

La formation d’un modèle d’IA consiste à lui apprendre à reconnaître des schémas dans les données afin de prendre des décisions. Le réglage fin est une stratégie qui adapte les modèles formés sur de grands ensembles de données, tels que le GPT-4 d’OpenAI, à des ensembles de données plus petits et spécifiques à une tâche, en poursuivant le processus de formation.
Dans les sections suivantes, nous allons approfondir le processus d’entraînement d’un modèle d’IA personnalisé à l’aide d’OpenAI fine-tuning, en vous guidant à travers chaque étape du processus de fine-tuning.
Comprendre l’IA et la formation des modèles
L’intelligence artificielle (IA) consiste à développer des systèmes capables d’accomplir des tâches qui requièrent généralement une intelligence de type humain, telles que l’apprentissage, la résolution de problèmes et la prise de décision. Un modèle d’IA, à la base, est un ensemble d’algorithmes qui font des prédictions basées sur des données d’entrée. L’apprentissage automatique, un sous-ensemble de l’IA, permet aux machines d’apprendre à partir de données et d’améliorer leurs performances de manière autonome.
Les modèles d’IA apprennent de la même manière qu’un enfant fait la distinction entre un chat et un chien, en observant les caractéristiques, en faisant des suppositions, en corrigeant les erreurs et en réessayant. Ce processus, connu sous le nom d’apprentissage du modèle, implique que le modèle traite les données d’entrée, analyse et traite les modèles, et utilise ces connaissances pour faire des prédictions. Les performances du modèle sont évaluées en comparant ses résultats aux résultats attendus, et des ajustements sont effectués pour améliorer les performances. Avec un entraînement suffisant, l’ensemble des algorithmes du modèle représentera un prédicteur mathématique précis pour une situation donnée, capable de gérer différentes variations des données d’entrée.
La formation d’un modèle à partir de zéro consiste à enseigner à un modèle à apprendre des modèles dans les données sans aucune connaissance préalable. Cela nécessite une grande quantité de données et de ressources informatiques, et le modèle peut ne pas être performant avec des données limitées.
Le réglage fin, quant à lui, commence par un modèle pré-entraîné qui a appris des modèles généraux à partir d’un grand ensemble de données. Le modèle est ensuite entraîné sur un ensemble de données plus petit et spécifique, ce qui lui permet d’appliquer les connaissances acquises précédemment à la nouvelle tâche, ce qui permet souvent d’obtenir de meilleures performances avec moins de données et de ressources informatiques. Le réglage fin est particulièrement utile lorsque l’ensemble de données spécifique à la tâche est relativement petit.
Préparation de la mise au point
L’amélioration d’un modèle existant par un entraînement supplémentaire sur un ensemble de données peut sembler une option intéressante par rapport à la création et à l’entraînement d’un modèle d’IA à partir de zéro. Toutefois, la réussite du processus d’affinage dépend de plusieurs facteurs clés.
Choisir le bon modèle
Lors de la sélection d’un modèle de base à affiner, il convient de tenir compte des éléments suivants :
Alignement des tâches : Il est important de définir clairement la portée de votre problème et la fonctionnalité attendue du modèle. Choisissez des modèles qui excellent dans des tâches similaires aux vôtres, car une dissemblance entre les tâches source et cible au cours du processus de réglage fin peut entraîner une baisse des performances. Par exemple, pour les tâches de génération de texte, GPT-3 peut convenir, alors que pour les tâches de classification de texte, BERT ou RoBERTa peuvent être plus performants.
Taille et complexité du modèle : Équilibrer les performances et l’efficacité en fonction des besoins, car si les modèles de grande taille capturent mieux les modèles complexes, ils requièrent davantage de ressources.
Mesures d’évaluation : Choisissez des mesures d’évaluation pertinentes pour votre tâche. Par exemple, la précision peut être importante pour la classification, tandis que BLEU ou ROUGE peut être bénéfique pour les tâches de génération de langage.
Communauté et ressources : Choisissez des modèles qui bénéficient d’une large communauté et de nombreuses ressources pour le dépannage et la mise en œuvre. Donnez la priorité aux modèles qui proposent des lignes directrices claires en matière de réglage fin pour votre tâche et recherchez des sources réputées pour les points de contrôle des modèles pré-entraînés.
