La recherche de compte avant un appel client prend souvent dix à quinze minutes par commercial. Le flux de travail est essentiellement manuel : le commercial quitte Salesforce, ouvre Google, parcourt plusieurs onglets et colle les résultats dans un champ de notes. L’essentiel du travail consiste à rechercher et à synthétiser.
Web Unlocker de Bright Data renvoie du Markdown propre à partir de la plupart des URL publiques. En le connectant à Salesforce Agentforce, un commercial peut obtenir une recherche de compte à partir d’une invite de chat, avec des sources attribuées, sans quitter Salesforce. Sous le capot, la construction comprend un sous-agent Agentforce, trois classes Apex et un petit proxy Cloudflare Worker.
TL;DR
- Un sous-agent Agentforce prend une invite en langage naturel d’un commercial, appelle Bright Data Web Unlocker et renvoie un briefing de compte avec des sources attribuées, le tout dans le chat Salesforce.
- Le client HTTP d’Apex échoue silencieusement sur les réponses en transfert fragmenté (chunked-transfer) au-delà de quelques kilo-octets (vérifié sur API v66.0), donc l’intégration passe par un petit Cloudflare Worker qui met en mémoire tampon et re-sert avec un en-tête
Content-Lengthexplicite. - L’interface Canvas d’Agentforce masque le flag YAML
is_user_input: Truerequis pour que les agents pilotés par chat reçoivent les entrées extraites des invites. La correction se fait en mode Script. - Le modèle External Credential actuel de Salesforce se divise en trois objets (External Credential, Named Credential, Permission Set), avec une case à cocher facile à manquer qui renvoie 401 si elle est ignorée.
- Agentforce masque par défaut les URL externes des réponses des agents. L’agent les lit en interne mais ne les affiche pas à moins que le domaine ne figure dans la liste d’autorisation des URL de confiance (Trusted URLs).
- L’empreinte totale est d’environ 6 Ko d’Apex, un Cloudflare Worker, trois objets d’identification Salesforce et un sous-agent. Chaque bloc de code a été testé dans une organisation Salesforce Developer Edition en production.
Avant de commencer
Vous aurez besoin de quatre comptes et outils, tous gratuits pour ce tutoriel :
- Un compte Bright Data avec au moins une zone Web Unlocker provisionnée. Les nouveaux comptes incluent des crédits d’essai gratuits, et le volume de requêtes du tutoriel s’inscrit confortablement dans ces crédits.
- Un compte Cloudflare pour le proxy Worker. Aucune carte de crédit n’est requise pour le niveau gratuit ; vous choisirez un sous-domaine
workers.devlors de la première utilisation. - Une organisation Salesforce Developer Edition avec Agentforce activé. Les organisations Developer Edition récentes sont livrées avec Agentforce, Data Cloud et Agentforce Studio pré-activés. Vérifiez que l’application Agentforce Studio apparaît dans votre App Launcher avant de continuer au-delà de la Partie 5 ; si ce n’est pas le cas, vous avez une organisation sans Agentforce et les parties suivantes ne fonctionneront pas.
- Un moyen d’envoyer une requête HTTP de test. La Partie 2 inclut une commande
curlpour vérifier le Worker. macOS, Linux et Windows 11 sont livrés aveccurl. Si vous préférez utiliser une interface graphique, Postman ou Insomnia fonctionnent avec les mêmes en-têtes et corps. Si vous n’avez aucun de ces outils et ne souhaitez pas en installer un, vous pouvez ignorer le test Worker autonome et valider de bout en bout depuis Salesforce dans la Partie 3 à la place. - Profil Administrateur système (ou un profil avec Author Apex, Modify All Data et Customize Application). Une nouvelle organisation Developer Edition vous l’accorde automatiquement. Si vous travaillez dans un sandbox d’entreprise avec un profil verrouillé, utilisez plutôt une nouvelle organisation Developer Edition.
Ce que vous allez construire
Vous allez construire un agent Agentforce appelé Account Briefing Agent. Un commercial saisit une question en langage naturel. L’agent achemine l’invite vers un sous-agent personnalisé, choisit les bons outils, appelle Bright Data via un proxy Cloudflare Worker léger, synthétise un briefing de compte avec des sources attribuées et publie le briefing dans le chat. L’architecture comporte cinq éléments :
- Bright Data Web Unlocker comme primitive de données web. C’est un point de terminaison unique qui accepte la plupart des URL et renvoie du Markdown propre.
- Cloudflare Worker comme proxy entre Salesforce et Bright Data. Le niveau gratuit couvre une petite équipe.
- Salesforce External Credential + Named Credential + Permission Set comme couche d’authentification.
- Apex avec trois classes : un service partagé, plus deux wrappers utilisant
@InvocableMethod(l’annotation qui les rend appelables depuis Agentforce, un par Agent Action). - Sous-agent Agentforce avec deux actions attachées, un bloc d’instructions et une description de classification.
Vue d’ensemble de l’architecture
Voici le flux de requêtes depuis l’invite d’un commercial jusqu’au briefing :
Rep prompt in Agentforce
│
▼
Agent Router ──► Account Web Intelligence subagent
│
├─► Apex: BrightDataNewsAction
│ └─► Named Credential → Cloudflare Worker → Web Unlocker → Google News
│
└─► Apex: BrightDataFetchAction
└─► Named Credential → Cloudflare Worker → Web Unlocker → target URL
│
▼
LLM synthesis ──► Briefing back to the repLe Cloudflare Worker existe parce que Salesforce Apex ne peut pas consommer de manière fiable les réponses HTTP/1.1 en transfert fragmenté (chunked-transfer), et Bright Data utilise l’encodage fragmenté pour toute charge utile dépassant quelques kilo-octets. Le Worker met en mémoire tampon la réponse dans un seul ArrayBuffer et la re-sert avec un en-tête Content-Length explicite. Sans lui, chaque appel depuis Apex renvoie un statut 200 et un corps de zéro octet. La Partie 2 ci-dessous décrit le débogage et la correction.
Bright Data propose plusieurs produits adaptés à ce type de construction : SERP API pour les résultats Google analysés, des scrapers dédiés pour LinkedIn et Crunchbase, et d’autres. Cette construction utilise uniquement Web Unlocker car il fonctionne via le même point de terminaison pour n’importe quelle URL, ce qui simplifie le côté Apex. Le proxy Cloudflare Worker de la Partie 2 couvre tous les points de terminaison de l’API Bright Data de manière égale, donc remplacer ultérieurement par SERP API ou un scraper dédié ne modifie pas le câblage côté Salesforce.
Partie 1 : Configurer Bright Data
Si vous n’avez pas de compte Bright Data, créez-en un sur la page d’inscription Bright Data. La zone Web Unlocker que vous utiliserez se trouve dans la section Web Access API du tableau de bord.
Créer ou noter la zone Web Unlocker
Ouvrez le tableau de bord, accédez à Web Access API dans la navigation de gauche et confirmez qu’une zone Web Unlocker existe. Si votre compte n’en a pas, cliquez sur Create API (en haut à droite) et choisissez Unlocker API dans le menu déroulant. Donnez-lui n’importe quel nom (les noms de zone ne peuvent pas être modifiés après la création, alors choisissez quelque chose de stable comme agentforce_unlocker). Quel que soit le nom choisi, notez-le. Vous le brancherez dans la constante UNLOCKER_ZONE dans BrightDataService.cls à la Partie 4, et dans le test curl de la Partie 2.
La zone Web Unlocker est la primitive utilisée par les deux actions Agentforce.
Créer un token API
Cliquez sur Settings (en bas à gauche) → onglet Users and API keys → Add API key avec la permission User. La clé est affichée une seule fois lors de sa génération, puis masquée. Copiez-la maintenant et conservez-la en lieu sûr ; vous la collerez dans Salesforce à la Partie 3.
C’est tout pour la configuration de Bright Data.
Partie 2 : Déployer le proxy Cloudflare Worker
Avant de configurer Salesforce, vous avez besoin d’un proxy devant Bright Data. La raison est une limitation dans la façon dont Salesforce Apex lit les réponses en transfert fragmenté ; tout développeur Apex effectuant des appels HTTP non triviaux est susceptible de la rencontrer.
Le bug
Le client Http d’Apex Salesforce prend en charge le HTTP standard, avec une lacune pratique : il n’analyse pas de manière fiable les réponses HTTP/1.1 qui utilisent l’encodage de transfert fragmenté sans en-tête Content-Length. Sur une réponse fragmentée, l’appel renvoie Status Code = 200, Content-Type = null, Response Size = 0 bytes, sans exception ni avertissement. getBody() et getBodyAsBlob().toString() renvoient tous deux des chaînes vides.
Le point de terminaison /request de Bright Data utilise l’encodage de transfert fragmenté pour les réponses dépassant quelques kilo-octets. Un appel Web Unlocker sur une petite page de test (le welcome.txt de Bright Data) reste en dessous du seuil et renvoie une réponse avec content-length, qu’Apex analyse correctement. Mais une vraie page (la page d’accueil d’une entreprise, une recherche Google News) dépasse le seuil et est fragmentée, et Apex renvoie un corps vide.
Deux éléments prouvent que c’est côté Apex, pas côté réseau : un appel curl au même point de terminaison avec la même charge utile renvoie un corps de 9 Ko correctement, et le même appel depuis l’exécution anonyme Apex renvoie 0 octet avec Transfer-Encoding: chunked dans les en-têtes de réponse.
La correction est structurelle, pas un changement de configuration : placez un proxy de mise en mémoire tampon entre Salesforce et Bright Data. Le proxy lit entièrement le flux fragmenté de Bright Data, puis re-sert la réponse à Salesforce avec un en-tête Content-Length explicite. Apex analyse cette réponse correctement.
Un Cloudflare Worker est bien adapté pour héberger ce proxy. Il est gratuit pour les faibles volumes, se déploie en quelques minutes, s’exécute en périphérie, et l’intégralité du corps tient en un seul écran de JavaScript.
Créer le Worker
Inscrivez-vous sur le tableau de bord Cloudflare si vous n’avez pas de compte. Dans le tableau de bord, trouvez Workers (il apparaît sous Compute → Workers & Pages selon votre version du tableau de bord). Cliquez sur Create application, puis choisissez Hello World parmi les modèles. Lors de la première utilisation, Cloudflare vous invite à choisir un sous-domaine workers.dev ; choisissez n’importe quoi (c’est votre sous-domaine de développement gratuit). Nommez le Worker quelque chose de facile à retenir ; cette construction utilise bd-proxy. Une fois le placeholder déployé, cliquez sur Edit code.
Sélectionnez tout le code placeholder dans l’éditeur et collez ceci à la place :
/**
* Bright Data to Salesforce Apex proxy.
*
* Salesforce Apex does not reliably consume HTTP/1.1 chunked-transfer
* responses, which is what Bright Data returns for any non-trivial payload.
* This Worker buffers the full response and re-serves it with an explicit
* Content-Length header. Apex parses that response cleanly.
*
* Production deployments typically route external API calls through an
* integration layer like MuleSoft or Heroku. This Worker is the minimal
* stand-in for that role.
