

Dans ce tutoriel, vous apprendrez :
- Comment configurer Snowflake pour recevoir des données de l’infrastructure de livraison de Bright Data.
- Configurer le jeu de données Goodreads Books pour une livraison directe dans un stage interne Snowflake.
- Déclencher un snapshot et le charger dans une table interrogeable, puis exécuter du SQL sur plus de 6 millions d’enregistrements de livres.
Plongeons dans le vif du sujet !
Présentation du flux d’ingestion Snowflake
À haut niveau, le pipeline comporte trois phases, chacune couverte dans sa propre section :
- Configuration de Snowflake : Créez la base de données, le stage, le rôle et l’utilisateur de service contre lequel Bright Data s’authentifiera. C’est la partie la plus intensive en SQL, mais chaque commande est fournie en intégralité et s’exécute dans l’ordre.
- Configuration de Bright Data : Choisissez un jeu de données sur le marketplace, connectez-le à votre environnement Snowflake et déclenchez un snapshot. Bright Data pousse les fichiers directement dans votre stage interne.
- Chargement et requêtes : Une seule commande
COPY INTOdéplace les fichiers stagés dans une table structurée. Le reste est du SQL standard.
Le résultat est une table Snowflake entièrement interrogeable, peuplée de données web structurées, actualisée selon le calendrier requis par votre cas d’usage. Pas d’exports CSV, pas de code ETL personnalisé.
Découvrez chaque phase et comment les mettre en œuvre !
1. Configuration de Snowflake
Bright Data livre les fichiers en s’authentifiant directement dans votre compte Snowflake. Cela nécessite un stage interne dédié (zone d’atterrissage pour les fichiers entrants), un rôle de service avec accès en écriture à ce stage, et un utilisateur de service assigné à ce rôle.
L’utilisation d’objets dédiés à cette fin maintient l’ingestion séparée de vos charges analytiques et facilite l’audit, la révocation ou la rotation des identifiants ultérieurement.
2. Configuration du jeu de données Bright Data et livraison du snapshot
Le Dataset Marketplace de Bright Data contient des jeux de données pré-construits et validés couvrant Amazon, LinkedIn, Crunchbase, Glassdoor, les annonces hôtelières, l’immobilier, les offres d’emploi, et bien plus. Chaque jeu de données est livré avec une référence complète des champs afin que vous puissiez concevoir votre schéma Snowflake avant l’arrivée du premier octet.
La livraison directe vers Snowflake est disponible pour le produit Datasets. Si vous utilisez les Web Scraper APIs, livrez les fichiers dans un bucket S3 et chargez depuis un stage externe.
Une fois Snowflake configuré comme destination de livraison, Bright Data gère le transfert. Il s’authentifie avec l’utilisateur de service que vous avez créé, stage les fichiers dans votre stage interne et consigne la livraison dans le panneau de contrôle. Vous pouvez déclencher des snapshots à la demande, selon un calendrier, ou via l’API Marketplace Dataset.
3. Chargement et requêtes
Une fois les fichiers dans le stage, une seule commande COPY INTO les charge dans votre table. Ensuite, vous interrogez avec du SQL standard, sans syntaxe spéciale ni nouvel outillage.
Configuration de Snowflake pour recevoir Bright Data
Commençons à construire le pipeline en préparant le côté Snowflake. Toutes les commandes de cette section s’exécutent dans la feuille SQL de Snowsight ou via SnowSQL. Exécutez d’abord ceci pour vous assurer d’avoir les privilèges nécessaires pour créer des bases de données, des rôles et des utilisateurs :
USE ROLE ACCOUNTADMIN;Prérequis
Pour suivre cette section, vous devez disposer de :
- Un compte Snowflake avec les privilèges
ACCOUNTADMINouSYSADMIN. - Une connaissance de base de l’interface Snowflake (Snowsight).
Étape #1 : Créer une base de données et un schéma
Dans Snowflake, une base de données est le conteneur de premier niveau pour tous vos objets de données. Un schéma se trouve à l’intérieur d’une base de données et regroupe les tables, stages et autres objets associés. La création d’une base de données et d’un schéma dédiés à Bright Data maintient ses objets séparés de vos données existantes et facilite la gestion des permissions.
CREATE DATABASE IF NOT EXISTS bright_data_db;
CREATE SCHEMA IF NOT EXISTS bright_data_db.web_data;Vous pouvez utiliser une base de données existante si vous préférez. Remplacez son nom partout où bright_data_db apparaît dans les commandes suivantes.
Étape #2 : Créer un warehouse dédié
Dans Snowflake, un warehouse est le cluster de calcul qui exécute les instructions SQL, y compris COPY INTO. Il est séparé du stockage, ce qui signifie que vous ne payez le calcul que lorsqu’il est actif. Un warehouse dédié à l’ingestion Bright Data rend ces coûts de calcul visibles et évite que les charges d’ingestion ne concurrencent vos requêtes analytiques pour les ressources.
CREATE WAREHOUSE IF NOT EXISTS bright_data_wh
WAREHOUSE_SIZE = 'XSMALL'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE;AUTO_SUSPEND = 60 arrête le warehouse après 60 secondes d’inactivité pour éviter qu’il ne tourne à vide entre les livraisons. AUTO_RESUME = TRUE le redémarre automatiquement lors du prochain COPY INTO. XSmall gère confortablement la plupart des livraisons Bright Data. Redimensionnez si les volumes augmentent.
Étape #3 : Créer un stage interne nommé
Dans Snowflake, un stage est un emplacement nommé où les fichiers se trouvent avant d’être chargés dans une table. Un stage interne nommé réside dans Snowflake lui-même. Aucun bucket S3 ni stockage cloud externe n’est requis.
Ce stage est le pont entre Bright Data et votre table. Plutôt que de charger les données directement dans une table ligne par ligne, Bright Data dépose des fichiers structurés (Parquet ou JSON) dans le stage en premier. Snowflake lit ensuite ces fichiers en masse via COPY INTO, ce qui est nettement plus rapide et plus économique que les insertions ligne par ligne. Cela vous offre également un point de contrôle : vous pouvez inspecter les fichiers dans le stage, vérifier qu’ils semblent corrects et choisir quand déclencher le chargement.
CREATE STAGE IF NOT EXISTS bright_data_db.web_data.bright_data_stage
COMMENT = 'Landing zone for Bright Data dataset deliveries';Étape #4 : Créer un rôle et lui accorder les permissions appropriées
Dans Snowflake, un rôle est un ensemble de privilèges pouvant être assignés à des utilisateurs. Plutôt que d’accorder des permissions directement à un utilisateur, vous les accordez à un rôle et assignez ce rôle à l’utilisateur. Cela facilite la révocation ou la modification des accès ultérieurement sans toucher au compte utilisateur lui-même.
