

La création de modèles spécialisés qui comprennent votre domaine nécessite souvent plus que de l’ingénierie rapide ou de la génération augmentée par récupération (RAG). Les modèles accessibles au public sont puissants, mais ils ne disposent pas des connaissances les plus récentes ou ne répondent pas aux exigences spécifiques de votre cas d’utilisation. Puisque nous disposons de données web, allant d’articles, de documentations, de listes de produits et de transcriptions vidéo, cette lacune peut être comblée par un réglage fin.
Dans cet article de blog, vous apprendrez
- Comment collecter et préparer des données web spécifiques à un domaine en utilisant les scrapers et les ensembles de données de Bright Data.
- Comment affiner un modèle GPT open-source avec les données collectées.
- Comment évaluer et déployer votre modèle affiné pour des tâches réelles.
Plongeons dans le vif du sujet !
Qu’est-ce que le réglage fin ?
En termes simples, le réglage fin est le processus qui consiste à prendre un modèle qui a déjà été pré-entraîné sur un grand ensemble de données générales et à l’adapter pour qu’il soit performant sur un nouvel ensemble de données ou une nouvelle tâche, souvent plus spécifique. Lorsque vous procédez à un réglage fin, sous le capot, vous modifiez les poids du modèle au lieu de le construire à partir de zéro. C’est en modifiant les poids que le modèle se comporte différemment ou de la manière souhaitée.
Les données web sont utiles pour le réglage fin car elles vous offrent les avantages suivants
- Fraîcheur : Elles sont continuellement mises à jour pour tenir compte des dernières tendances, des derniers événements et des dernières technologies.
- Diversité : L’accès à des styles d’écriture, des sources et des pensées différents réduit les biais liés à des ensembles de données étroits.
Le processus de mise au point fonctionne comme suit :
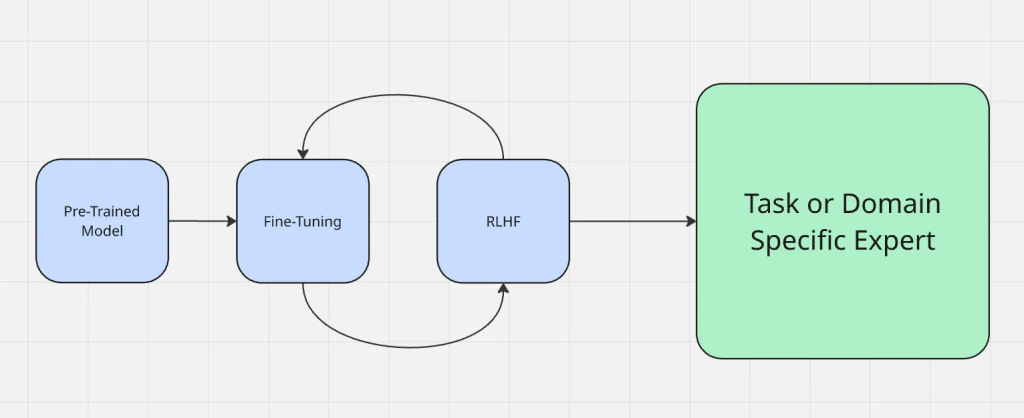
Le réglage fin est différent des autres méthodes d’adaptation couramment utilisées, telles que l’ingénierie des requêtes et la génération augmentée par la recherche. L’ingénierie d’invite modifie la façon dont vous posez des questions à un modèle, mais ne modifie pas le modèle lui-même. La RAG ajoute une source de connaissances externe au moment de l’exécution, comme pour donner un contexte à quelque chose de nouveau. Le réglage fin, quant à lui, met à jour directement les paramètres du modèle, ce qui le rend plus fiable pour produire des résultats précis dans le domaine sans contexte supplémentaire à chaque fois.
Contrairement à la génération augmentée par récupération (RAG), qui enrichit un modèle avec un contexte externe au moment de l’exécution, le réglage fin adapte le modèle lui-même. Si vous souhaitez approfondir les compromis, consultez RAG vs Fine-Tuning.
Pourquoi utiliser les données Web pour le réglage fin ?
