
Dans cet article, vous apprendrez :
- Ce qu’est Alteryx One et les fonctionnalités qu’il offre.
- Pourquoi le connecter aux données web de Bright Data rend les workflows plus pertinents.
- Comment définir un workflow automatisé dans Alteryx One en utilisant des données web structurées et fraîches issues du web scraping de Bright Data.
Plongeons dans le vif du sujet !
Qu’est-ce qu’Alteryx One ?
Alteryx One est une plateforme d’analyse unifiée et propulsée par l’IA. Elle regroupe la préparation des données, l’analyse, l’automatisation et l’IA dans un environnement unique. En détail, elle aide les organisations à se connecter à plusieurs sources de données, à créer des workflows réutilisables et à opérationnaliser les insights à grande échelle.
Les principales fonctionnalités offertes par Alteryx One sont :
- Analyse native IA : Intégrez l’IA dans les workflows d’analyse pour détecter des tendances, générer des insights et soutenir la modélisation prédictive sans outils séparés.
- Préparation des données prête pour l’IA : Connectez, nettoyez et transformez des données provenant de plusieurs sources en jeux de données fiables et prêts à l’analyse, avec une gouvernance intégrée.
- Automatisation des workflows : Automatisez les tâches analytiques répétitives et les processus de bout en bout, réduisant les efforts manuels et améliorant la cohérence.
- Espace de travail analytique unifié : Fournissez un environnement unique où les équipes peuvent créer, exécuter et gérer des workflows analytiques de manière collaborative.
- Gouvernance et sécurité d’entreprise : Assurez la conformité, le suivi de la traçabilité et le contrôle des accès afin que l’analyse puisse évoluer en toute sécurité au sein des grandes organisations.
- Intégrations extensibles : Connectez-vous aux systèmes d’entreprise et aux LLM pour intégrer l’analyse directement dans les écosystèmes de données existants.
Comment Bright Data soutient Alteryx One
Les workflows Alteryx One ne sont aussi puissants que les données qu’ils consomment. Certes, la plateforme offre des capacités robustes pour la préparation des données, l’analyse et l’automatisation. Pourtant, la qualité, la fraîcheur et la fiabilité des données d’entrée déterminent en fin de compte la précision des résultats. C’est là que Bright Data joue un rôle central en tant que fournisseur de données web de niveau entreprise !
Bright Data fournit des données web structurées à grande échelle via une infrastructure proxy mondiale de plus de 400 millions d’IP dans 195 pays. Avec une disponibilité de 99,99 % et un taux de succès de 99,95 %, elle offre la fiabilité nécessaire pour des pipelines d’analyse en production.
Pour une intégration directe avec Alteryx One, vous pouvez commencer par récupérer des données web fraîches via les API de Web Scraping de Bright Data ou en accédant à des données web statiques via les datasets Bright Data. Ces données peuvent être automatiquement livrées vers Amazon S3 (ou toute autre destination de livraison courante) dans un format structuré.