Ce rôle donne à Bright Data exactement l’accès dont il a besoin, et rien de plus.
CREATE ROLE IF NOT EXISTS bright_data_loader;
-- Allow the role to use the database and schema
GRANT USAGE ON DATABASE bright_data_db TO ROLE bright_data_loader;
GRANT USAGE ON SCHEMA bright_data_db.web_data TO ROLE bright_data_loader;
-- Allow the role to use and operate the warehouse
GRANT USAGE ON WAREHOUSE bright_data_wh TO ROLE bright_data_loader;
GRANT OPERATE ON WAREHOUSE bright_data_wh TO ROLE bright_data_loader;
-- Allow the role to write files into the stage
-- READ must be granted alongside WRITE; Snowflake requires it for COPY INTO ... FROM @stage
GRANT READ ON STAGE bright_data_db.web_data.bright_data_stage
TO ROLE bright_data_loader;
GRANT WRITE ON STAGE bright_data_db.web_data.bright_data_stage
TO ROLE bright_data_loader;Voici ce que fait chaque grant et pourquoi il est requis :
- USAGE sur la base de données et le schéma : Permet au rôle de voir et de naviguer vers les objets qu’ils contiennent. Sans cela, Snowflake retournera une erreur « l’objet n’existe pas » même si le rôle a des privilèges directs sur le stage.
- USAGE sur le warehouse : Permet au rôle d’exécuter des instructions SQL contre le warehouse. C’est ce qui permet à
COPY INTOde s’exécuter réellement. - OPERATE sur le warehouse : Permet au rôle de reprendre le warehouse s’il a été suspendu. Sans cela, un warehouse auto-suspendu ne redémarrera pas quand Bright Data déclenche un chargement.
- READ sur le stage : Requis pour que
COPY INTOpuisse lire les fichiers depuis le stage vers la table. - WRITE sur le stage : Requis pour que Bright Data puisse déposer des fichiers dans le stage.
Étape #5 : Créer l’utilisateur de service Bright Data
Un utilisateur de service est un compte Snowflake créé pour un système ou une application plutôt que pour une personne. L’utilisation d’un utilisateur de service dédié signifie que l’accès de Bright Data est isolé de tout compte utilisateur humain, et vous pouvez faire pivoter ou révoquer ses identifiants sans affecter qui que ce soit d’autre.
CREATE USER IF NOT EXISTS brightdata_svc
PASSWORD = 'YourStrongPasswordHere'
LOGIN_NAME = 'brightdata_svc'
DEFAULT_ROLE = bright_data_loader
DEFAULT_WAREHOUSE = bright_data_wh
DEFAULT_NAMESPACE = bright_data_db.web_data
MUST_CHANGE_PASSWORD = FALSE
DISABLED = FALSE
COMMENT = 'Service user for Bright Data dataset delivery';
GRANT ROLE bright_data_loader TO USER brightdata_svc;MUST_CHANGE_PASSWORD = FALSE empêche Snowflake de demander une réinitialisation du mot de passe à la première connexion, ce qui casserait une connexion automatisée. DEFAULT_ROLE, DEFAULT_WAREHOUSE et DEFAULT_NAMESPACE garantissent que l’utilisateur de service se connecte toujours avec le bon contexte, quel que soit le mode d’initiation de la session. La dernière ligne assigne le rôle bright_data_loader à cet utilisateur, lui donnant exactement les privilèges définis à l’étape #4.
Stockez le nom d’utilisateur et le mot de passe de manière sécurisée. Vous les collerez dans le panneau de contrôle Bright Data dans la section suivante.
Étape #6 : Ajouter les IPs de Bright Data à la liste blanche (si vous utilisez une politique réseau)
Si votre compte Snowflake applique une politique réseau, les serveurs de livraison de Bright Data doivent être ajoutés à la liste autorisée. Les IPs ci-dessous étaient à jour au moment de la rédaction. Vérifiez les dernières plages auprès du support Bright Data ou de leur documentation avant d’appliquer, car les IPs statiques peuvent changer :
ALTER NETWORK POLICY your_policy_name
SET ALLOWED_IP_LIST = (
-- paste your existing allowed IPs here,
'35.169.71.210',
'34.233.211.38',
'44.194.183.74',
'54.243.177.151'
);Si votre compte n’a pas de politique réseau active, ignorez cette étape.
Étape #7 : Créer la table cible
Ce tutoriel utilise les données de livres Goodreads comme exemple. Le schéma ci-dessous correspond directement aux noms de champs que le jeu de données Goodreads Books de Bright Data livre en JSON :
CREATE TABLE IF NOT EXISTS bright_data_db.web_data.goodreads_books (
id VARCHAR, -- Goodreads book ID
name VARCHAR, -- book title
url VARCHAR,
author VARIANT, -- array: [{name, num_books, num_followers}]
star_rating FLOAT, -- average rating 1-5
num_ratings INT, -- total number of ratings
num_reviews VARCHAR, -- total reviews (may be formatted, e.g. "1,234")
summary VARCHAR, -- book description/blurb
genres VARIANT, -- array of genre strings
first_published VARCHAR, -- publication date as text
about_author VARIANT, -- object: {name, num_books, num_followers}
community_reviews VARIANT -- object: {5_stars, 4_stars, ...} with counts and percentages
);VARIANT est le type semi-structuré de Snowflake. Il stocke les tableaux et les objets imbriqués tels quels et vous permet de les interroger avec la notation par points et la syntaxe entre crochets (author[0]:name, community_reviews['5_stars']:reviews_num). Cela évite d’aplatir les champs imbriqués complexes au moment du chargement. Vous pouvez le faire ultérieurement avec une vue ou un LATERAL FLATTEN une fois que vous connaissez les sous-champs dont vous avez besoin.
Quelques décisions de champs à comprendre :
authoren VARIANT : Chaque livre peut avoir plusieurs auteurs. Le champ arrive sous forme de tableau d’objets. Le stocker en VARIANT préserve toutes les données d’auteur sans nécessiter une table de jointure séparée.genresen VARIANT : Le genre est également un tableau. Un livre peut appartenir à plusieurs genres. Aplatissez-le avecLATERAL FLATTEN(INPUT => genres)lorsque vous devez interroger par genre.num_reviewsen VARCHAR : Le dictionnaire de données de Bright Data marque ce champ comme Texte plutôt que Nombre, ce qui signifie qu’il peut arriver formaté (par exemple"1 234"plutôt que1234). Convertissez-le au moment de la requête avecTO_NUMBER(REPLACE(num_reviews, ',', ''))si vous devez l’agréger.community_reviewsen VARIANT : Contient une répartition des notes par niveau d’étoiles, chacune avec un nombre et un pourcentage. Stockez en VARIANT et interrogez les niveaux d’étoiles spécifiques selon les besoins.
