

Dans cet article, vous apprendrez
- Ce qu’est l’outil Anthropic web fetch et ses principales limites.
- Comment il fonctionne.
- Comment l’utiliser avec cURL et Python.
- Ce que Bright Data propose pour atteindre des objectifs similaires.
- Comment l’outil Anthropic web fetch et les outils de données web de Bright Data se comparent.
- Un tableau récapitulatif pour une comparaison rapide.
Plongeons dans le vif du sujet !
Qu’est-ce que l’outil Anthropic Web Fetch ?
L’outil Anthropic web fetch permet aux modèles de Claude de récupérer le contenu de pages web et de documents PDF. Cet outil a été introduit gratuitement dans la version bêta de Claude le 2026-09-10.
En incluant cet outil dans une requête API de Claude, le LLM configuré peut récupérer et analyser le texte intégral d’une page web ou d’une URL PDF spécifiée. Cela permet à Claude d’accéder à des informations actualisées et basées sur les sources pour les réponses fondées.
Remarques et limitations
Voici les principales remarques et limitations associées à l’outil Anthropic web fetch :
- Disponible sur l’API de Claude sans frais supplémentaires. Vous ne payez que les frais de jeton standard pour le contenu récupéré qui est inclus dans votre contexte de conversation.
- Récupère le contenu complet des pages web et des documents PDF spécifiés.
- Actuellement en version bêta et nécessite l’en-tête bêta
web-fetch-2026-09-10. - Claude ne peut pas construire dynamiquement des URL. Vous devez lui fournir explicitement des URL complètes, ou il ne peut utiliser que des URL obtenues lors de recherches précédentes sur le web ou des résultats de recherche.
- Claude ne peut récupérer que les URLs qui sont déjà apparues dans le contexte de la conversation. Cela inclut les URL provenant de messages d’utilisateurs, de résultats d’outils côté client, ou de résultats de recherches ou de récupérations sur le web antérieures.
- Ne fonctionne qu’avec les modèles suivants : Claude Opus 4.1
(claude-opus-4-1-20260805), Claude Opus 4(claude-opus-4-20260514), Claude Sonnet 4.5(claude-sonnet-4-5-20260929), Claude Sonnet 4(claude-sonnet-4-20260514), Claude Sonnet 3.7(claude-3-7-sonnet-20260219), Claude Sonnet 3.5 v2 (deprecated)(claude-3-5-sonnet-latest), et Claude Haiku 3.5(claude-3-5-haiku-latest). - Ne prend pas en charge les sites web JavaScript à rendu dynamique.
- Peut inclure des citations optionnelles pour le contenu recherché.
- Fonctionne avec la mise en cache de l’invite, de sorte que les résultats mis en cache peuvent être réutilisés au fil des conversations.
- Prend en charge les paramètres
max_uses,allowed_domains,blocked_domainsetmax_content_tokens. - Les codes d’erreur courants sont :
invalid_input,url_too_long,url_not_allowed,url_not_accessible,too_many_requests,unsupported_content_type,max_uses_exceeded, etunavailable.
Fonctionnement de la recherche sur le web dans les modèles Claude
Voici ce qui se passe en coulisses lorsque vous ajoutez l’outil Anthropic web fetch à votre demande d’API:
- Claude détermine quand récupérer le contenu en fonction de l’invite et des URLs fournies.
- L’API récupère le contenu en texte intégral à partir de l’URL spécifiée.
- Pour les PDF, l’extraction automatique du texte est effectuée.
- Claude analyse le contenu récupéré et génère une réponse, incluant éventuellement des citations.
La réponse obtenue est ensuite renvoyée à l’utilisateur ou ajoutée au contexte de la conversation pour une analyse plus approfondie.
Comment utiliser l’outil Anthropic Web Fetch ?
Les deux principales façons d’utiliser l’outil de recherche sur le web consistent à l’activer dans une requête adressée à l’un des modèles Claude pris en charge. Cela peut se faire de l’une ou l’autre des manières suivantes :
- Via un appel API direct à l’API Anthropic.
- Par l’intermédiaire de l’un des SDK clients de Claude, comme la bibliothèque API Python d’Anthropic.
Voir comment dans les sections suivantes !
