

Dans cet article, vous apprendrez :
- Ce qu’est Microsoft TaskWeaver et ce qui le rend unique.
- Pourquoi l’extension de TaskWeaver avec les services Bright Data vous permet de surmonter les limites du LLM.
- Comment intégrer Bright Data dans TaskWeaver grâce à un plugin personnalisé.
C’est parti !
Qu’est-ce que Microsoft TaskWeaver ?
Microsoft TaskWeaver est un framework open source, axé sur le code, qui transforme les requêtes en langage naturel en code Python exécutable. Son objectif ultime est d’alimenter des agents IA qui planifient et exécutent de manière indépendante des tâches complexes.
Cette technologie fonctionne en prenant votre invite et en la décomposant en étapes réalisables. Elle sélectionne ensuite les plugins appropriés pour atteindre l’objectif, génère du code Python pour exécuter le plan, exécute le code dans un environnement sécurisé et renvoie les résultats.
TaskWeaver est open source et a recueilli plus de 6 000 étoiles sur GitHub. Parmi les principales fonctionnalités qui le distinguent, on peut citer
- Approche « code-first »: convertit les demandes des utilisateurs en code Python, donnant aux agents la possibilité de générer et d’exécuter directement des solutions.
- Écosystème de plugins: prend en charge des tâches spécialisées grâce à des plugins, ce qui rend le framework hautement extensible.
- Traitement riche des données: fonctionne de manière native avec les structures de données Python telles que DataFrames, ouvrant la voie à des analyses de données avancées.
- Adaptation au domaine: intègre des connaissances spécifiques au domaine pour des résultats plus précis.
- Exécution avec état et réflexive: conserve le contexte et peut réfléchir sur sa propre exécution de code pour s’autocorriger.
- Sécurisé et ouvert: exécute le code dans un environnement sûr tout en offrant une expérience open source prête à l’emploi.
Pour en savoir plus, consultez la documentation officielle.
Pourquoi ajouter des capacités de récupération de données Web à TaskWeaver
Les LLM sont intrinsèquement limités par les données sur lesquelles ils ont été formés. Bien qu’ils puissent générer du texte, du code ou du multimédia, le résultat est toujours basé sur leurs connaissances obsolètes. De plus, ils ne peuvent pas interagir avec des pages web en direct comme le ferait un utilisateur humain. Ces deux éléments constituent les principales contraintes des modèles d’IA actuels.
TaskWeaver surmonte ces limites en permettant aux agents de s’intégrer à des plugins personnalisés. Vous pouvez considérer les plugins comme des outils spécialisés que le LLM peut utiliser pour effectuer des tâches qui dépassent ses capacités intégrées, élargissant ainsi efficacement son champ d’application et son utilité pratique.
En appelant ces plugins, le code généré par un agent TaskWeaver peut interagir avec des environnements externes et effectuer des opérations complexes. Par exemple, Bright Data propose une gamme d’outils puissants :
- API Web Unlocker: récupérez le contenu de n’importe quel site web en une seule requête et recevez du code HTML ou Markdown propre, avec une gestion automatisée des Proxies, du déblocage, des en-têtes et des CAPTCHA.
- API SERP: collectez les résultats des moteurs de recherche Google, Bing et autres à grande échelle, sans vous soucier des blocages.
- API de Scraping web: récupérez des données structurées et analysées à partir de sites connus tels qu’Amazon, Instagram, LinkedIn, Yahoo Finance, etc.
- Et d’autres solutions Bright Data…
Grâce à l’accès à des plugins connectés à ces services, un agent TaskWeaver peut effectuer des recherches sur le Web, extraire du contenu et récupérer des données structurées en temps réel à partir de domaines populaires. Cela permet à l’IA de gérer des workflows complexes et adaptés aux entreprises, qui vont bien au-delà de ce qu’un LLM standard pourrait accomplir à lui seul.
Comment intégrer Bright Data dans TaskWeaver via un plugin personnalisé
Dans cette section du tutoriel, vous apprendrez comment intégrer un agent TaskWeaver à Bright Data pour la récupération de données web.
Plus précisément, vous verrez comment étendre une application TaskWeaver avec un outil personnalisé qui se connecte à l’API Bright Data Web Unlocker. Cela permet à votre agent « code-first » de récupérer des données à partir de n’importe quelle page Web sur Internet et de les traiter selon vos besoins.
Remarque: pour une approche similaire, consultez notre guide d’intégration avec smoleagents, un autre agent technologique IA axé sur le code.
Suivez attentivement les instructions ci-dessous !
Prérequis
Pour suivre ce tutoriel, vous avez besoin de :
- Python 3.10 ou supérieur installé localement : nécessaire pour exécuter TaskWeaver et ses plugins.
- Git installé localement : nécessaire pour cloner le référentiel TaskWeaver depuis GitHub.
- Le démon Docker en cours d’exécution : doit être en cours d’exécution pour éviter les erreurs avec la fonctionnalité de vérification du code (qui est facultative).
- Une clé API OpenAI (ou la clé API de tout autre LLM pris en charge).
Pour travailler avec Bright Data, vous aurez également besoin :
- Un compte Bright Data avec une clé API.
- Une zone Web Unlocker configurée dans votre compte.
Ne vous inquiétez pas pour la configuration de Bright Data pour l’instant, car cela sera abordé dans une étape dédiée.
Étape n° 1 : créer un projet Microsoft TaskWeaver
Commencez par créer un dossier pour votre projet TaskWeaver et accédez-y dans le terminal :
mkdir taskweaver-bright-data-example
cd taskweaver-bright-data-exampleDans le dossier du projet, créez un environnement virtuel:
python -m venv .venvActivez-le ensuite. Sous Linux/macOS, exécutez cette commande :
source .venv/bin/activateOu, sous Windows, exécutez :
.venvScriptsactivateMaintenant, installez TaskWeaver à l’aide des commandes suivantes :
git clone https://github.com/microsoft/TaskWeaver.git
cd TaskWeaver
pip install -r requirements.txtCela clonera TaskWeaver/ dans votre dossier de projet et installera toutes les dépendances dans l’environnement virtuel que vous venez de créer via pip.