Remarque : Si vous choisissez un autre jeu de données sur le marketplace (entreprises LinkedIn, offres d’emploi, produits Amazon, etc.), adaptez le schéma à sa liste de champs. Bright Data fournit une référence complète des champs pour chaque jeu de données sur sa page dans le panneau de contrôle.
Excellent ! Votre environnement Snowflake est maintenant prêt à recevoir des données de Bright Data.
Configuration de Bright Data pour livrer vers Snowflake
Avec le côté Snowflake en place, configurons Bright Data pour y pousser des données.
Prérequis
Pour suivre cette section, vous devez disposer de :
- Un compte Bright Data avec un abonnement actif ou un essai.
- Les détails de connexion Snowflake de la section précédente : identifiant de compte, nom d’utilisateur, mot de passe, noms de la base de données, du schéma, du stage et du warehouse.
Étape #1 : Choisir un jeu de données
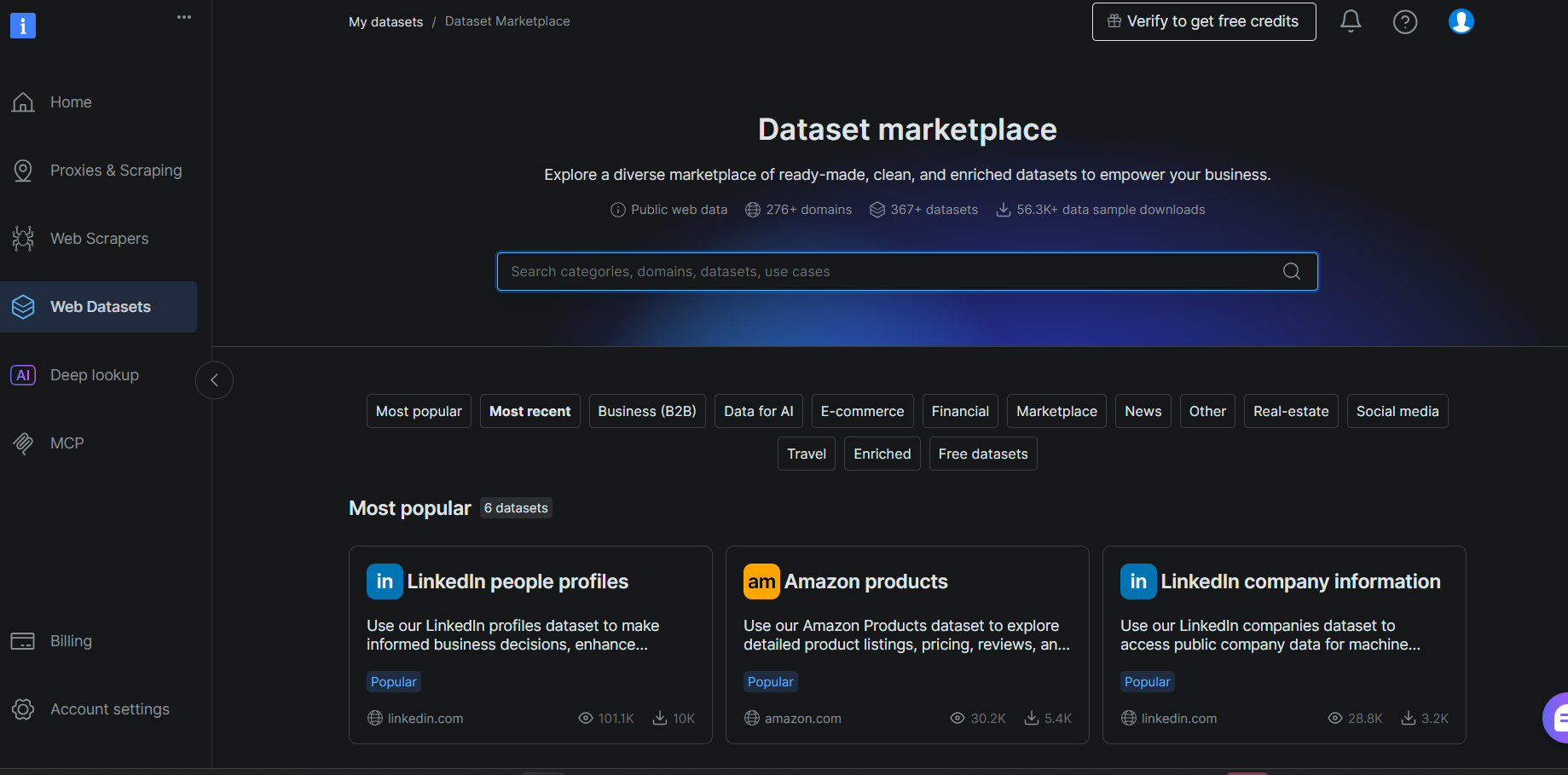
Connectez-vous à votre compte Bright Data et naviguez vers Web Datasets > Dataset Marketplace. Recherchez Goodreads et sélectionnez le jeu de données Goodreads Books dans les résultats.
Sur la page du jeu de données, consultez la liste des champs dans le panneau de gauche. Notez comment chaque champ correspond directement à une colonne de la table que vous avez créée à l’étape #7. Cela confirme que votre schéma est correct avant l’arrivée d’une seule ligne.
