À la fin de ce tutoriel, vous comprendrez :
- Pourquoi PyTorch est un excellent choix pour créer un flux de travail d’apprentissage automatique multimodal.
- La nécessité d’une source fiable de données provenant de Jeux de données contenant plusieurs millions d’enregistrements, tels que ceux fournis par Bright Data.
- Comment tirer parti des Jeux de données Bright Data dans PyTorch pour affiner un modèle d’apprentissage automatique pour la classification d’images de produits dans un processus multimodal.
C’est parti !
Pourquoi utiliser PyTorch pour l’apprentissage automatique multimodal
La valeur des données réside dans les informations qu’elles permettent d’obtenir. Pour les entreprises, l’exploitation des données avec la bonne approche peut permettre de prendre des décisions plus éclairées, d’affiner les stratégies et d’améliorer les résultats, tels que la fidélisation des clients et les performances marketing.
L’apprentissage automatique moderne vous permet de traiter non seulement des données structurées telles que les notes ou les chiffres de vente, mais aussi des données non structurées telles que des images, du texte et même des vidéos. Cela ouvre la voie à des informations multimodales. Par exemple, la combinaison d’images d’avis avec du texte peut fournir une compréhension plus riche de ce qui motive l’engagement des clients.
Cet article est basé sur PyTorch, un framework d’apprentissage automatique Python largement utilisé pour la création et l’entraînement de réseaux neuronaux profonds. La bibliothèque prend en charge une longue liste de tâches, notamment la classification d’images, le traitement du langage naturel et les workflows combinés où plusieurs types de données sont analysés ensemble.
Voici quelques applications courantes de PyTorch :
- Évaluation de la qualité des images des produits: déterminer automatiquement si les images sont visuellement attrayantes et susceptibles d’intéresser les clients.
- Analyse du sentiment des clients: extraire des informations à partir des avis textuels pour comprendre les opinions et la satisfaction des utilisateurs.
- Création de systèmes de recommandation: combiner des caractéristiques textuelles et visuelles pour générer des suggestions de produits plus précises et personnalisées.
- Modélisation prédictive avec des données multimodales: utiliser à la fois des informations visuelles et textuelles pour prévoir les tendances, les ventes ou le comportement des clients.
Comment obtenir des données multimodales de haute qualité pour votre entreprise
Quel que soit le type d’application d’apprentissage automatique ou d’IA que vous développez, vous devez garder à l’esprit que l’efficacité de ces systèmes dépend de la qualité des données sur lesquelles ils sont entraînés.
Dans les applications multimodales, l’approvisionnement en données peut être particulièrement difficile, car il nécessite la collecte d’informations sous forme textuelle et visuelle. C’est là qu’interviennent les fournisseurs de données fiables, tels que Bright Data.
Bright Data propose une suite de solutions prêtes à l’emploi pour l’IA et l’apprentissage automatique, destinées aux entreprises de toutes tailles, des start-ups aux grandes entreprises :
- API Web Scraper: fournit un accès programmatique à des données structurées provenant de centaines de sites web populaires, permettant la collecte automatisée de données web récentes à grande échelle.
- Marché des jeux de données: propose des jeux de données multimodaux prêtes à l’emploi contenant des milliards d’entrées, notamment des images, du texte et des champs structurés.
- Services d’acquisition de données gérés: solutions entièrement gérées et adaptées aux entreprises qui permettent aux équipes d’acquérir et de conserver des données sans avoir à créer ou à maintenir des pipelines de scraping.
- Services d’annotation de données: solutions d’annotation évolutives et personnalisables pour les tâches de traitement du langage naturel, de vision par ordinateur et de reconnaissance vocale.
Ces solutions permettent aux chercheurs, aux PME et aux grandes entreprises de collecter et d’intégrer efficacement des données web publiques. Elles peuvent être exploitées pour alimenter des workflows d’apprentissage automatique multimodal, former des modèles d’IA sophistiqués, développer des agents intelligents et créer des systèmes d’analyse et de veille économique.
Comment créer un pipeline d’analyse d’apprentissage automatique multimodal à l’aide de PyTorch avec un jeu de données Bright Data
Dans cette section guidée, vous apprendrez à former un modèle d’apprentissage automatique sur l’ensemble de données «Produits Amazon »de Bright Data, qui contient à la fois des données textuelles et des données image.
Nous partons du principe que vous vendez des produits en ligne et que vous comprenez l’importance de les présenter avec des images appropriées. L’objectif est d’utiliser PyTorch pour former un modèle d’apprentissage automatique sur des images de produits e-commerce ainsi que leurs informations de notation. Ce modèle se chargera ensuite d’évaluer automatiquement si une image de produit est « bonne » ou « mauvaise ».
Grâce à ce workflow ML multimodal, votre entreprise peut évaluer de manière programmatique la probabilité que vos images de produits attirent les clients et suscitent leur intérêt.
Remarque: il ne s’agit que d’un exemple. En utilisant PyTorch avec les Jeux de données et les flux de données de Bright Data, vous pouvez couvrir de nombreux autres cas d’utilisation et scénarios.
Suivez les instructions ci-dessous !
Prérequis
Pour suivre cette section, assurez-vous de disposer des éléments suivants :
- Python 3.9 ou une version supérieure installée localement.
- Un compte Bright Data.
De plus, une bonne connaissance du modèle ResNet-18 et du fonctionnement du réglage fin vous sera utile pour comprendre pleinement la logique de classification d’images multimodale PyTorch.