TaskWeaver s’exécute en tant que processus et nécessite un répertoire de projet pour stocker les plugins, les fichiers de configuration et les données de session. Le référentiel que vous venez de cloner fournit un exemple de projet dans le répertoire TaskWeaver/project/: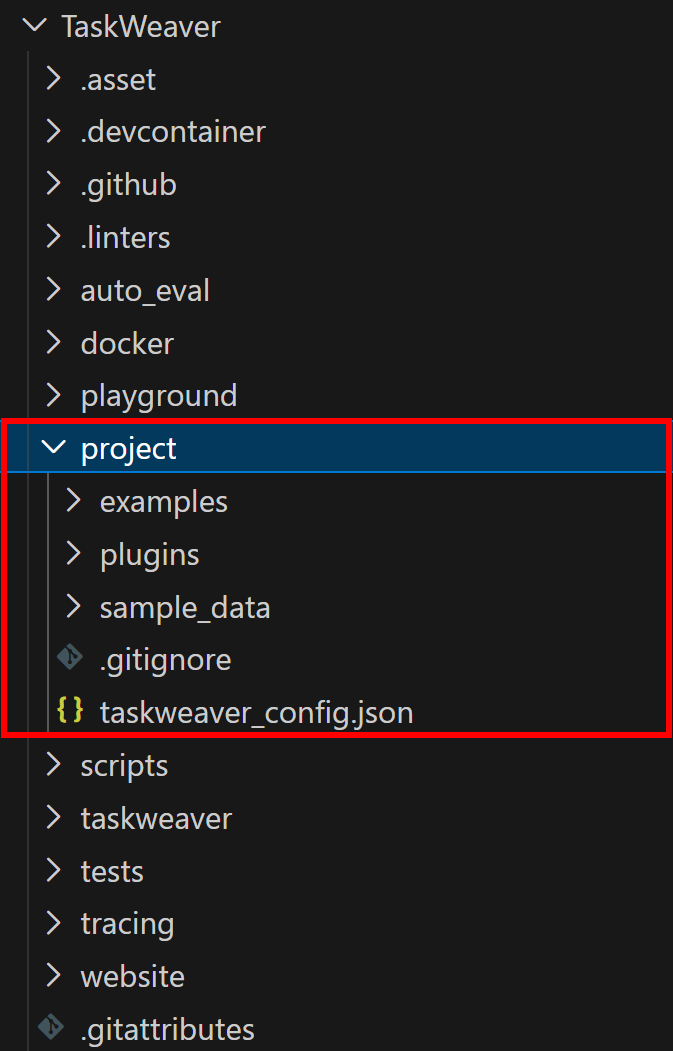
Copiez le contenu du dossier du projet dans votre espace de travail. Après cela, votre dossier taskweaver-bright-data-example/ devrait ressembler à ceci :
taskweaver-bright-data-example/
├─ .venv/
├─ TaskWeaver/
├─ plugins/ # Dossier pour stocker vos plugins
├─ examples/
│ ├─ planner_examples/ # Exemples de scripts de planification
│ └─ code_generator_examples/ # Exemples de scripts de générateur de code
├─ sample_data/ # Exemples de jeux de données facultatifs
├─ .gitignore
└─ taskweaver_config.json # Fichier de configuration du projetEn particulier, un répertoire de projet Microsoft TaskWeaver typique contient des dossiers et des fichiers spécifiques, comme décrit dans la documentation officielle.
Chargez taskweaver-bright-data-example/ dans votre IDE Python préféré, tel que Visual Studio Code ou PyCharm.
Une fois votre environnement virtuel activé, lancez l’application tout en restant dans le dossier /TaskWeaver à l’aide de la commande suivante :
python -m taskweaverCela lancera le processus TaskWeaver à partir du dossier /TaskWeaver, qui chargera les fichiers et le répertoire du projet à partir du dossier taskweaver-bright-data-example/.
Si tout fonctionne correctement, vous devriez voir ceci dans votre terminal :
Succès ! Microsoft TaskWeaver fonctionne. Après avoir exécuté l’application pour la première fois, les dossiers suivants seront créés :
workspace/: stocke les données de session pour votre projet.logs/: stocke les fichiers journaux générés par le programme.
Remarque: si vous essayez d’entrer une invite maintenant, cela échouera car vous devez encore configurer une connexion à un LLM. Cela sera abordé dans l’étape suivante.
Étape n° 2 : configurer le LLM dans TaskWeaver
TaskWeaver prend en charge un large éventail de LLM. Dans ce tutoriel, nous allons intégrer un modèle OpenAI, mais vous pouvez facilement adapter les instructions à tout autre fournisseur de LLM pris en charge.
Pour configurer le modèle GPT-4.1 mini dans TaskWeaver, assurez-vous que votre fichier taskweaver_config.json situé dans taskweaver-bright-data-example/ contient les éléments suivants :
{
"llm.api_key": "<YOUR_OPENAI_API_KEY>",
"llm.model": "gpt-4.1-mini"
}Remplacez <VOTRE_CLÉ_API_OPENAI> par votre clé API OpenAI réelle.