Collecte et préparation des données
Lors de la mise au point, la qualité et la diversité de vos données peuvent avoir un impact significatif sur la performance de votre modèle. Voici quelques éléments clés à prendre en compte :
Types de données nécessaires : Le type de données dépend de votre tâche spécifique et des données sur lesquelles le modèle a été pré-entraîné. Pour les tâches NLP, vous avez généralement besoin de données textuelles provenant de sources telles que des livres, des articles, des messages sur les médias sociaux ou des transcriptions de discours. Utilisez des méthodes telles que le web scraping, les enquêtes ou les API des plateformes de médias sociaux pour collecter des données. Par exemple, le web scraping avec l’IA peut être particulièrement utile lorsque vous avez besoin d’une grande quantité de données diverses et actualisées.
Nettoyage et annotation des données : Le nettoyage des données consiste à supprimer les données non pertinentes, à traiter les données manquantes ou incohérentes et à les normaliser. L’annotation consiste à étiqueter les données afin que le modèle puisse en tirer des enseignements. L’utilisation d’outils automatisés tels que Bright data permet de rationaliser ces processus et d’améliorer l’efficacité.
Incorporation d’un ensemble de données diversifié et représentatif : Lors de la mise au point d’un modèle, un ensemble de données diversifié et représentatif garantit que le modèle apprend à partir de différentes perspectives, ce qui permet d’obtenir des prédictions plus généralisées et plus fiables. Par exemple, si vous affinez un modèle d’analyse des sentiments pour les critiques de films, votre ensemble de données doit inclure des critiques d’un large éventail de films, de genres et de sentiments, reflétant ainsi la distribution des classes dans le monde réel.
Mise en place de l’environnement de formation
Assurez-vous que vous disposez du matériel et des logiciels nécessaires pour le modèle et le cadre d’IA choisis. Par exemple, les grands modèles de langage (LLM) nécessitent souvent une puissance de calcul importante, généralement fournie par les GPU.
Des frameworks tels que TensorFlow ou PyTorch sont couramment utilisés pour l’apprentissage des modèles d’IA. L’installation des bibliothèques et des outils pertinents, ainsi que de toutes les dépendances supplémentaires, est essentielle pour une intégration transparente dans le flux de travail de formation. Par exemple, des outils tels que l’API OpenAI peuvent être nécessaires pour affiner des modèles spécifiques développés par OpenAI.
Le processus de mise au point
Après avoir compris les principes de base de la mise au point, examinons une application dans le domaine du traitement du langage naturel.
J’utiliserai l’API OpenAI pour affiner un modèle pré-entraîné. Le réglage fin est actuellement possible pour les modèles tels que gpt-3.5-turbo-0125 (recommandé), gpt-3.5-turbo-1106, gpt-3.5-turbo-0613, babbage-002, davinci-002, et le modèle expérimental gpt-4-0613. Le réglage fin du GPT-4 est en phase expérimentale et les utilisateurs éligibles peuvent en demander l’accès dans l’interface utilisateur du réglage fin.
1. Préparation de l’ensemble de données
Selon une étude, il a été constaté que le GPT-3.5 manque de raisonnement analytique. Essayons donc d’affiner le modèle gpt-3.5-turbo pour améliorer son raisonnement analytique à l’aide d’un ensemble de questions de raisonnement analytique issues du test d’admission aux facultés de droit (AR-LSAT), publié en 2022. L’ensemble de données accessible au public est disponible ici.
La qualité d’un modèle affiné dépend directement des données utilisées pour l’affinage. Chaque exemple de l’ensemble de données doit être une conversation formatée selon l’API Chat Completions d’OpenAI, avec une liste de messages où chaque message a un rôle, un contenu et un nom optionnel, et stocké sous forme de fichier JSONL.
Le format de conversation requis pour la mise au point de gpt-3.5-turboisest le suivant :
{"messages": [{"role": "system", "content": ""}, {"role": "user", "content": ""}, {"role": "assistant", "content": ""}]}
Dans ce format, "messages" est une liste de messages formant une conversation entre trois "rôles": système, utilisateur et assistant. Le "contenu" du rôle "système" doit spécifier le comportement du système affiné.
Vous trouverez ci-dessous un exemple formaté tiré de l’ensemble de données AR-LSAT que nous utiliserons dans ce guide :

Voici les principales considérations à prendre en compte lors de la création de l’ensemble de données :
- Page de tarification d’OpenAI
- carnet de comptage de jetons
- Script Python
2. Générer la clé API et installer la bibliothèque OpenAI
Afin d’affiner un modèle OpenAI, il est obligatoire d’avoir un compte de développeur OpenAI avec un solde de crédit suffisant.
