
Dans ce guide, vous découvrirez :
- Ce qu’est Langflow et pourquoi il est devenu si populaire.
- Les limites de l’utilisation des LLMs standards dans les applications Langflow, et comment les surmonter avec des données externes.
- Comment construire une application Langflow AI intégrée à Bright Data pour l’accès aux données web.
Plongeons dans l’aventure !
Qu’est-ce que Langflow ?
Langflow est un outil open-source construit en Python et JavaScript pour construire et déployer des agents et des workflows alimentés par l’IA. Avec plus de 92k étoiles sur GitHub, c’est l’une des bibliothèques les plus populaires et les plus largement adoptées pour le développement d’agents d’IA.
Langflow fonctionne comme une plateforme de développement visuel à code bas. Il vous permet de créer des applications complexes d’intelligence artificielle en connectant simplement des composants préconstruits à l’aide d’une interface de type “glisser-déposer”. Cette approche élimine la nécessité d’un codage intensif. Toutefois, Langflow prend en charge l’intégration de codes personnalisés pour une flexibilité maximale.
Langflow propose un large éventail de fonctionnalités d’IA, notamment des agents, des LLM, des magasins de vecteurs et une intégration avec n’importe quelle API, modèle ou base de données.
Pourquoi les applications d’IA ont besoin d’un accès aux données
Comparé à d’autres frameworks, Langflow brille en tant que plateforme visuelle low-code pour la création d’applications d’IA. Mais comme tout autre système alimenté par LLM, les applications basées sur Langflow ne sont aussi intelligentes que les données auxquelles elles ont accès.
Les LLM sont formés sur des ensembles de données statiques et ne sont pas sensibilisés aux événements en temps réel ou aux données d’entreprises privées. Ils sont donc déconnectés du monde actuel, à moins que vous ne les mettiez en contact avec des sources de données fraîches et pertinentes. Or, le web est la source d’information la plus vaste qui soit.
Pour surmonter ces limitations des LLM, Langflow vous permet de vous connecter à des pipelines de données web flexibles. Ce modèle est fondamental dans des cas d’utilisation importants tels que :
- Lesflux de travail du RAG, où les données récupérées améliorent les résultats du LLM.
- Les pipelines de données, où les données sont extraites et nettoyées avant d’être analysées.
- Les agents d’intelligence artificielle, qui ont besoin de connaissances externes pour effectuer des tâches telles que répondre à des requêtes, résumer des documents ou effectuer des recherches sur le web.
Or, l’extraction de données publiques précises sur le web n’est pas une mince affaire. Vous avez besoin d’une infrastructure qui peut :
- Se connecter à pratiquement n’importe quel site web (même ceux qui sont protégés par des technologies anti-scraping).
- Extraire les données requises de manière fiable.
- Renvoyez-le dans un format structuré et prêt à l’emploi.
C’est exactement ce que propose Bright Data. En combinant Langflow et les outils de Bright Data, votre application d’IA acquiert de puissantes capacités, notamment :
- Scraping web en temps réel tout en contournant les défenses anti-bots.
- Extraction de données structurées à partir de plateformes de premier plan telles qu’Amazon, LinkedIn, Zillow, etc.
- Accès aux résultats des moteurs de recherche pour des données SERP en direct, basées sur des requêtes.
- Capture visuelle des données grâce à des captures d’écran automatisées en pleine page.
Vous pouvez vous connecter à Bright Data directement via un composant Langflow personnalisé. Cela signifie que vous n’avez pas besoin de construire ou de maintenir une logique de backend complexe. Il vous suffit de connecter le composant à votre flux et vous êtes prêt à partir !
Construire une application d’IA en Langflow avec un accès aux données Web grâce à Bright Data
Dans ce tutoriel, vous utiliserez Langflow pour construire un agent d’intelligence artificielle capable de récupérer des données web en direct en l’intégrant à Bright Data.
Gardez à l’esprit que la configuration de l’agent d’IA présentée ici n’est qu’un exemple simple de ce que vous pouvez créer grâce à cette intégration. Il existe d’innombrables autres applications d’IA que vous pouvez créer grâce à l’intégration Bright Data × Langflow. Pour vous inspirer, consultez notre liste de cas d’utilisation possibles.
Suivez le guide ci-dessous pour créer un agent IA alimenté par Bright Data dans Langflow !
Conditions préalables
Pour suivre ce tutoriel, assurez-vous que vous remplissez les conditions suivantes :
- Au moins un processeur double cœur et 2 Go de RAM (recommandé : processeur multicœur et au moins 4 Go de RAM).
- Python version 3.10 à 3.12 sous Windows, ou 3.10 à 3.13 sous macOS/Linux, installé localement.
uvinstallé localement.- Une clé d’API de Bright Data.
- Une clé API pour se connecter à l’un des LLM pris en charge (ici, nous utiliserons Gemini, dont l’utilisation via l’API est gratuite).
Ne vous inquiétez pas si vous n’avez pas de clé API Bright Data, car vous serez guidé dans le processus de configuration au cours du didacticiel.
Pour installer uv, lancez la commande suivante :
pip install uvSi vous utilisez Windows, vous aurez également besoin de Microsoft Visual C++ 14.0 ou d’une version plus récente. Téléchargez-le et suivez le guide d’assistance pour terminer l’installation.
Étape 1 : Mise en place de Langflow
Tout d’abord, créez un dossier pour votre projet Langflow et naviguez-y :
mkdir langflow-agent
cd langflow-agentLe dossier langflow-agent servira de répertoire au projet Langflow.
Dans le dossier du projet, créez un environnement virtuel Python à l’aide de uv:
uv venv venvEnsuite, sous macOS/Linux, activez-le avec :
source venv/bin/activateDe manière équivalente, sous Windows, exécutez :
venvScriptsactivateAvec votre environnement virtuel activé, installez Langflow dans l’environnement de votre projet :
uv pip install langflowCela prendra un peu de temps, soyez patient.