Remarque: à l’heure où nous écrivons ces lignes, TaskWeaver ne prend pas en charge les modèles GPT-5. Si vous essayez de configurer un modèle GPT-5, vous obtiendrez l’erreur suivante :
{'error': {'message': "Paramètre non pris en charge : 'max_tokens' n'est pas pris en charge avec ce modèle. Utilisez plutôt 'max_completion_tokens'.", 'type': 'invalid_request_error', 'param': 'max_tokens', 'code': 'unsupported_parameter'}}Fantastique ! Votre projet TaskWeaver est désormais alimenté par le mini-modèle OpenAI GPT-4.1 et prêt à traiter les invites.
Étape n° 3 : configurer une zone API Bright Data Web Unlocker
Pour connecter votre agent TaskWeaver à Bright Data afin de bénéficier des fonctionnalités de Scraping web, vous devez d’abord effectuer quelques étapes préliminaires. Plus précisément, vous devez préparer votre compte Bright Data en configurant une zone Web Unlocker.
Si vous n’avez pas encore de compte, créez un compte Bright Data. Sinon, connectez-vous simplement. Une fois dans votre compte, accédez à la page « Proxies & Scraping » (Proxys et scraping). Dans la section « My Zones » (Mes zones), recherchez une ligne intitulée « Web Unlocker API » dans le tableau :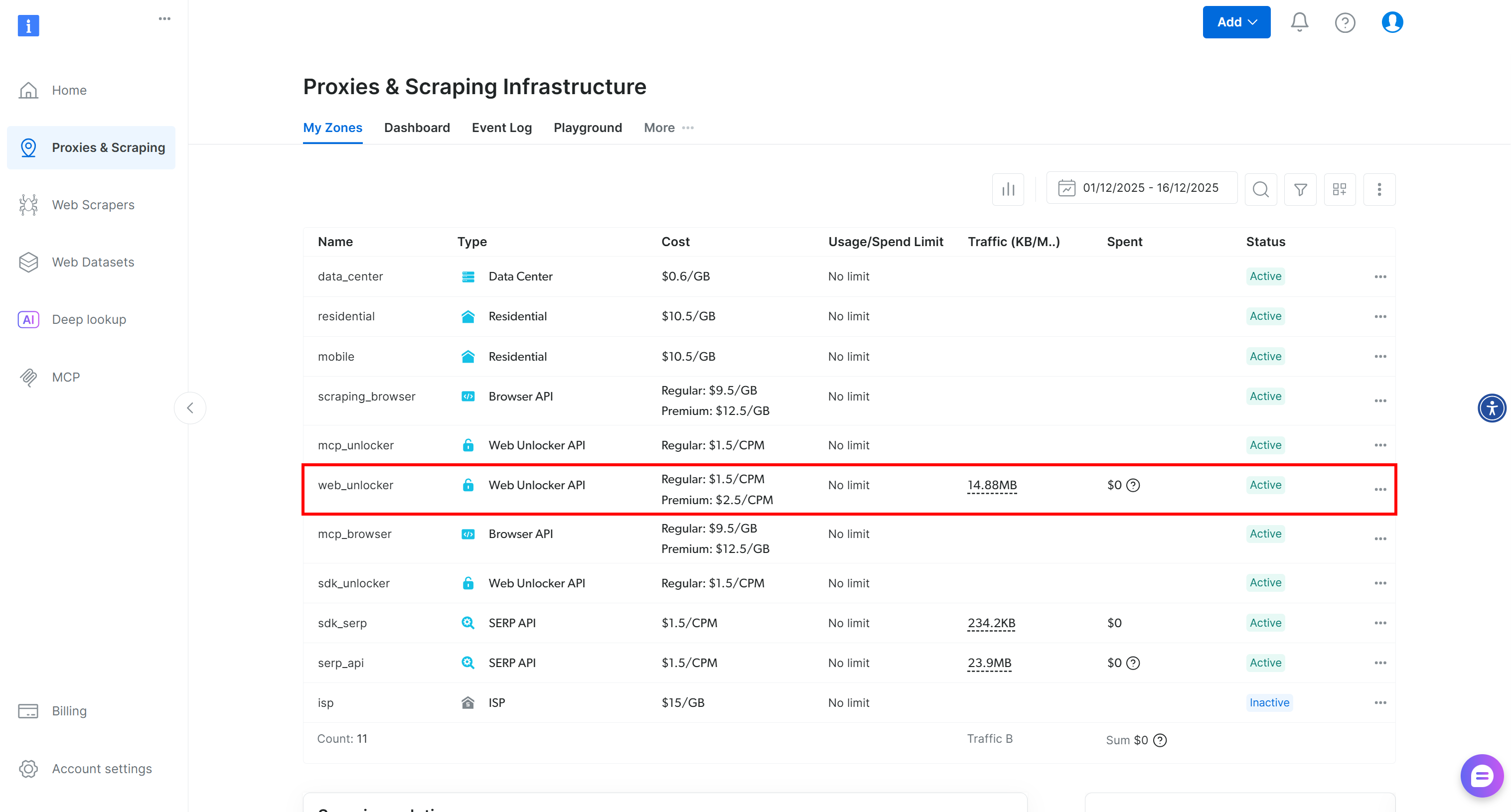
Si vous ne voyez pas de ligne intitulée « Web Unlocker API », cela signifie qu’une telle zone n’a pas encore été configurée dans votre compte Bright Data. Pour en créer une, faites défiler vers le bas jusqu’à la section « Unlocker API » et cliquez sur « Create zone » (Créer une zone) pour en ajouter une :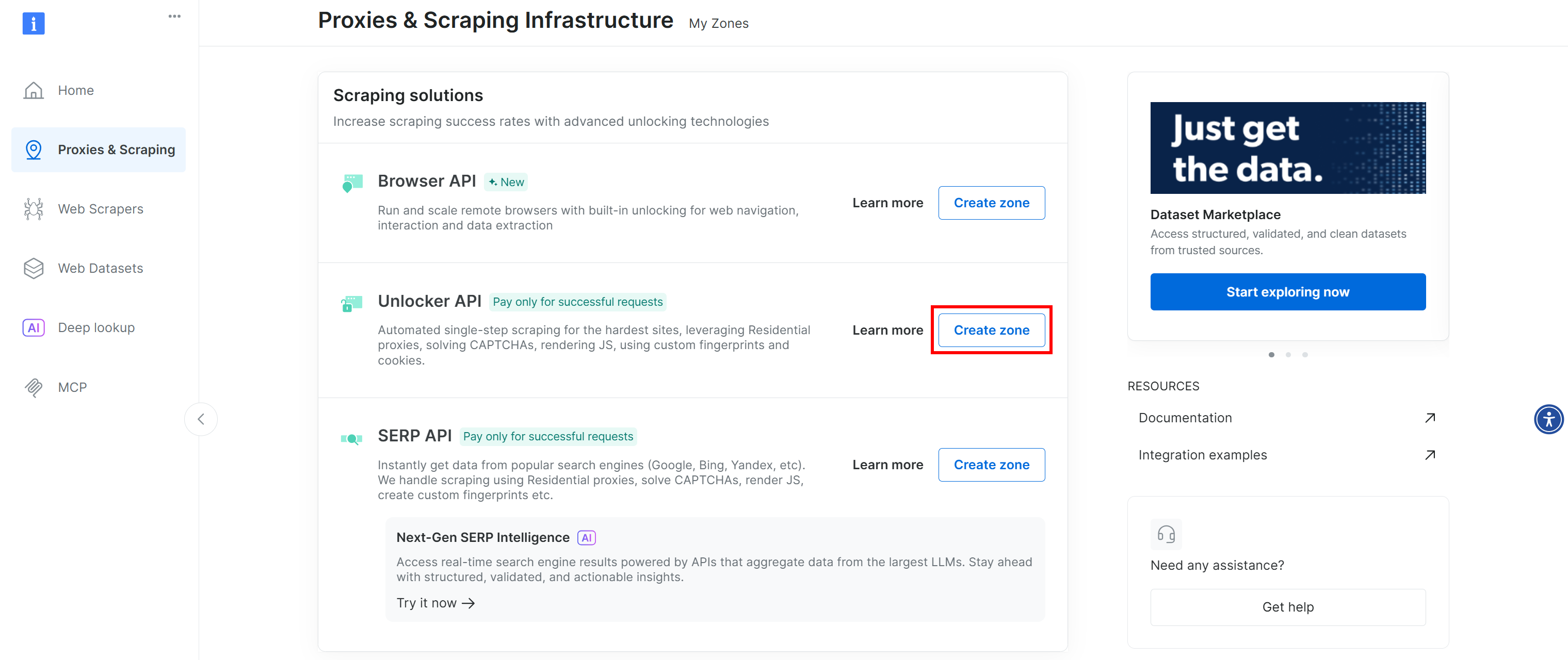
Créez une zone Web Unlocker API et donnez-lui un nom, tel que web_unlocker (ou tout autre nom de votre choix). Mémorisez le nom de la zone, car vous en aurez besoin pour accéder au service via l’API dans un plugin personnalisé.
Sur la page de la zone Web Unlocker, assurez-vous que le bouton est réglé sur « Active » pour confirmer que la zone est activée.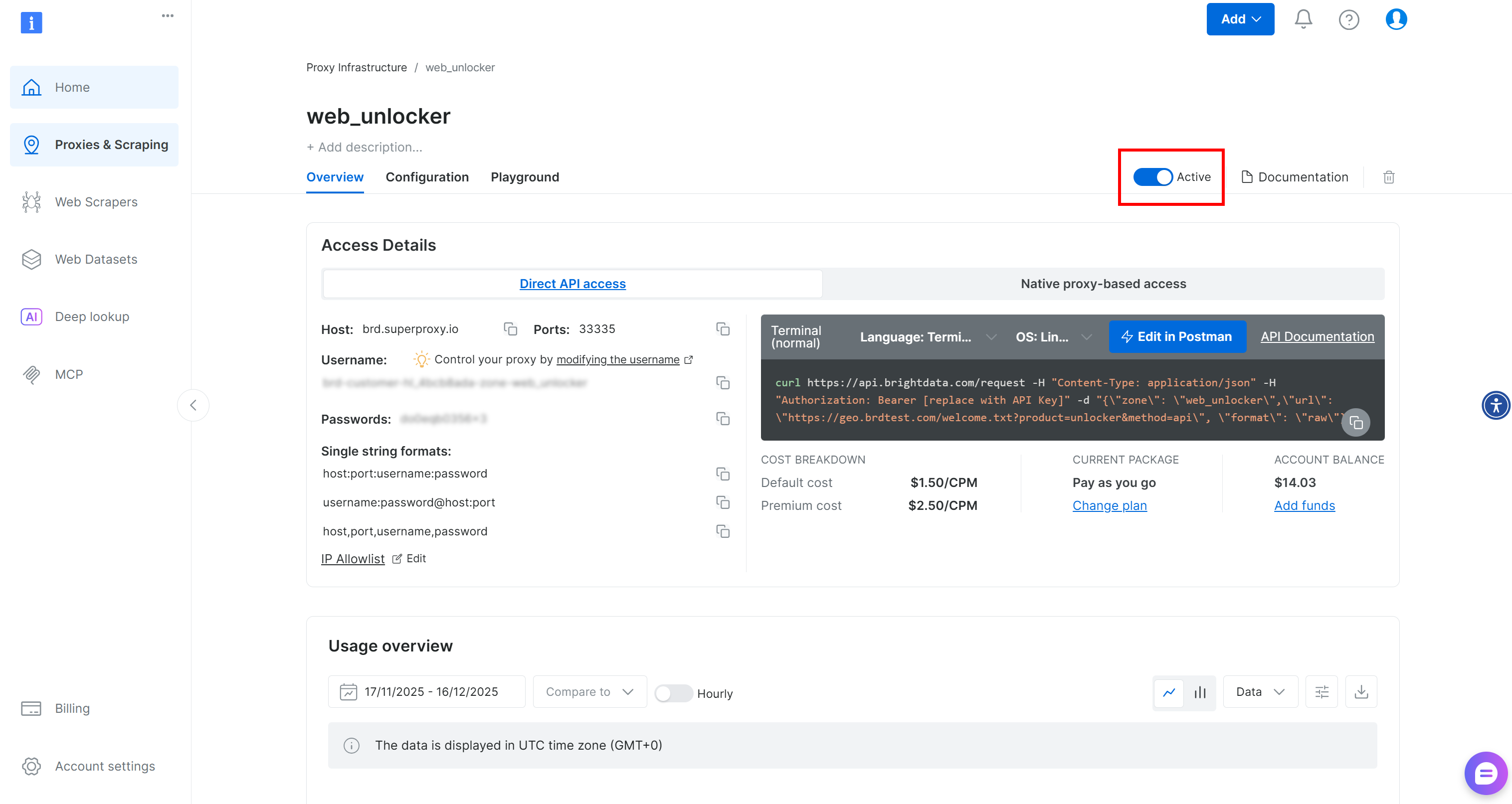
Enfin, suivez le guide officiel pour générer votre clé API Bright Data. Conservez-la en lieu sûr, car vous en aurez besoin sous peu.