Alteryx One peut ensuite importer ce jeu de données directement depuis S3, où il est traité via un workflow sans code. Enfin, les résultats traités sont réécrits vers S3 (ou toute destination préférée) pour une utilisation en aval.
Le résultat est un pipeline d’analyse automatisé de bout en bout. Ici, Bright Data assure une ingestion de données fiable et de niveau entreprise, tandis qu’Alteryx One transforme ces données en insights exploitables.
Créer un workflow d’analyse de données automatisé dans Alteryx One avec des données web de Bright Data
Dans ce chapitre étape par étape, vous serez guidé à travers la configuration d’un workflow automatisé dans Alteryx One.
Pour illustrer ce type de workflow d’automatisation web, vous vous appuierez sur les composants suivants :
- Le Yahoo Finance Scraper de Bright Data pour collecter des données boursières fraîches, en le configurant pour une livraison vers Amazon S3.
- Un workflow Alteryx One qui importe les données, les trie par volume et les divise en deux jeux de données : l’un pour les actions en hausse et l’autre pour les actions en baisse. Ensuite, il réécrit les résultats traités vers Amazon S3.
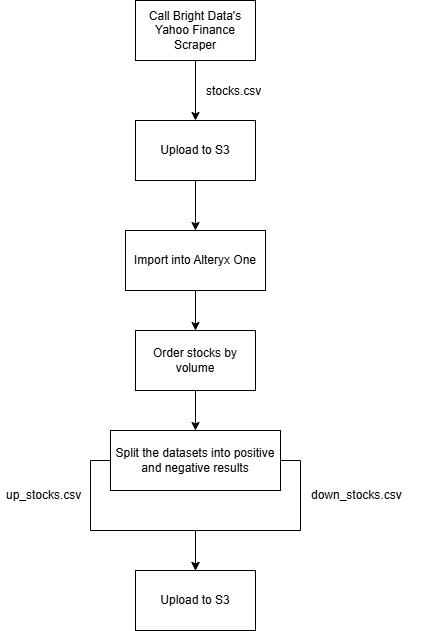
Suivez les instructions ci-dessous pour créer ce workflow !
Prérequis
Pour suivre cette section, assurez-vous de disposer de :
- Un compte Alteryx One (même un compte en essai gratuit convient).
- Un bucket S3 défini dans votre compte AWS.
- Un compte Bright Data avec une clé API configurée. Suivez les instructions officielles pour générer votre clé API.
Dans ce tutoriel, nous supposerons que votre bucket S3 est nommé bright-data-datasets. Cependant, tout autre nom de bucket fonctionnera également.
Étape n°1 : Configurer l’API de scraping Bright Data
La première étape de votre pipeline d’automatisation de données web consiste à récupérer les données sources depuis le web. Pour ce faire, vous utiliserez le Yahoo Finance Scraper de Bright Data pour collecter des données financières en temps réel. Commençons !
Commencez par créer un compte Bright Data, si vous n’en avez pas encore. Sinon, connectez-vous à votre compte existant. Dans le panneau de contrôle, accédez à la page « Scrapers > Scrapers Library » :
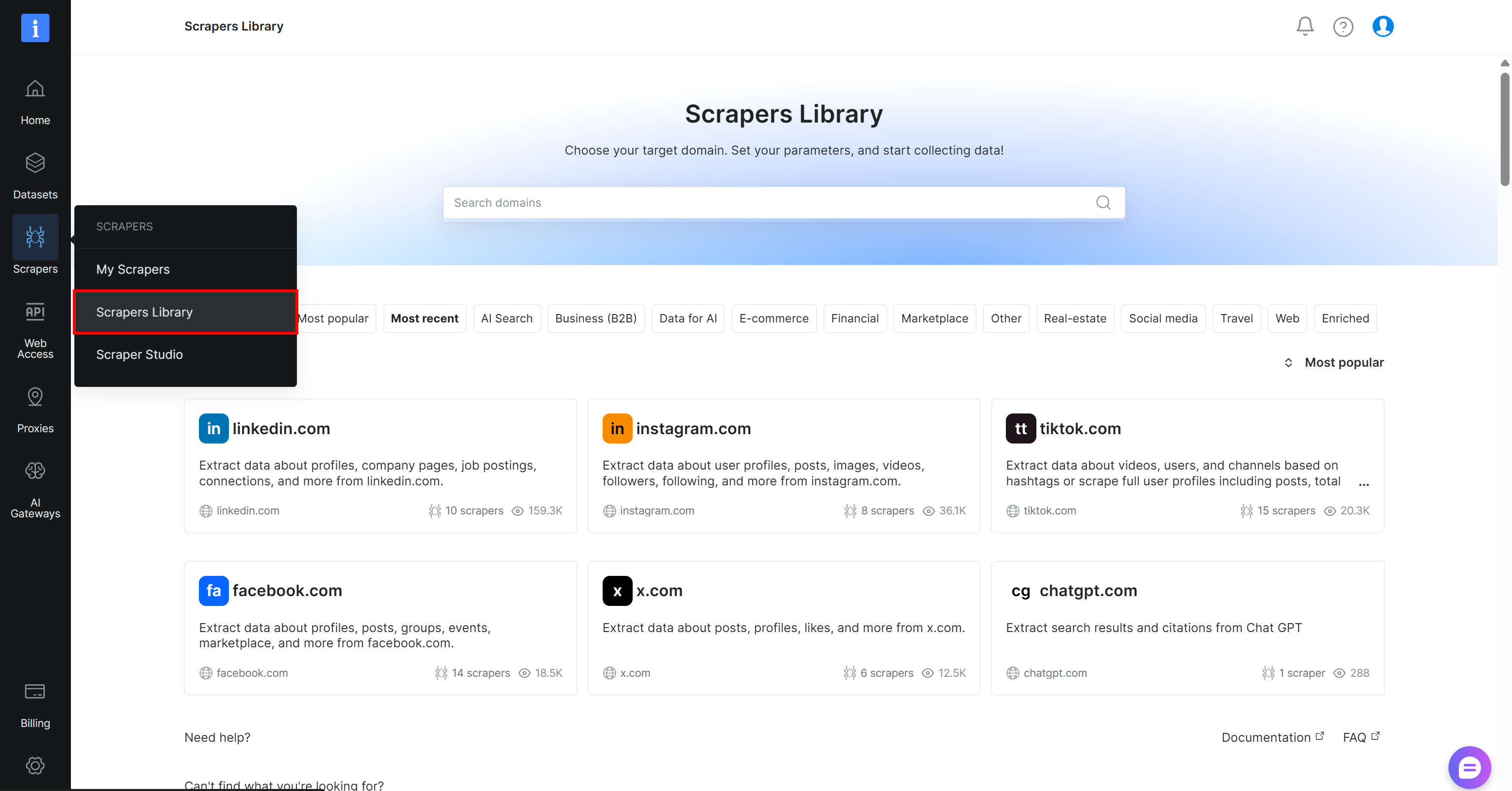
Recherchez « yahoo finance » et sélectionnez le scraper « finance.yahoo.com » :
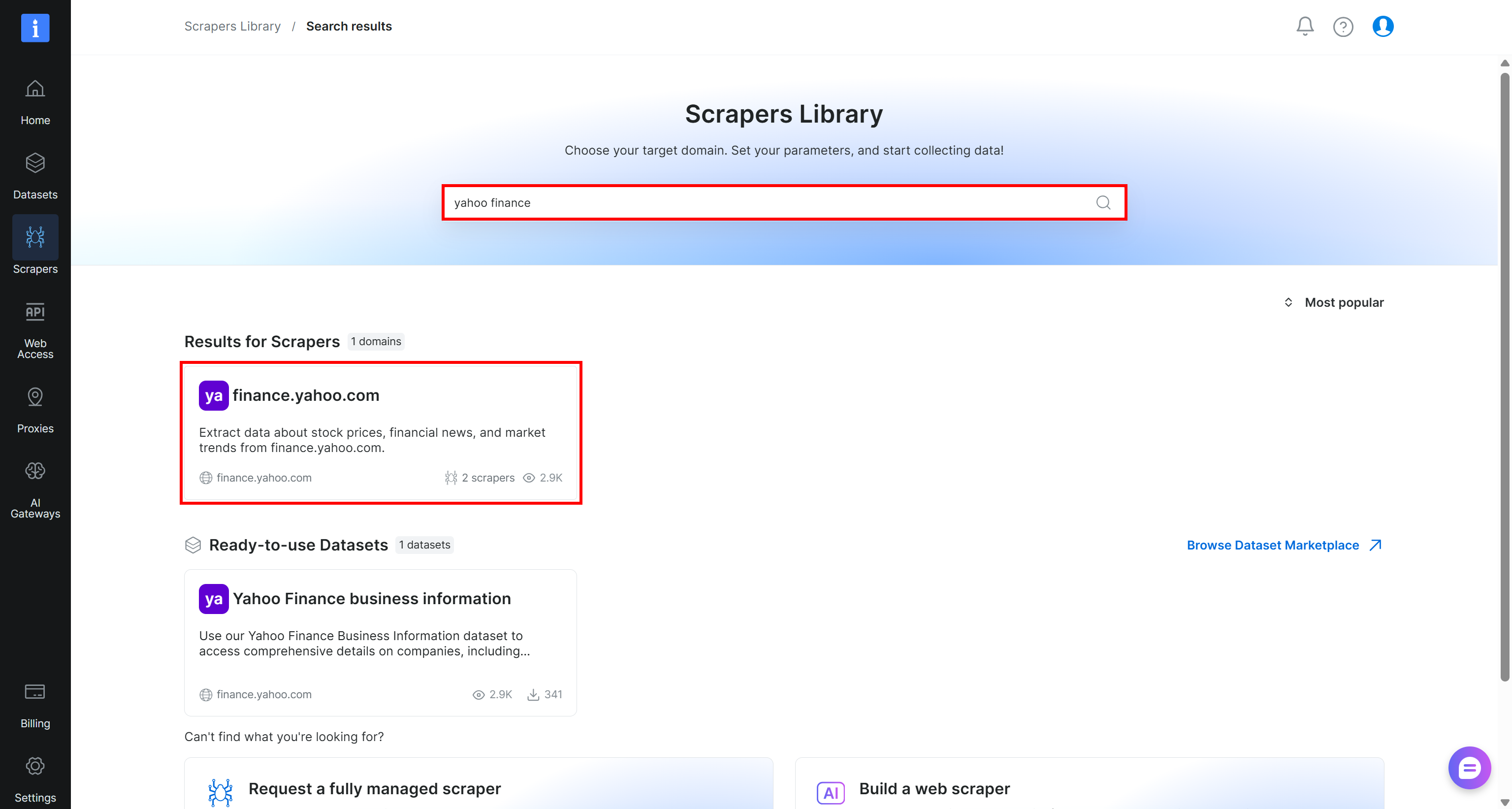
Sur la page du Yahoo Finance Scraper, examinez les exigences d’entrée du scraper et le schéma de sortie :
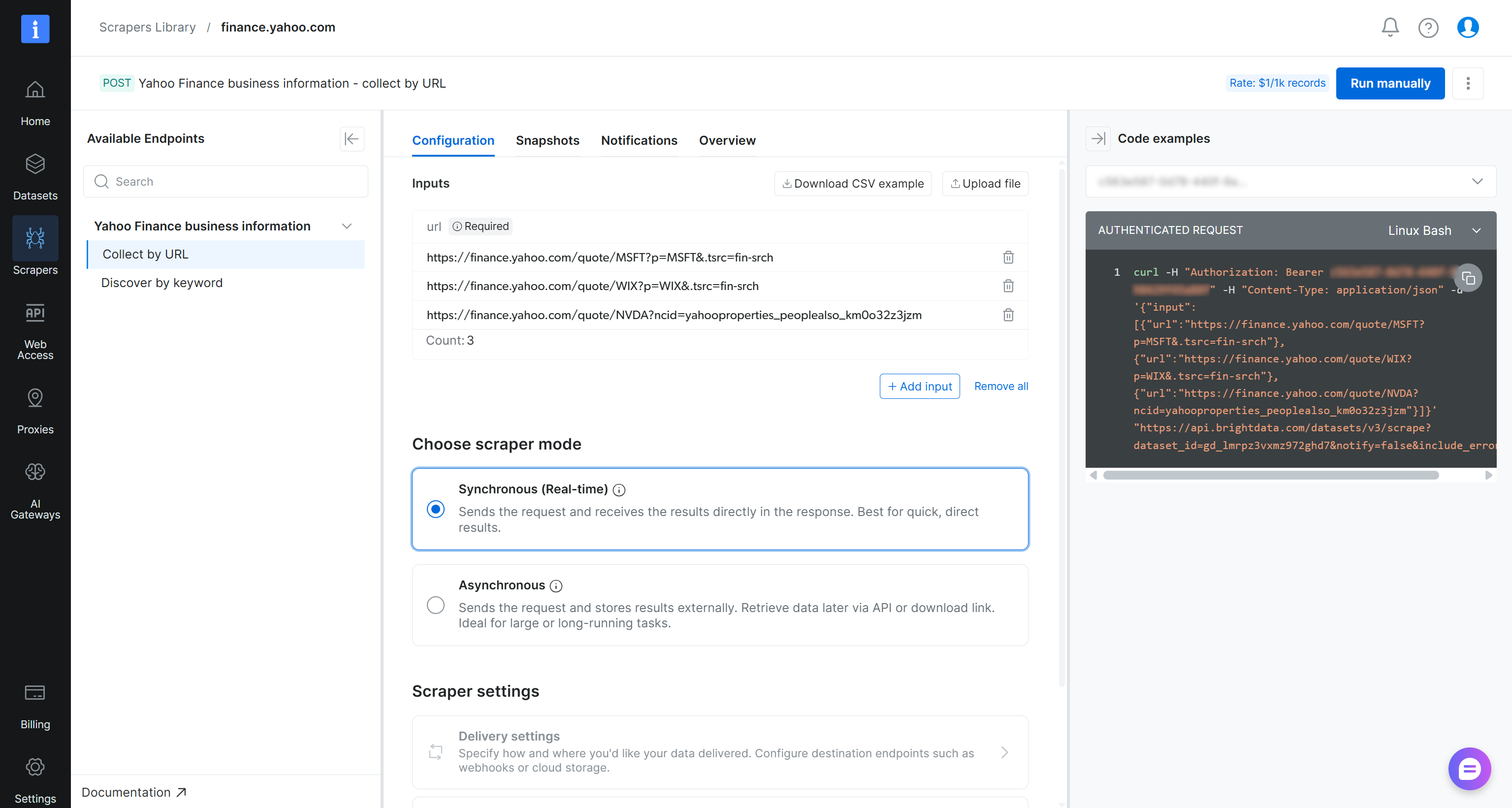
En résumé, le scraper accepte une ou plusieurs URL de pages boursières Yahoo Finance en entrée et retourne des données financières structurées en temps réel. Exactement ce dont nous avons besoin !
Étape n°2 : Configurer la livraison vers S3
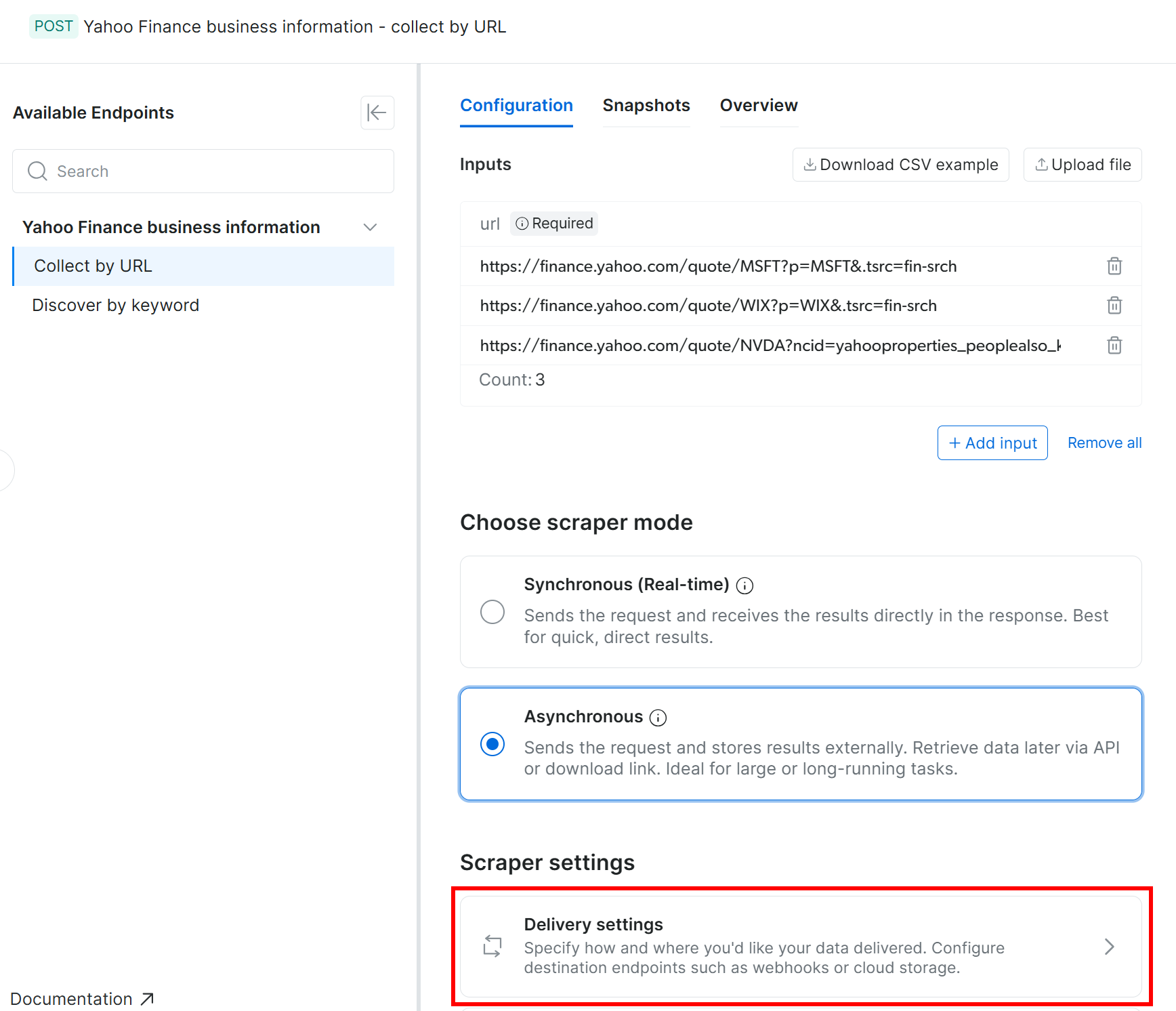
Les API de Web Scraping de Bright Data prennent en charge la livraison automatique des données scrapées vers Amazon S3 (ainsi que plusieurs autres fournisseurs de stockage cloud et méthodes de livraison). Pour activer la livraison vers Amazon S3, vous devez d’abord passer le scraper en mode asynchrone.