Étape #2 : Configurer Snowflake comme destination de livraison
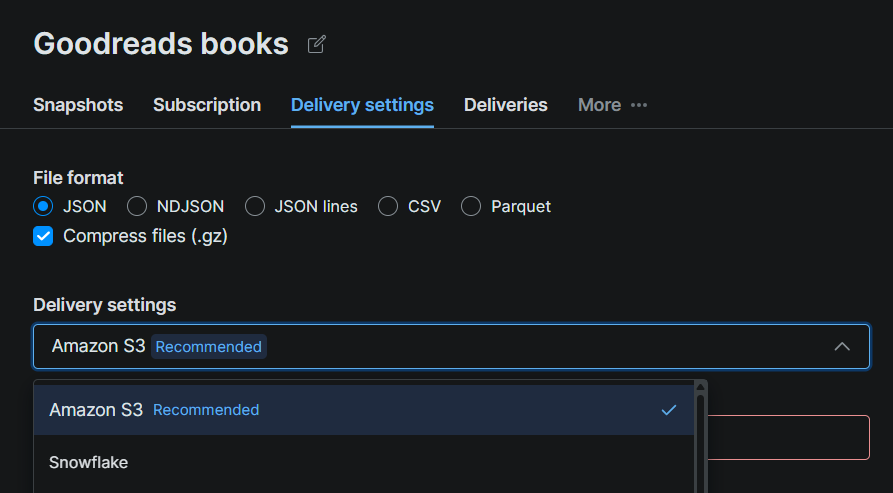
Cliquez sur l’onglet Delivery Settings sur la page du jeu de données et sélectionnez Snowflake comme destination. Remplissez le formulaire de connexion avec les détails de votre configuration Snowflake :
| Champ | Valeur |
|---|---|
| Identifiant de compte | Votre URL de compte Snowflake (ex. xy12345.us-east-1) |
| Base de données | bright_data_db |
| Schéma | web_data |
| Stage | bright_data_stage |
| Warehouse | bright_data_wh |
| Rôle | bright_data_loader |
| Utilisateur | brightdata_svc |
| Mot de passe | Le mot de passe défini à l’étape #5 |
Les trois champs sous le formulaire de connexion sont optionnels et peuvent être laissés à leurs valeurs par défaut pour ce tutoriel :
- Nom de fichier du jeu de données : Un préfixe personnalisé pour les fichiers que Bright Data stage. Laissez vide pour utiliser le nommage par défaut.
- Taille des lots (nombre d’enregistrements) : Le nombre d’enregistrements que Bright Data regroupe dans chaque fichier stagé. La valeur par défaut convient à la plupart des charges de travail.
- Regrouper les lots dans un seul fichier (.tar) : Combine tous les lots dans une seule archive avant le staging. Laissez décoché sauf si votre pipeline nécessite spécifiquement un seul fichier par livraison.
Cliquez sur Test Snowflake. Une confirmation verte signifie que Bright Data peut s’authentifier et écrire dans votre stage. Une fois le test réussi, cliquez sur Save.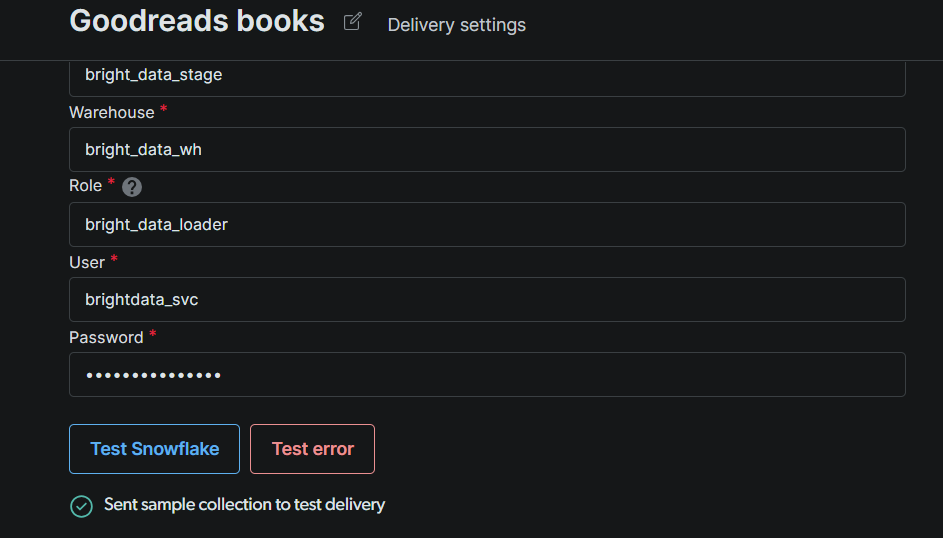
Remarque : Si le test échoue, vérifiez trois choses dans l’ordre : (1) le format de l’identifiant de compte (Snowflake attend orgname-accountname ou le format hérité accountid.region.cloud) ; (2) si l’utilisateur de service possède tous les grants de l’étape #4, y compris l’assignation du rôle ; (3) si les IPs de Bright Data sont sur liste blanche si votre compte a une politique réseau active.
Étape #3 : Demander un snapshot
Sur la page du jeu de données, cliquez sur l’onglet Deliveries. Puis cliquez sur Add delivery + dans le coin supérieur droit. Cela ouvre un panneau de configuration de livraison où vous sélectionnez votre destination (Snowflake), choisissez un snapshot ou une plage de dates à livrer, et confirmez.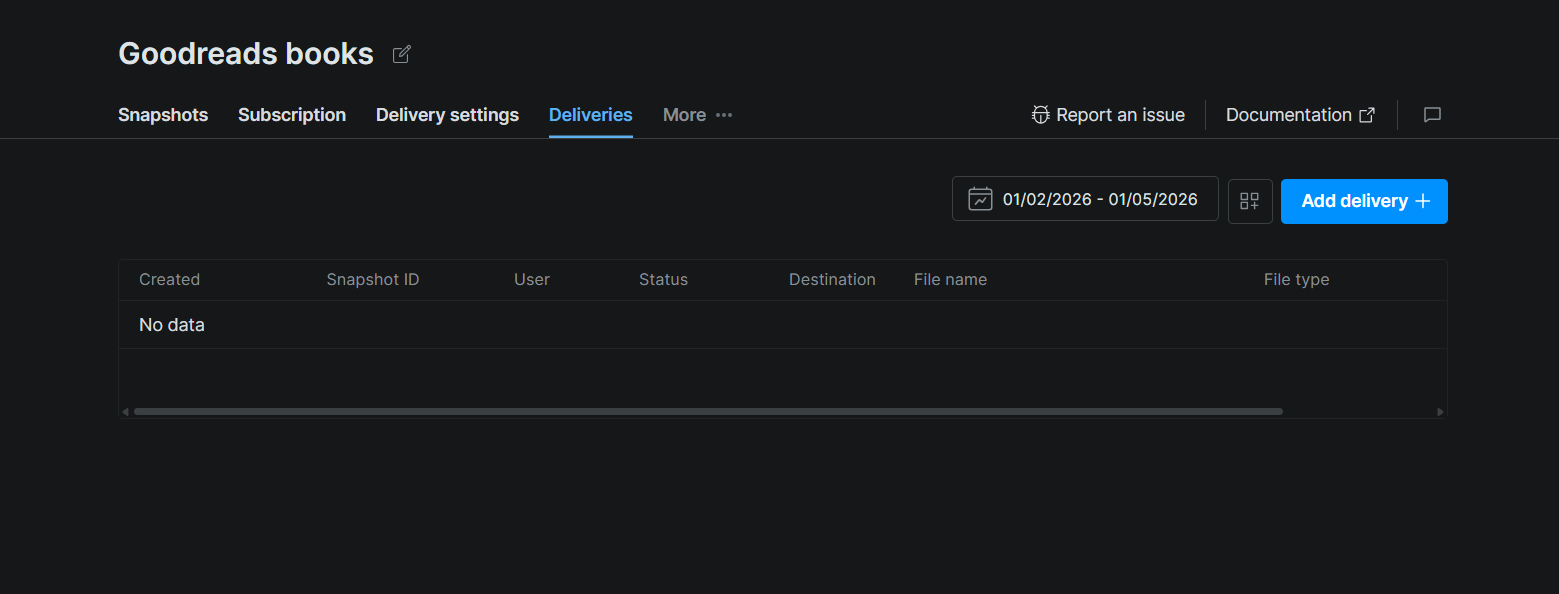
Une fois soumise, la livraison apparaît dans le tableau avec des colonnes pour l’ID du snapshot, le statut, la destination, le nom du fichier et le type de fichier. Le statut passera de en attente à terminé lorsque Bright Data aura fini de pousser les fichiers vers votre stage.