Dans les deux cas, nous montrerons comment utiliser l’outil web fetch pour scraper la page d’accueil d’Anthropic, illustrée ci-dessous :

Conditions préalables
La principale condition pour utiliser l’outil web fetch d’Anthropic est d’avoir accès à une clé API d’Anthropic. Nous supposerons ici que vous disposez d’un compte Anthropic avec une clé API.
Par un appel direct à l’API
Utilisez l’outil web fetch en effectuant un appel direct à l’API d’Anthropic avec l’un des modèles pris en charge, comme indiqué ci-dessous dans une requête cURL POST:
curl https://api.anthropic.com/v1/messages N-header "x-api-n", "x-api-n-", "x-api-n-", etc.
--header "x-api-key : <YOUR_ANTHROPIC_API_KEY>" N-header "x-api-key : <YOUR_ANTHROPIC_API_KEY>" N-header "anthropic-version".
--header "anthropic-version : 2023-06-01"
--header "anthropic-beta : web-fetch-2026-09-10" N-header "content-type of application" : N--fetch-2026-09-10
--header "content-type : application/json" N--data "{compatible}".
--data '{
"model" : "claude-sonnet-4-5-20260929",
"max_tokens" : 1024,
"messages" : [
{
"role" : "utilisateur",
"content" : "Récupérer le contenu de 'https://www.anthropic.com/'"
}
],
"tools" : [{
"type" : "web_fetch_20260910",
"name" : "web_fetch",
"max_uses" : 5
}]
}'Notez que claude-sonnet-4-5-20260929 est l’un des modèles pris en charge par l’outil web fetch.
Notez également que les deux en-têtes spéciaux, anthropic-version et anthropic-beta, sont requis.
Pour activer l’outil de recherche web dans le modèle configuré, vous devez ajouter l’élément suivant au tableau des outils dans le corps de la requête :
{
"type" : "web_fetch_20260910",
"name" : "web_fetch",
"max_uses" : 5
}Les champs type et name sont importants, tandis que max_uses est optionnel et définit combien de fois l’outil peut être appelé au cours d’une même itération.
Remplacez le caractère générique <YOUR_ANTHROPIC_API_KEY> par votre véritable clé API Anthropic. Ensuite, exécutez la requête et vous devriez obtenir quelque chose comme ceci :
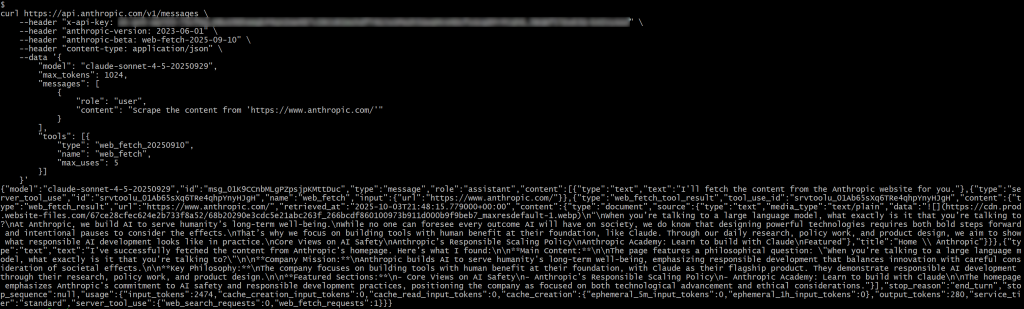
Dans la réponse, vous devriez voir :
{"type" : "server_tool_use", "id" : "srvtoolu_01Ab65sXq6TRe4qhpYnyHJgH", "name" : "web_fetch", "input":{"url" : "https://www.anthropic.com/"}}Ceci indique que le LLM a exécuté un appel à l’outil web_fetch.
Plus précisément, le résultat produit par l’outil serait quelque chose comme :

"Lorsque vous parlez à un grand modèle de langage, à quoi parlez-vous exactement ?
Chez Anthropic, nous construisons l'IA pour servir le bien-être de l'humanité à long terme.
Si personne ne peut prévoir tous les résultats que l'IA aura sur la société, nous savons que la conception de technologies puissantes nécessite à la fois des avancées audacieuses et des pauses intentionnelles pour en considérer les effets.
C'est pourquoi nous nous concentrons sur la construction d'outils qui, comme Claude, sont axés sur les avantages pour l'homme. Grâce à nos recherches quotidiennes, à notre travail politique et à la conception de nos produits, nous voulons montrer à quoi ressemble le développement responsable de l'IA dans la pratique.