Pour générer la clé API et installer la bibliothèque OpenAI, suivez ces étapes :
1. Inscrivez-vous sur le site officiel d’OpenAI.
2. Pour permettre un réglage fin, rechargez votre solde de crédit à partir de l’onglet “Facturation” sous “Paramètres”.
3. Cliquez sur l’icône du profil de l’utilisateur dans le coin supérieur gauche et sélectionnez “API Keys” pour accéder à la page de création de clés.
4. Générer une nouvelle clé secrète en fournissant un nom.

5. Installez la bibliothèque Python OpenAI pour un réglage fin.
pip install openai
6. Utilisez la bibliothèque os pour définir le jeton comme variable d’environnement et établir la communication API.
import os
from openai import OpenAI
# Set the OPENAI_API_KEY environment variable
os.environ['OPENAI_API_KEY'] = 'The key generated in step 4'
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'])
3. Téléchargement des fichiers de formation et de validation
Après avoir validé vos données, téléchargez les fichiers à l’aide de l’API Fichiers pour affiner les tâches.
training_file_id = client.files.create(
file=open(training_file_name, "rb"),
purpose="fine-tune"
)
validation_file_id = client.files.create(
file=open(validation_file_name, "rb"),
purpose="fine-tune"
)
print(f"Training File ID: {training_file_id}")
print(f"Validation File ID: {validation_file_id}")
Les identifiants uniques des données de formation et de validation s’affichent en cas d’exécution réussie.

4. Création d’un travail de mise au point
Après avoir téléchargé les fichiers, créez une tâche de réglage fin, soit via l’interface utilisateur, soit par programmation.
Voici comment lancer un travail de réglage fin à l’aide du SDK OpenAI :
response = client.fine_tuning.jobs.create(
training_file=training_file_id.id,
validation_file=validation_file_id.id,
model="gpt-3.5-turbo",
hyperparameters={
"n_epochs": 10,
"batch_size": 3,
"learning_rate_multiplier": 0.3
}
)
job_id = response.id
status = response.status
print(f'Fine-tunning model with jobID: {job_id}.')
print(f"Training Response: {response}")
print(f"Training Status: {status}")
model: le nom du modèle à affiner(gpt-3.5-turbo,babbage-002,davinci-002, ou un modèle existant affiné).fichier_formationetfichier_validation: les identifiants des fichiers renvoyés lors de leur téléchargement.n_epochs,batch_size, etlearning_rate_multiplier: Hyperparamètres qui peuvent être personnalisés.
Pour définir des paramètres de réglage fin supplémentaires, reportez-vous à la spécification de l’API pour le réglage fin.
Le code ci-dessus génère les informations suivantes pour le jobID (`ftjob-0EVPunnseZ6Xnd0oGcnWBZA7`) :

Une tâche de réglage fin peut prendre du temps. Il peut être mis en file d’attente derrière d’autres tâches, et la durée de la formation peut varier de quelques minutes à quelques heures en fonction du modèle et de la taille de l’ensemble de données.
Une fois la formation terminée, un courriel de confirmation sera envoyé à l’utilisateur qui a lancé le travail de mise au point.
Vous pouvez contrôler l’état de votre travail de réglage fin via l’interface utilisateur de réglage fin :
5. Analyse du modèle affiné
OpenAI calcule les paramètres suivants pendant la formation :
- Perte de formation
- Précision des jetons d’entraînement
- Perte de validation
- Précision du jeton de validation
La perte de validation et la précision des jetons de validation sont calculées de deux manières : sur un petit lot de données à chaque étape, et sur l’ensemble de validation complet à la fin de chaque époque. La perte de validation totale et la précision des jetons de validation totale sont les mesures les plus précises pour suivre les performances de votre modèle et servent à vérifier que l’apprentissage se déroule sans heurts (la perte doit diminuer, la précision des jetons doit augmenter).
