

Dans cet article, nous allons apprendre :
- Ce qu’est HTTP et les fonctionnalités qu’il offre
- Comment utiliser HTTPX pour le web scraping dans une section guidée
- Fonctionnalités HTTPX avancées pour le web scraping
- Comparaison entre HTTPX et Requests pour les requêtes automatisées. Requests pour les requêtes automatisées
C’est parti !
Qu’est-ce que HTTPX ?
HTTPX est un client HTTP complet pour Python 3, construit sur la base de la bibliothèque retryablehttp . Tout cela dans le but de garantir des résultats fiables même avec un nombre élevé de threads. HTTPX fournit des API synchrones et asynchrones, et prend en charge les protocoles HTTP/1.1 et HTTP/2.
⚙️ Caractéristiques
- Base de code simple et modulaire, facilitant la contribution.
- Flags rapides et entièrement configurables pour sonder plusieurs éléments.
- Prise en charge de diverses méthodes de sondage basées sur HTTP.
- Repli automatique intelligent de HTTPS à HTTP par défaut.
- Accepte les hôtes, les URL et les CIDR en entrée.
- Prend en charge les proxies, les en-têtes HTTP personnalisés, les délais personnalisés, l’authentification de base, etc.
👍 Avantages
- Disponible à partir de la ligne de commande en utilisant
httpx[cli]. - Regorge de fonctionnalités, notamment la prise en charge de HTTP/2 et d’une API asynchrone.
- Ce projet est activement développé…
👎 Inconvénients
- …avec des mises à jour fréquentes qui peuvent introduire des ruptures avec les nouvelles versions.
- Moins populaire que la bibliothèque
requests.
Scraping avec HTTPX : un guide étape par étape
HTTPX est un client HTTP, ce qui signifie qu’il vous aide à récupérer le contenu HTML brut d’une page. Pour analyser et extraire les données du HTML, vous aurez besoin d’un analyseur HTML comme BeautifulSoup.
En fait, HTTPX n’est pas n’importe quel client HTTP, mais l’un des meilleurs clients HTTP Python pour le web scraping.
Suivez ce tutoriel pour apprendre à utiliser HTTPX pour le web scraping avec BeautifulSoup !
Avertissement: Bien que HTTPX ne soit utilisé que dans les premières étapes du processus, nous vous guiderons à travers un flux de travail complet. Si vous êtes intéressé par des techniques de scraping HTTPX plus avancées, vous pouvez passer au chapitre suivant après l’étape 3.
Étape n° 1 : configuration du projet
Vérifiez que Python 3+ est bien installé sur votre machine. Sinon, téléchargez-le sur le site officiel et suivez les instructions d’installation.
Maintenant, utilisez la commande suivante pour créer un répertoire pour votre projet de scraping HTTPX :
mkdir httpx-scraper
Naviguez-y et initialisez un environnement virtuel à l’intérieur :
cd httpx-scraper
python -m venv env
Ouvrez le dossier du projet sur votre IDE Python préféré. Visual Studio Code avec l’extension Python ou PyCharm Community Edition feront l’affaire.
Créez ensuite un fichier scraper.py dans le dossier du projet. Actuellement, scraper.py est un script Python vide mais il contiendra bientôt la logique de scraping.
Sur le terminal de votre IDE, activez l’environnement virtuel. Sous Linux ou macOS, exécutez :
./env/bin/activate
En d’autres termes, pour Windows, lancez :
env/Scripts/activate
Génial ! Nous sommes maintenant complètement prêt pour commencer.
Étape n° 2 : installation des bibliothèques de scraping
Dans un environnement virtuel activé, installez HTTPX et BeautifulSoup avec la commande suivante :
pip install httpx beautifulsoup4
Cela ajoutera à la fois httpx et beautifulsoup4 aux dépendances de votre projet.
Importez-les dans votre script scraper.py :
import httpx
from bs4 import BeautifulSoup
Parfait ! Vous êtes prêt à passer à l’étape suivante de votre processus de scraping.