Points de vue sur la sécurité de l'IA
Politique de mise à l'échelle responsable d'Anthropic
Académie Anthropic : Apprendre à construire avec Claude
En vedette
Ceci représente une sorte de version Markdown de la page d’accueil de l’URL d’entrée spécifiée. Il s’agit d’une “sorte de” Markdown, car certains liens sont omis et – à part la première image – la sortie se concentre principalement sur le texte, ce qui est exactement ce que l’outil web fetch est conçu pour retourner.
Remarque : dans l’ensemble, le résultat est exact, mais il manque certainement du contenu, qui a pu être perdu au cours du traitement par l’outil. En fait, la page originale contient plus de texte que ce qui a été récupéré.
Utilisation de la bibliothèque Anthropic Python API
Il est également possible d’appeler l’outil web fetch en utilisant la bibliothèque Anthropic Python API avec :
# pip install anthropic
import anthropic
# Remplacez-la par votre clé API Anthropic
ANTHROPIC_API_KEY = "<VOTRE_CLÉ_D'API_ANTHROPIQUE>"
# Initialiser le client de l'API Anthropic
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
# Effectuer une requête à Claude avec l'outil web fetch activé
response = client.messages.create(
model="claude-sonnet-4-5-20260929",
max_tokens=1024,
messages=[
{
"role" : "user",
"content" : "Récupérer le contenu de 'https://www.anthropic.com/'"
}
],
tools=[
{
"type" : "web_fetch_20260910",
"name" : "web_fetch",
"max_uses" : 5
},
],
extra_headers={
"anthropic-beta" : "web-fetch-2026-09-10"
}
)
# Imprimer le résultat produit par l'IA dans le terminal
print(response.content)
Cette fois, le résultat sera :
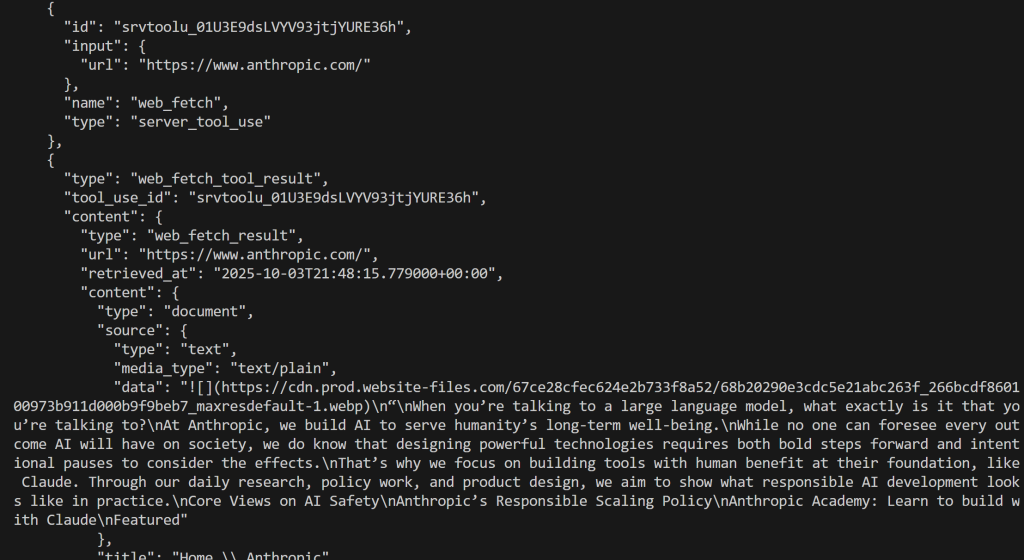
Super ! C’est l’équivalent de ce que nous avons vu précédemment.
Introduction aux outils de données Web de Bright Data
L’infrastructure IA de Bright Data offre un riche ensemble de solutions pour permettre à votre IA de rechercher, de parcourir et de naviguer librement sur le web. Il s’agit notamment de
- API Unlocker: Récupérez de manière fiable le contenu de n’importe quelle URL publique, en contournant automatiquement les blocages et en résolvant les CAPTCHA.
- API Crawl: Parcourez et extrayez sans effort des sites web entiers, avec des sorties dans des formats prêts pour LLM, pour une inférence et un raisonnement efficaces.