Dans l’onglet « Configuration », sélectionnez l’option « Asynchronous ». Puis cliquez sur « Delivery settings » :
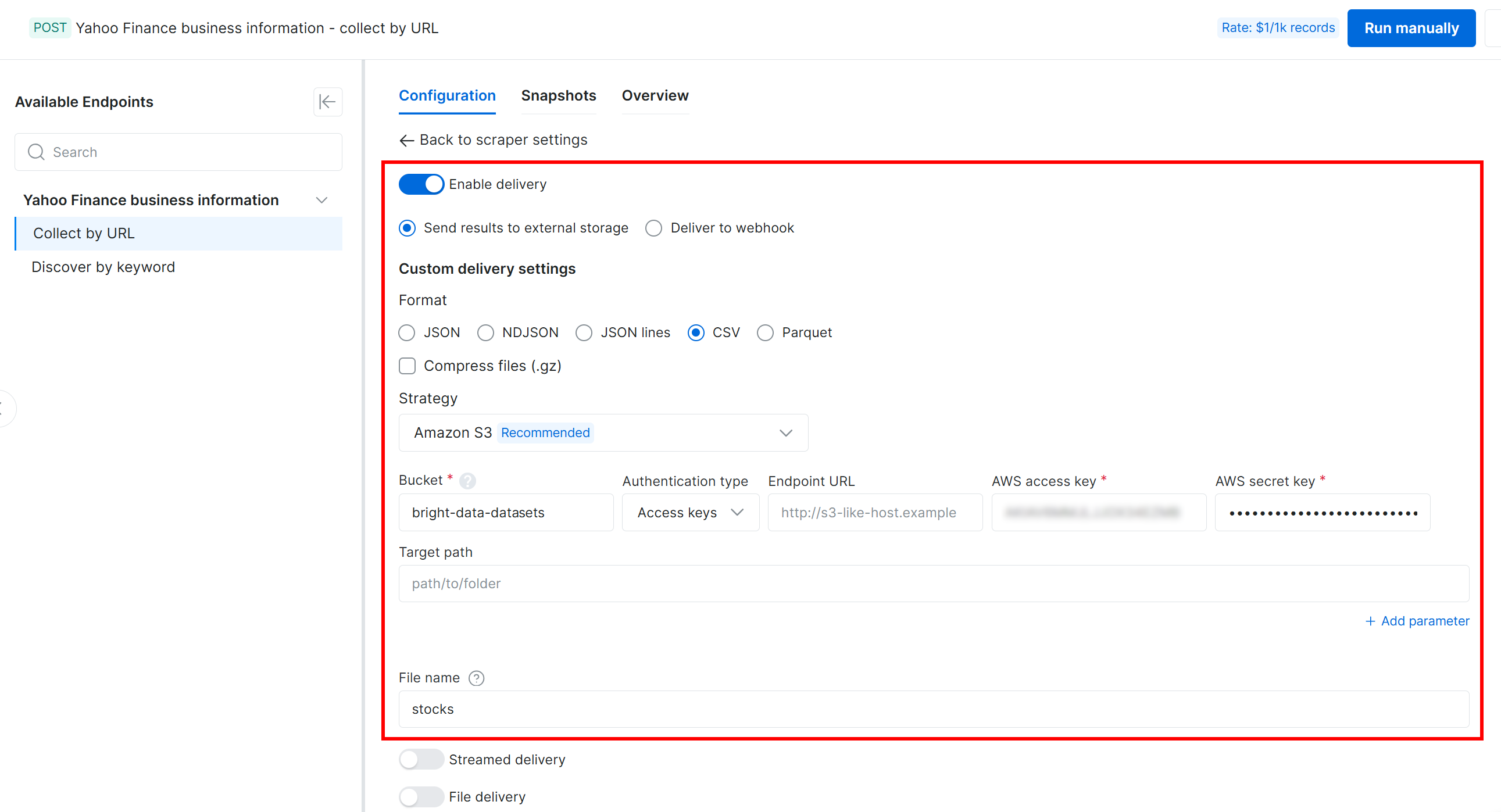
Ensuite, configurez la livraison vers votre bucket Amazon S3 avec les paramètres suivants :
- Activez le bouton « Enable delivery ».
- Définissez le format des données de sortie sur CSV.
- Sélectionnez « Amazon S3 » comme destination de stockage.
- Saisissez le nom de votre bucket S3 (dans cet exemple,
bright-data-datasets). (Vous pouvez laisser le champ « Endpoint URL » vide.) - Laissez le champ « Target path » vide pour télécharger le fichier dans le dossier racine du bucket.
- Définissez l’option « Authentication type » sur « Access keys ».
- Collez votre AWS Access Key ID et AWS Secret Access Key.
- Définissez le nom du fichier sur
stocks.
Avec cette configuration, l’API de Web Scraping s’exécute en mode asynchrone. Au lieu de retourner les données immédiatement, Bright Data crée une tâche de scraping qui s’exécute sur son infrastructure. Une fois la tâche terminée, les données scrapées sont automatiquement téléchargées vers votre bucket Amazon S3. Simple et sans intervention manuelle !
Étape n°3 : Exécuter la tâche de récupération des données web
Pour vérifier que le workflow d’extraction de données web fonctionne correctement, ajoutez quelques URL de pages boursières Yahoo Finance en entrée. Dans cet exemple, nous supposerons que vous souhaitez suivre les 10 principales actions Nasdaq (c’est-à-dire NVDA, AAPL, GOOGL, MSFT, AMZN, TSLA, META, AVGO, WMT et AMD).
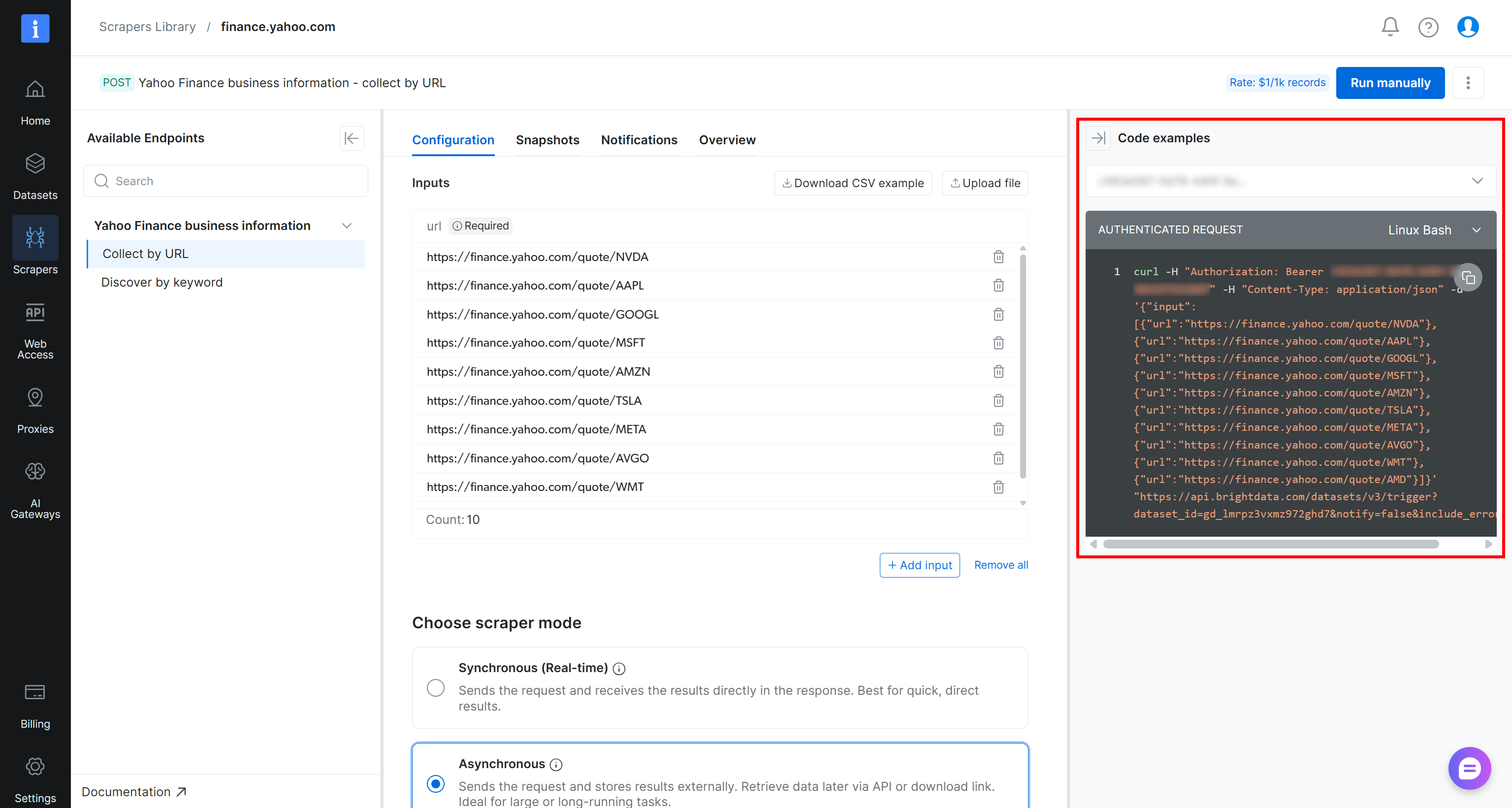
Pour déclencher la tâche de scraping par programmation, vous pouvez utiliser l’extrait cURL fourni sur la page du scraper :
curl -H "Authorization: Bearer <YOUR_BRIGHT_DATA_API_KEY>" -H "Content-Type: application/json" -d '{"input":[{"url":"https://finance.yahoo.com/quote/NVDA"},{"url":"https://finance.yahoo.com/quote/AAPL"},{"url":"https://finance.yahoo.com/quote/GOOGL"},{"url":"https://finance.yahoo.com/quote/MSFT"},{"url":"https://finance.yahoo.com/quote/AMZN"},{"url":"https://finance.yahoo.com/quote/TSLA"},{"url":"https://finance.yahoo.com/quote/META"},{"url":"https://finance.yahoo.com/quote/AVGO"},{"url":"https://finance.yahoo.com/quote/WMT"},{"url":"https://finance.yahoo.com/quote/AMD"}]}' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lmrpz3vxmz972ghd7¬ify=false&include_errors=true"Vous pouvez également exécuter le script Python suivant :
# pip install requests
import requests
import json
headers = {
"Authorization": "Bearer <YOUR_BRIGHT_DATA_API_KEY>",
"Content-Type": "application/json",
}
data = json.dumps({
"input": [{"url":"https://finance.yahoo.com/quote/NVDA"},{"url":"https://finance.yahoo.com/quote/AAPL"},{"url":"https://finance.yahoo.com/quote/GOOGL"},{"url":"https://finance.yahoo.com/quote/MSFT"},{"url":"https://finance.yahoo.com/quote/AMZN"},{"url":"https://finance.yahoo.com/quote/TSLA"},{"url":"https://finance.yahoo.com/quote/META"},{"url":"https://finance.yahoo.com/quote/AVGO"},{"url":"https://finance.yahoo.com/quote/WMT"},{"url":"https://finance.yahoo.com/quote/AMD"}],
})
response = requests.post(
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lmrpz3vxmz972ghd7¬ify=false&include_errors=true",
headers=headers,
data=data
)
print(response.json())Dans les deux cas, assurez-vous de remplacer <YOUR_BRIGHT_DATA_API_KEY> par votre clé API Bright Data.
Remarque : Pour une approche encore plus simple, exécutez la tâche en cliquant directement sur le bouton « Run manually » depuis le panneau de contrôle.