*/
export default {
async fetch(request) {
const url = new URL(request.url);
const bdUrl = 'https://api.brightdata.com' + url.pathname + url.search;
// Strip Cloudflare-injected headers we shouldn't forward upstream.
const forwardHeaders = new Headers(request.headers);
forwardHeaders.delete('host');
forwardHeaders.delete('cf-connecting-ip');
forwardHeaders.delete('cf-ray');
forwardHeaders.delete('cf-visitor');
forwardHeaders.delete('x-forwarded-for');
forwardHeaders.delete('x-forwarded-proto');
forwardHeaders.delete('x-real-ip');
try {
const bdResponse = await fetch(bdUrl, {
method: request.method,
headers: forwardHeaders,
body: ['GET', 'HEAD'].includes(request.method)
? undefined
: await request.arrayBuffer(),
});
// Buffer the entire response into a single ArrayBuffer. This collapses
// chunked transfer into a buffer of known length.
const bodyBuffer = await bdResponse.arrayBuffer();
const responseHeaders = new Headers();
const ct = bdResponse.headers.get('Content-Type');
if (ct) responseHeaders.set('Content-Type', ct);
responseHeaders.set('Content-Length', bodyBuffer.byteLength.toString());
const brdStatus = bdResponse.headers.get('x-brd-status-code');
if (brdStatus) responseHeaders.set('X-Brd-Status-Code', brdStatus);
return new Response(bodyBuffer, {
status: bdResponse.status,
headers: responseHeaders,
});
} catch (err) {
return new Response(
JSON.stringify({ error: 'Proxy error', message: err.message }),
{ status: 502, headers: { 'Content-Type': 'application/json' } }
);
}
},
};Les deux lignes qui corrigent l’intégration sont await bdResponse.arrayBuffer() (qui lit l’intégralité du flux fragmenté en mémoire) et l’en-tête Content-Length explicite défini à partir de bodyBuffer.byteLength (Apex analyse le corps correctement à partir de là). Tout le reste gère le transfert des en-têtes : il supprime les en-têtes injectés par Cloudflare pour les requêtes entrantes et préserve le code de statut en amont pour les réponses sortantes.
Cliquez sur Deploy (en haut à droite). Cloudflare vous donne une URL comme https://<worker-name>.<your-subdomain>.workers.dev. Copiez-la ; vous aurez besoin de cette URL pour Salesforce à la Partie 3.
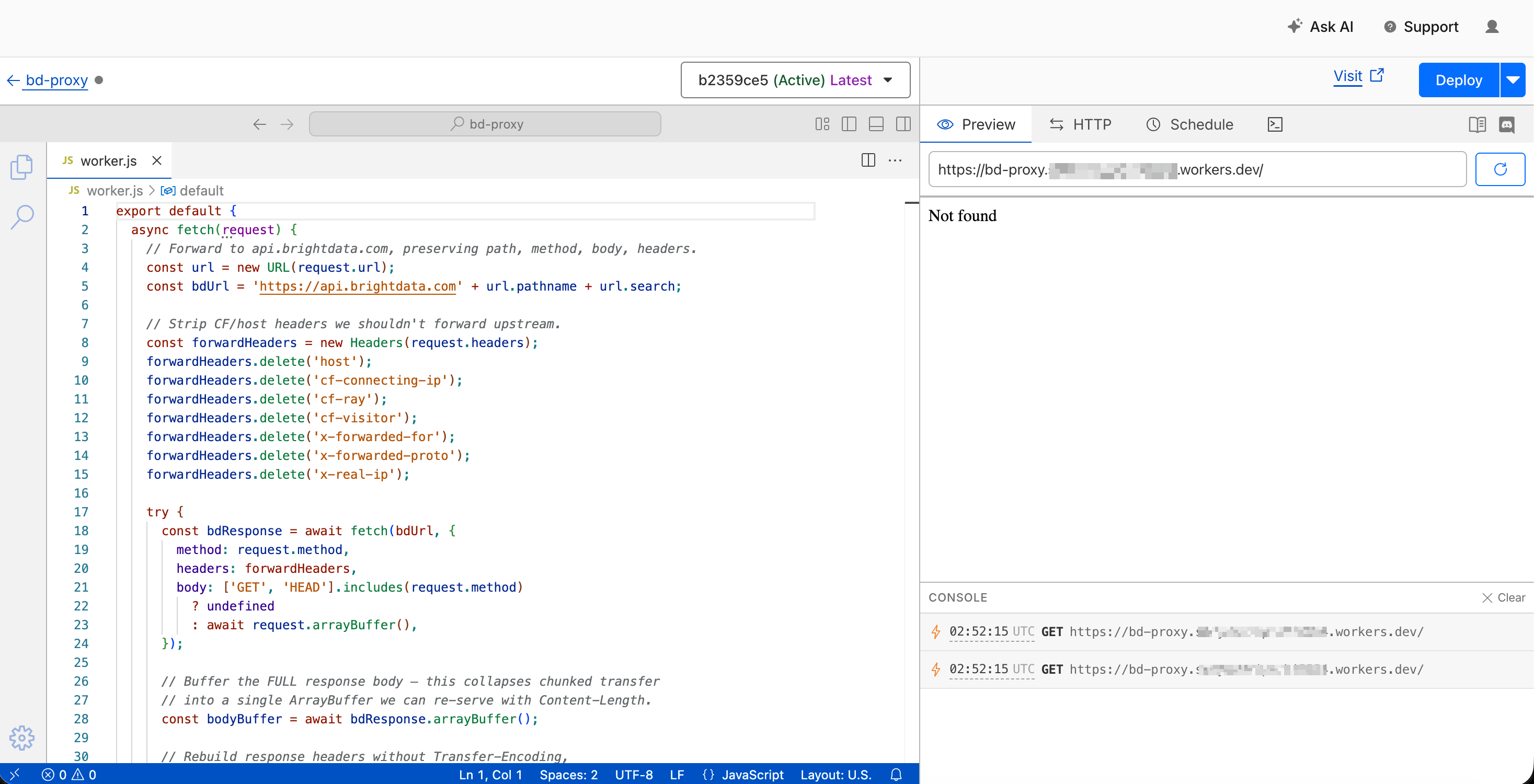
Les lignes importantes : await bdResponse.arrayBuffer() lit l’intégralité du flux fragmenté en mémoire, et l’en-tête Content-Length explicite sur l’objet de réponse signifie qu’Apex peut analyser le corps correctement.
Vérifier que le Worker fonctionne
Depuis votre terminal local, exécutez un test rapide contre le Worker. Remplacez l’URL par la vôtre et utilisez votre propre token API Bright Data :
curl -i https://<your-worker>.workers.dev/request \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <your-bd-token>" \
-d '{"zone":"mcp_unlocker","url":"https://www.salesforce.com","format":"raw","data_format":"markdown"}' \
| head -20Les en-têtes de réponse doivent inclure un statut 200 et un en-tête content-length: <some-number>. Ils ne doivent pas inclure transfer-encoding: chunked. C’est la preuve que le proxy fonctionne correctement. Voici les échecs courants : 401 signifie que votre token Bright Data est incorrect (vérifiez à nouveau l’en-tête Authorization: Bearer ...) ; 502 du Worker signifie que votre code Worker n’a pas été déployé (vérifiez à nouveau l’étape Deploy) ; un en-tête transfer-encoding: chunked qui apparaît encore signifie que vous avez manqué les lignes arrayBuffer() + Content-Length dans le code source du Worker.
Dans un déploiement en entreprise, ce Worker serait remplacé par un niveau d’intégration de qualité production : MuleSoft fonctionnant sur Anypoint, un microservice Heroku, ou une passerelle API personnalisée avec authentification, observabilité et limitation de débit. Le Worker est un substitut minimal pour ce rôle, mais le même modèle fonctionne dans ces configurations de production.
Partie 3 : Configurer les identifiants Salesforce
Le modèle External Credential de Salesforce divise un identifiant tiers en trois objets : un External Credential (contient le token), un Named Credential (contient le point de terminaison) et un Permission Set (accorde aux utilisateurs l’accès au principal de l’External Credential).
Créer l’External Credential
Cliquez sur l’icône d’engrenage (en haut à droite de n’importe quelle page Salesforce) → Setup. Dans Setup, utilisez la zone Quick Find en haut du rail gauche et recherchez Named Credentials. Cliquez sur le résultat. Sur la page qui se charge, cliquez sur l’onglet External Credentials, puis sur New.
Remplissez les champs suivants :
- Label :
Bright Data Cred - Name :
Bright_Data_Cred(rempli automatiquement) - Authentication Protocol :
Custom
Cliquez sur Save.
Sur la page de détail, trouvez la section Principals et cliquez sur New :
- Parameter Name :
BrightDataPrincipal - Sequence Number :
1 - Identity Type :
Named Principal
Dans la section Authentication Parameters sous le principal, ajoutez :
- Name :
api_key - Value : collez votre token API Bright Data
Cliquez sur Save.
De retour sur la page External Credential, trouvez la section Custom Headers et cliquez sur New :
- Name :
Authorization - Value :
Bearer {!$Credential.Bright_Data_Cred.api_key} - Sequence Number :
1
⚠️ Le champ de fusion doit correspondre aux noms que vous avez définis.
Bright_Data_Creddans la formule doit correspondre au nom API de l’External Credential.api_keydoit correspondre au nom du paramètre d’authentification que vous avez défini dans le Principal. Si vous avez renommé l’un ou l’autre, modifiez la formule en conséquence.
C’est essentiel : cochez la case Allow Formulas in HTTP Header sur cet en-tête personnalisé. Pour la trouver : après avoir enregistré la ligne d’en-tête, cliquez sur la ligne pour ouvrir sa vue de détail. La case à cocher se trouve sur cette page de détail, pas sur la page parent External Credential. Si vous l’ignorez, Salesforce envoie la chaîne littérale Bearer {!$Credential...} à Bright Data, qui renvoie 401, et le message d’erreur ne vous indique pas quelle case à cocher vous avez manquée. Cliquez sur Save.
⚠️ Vous rencontrerez une case à cocher du même nom dans la section suivante. « Allow Formulas in HTTP Header » apparaît à deux endroits. La Case A est celle que vous venez de cocher (sur la page de détail de l’en-tête personnalisé). La Case B se trouve dans les options d’appel (Callout Options) du Named Credential. Les deux doivent être cochées. Si une seule est cochée, le champ de fusion est envoyé comme texte littéral et Bright Data renvoie 401.