Étape 3 : Récupérer le code HTML de la page cible
Dans cet exemple, la page cible sera le site « Quotes to Scrape » :
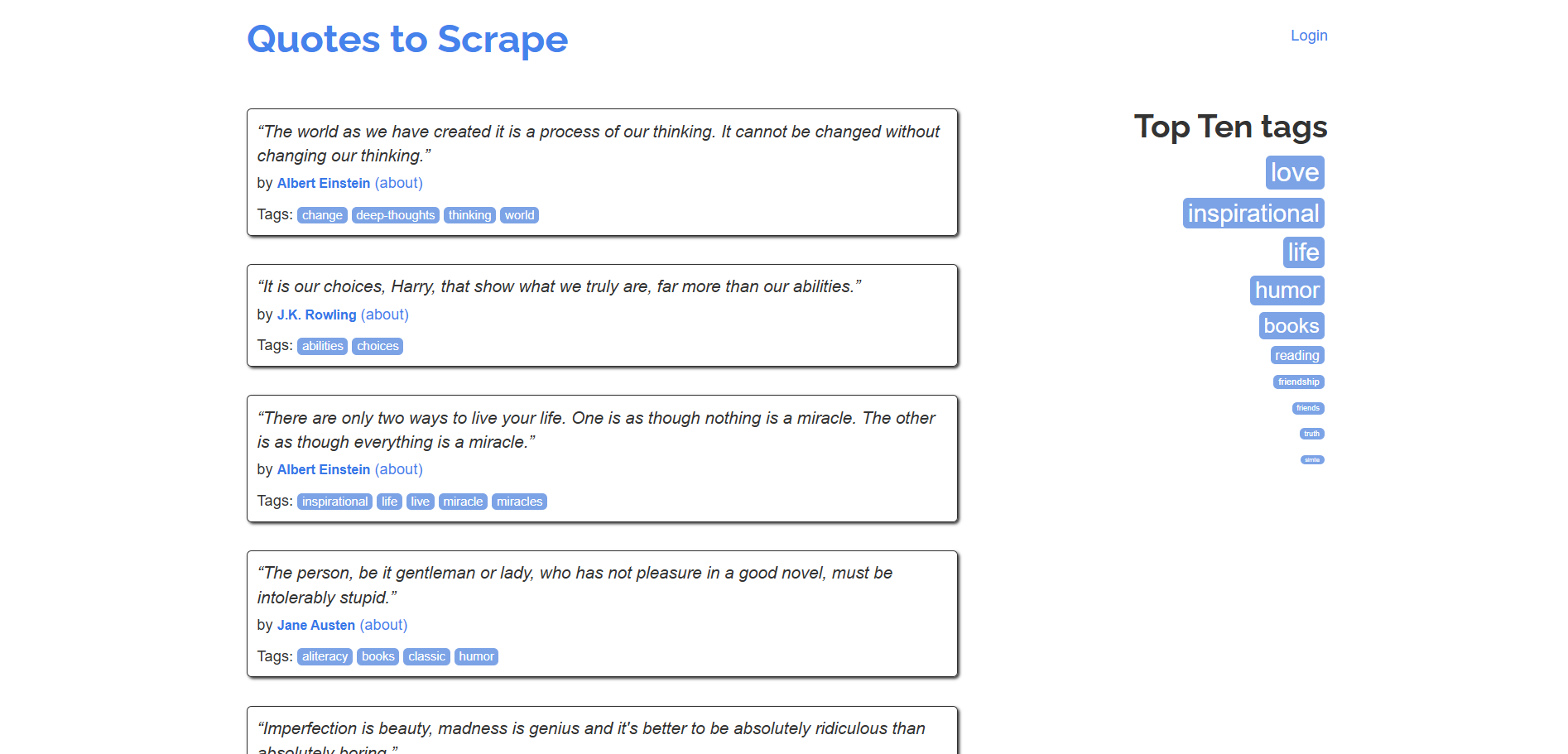
Utilisez HTTPX pour récupérer le code HTML de la page d’accueil avec la méthode get() :
# Make an HTTP GET request to the target page
response = httpx.get("http://quotes.toscrape.com")
En coulisses, HTTPX envoie une requête HTTP GET au serveur, qui répond avec le code HTML de la page. Vous pouvez accéder au contenu HTML en utilisant l’attribut response.text :
html = response.text
print(html)
Ceci imprimera le contenu HTML brut de la page :
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Quotes to Scrape</title>
<link rel="stylesheet" href="/static/bootstrap.min.css">
<link rel="stylesheet" href="/static/main.css">
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>
Excellent ! Il est temps d’analyser ce contenu et d’en extraire les données dont vous avez besoin.
Étape 4 : Analyse du code HTML
Envoyez le contenu HTML au constructeur de BeautifulSoup pour qu’il le parse :
# Parse the HTML content using
BeautifulSoup soup = BeautifulSoup(html, "html.parser")
html.parser est le parseur HTML standard de Python qui sera utilisé pour parser le contenu.
La variable soupe contient maintenant le HTML analysé et expose les méthodes pour extraire les données dont vous avez besoin.