Étape n° 1 : créer un projet JupyterLab
Lorsque vous travaillez avec des données multimodales, il est utile de visualiser vos Jeux de données. C’est pourquoi JupyterLab est un excellent choix comme environnement de développement. Ensuite, une fois votre flux de travail développé, le code peut être facilement converti en un pipeline d’apprentissage automatique prêt à être mis en production.
Commencez par créer un dossier dédié au projet et accédez-y :
mkdir pytorch-brightdata-product-image-analysis
cd pytorch-brightdata-product-image-analysisEnsuite, initialisez un environnement virtuel à l’intérieur :
python -m venv .venvSous macOS/Linux, activez l’environnement virtuel avec :
source .venv/bin/activateOu, sous Windows, exécutez :
.venvScriptsactivateUne fois l’environnement virtuel activé, installez JupyterLab via le paquet jupyterlab:
pip install jupyterlabLancez JupyterLab avec :
jupyter labL’interface JupyterLab s’ouvrira à l’adresse http://localhost:8888/lab/ dans votre navigateur. Créez un nouveau notebook en cliquant sur le bouton « Python 3 (ipykernel) » dans la section « Notebook » :
Vous verrez apparaître un fichier Untitled.ipynb:
Donnez à votre nouveau notebook un nom tel que « Bright Data + PyTorch » et enregistrez-le.
C’est terminé ! Vous disposez désormais d’un environnement Python entièrement configuré, prêt à développer des workflows d’apprentissage automatique multimodal via PyTorch.
Étape n° 2 : installer et importer les dépendances requises
Dans votre notebook, ajoutez une nouvelle cellule de code avec la commande pip suivante
!pip install pillow tqdm requests scikit-learn torch torchvision pandasExécutez ce bloc pour installer toutes les bibliothèques nécessaires :
pillow: pour charger et traiter les images.tqdm: pour afficher les barres de progression des boucles, ce qui est utile pour suivre le chargement et l’entraînement des données.requests: pour télécharger des images à partir d’URL via des requêtes HTTP.scikit-learn: fournit des outils tels quetrain_test_splitpour diviser les Jeux de données.torch: la bibliothèque PyTorch de base pour la création et l’entraînement de modèles d’apprentissage automatique.torchvision: fournit des jeux de données, des modèles pré-entraînés et des transformations d’images.pandas: traite les données structurées telles que les fichiers CSV et facilite la manipulation des données.
