qu'ingénieur logiciel indépendant témoigne de sa capacité d'adaptation et de sa motivation, deux qualités essentielles pour le travail à distance. Son expérience en rédaction technique et en édition suggère de solides compétences en communication, indispensables pour collaborer avec des équipes à distance. De plus, ses connaissances variées en programmation, attestées par ses publications sur les tests unitaires et les bundlers JavaScript, renforcent son expertise technique.nnIl a reçu de nombreux commentaires positifs de la part de ses clients, qui soulignent sa fiabilité et la clarté de ses livrables, des qualités essentielles pour une collaboration à distance efficace. De plus, ses compétences linguistiques en italien, en anglais et en espagnol peuvent améliorer la communication au sein d'équipes internationales diversifiées. Dans l'ensemble, la combinaison des compétences techniques, des aptitudes en communication et des recommandations positives d'Antonello fait de lui un candidat idéal pour un poste à distance. »
}Et voilà ! Le workflow HR LangChain, enrichi de données en temps réel, est désormais complet.
Conclusion
Dans ce tutoriel, vous avez découvert pourquoi le Scraping web est une méthode efficace pour collecter des données pour vos workflows d’IA et comment analyser ces données à l’aide de LangChain.
Plus précisément, vous avez créé un script de Scraping web LangChain basé sur Python pour extraire des données d’une page de profil LinkedIn et les traiter à l’aide des API OpenAI. Bien que ce workflow LangChain soit idéal pour prendre en charge les tâches RH, le code présenté peut facilement être étendu à d’autres workflows et scénarios.
Les principaux défis liés au Scraping web dans LangChain sont les suivants :
- Les sites en ligne modifient souvent la structure de leurs pages.
- De nombreux sites mettent en œuvre des mesures anti-bot avancées.
- La récupération simultanée de grands volumes de données peut être complexe et coûteuse.
L’API Web Scraper de Bright Data représente une solution efficace pour extraire des données des principaux sites web, surmontant facilement ces défis. Grâce à son intégration fluide avec LangChain, c’est un outil précieux pour prendre en charge les applications RAG et d’autres solutions basées sur LangChain.
N’hésitez pas à découvrir nos autres offres pour l’IA et le LLM.
Inscrivez-vous dès maintenant pour découvrir quels services Proxy ou produits de scraping de Bright Data répondent le mieux à vos besoins. Commencez par un essai gratuit !