Pour déclencher des livraisons de manière programmatique, l’API Marketplace Dataset utilise un flux en deux étapes : appelez d’abord l’API Filter pour créer un snapshot filtré, puis appelez Deliver Snapshot pour le pousser vers votre stage Snowflake.
Étape 1 : Créer un snapshot filtré :
curl --request POST
--url "https://api.brightdata.com/datasets/filter"
--header "Authorization: Bearer YOUR_API_TOKEN"
--header "Content-Type: application/json"
--data '{
"dataset_id": "YOUR_DATASET_ID",
"filter": {
"operator": "and",
"filters": [
{"name": "star_rating", "operator": ">", "value": "4"},
{"name": "num_ratings", "operator": ">", "value": "1000"}
]
}
}'La réponse contient un snapshot_id. Transmettez-le à l’appel suivant.
Étape 2 : Livrer le snapshot vers votre stage Snowflake :
curl --request POST
--url "https://api.brightdata.com/datasets/snapshots/YOUR_SNAPSHOT_ID/deliver"
--header "Authorization: Bearer YOUR_API_TOKEN"
--header "Content-Type: application/json"
--data '{
"destination": "snowflake"
}'Bright Data utilisera par défaut le format configuré pour votre jeu de données. Si vous souhaitez le spécifier explicitement, ajoutez "format": "parquet" ou "format": "ndjson" au corps de la requête. Quel que soit le format qui arrive dans le stage, c’est celui que vous passez à FILE_FORMAT dans COPY INTO.
Interrogez GET /datasets/snapshots/YOUR_SNAPSHOT_ID pour vérifier le statut de livraison, ou surveillez-le dans l’onglet Deliveries du panneau de contrôle. Quand la colonne Status affiche terminé, vos fichiers sont dans le stage et prêts à être chargés. Parfait !
Lorsque la livraison se termine, vous recevrez également un e-mail avec un lien vers la page du snapshot dans le panneau de contrôle. Là, vous pouvez prévisualiser les 30 premiers enregistrements, vérifier le nombre total d’enregistrements et télécharger un rapport de synthèse des coûts. À 2,50 $ pour 1 000 enregistrements, le rapport vous indique exactement combien d’enregistrements sont arrivés et leur coût. Parfait !
Chargement des données dans Snowflake
Le travail de Bright Data se termine quand les fichiers atterrissent dans votre stage interne. Les charger dans la table est de votre responsabilité, et cela ne prend qu’une seule commande SQL. Cette séparation mérite d’être comprise : elle signifie que vous contrôlez quand le chargement s’exécute, quelle gestion des erreurs s’applique et à quelle fréquence vous actualisez la table.
Prérequis
Pour suivre cette section, vous devez avoir :
- Complété les sections de configuration Snowflake et de configuration Bright Data ci-dessus.
- Confirmé qu’une livraison de snapshot est terminée (via e-mail ou la page du snapshot dans le panneau de contrôle Bright Data).
Étape #1 : Confirmer que les fichiers sont arrivés dans le stage
Exécutez ceci avant tout le reste :
LIST @bright_data_db.web_data.bright_data_stage;Vous devriez voir un ou plusieurs fichiers listés avec leurs tailles et horodatages. Si le stage est vide, le snapshot n’a pas encore fini d’être livré. Vérifiez son statut sur la page du snapshot dans le panneau de contrôle Bright Data.
Notez l’extension de fichier dans les résultats. Le format que Bright Data utilise pour la livraison détermine le FILE_FORMAT que vous passez à COPY INTO à l’étape suivante. Pour les snapshots déclenchés via l’interface, Bright Data livre généralement en NDJSON sauf si vous avez spécifié autrement lors de la configuration de la livraison. Pour les snapshots déclenchés via l’API avec l’endpoint deliver-snapshot, le format est celui que vous avez passé dans le corps de la requête. Si vous voyez des fichiers .parquet, utilisez TYPE = 'PARQUET'. Si vous voyez des fichiers .json ou .ndjson, utilisez TYPE = 'JSON'.