Une fois déclenchée, la requête de scraping sera envoyée à l’infrastructure cloud de Bright Data, où la tâche d’extraction commencera. Vous pouvez surveiller son statut en temps réel depuis le panneau de contrôle Bright Data :
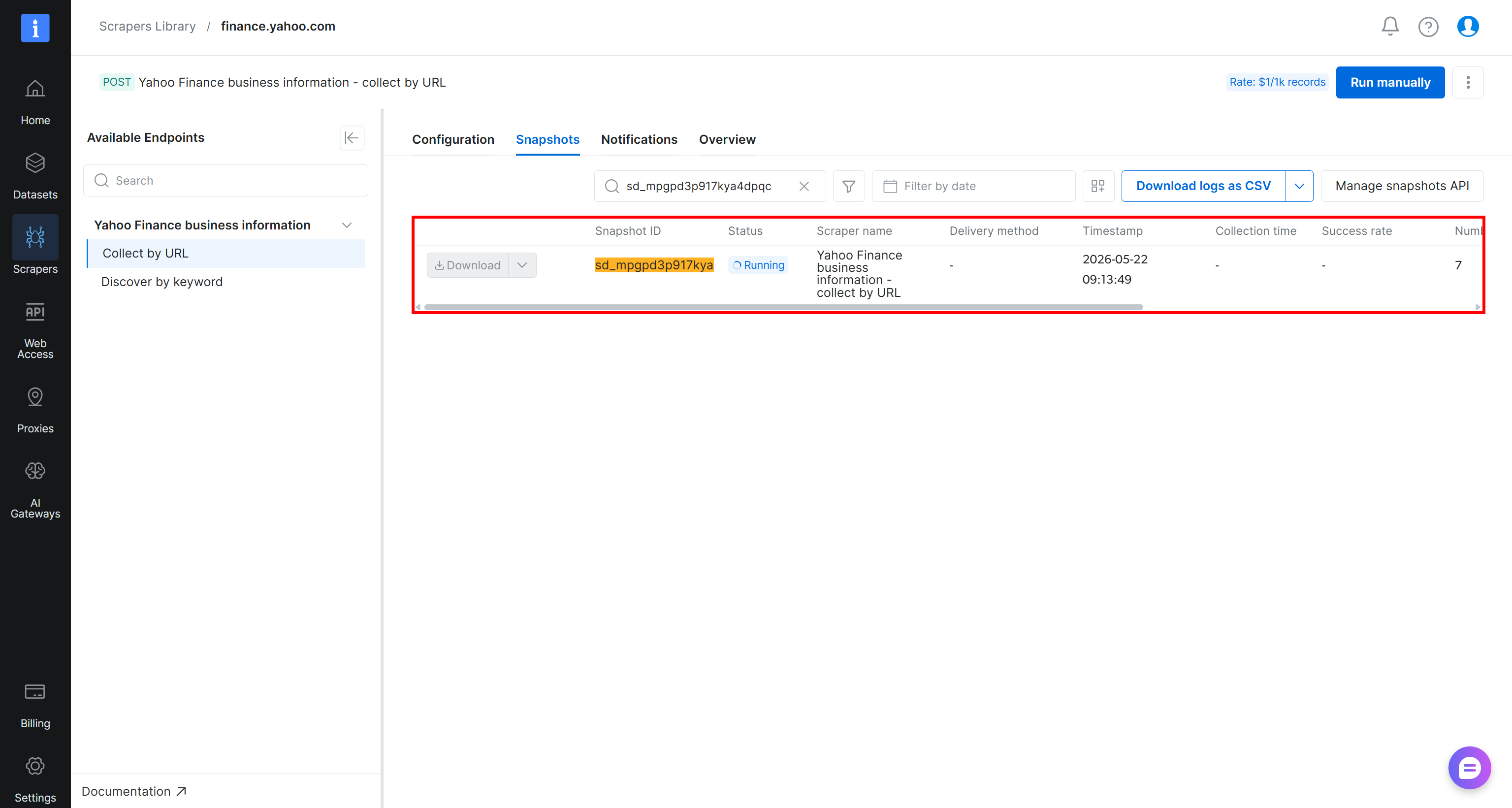
Lorsque le statut de la tâche passe à « Ready », ouvrez votre bucket Amazon S3. Vous devriez remarquer un nouveau fichier nommé stocks.csv :

Téléchargez le fichier stocks.csv et ouvrez-le. Vous verrez quelque chose comme ceci :
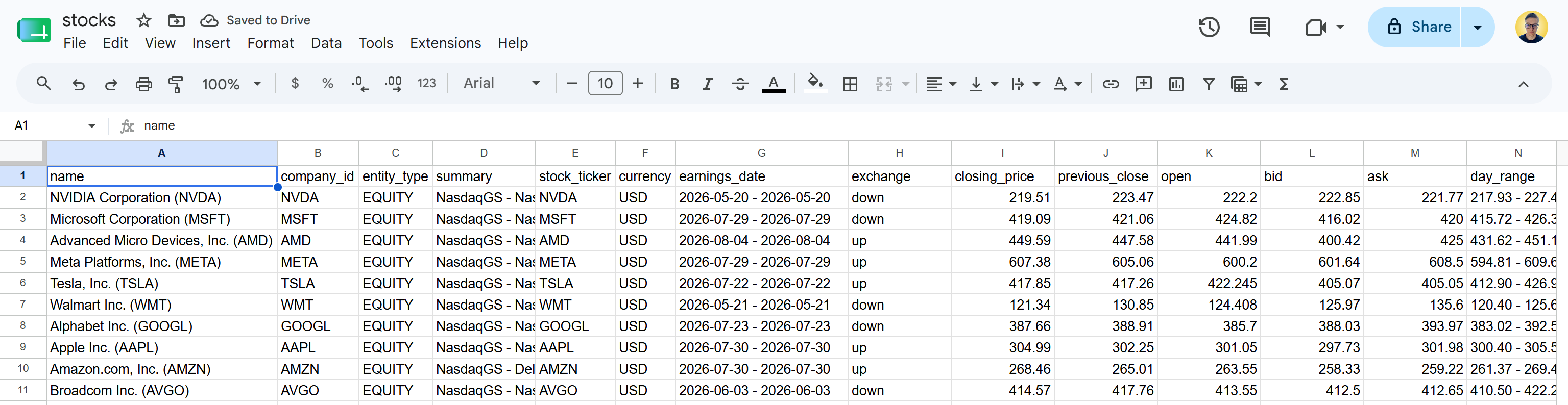
Il s’agit des mêmes données boursières disponibles sur les pages Yahoo Finance spécifiées. L’API Yahoo Finance Scraper de Bright Data a récupéré les données boursières et les a transformées en un format CSV structuré.
Pour mieux comprendre comment les données scrapées sont structurées et quelles colonnes sont disponibles, consultez la section « Dictionary » dans l’onglet « Overview » de la page du scraper Yahoo Finance :
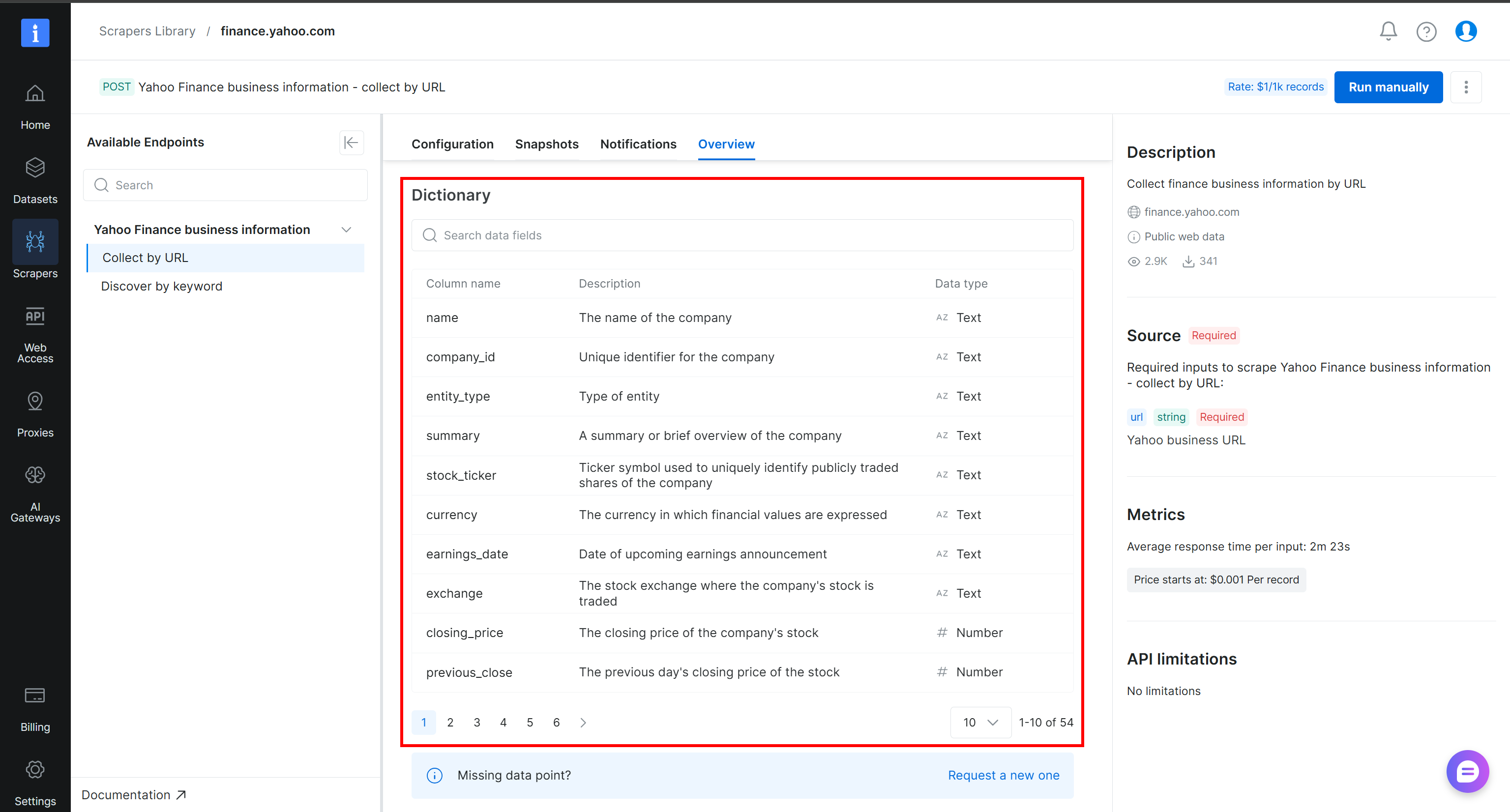
Parfait ! Vous disposez maintenant des données nécessaires pour créer votre pipeline de données web Alteryx One.
Étape n°4 : Connecter Alteryx One à la source de données S3
Actuellement, les données sources scrapées sont livrées vers Amazon S3. L’étape suivante consiste à connecter votre compte Alteryx One à ce bucket S3 afin que les workflows puissent accéder aux données et les analyser selon les besoins.