Une fois l’installation terminée, vérifiez que l’installation fonctionne en lançant l’application à l’aide de cette commande :
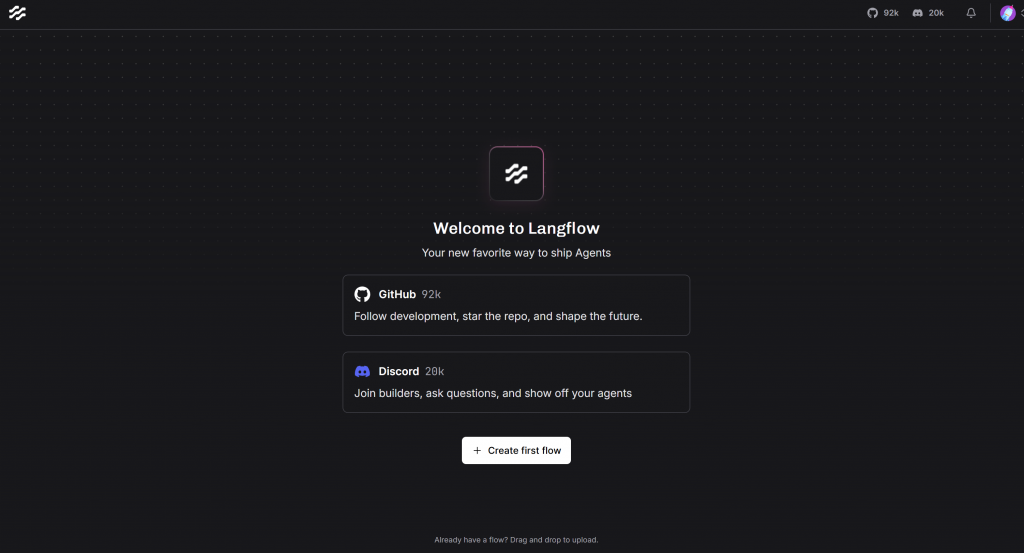
uv run langflow runAttendez que LangFlow initialise le serveur local. Une fois qu’il est prêt, il devrait être disponible sur cette page dans votre navigateur :
http://localhost:7860Ouvrez-le, et si tout s’est passé comme prévu et que c’est la première fois que vous utilisez Langflow, vous verrez cette interface :
Si vous rencontrez des erreurs, reportez-vous au guide d’installation officiel.
C’est formidable ! Votre installation LangFlow est maintenant opérationnelle.
Étape 2 : Configuration de Bright Data
Pour permettre à votre application d’IA de récupérer des données sur le web, vous devez la connecter à l’infrastructure d’IA de Bright Data.
Bright Data propose de nombreuses solutions de collecte de données, mais dans ce tutoriel, nous nous concentrerons sur.. :
- Web Unlocker: Une API de scraping avancée qui contourne les protections contre les robots et renvoie n’importe quelle page web au format HTML ou Markdown.
Remarque: l’intégration avec d’autres outils Bright Data tels que les API Web Scraper est également possible, mais ce guide se concentre sur le Web Unlocker à usage général.
Pour utiliser Web Unlocker dans votre application Langflow, vous devez tout d’abord :
- Configurez une zone Web Unlocker dans votre compte Bright Data.
- Générez votre clé API Bright Data pour authentifier les demandes.
Suivez les instructions ci-dessous pour faire les deux ! À titre de référence, vous pouvez également consulter la documentation officielle.
Tout d’abord, si vous n’avez pas encore de compte Bright Data, inscrivez-vous gratuitement. Si vous en avez un, connectez-vous et ouvrez votre tableau de bord. Cliquez sur le bouton “Proxies & Scraping” :
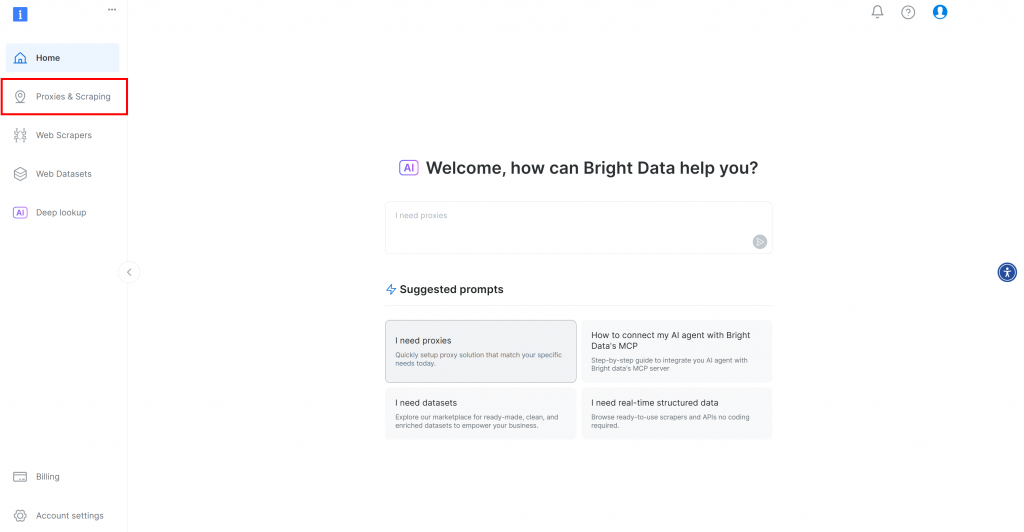
Vous serez redirigé vers la page “Proxies & Scraping Infrastructure” :

Si vous avez déjà une zone Web Unlocker, vous la verrez apparaître sur cette page. Dans cet exemple, la zone existe déjà et s’appelle "unblocker" (retenez ce nom, car vous en aurez besoin plus tard).