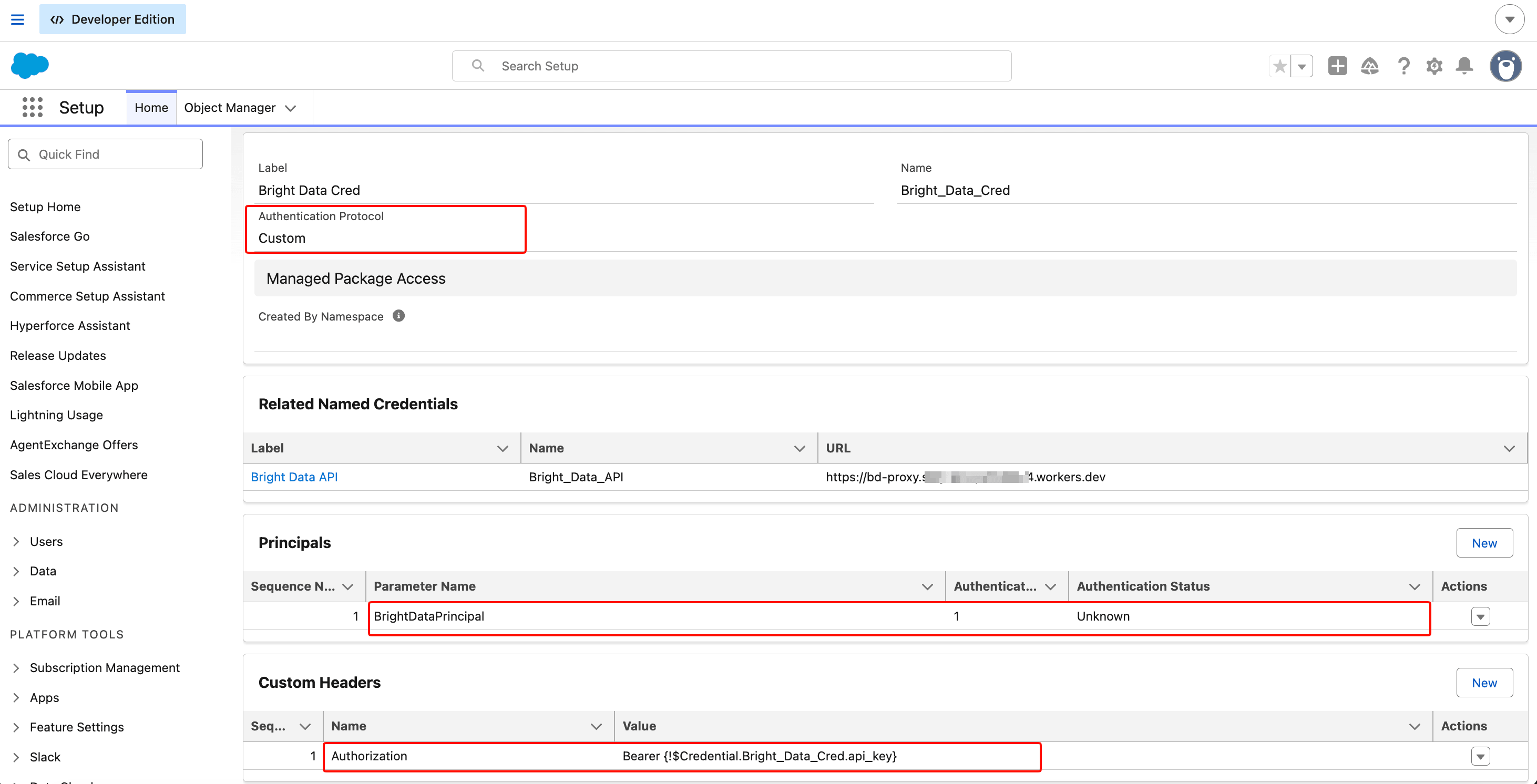
La valeur du champ de fusion de l’en-tête personnalisé est la partie qui résout le token API au moment de la requête. La case à cocher Allow Formulas in HTTP Header (non visible à cette profondeur ; elle se trouve sur la page de détail de l’en-tête) doit être cochée, sinon le champ de fusion est envoyé comme texte littéral.
Créer le Named Credential
Dans la même section Named Credentials, revenez à l’onglet Named Credentials et cliquez sur New :
- Label :
Bright Data API - Name :
Bright_Data_API - URL : collez l’URL de votre Cloudflare Worker (par exemple
https://bd-proxy.<your-subdomain>.workers.dev) - Enabled for Callouts : coché
- External Credential : sélectionnez
Bright Data Cred
Sous Callout Options, définissez ces options :
- Generate Authorization Header : décoché (vous fournissez le vôtre via l’en-tête personnalisé)
- Allow Formulas in HTTP Header : coché (pour que le champ de fusion soit résolu)
- Allow Formulas in HTTP Body : coché (pour que les corps JSON dynamiques fonctionnent)
Cliquez sur Save.
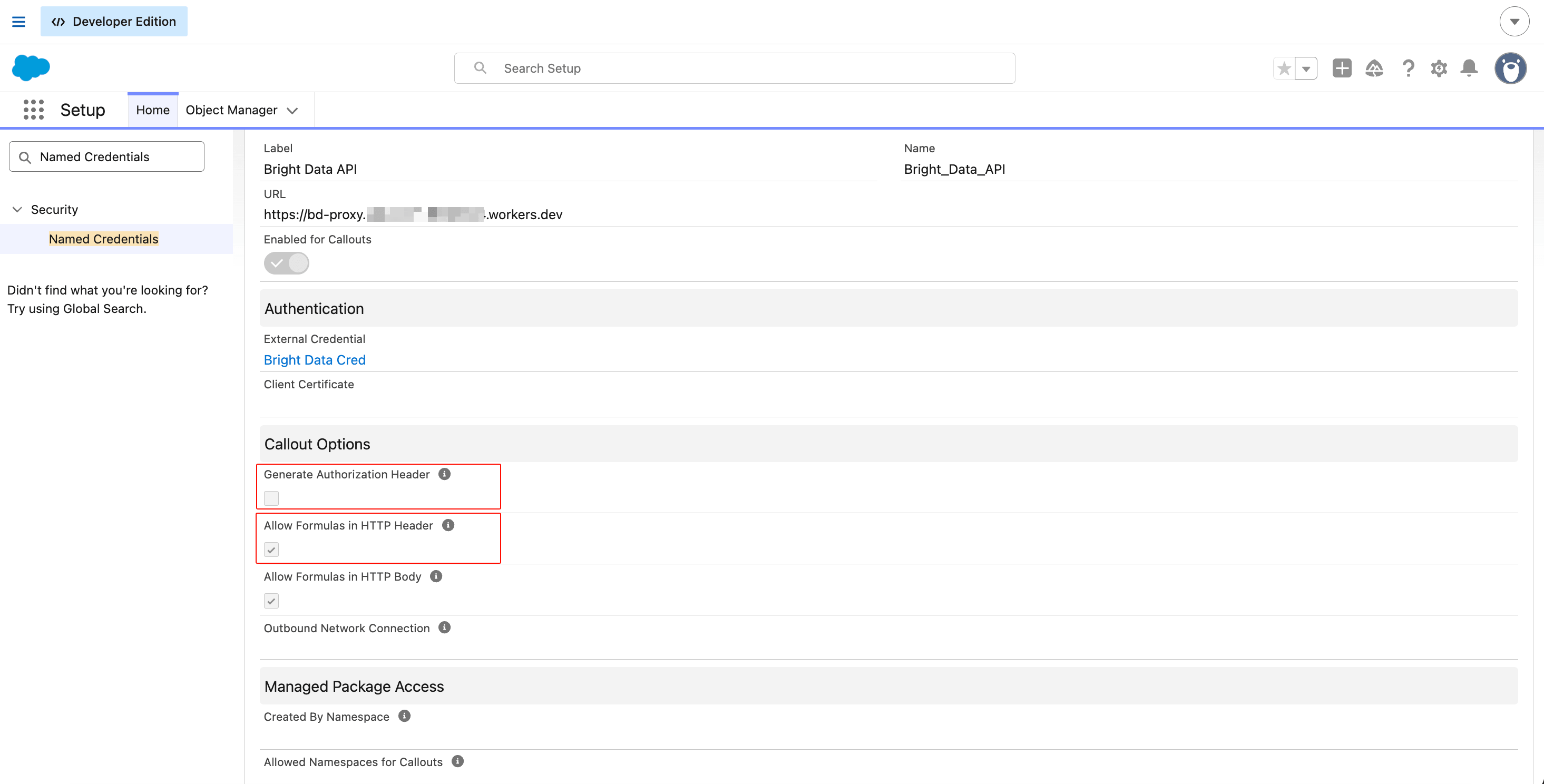
L’URL pointe vers le Cloudflare Worker, pas directement vers api.brightdata.com. C’est ainsi que fonctionne la correction du transfert fragmenté. Les trois états des cases à cocher sont importants indépendamment ; en avoir une incorrecte casse l’appel sans avertissement.
Créer le Permission Set
Salesforce bloque même les Administrateurs système d’utiliser le principal d’un External Credential jusqu’à ce qu’un Permission Set accorde explicitement l’accès. Si vous ignorez cette étape, Apex renvoie une erreur INVALID_OPERATION sans diagnostic utile.
Dans Setup, recherchez Permission Sets et cliquez sur New :
- Label :
Bright Data Access - API Name :
Bright_Data_Access - License : laisser vide
Cliquez sur Save.
Sur la page de détail, faites défiler jusqu’à External Credential Principal Access et cliquez sur Edit. Déplacez Bright_Data_Cred - BrightDataPrincipal de la liste Available vers la liste Enabled. Cliquez sur Save.
De retour sur la page de détail, cliquez sur Manage Assignments en haut, puis sur Add Assignments, sélectionnez votre propre utilisateur et complétez l’affectation.
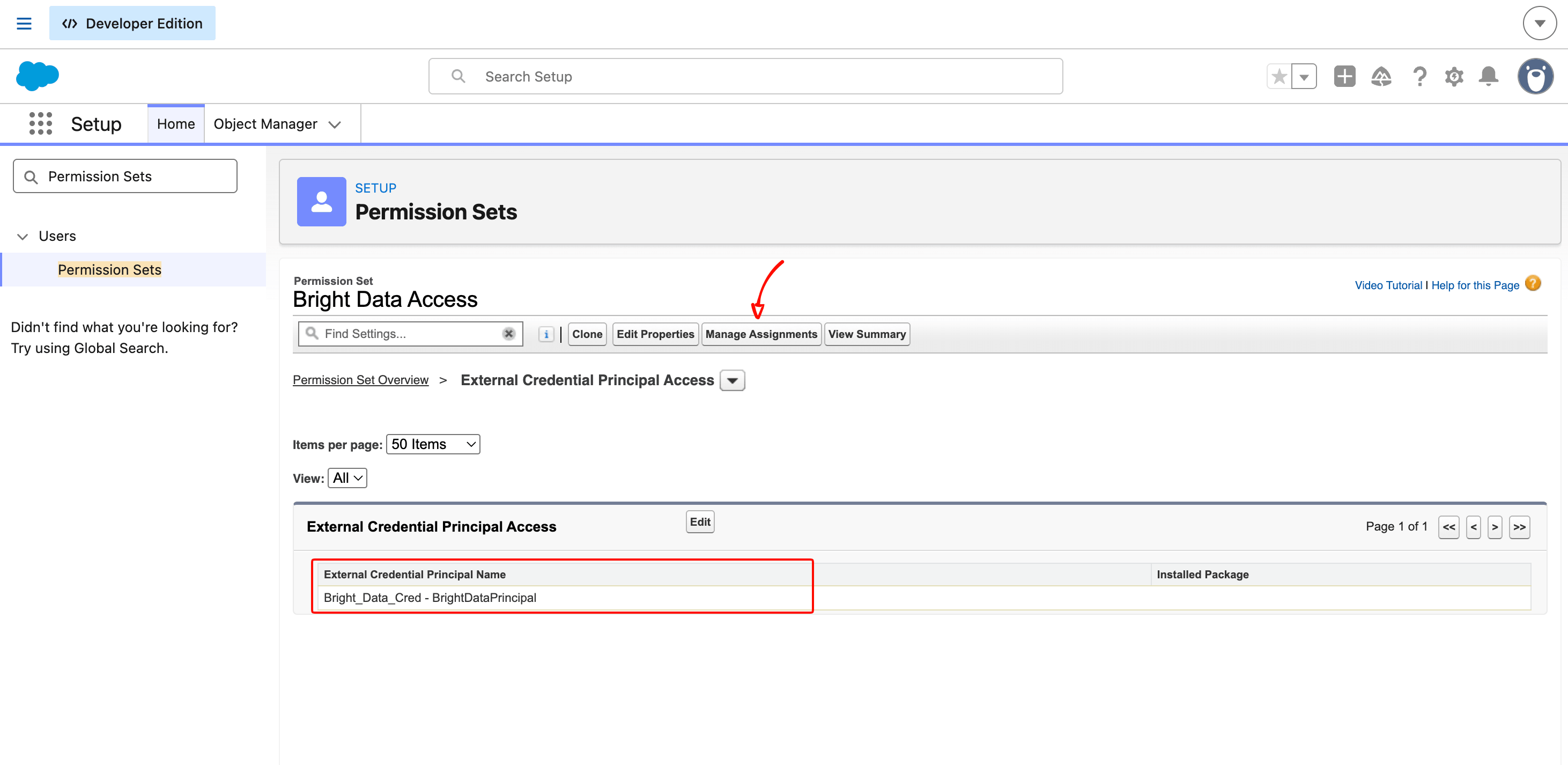
Le Permission Set est le mécanisme de contrôle qui vous permet de définir quels utilisateurs peuvent exécuter du code qui appelle Bright Data. Dans une organisation d’entreprise, cela serait attribué via un Permission Set Group à des utilisateurs de service ou des profils spécifiques, pas à des administrateurs individuels.