Dans une autre cellule de code, importez tous les modules requis :
import os
import io
import json
import requests
from PIL import Image, ImageStat
from tqdm import tqdm
from sklearn.model_selection import train_test_split
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, models
from tqdm import tqdm
from PIL import ImageParfait ! Grâce à ces deux cellules, votre notebook est désormais prêt à traiter les jeux de données multimodales Bright Data et à effectuer le traitement d’images et de textes à l’aide de PyTorch.
Étape n° 3 : télécharger l’ensemble de données Bright Data
Maintenant que votre notebook est configuré pour le développement PyTorch, il est temps d’obtenir l’élément le plus important de ce flux de travail : les données d’entrée !
Pour ce tutoriel, nous utiliserons l’ensemble de données« Produits Amazon », l’un des nombreux jeux de données de commerce électronique disponibles sur Bright Data. Au moment de la rédaction de cet article, cet ensemble de données contient plus de 311 millions d’entrées, chacune comportant 87 champs de données. Pour chaque produit, ces champs répertorient les URL des images, les notes des avis, l’ASIN du produit et bien d’autres informations.
Remarque: vous pouvez collecter des données structurées récentes à partir de plateformes telles qu’Amazon, eBay, Walmart et bien d’autres à l’aide du Scraper e-commerce de Bright Data.
Pour commencer, si vous n’avez pas encore de compte Bright Data, créez-en un. Sinon, connectez-vous et rendez-vous sur la page «Dataset marketplace »(Marché des jeux de données) de votre compte :
Sélectionnez l’ensemble de données « Amazon products » parmi les plus populaires :
Vous accéderez à la page des Jeux de données: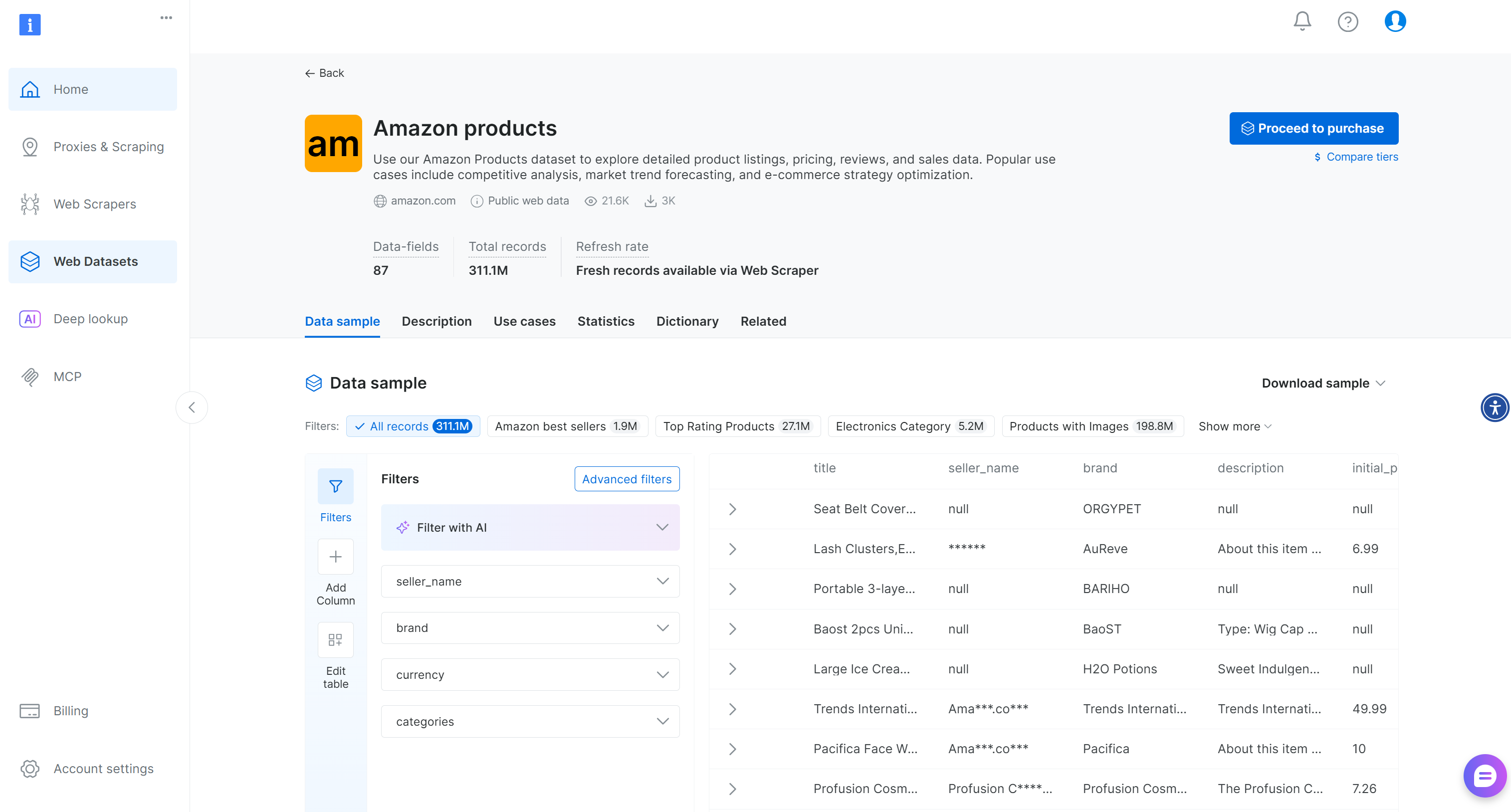