Étape #2 : Charger les fichiers dans la table
Pour les fichiers Parquet :
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE
ON_ERROR = 'CONTINUE';Pour les fichiers JSON ou NDJSON :
COPY INTO bright_data_db.web_data.goodreads_books (
id, name, url, author, star_rating, num_ratings,
num_reviews, summary, genres, first_published,
about_author, community_reviews
)
FROM (
SELECT
$1:id::VARCHAR,
$1:name::VARCHAR,
$1:url::VARCHAR,
$1:author::VARIANT,
$1:star_rating::FLOAT,
$1:num_ratings::INT,
$1:num_reviews::VARCHAR,
$1:summary::VARCHAR,
$1:genres::VARIANT,
$1:first_published::VARCHAR,
$1:about_author::VARIANT,
$1:community_reviews::VARIANT
FROM @bright_data_db.web_data.bright_data_stage
)
FILE_FORMAT = (TYPE = 'JSON' STRIP_OUTER_ARRAY = TRUE)
ON_ERROR = 'CONTINUE';MATCH_BY_COLUMN_NAME (Parquet uniquement) mappe les noms de colonnes automatiquement, l’ordre n’a donc pas d’importance. ON_ERROR = CONTINUE ignore les lignes malformées plutôt que d’abandonner le chargement entier.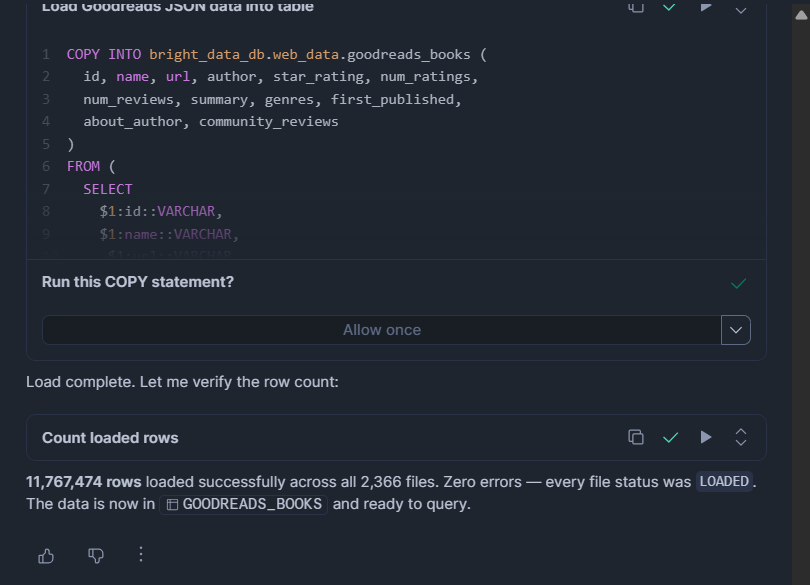
Étape #3 : Vérifier le chargement
-- Count the loaded rows
SELECT COUNT(*) FROM bright_data_db.web_data.goodreads_books;
-- Check for skipped rows or errors in the last hour
SELECT *
FROM TABLE(BRIGHT_DATA_DB.INFORMATION_SCHEMA.COPY_HISTORY(
TABLE_NAME => 'BRIGHT_DATA_DB.WEB_DATA.GOODREADS_BOOKS',
START_TIME => DATEADD(HOURS, -1, CURRENT_TIMESTAMP())
));COPY_HISTORY affiche les lignes chargées, les lignes ignorées, les noms de fichiers traités et le message d’erreur exact pour toute ligne ayant échoué. Consultez-le après chaque chargement, surtout la première fois.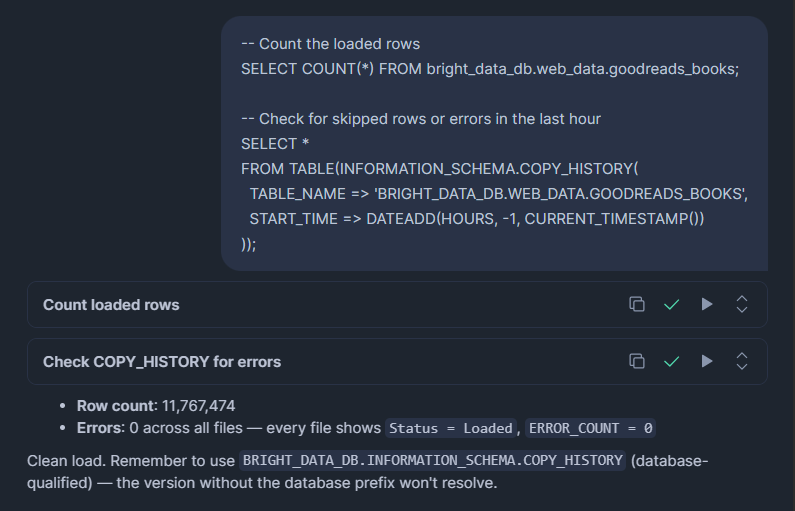
Interrogation des données
Avec les données de livres Goodreads dans Snowflake, la valeur réside dans la compréhension des tendances de lecture, des performances des auteurs et de la popularité des genres à grande échelle sur des millions de titres. Les requêtes ci-dessous reflètent directement ces cas d’usage.
Inspecter les données brutes
Avant d’écrire des requêtes analytiques, vérifiez que les données semblent conformes aux attentes :
SELECT id, name, url, star_rating, num_ratings, first_published
FROM bright_data_db.web_data.goodreads_books
LIMIT 10;RÉSULTAT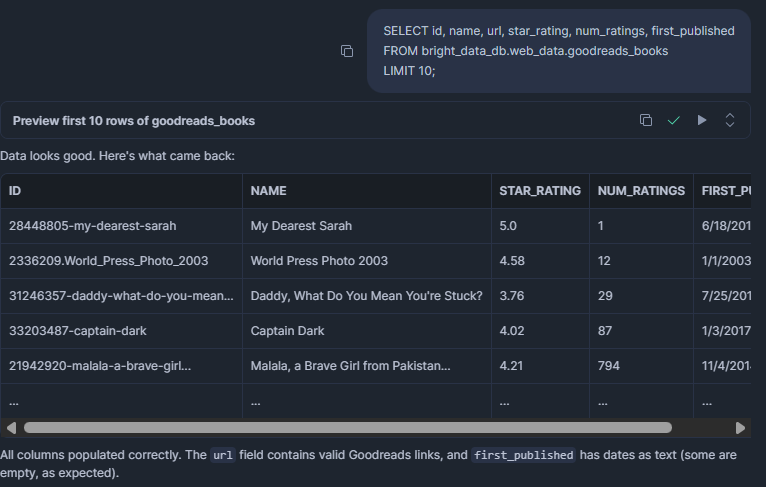
Quels livres ont la validation lecteur la plus solide ?
Un star_rating élevé seul ne suffit pas. Un livre avec 4,8 étoiles de 12 personnes ne vous dit pas grand-chose. Cette requête fait ressortir les livres qui sont à la fois bien notés et largement lus, ce qui est la combinaison qui signale qu’un livre a une réelle longévité.
SELECT
name,
author[0]:name::VARCHAR AS primary_author,
star_rating,
num_ratings,
first_published
FROM bright_data_db.web_data.goodreads_books
WHERE num_ratings > 10000
AND star_rating >= 4.5
ORDER BY num_ratings DESC
LIMIT 20;Résultat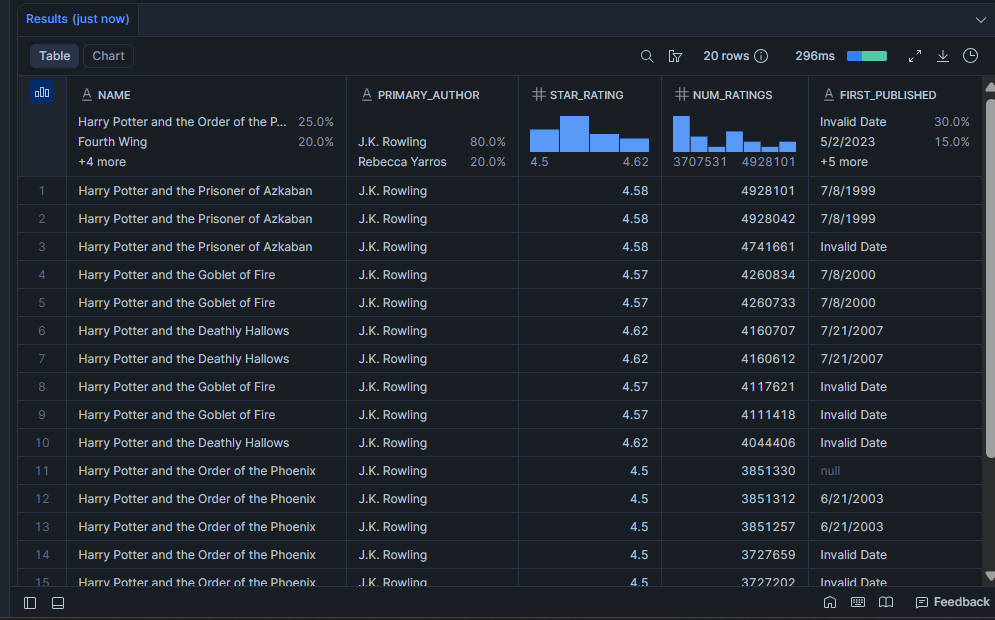
Quels genres ont le plus de titres et la note moyenne la plus élevée ?