Vérifier le câblage avant de continuer
Cliquez sur l’icône d’engrenage (en haut à droite) → Developer Console. Elle s’ouvre dans une nouvelle fenêtre de navigateur. Une fois cette fenêtre active, ouvrez Apex anonyme via Debug → Open Execute Anonymous Window. Collez le code ci-dessous, puis cliquez sur Execute :
HttpRequest req = new HttpRequest();
req.setEndpoint('callout:Bright_Data_API/request');
req.setMethod('POST');
req.setHeader('Content-Type', 'application/json');
req.setBody('{"zone":"mcp_unlocker","url":"https://geo.brdtest.com/welcome.txt?product=unlocker&method=api","format":"raw"}');
req.setTimeout(60000);
HttpResponse res = new Http().send(req);
System.debug('STATUS: ' + res.getStatusCode());
System.debug('BODY: ' + res.getBody().left(500));Après avoir cliqué sur Execute, une nouvelle ligne de journal apparaît dans le panneau inférieur de la Developer Console. Double-cliquez sur cette ligne pour ouvrir la visionneuse de journaux, puis cochez Debug Only en bas (ou tapez USER_DEBUG dans la zone de filtre). Vous devriez voir deux lignes affichant vos valeurs STATUS et BODY. Recherchez STATUS: 200 et un corps contenant le texte de bienvenue Bright Data. Si vous voyez 401, vérifiez à nouveau la case « Allow Formulas in HTTP Header » de l’en-tête personnalisé (celle sur la page de détail de l’en-tête, et celle dans les Callout Options du Named Credential). Si vous voyez INVALID_OPERATION, vérifiez à nouveau l’affectation du Permission Set.
Partie 4 : Écrire la couche Apex
Apex n’enregistre qu’un seul @InvocableMethod par classe comme action appelable par Agentforce. C’est pourquoi l’intégration utilise trois classes au lieu d’une : un service partagé pour la plomberie HTTP, et une classe par Agent Action.
Collez chaque bloc tel quel. La principale ligne que vous pourriez vouloir modifier est private static final String UNLOCKER_ZONE = 'mcp_unlocker'; dans BrightDataService.cls si votre zone Bright Data a un nom différent (Partie 1).
Dans Setup, recherchez Apex Classes dans Quick Find et cliquez sur le résultat. Cliquez sur New. L’éditeur s’ouvre avec une classe placeholder comme public class YourClassName {}. Cliquez sur la zone de code (la grande zone de texte, pas le panneau Version Settings à droite), sélectionnez tout le texte placeholder, appuyez sur Supprimer, puis collez le code source ci-dessous. Le nom de la classe est tiré du code source, vous n’avez donc pas à remplir d’autres champs. Cliquez sur Save.
Créez les trois classes dans cet ordre, car BrightDataNewsAction et BrightDataFetchAction référencent toutes deux BrightDataService. Le service doit être enregistré en premier :
BrightDataService.cls : la couche HTTP et d’analyse partagée
Cette classe contient la plomberie HTTP et les deux méthodes d’aide (searchNews et fetchUrlAsMarkdown) que les deux Agent Actions appellent. Aucun @InvocableMethod n’est présent ici ; cette annotation se trouve dans les classes wrapper d’action ci-dessous. Voici la classe :
public with sharing class BrightDataService {
private static final String BD_ENDPOINT = 'callout:Bright_Data_API/request';
private static final String UNLOCKER_ZONE = 'mcp_unlocker';
private static final Integer CALLOUT_TIMEOUT = 60000;
private static final Integer MAX_RESPONSE_CHARS = 50000;
/**
* Fetches the Google News results page for `companyName` (past month) as
* clean Markdown via Bright Data Web Unlocker. The LLM downstream is
* responsible for extracting individual articles, sources, and dates.
*/
public static String searchNews(String companyName) {
String googleNewsUrl =
'https://www.google.com/search?q='
+ EncodingUtil.urlEncode(companyName, 'UTF-8')
+ '&tbm=nws&tbs=qdr:m';
Map<String, Object> body = new Map<String, Object>{
'zone' => UNLOCKER_ZONE,
'url' => googleNewsUrl,
'format' => 'raw',
'data_format' => 'markdown'
};
HttpResponse res = sendRequest(JSON.serialize(body));
if (res.getStatusCode() != 200) {
return 'Bright Data returned status '
+ res.getStatusCode() + ': ' + res.getBody().left(300);
}
String content = res.getBody();
if (String.isBlank(content)) {
return 'No content returned for "' + companyName
+ '". The page may have been empty or blocked.';
}
if (content.length() > MAX_RESPONSE_CHARS) {
content = content.left(MAX_RESPONSE_CHARS)
+ '\n\n[Content truncated at ' + MAX_RESPONSE_CHARS + ' characters]';
}
return 'Google News results for "' + companyName
+ '" (past month). Extract article titles, sources, '
+ 'publication dates, and URLs from the Markdown below:\n\n'
+ content;
}
/**
* Fetches any URL via Bright Data Web Unlocker and returns the page as
* clean Markdown.
*/
public static String fetchUrlAsMarkdown(String url) {
Map<String, Object> body = new Map<String, Object>{
'zone' => UNLOCKER_ZONE,
'url' => url,
'format' => 'raw',
'data_format' => 'markdown'
};
HttpResponse res = sendRequest(JSON.serialize(body));
if (res.getStatusCode() != 200) {
return 'Web Unlocker returned status '
+ res.getStatusCode() + ': ' + res.getBody().left(300);
}
String content = res.getBody();
if (content.length() > MAX_RESPONSE_CHARS) {
content = content.left(MAX_RESPONSE_CHARS)
+ '\n\n[Content truncated at ' + MAX_RESPONSE_CHARS + ' characters]';
}
return content;
}
private static HttpResponse sendRequest(String jsonBody) {
HttpRequest req = new HttpRequest();
req.setEndpoint(BD_ENDPOINT);
req.setMethod('POST');
req.setHeader('Content-Type', 'application/json');
req.setBody(jsonBody);
req.setTimeout(CALLOUT_TIMEOUT);
return new Http().send(req);
}
}La classe n’a pas de @InvocableMethod, intentionnellement. C’est la couche HTTP partagée que les deux classes d’action utilisent.
BrightDataNewsAction.cls : l’action de recherche d’actualités
Agentforce appelle ce wrapper invocable léger lorsque l’agent décide de rechercher des actualités. Il valide l’entrée, délègue le travail HTTP à BrightDataService.searchNews() et renvoie le résultat dans la forme Response qu’Agentforce attend. Voici la classe :
public with sharing class BrightDataNewsAction {
public class Request {
@InvocableVariable(
required=true
label='Company Name'
description='The name of the company to search news about. E.g. "Salesforce" or "Acme Corp".')
public String companyName;
}
public class Response {
@InvocableVariable(
label='News Results'
description='Formatted summary of recent news with titles, sources, dates, URLs, and snippets.')
public String newsResults;
}
@InvocableMethod(
label='Search Recent Company News (Bright Data)'
description='Searches Google News via Bright Data for recent (past month) articles about a specific named company. Use this whenever the user asks about recent news, announcements, press releases, funding rounds, acquisitions, leadership changes, or current events for a named company.'
callout=true)
public static List<Response> searchCompanyNews(List<Request> requests) {
List<Response> responses = new List<Response>();
for (Request req : requests) {
Response resp = new Response();
try {
resp.newsResults = String.isBlank(req.companyName)
? 'Error: A company name is required.'
: BrightDataService.searchNews(req.companyName);
} catch (Exception e) {
resp.newsResults = 'Error fetching news for ' + req.companyName + ': ' + e.getMessage();
}
responses.add(resp);
}
return responses;
}
}Le moteur de raisonnement d’Agentforce lit le champ description de l’annotation @InvocableMethod pour décider quand appeler cette action.
BrightDataFetchAction.cls : l’action de récupération d’URL
Le second wrapper invocable suit le même modèle que l’action d’actualités, mais il récupère n’importe quelle URL mentionnée par le commercial. Le bloc de validation rejette également les entrées malformées avant l’appel. Voici la classe :
public with sharing class BrightDataFetchAction {
public class Request {
@InvocableVariable(
required=true
label='URL to Fetch'
description='The full URL of a web page to retrieve. Must start with http:// or https://.')
public String url;
}
public class Response {
@InvocableVariable(
label='Page Content'
description='Clean Markdown representation of the page content.')
public String pageContent;
}
@InvocableMethod(
label='Fetch Web Page as Markdown (Bright Data)'
description='Retrieves the content of any web URL via Bright Data Web Unlocker and returns it as clean Markdown. Use this when you need to read a specific URL: a company homepage, blog post, press release, or any link the user mentions.'
callout=true)
public static List<Response> fetchUrlAsMarkdown(List<Request> requests) {
List<Response> responses = new List<Response>();
for (Request req : requests) {
Response resp = new Response();
try {
if (String.isBlank(req.url)
|| (!req.url.startsWithIgnoreCase('http://')
&& !req.url.startsWithIgnoreCase('https://'))) {
resp.pageContent = 'Error: A valid URL starting with http:// or https:// is required.';
} else {
resp.pageContent = BrightDataService.fetchUrlAsMarkdown(req.url);
}
} catch (Exception e) {
resp.pageContent = 'Error fetching ' + req.url + ': ' + e.getMessage();
}
responses.add(resp);
}
return responses;
}
}Après avoir enregistré les trois classes, Setup → Apex Classes devrait les afficher comme Active.