Si vous n’avez pas encore la zone requise, descendez jusqu’à la carte “Web Unlocker API” et cliquez sur “Créer une zone” :
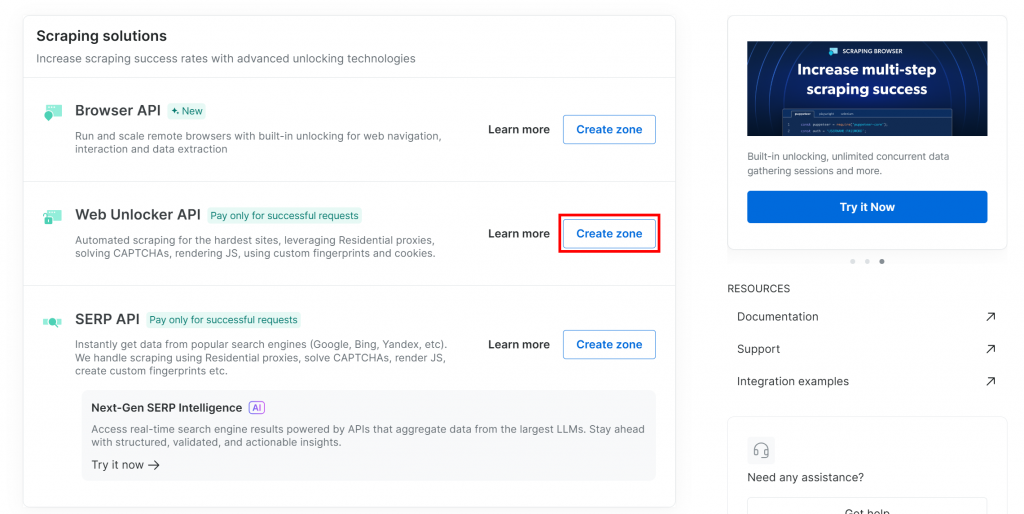
Donnez un nom à votre zone (comme “débloqueur”), activez les fonctions avancées pour de meilleures performances et cliquez sur le bouton “Ajouter” :
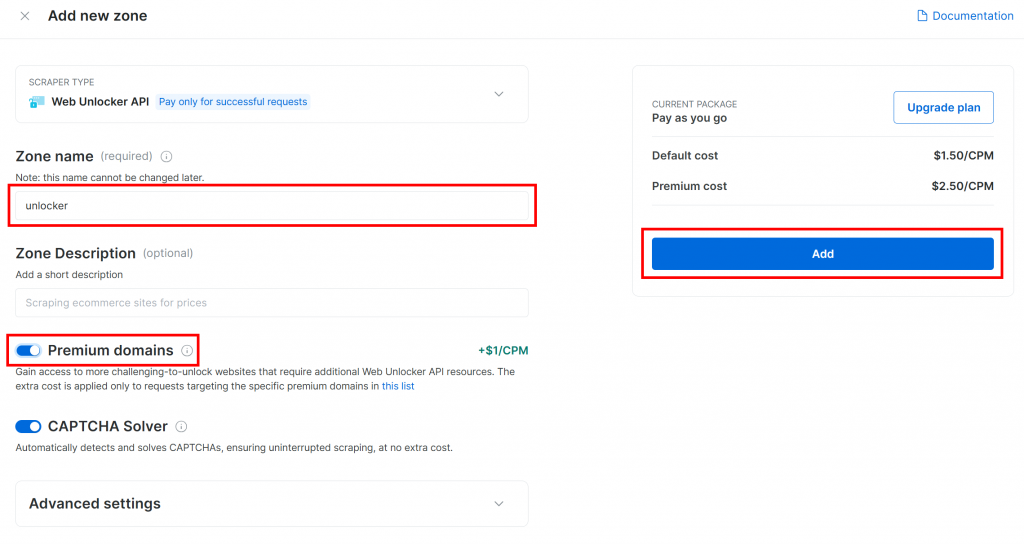
Une fois le produit créé, vous arrivez sur la page des détails de la zone. Assurez-vous que la case “Actif” est cochée, ce qui confirme que le produit est prêt à être utilisé :
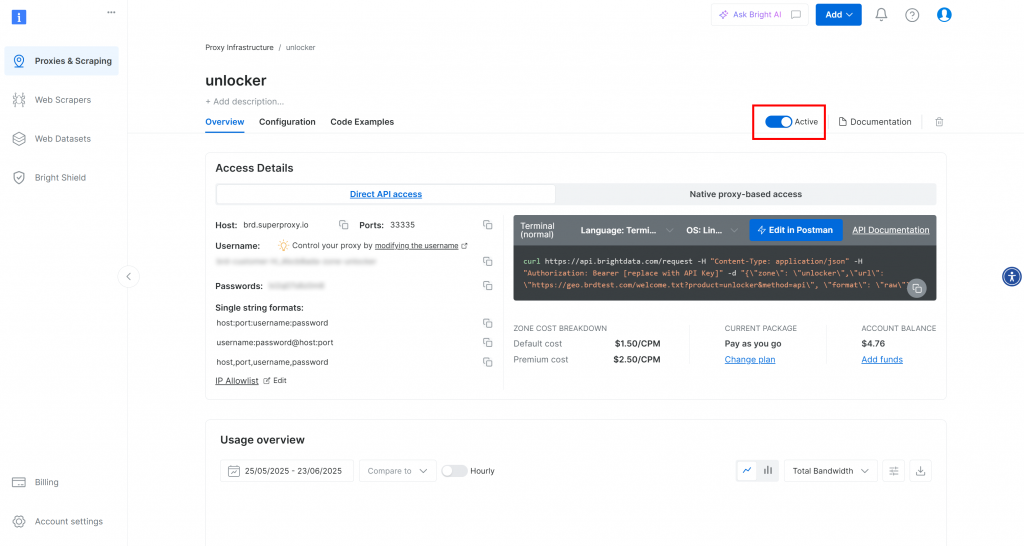
Suivez ensuite la documentation officielle de Bright Data pour générer votre clé API. Une fois que vous l’avez obtenue, conservez-la dans un endroit sûr, car vous en aurez bientôt besoin.
C’est parfait ! Vous êtes prêt à intégrer Bright Data à Langflow à l’aide d’un composant personnalisé.
Étape 3 : Initialisation d’un nouveau flux vierge
Avant de continuer, vous devez créer un nouveau flux Langflow. Retournez sur le serveur local Langflow et cliquez sur le bouton “Créer le premier flux” :

La fenêtre modale suivante apparaît. Appuyez sur le bouton “Blank Flow” dans le coin inférieur droit :
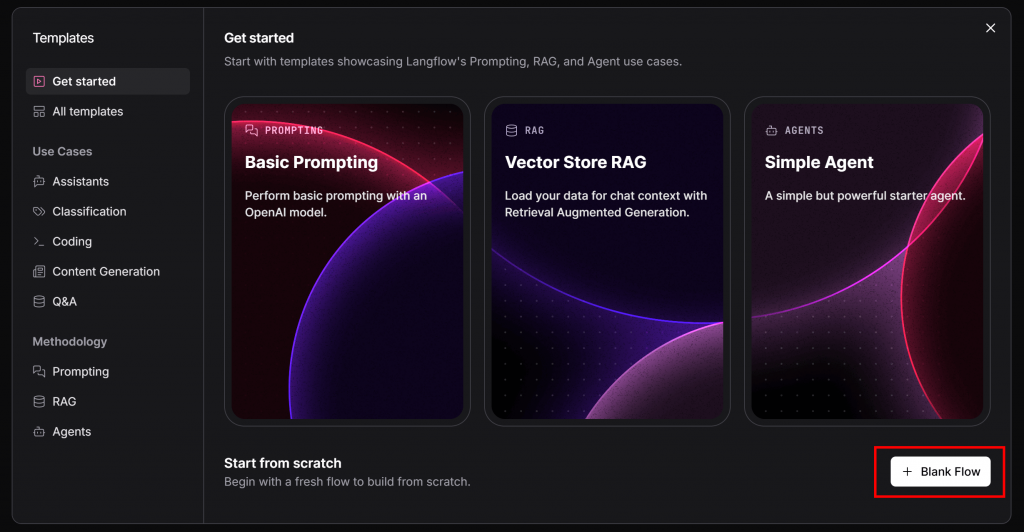
Donnez un nom à votre flux, par exemple “Langflow x Bright Data AI App”. Une fois créé, vous verrez une toile vierge comme celle-ci :
Le canevas ci-dessus est l’endroit où vous pouvez ajouter et connecter des composants pour définir votre application d’IA. Bravo pour votre travail !