HTTPX a fait son travail de récupération du HTML, et nous passons maintenant à la phase traditionnelle de scraping des données avec BeautifulSoup. Pour plus d’informations, consultez notre tutoriel sur le web scraping avec BeautifulSoup.
Étape n° 5 : récupération des données
Vous pouvez scraper les données de la page avec les lignes de code suivantes :
# Where to store the scraped data
quotes = []
# Extract all quotes from the page
quote_elements = soup.find_all("div", class_="quote")
# Loop through quotes and extract text, author, and tags
for quote_element in quote_elements:
text = quote_element.find("span", class_="text").get_text().get_text().replace("“", "").replace("”", "")
author = quote_element.find("small", class_="author")
tags = [tag.get_text() for tag in quote_element.find_all("a", class_="tag")]
# Store the scraped data
quotes.append({
"text": text,
"author": author,
"tags": tags
})
Ce snippet définit une liste nommée « quotes » pour stocker les données récupérées. Il sélectionne ensuite tous les éléments HTML de la citation et itère sur eux pour extraire le texte de la citation, l’auteur et les balises. Chaque citation extraite est stockée sous forme de dictionnaire dans la liste des citations , organisant les données en vue d’une utilisation ultérieure ou d’une exportation.
Oui ! Logique de scraping implémentée.
Étape 6 : exportation des données extraites
Utilisez la logique suivante pour exporter les données extraites vers un fichier CSV :
# Specify the file name for export
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
# Write the header row
writer.writeheader()
# Write the scraped quotes data
writer.writerows(quotes)
Cet extrait ouvre un fichier nommé quotes.csv en mode écriture, définit les en-têtes de colonnes (texte, auteur, balises), écrit les en-têtes dans le fichier, puis écrit chaque dictionnaire de la liste des citations dans le fichier CSV. Le csv.DictWriter gère le formatage, ce qui facilite le stockage de données structurées.
N’oubliez pas d’importer csv depuis la bibliothèque standard de Python :
import csv
Étape 7 : assemblage
Votre script HTTPX final pour le web scraping contiendra :
import httpx
from bs4 import BeautifulSoup
import csv
# Make an HTTP GET request to the target page
response = httpx.get("http://quotes.toscrape.com")
# Access the HTML of the target page
html = response.text
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
# Where to store the scraped data
quotes = []
# Extract all quotes from the page
quote_elements = soup.find_all("div", class_="quote")
# Loop through quotes and extract text, author, and tags
for quote_element in quote_elements:
text = quote_element.find("span", class_="text").get_text().replace("“", "").replace("”", "")
author = quote_element.find("small", class_="author").get_text()
tags = [tag.get_text() for tag in quote_element.find_all("a", class_="tag")]
# Store the scraped data
quotes.append({
"text": text,
"author": author,
"tags": tags
})
# Specify the file name for export
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
# Write the header row
writer.writeheader()
# Write the scraped quotes data
writer.writerows(quotes)
L’exécuter avec :
python scraper.py
Ou, sous Linux/macOS :
python3 scraper.py
Un fichier quotes.csv apparaît dans le dossier racine de votre projet. Ouvrez le fichier et vous verrez :

Et voilà ! Vous venez d’apprendre à faire du web scraping avec HTTPX et BeautifulSoup.
Fonctionnalités et techniques avancées de HTTPX Web Scraping
Maintenant que vous savez comment utiliser HTTPX pour le web scraping dans un scénario de base, vous êtes prêt à le voir à l’œuvre dans des cas d’utilisation plus complexes.
Dans les exemples ci-dessous, le site cible sera le point de terminaison HTTPBin.io /anything. Il s’agit d’une API spéciale qui renvoie l’adresse IP, les en-têtes et d’autres informations envoyées par l’appelant.
Maîtriser HTTPX pour le web scraping !
Définir des en-têtes personnalisés
HTTPX vous permet de spécifier des en-têtes personnalisés grâce à l’argument headers :
import httpx
# Custom headers for the request
headers = {
"accept": "application/json",
"accept-language": "en-US,en;q=0.9,fr-FR;q=0.8,fr;q=0.7,es-US;q=0.6,es;q=0.5,it-IT;q=0.4,it;q=0.3"
}
# Make a GET request with custom headers
response = httpx.get("https://httpbin.io/anything", headers=headers)
# Handle the response...
Définir un agent utilisateur personnalisé
User-Agent est l’un des en-têtes HTTP les plus importants pour le web scraping.. Par défaut, HTTPX utilise l’agent utilisateur suivant :
python-httpx/<VERSION>
Cette valeur peut facilement révéler que vos demandes sont automatisées, ce qui pourrait conduire à un blocage par le site cible.