Ici, vous pouvez filtrer les entrées manuellement ou utiliser des filtres alimentés par l’IA pour créer des sous-ensembles adaptés à vos besoins. Notez que ces filtres peuvent également être appliqués par programmation via l’API Filter, qui vous permet de créer des instantanés de Jeux de données en fonction de critères spécifiques.
Pour ce tutoriel, nous n’avons besoin que d’un petit échantillon de données pour illustrer un workflow ML multimodal, donc l’échantillon gratuit suffit. Pour un workflow prêt à l’emploi ou adapté à l’entreprise, vous devez télécharger un ensemble de données complet adapté à vos besoins spécifiques.
Pour télécharger l’échantillon de jeu de données, ouvrez le menu déroulant « Dataset sample » (Échantillon de jeu de données) et sélectionnez « Download as CSV » (Télécharger au format CSV) :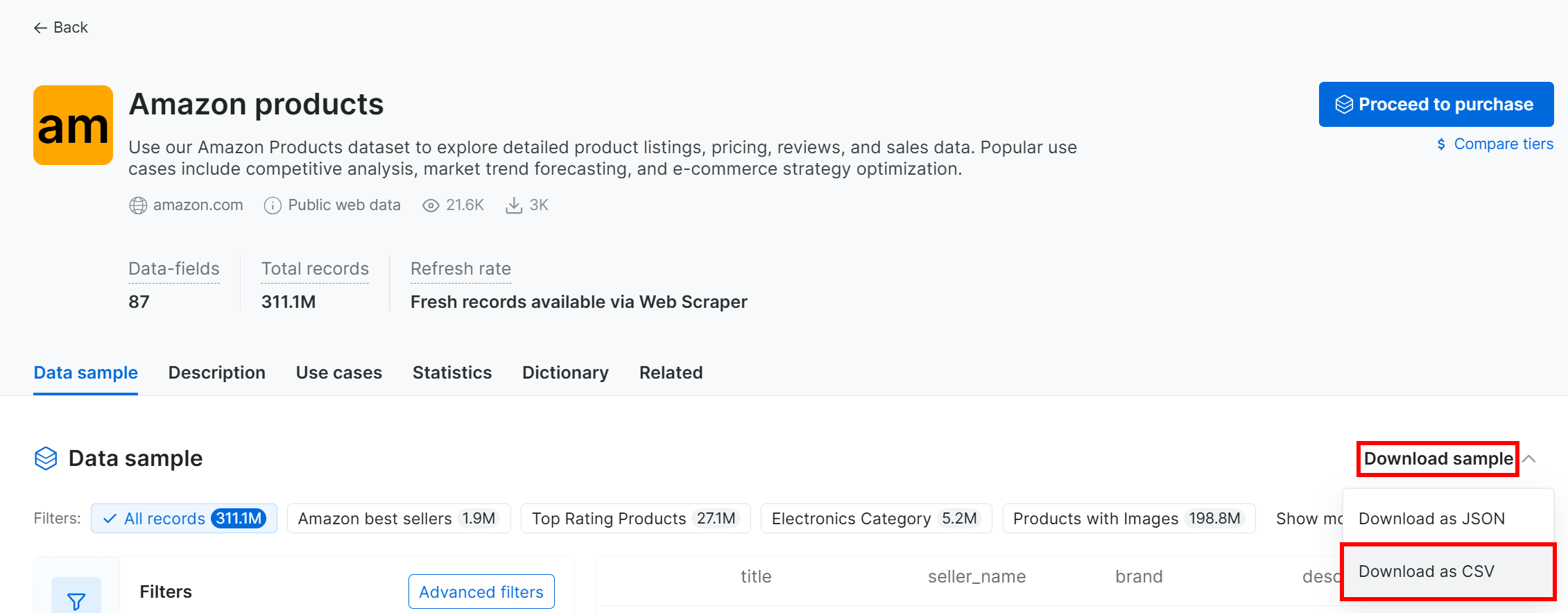
Vous recevrez un fichier nommé Amazon products.csv, contenant 1 000 produits (~7,3 Mo). Renommez-le amazon_products.csv et placez-le dans le dossier de votre projet :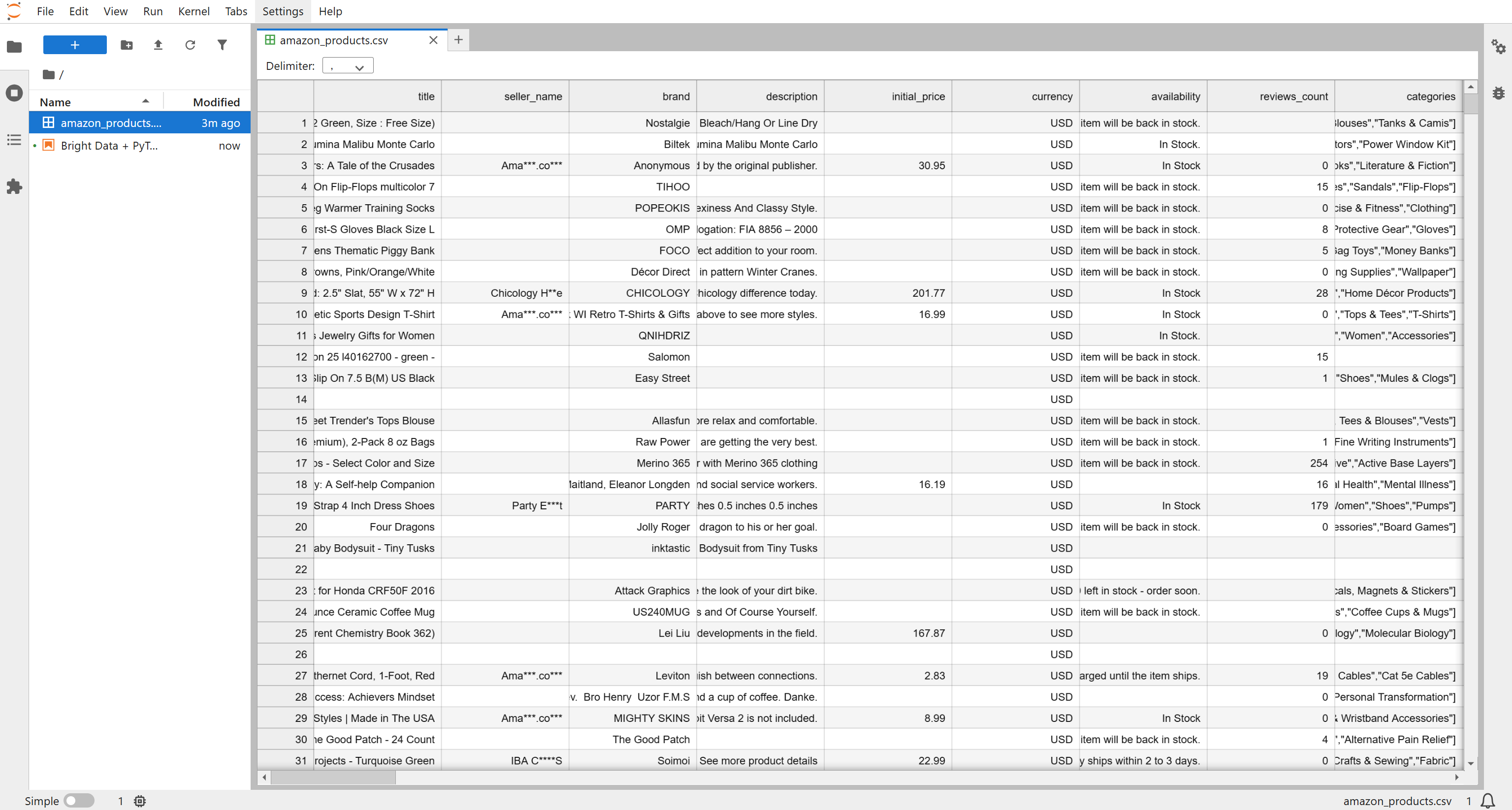
Parmi les 87 champs disponibles, ceux qui sont pertinents pour ce workflow multimodal sont les suivants :
asin: identifiant unique du produit sur Amazon.image_url: l’URL de l’image principale du produit.images: tableau au format JSON contenant des URL d’images supplémentaires pour le produit.rating: la note moyenne attribuée par les clients, sur une échelle de 1 à 5.
Ces champs vous permettent de combiner des données visuelles (images) avec des données numériques structurées (notes) dans un workflow ML multimodal PyTorch. Fantastique ! Vous disposez désormais de l’ensemble de données d’entrée.
Étape n° 4 : définir la logique pour télécharger et étiqueter les images des produits
De retour dans le notebook, initialisez la logique de base en ajoutant les fonctions de téléchargement et d’étiquetage des images. Ces deux fonctions constituent les éléments de base de la mise en œuvre du processus de classification des images ML, qui nécessite les étapes suivantes :
- Collectez les données produit, notamment
image_url,imagesarray,ratingetasin, à partir de l’ensemble de données « Amazon products » de Bright Data. - Extraire et dédupliquer les URL d’images pour chaque entrée de produit.