Les données web se présentent sous des formats riches et récents (articles, listes de produits, messages de forum, transcriptions de vidéos et même textes dérivés de vidéos), ce qui leur confère un avantage que ni les ensembles de données statiques ni les ensembles de données synthétiques ne peuvent égaler. Cette variété permet à un modèle de traiter plus efficacement différents types d’entrées.
Voici quelques exemples de contextes différents dans lesquels les données web brillent :
- Données des médias sociaux : Les jetons des plateformes sociales aident les modèles à comprendre le langage informel, l’argot et les tendances en temps réel, ce qui est essentiel pour des applications telles que l’analyse des sentiments ou les robots de conversation.
- Ensembles de données structurées : Les jetons provenant de sources structurées telles que les catalogues de produits ou les rapports financiers permettent une compréhension précise et spécifique à un domaine, essentielle pour les systèmes de recommandation ou les prévisions financières.
- Contexte de niche : Les startups et les applications spécialisées bénéficient de tokens provenant d’ensembles de données pertinents adaptés à leurs cas d’utilisation, tels que des documents juridiques pour la technologie juridique ou des journaux médicaux pour l’IA de l’assurance-maladie.
Les données Web apportent une variété et un contexte naturels, améliorant le réalisme et la robustesse d’un modèle affiné.
Stratégies de collecte de données
Les scrapers à grande échelle et les fournisseurs d’ensembles de données tels que Bright Data permettent de collecter des volumes massifs de contenu web de manière rapide et fiable. Cela vous permet de constituer des ensembles de données spécifiques à un domaine sans passer des mois sur la collecte manuelle.
Bright Data a mis en place l’infrastructure de collecte de données web la plus diversifiée et la plus fiable du secteur, constituée de plusieurs réseaux et sources différents. Les données web ne se limitent pas à du texte brut. Bright data peut capturer des entrées multimodales telles que des métadonnées, des attributs de produits et des transcriptions vidéo, qui aident un modèle à apprendre un contexte plus riche.
La collecte de données à l’aide de scraps bruts doit être évitée car ils contiennent presque toujours du bruit, du contenu non pertinent ou des artefacts de formatage. Le filtrage, la suppression des doublons et le nettoyage structuré sont des étapes importantes pour s’assurer que l’ensemble de données d’entraînement améliore les performances au lieu d’introduire de la confusion.
Préparation des données Web en vue d’une mise au point
- Convertir les scraps bruts en paires d’entrées/sorties structurées. Les données non traitées sont rarement prêtes pour la formation en l’état. La première étape consiste à convertir les données en paires entrées/sorties structurées. Par exemple, une documentation sur le réglage fin peut être formatée en une invite telle que “Qu’est-ce que le réglage fin ?” avec la réponse originale comme sortie cible. Ce type de structure garantit que le modèle apprend à partir d’exemples bien définis et non d’un texte non organisé.
- Prise en charge de divers formats : JSON, CSV, transcriptions, pages web. Les données web se présentent généralement sous différents formats, tels que JSON provenant d’API, des exportations CSV, du HTML brut ou des transcriptions de vidéos. La normalisation des données web dans un format cohérent tel que JSONL simplifie leur gestion et leur introduction dans les pipelines de formation.
- Regrouper les ensembles de données pour une formation efficace. Pour améliorer les résultats et le processus de formation, les ensembles de données sont souvent “arrangés”, c’est-à-dire que plusieurs exemples plus courts sont combinés en une seule séquence afin de réduire les tokens gaspillés et d’optimiser l’utilisation de la mémoire du GPU lors de la mise au point.
- Équilibrer les données web spécifiques à un domaine et les données web générales. Il est important de trouver un équilibre. Un excès de données spécifiques à un domaine peut rendre le modèle étroit et superficiel, tandis qu’un excès de données générales peut diluer les connaissances spécialisées ciblées. Les meilleurs résultats proviennent généralement de la combinaison d’une base solide de données web générales et d’exemples spécifiques à un domaine.
Choix d’un modèle de base
Le choix du bon modèle de base a un impact direct sur les performances de votre système. Il n’existe pas de solution unique, surtout si l’on considère la variété des offres au sein de chaque famille de modèles. En fonction du type de données, des résultats souhaités et du budget, un modèle peut mieux répondre à vos besoins qu’un autre.