Lorsqu’un travail de réglage fin est actif, vous pouvez consulter ces mesures via
1. L’interface utilisateur :

2. L’API :
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'],)
jobid = ‘jobid you want to monitor’
print(f"Streaming events for the fine-tuning job: {jobid}")
# signal.signal(signal.SIGINT, signal_handler)
events = client.fine_tuning.jobs.list_events(fine_tuning_job_id=jobid)
try:
for event in events:
print(
f'{event.data}'
)
except Exception:
print("Stream interrupted (client disconnected).")
Le code ci-dessus produira les événements de flux pour le travail de réglage fin, y compris le nombre d’étapes, la perte d’apprentissage, la perte de validation, le nombre total d’étapes et la précision moyenne des jetons pour l’apprentissage et la validation :
Streaming events for the fine-tuning job: ftjob-0EVPunnseZ6Xnd0oGcnWBZA7
{'step': 67, 'train_loss': 0.30375099182128906, 'valid_loss': 0.49169286092122394, 'total_steps': 67, 'train_mean_token_accuracy': 0.8333333134651184, 'valid_mean_token_accuracy': 0.8888888888888888}
6. Ajuster les paramètres et l’ensemble de données pour améliorer les performances
Si les résultats d’un travail de réglage fin ne sont pas à la hauteur de vos espérances, envisagez les moyens suivants pour améliorer les performances :
1. Ajuster l’ensemble de données de formation :
- Pour affiner votre ensemble de données de formation, envisagez d’ajouter des exemples qui répondent aux faiblesses du modèle et assurez-vous que la distribution des réponses dans vos données correspond à la distribution attendue.
- Il est également important de vérifier vos données pour détecter les problèmes que le modèle reproduit et de s’assurer que vos exemples contiennent toutes les informations nécessaires à la réponse.
- Maintenir la cohérence entre les données créées par plusieurs personnes et normaliser le format de tous les exemples de formation pour qu’il corresponde à ce qui est attendu lors de l’inférence.
- En général, des données de haute qualité sont plus efficaces qu’une grande quantité de données de faible qualité.
2. Ajustement des hyperparamètres :
- OpenAI vous permet de spécifier trois hyperparamètres : les époques, le multiplicateur du taux d’apprentissage et la taille du lot.
- Commencez par les valeurs par défaut choisies par les fonctions intégrées en fonction de la taille de l’ensemble de données, puis ajustez-les si nécessaire.
- Si le modèle ne suit pas les données d’apprentissage comme prévu, augmentez le nombre d’époques.
- Si le modèle devient moins diversifié que prévu, diminuez le nombre d’époques de 1 ou 2.
- Si le modèle ne semble pas converger, augmentez le multiplicateur du taux d’apprentissage.
7. Utilisation d’un modèle à points de contrôle
Actuellement, OpenAI donne accès aux points de contrôle des trois dernières époques d’un travail de réglage fin. Ces points de contrôle sont des modèles complets qui peuvent être utilisés pour l’inférence et la mise au point ultérieure.
Pour accéder à ces points de contrôle, attendez qu’un travail aboutisse, puis interrogez le point d’arrivée des points de contrôle avec l’identifiant de votre travail de réglage fin. Le champ fine_tuned_model_checkpoint de chaque objet de point de contrôle sera renseigné avec le nom du point de contrôle du modèle. Vous pouvez également obtenir le nom du modèle de point de contrôle via l’interface utilisateur de réglage fin