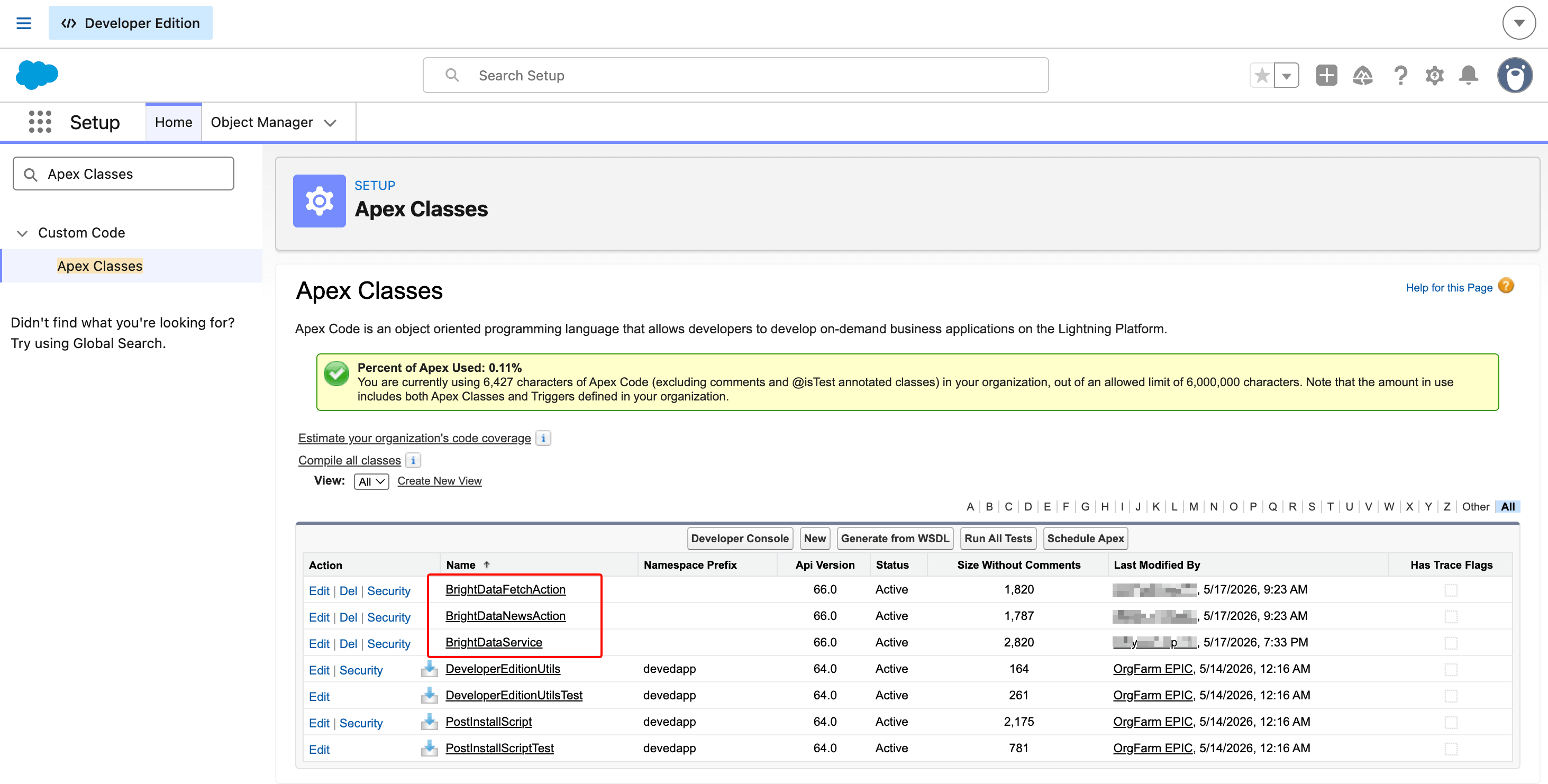
L’empreinte Apex totale est d’environ 6,4 Ko répartis sur trois classes. Le service partagé plus une classe d’action par Agent Action est le modèle Salesforce standard lorsque plusieurs invocables sont nécessaires.
Tester les actions
Avant de connecter les actions à Agentforce, confirmez qu’elles fonctionnent de bout en bout. Dans Apex anonyme :
BrightDataNewsAction.Request r = new BrightDataNewsAction.Request();
r.companyName = 'Salesforce';
List<BrightDataNewsAction.Response> out =
BrightDataNewsAction.searchCompanyNews(new List<BrightDataNewsAction.Request>{ r });
System.debug('LENGTH: ' + out[0].newsResults.length());
System.debug('PREVIEW: ' + out[0].newsResults.left(800));Attendez-vous à ce que LENGTH soit compris entre 5 000 et 10 000, avec un aperçu qui commence par le préfixe de la classe de service puis le Markdown Google News. Si vous voyez LENGTH: 0 ou une chaîne d’erreur, revenez à l’étape de vérification de la Partie 3.
Partie 5 : Enregistrer les actions comme Assets Agentforce
Les classes Apex ne sont pas visibles par Agentforce par défaut. Chaque @InvocableMethod doit être enregistré comme Agent Action (nouveau label : Agentforce Asset) avant que l’agent puisse l’appeler.
Dans Setup, recherchez Agent Actions (ou Agentforce Assets, selon le label de votre organisation) et cliquez sur New Agent Action. Vous ferez cela deux fois, une fois pour chaque classe d’action.
Pour l’action d’actualités, remplissez :
- Reference Action Type :
Apex - Reference Action Category :
Invocable Methods - Reference Action :
BrightDataNewsAction.searchCompanyNews
Sur l’écran suivant, remplissez ces champs :
- Agent Action Label : conservez le
Search Recent Company News (Bright Data)auto-rempli - Agent Action Description : conservez la description auto-remplie (elle provient de l’annotation
@InvocableMethod) - Show loading text for this action : coché
- Loading Text :
Searching recent news…
Salesforce détecte automatiquement l’entrée (companyName, requis, String) et la sortie (newsResults, String). Laissez le mappage auto-détecté. Cliquez sur Finish.
Répétez pour l’action de récupération :
- Reference Action :
BrightDataFetchAction.fetchUrlAsMarkdown - Loading Text :
Fetching web page… - L’entrée est
url(requis, String). La sortie estpageContent(String).
Une fois les deux enregistrées, la liste Agent Actions affiche les deux avec le statut Active.
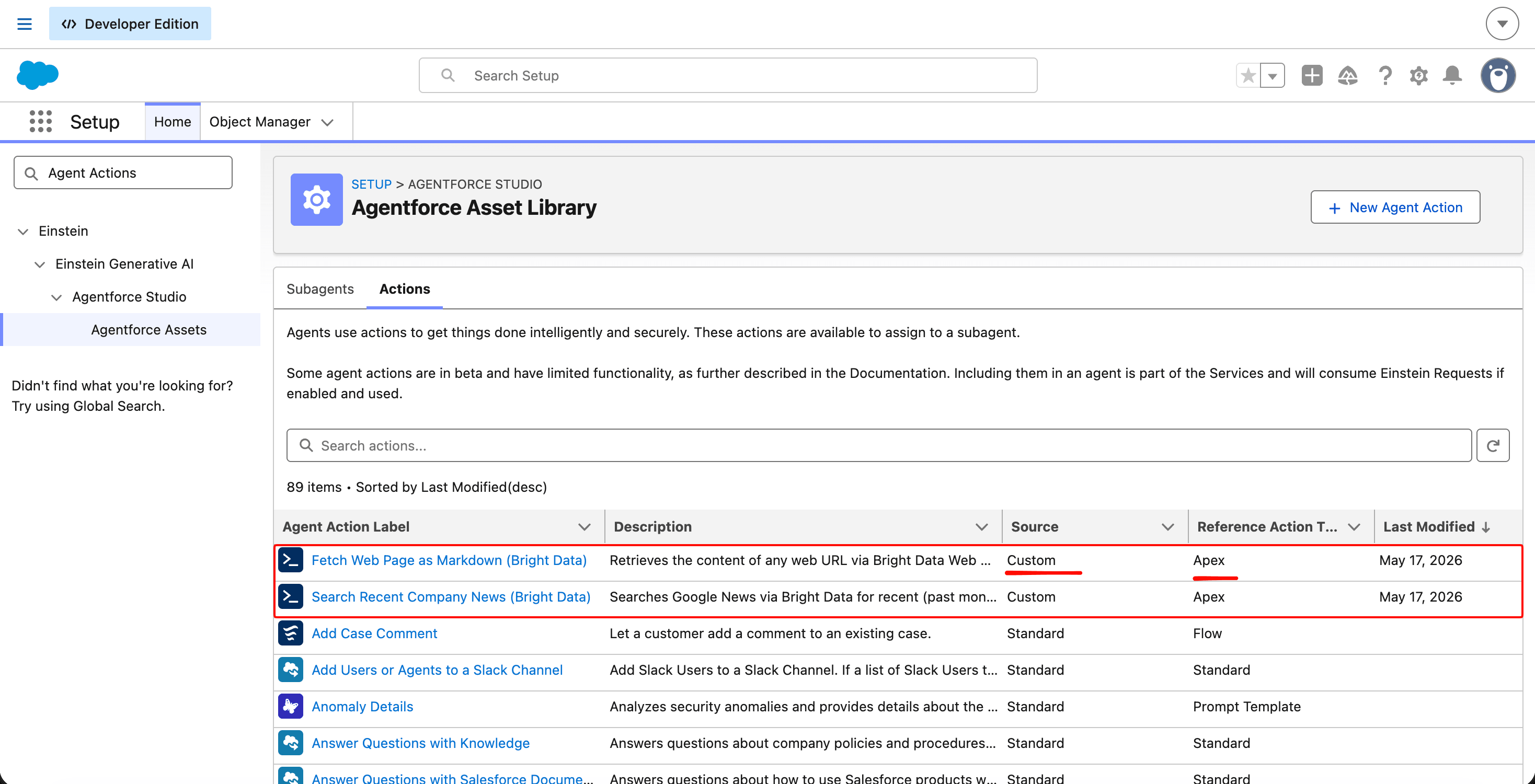
Les actions personnalisées apparaissent dans la même bibliothèque d’assets que les actions standard livrées avec le modèle Employee. Le moteur de raisonnement d’Agentforce les traite de manière égale ; la colonne source est une métadonnée, pas un commutateur comportemental.
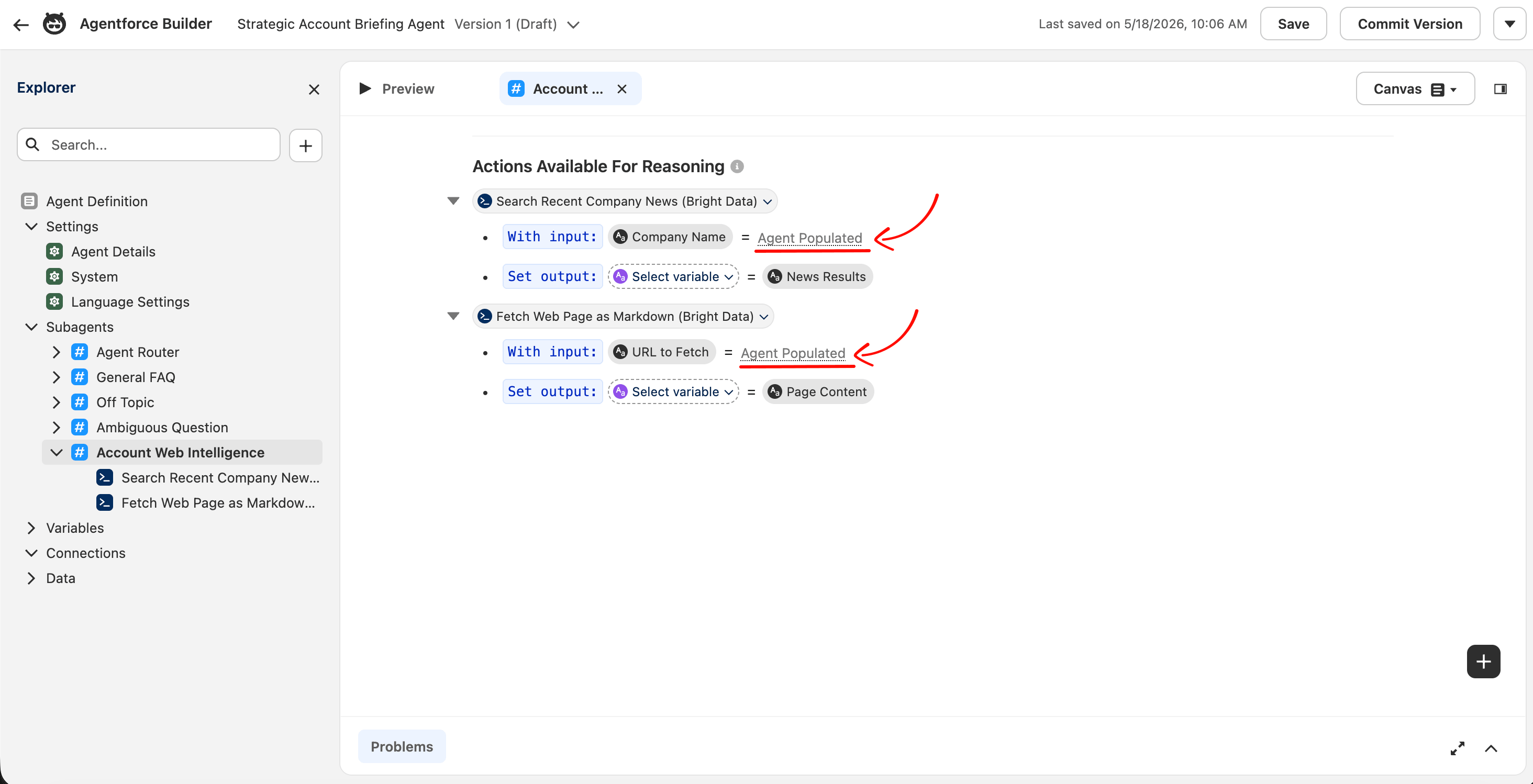
« Agent Populated » est le libellé utilisé par Salesforce lorsqu’une entrée est renseignée par le raisonnement du LLM au moment de l’exécution. C’est l’état dont l’intégration a besoin pour les agents pilotés par chat.