Étape 4 : Définir un composant de données Bright personnalisé
La façon la plus simple d’intégrer Langflow à Bright Data est de créer un composant personnalisé. Celui-ci permettra à votre agent d’intelligence artificielle de collecter des données Web à l’aide de l’API Web Unlocker de Bright Data.
Dans Langflow, les composants personnalisés sont des classes Python définies par :
- Entrées: Les données ou paramètres dont votre composant a besoin.
- Sorties: Les données que votre composant renvoie aux nœuds en aval.
- Logique: Le traitement interne permettant de convertir les entrées en sorties.
Plus précisément, votre composant personnalisé Langflow x Bright Data doit.. :
- Acceptez votre clé API Bright Data et le nom de la zone Web Unlocker comme entrées (pour l’authentification).
- Recevez l’URL cible de la page web que vous souhaitez récupérer.
- Effectuer une requête à l’API Web Unlocker, configurée pour renvoyer la page au format Markdown ( idéal pour la consommation par l’IA).
- Renvoyer le contenu récupéré en tant que résultat.
Vous pouvez mettre en œuvre tout ce qui précède avec le composant Python personnalisé suivant :
from langflow.custom import Component
from langflow.io import SecretStrInput, StrInput, Output
from langflow.schema import Data
import httpx
# A Langflow custom component must extend Component
class BrightDataComponent(Component):
# The component name shown in the Langflow UI
display_name = "Bright Data"
# The description in the component details
description = "Retrieve data from the web in Markdown format using Bright Data"
icon = "sparkles" # UI icon identifier
name = "BrightData" # Internal name used by Langflow
# --- INPUTS ---
# Define the inputs required by the component
inputs = [
SecretStrInput(
name="api_key",
display_name="Bright Data API Key",
required=True,
info="Your Bright Data API key from the dashboard"
),
StrInput(
name="zone",
display_name="Web Unlocker Zone Name",
info="The name of the Web Unlocker zone to connect to (e.g., 'web_unlocker')",
required=True
),
StrInput(
name="url",
display_name="Target URL",
info="The URL to transform into Markdown data",
tool_mode=True
),
]
# --- OUTPUT ---
# Define the output returned by the component
outputs = [
Output(
name="web_data",
display_name="Web Data Result",
method="get_web_data" # The name of the method used to generate the output
)
]
# --- LOGIC ---
# This method retrieves web data from Bright Data and returns it
def get_web_data(self) -> Data:
try:
# Bright Data Web Unlocker API endpoint
url = "https://api.brightdata.com/request"
# Request headers including API key for authentication
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
# Payload specifying the zone, URL, and output format
payload = {
"zone": self.zone,
"url": self.url,
"format": "raw",
"data_format": "markdown"
}
# Send the POST request with a 180-second timeout
with httpx.Client(timeout=180.0) as client:
response = client.post(url, json=payload, headers=headers)
# Raise an error if HTTP status code is not 2xx
response.raise_for_status()
# Extract contains the Markdown-formatted web data
markdown_data = response.text
return Data(data={"data": markdown_data})
# Handle timeout errors
except httpx.TimeoutException:
error_msg = "The Web Unlocker request timed out"
return Data(data={"error": error_msg, "data": None})
# Handle other HTTP errors (e.g., 4xx, 5xx)
except httpx.HTTPStatusError as e:
error_msg = f"Request failed with status {e.response.status_code}: {e.response.text}"
return Data(data={"error": error_msg, "data": None})Le composant BrightData accepte les entrées suivantes :
- Votre clé d’API Bright Data.
- Le nom de votre zone Web Unlocker.
- L’URL de la page que vous souhaitez récupérer.
Il utilise ensuite le client HTTPX Python pour envoyer une requête à l’API Web Unlocker, configurée pour renvoyer la réponse au format Markdown. La représentation Markdown de la page renvoyée par l’API devient la sortie du composant.
Note: Nous avons utilisé HTTPX car c’est la bibliothèque client HTTP par défaut disponible dans Langflow. Pour en savoir plus, lisez notre guide sur l ‘utilisation de HTTPX pour le web scraping.
Fantastique ! Découvrez comment ajouter ce composant à votre flux et laisser l’agent d’intelligence artificielle consommer ses résultats.