- Téléchargez les images à partir de toutes les URL et stockez-les localement.
- Étiquetez les images en combinant des heuristiques visuelles (fond blanc, résolution) et les notes des avis.
- Préparer un jeu de données PyTorch à partir des images étiquetées, adapté à l’entraînement d’un modèle CNN (réseau neuronal convolutif).
- Affiner un CNN pour prédire la qualité de l’image (« BONNE » ou « MAUVAISE ») à l’aide de l’ensemble de données étiquetées.
- Évaluer le modèle sur un ensemble de test.
- Utilisez le modèle pour évaluer automatiquement les images de nouveaux produits.
Dans une nouvelle cellule de code de votre notebook, écrivez les fonctions permettant de télécharger et d’étiqueter les images de produits :
def download_image(url):
# Envoyer une requête GET à l'URL de l'image
response = requests.get(url)
# Lire le contenu de la réponse dans un objet BytesIO
image_bytes = io.BytesIO(response.content)
# Ouvrir l'image avec PIL et la convertir en mode RVB
image = Image.open(image_bytes).convert("RGB")
return image
def label_image(image, rating):
# Obtenir la largeur et la hauteur de l'image
w, h = image.size
# Recadrer les 10 pixels supérieurs pour analyser la luminosité de la bordure
border = image.crop((0, 0, w, 10))
# Calculer les statistiques (moyenne) pour la bordure
stat = ImageStat.Stat(border)
# Luminosité moyenne sur les canaux RVB
brightness = sum(stat.mean) / 3
# Déterminer si l'image a un fond blanc
is_white_bg = brightness > 240
# Déterminer si l'image est en basse résolution (côté le plus petit < 400px)
is_low_res = min(image.size) < 400
# Étiquette heuristique : 1=bon si fond blanc et pas en basse résolution, sinon 0=mauvais
heuristic_label = 1 si (is_white_bg et not is_low_res) sinon 0
# Si la note est manquante ou nulle, se fier uniquement à l'heuristique
si rating est None ou rating == 0 :
renvoyer heuristic_label
# Normaliser la note dans une plage de 0 à 1
r = rating / 5
# Appliquer une supervision faible pour ajuster l'étiquette en fonction des notes extrêmes
if heuristic_label == 1 and r < 0.5: # note très faible → marquer comme mauvais
return 0
if heuristic_label == 0 and r > 0.9: # excellente note → marquer comme bon
return 1
# Sinon, conserver l'étiquette heuristique
return heuristic_labelLa fonction download_image() télécharge simplement une image à partir d’une URL donnée et la renvoie sous forme d’instance PIL Image. La fonction label_image(), quant à elle, met en œuvre une évaluation multimodale des images de produits, combinant des indices visuels et des données textuelles/numériques telles que les notes attribuées par les clients.
label_image() applique d’abord des heuristiques (vérification d’un fond blanc et d’une résolution suffisante) pour attribuer une étiquette initiale « bonne » ou « mauvaise ». Ensuite, si une note est disponible, la fonction ajuste l’étiquette comme suit :
- Les notes très basses l’emportent sur une image visuellement bonne.
- Les excellentes évaluations sauvent une image de mauvaise qualité.
Cette logique est logique, car même si une image semble bonne, une mauvaise note indique qu’elle n’est pas avantageuse. À l’inverse, une excellente note peut mettre en valeur une image réussie malgré des images de mauvaise qualité. Ainsi, les informations visuelles et numériques sont prises en compte lors de l’attribution de l’étiquette finale.
Super ! Il est temps d’importer l’ensemble de données et de préparer vos entrées de produit afin d’appliquer ces deux fonctions à toutes les images.
Étape n° 5 : charger l’ensemble de données et se préparer à télécharger toutes les images
Si vous examinez le fichier amazon_products.csv, vous verrez que les images des produits sont stockées dans deux champs de données :
image_url: URL de l’image principale du produit.images: chaîne au format JSON contenant un tableau de toutes les images supplémentaires du produit.
Dans un nouveau bloc de code, chargez le fichier CSV et récupérez toutes les images de chaque produit à l’aide d’une fonction d’aide :
def extract_image_list(row):
image_urls = []
# Vérifiez s'il existe une seule image_url principale et ajoutez-la si elle existe et n'est pas vide.
if isinstance(row.get("image_url"), str) and row["image_url"].strip():
image_urls.append(row["image_url"].strip())
# Vérifier le champ « images », qui peut être une chaîne JSON ou une liste Python
images_field = row.get("images")
if isinstance(images_field, str):
# Décoder la chaîne JSON en une liste Python
decoded = json.loads(images_field)
if isinstance(decoded, list):
# Ajouter toutes les images de la liste à image_urls
image_urls.extend(decoded)
# Dédupliquer les URL en les convertissant en un ensemble, puis en une liste
return list(set(image_urls))
# Charger le CSV des produits Amazon dans un DataFrame
df = pd.read_csv("amazon_products.csv")
# Supprimer les lignes qui ne contiennent pas les champs obligatoires
df = df.dropna(subset=["asin", "image_url", "images", "rating"])
# Appliquer la fonction extract_image_list à chaque ligne pour générer une liste de toutes les URL d'images uniques
df["all_image_urls"] = df.apply(extract_image_list, axis=1)Le jeu de données importé comporte désormais une nouvelle colonne intitulée all_image_urls. Celle-ci stocke une liste dédupliquée de toutes les URL d’images, combinant l’image principale et toutes les images supplémentaires. À l’étape suivante, vous accéderez à ce champ pour télécharger et traiter toutes les images de chaque produit !