Partie 7 : Tester l’agent
Dans l’Agent Builder, cliquez sur l’onglet Preview. L’interface de chat s’ouvre avec une bannière jaune contenant un bouton Reset Simulator. Si la bannière apparaît, cliquez dessus. La réinitialisation est importante car la mémoire de conversation du simulateur est propre à chaque session, et réinitialiser entre les tests est le moyen le plus simple d’obtenir des traces indépendantes. Les quatre tests ci-dessous vérifient le routage, les appels à action unique, les appels parallèles et le mode d’échec honnête.
Si l’onglet Preview est grisé, recherchez un bouton Activate en haut du canvas et activez-le. L’activation ici ne fait qu’activer l’agent pour le Preview/Simulator ; les utilisateurs finaux ne peuvent pas y accéder tant que vous ne l’avez pas également assigné via Setup → Agentforce Studio → Connections, ce qui est hors du périmètre de cette configuration.
Test 1 : Recherche d’actualités uniquement
Pour vérifier que l’action d’actualités s’exécute de bout en bout, saisissez :
What's new at Salesforce in the past month?L’agent devrait router vers Account Web Intelligence, afficher un état de chargement « Searching recent news… », puis retourner un résumé d’actualités thématique avec les noms des sources cités en ligne. Ouvrez l’onglet Trace en bas du canvas pour voir la chaîne de raisonnement complète. Le panneau Interaction Summary à droite de l’aperçu affiche la même chaîne sous forme compacte : quel sous-agent le Router a sélectionné, quelles actions ont été invoquées et comment l’agent a raisonné.
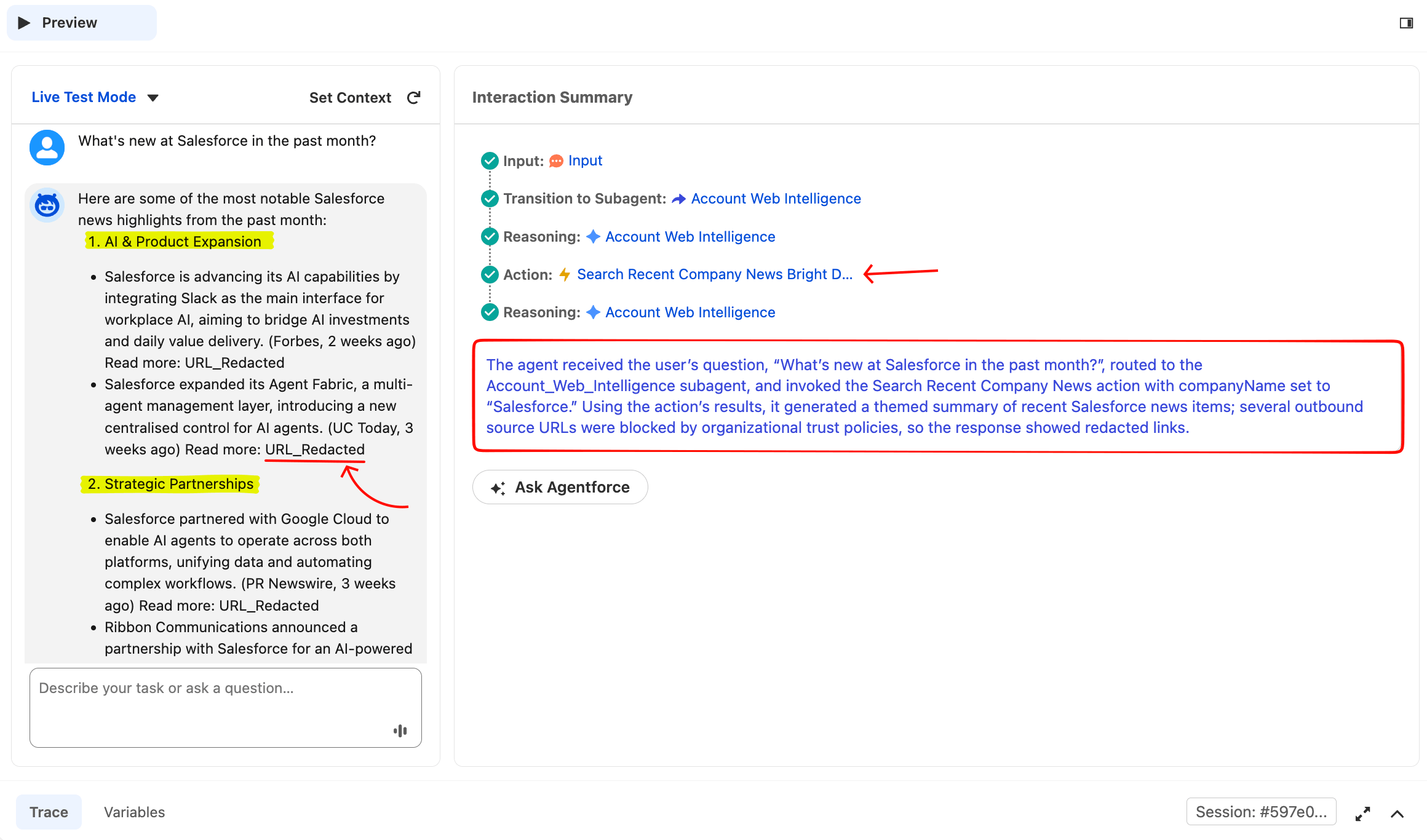
Il s’agit d’une exécution propre à action unique. Le Router a correctement routé, l’agent a extrait companyName="Salesforce" de la question en langage naturel, a appelé l’action et a synthétisé un résumé thématique. Les espaces réservés URL_Redacted sont le résultat de la politique de confiance des URL de Salesforce (expliquée dans la section « Gouvernance d’entreprise » ci-dessous).
Le routage est piloté par LLM, donc dans de rares cas, la description du sous-agent Account Web Intelligence peut être supplantée par une description similaire dans le modèle (par ex., General FAQ). Si votre premier test route vers le mauvais sous-agent, ajoutez des mots-clés plus spécifiques à la description (« company news », « press release », « recent funding », « fetch URL »), enregistrez, cliquez sur Reset Simulator et réessayez. Le routeur reclassifie à chaque nouvelle session.
Test 2 : Récupération d’URL uniquement
Pour vérifier qu’une question avec une URL directe route vers l’action de récupération, cliquez sur Reset Simulator et saisissez :
Read https://www.snowflake.com and tell me what they doL’agent devrait appeler l’action Fetch, et non l’action d’actualités. Une question différente route vers un outil différent.
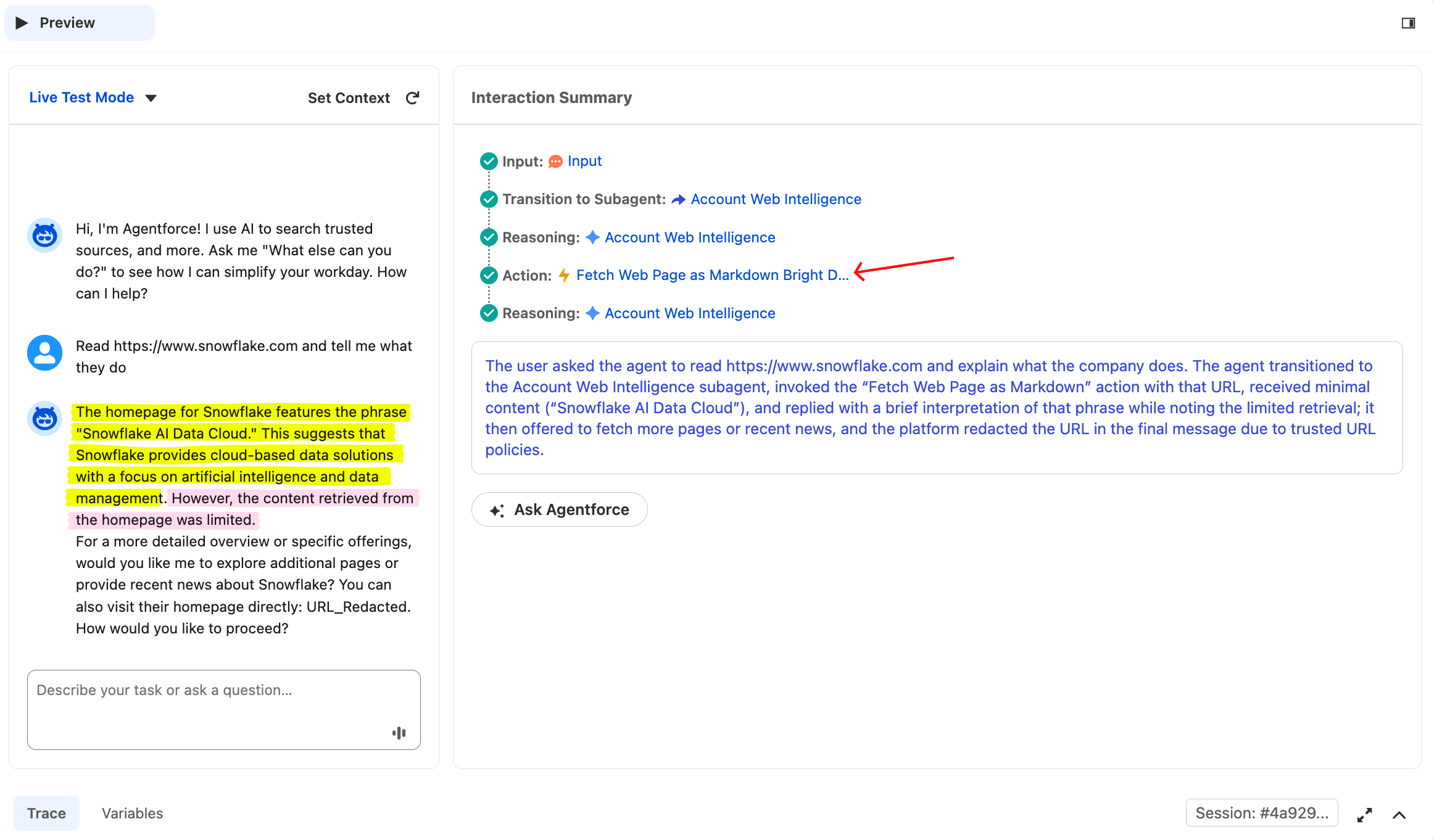
C’est le même agent, mais une question différente route vers un outil différent. L’Agent Router a classifié la question comme une récupération d’URL (et non une recherche d’actualités) et n’a appelé que l’action de récupération. C’est la preuve que l’agent raisonne, et non qu’il exécute un pipeline fixe.