Pour choisir le bon modèle, suivez cette liste de contrôle :
- De quelle(s) modalité(s) votre modèle aura-t-il besoin ?
- Quelle est la taille de vos données d’entrée et de sortie ?
- Quelle est la complexité des tâches que vous essayez d’accomplir ?
- Quelle est l’importance des performances par rapport au budget ?
- Quelle est l’importance de la sécurité de l’assistant d’IA dans votre cas d’utilisation ?
- Votre entreprise a-t-elle déjà conclu un accord avec Azure ou GCP ?
Par exemple, si vous traitez des vidéos ou des textes extrêmement longs (des heures de centaines de milliers de mots), Gemini 1.5 pro pourrait être un choix optimal, offrant une fenêtre contextuelle allant jusqu’à 1 million de tokens.
Plusieurs modèles open-source sont de bons candidats pour l’affinage des données web, notamment les modèles Gemma 3, Llama 3.1, Mistral 7B ou Falcon. Les versions plus petites sont pratiques pour la plupart des projets d’affinage, tandis que les versions plus grandes s’imposent lorsque votre domaine nécessite une couverture et une précision élevées. Vous pouvez également consulter ce guide sur l’adaptation de Gemma 3 pour le réglage fin.
La mise au point avec des données brillantes
Pour démontrer comment les données web alimentent le réglage fin, nous allons parcourir un exemple en utilisant Bright Data comme source. Dans cet exemple, nous utiliserons l’API Scraper de Bright Data pour collecter des informations sur les produits à partir d’Amazon, puis pour affiner un modèle Llama 4 sur Hugging Face.
Étape 1 : Collecte de l’ensemble de données
Grâce à l’API web scraper de Bright Data, vous pouvez récupérer des données structurées sur les produits (titre, produits, descriptions, commentaires, etc.) avec seulement quelques lignes de Python.
L’objectif de cette étape est de créer un petit projet qui :
- active un environnement virtuel Python
- Appelle l’API Web Scraper de Bright Data
- Enregistre les résultats dans amazon-data.json
Conditions préalables
- Python 3.10+
- Une clé API Bright Data
- Un ID de collecteur Bright Data (à partir du tableau de bord Bright Data) /cp/scrapers
- Une clé OPENAI_API_KEY puisque nous allons affiner un modèle GPT-4.
Créer un dossier de projet
mkdir web-scraper u0026u0026 cd web-scrapper
Créer et activer un environnement virtuel
Activez un environnement virtuel, et vous devriez voir (venv) au début de votre invite de commande.
//macOS/Linux (bash or zsh):npython3 -m venv venvnsource venv/bin/activatennWindowsnpython -m venv venvn.venvScriptsActivate.ps1
Installer les dépendances
Il s’agit d’une bibliothèque permettant d’effectuer des requêtes web HTTP.
pip install requests
Une fois cette étape terminée, vous êtes prêt à obtenir les données qui vous intéressent en utilisant les API de Bright Data.
Définir la logique du scraper
L’extrait suivant déclenchera votre collecteur Bright Data (par exemple, les produits Amazon), interrogera jusqu’à ce que le scrape soit terminé et enregistrera les résultats dans un fichier JSON local.
Remplacez votre clé d’api dans la chaîne de clé d’api ici.