Étape 5 : Ajouter le composant Custom Bright Data
Pour enregistrer le composant que vous avez défini précédemment, cliquez sur le bouton “Nouveau composant personnalisé” dans le coin inférieur gauche. Un nouveau composant personnalisé générique “Hello, World” apparaît sur votre toile. Survolez-le et cliquez sur la section “Code” pour personnaliser sa logique :
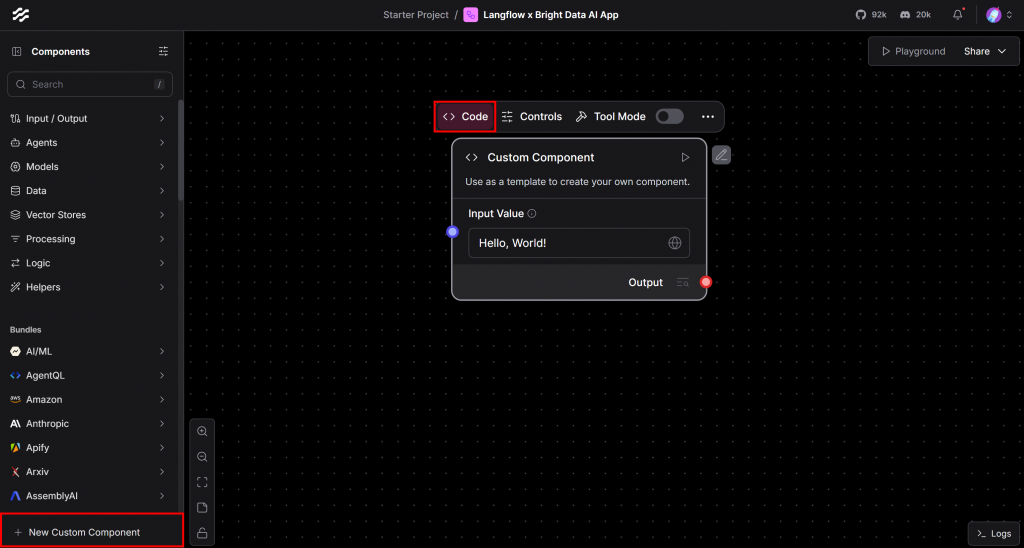
Dans l’éditeur de code qui apparaît, collez le code source complet de votre classe BrightDataComponent:
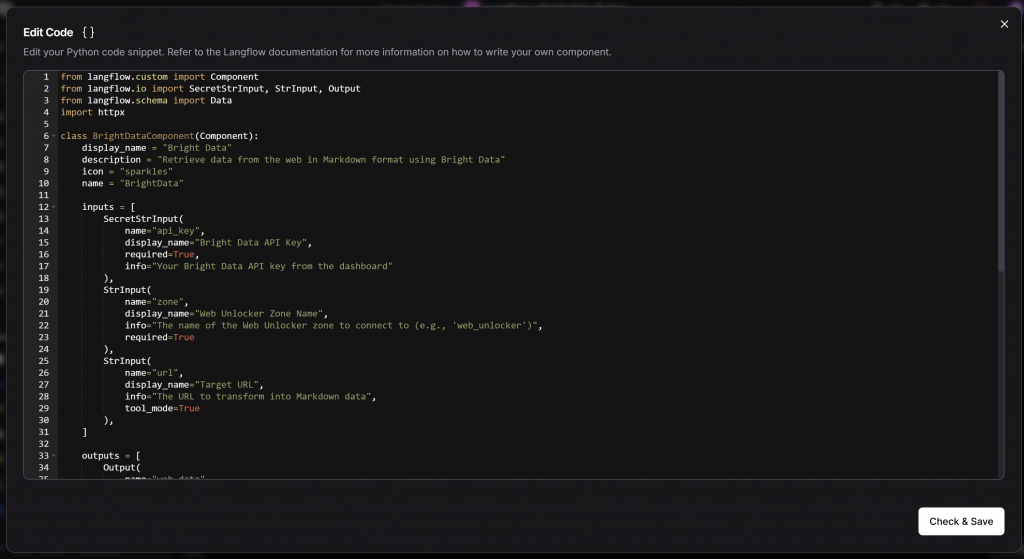
Appuyez sur le bouton “Check & Save”. Vous devriez maintenant voir le composant générique “Custom Component” remplacé par votre composant Bright Data :
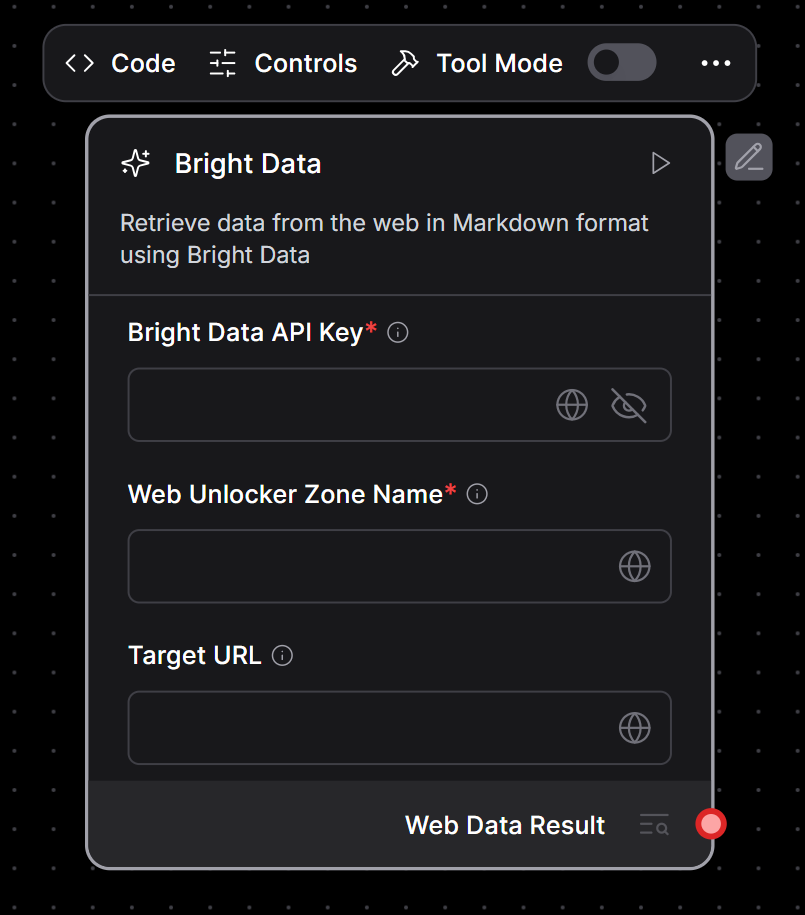
Comme vous pouvez le voir, le composant personnalisé de remplacement a été mis à jour avec votre composant personnalisé pour l’intégration avec Bright Data.
Remarque: il n’est pas nécessaire de recréer manuellement le composant Bright Data dans chaque flux.
Il vous suffit de stocker votre composant personnalisé dans un fichier Python et de le charger automatiquement à l’aide de la méthode décrite dans la documentation Langflow.
Merveilleux ! Votre flux d’IA peut désormais s’intégrer à Bright Data pour récupérer des données web.
Étape 6 : Connecter l’agent d’intelligence artificielle aux données Bright
Vous pouvez utiliser le composant Bright Data directement dans votre application Langflow ou le transformer en un outil avec lequel les agents d’intelligence artificielle peuvent interagir. En le transformant en outil, vous donnez à l’agent la possibilité d’extraire du contenu en direct de n’importe quelle page web dans un format Markdown adapté à l’IA. En d’autres termes, vous permettez à votre IA d’accéder et de récupérer des informations en temps réel à partir de n’importe quel site.