Parfait ! Vous avez maintenant tout ce qu’il faut pour utiliser le plugin API Web Unlocker de Bright Data dans votre application TaskWeaver.
Étape n° 4 : définir le plugin TaskWeaver Web Unlocker pour l’intégration de Bright Data
Les plugins sont des unités qui peuvent être orchestrées par l’interpréteur de code de TaskWeaver. Plus précisément, chaque plugin est une fonction Python qui peut être appelée dans le code généré.
Dans TaskWeaver, un plugin comprend deux fichiers :
- Implémentation du plugin: un fichier Python qui définit le plugin.
- Schéma du plugin: un fichier YAML qui définit les entrées, les sorties et les métadonnées du plugin.
Les deux fichiers doivent être placés dans le sous-dossier plugins/ de votre projet.
Dans ce cas, vous devez ajouter un plugin qui appelle l’API Bright Data Web Unlocker. Pour plus d’informations sur la manière d’appeler ce point de terminaison API, consultez la documentation officielle.
Dans votre environnement virtuel actif, installez d’abord un client HTTP Python tel que Requests:
pip install requestsAjoutez ensuite un fichier plugin web_unlocker.py dans le dossier plugins/. Définissez-le comme suit :
# taskweaver-bright-data-example/plugins/web_unlocker.py
import requests
from taskweaver.plugin import Plugin, register_plugin
@register_plugin
class WebUnlockerPlugin(Plugin):
def __call__(
self,
url: str,
data_format: str = None
):
# Lire les valeurs de configuration pour l'appel API
bright_data_api_key = self.config.get("api_key")
zone = self.config.get("zone", "web_unlocker")
default_format = self.config.get("data_format", "markdown")
# En-têtes HTTP requis par l'API Bright Data pour l'authentification
headers = {
"Authorization": f"Bearer {bright_data_api_key}",
"Content-Type": "application/json"
}
# Charge utile de la requête envoyée à Bright Data Web Unlocker
payload = {
"zone": zone,
"url": url,
"format": "raw", # Pour obtenir la réponse directement dans le corps
"data_format": data_format ou default_format
}
# Envoi de la requête à l'API Bright Data Web Unlocker
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers,
)
# Levée d'une exception pour les réponses HTTP non 2xx
response.raise_for_status()
# Extraire le contenu de la réponse et le code d'état HTTP
content = response.text
status = response.status_code
# Résumé en langage naturel renvoyé au LLM
description = (
f"Page récupérée avec succès à l'aide de Bright Data Web Unlocker "
f"(HTTP {status}, {len(content)} caractères)."
)
# Conserver la page récupérée en tant qu'artefact dans l'espace de travail de la session
self.ctx.add_artifact(
name="web_unlocker_page",
file_name="page_content.md",
type="txt",
val=content
)
# Renvoyer à la fois le contenu brut et une description lisible par l'utilisateur
return content, descriptionCe plugin récupère une page web via l’API Bright Data Web Unlocker. Tout d’abord, il lit les valeurs de configuration dans la section des configurations YAML du plugin (à définir prochainement) à l’aide de self.config.get().
Ensuite, il envoie une requête HTTP, vérifie les erreurs et enregistre la page récupérée en tant qu’artefact dans l’espace de travail via self.ctx.add_artifact(), ce qui vous permet de vérifier le résultat pendant et après l’exécution. Enfin, il renvoie à la fois le contenu brut de la page et un résumé lisible par l’homme à l’usage du LLM.
Remarque: par défaut, l’appel à l’API Bright Data Web Unlocker a été configuré pour renvoyer le contenu des pages web au format Markdown, ce qui est idéal pour l’ingestion LLM. Il s’agit d’une fonctionnalité utile fournie par l’API Web Unlocker pour prendre en charge les intégrations IA et simplifier le traitement du contenu.
Génial ! Avant que l’agent TaskWeaver puisse utiliser ce plugin, vous devez également spécifier le fichier de schéma YAML du plugin.