import requestsnimport jsonnimport timenndef trigger_amazon_products_scraping(api_key, urls):n url = u0022https://api.brightdata.com/datasets/v3/triggeru0022nn params = {n u0022dataset_idu0022: u0022gd_l7q7dkf244hwjntr0u0022,n u0022include_errorsu0022: u0022trueu0022,n u0022typeu0022: u0022discover_newu0022,n u0022discover_byu0022: u0022best_sellers_urlu0022,n }n data = [{u0022category_urlu0022: url} for url in urls]nn headers = {n u0022Authorizationu0022: fu0022Bearer {api_key}u0022,n u0022Content-Typeu0022: u0022application/jsonu0022,n }nn response = requests.post(url, headers=headers, params=params, json=data)nn if response.status_code == 200:n snapshot_id = response.json()[u0022snapshot_idu0022]n print(fu0022Request successful! Response: {snapshot_id}u0022)n return response.json()[u0022snapshot_idu0022]n else:n print(fu0022Request failed! Error: {response.status_code}u0022)n print(response.text)nndef poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):n snapshot_url = fu0022https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=jsonu0022n headers = {n u0022Authorizationu0022: fu0022Bearer {api_key}u0022n }nn print(fu0022Polling snapshot for ID: {snapshot_id}...u0022)nn while True:n response = requests.get(snapshot_url, headers=headers)nn if response.status_code == 200:n print(u0022Snapshot is ready. Downloading...u0022)n snapshot_data = response.json()nn with open(output_file, u0022wu0022, encoding=u0022utf-8u0022) as file:n json.dump(snapshot_data, file, indent=4)nn print(fu0022Snapshot saved to {output_file}u0022)n returnn elif response.status_code == 202:n print(Fu0022Snapshot is not ready yet. Retrying in {polling_timeout} seconds...u0022)n time.sleep(polling_timeout)n else:n print(fu0022Request failed! Error: {response.status_code}u0022)n print(response.text)n breaknnif __name__ == u0022__main__u0022:n BRIGHT_DATA_API_KEY = u0022your_api_keyu0022n urls = [n u0022https://www.amazon.com/gp/bestsellers/office-products/ref=pd_zg_ts_office-productsu0022n ]n snapshot_id = trigger_amazon_products_scraping(BRIGHT_DATA_API_KEY, urls)n poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, u0022amazon-data.jsonu0022)
Exécutez le code
python3 web_scraper.py
Vous devriez voir :
- Un ID d’instantané imprimé
- Scrape terminé.
- Sauvegardé dans amazon-data.json (…items)
Le processus crée automatiquement les données qui contiennent nos données scrappées. Il s’agit de la structure attendue des données :
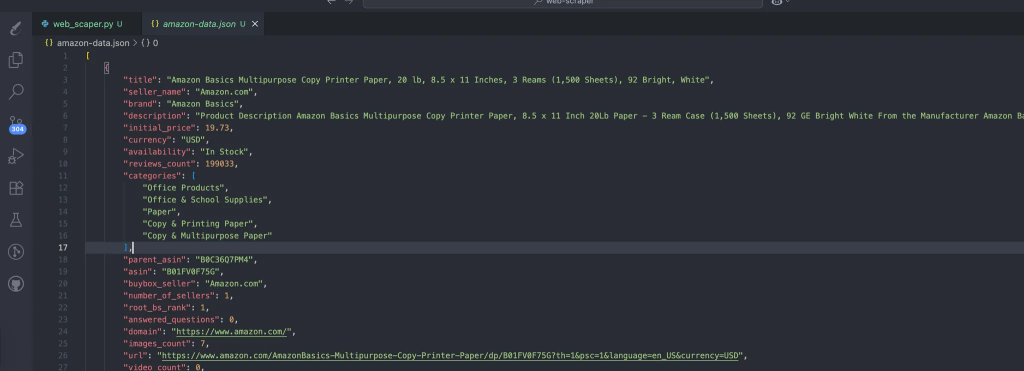
Etape #2 : Transformer le JSON en paires d’entraînement
Créez prepare_pair.py à la racine du projet, avec l’extrait suivant pour structurer nos données au format JSONL afin de les rendre prêtes pour votre étape d’ajustement.