Utile pour comprendre où la demande des lecteurs est concentrée. Un genre avec un grand nombre de titres mais une note moyenne faible peut être saturé d’entrées de faible qualité, ce qui représente une opportunité pour les éditeurs ou les moteurs de recommandation.
SELECT
g.value::VARCHAR AS genre,
COUNT(*) AS book_count,
ROUND(AVG(star_rating), 2) AS avg_rating,
SUM(num_ratings) AS total_ratings
FROM bright_data_db.web_data.goodreads_books,
LATERAL FLATTEN(INPUT => genres) g
WHERE g.value IS NOT NULL
GROUP BY genre
ORDER BY total_ratings DESC
LIMIT 15;Résultat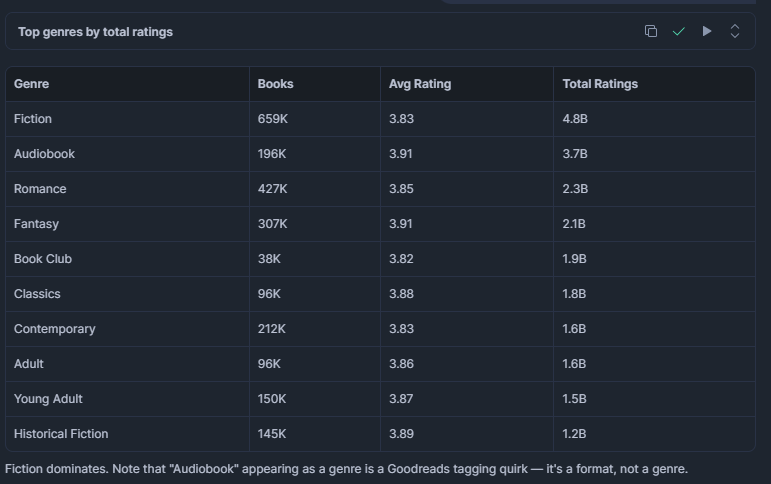
Qui sont les auteurs les plus suivis dans le jeu de données ?
Le nombre de followers d’un auteur est un indicateur de son audience sur la plateforme. Le combiner avec la note moyenne des livres montre si les auteurs les plus suivis sont aussi les plus respectés, ou si le nombre de followers et la qualité divergent.
about_author est un objet plat sur chaque enregistrement de livre, ce qui le rend facile à interroger sans indexation de tableau. Notez que cela reflète l’auteur tel que décrit sur la page de ce livre spécifique, ce qui peut légèrement différer de author (le tableau des auteurs crédités).
SELECT
about_author:name::VARCHAR AS author_name,
about_author:num_books::INT AS books_published,
about_author:num_followers::VARCHAR AS followers,
ROUND(AVG(star_rating), 2) AS avg_book_rating,
SUM(num_ratings) AS total_ratings_received
FROM bright_data_db.web_data.goodreads_books
WHERE about_author:name IS NOT NULL
GROUP BY author_name, books_published, followers
ORDER BY followers DESC NULLS LAST
LIMIT 20;Résultat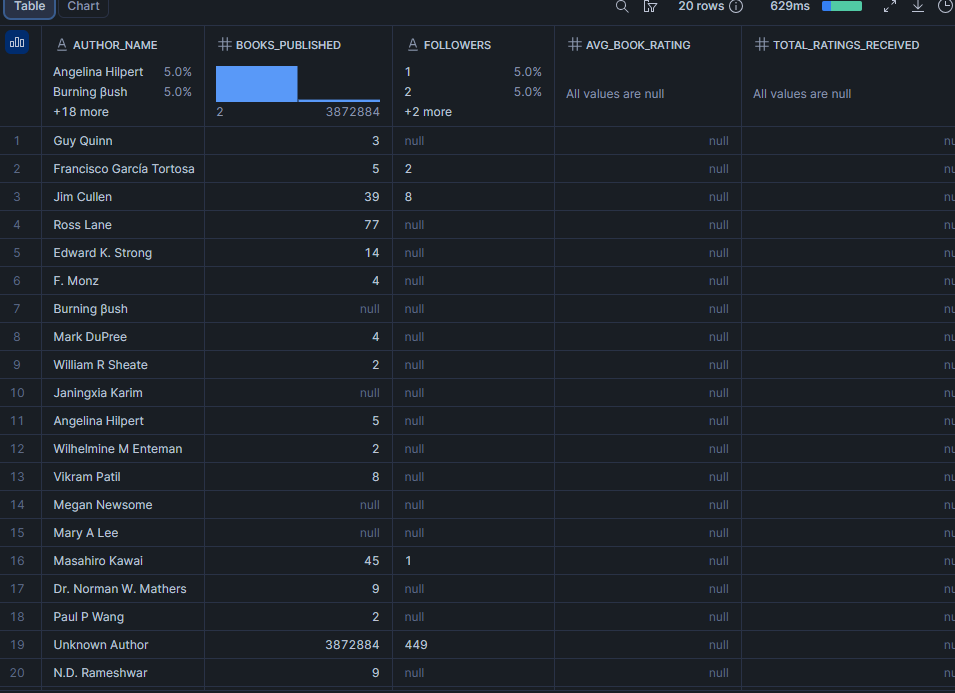
Remarque : followers est trié comme du texte car le champ source est VARCHAR (il peut contenir des valeurs formatées comme "12,3k"). Si votre jeu de données livre un entier propre, convertissez-le avec TO_NUMBER(followers) et triez numériquement.