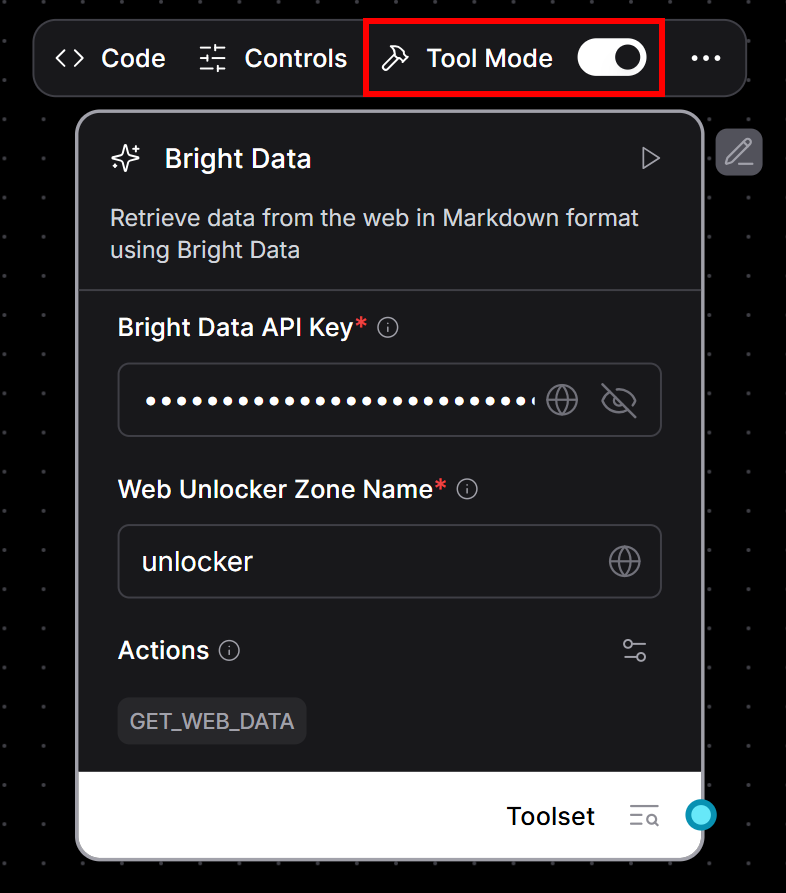
Faire du composant lumineux un outil :
- Survolez votre composant Bright Data.
- Activez le commutateur “Tool Mode” pour l’activer.
- Remplir les champs obligatoires :
- Votre clé d’API Bright Data.
- Le nom de votre zone Web Unlocker (par exemple,
"unlocker").
Voici ce que vous devriez voir maintenant :
Maintenant que votre composant Bright Data est prêt en tant qu’outil, connectez-le à un agent d’IA :
- Dans la barre latérale gauche, trouvez le composant “Agents > Agent”.
- Faites-le glisser sur la toile.
- Configurez l’agent pour qu’il utilise votre LLM préféré (dans cet exemple, nous utiliserons Gemini, en sélectionnant un modèle gratuit comme
gemini-2.5-flashet en collant votre clé API Gemini). - Connectez la sortie du composant Bright Data à l’entrée “Tools” du composant Agent :
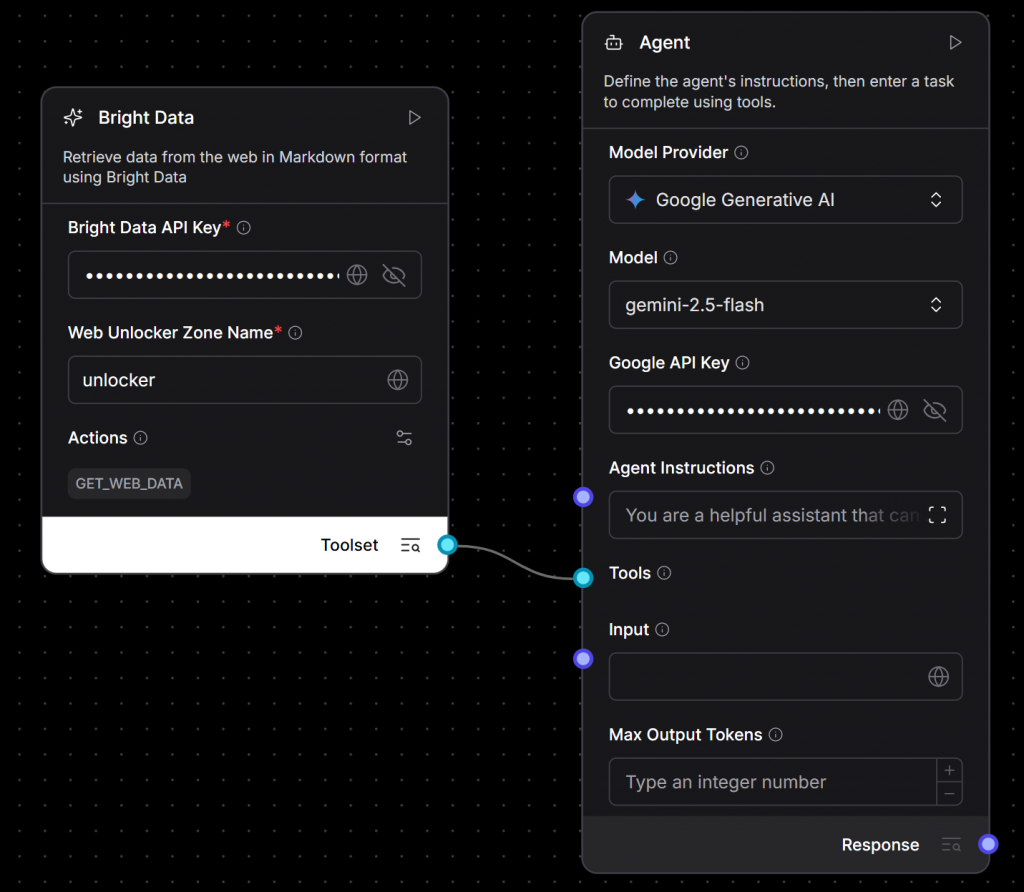
Nous y voilà ! Le cœur de votre application d’IA est désormais entièrement câblé. Vous venez de construire un agent alimenté par Gemini qui peut récupérer dynamiquement du contenu Web en direct à l’aide de l’infrastructure de scraping de Bright Data.