- API SERP: Rassemblez en temps réel des résultats de moteurs de recherche géospécifiques pour découvrir des sources de données pertinentes pour une requête spécifique.
- Browser API: Permettez à votre IA d’interagir avec des sites dynamiques et d’automatiser des flux de travail agentiques à l’échelle en utilisant des navigateurs furtifs à distance.
Parmi les nombreux outils, services et produits de récupération de données web dans l’infrastructure Bright Data, nous nous concentrerons sur Web MCP. Celui-ci fournit des outils prêts à être intégrés à l’IA, construits au-dessus des produits Bright Data, qui sont directement comparables à ceux proposés par Anthropic. Notez que Web MCP fonctionne également comme Claude MCP, en s’intégrant pleinement à tous les modèles Anthropic.
Parmi la soixantaine d’outils disponibles, l’outil scrape_as_markdown est celui qui se prête le mieux à la comparaison. Il vous permet de récupérer l’URL d’une seule page web avec des options avancées pour l’extraction du contenu et renvoie les résultats au format Markdown. Cet outil peut accéder à n’importe quelle page web, même celles qui utilisent la détection des robots ou les CAPTCHA.
Il est important de noter que cet outil est disponible sur Web MCP même dans la version gratuite, ce qui signifie que vous pouvez l’utiliser sans frais. Il permet donc d’obtenir des fonctionnalités de récupération de données web similaires à celles de l’outil de récupération de données web d’Anthropic, ce qui rend Web MCP idéal pour une comparaison directe.
Anthropic Web Fetch Tool vs Bright Data Web Data Tools
Dans cette section, nous allons mettre en place un processus de comparaison entre l’outil de récupération de données web d’Anthropic et les outils de données web de Bright Data. En détail, nous allons
- Utiliser l’outil de web fetch à travers la bibliothèque API Python d’Anthropic.
- Nous nous connecterons au MCP Web de Bright Data en utilisant les adaptateurs MCP LangChain (mais toute autre intégration prise en charge est possible).
Nous exécuterons les deux approches en utilisant la même invite et le même modèle Claude pour les quatre URL d’entrée suivantes :
"https://www.anthropic.com/""https://www.g2.com/products/bright-data/reviews""https://www.amazon.com/Owala-FreeSip-Insulated-Stainless-BPA-Free/dp/B0BZYCJK89/""https://it.linkedin.com/in/antonello-zanini"
Celles-ci représentent un bon mélange de pages du monde réel dont vous pourriez vouloir qu’une IA récupère automatiquement le contenu : la page d’accueil d’un site Web, une page de produit G2, une page de produit Amazon et un profil LinkedIn public. Il est à noter que G2 est notoirement difficile à gratter en raison de la protection de Cloudflare, c’est pourquoi elle a été intentionnellement incluse dans la comparaison.
Voyons comment les deux outils se comportent !
Conditions préalables
Avant de suivre cette section, vous devez avoir
- Python installé localement.
- Une clé API Anthropic.
- Un compte Bright Data avec une clé API.
Pour configurer un compte Bright Data et générer votre clé API, suivez le guide officiel. Il est également recommandé de consulter la documentation officielle Web MCP.
En outre, une connaissance du fonctionnement de l ‘intégration LangChain et une familiarité avec les outils fournis par Web MCP seront utiles.
Script d’intégration de l’outil Web Fetch
Pour lancer l’outil Anthropic web fetch à travers les URLs d’entrée sélectionnées, vous pouvez écrire la logique Python comme suit :
# pip install anthropic
import anthropic
Remplacez-la par votre clé API Anthropic
ANTHROPIC_API_KEY = ""
Initialiser le client de l'API Anthropic
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
def scrape_content_with_anthropic_web_fetch_tool(url) :
return client.messages.create( model="claude-sonnet-4-5-20260929",
max_tokens=1024,
messages=[
{
"role" : "user",
"content" : f "Scrape le contenu de '{url}'"
}
],
tools=[
{
"type" : "web_fetch_20260910",
"name" : "web_fetch",
"max_uses" : 5
},
],
extra_headers={
"anthropic-beta" : "web-fetch-2026-09-10"
}
)
Ensuite, vous pouvez appeler cette fonction sur une URL d’entrée comme ceci :
scrape_content_with_anthropic_web_fetch_tool("https://www.anthropic.com/")
Script d’intégration des outils de données Web de Bright Data
Web MCP peut être intégré avec une large gamme de technologies, comme décrit sur notre blog. Ici, nous allons démontrer l’intégration avec LangChain, car c’est l’une des options les plus faciles et les plus populaires.