Étape n° 6 : télécharger et étiqueter toutes les images
Dans une cellule, implémentez la logique permettant de télécharger toutes les images des produits dans un dossier images/ local et de les étiqueter :
# Créer le dossier « images » s'il n'existe pas encore.
os.makedirs("images", exist_ok=True)
# Initialiser une liste pour stocker les métadonnées de chaque image téléchargée et étiquetée.
records = []
# Parcourir chaque ligne de produit dans le DataFrame avec une barre de progression.
for idx, row in tqdm(df.iterrows(), total=len(df)):
# Accéder aux champs de données produit requis
url_list = row["all_image_urls"]
rating = float(row["rating"])
asin = row.get("asin")
# Parcourir chaque URL d'image pour ce produit afin de la télécharger et de la nommer
for i, url in enumerate(url_list):
# Télécharger l'image
image = download_image(url)
if image is None:
continue
# Construire un nom de fichier à l'aide de l'ASIN et de l'index de l'image
filename = f"{asin}_{i}.jpg"
path = os.path.join("images", filename)
# Enregistrer l'image téléchargée sur le disque
image.save(path)
# Étiqueter l'image à l'aide des informations multimodales
label = label_image(image, rating)
# Stocker les métadonnées pertinentes pour cette image
records.append({
"asin": asin,
"image_path": path,
"image_url": url,
"label": label
})
# Convertir la liste des enregistrements en un DataFrame et l'exporter vers un fichier CSV
labeled_df = pd.DataFrame(records)
labeled_df.to_csv("labeled_images.csv", index=False)Lorsque vous exécutez ce bloc de code dans votre notebook, le processus de téléchargement démarre. Il faudra télécharger plus de 2 500 images, alors soyez patient pendant quelques minutes.
Une fois le processus terminé, la cellule de code devrait afficher une barre de progression atteignant 100 % :
À présent, le dossier images/ de votre répertoire de projet contiendra toutes les images de produits téléchargées à partir de l’ensemble de données :
De plus, le fichier labeled_images.csv sera créé localement et rempli avec les informations d’étiquetage pour chaque image :
Super ! Vous disposez désormais de toutes les images locales et informations d’étiquetage nécessaires pour entraîner le modèle d’apprentissage automatique dans un processus multimodal.
Étape n° 7 : préparer les Jeux de données d’entraînement et de test
Ajoutez un nouveau bloc pour lire les informations d’étiquetage des images à partir du fichier labeled_images.csv et utilisez-les pour produire des jeux de données d’entraînement et de test que vous utiliserez pour affiner le modèle d’apprentissage automatique :
# Définir une classe PyTorch Dataset personnalisée pour les images de produits
class ProductImageDataset(Dataset):
def __init__(self, df, transform=None):
self.df = df
self.transform = transform
def __len__(self):
# Renvoyer le nombre total d'échantillons dans l'ensemble de données
return len(self.df)
def __getitem__(self, idx) :
# Obtenir le chemin d'accès à l'image et l'étiquette pour un index donné
path, label = self.df.iloc[idx]["image_path"], self.df.iloc[idx]["label"]
# Charger l'image et la convertir en RVB
image = Image.open(path).convert("RGB")
# Appliquer les transformations si elles sont fournies (par exemple, redimensionnement, conversion tensorielle)
if self.transform:
image = self.transform(image)
# Renvoyer le tenseur d'image et l'étiquette sous forme de tenseur torch
return image, torch.tensor(label, dtype=torch.long)
# Charger le CSV des images étiquetées
labeled_df = pd.read_csv("labeled_images.csv")
# Diviser l'ensemble de données en ensembles d'entraînement et de test, en conservant une distribution équilibrée des étiquettes
train_df, test_df = train_test_split(
labeled_df,
test_size=0.2,
stratify=labeled_df["label"]
)
# Définir les transformations pour redimensionner les images à 224x224 et les convertir en tenseurs
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
# Initialiser les objets de l'ensemble de données
train_ds = ProductImageDataset(train_df, transform)
test_ds = ProductImageDataset(test_df, transform)
# Envelopper les Jeux de données dans DataLoaders pour le traitement par lots et le mélange
train_dl = DataLoader(train_ds, batch_size=32, shuffle=True)
test_dl = DataLoader(test_ds, batch_size=32)Cet extrait prépare les images de produits étiquetées pour l’entraînement d’un CNN PyTorch. Pour ce faire, il définit un jeu de données personnalisé et applique les transformations d’images suivantes :
transforms.Resize((224, 224)): redimensionne les images à224×224. Cela est important car les images du jeu de données ont des résolutions et des formats différents, alors que les CNN s’attendent à ce que toutes les entrées aient la même taille fixe.transforms.ToTensor(): les modèles PyTorch fonctionnent sur des tenseurs plutôt que sur des images PIL brutes. Cela convertit chaque image en un tenseur normalisé de forme(C, H, W)(canaux, hauteur, largeur), le rendant compatible avec le CNN.
Ensemble, ces transformations normalisent toutes les images en termes de taille et de format, ce qui permet au modèle de se concentrer sur l’apprentissage des modèles visuels plutôt que sur le traitement d’entrées incohérentes. L’ensemble de données est ensuite divisé en ensembles d’entraînement et de test, en conservant les distributions des étiquettes, et encapsulé dans des objets DataLoader afin de générer des lots de données d’images et d’étiquettes.
Dans l’ensemble, cette étape garantit que le CNN reçoit des données correctement formatées, jetant ainsi les bases d’un apprentissage automatique multimodal efficace. Formidable !