Étape 7 : Compléter le flux
Pour que votre flux d’IA soit pleinement fonctionnel, il a besoin d’un composant d’entrée et d’un composant de sortie. Connectez donc un composant Chat d’entrée à votre agent d’intelligence artificielle et un composant Chat de sortie pour recevoir sa réponse.
Après cela, votre flux devrait ressembler à ceci :
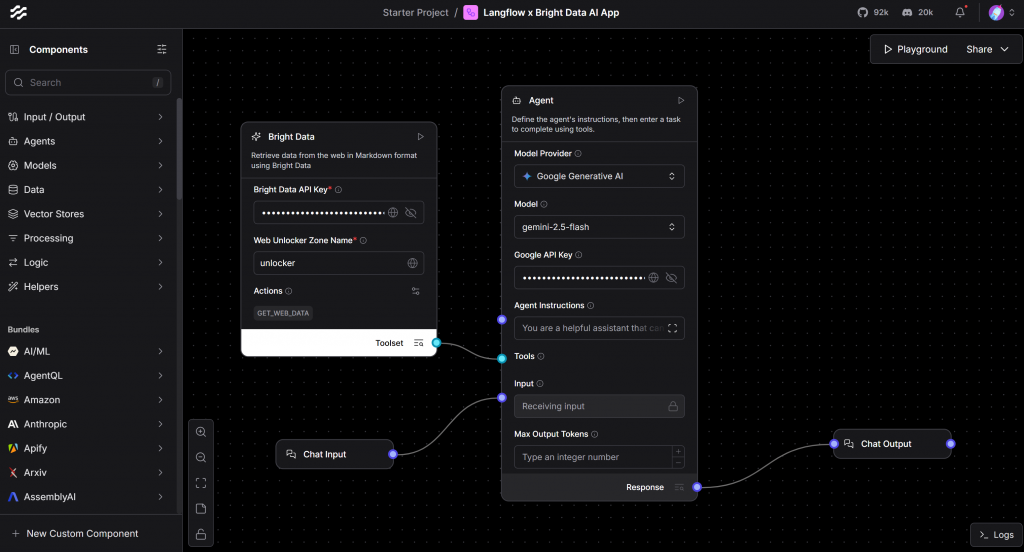
La configuration ci-dessus vous donne une interface de type chat pour interagir avec votre agent d’intelligence artificielle.
Vous y êtes ! Votre application Langflow × Bright Data AI est maintenant complète et prête à être utilisée.
Étape n° 8 : Tester l’application d’IA
Pour lancer votre application d’IA, cliquez sur le bouton “Playground” dans le coin supérieur droit de l’interface Langflow :

Voici ce que vous devriez voir :
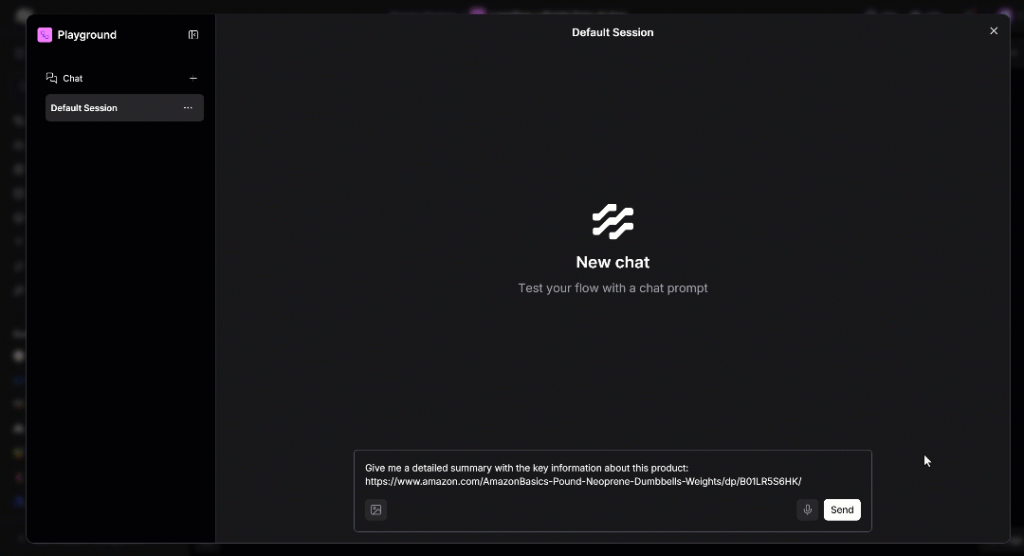
Vous obtenez une expérience de type ChatGPT, mais avec votre propre agent d’intelligence artificielle. Pour vérifier que tout fonctionne, essayez d’entrer une invite telle que :
Give me a detailed summary with the key information about this product:
https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/Voici ce qui se passera en coulisses :
- L’invite passe de Chat Input au composant AI Agent.
- L’agent utilise le LLM configuré (Gemini dans ce cas) et déclenche l’outil requis provenant du composant Bright Data.
- L’agent reçoit le contenu web scrappé, le traite et transmet la réponse finale à Chat Output (qui correspond à la réponse que vous verrez dans le chat).
L’invite ci-dessus est un excellent test, car Gemini seul ne peut pas gratter des sites tels qu’Amazon en raison de leurs protections anti-bots. Le Web Unlocker de Bright Data résout ce problème en contournant le CAPTCHA d’Amazon, en extrayant les données de la page et en les fournissant dans un format Markdown prêt pour l’IA.