Pour créer une connexion à votre bucket Amazon S3, connectez-vous à Alteryx One. Accédez à la page « Data » et ouvrez l’onglet « Connections ». Cliquez ensuite sur « New Connection » :
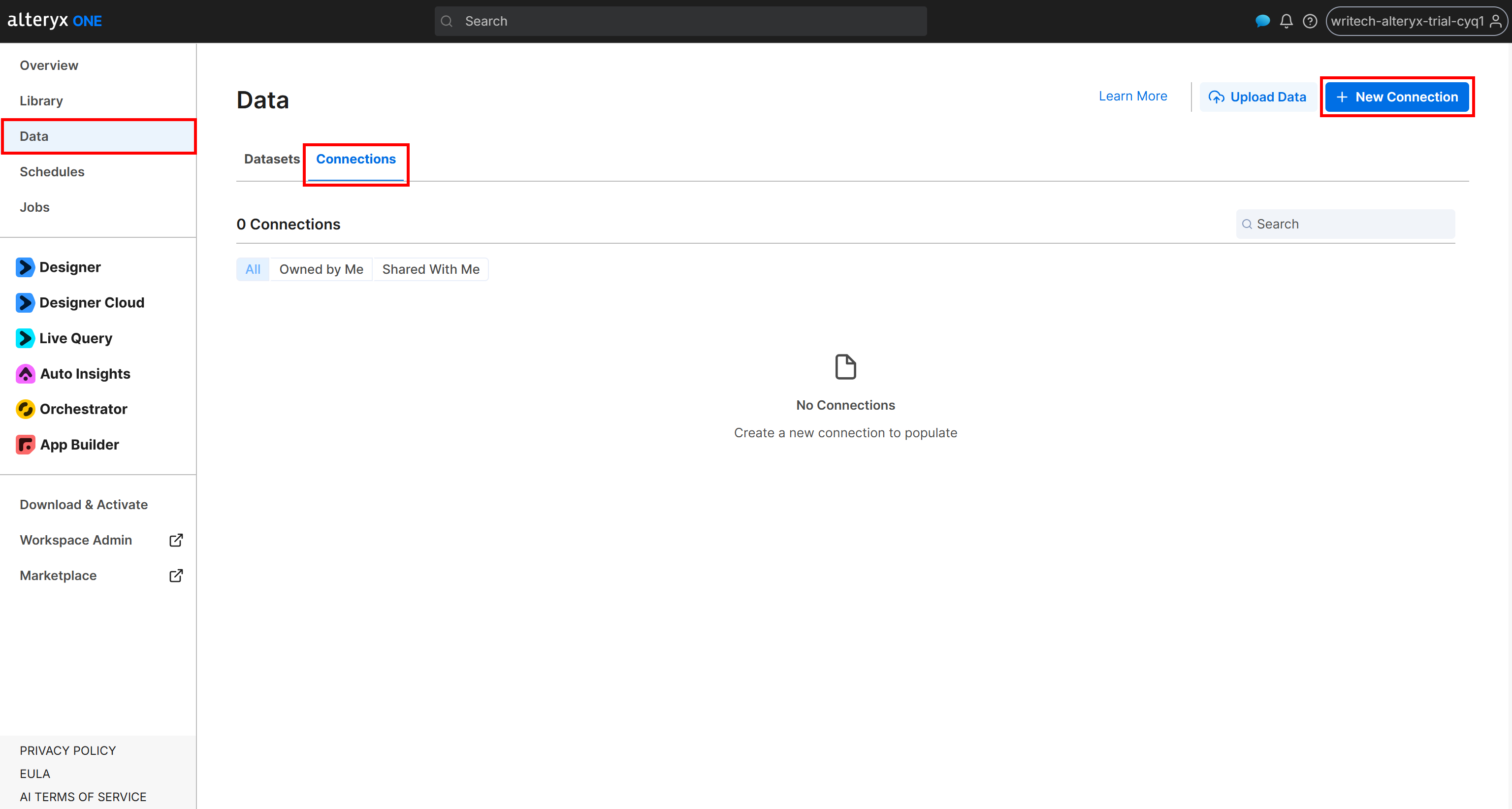
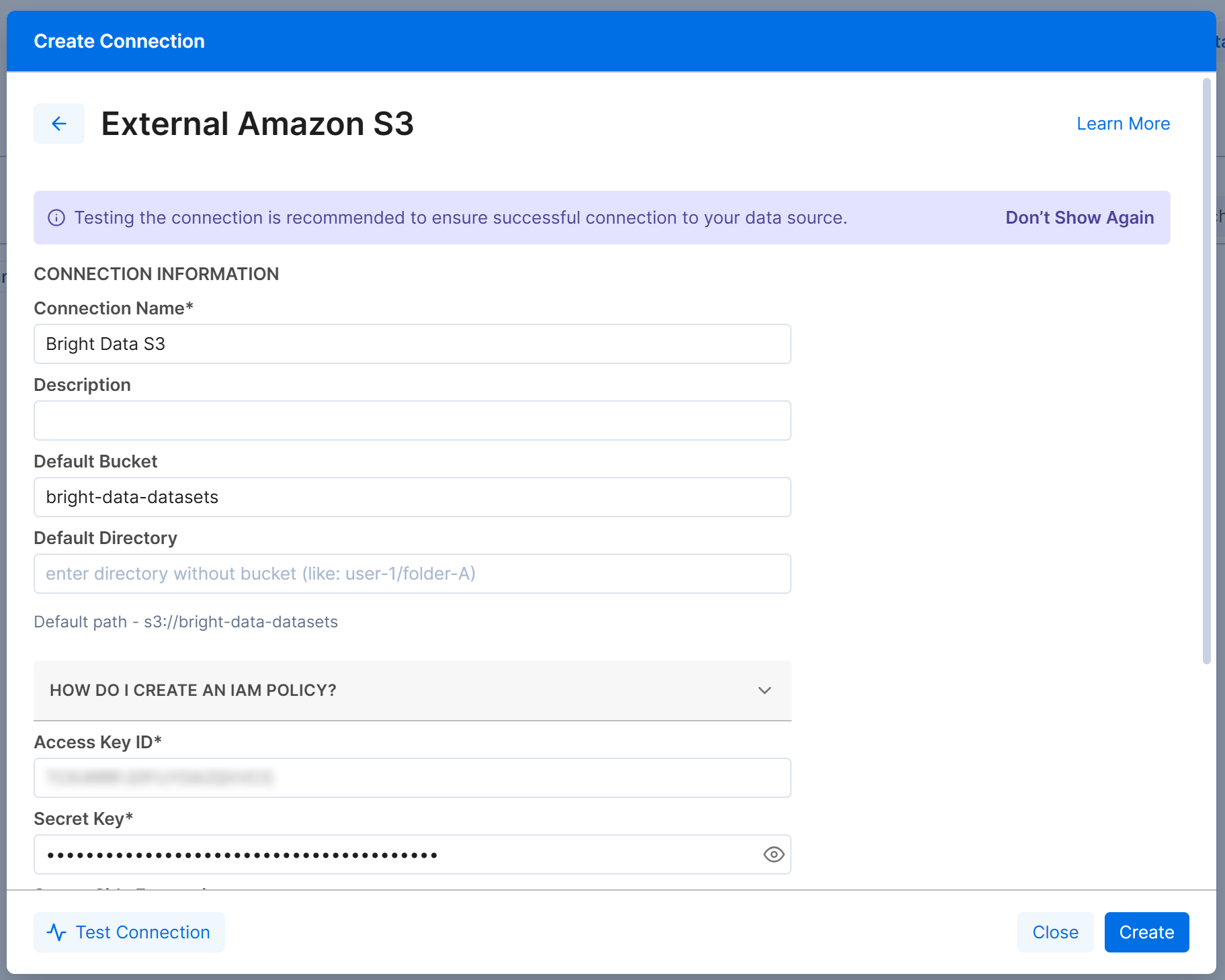
Ensuite, remplissez le formulaire de connexion « External Amazon S3 » comme suit :
- Connection Name : Bright Data S3 (ou tout autre nom de votre choix).
- Default Bucket :
bright-data-datasets(ou le nom réel de votre bucket). - Access Key ID et Secret Access Key : Votre AWS Access Key ID et AWS Secret Access Key.
Cliquez sur « Create », et la connexion Amazon S3 apparaîtra dans l’onglet « Connections » :
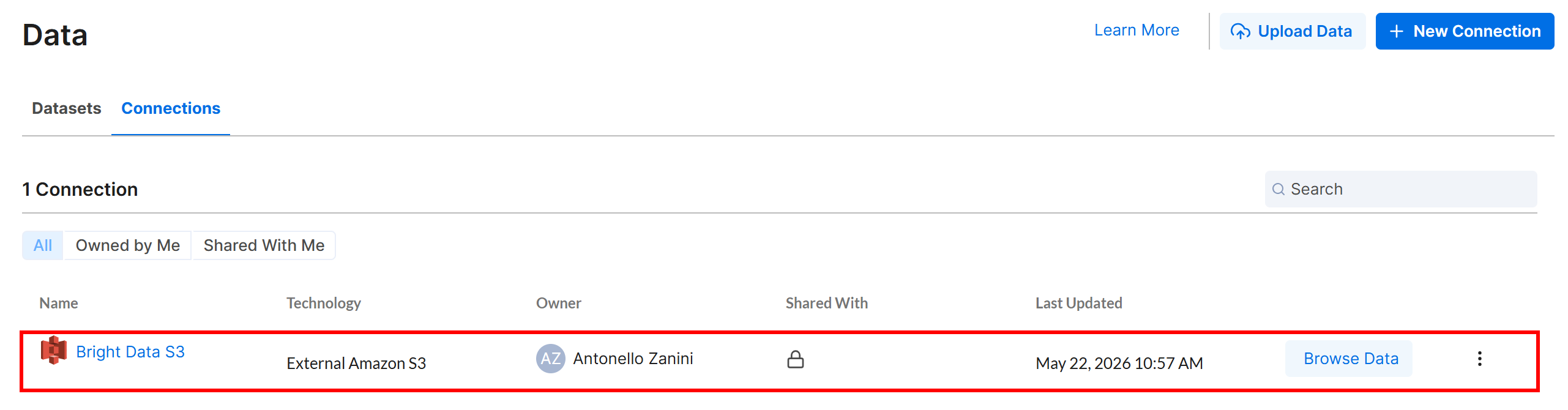
Excellent ! Il est temps de définir un workflow Alteryx One qui lit les données d’entrée depuis votre bucket Amazon S3, où l’API Yahoo Finance Scraper stocke ses résultats.