Étape n° 8 : entraîner le modèle d’apprentissage automatique multimodal
Une fois les jeux de données d’entraînement et de test prêts, affinez un CNN dans PyTorch pour la classification d’images à l’aide de ce code :
# Sélectionner le périphérique pour l'entraînement (GPU si disponible, sinon CPU)
device = "cuda" if torch.cuda.is_available() else "cpu"
# Charger un modèle ResNet-18 pré-entraîné à partir de torchvision
model = models.resnet18(weights=models.ResNet18_Weights.IMAGENET1K_V1)
# Remplacer la couche finale entièrement connectée pour produire 2 classes (GOOD/BAD)
model.fc = nn.Linear(model.fc.in_features, 2)
# Déplacer le modèle vers le périphérique sélectionné
model = model.to(device)
# Définir la fonction de perte pour la classification
criterion = nn.CrossEntropyLoss()
# Définir l'optimiseur avec un faible taux d'apprentissage
opt = torch.optim.Adam(model.parameters(), lr=1e-4)
# Boucle d'entraînement pour 3 époques
for epoch in range(3):
model.train()
total_loss = 0
# Itérer sur les lots d'images et d'étiquettes
for images, labels in tqdm(train_dl, desc=f"Époque {epoch+1}"):
images, labels = images.to(device), labels.to(device)
opt.zero_grad()
out = model(images)
loss = criterion(out, labels)
loss.backward()
opt.step()
total_loss += loss.item()
# Imprimer la perte moyenne pour l'époque
print(f"Époque {epoch+1} : perte moyenne={total_loss/len(train_dl):.4f}")La cellule ci-dessus affine un CNN ResNet-18 pré-entraîné, un réseau neuronal convolutif de 18 couches principalement utilisé pour classer les images en différentes catégories.
Dans ce cas, le modèle ML classera les images de produits comme bonnes ou mauvaises. L’utilisation des poids ImageNet accélère la convergence et exploite les caractéristiques déjà apprises à partir de millions d’images naturelles. Ensuite, la couche finale entièrement connectée est remplacée pour produire deux classes (« GOOD » et « BAD », comme prévu).
Dans la boucle, l’instance CrossEntropyLoss mesure l’erreur de classification, tandis que l’optimiseur Adam met à jour les poids du modèle. Chaque époque itère sur des lots, effectuant un passage en avant, calculant la perte, la rétropropagation et les mises à jour des poids.
Exécutez le bloc de code et vous obtiendrez un résultat comme celui-ci :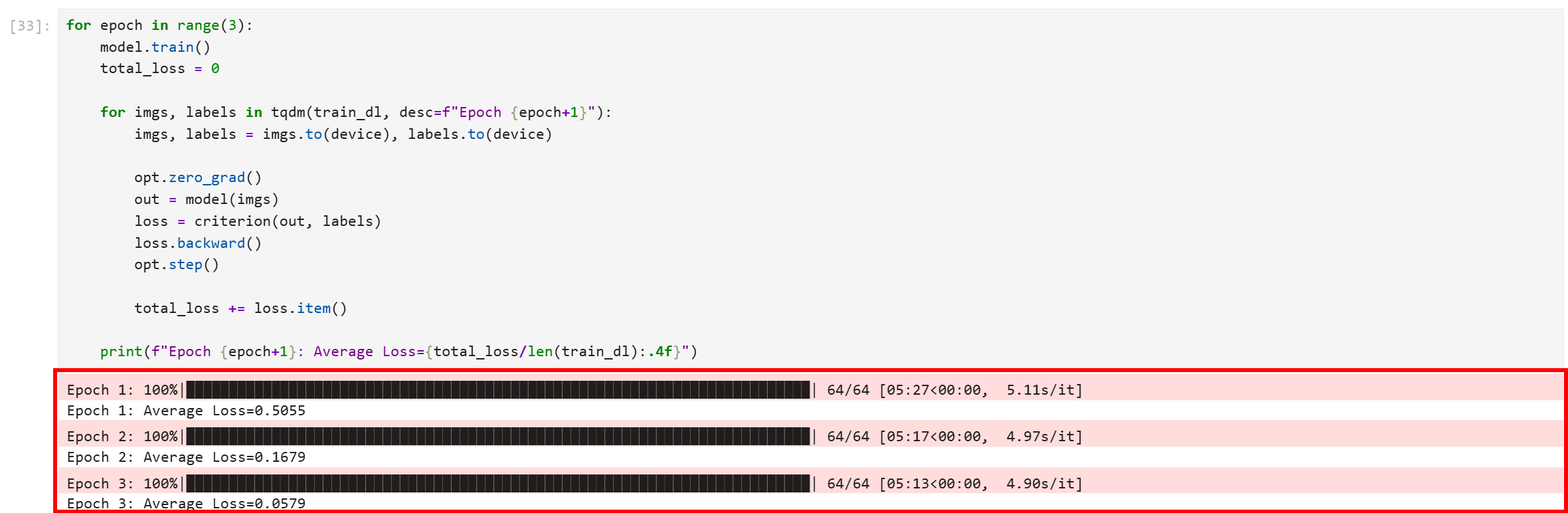
Notez que les trois époques se sont déroulées avec succès. La perte moyenne finale est de 0,0579, ce qui est assez faible et indique que le modèle a bien convergé et a appris à distinguer les images d’entraînement avec un haut niveau de confiance.
Et voilà ! Vous venez d’affiner un CNN pour la distinction de la qualité des images dans le commerce électronique.