Test 3 : Les deux actions en parallèle
Le test 3 réussit lorsque les deux actions sont invoquées, qu’elles retournent toutes les deux 200 ou non. Si les deux réussissent, vous verrez un briefing combiné propre. Si l’une échoue (comme dans la capture d’écran ci-dessous), l’agent devrait tout de même produire un briefing en utilisant celle qui a réussi. Cela démontre la règle 5. Après Reset Simulator, saisissez :
Give me a briefing on Anthropic, recent news plus what their homepage says about their productL’agent devrait appeler les deux actions, puis synthétiser un briefing combiné. La Trace affiche deux lignes Action distinctes dans la même chaîne de raisonnement.
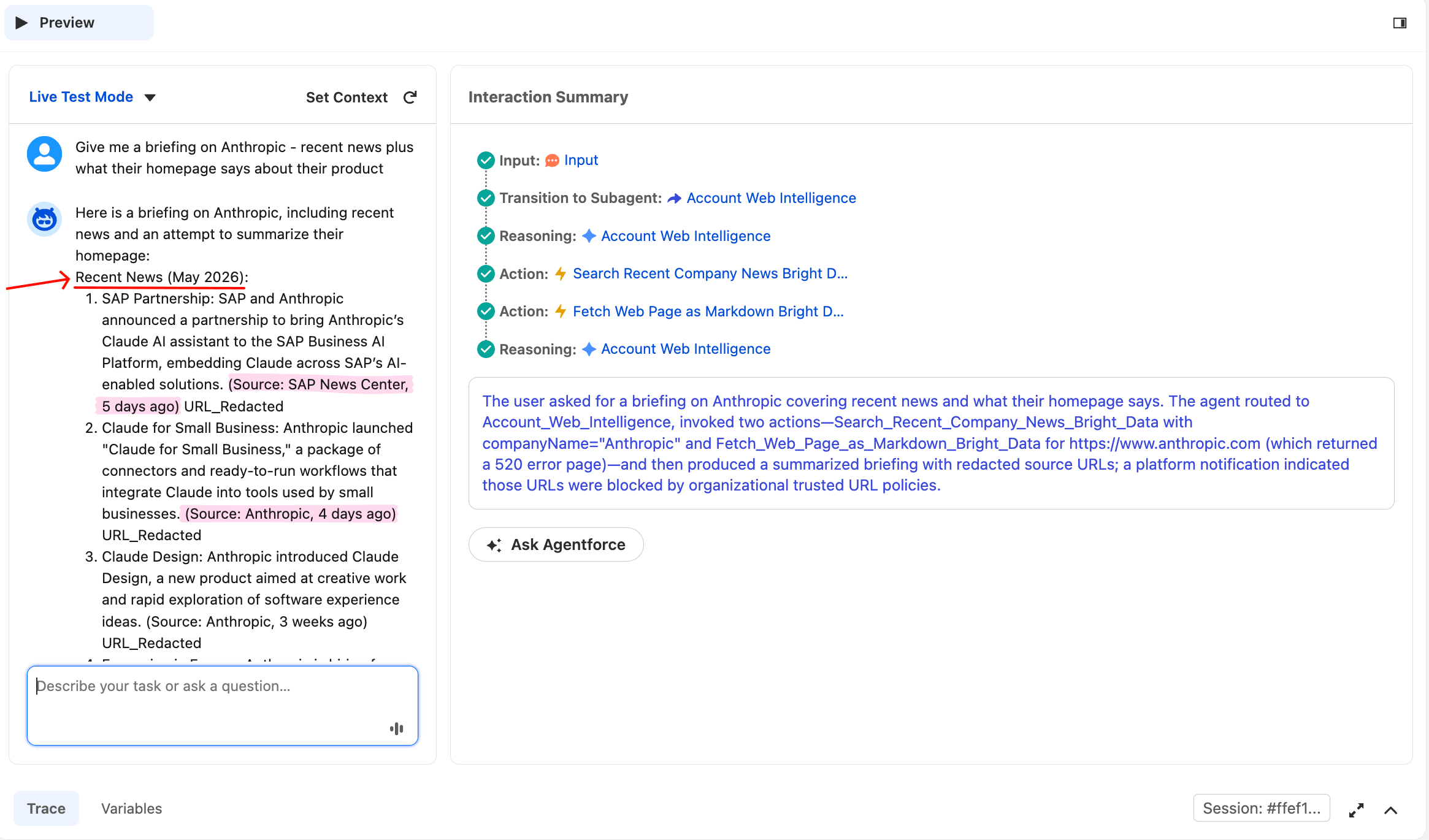
L’agent a appelé les deux actions à partir d’une seule question utilisateur. La section d’actualités sur Anthropic provient du Web Unlocker de Bright Data qui appelle Google News.
La même réponse se poursuit ci-dessous avec la section page d’accueil, où cette exécution a rencontré un échec partiel qu’il vaut la peine d’examiner en détail :
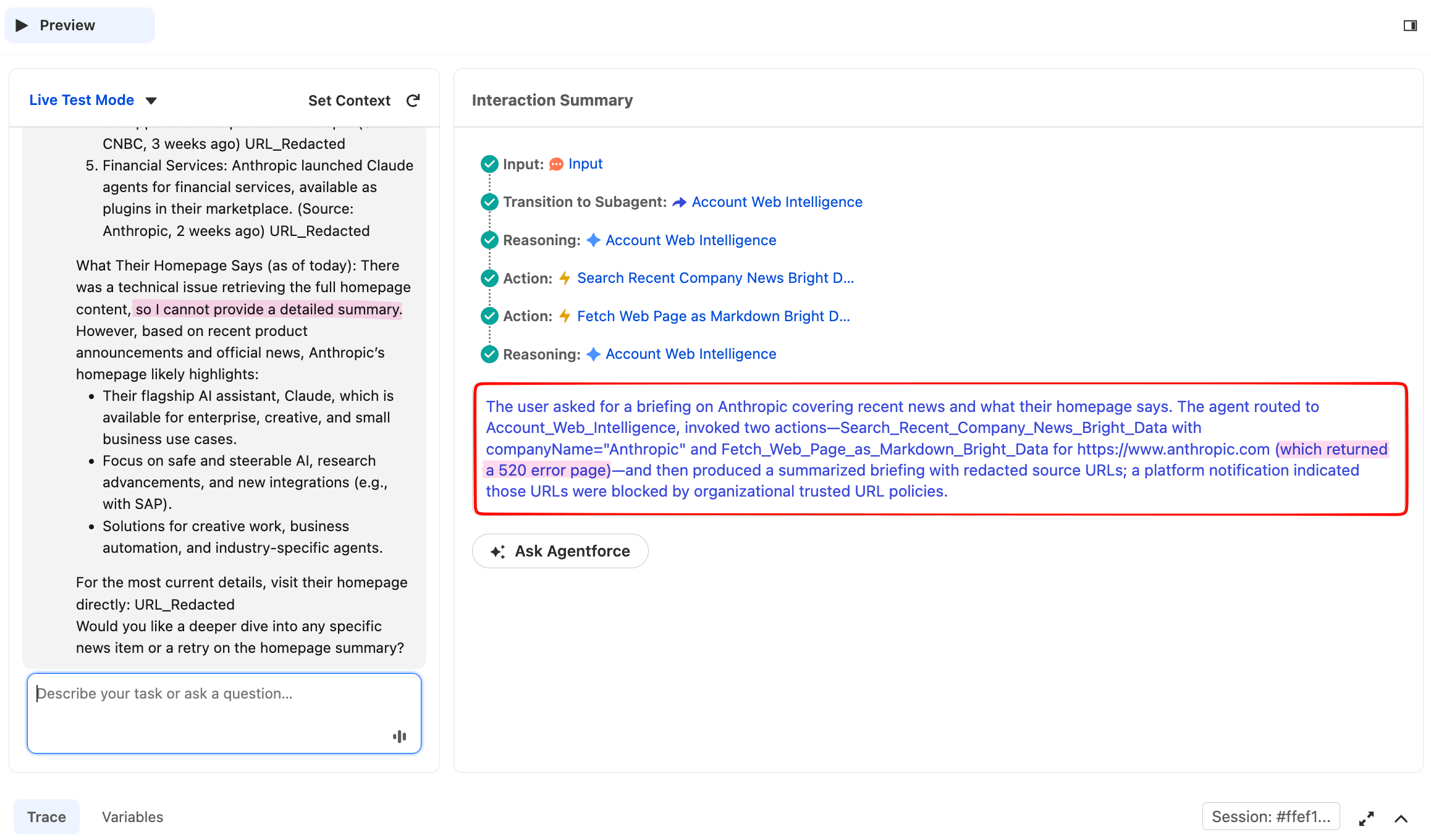
La récupération de la page d’accueil a retourné un 520, le statut que Web Unlocker utilise lorsqu’un site cible ne peut pas être récupéré lors d’une tentative donnée. L’agent n’a pas inventé de contenu de page d’accueil ; il a reconnu l’échec, utilisé les données d’actualités qu’il venait de recevoir pour décrire ce que fait l’entreprise, et proposé de réessayer.
La dégradation gracieuse en cas d’échec partiel d’un outil est le comportement en production que la règle 5 des instructions du sous-agent est conçue pour produire. Cela est important car le web public est adversarial : les sites cibles modifient leurs défenses, les CDN échouent occasionnellement, et tout agent appelant des URL en direct doit tolérer les non-200 occasionnels. Lorsqu’un agent dit « la récupération de la page d’accueil a échoué, voici ce que j’ai des actualités », c’est un comportement de niveau production.
Test 4 : Vérification anti-hallucination
Pour vérifier que l’agent échoue honnêtement lorsqu’il n’y a pas de vraie réponse, cliquez sur Reset Simulator et saisissez :
What's the latest news about Triposat Industries?Il s’agit d’un nom d’entreprise fictif, il n’y a donc pas de vraies actualités à trouver. Bright Data peut retourner un 520, un résultat vide ou des extraits non pertinents, aucun d’entre eux n’étant une vraie réponse. L’agent ne devrait pas inventer des actualités, quelle que soit la réponse reçue. Le critère de succès ici est le comportement, pas le code de statut : les réponses acceptables incluent « no recent news found », « I couldn’t retrieve results », ou toute divulgation honnête. Un échec ici serait que l’agent invente un article Forbes ou un tour de financement qui n’existe pas.