Étape n° 5 : poursuivre avec la définition du schéma du plugin
Le schéma du plugin spécifie comment le LLM dans TaskWeaver comprend et appelle le plugin. Il doit être écrit au format YAML. Créez donc un fichier nommé web_unlocker.yaml dans le dossier plugins/ comme suit :
# taskweaver-bright-data-example/plugins/web_unlocker.yaml
name: web_unlocker
enabled: true
plugin_only: true
description: >-
Récupère et déverrouille les pages web à l'aide de l'API Bright Data Web Unlocker,
contournant les protections anti-bot et renvoyant un contenu de page propre.
parameters:
- name: url
type : str
required : true
description : URL complète de la page web à récupérer.
- name : data_format
type : str
required : false
description : Format de sortie du contenu de la page (« markdown » ou HTML brut, s'il est omis).
returns :
- name : content
type : str
description : Contenu de la page déverrouillée.
- nom : description
type : str
description : Résumé en langage naturel de l'opération de récupération.
configurations :
api_key : <VOTRE_CLÉ_API_BRIGHT_DATA> # Remplacez par votre clé API Bright Data.
zone : web_unlocker # Remplacez par le nom de votre zone Web Unlocker.
data_format : markdownLe fichier YAML ci-dessus décrit les entrées et les sorties de la fonction __call__() dans la classe WebUnlockerPlugin définie précédemment. Grâce à ce schéma, le LLM de TaskWeaver comprendra comment fonctionne le plugin web_unlocker.py et comment l’appeler dans le code Python généré.
Dans la section configurations, spécifiez votre clé API Bright Data, le nom de la zone Web Unlocker et le format de sortie souhaité. Remplacez les champs api_key et zone par les valeurs que vous avez configurées à l’étape n° 3.