Avant de commencer, il est recommandé de consulter le guide : “Adaptateurs LangChain MCP avec le Web MCP de Bright Data“.
Dans ce cas, vous devriez obtenir un extrait Python comme celui-ci :
# pip install "langchain[anthropic]" langchain-mcp-adapters langgraph
import asyncio
from langchain_anthropic import ChatAnthropic
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
import json
# Remplacer par vos clés API
ANTHROPIC_API_KEY = "<VOTRE_CLÉ_D'API_ANTHROPIQUE>"
BRIGHT_DATA_API_KEY = "<VOTRE_CLÉS_API_DONNÉES_BRILLANTES>"
async def scrape_content_with_bright_data_web_mcp_tools(agent, url) :
# Description de la tâche de l'agent
input_prompt = f "Récupérer le contenu de '{url}'"
# Exécuter la requête dans l'agent, streamer la réponse et la renvoyer sous forme de chaîne de caractères
output = []
async for step in agent.astream({"messages" : [input_prompt]}, stream_mode="values") :
content = step["messages"][-1].content
if isinstance(content, list) :
output.append(json.dumps(content))
else :
output.append(content)
return "".join(output)
async def main() :
# Initialise le moteur LLM
llm = ChatAnthropic(
model="claude-sonnet-4-5-20260929",
api_key=ANTHROPIC_API_KEY
)
# Configuration pour se connecter à une instance locale du serveur Bright Data Web MCP
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN" : BRIGHT_DATA_API_KEY,
"PRO_MODE" : "false" # Optionnellement mis à "true" pour le mode Pro
}
)
# Connexion au serveur MCP
async with stdio_client(server_params) as (read, write) :
async with ClientSession(read, write) as session :
# Initialiser la session du client MCP
await session.initialize()
# Obtenir les outils Web MCP
tools = await load_mcp_tools(session)
# Créer l'agent ReAct avec l'intégration Web MCP
agent = create_react_agent(llm, tools)
# scrape_content_with_bright_data_web_mcp_tools(agent, "https://www.anthropic.com/")
if __name__ == "__main__" :
asyncio.run(main())
Ceci définit un agent ReAct qui a accès aux outils Web MCP.
Rappelons-le : Web MCP offre un mode Pro, qui donne accès à des outils premium. L’utilisation du mode Pro n’est pas strictement nécessaire dans ce cas. Vous pouvez donc vous contenter des outils disponibles dans la partie gratuite. Les outils gratuits incluent scrape_as_markdown, qui est suffisant pour ce benchmark.
En termes plus simples, du point de vue des coûts, l’utilisation de Web MCP en mode gratuit ne coûtera pas plus que l’utilisation de jetons pour le modèle Claude lui-même (qui est le même dans les deux scénarios). Essentiellement, la structure des coûts pour cette configuration est la même que lors d’une connexion directe à Claude via l’API.