Étape n°5 : Initialiser le workflow Alteryx One
Accédez à la page « Overview » et cliquez sur le bouton « New Workflow with Designer Cloud » :
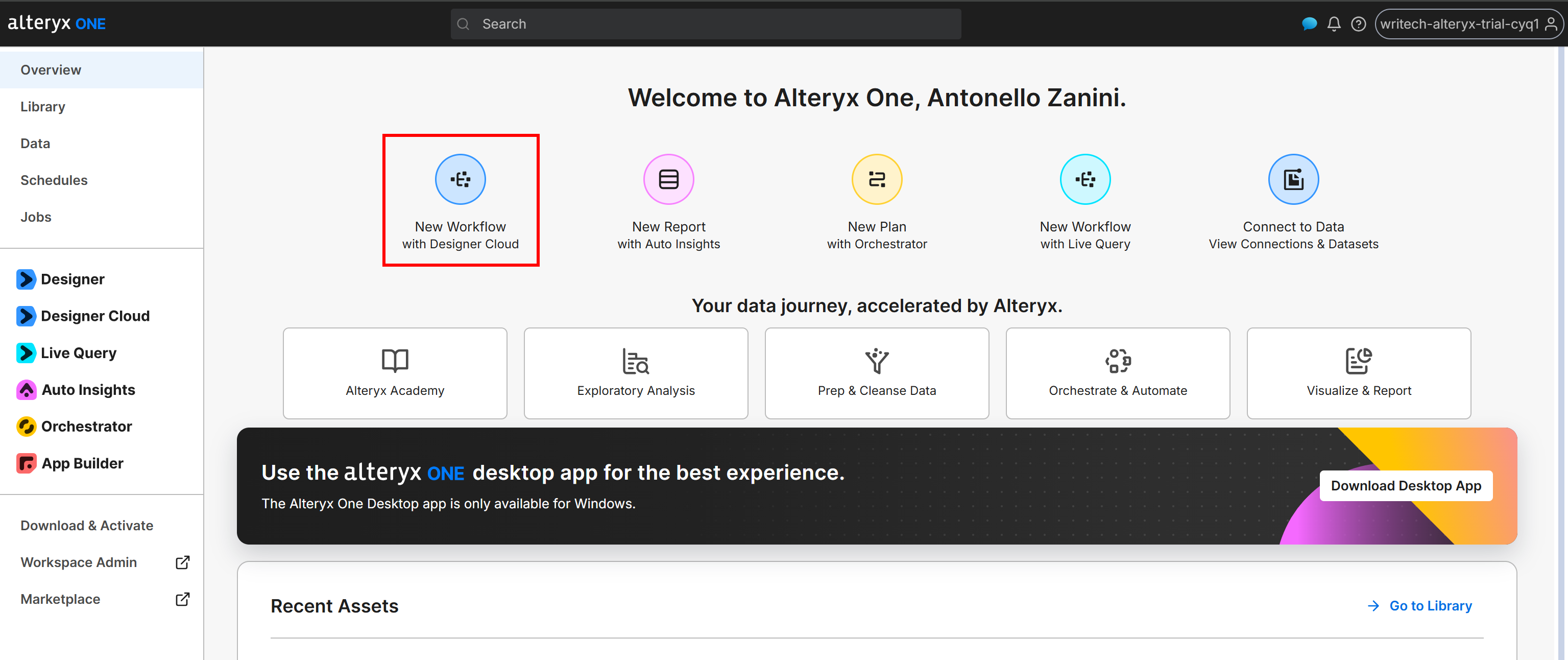
Vous pouvez également créer le workflow depuis l’application de bureau Alteryx One.
Donnez un nom à votre workflow, par exemple « Automated Stock Analyzer » :
La première étape de la création du workflow consiste à charger les données sources. Pour ce faire, faites glisser le nœud « Input Data » sur le canevas du workflow :

Double-cliquez ensuite sur le nœud pour le configurer et le connecter à votre bucket Amazon S3, en sélectionnant le fichier stocks.csv. Suivez l’assistant de configuration pour importer le jeu de données. Une fois terminé, vous devriez voir les données chargées avec succès :
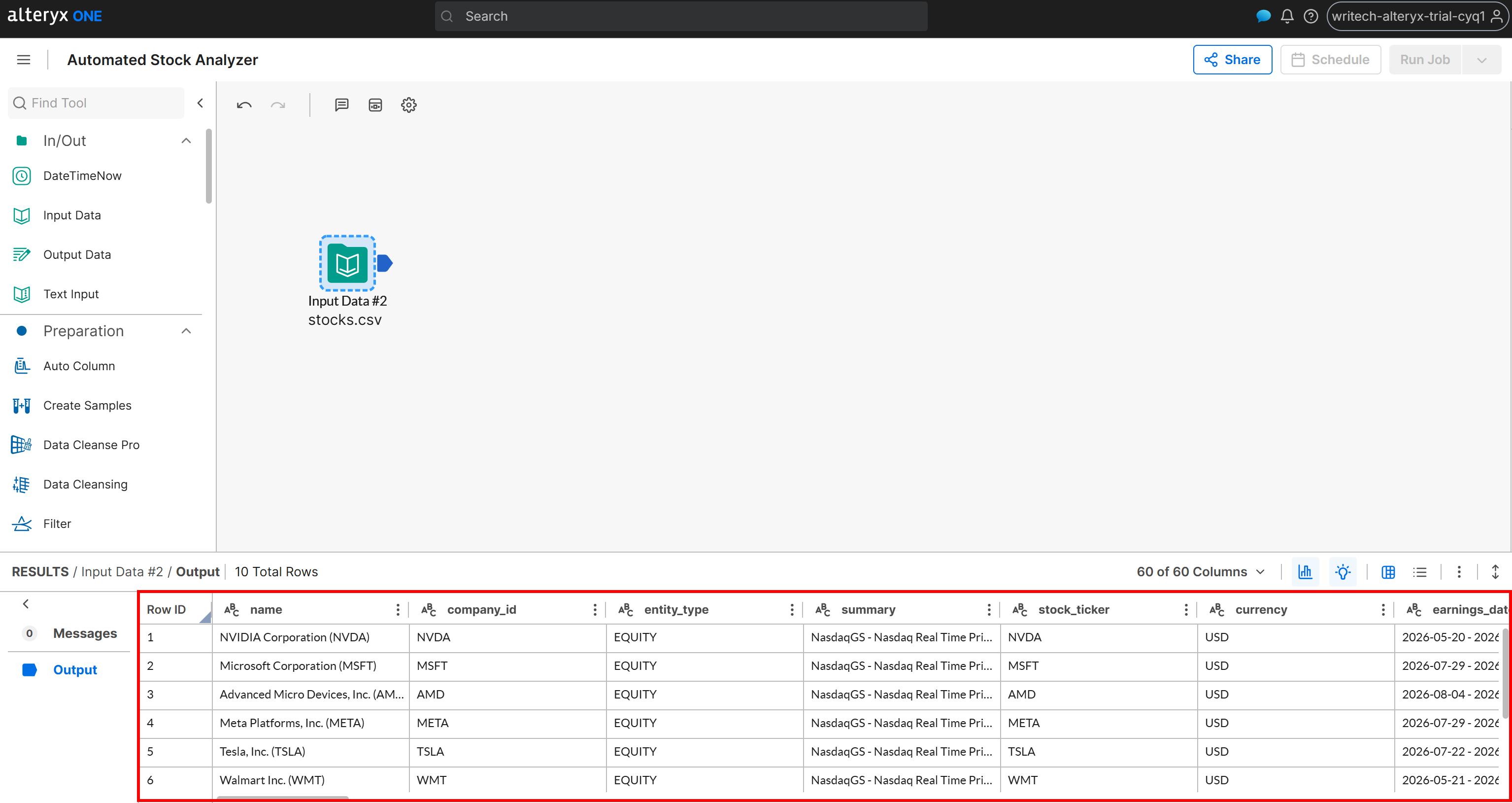
À ce stade, le workflow a accès aux données web scrapées. Parfait ! Vous pouvez maintenant commencer à ajouter la logique d’analyse des données.
Étape n°6 : Définir la logique d’analyse des données
Supposons que vous souhaitiez que les résultats soient ordonnés selon un critère spécifique, tel que le volume de transactions journalier. Ajoutez un nœud « Sort » et, dans la configuration du tri, sélectionnez la colonne volume et définissez l’ordre sur Ascending :
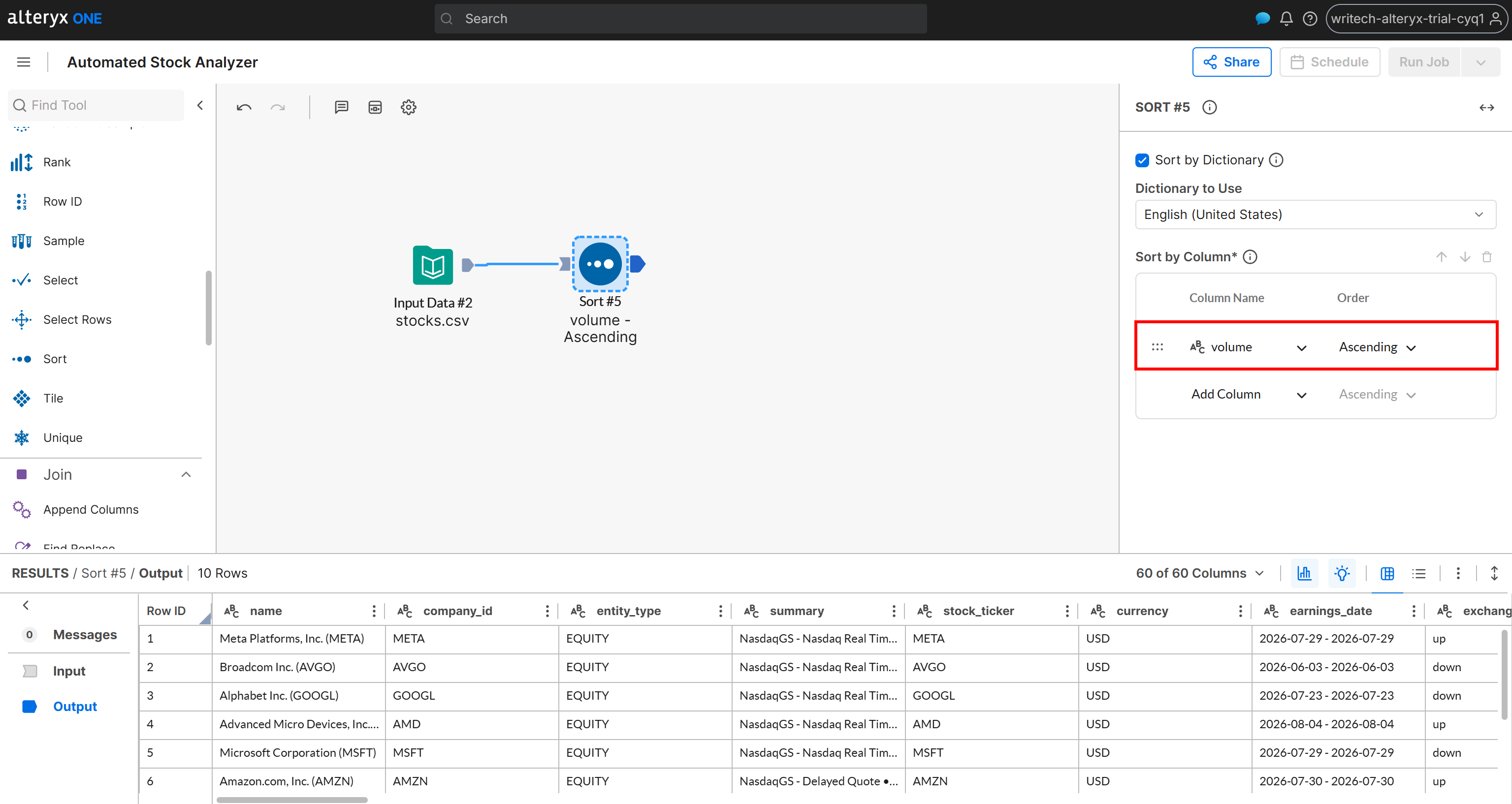
Supposons maintenant que vous souhaitiez diviser le jeu de données en deux groupes :
- Les actions qui ont clôturé la journée en territoire positif.