Pour éviter cela, vous pouvez définir un User-Agent personnalisé pour imiter un vrai navigateur, comme suit :
import httpx
# Define a custom User-Agent
headers = {
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36"
}
# Make a GET request with the custom User-Agent
response = httpx.get("https://httpbin.io/anything", headers=headers)
# Handle the response...
Découvrez les meilleurs agents utilisateurs pour le web scraping!
Définir les cookies
Tout comme les en-têtes HTTP, vous pouvez définir des cookies dans HTTPX en utilisant l’argument cookies :
import httpx
# Define cookies as a dictionary
cookies = {
"session_id": "3126hdsab161hdabg47adgb",
"user_preferences": "dark_mode=true"
}
# Make a GET request with custom cookies
response = httpx.get("https://httpbin.io/anything", cookies=cookies)
# Handle the response...
Cela vous permet d’inclure les données de session nécessaires à vos requêtes de web scraping.
Intégration de proxies
Vous pouvez acheminer vos requêtes HTTPX via un proxy pour protéger votre identité et éviter les interdictions d’IP lorsque vous effectuez du web scraping. Cela est possible en utilisant l’argument proxies :
import httpx
# Replace with the URL of your proxy server
proxy = "<YOUR_PROXY_URL>"
# Make a GET request through a proxy server
response = httpx.get("https://httpbin.io/anything", proxy=proxy)
# Handle the response...
Pour en savoir plus, consultez notre guide sur comment utiliser HTTPX avec un proxy.
Gestion des erreurs
Par défaut, HTTPX ne soulève des erreurs que pour des problèmes de connexion ou de réseau. Pour lever des exceptions également pour les réponses HTTP avec les codes d’état 4xx et 5xx utilisez la méthode raise_for_status() comme indiqué ci-dessous :
import httpx
try:
response = httpx.get("https://httpbin.io/anything")
# Raise an exception for 4xx and 5xx responses
response.raise_for_status()
# Handle the response...
except httpx.HTTPStatusError as e:
# Handle HTTP status errors
print(f"HTTP error occurred: {e}")
except httpx.RequestError as e:
# Handle connection or network errors
print(f"Request error occurred: {e}")
Traitement des sessions
Lors de l’utilisation de l’API de premier niveau dans HTTPX, une nouvelle connexion est établie pour chaque requête. En d’autres termes, les connexions TCP ne sont pas réutilisées. Lorsque le nombre de demandes adressées à un hôte augmente, cette approche devient inefficace.
En revanche, l’utilisation d’une instance httpx.Client permet HTTP connection pooling. Cela signifie que plusieurs demandes adressées au même hôte peuvent réutiliser une connexion TCP existante au lieu d’en créer une nouvelle pour chaque demande.
Les avantages de l’utilisation d’un Client par rapport à l’API de premier niveau sont les suivants :
- Réduction de la latence entre les requêtes (en évitant les échanges répétés)
- Réduction de la charge du CPU et du nombre d’allers-retours
- Réduction de la congestion du réseau
En outre, les instances de Client prennent en charge la gestion des sessions avec des fonctionnalités non disponibles dans l’API de premier niveau, notamment :
- La persistance des cookies entre les demandes
- L’application de la configuration à toutes les demandes sortantes
- L’envoi de requêtes par l’intermédiaire de serveurs proxy HTTP
Il est recommandé d’utiliser un Client dans HTTPX avec un gestionnaire de contexte (avec déclaration) :
import httpx
with httpx.Client() as client:
# Make an HTTP request using the client
response = client.get("https://httpbin.io/anything")
# Extract the JSON response data and print it
response_data = response.json()
print(response_data)
Alternativement, vous pouvez gérer manuellement le client et fermer le pool de connexion explicitement avec client.close():
import httpx
client = httpx.Client()
try:
# Make an HTTP request using the client
response = client.get("https://httpbin.io/anything")
# Extract the JSON response data and print it
response_data = response.json()
print(response_data)
except:
# Handle the error...
pass
finally:
# Close the client connections and release resources
client.close()
Note: Si vous êtes familier avec la bibliothèque requests , httpx.Client() a une fonction similaire à requests.Session(). .
API asynchrone
Par défaut, HTTPX propose une API synchrone standard. Parallèlement, il propose également un client asynchrone pour les cas où il est nécessaire. Si vous travaillez avec asyncio, l’utilisation d’un client asynchrone est essentielle pour envoyer des requêtes HTTP sortantes de manière efficace.