import json, random, osnnINPUT = u0022amazon-data.jsonu0022nOUTPUT = u0022pairs.jsonlu0022nSYSTEM = u0022You are an expert copywriter. Generate concise, accurate product descriptions.u0022nndef make_example(item):n title = item.get(u0022titleu0022) or item.get(u0022nameu0022) or u0022Unknown productu0022n brand = item.get(u0022brandu0022) or u0022Unknown brandu0022n features = item.get(u0022featuresu0022) or item.get(u0022bulletsu0022) or []n features_str = u0022, u0022.join(features) if isinstance(features, list) else str(features)n target = item.get(u0022descriptionu0022) or item.get(u0022aboutu0022) or u0022u0022n user = fu0022Write a crisp product description.nTitle: {title}nBrand: {brand}nFeatures: {features_str}nDescription:u0022n assistant = target.strip()[:1200] # keep it tightn return {u0022systemu0022: SYSTEM, u0022useru0022: user, u0022assistantu0022: assistant}nndef main():n if not os.path.exists(INPUT):n raise SystemExit(fu0022Missing {INPUT}u0022)n data = json.load(open(INPUT, u0022ru0022, encoding=u0022utf-8u0022))n pairs = [make_example(x) for x in data if isinstance(x, dict)]n random.shuffle(pairs)n with open(OUTPUT, u0022wu0022, encoding=u0022utf-8u0022) as out:n for ex in pairs:n out.write(json.dumps(ex, ensure_ascii=False) + u0022nu0022)n print(fu0022Wrote {len(pairs)} examples to {OUTPUT}u0022)nnif __name__ == u0022__main__u0022:n main()
Exécutez la commande suivante :
python3 prepare_pairs.py
Et devrait donner la sortie suivante dans le fichier :
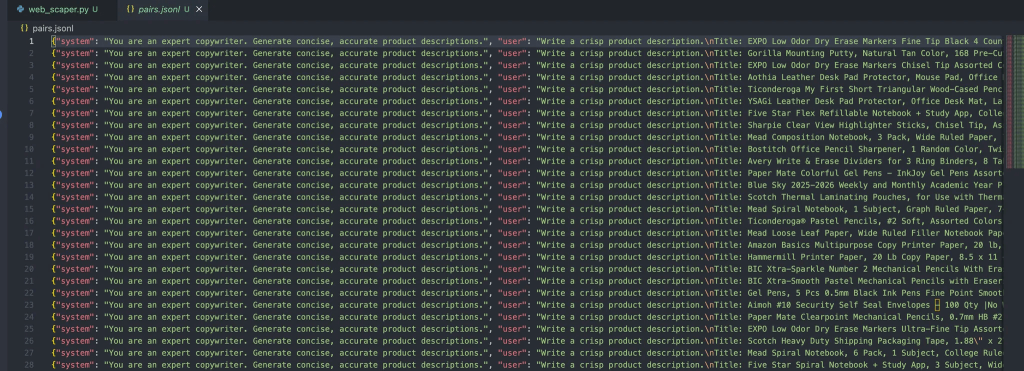
Chaque message dans ces objets contient trois rôles :
- Système: Il fournit le contexte initial à l’assistant.
- Utilisateur: l’entrée de l’utilisateur.
- Assistant: la réponse de l’assistant.
Étape n° 3 : Téléchargement du fichier pour peaufinage
Une fois que le fichier est prêt, les étapes suivantes consistent simplement à le câbler dans les pipelines de réglage fin d’OpenAI avec les étapes suivantes :
Installer les dépendances d’OpenAI
pip install openai
Créer un script upload.py pour charger votre jeu de données
Ce script lira le fichier pairs.jsonl que nous avons déjà.
from openai import OpenAInclient = OpenAI(api_key=u0022your_api_key_hereu0022)nnwith open(u0022pairs.jsonlu0022, u0022rbu0022) as f:n uploaded = client.files.create(file=f, purpose=u0022fine-tuneu0022)nnprint(uploaded)
Exécutez la commande suivante :
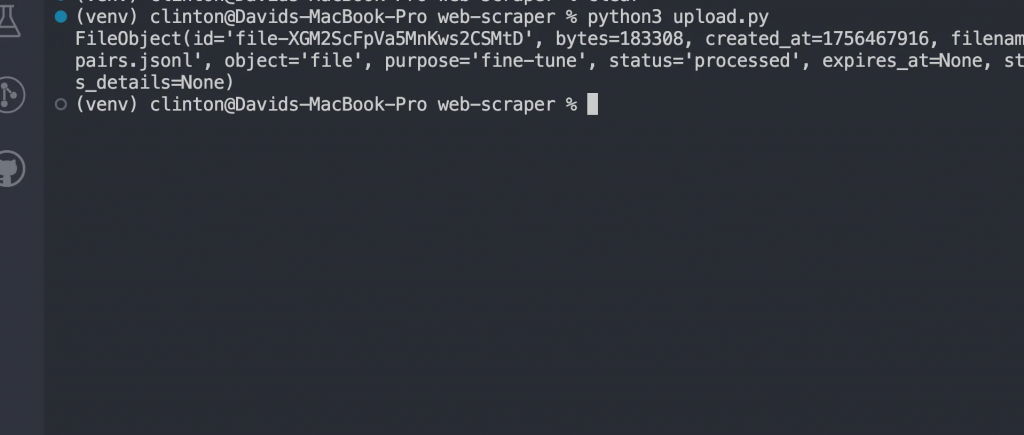
python3 upload.py
Vous devriez maintenant voir une réponse comme :