Vous pouvez valider les résultats du modèle de point de contrôle en exécutant des requêtes avec une invite et le nom du modèle à l’aide de la fonction openai.chat.completions.create() :
completion = client.chat.completions.create(
model="ft:gpt-3.5-turbo-0125:personal::9PWZuZo5",
messages=[
{"role": "system", "content": "Instructions: You will be presented with a passage and a question about that passage. There are four options to be chosen from, you need to choose the only correct option to answer that question. If the first option is right, you generate the answer 'A', if the second option is right, you generate the answer 'B', if the third option is right, you generate the answer 'C', if the fourth option is right, you generate the answer 'D', if the fifth option is right, you generate the answer 'E'. Read the question and options thoroughly and select the correct answer from the four answer labels. Read the passage thoroughly to ensure you know what the passage entails"},
{"role": "user", "content": "Passage: For the school paper, five studentsu2014Jiang, Kramer, Lopez, Megregian, and O'Neillu2014each review one or more of exactly three plays: Sunset, Tamerlane, and Undulation, but do not review any other plays. The following conditions must apply: Kramer and Lopez each review fewer of the plays than Megregian. Neither Lopez nor Megregian reviews any play Jiang reviews. Kramer and O'Neill both review Tamerlane. Exactly two of the students review exactly the same play or plays as each other.Question: Which one of the following could be an accurate and complete list of the students who review only Sunset?nA. LopeznB. O'NeillnC. Jiang, LopeznD. Kramer, O'NeillnE. Lopez, MegregiannAnswer:"}
]
)
print(completion.choices[0].message)
Le résultat extrait du dictionnaire de réponses est le suivant :

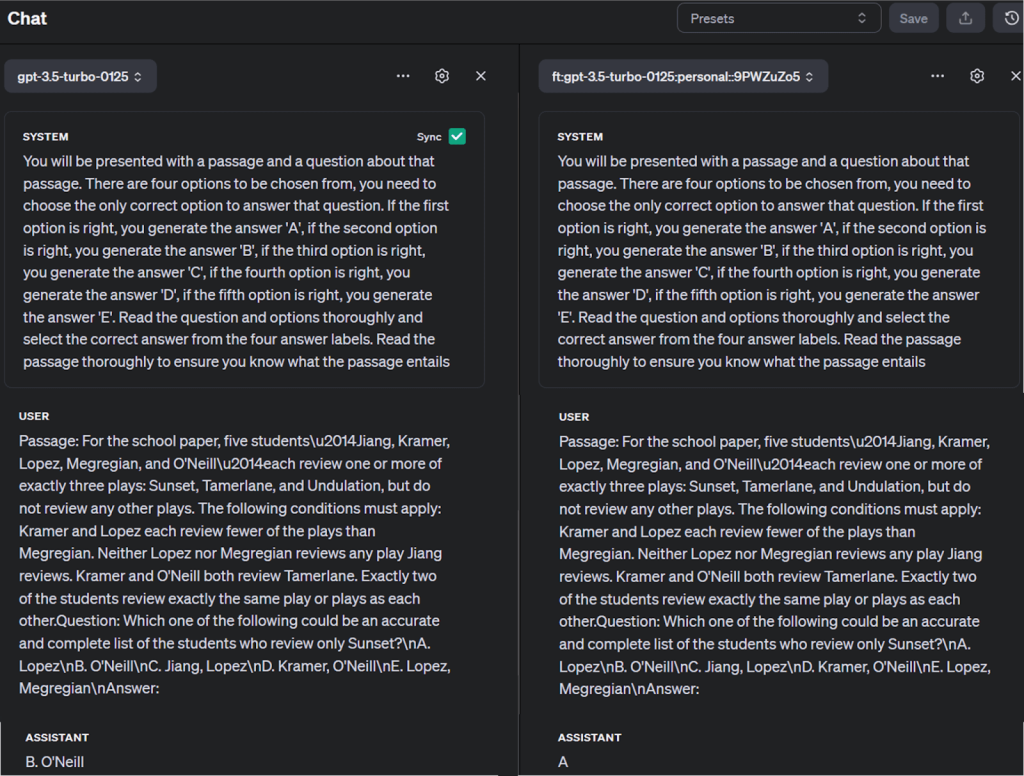
Vous pouvez également comparer le modèle affiné avec d’autres modèles dans le terrain de jeu de l’OpenAI, comme indiqué ci-dessous :
Conseils et bonnes pratiques
Pour une mise au point réussie, voici quelques conseils :
Qualité des données : Veillez à ce que les données spécifiques à votre tâche soient propres, diversifiées et représentatives afin d’éviter le surajustement, c’est-à-dire que le modèle donne de bons résultats sur les données d’apprentissage, mais de mauvais résultats sur les données non vues.
Sélection des hyperparamètres : Choisir les hyperparamètres appropriés pour éviter une convergence lente ou des performances sous-optimales. Cette opération peut s’avérer complexe et chronophage, mais elle est cruciale pour une formation efficace.
Gestion des ressources : Sachez que la mise au point de grands modèles nécessite des ressources informatiques et un temps considérables.
Éviter les pièges
Surajustement et sous-ajustement : Équilibrez la complexité de votre modèle et la quantité d’entraînement pour éviter l’overfitting (variance élevée) et l’underfitting (biais élevé).
Oubli catastrophique : Au cours du réglage fin, le modèle peut oublier des connaissances générales apprises précédemment. Pour atténuer ce risque, évaluez régulièrement les performances de votre modèle sur une variété de tâches.