Résultats de l’analyse comparative
Maintenant, exécutez les deux fonctions représentant les deux méthodes de récupération des données pour l’IA en utilisant une logique comme celle-ci :
# Où stocker les résultats de l'analyse comparative
benchmark_results = []
# Les URL d'entrée pour tester les deux approches
urls = [
"https://www.anthropic.com/",
"https://www.g2.com/products/bright-data/reviews",
"https://www.amazon.com/Owala-FreeSip-Insulated-Stainless-BPA-Free/dp/B0BZYCJK89/",
"https://it.linkedin.com/in/antonello-zanini"
]
# Tester chaque URL
for url in urls :
print(f "Test des deux approches sur l'URL suivante : {url}")
anthropic_start_time = time.time()
anthropic_response = scrape_content_with_anthropic_web_fetch_tool(url)
anthropic_end_time = time.time()
bright_data_start_time = time.time()
bright_data_response = await scrape_content_with_bright_data_web_mcp_tools(agent, url)
bright_data_end_time = time.time()
benchmark_entry = {
"url" : url,
"anthropic" : {
"execution_time" : anthropic_end_time - anthropic_start_time,
"output" : anthropic_response.to_json()
},
"bright_data" : {
"execution_time" : bright_data_end_time - bright_data_start_time,
"output" : bright_data_response
}
}
benchmark_results.append(benchmark_entry)
# Exporter les données du benchmark
avec open("benchmark_results.json", "w", encoding="utf-8") as f :
json.dump(benchmark_results, f, ensure_ascii=False, indent=4)
Les résultats peuvent être résumés dans le tableau suivant :
| Anthropic Web Fetch Tool | Données brillantes Outils de données Web | |
|---|---|---|
| Page d’accueil d’Anthropic | ✔️ (informations textuelles partielles) | ✔️ (informations complètes en Markdown) |
| Page d’évaluation G2 | ❌ (l’outil a échoué après ~10 secondes) | ✔️ (version complète de la page en Markdown) |
| Page produit Amazon | ✔️ (informations partielles) | ✔️ (version Markdown complète de la page ou données produit JSON structurées en mode Pro) |
| Page de profil LinkedIn | ❌ (l’outil a échoué immédiatement) | ✔️ (version complète de la page en format Markdown ou données de profil JSON structurées en mode Pro) |
Comme vous pouvez le constater, non seulement l’outil Anthropic web fetch est moins efficace que les outils de données web de Bright Data, mais même lorsqu’il fonctionne, il produit des résultats moins complets.
L’outil Anthropic se concentre principalement sur le texte, alors que les outils Web MCP comme scrape_as_markdown renvoient la version Markdown complète d’une page. En outre, avec des outils Pro tels que web_data_amazon_product, vous pouvez obtenir des flux de données structurés à partir de sites populaires tels qu’Amazon.
Dans l’ensemble, les outils de données Web de Bright Data sont les grands gagnants en termes de précision et de temps d’exécution !
Résumé : tableau comparatif
| Anthropic Web Fetch Tool | Outils de données Web de Bright Data | |
|---|---|---|
| Types de contenu | Pages web, PDF | Pages web |
| Capacités | Extraction de texte | Extraction de contenu, web scraping, web crawling, etc. |
| Sortie | Principalement du texte brut | Markdown, JSON, et autres formats prêts pour LLM |
| Intégration de modèles | Ne fonctionne qu’avec des modèles Claude spécifiques | Intégration complète avec n’importe quel LLM et plus de 70 technologies |
| Prise en charge des sites rendus en JavaScript | ❌ | ✔️ |
| Traitement des contournements de robots/CAPTCHA | ❌ | ✔️ |
| Robustesse | Bêta | Prêt pour la production |
| Prise en charge des demandes de lots | ✔️ | ✔️ |
| Intégration des agents | Uniquement dans les solutions Claude | ✔️ (dans toute solution de création d’agents IA prenant en charge MCP ou les outils officiels de Bright Data) |
| Fiabilité et exhaustivité | Contenu partiel ; peut échouer sur des pages complexes | Extraction du contenu complet ; gère les sites et les pages complexes avec protection contre les robots. |
| Coût | Utilisation de jetons standard uniquement | Utilisation de jetons standard uniquement en mode gratuit ; coûts supplémentaires en mode Pro |
Pour l’intégration de Web MCP avec les technologies Anthropic et les modèles Claude, reportez-vous aux guides suivants :
- Intégrer le code Claude avec le Web MCP de Bright Data
- Web Scraping avec Claude : Analyse par l’IA en Python
- Comment utiliser Bright Data avec Pica MCP dans Claude Desktop
Conclusion
Dans cet article de blog comparatif, vous avez vu comment l’outil de récupération de données Web d’Anthropic se compare aux capacités de récupération et d’interaction de données Web offertes par Bright Data. En particulier, vous avez appris comment utiliser l’outil Anthropic dans des exemples réels, suivi d’une comparaison de référence en utilisant un agent LangChain équivalent interagissant avec le MCP Web de Bright Data.
Le grand gagnant a été les outils de Bright Data, qui comprennent une gamme de produits et de services prêts pour l’IA, capables de prendre en charge une grande variété de cas d’utilisation et de scénarios.
Créez gratuitement un compte Bright Data dès aujourd’hui et commencez à explorer nos outils de données web prêts pour l’IA !