Ajuster le modèle
Créez un fichier fine-tune.py et remplacez FILE_ID par l’identifiant du fichier téléchargé que nous avons obtenu dans notre réponse ci-dessus, et exécutez le fichier :
from openai import OpenAInclient = OpenAI()nn# replace with your uploaded file idnFILE_ID = u0022file-xxxxxxu0022nnjob = client.fine_tuning.jobs.create(n training_file=FILE_ID,n model=u0022gpt-4o-mini-2024-07-18u0022n)nnprint(job)
Nous devrions obtenir la réponse suivante :
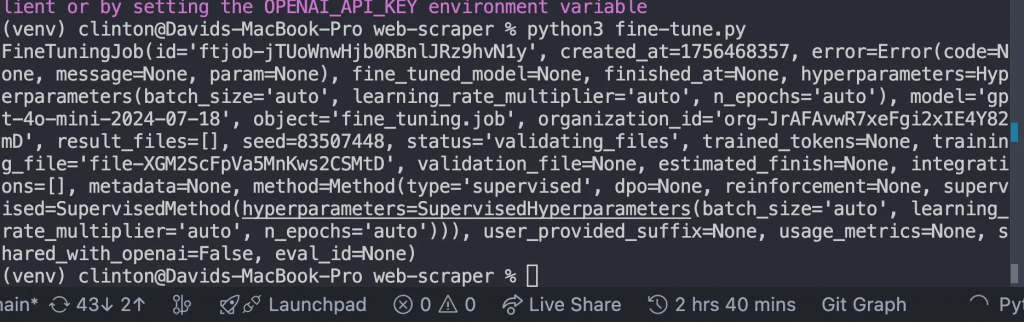
Surveiller jusqu’à la fin de la formation
Une fois que vous avez lancé le travail de réglage fin, le modèle a besoin de temps pour s’entraîner sur votre ensemble de données. Selon la taille de l’ensemble de données, cela peut prendre de quelques minutes à quelques heures.
Mais vous ne voulez pas deviner quand il sera prêt ; au lieu de cela, écrivez et exécutez ce code dans monitor.py
from openai import OpenAInclient = OpenAI()nnjobs = client.fine_tuning.jobs.list(limit=1)nprint(jobs)
Exécutez ensuite le fichier avec python3 [manage.py](http://manage.py) dans le terminal, et il devrait afficher des détails tels que :
- Si l’apprentissage a réussi ou échoué.
- Combien de tokens ont été formés
- L’ID du nouveau modèle affiné.
Dans cette section, vous ne devez avancer que lorsque le champ d’état indique
u0022succeededu0022
Discutez avec votre modèle affiné
Une fois le travail terminé, vous avez maintenant votre propre modèle GPT personnalisé. Pour l’utiliser, ouvrez chat.py, mettez à jour l’identifiant MODEL_ID avec celui renvoyé par votre travail de réglage fin, et exécutez le fichier :
from openai import OpenAInclient = OpenAI()nn# replace with your fine-tuned model idnMODEL_ID = u0022ft:gpt-4o-mini-2024-07-18:your-org::custom123u0022nnwhile True:n user_input = input(u0022User: u0022)n if user_input.lower() in [u0022quitu0022, u0022qu0022]:n breaknn response = client.chat.completions.create(n model=MODEL_ID,n messages=[n {u0022roleu0022: u0022systemu0022, u0022contentu0022: u0022You are a helpful assistant fine-tuned on domain data.u0022},n {u0022roleu0022: u0022useru0022, u0022contentu0022: user_input}n ]n )n print(u0022Assistant:u0022, response.choices[0].message.content)
Cette étape prouve que le réglage fin a fonctionné. Au lieu d’utiliser le modèle de base général, vous parlez maintenant à un modèle entraîné spécifiquement sur vos données.
C’est ici que vous verrez vos résultats prendre vie.