Et voilà ! L’intégration de TaskWeaver + Bright Data est terminée.
Remarque: vous pouvez utiliser la même approche pour intégrer d’autres services Bright Data via l’API, tels que l’API SERP ou les API de Scraping web.
Étape n° 6 : tester l’agent TaskWeaver
Il est temps de vérifier que l’agent code-first dans TaskWeaver peut désormais appeler le plugin alimenté par Bright Data. L’idée est que le code généré invoque la fonction du plugin et accède aux capacités de déverrouillage Web fournies par l’API Web Unlocker.
Pour le tester, essayez une invite comme celle-ci :
Récupérez le dernier journal des modifications MCP à partir de « https://modelcontextprotocol.io/specification/2025-11-25/changelog » et listez les modifications.Cette tâche serait normalement impossible pour un LLM standard, car elle nécessite un outil personnalisé pour naviguer vers une URL et en extraire des informations. Cependant, avec TaskWeaver + Bright Data, l’agent peut s’en charger !
Lancez l’application TaskWeaver avec :
python -m taskweaverCollez l’invite et appuyez sur Entrée. Vous devriez voir quelque chose comme ceci :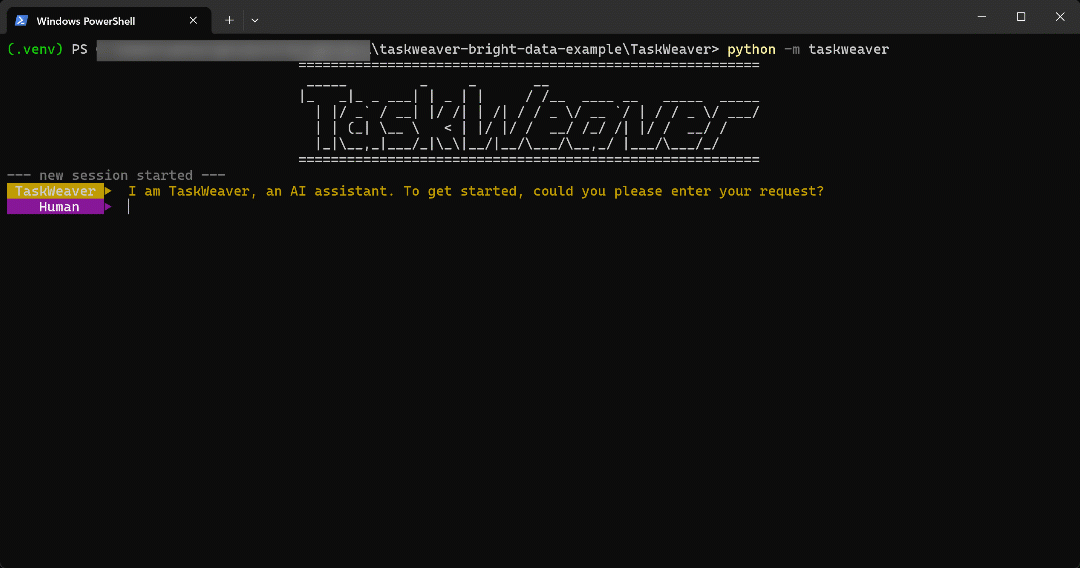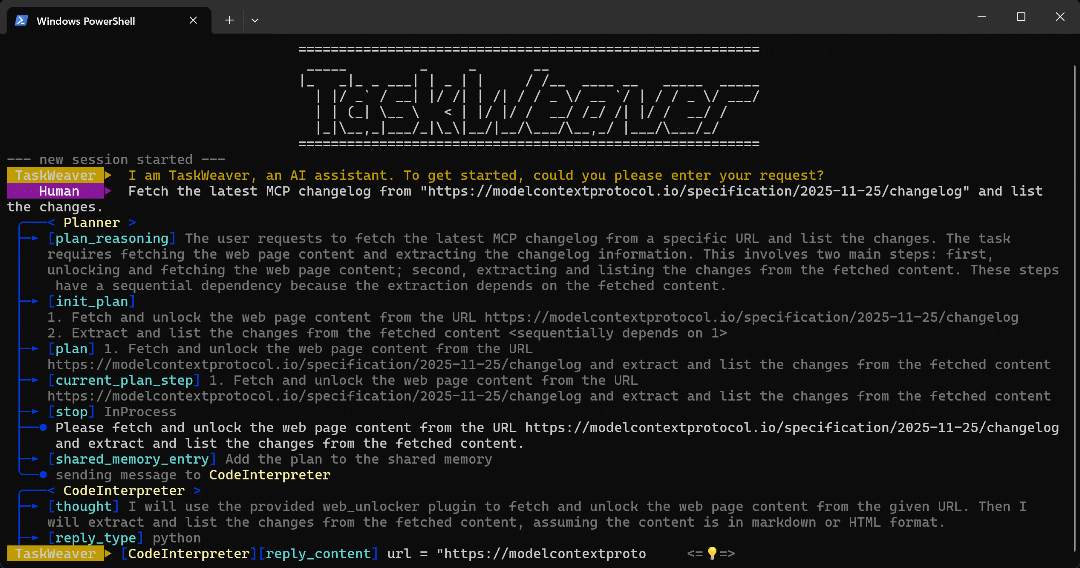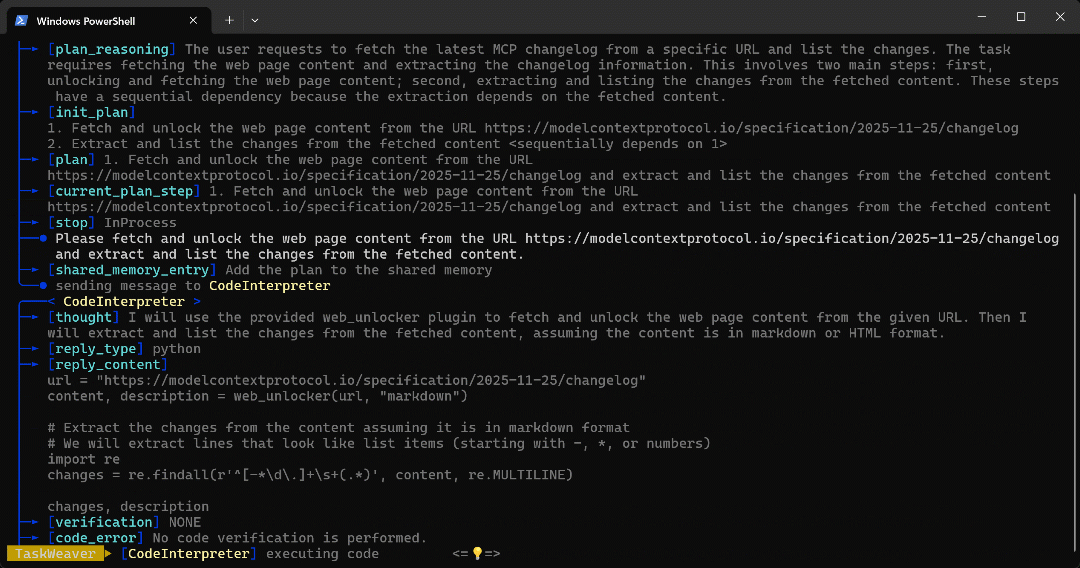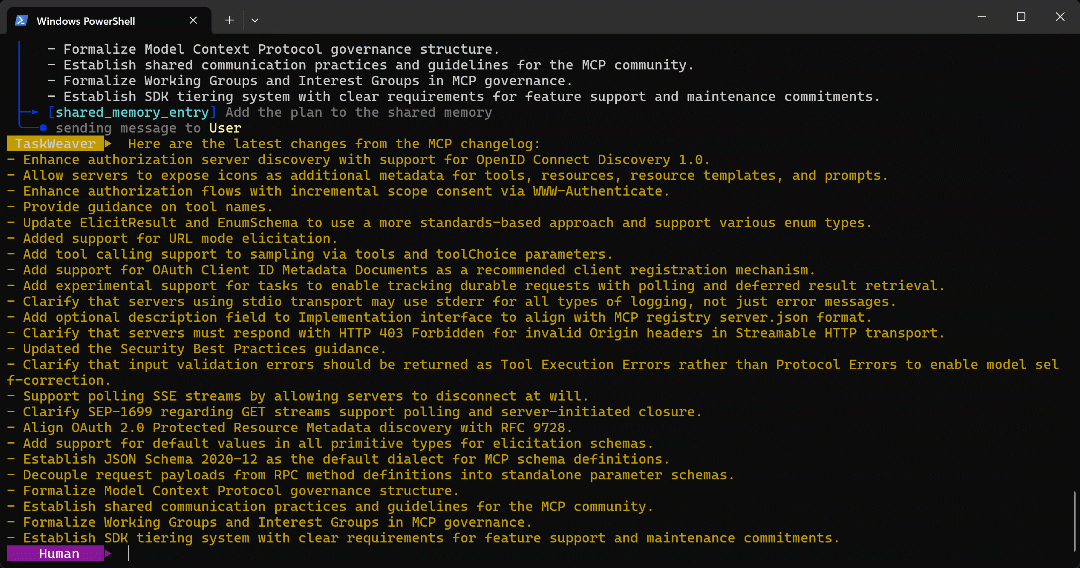
Comme vous pouvez le constater, l’agent :
- Le TaskWeaver
Plannercommence par élaborer un plan pour exécuter la tâche. - Le plan est ensuite envoyé à l’agent interne
CodeInterpreter, qui génère du code Python pour atteindre l’objectif. - Le code Python appelle le plugin Web Unlocker API, puis extrait tous les points de l’article à l’aide d’une expression régulière.