La programmation asynchrone est un modèle de concurrence nettement plus efficace que le multithreading. Il offre des améliorations notables en termes de performances et prend en charge les connexions réseau de longue durée comme les WebSockets. Il s’agit donc d’un facteur clé pour accélérer le web scraping.
Pour effectuer des requêtes asynchrones dans HTTPX, vous aurez besoin d’un AsyncClient. Initialisez-le et utilisez-le pour effectuer une requête GET comme indiqué ci-dessous :
import httpx
import asyncio
async def fetch_data():
async with httpx.AsyncClient() as client:
# Make an async HTTP request
response = await client.get("https://httpbin.io/anything")
# Extract the JSON response data and print it
response_data = response.json()
print(response_data)
# Run the async function
asyncio.run(fetch_data())
L’instruction with garantit que le client est automatiquement fermé à la fin du bloc. Alternativement, si vous gérez le client manuellement, vous pouvez le fermer explicitement avec await client.close().
Rappelez-vous que toutes les méthodes de requête HTTPX (get() post()) sont asynchrones lorsqu’on utilise un AsyncClient. Par conséquent, vous devez ajouter await avant de les appeler pour obtenir une réponse.
Nouvelle tentative pour les requêtes qui ont échoué
L’instabilité du réseau durant les tâches de scraping peut entraîner des échecs de connexion ou des dépassements de délai. HTTPX simplifie le traitement de ces questions grâce à son interface HTTPTransport . Grâce à ce mécanisme, les requêtes sont relancées lorsqu’un httpx.ConnectError ou un httpx.ConnectTimeout se produit.
L’exemple suivant montre comment configurer un transport pour qu’il réessaie les demandes jusqu’à 3 fois :
import httpx
# Configure transport with retry capability on connection errors or timeouts
transport = httpx.HTTPTransport(retries=3)
# Use the transport with an HTTPX client
with httpx.Client(transport=transport) as client:
# Make a GET request
response = client.get("https://httpbin.io/anything")
# Handle the response...
Notez que seules les erreurs liées à la connexion déclenchent une nouvelle tentative. Pour gérer les erreurs de lecture/écriture ou les codes d’état HTTP spécifiques, vous devez mettre en œuvre une logique de relance personnalisée avec des bibliothèques telles que tenacity.
HTTPX vs Requêtes pour le Web Scraping
Voici un tableau récapitulatif pour comparer HTTPX et Requêtes pour le web scraping:
| Fonctionnalité | HTTPX | Requests |
|---|---|---|
| Étoiles sur GitHub | 8k | 52.4k |
| Asynchrone | ✔️ | ❌ |
| Mise en commun des connexions | ✔️ | ✔️ |
| Prise en charge de HTTP/2 | ✔️ | ❌ |
| Personnalisation de l’agent utilisateur | ✔️ | ✔️ |
| Prise en charge des proxies | ✔️ | ✔️ |
| Traitement des cookies | ✔️ | ✔️ |
| Délais d’expiration | Personnalisable pour la connexion et la lecture | Personnalisable pour la connexion et la lecture |
| Nouvelles tentatives | Disponible via les transports | Disponible via HTTPAdapters |
| Performances | Élevées | Moyennes |
| Soutien et popularité de la communauté | Croissance | Excellents |
Conclusion
Dans cet article, vous avez exploré la bibliothèque httpx pour le web scraping. Vous avez compris ce qu’est la librairie httpx, ce que cela apporte et les avantages. HTTPX est une option rapide et fiable pour effectuer des requêtes HTTP lors de la collecte de données en ligne.
Le problème est que les requêtes HTTP automatisées révèlent votre adresse IP publique, ce qui peut révéler votre identité et votre localisation. Cela compromet votre vie privée. Pour renforcer votre sécurité et votre confidentialité, l’une des méthodes les plus efficaces consiste à utiliser un serveur proxy pour cacher votre adresse IP.
Bright Data contrôle les meilleurs serveurs proxy au monde, au service des entreprises du Fortune 500 et de plus de 20 000 clients. Son offre comprend une large gamme de types de proxies :
- Proxys de centre de données — Plus de 770 000 adresses IP de datacenters.
- Proxys résidentiels – Plus de 72 millions d’adresses IP résidentielles dans plus de 195 pays.
- Proxys de fournisseurs d’accès à Internet — Plus de 700 000 adresses IP de fournisseurs d’accès Internet.
Créez un compte Bright Data gratuit dès aujourd’hui pour tester nos solutions de scraping et nos proxys !