Étape n° 9 : Évaluer les performances du modèle
Pour vérifier les performances du modèle, exécutez une étape d’évaluation :
# Charger la version d'évaluation du modèle
model.eval()
# Pour suivre les images traitées
correct = 0
total = 0
# Évaluer le modèle par rapport à l'ensemble de données d'entraînement
with torch.no_grad():
for images, labels in test_dl:
images, labels = images.to(device), labels.to(device)
out = model(images)
prediction = out.argmax(dim=1)
correct += (prediction == labels).sum().item()
total += len(labels)
# Afficher les résultats
print("Précision du test :", correct / total)Cela permet de mesurer la capacité du modèle affiné à généraliser sur des données qu’il n’a jamais vues auparavant (l’ensemble de données de test). Plus précisément, il effectue l’évaluation du modèle via l’inférence.
La cellule de code passe d’abord le modèle en mode évaluation et désactive le suivi du gradient afin d’optimiser la vitesse et de garantir un comportement cohérent. Ensuite, la boucle itère à travers l’ensemble de données de test, en comparant les prédictions du modèle aux étiquettes réelles. Enfin, elle calcule la précision totale, fournissant ainsi une mesure claire de la capacité du modèle à généraliser au-delà de l’ensemble d’apprentissage.
Le résultat devrait être similaire à celui-ci :

Un score de précision de test de 0,924XXX signifie que votre modèle ResNet-18 affiné a correctement classé plus de 92,4 % des images de produits dans votre jeu de données de test inédit comme « BON » ou « MAUVAIS ».
Ce résultat peut être considéré comme excellent pour une classification binaire sur des données réelles telles que des images de produits e-commerce. Il suggère fortement que le modèle a réussi à apprendre la différence entre les caractéristiques d’une bonne et d’une mauvaise qualité d’image et ne se contente pas de mémoriser les données d’entraînement.
Bravo ! Appliquons maintenant le modèle affiné à quelques nouvelles images pour voir s’il fonctionne comme prévu.
Étape n° 10 : utiliser le modèle ML pour prédire la qualité des images
Pour vérifier si le modèle affiné fonctionne comme prévu, vous devez tester ses performances sur des images qu’il n’a jamais rencontrées. Comme le modèle est entraîné pour fonctionner avec n’importe quelle image de produit e-commerce, vous pouvez le tester avec des images provenant de plateformes telles que eBay, Walmart, Alibaba ou vos propres bases de données internes de produits.
Dans cette démonstration, nous allons tester le modèle sur les deux images de produits suivantes provenant d’eBay :
Pour ce faire, ajoutez le code suivant dans un bloc dédié :
def predict_image_quality(img: Image.Image) -> str:
# Régler le modèle en mode évaluation
model.eval()
# Appliquer les transformations et ajouter une dimension par lots
x = transform(img).unsqueeze(0).to(device)
with torch.no_grad():
# Passez en avant, obtenez l'index de classe prédit et extrayez-le sous forme de scalaire
prediction = model(x).argmax().item()
# Renvoyez la chaîne de résultat
return "GOOD" if prediction == 1 else "BAD"
# Images de test
image_urls = ["https://i.ebayimg.com/images/g/N5kAAOSwTlplqFTa/s-l500.webp", "https://i.ebayimg.com/images/g/yUsAAOSweMJd67Jd/s-l1600.webp"]
# Parcourir les URL des images, télécharger, prédire et afficher
for image_url in image_urls:
# Télécharger le contenu de l'image à l'aide d'une requête HTTP
response = requests.get(image_url)
image = Image.open(io.BytesIO(response.content)).convert("RGB")
# Appeler la fonction de prédiction
quality = predict_image_quality(image)
# Afficher l'image dans le notebook avec les résultats du modèle
display(image)
print(image_url, "→", quality)Après avoir exécuté la cellule, vous observerez les classifications suivantes :
Notez que le modèle a classé l’image comme « MAUVAISE ». Ce résultat est correct, car l’image est visiblement de mauvaise qualité, floue et l’arrière-plan manque de contraste, ce qui ne permet pas de mettre correctement en valeur le produit.
En revanche, sur la deuxième image, il produit :
Cette fois, la classification est « GOOD », ce qui est un résultat convaincant étant donné que l’image est visuellement attrayante, nette et bien éclairée. De plus, elle montre clairement le produit.
Et voilà ! Grâce aux riches Jeux de données de Bright Data, vous avez récupéré des données sur des produits e-commerce (dans ce cas, sur Amazon). Vous avez ensuite utilisé PyTorch pour affiner un CNN pour la reconnaissance d’images en suivant une approche d’analyse de données ML multimodale.
Conclusion
Dans cet article, vous avez vu comment mettre en œuvre un système d’apprentissage automatique multimodal. Nous avons utilisé des jeux de données contenant des centaines de millions de produits Amazon et leurs images correspondantes.
En introduisant ces données dans un workflow PyTorch dans un notebook Python, vous avez réussi à affiner un CNN (réseau neuronal convolutif) pour classer les images de produits e-commerce comme bonnes ou mauvaises.
Ce projet répond directement aux besoins des petites et moyennes entreprises ou des grandes entreprises qui cherchent des moyens d’évaluer rapidement la qualité des images pour la représentation des produits, en particulier à des fins de commerce électronique.
Tout cela ne serait pas possible sans les services de données d’entreprise de Bright Data, qui vous aident à collecter des données provenant de plus de 100 domaines, dont Amazon, Walmart, LinkedIn, Zillow, Airbnb, Yahoo Finance et bien d’autres.
Inscrivez-vous dès aujourd’hui pour créer un compte Bright Data et tester gratuitement nos solutions de données !