Vous pouvez vous attendre à des résultats comme :
u002du002d- Generating Descriptions with Fine-Tuned Model using Synthetic Test Data u002du002d-nnPROMPT for item: ErgoPro-EL100nGENERATED (Fine-tuned):n**Introducing the ErgoPro-EL100: The Ultimate Executive Ergonomic Office Chair**nnExperience the pinnacle of comfort and support with the ComfortLuxe ErgoPro-EL100, designed to elevate your work experience. This premium office chair boasts a high-back design that cradles your upper body, providing unparalleled lumbar support and promoting a healthy posture.nnThe breathable mesh fabric ensures a cool and comfortable seating experience, while the synchronized tilt mechanism allows for seamless adjustments to your preferred working position. The padded armrests provide additional support and comfort, reducing strain on your shoulders and wrists.nnBuilt to last, the ErgoPro-EL100 features a heavy-duty nylon base that ensures stability and durability. Whether you're working long hours or simplynu002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002dnnPROMPT for item: HeightRise-FD20nGENERATED (Fine-tuned):n**Elevate Your Productivity with FlexiDesk's HeightRise-FD20 Adjustable Standing Desk Converter**nnTake your work to new heights with FlexiDesk's HeightRise-FD20, the ultimate adjustable standing desk converter. Designed to revolutionize your workspace, this innovative converter transforms any desk into a comfortable and ergonomic standing station.nn**Experience the Benefits of Standing**nnThe HeightRise-FD20 features a spacious dual-tier surface, perfect for holding your laptop, monitor, and other essential work tools. The smooth gas spring lift allows for effortless height adjustments, ranging from 6 to 17 inches, ensuring a comfortable standing position that suits your needs.nn**Durable and Reliable**nnWith a sturdy construction and non-slip rubber feetnu002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002d
Conclusion
Lorsque l’on travaille avec le réglage fin à l’échelle du web, il est important d’être réaliste en ce qui concerne les contraintes et les flux de travail :
- Besoins en ressources: L’entraînement sur des ensembles de données volumineux et diversifiés nécessite des capacités de calcul et de stockage. Si vous expérimentez, commencez par de plus petites tranches de vos données avant de passer à l’échelle supérieure.
- Procédez par itérations successives: Au lieu de déverser des millions d’enregistrements lors de votre première tentative, affinez avec un ensemble de données plus petit. Utilisez les résultats pour repérer les lacunes ou les erreurs dans votre pipeline de prétraitement.
- Flux de déploiement: Traitez les modèles affinés comme n’importe quel autre artefact logiciel. Versionnez-les, intégrez-les à CI/CD lorsque c’est possible et conservez des options de retour en arrière au cas où un nouveau modèle ne serait pas assez performant.
Heureusement, Bright Data vous couvre avec de nombreux services prêts pour l’IA pour l’acquisition ou la création d’ensembles de données :
- Scraping Browser: Un navigateur compatible avec Playwright, Selenium et Puppeter, avec des capacités de déverrouillage intégrées.
- API de raclage Web: API préconfigurées pour l’extraction de données structurées à partir de plus de 100 domaines majeurs.
- Web Unlocker: Une API tout-en-un qui gère le déverrouillage des sites dotés de protections anti-bots.
- SERP API: Une API spécialisée qui déverrouille les résultats des moteurs de recherche et extrait des données SERP complètes.
- Données pour les modèles de fondation: Accédez à des ensembles de données conformes, à l’échelle du web, pour faciliter le pré-entraînement, l’évaluation et la mise au point.
- Fournisseurs de données: Connectez-vous avec des fournisseurs de confiance pour obtenir des ensembles de données de haute qualité, prêts pour l’IA, à grande échelle.
- Paquets de données: Obtenez des ensembles de données curatées et prêtes à l’emploi, structurées, enrichies et annotées.
L’affinement des modèles de langage à grande échelle à l’aide de données Web permet une spécialisation poussée des domaines. Le web fournit un contenu frais, diversifié et multimodal, allant des articles et des revues aux transcriptions et aux métadonnées structurées, que les ensembles de données curatées ne peuvent pas égaler à eux seuls.
Créez gratuitement un compte Bright Data pour tester notre infrastructure de données prête pour l’IA !