- Les actions qui ont clôturé la journée en territoire négatif.
Pour ce faire, classifiez les actions selon que leur champ exchange contient « up » ou « down ». Ajoutez un nœud « Filter » et connectez-le à la sortie du nœud « Sort ». Définissez ensuite une condition de filtre telle que :
- Column Name :
exchange - Operator : Equals
- Value :
up
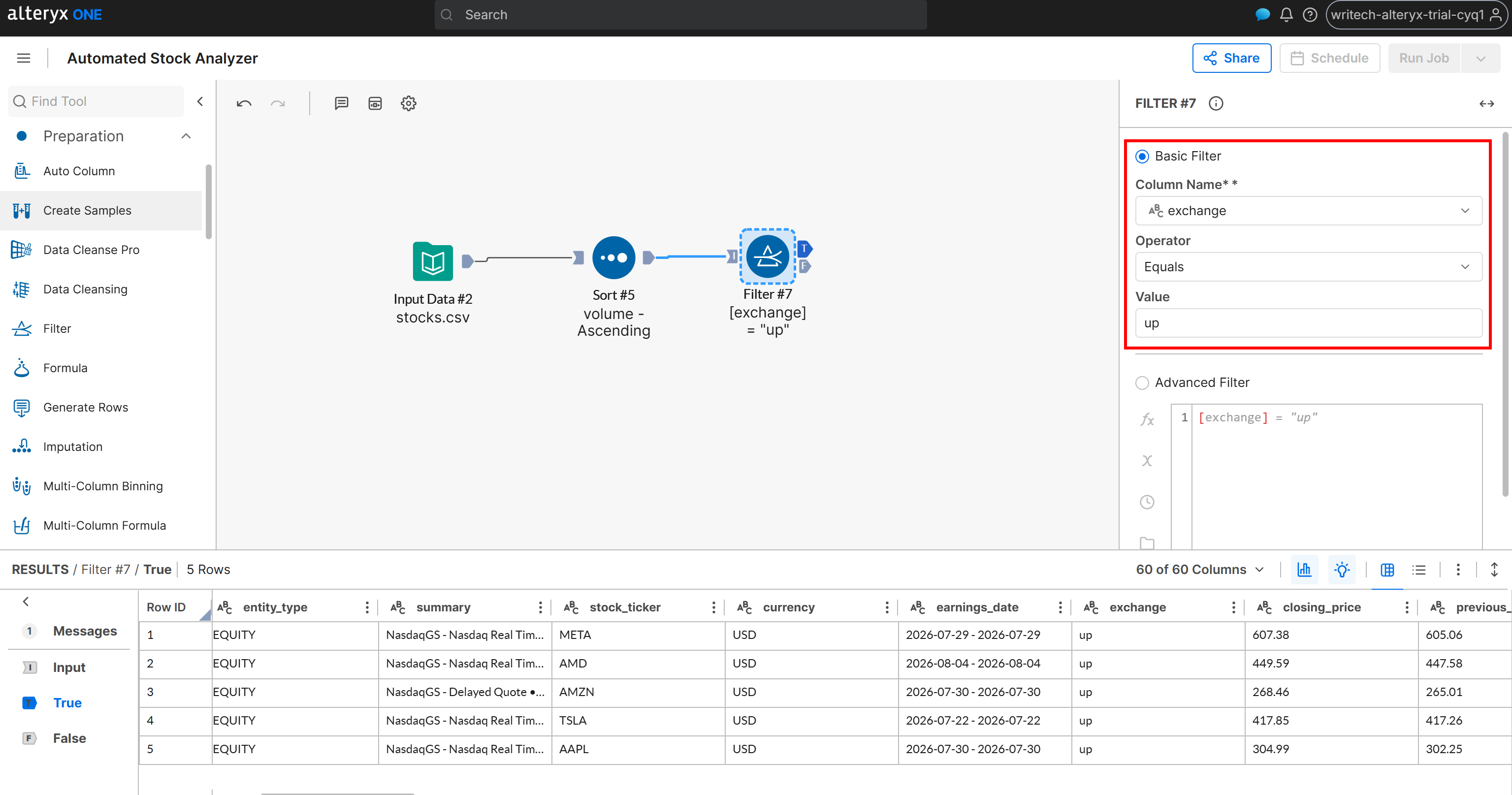
Le nœud Filter produit deux sorties :
T(True) : Contient les actions dont le champexchangeest « up ».F(False) : Contient les actions dont le champexchangen’est pas « up » (c’est-à-dire « down »).
La dernière étape de ce simple workflow d’automatisation web consiste à définir les destinations de sortie. Occupons-nous-en !
Étape n°7 : Spécifier les fichiers de sortie
Ajoutez un nœud « Output Data » au canevas et connectez-le à la sortie T du nœud « Filter ». Configurez le nœud « Output Data » pour écrire les données dans votre bucket Amazon S3 (ou toute autre source de données connectée). Par exemple, créez un fichier nommé up_stocks.csv :
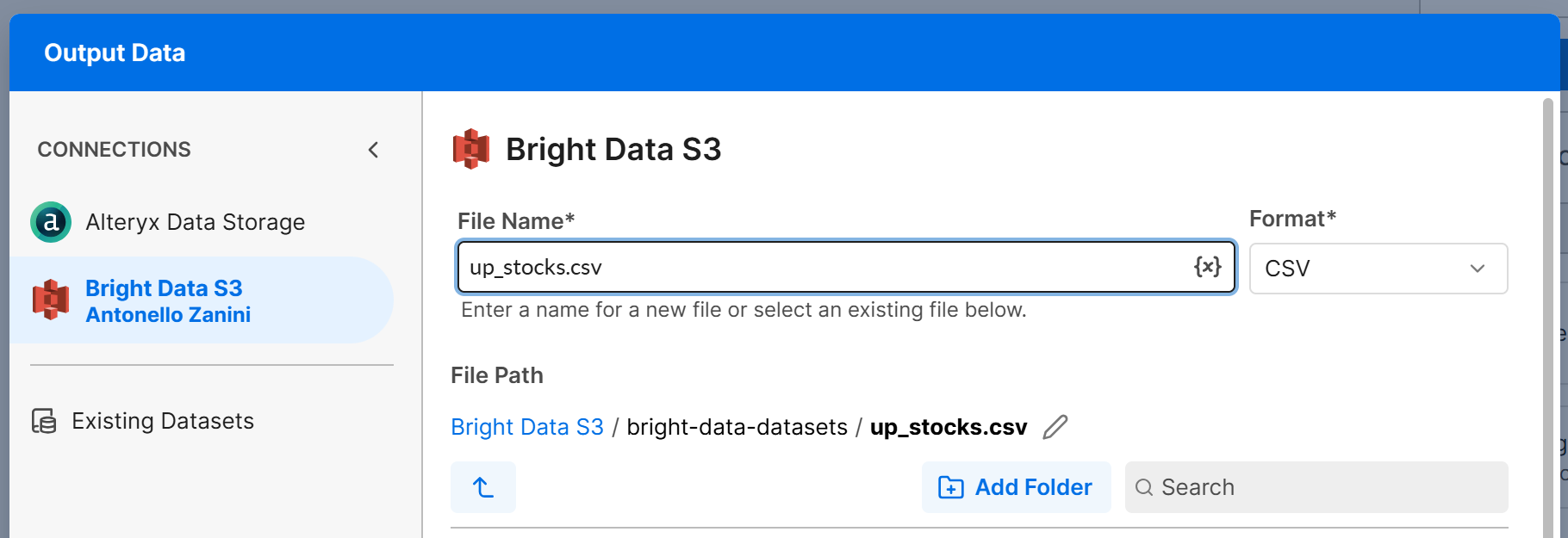
Cliquez sur « Next » puis sur « Confirm » pour enregistrer la configuration de sortie pour la branche T. Répétez le même processus pour la branche F, et configurez-la pour écrire dans un fichier down_stocks.csv.
Voici à quoi ressemblera le workflow final :
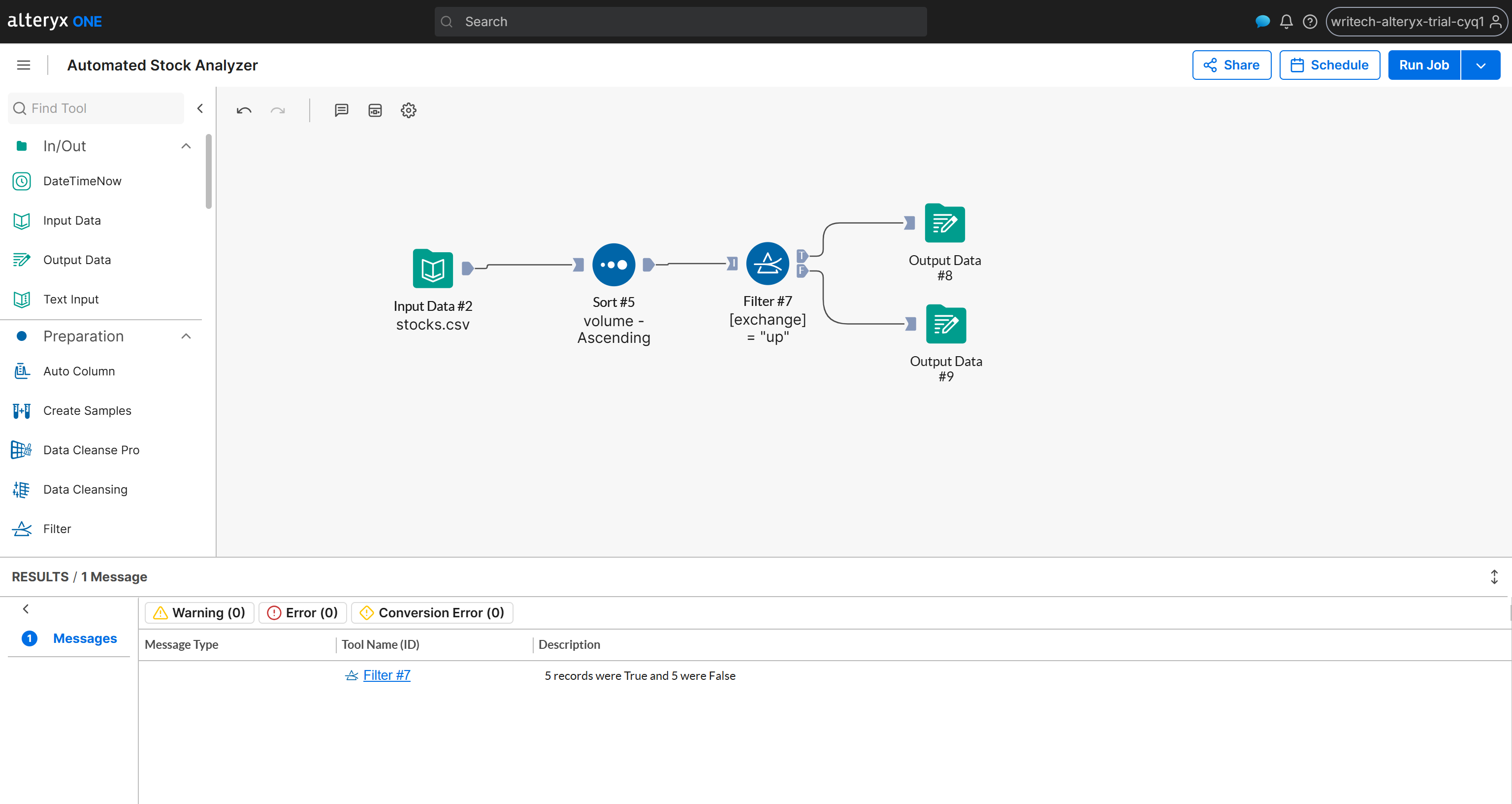
Mission accomplie ! Il ne vous reste plus qu’à exécuter le workflow pour vérifier que tout fonctionne comme prévu.