Sensibilité au changement de domaine : Si vos données de mise au point diffèrent considérablement des données de préformation, vous risquez de rencontrer des problèmes de changement de domaine. Utilisez des techniques d’adaptation de domaine pour combler ce fossé.
Sauvegarde et réutilisation des modèles
Après la formation, enregistrez l’état de votre modèle pour pouvoir le réutiliser ultérieurement. Cela comprend les paramètres du modèle et tout état de l’optimiseur qui a été utilisé. Cela vous permet de reprendre la formation plus tard à partir du même état.
Considérations éthiques
Amplification des biais : Les modèles pré-entraînés peuvent hériter de biais, qui peuvent être amplifiés lors du réglage fin. Si des prédictions impartiales sont nécessaires, il faut toujours opter pour des modèles pré-entraînés dont les biais et l’impartialité ont été testés.
Résultats non intentionnels : Les modèles finement ajustés peuvent générer des résultats plausibles mais incorrects. Il convient de mettre en œuvre des mécanismes robustes de post-traitement et de validation pour y remédier.
Dérive du modèle : Les performances d’un modèle peuvent se détériorer au fil du temps en raison de changements dans l’environnement ou la distribution des données. Surveillez régulièrement les performances de votre modèle et affinez-les si nécessaire.
Techniques avancées et formation continue
Les techniques avancées de réglage fin des LLM comprennent l’adaptation à faible classement (LoRA) et la LoRA quantifiée (QLoRA), qui réduisent les coûts de calcul et les coûts financiers tout en maintenant les performances. Le Parameter Efficient Fine Tuning (PEFT) adapte efficacement les modèles avec un minimum de paramètres entraînables. DeepSpeed et ZeRO optimisent l’utilisation de la mémoire pour l’entraînement à grande échelle. Ces techniques relèvent des défis tels que le surajustement, l’oubli catastrophique et la sensibilité au changement de domaine, améliorant ainsi l’efficacité et l’efficience de l’ajustement fin du LLM.
Au-delà du réglage fin, il existe d’autres techniques de formation avancées telles que l’apprentissage par transfert et l’apprentissage par renforcement. L’apprentissage par transfert consiste à appliquer les connaissances acquises dans le cadre d’un problème à un autre problème connexe, tandis que l’apprentissage par renforcement est un type d’apprentissage automatique dans lequel un agent apprend à prendre des décisions en effectuant des actions dans un environnement afin de maximiser une récompense.
Pour ceux qui souhaitent approfondir l’apprentissage des modèles d’IA, les ressources ci-dessous peuvent s’avérer utiles :
- L’attention est tout ce dont vous avez besoin par Ashish Vaswani et al.
- Le livre “Deep Learning” par Ian Goodfellow, Yoshua Bengio, et Aaron Courville
- Le livre “Speech and Language Processing” de Daniel Jurafsky et James H. Martin
- Différents modes de formation des gestionnaires de l’éducation et de la formation tout au long de la vie
- Maîtriser les techniques du LLM : Formation
- Cours de PNL par Hugging Face
Conclusion
L’entraînement d’un modèle d’IA est un processus qui nécessite une quantité importante de données de haute qualité. Si la définition du problème, la sélection d’un modèle et son affinement par itérations sont essentiels, le véritable facteur de différenciation est la qualité et le volume des données utilisées. Au lieu de construire et de maintenir des web scrapers, vous pouvez simplifier la collecte de données en utilisant des ensembles de données préconstruits ou personnalisés disponibles sur la plateforme de Bright Data.
Avec le Dataset Marketplace, vous pouvez accéder à des ensembles de données validés et prêts à l’emploi provenant de sites web populaires, ou vous pouvez générer des ensembles de données personnalisés pour répondre à vos besoins spécifiques à l’aide de la plateforme automatisée. Vous pouvez ainsi vous concentrer sur l’entraînement efficace de vos modèles à l’aide de données précises et conformes, ce qui vous permet d’obtenir des résultats plus rapides et plus fiables dans divers secteurs d’activité.
Explorez les solutions d’ensembles de données de Bright Data et intégrez-les facilement dans votre flux de travail pour une collecte de données transparente.
Inscrivez-vous dès maintenant et commencez votre essai gratuit de l’infrastructure de scraping de Bright Data, y compris des échantillons de données gratuits.