Exécutez l’invite et vous devriez voir ce qui suit :
Pour confirmer que l’agent a utilisé Bright Data, développez la liste déroulante “Accessing web_get_data” :
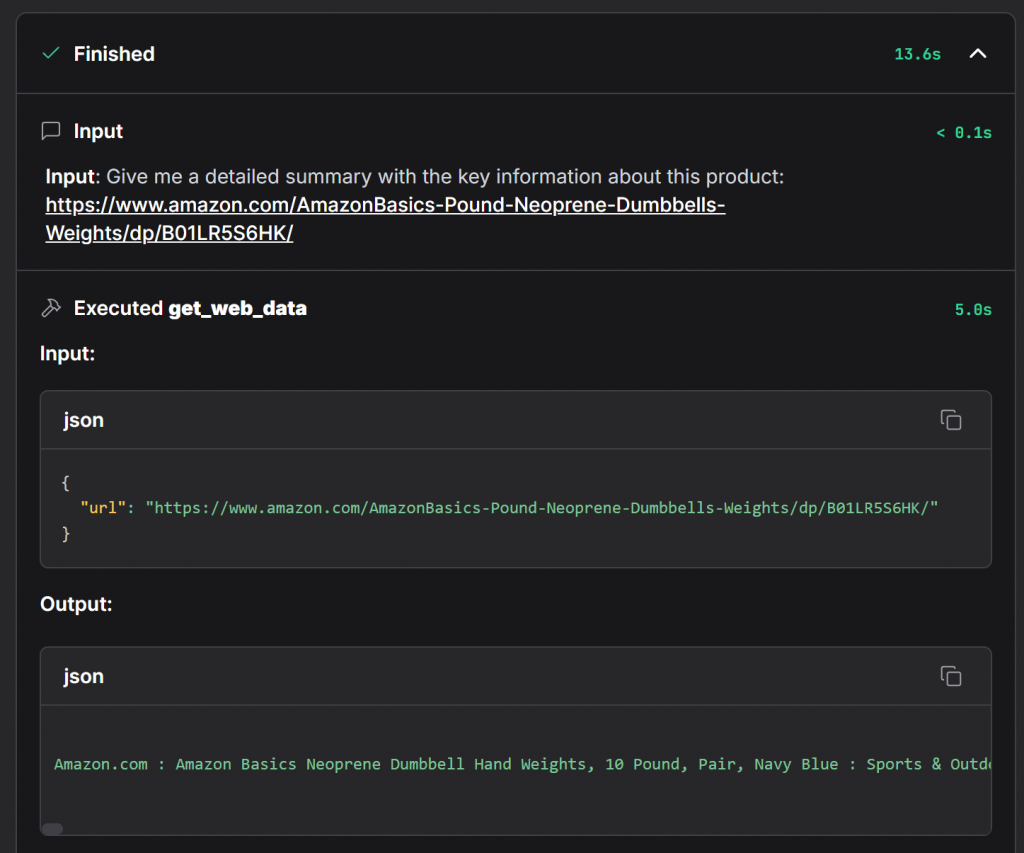
Cela montre tous les détails de l’appel de fonction get_web_data, qui est la méthode principale de votre composant Bright Data. Vous pouvez y vérifier que les données ont été extraites avec succès de la page du produit Amazon.
Voici une capture d’écran partielle du résultat produit par l’agent IA :

Chaque information contenue dans ce résumé généré par l’IA est réelle et non hallucinée, comme vous pouvez le vérifier en visitant la page originale d’Amazon:
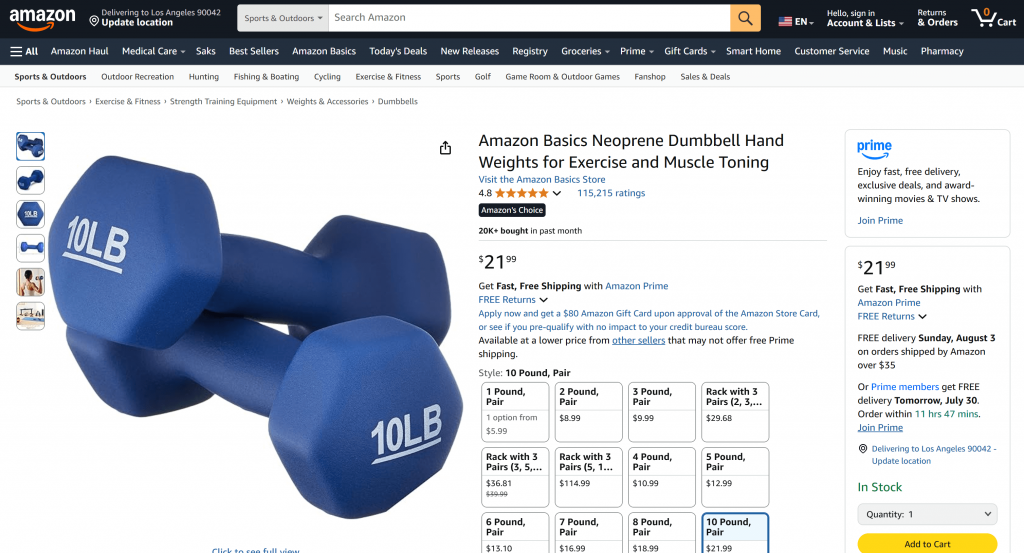
Et voilà ! Vous venez de construire et de tester une application d’IA avec accès aux données web en utilisant Langflow et Bright Data.
Prochaines étapes
Maintenant que votre intégration est opérationnelle, voici les prochaines étapes à suivre :
- Déployez votre agent à l’aide de l’une des méthodes officiellement prises en charge, soit dans le nuage, soit sur votre propre serveur.
- Étendez l’intégration en connectant d’autres produits Bright Data, tels que les API Web Scraper ou SERP. Pour ce faire, il suffit de modifier la logique de votre
composant BrightDatapour appeler différentes API de Bright Data , comme décrit dans la documentation officielle. - Recombinez vos composants pour créer des cas d’utilisation plus avancés, notamment des pipelines RAG, des flux de données, des flux d’automatisation de l’IA, etc.
- Connectez votre agent d’intelligence artificielle au serveur MCP de Bright Data pour l’intégrer à plus de 50 outils prêts à l’emploi.
Conclusion
Dans cet article, vous avez appris à utiliser Langflow pour construire un agent d’intelligence artificielle avec un accès aux données web. Cela a été rendu possible grâce à une intégration personnalisée avec les outils de Bright Data. Cette configuration donne à votre LLM la possibilité d’extraire et de traiter des données de pratiquement n’importe quel site web en temps réel.
Gardez à l’esprit que ce que nous avons présenté ici n’est qu’un exemple de base. Si vous souhaitez créer des agents plus avancés, vous avez besoin d’outils pour récupérer, valider et transformer les données Web en direct en informations optimisées pour la consommation de l’IA. C’est précisément ce que vous trouverez dans l’infrastructure Bright Data AI.
Créez un compte Bright Data gratuit et commencez à expérimenter nos outils de recherche de données prêts pour l’IA !