Étape n°8 : Lancer le workflow
Cliquez sur le bouton « Run Job » et attendez que le workflow automatisé d’analyse de données web propulsé par Bright Data se termine :

Une fois l’exécution terminée, vous recevrez une notification de succès dans Alteryx One, ainsi qu’un e-mail de confirmation.
Inspectez maintenant la sortie générée pour le scénario T :
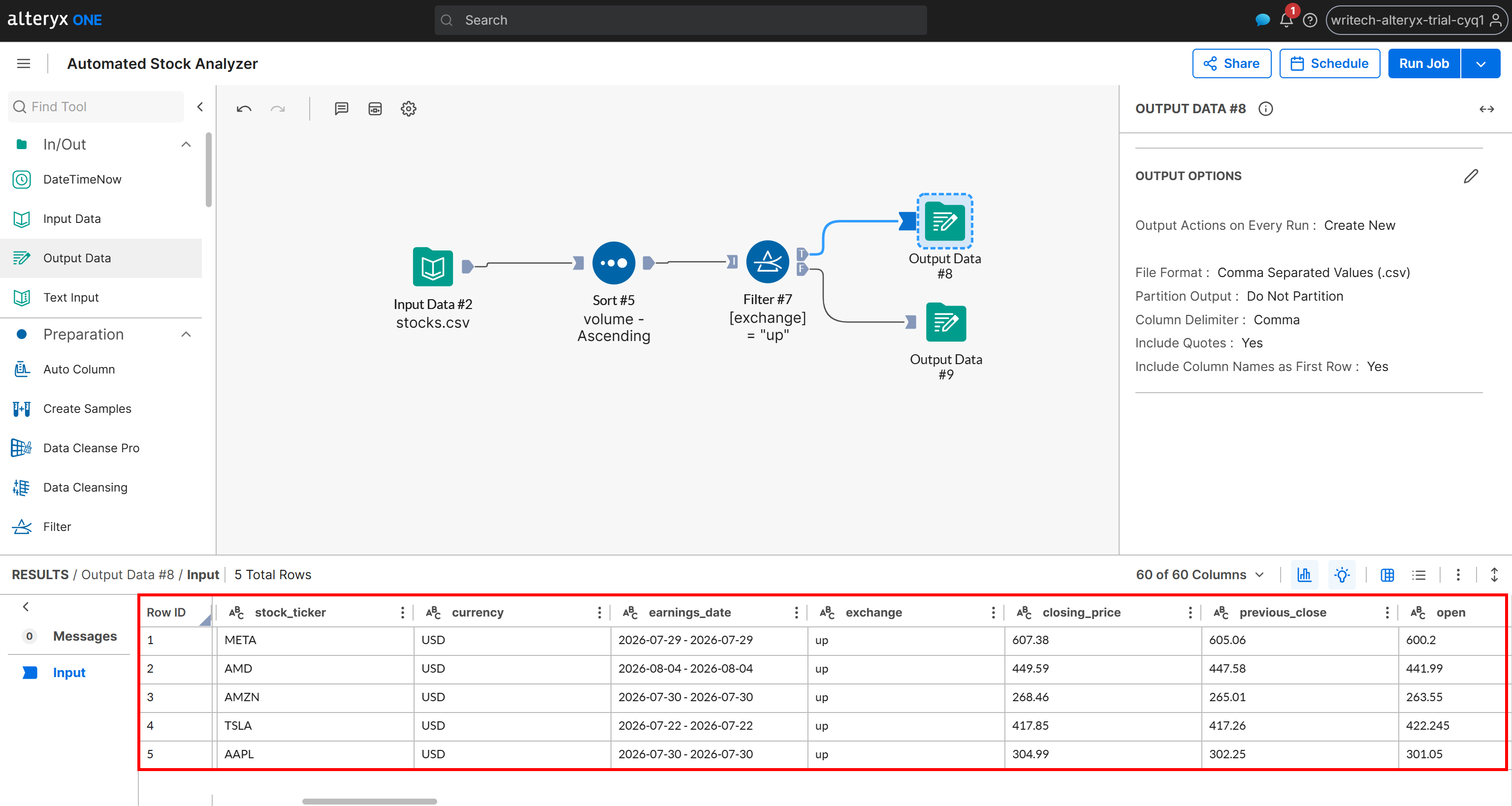
Notez que cette sortie contient uniquement les actions dont le statut de variation est « up », triées par volume en ordre croissant. Les mêmes données sont également disponibles dans le fichier up_stocks.csv généré par le pipeline et stocké dans votre bucket Amazon S3.
Inspectez ensuite la sortie générée pour le scénario F :
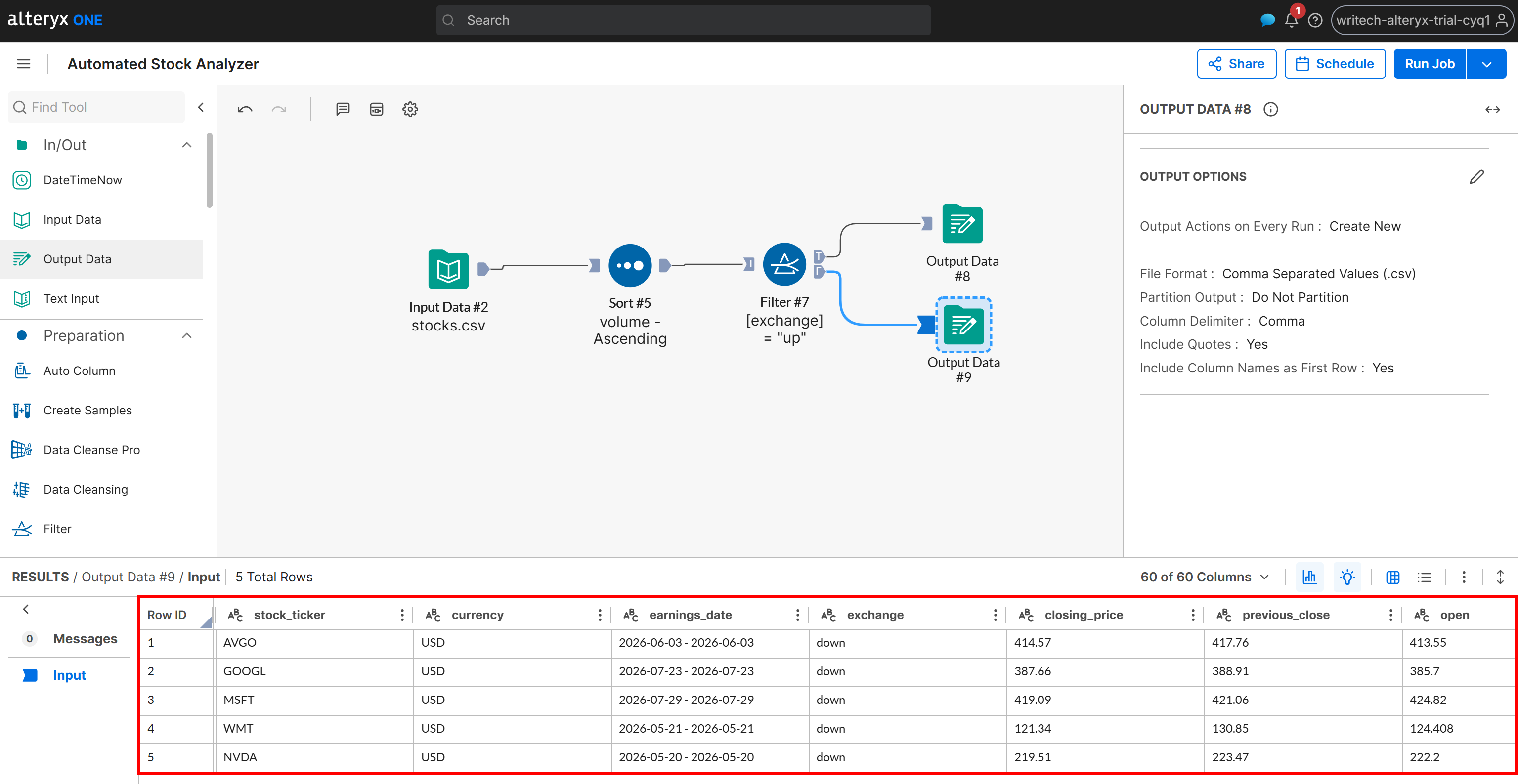
Cette sortie contient uniquement les actions dont le statut de variation est « down », également triées par volume en ordre croissant. Les mêmes résultats sont écrits dans le fichier down_stocks.csv dans votre bucket Amazon S3.
Et voilà ! Vous venez de créer un pipeline d’analyse de données web dans Alteryx One propulsé par Bright Data. Notez qu’il ne s’agissait que d’un exemple, et que de nombreux autres scénarios d’automatisation de données web sont possibles.
Prochaines étapes
Gardez à l’esprit qu’il ne s’agissait que d’un simple pipeline d’analyse de données avec quelques étapes d’exemple. En pratique, vous pouvez le rendre beaucoup plus complexe en ajoutant des nœuds de traitement supplémentaires (y compris des nœuds IA) et même en introduisant plusieurs sources de données.
Par exemple, vous pouvez configurer d’autres API de Web Scraping Bright Data pour écrire dans le même bucket Amazon S3. Les jeux de données résultants peuvent ensuite être combinés pour l’enrichissement et une analyse plus avancée à l’aide d’opérations de jointure.
De plus, pour créer un pipeline de données entièrement automatisé et toujours à jour :
- Déclenchez les API de Web Scraping Bright Data pour mettre à jour les données sources dans Amazon S3.
- Dans Bright Data, configurez un webhook qui appelle l’API d’exécution de workflow Alteryx One.
Conclusion
Dans ce tutoriel, vous avez appris ce qu’Alteryx One apporte à l’analyse de données automatisée. Plus précisément, vous avez vu comment les données récupérées via les API de Web Scraping de Bright Data peuvent être intégrées dans Alteryx One via Amazon S3. Des données web de haute qualité améliorent considérablement la précision et la valeur des insights, conduisant à de meilleurs résultats d’analyse.
Créez un compte Bright Data gratuit dès aujourd’hui et commencez à explorer nos solutions de données web prêtes pour l’entreprise !