Quelle est la polarisation d’un livre ? Extraire la répartition des étoiles des avis communautaires
Un livre avec une note moyenne élevée mais une grande part d’avis 1 étoile peut être controversé plutôt qu’universellement apprécié. Cette requête extrait la distribution des notes pour n’importe quel livre spécifique.
SELECT
name,
star_rating,
num_reviews,
community_reviews['5_stars']:reviews_num::INT AS five_star_count,
community_reviews['4_stars']:reviews_num::INT AS four_star_count,
community_reviews['3_stars']:reviews_num::INT AS three_star_count,
community_reviews['2_stars']:reviews_num::INT AS two_star_count,
community_reviews['1_stars']:reviews_num::INT AS one_star_count,
community_reviews['1_stars']:reviews_percentage::FLOAT AS one_star_pct
FROM bright_data_db.web_data.goodreads_books
WHERE id = 'YOUR_BOOK_ID'; -- substitute the Goodreads book IDnum_reviews donne le nombre total d’avis écrits en parallèle de la répartition par étoiles, utile pour distinguer les livres qui attirent de longs avis écrits de ceux qui collectent des notes silencieuses.
Et voilà ! Vous disposez maintenant d’un pipeline fonctionnel qui extrait des données web structurées de Bright Data et les rend interrogeables dans Snowflake.
Automatisation des actualisations
Pour une utilisation en production, vous voudrez que les nouveaux snapshots se chargent automatiquement plutôt que d’exécuter manuellement COPY INTO à chaque fois. Commencez par l’option A. Ne passez à l’option B que si vous avez besoin que la table se mette à jour en quelques secondes après la fin de la livraison.
Option A : Snowflake Task pour l’ingestion pilotée par planification
Une Snowflake Task exécute COPY INTO selon un calendrier cron et ne nécessite aucune infrastructure supplémentaire. Définissez un calendrier de livraison correspondant dans Bright Data afin que les fichiers soient prêts dans le stage lorsque la tâche se déclenche.
CREATE TASK IF NOT EXISTS bright_data_db.web_data.load_goodreads_task
WAREHOUSE = bright_data_wh
SCHEDULE = 'USING CRON 0 6 * * * UTC'
AS
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE
ON_ERROR = 'CONTINUE';
ALTER TASK bright_data_db.web_data.load_goodreads_task RESUME;Conseil pro : Lors de votre première exécution automatisée, vérifiez COPY_HISTORY après le déclenchement de la tâche pour confirmer que le timing du calendrier est aligné avec la fin de la livraison par Bright Data. Une tâche qui s’exécute avant la fin de la livraison trouvera un stage vide et chargera zéro ligne.
Option B : API REST Snowpipe pour l’ingestion événementielle à faible latence
Snowpipe charge les fichiers depuis le stage en quelques secondes après leur arrivée, déclenché de manière programmatique via son endpoint REST insertFiles. Utilisez ceci uniquement si votre cas d’usage nécessite une fraîcheur quasi-temps réel. Cela ajoute une complexité de configuration significative par rapport à l’option A.
La configuration comporte deux parties. Premièrement, créez le pipe :
CREATE PIPE IF NOT EXISTS bright_data_db.web_data.goodreads_pipe
AS
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;Notez l’absence de AUTO_INGEST = TRUE. Pour les stages internes nommés, l’auto-ingestion via messagerie cloud n’est disponible que pour les comptes Snowflake hébergés sur AWS et est actuellement une fonctionnalité en préversion. L’approche API REST fonctionne sur toutes les plateformes cloud.
Deuxièmement, connectez votre gestionnaire de webhook pour lister les fichiers stagés et les soumettre à Snowpipe lorsqu’un snapshot est prêt :
import snowflake.connector
from snowflake.ingest import SimpleIngestManager, StagedFile
SNOWFLAKE_ACCOUNT = "your-account-identifier"
SNOWFLAKE_USER = "brightdata_svc"
SNOWFLAKE_PASSWORD = "YourStrongPasswordHere"
PIPE_NAME = "bright_data_db.web_data.goodreads_pipe"
STAGE_NAME = "bright_data_db.web_data.bright_data_stage"
def handle_brightdata_webhook(snapshot_id: str):
# Step 1: list files that arrived in the stage
conn = snowflake.connector.connect(
account=SNOWFLAKE_ACCOUNT,
user=SNOWFLAKE_USER,
password=SNOWFLAKE_PASSWORD,
)
cursor = conn.cursor()
cursor.execute(f"LIST @{STAGE_NAME}")
staged_files = [StagedFile(row[0], None) for row in cursor.fetchall()]
cursor.close()
conn.close()
if not staged_files:
print(f"No files found in stage for snapshot {snapshot_id}")
return
# Step 2: tell Snowpipe to load them
ingest_manager = SimpleIngestManager(
account=SNOWFLAKE_ACCOUNT,
host=f"{SNOWFLAKE_ACCOUNT}.snowflakecomputing.com",
user=SNOWFLAKE_USER,
pipe=PIPE_NAME,
private_key=open("rsa_key.p8", "rb").read(), # Snowpipe REST requires key-pair auth
)
response = ingest_manager.ingest_files(staged_files)
print(f"Snowpipe response: {response}")Remarque : L’API REST Snowpipe nécessite une authentification par paire de clés, pas une authentification par mot de passe. Générez une paire de clés RSA, assignez la clé publique à brightdata_svc dans Snowflake (ALTER USER brightdata_svc SET RSA_PUBLIC_KEY='...'), et passez le chemin du fichier de clé privée ci-dessus. Installez le SDK avec pip install snowflake-ingest.
Conclusion
Dans cet article, vous avez appris à construire un pipeline complet d’ingestion de données web de Bright Data vers Snowflake. Le flux de travail :
- Prépare Snowflake avec une base de données, un stage, un rôle et un utilisateur de service dédiés contre lesquels Bright Data s’authentifie directement.
- Configure un jeu de données Bright Data avec Snowflake comme destination de livraison, sans stockage intermédiaire requis.
- Déclenche un snapshot via l’onglet Deliveries du panneau de contrôle ou l’API Dataset, puis surveille le statut de livraison jusqu’à ce que les fichiers arrivent dans le stage.
- Charge les fichiers stagés dans une table Snowflake structurée avec une seule commande
COPY INTOet interroge les données avec du SQL standard.
La même configuration fonctionne pour n’importe quel jeu de données du marketplace Bright Data : produits Amazon, entreprises LinkedIn, offres d’emploi, annonces hôtelières, enregistrements Crunchbase, et bien plus. Chacun suit le même schéma de livraison ; seul le schéma de table change.
Créez un compte Bright Data gratuit dès aujourd’hui et commencez à intégrer des données web en direct dans votre environnement Snowflake !