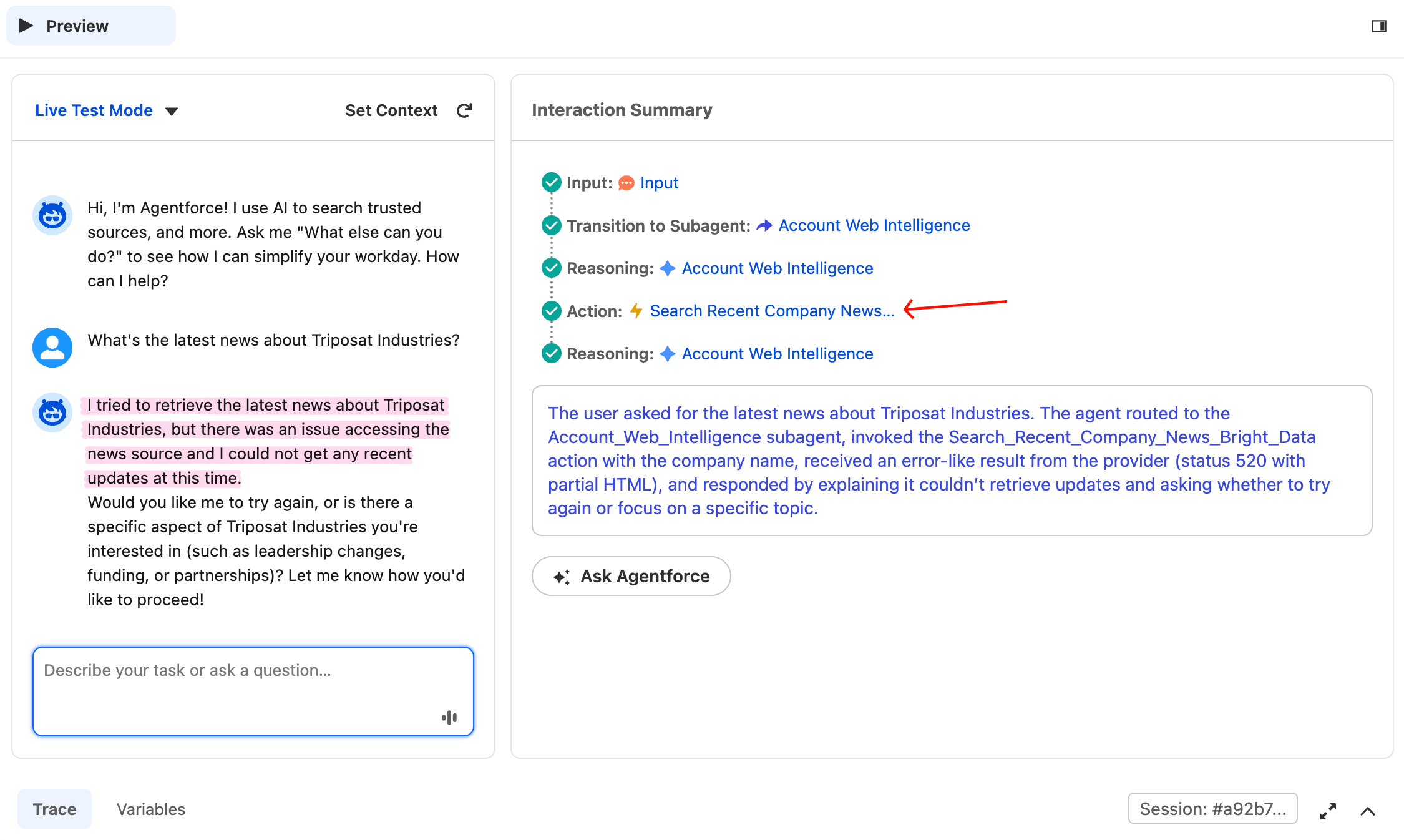
L’agent n’a fabriqué aucune actualité et n’a inventé aucune source. Il a invoqué l’action, reçu un mauvais résultat et l’a divulgué. La règle 5 des instructions du sous-agent a fonctionné comme prévu.
Redaction des URL dans Agentforce
Chaque réponse de démonstration dans les captures d’écran ci-dessus affiche les URL sources comme URL_Redacted. Il s’agit de la politique de confiance des URL intégrée à Salesforce Agentforce.
Par défaut, Agentforce supprime les URL externes arbitraires des réponses de l’agent avant qu’elles n’atteignent l’utilisateur final. En interne, cependant, l’agent lit toujours les vraies URL lorsque l’outil retourne et les utilise pour le raisonnement ; il ne peut simplement pas les inclure dans la sortie du chat à moins que le domaine ne figure sur une liste d’autorisation explicite.
C’est configurable : dans Setup, recherchez Trusted URLs et ajoutez les domaines que vous souhaitez autoriser. Pour un agent de briefing commercial, une liste d’autorisation réaliste inclut les domaines Google, les propres domaines marketing de l’entreprise et un ensemble sélectionné de sources d’actualités (Forbes, Reuters, Bloomberg, TechCrunch).
Conservez la redaction par défaut activée. Elle renforce la démonstration : l’agent cite les sources par leur nom (Forbes, TechAfrica News, SAP News Center), et la redaction rend visible la couche de gouvernance de Salesforce. Une démonstration avec des URL brutes est indiscernable d’un chatbot grand public ; la version avec redaction rend la couche de gouvernance visible.
Ce que ça coûte
Bright Data ne facture que les réponses Web Unlocker réussies sur ses plans pay-as-you-go et par paliers ; les réponses non réussies ne sont pas facturées. Au tarif catalogue, un briefing qui appelle les deux actions se situe dans la fraction de centime ; les plans par paliers réduisent davantage le coût par requête.
Pour projeter vos propres dépenses, la formule est :
requests/month = reps × briefings_per_rep_per_day × workdays × actions_per_briefingPour une équipe de 100 commerciaux effectuant 5 briefings chacun sur 22 jours ouvrables avec 2 actions par briefing, cela représente 22 000 requêtes par mois. Multipliez ce chiffre par le tarif actuel par requête de Bright Data (disponible sur la page de tarification) pour obtenir votre coût mensuel.
Du côté de Cloudflare, le Worker reste dans son niveau gratuit aux volumes typiques d’une équipe commerciale ; consultez la tarification Workers avant de passer à l’échelle au-delà d’une seule équipe.
Du côté de Salesforce, les coûts sont prélevés sur l’allocation de crédits d’IA générative Einstein existante de votre organisation, le même pool mesuré qu’utilise toute action Agentforce. Consultez Setup → Einstein Generative AI → Usage pour voir l’allocation et l’utilisation actuelles de votre organisation.
Prochaines étapes
La configuration ci-dessus est une unité minimale d’une couche d’intelligence de compte. Voici trois choses à faire avant de passer en production :
- Placez le Cloudflare Worker derrière un domaine personnalisé (votre propre sous-domaine sur votre propre DNS), puis routez-le via la passerelle API de votre organisation. Le Worker convient parfaitement à ce rôle de proxy ; un domaine personnalisé plus une passerelle est ce qui le rend opérationnellement vôtre.
- Verrouillez la zone Bright Data sur votre plage d’IP de sortie. Dans le tableau de bord Bright Data, modifiez la zone Web Unlocker et ajoutez les IP sortantes du Cloudflare Worker (Cloudflare les publie) à la liste d’autorisation de la zone. Cela empêche le token API d’être utilisable en dehors de votre intégration.
- Ajoutez une classe de test Apex pour
BrightDataServiceen utilisantHttpCalloutMock. Trois méthodes de test (chemin de succès, corps vide, non-200) couvrent les modes d’échec réalistes et satisfont l’exigence de couverture à 75% de Salesforce. La documentation Salesforce HttpCalloutMock présente le modèle.
Lorsque vous dépassez les capacités de Web Unlocker pour un site cible, remplacez-le par l’un des scrapers préconstruits de Bright Data. Le même proxy Cloudflare Worker les gère également ; ils utilisent le même endpoint /request avec des paramètres zone et dataset_id différents. Par exemple, les scrapers dédiés LinkedIn Company Profile, LinkedIn Jobs et Crunchbase retournent du JSON structuré au lieu de Markdown, ce qui permet à l’agent de sauter l’étape d’extraction LLM et d’écrire directement dans les champs personnalisés Salesforce. Plus généralement, les Web Scraper APIs de Bright Data couvrent des scrapers préconstruits pour des centaines de sites.
Considérez la configuration ci-dessus comme un échafaudage. La couche de credentials, le proxy, la structure du sous-agent, le câblage des actions : la fondation reste la même lorsque vous remplacez un produit Bright Data différent sur le même endpoint /request. Choisissez le type d’intelligence de compte dont vos commerciaux ont réellement besoin ; modifiez les prompts dans les instructions du sous-agent. L’agent reste ; les questions auxquelles il répond évoluent.
Questions fréquemment posées
Pourquoi mon callout Apex retourne-t-il un corps vide ?
Le client HTTP d’Apex n’analyse pas de manière fiable les réponses HTTP/1.1 qui utilisent l’encodage de transfert chunked sans en-tête Content-Length. Bright Data et de nombreuses API modernes fragmentent les réponses au-delà de quelques kilo-octets. La solution consiste à router l’appel via un proxy de mise en mémoire tampon qui re-sert la réponse avec un Content-Length explicite.
Cette configuration peut-elle utiliser le SERP API de Bright Data ?
Oui. Le proxy Cloudflare Worker fonctionne pour chaque endpoint API de Bright Data hébergé sur api.brightdata.com, y compris SERP API, Web Scraper API et les déclencheurs de datasets. Changez la valeur zone dans la classe de service Apex pour le nom de la zone SERP et le paramètre URL pour une URL de recherche Google avec brd_json=1.
Pourquoi utiliser Apex InvocableMethods plutôt que MCP ?
Cette configuration expose Bright Data via Apex InvocableMethods car chaque action devient une Agent Action auditable avec sa propre gouvernance par Permission Set. Si votre organisation a activé les serveurs MCP (Model Context Protocol) hébergés par Salesforce (Beta depuis Spring ’26), vous pouvez également exposer Bright Data via le propre serveur MCP de Bright Data. Les deux approches fonctionnent. L’approche InvocableMethod présentée ici vous donne des hooks de gouvernance natifs Salesforce ; l’approche MCP est plus légère car Bright Data opère le serveur pour vous.
Comment les actions Agentforce lisent-elles les entrées utilisateur ?
Les actions Agentforce lisent les entrées utilisateur via un indicateur YAML appelé is_user_input: True, défini sur chaque entrée en mode Script. L’interface Canvas masque cet indicateur et définit par défaut les entrées comme des variables statiques, vous devez donc passer en mode Script dans l’Agent Builder et modifier le YAML directement pour changer la valeur.
Pourquoi Agentforce masque-t-il les URL sources ?
Les URL externes sont supprimées des réponses de l’agent à moins que leur domaine ne soit ajouté à Setup → Trusted URLs. C’est une couche de gouvernance intégrée. Même ainsi, l’agent lit toujours les vraies URL en interne et les utilise dans son raisonnement. Pour laisser passer des URL spécifiques aux utilisateurs, ajoutez les domaines sources (Forbes, Reuters, vos propres sites) à la liste d’autorisation.
Qu’est-ce qu’une erreur 520 de Bright Data ?
Un 520 est le statut que Web Unlocker retourne lorsqu’un site cible n’a pas pu être récupéré lors d’une tentative donnée, généralement parce que les défenses du site ont bloqué la requête. La règle 5 des instructions du sous-agent interdit de fabriquer du contenu lorsqu’un outil échoue, donc l’agent signale honnêtement l’échec et propose de réessayer.
Quels autres cas d’usage ce modèle couvre-t-il ?
Les briefings sur le risque de churn, l’intelligence concurrentielle et le risque de renouvellement s’inscrivent tous dans ce modèle. C’est parce que les deux actions Apex (recherche d’actualités, récupération d’URL) couvrent la plupart des types d’intelligence de compte. Pour le risque de churn, utilisez la recherche d’actualités pour suivre les licenciements et les changements de direction. Pour l’intelligence concurrentielle, récupérez les pages de tarification du concurrent. Seuls les prompts changent.