- Le code est exécuté et les données souhaitées sont récupérées via l’API Web Unlocker et stockées dans le dossier de l’espace de travail tel que configuré avec
self.ctx.add_artifact(). - Les données Markdown renvoyées, contenant le contenu de la page spécifiée par l’URL, sont renvoyées au
Planner, qui passe à l’étape suivante. - La liste des puces extraites de la page cible est renvoyée à l’utilisateur comme prévu.
Formidable ! L’agent TaskWeaver fonctionne parfaitement. Prenons le temps d’examiner le résultat obtenu.
Étape n° 7 : explorer le résultat
Le résultat final de l’exécution de l’agent est le suivant :
Comme vous pouvez le vérifier sur la page cible, cette liste correspond exactement aux informations trouvées dans le journal des modifications MCP :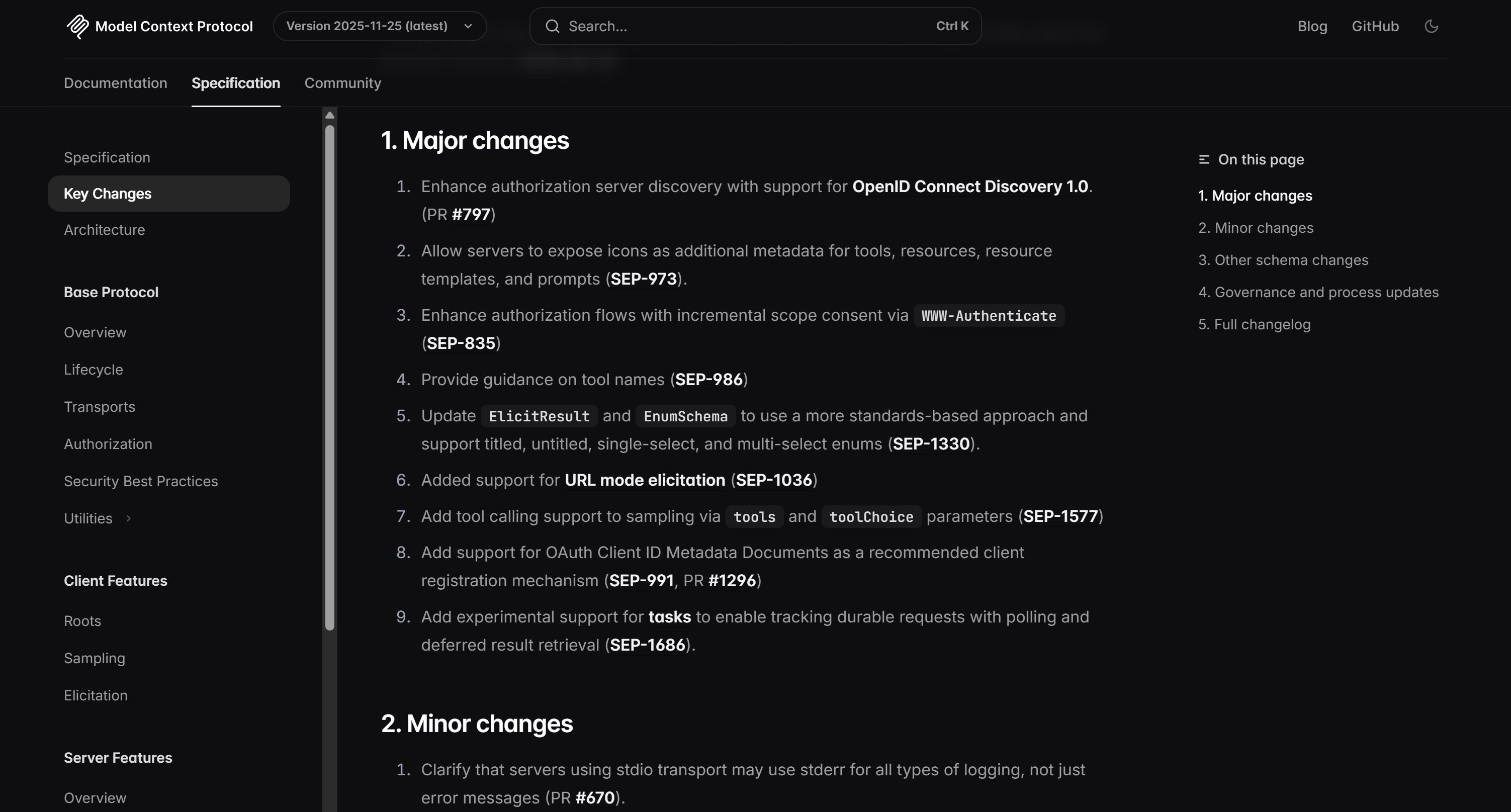
Plus précisément, l’agent a produit le résultat à l’aide du code Python suivant :
url = "https://modelcontextprotocol.io/specification/2025-11-25/changelog"
content, description = web_unlocker(url, "markdown")
# Extraire les modifications du contenu en supposant qu'il est au format Markdown.
# Nous allons extraire les lignes qui ressemblent à des éléments de liste (commençant par -, * ou des chiffres).
import re
changes = re.findall(r'^[-*d.]+s+(.*)', content, re.MULTILINE)
changes, descriptionRemarquez comment l’extrait généré appelle le plugin de la fonction web_unlocker() pour récupérer la page d’entrée au format Markdown. Il la traite ensuite à l’aide d’une expression régulière simple afin d’extraire les informations pertinentes.
Pour vérifier que l’API Web Unlocker a renvoyé le contenu de la page au format Markdown, consultez les fichiers dans le dossier workspace/. Chaque exécution d’agent génère un sous-dossier de session dans workspace/sessions/, contenant un sous-dossier pour cette exécution spécifique.
Dans le dossier cwd/, vous trouverez le fichier .md créé via l’appel self.ctx.add_artifact(). Ouvrez-le pour afficher le contenu renvoyé par l’API Web Unlocker :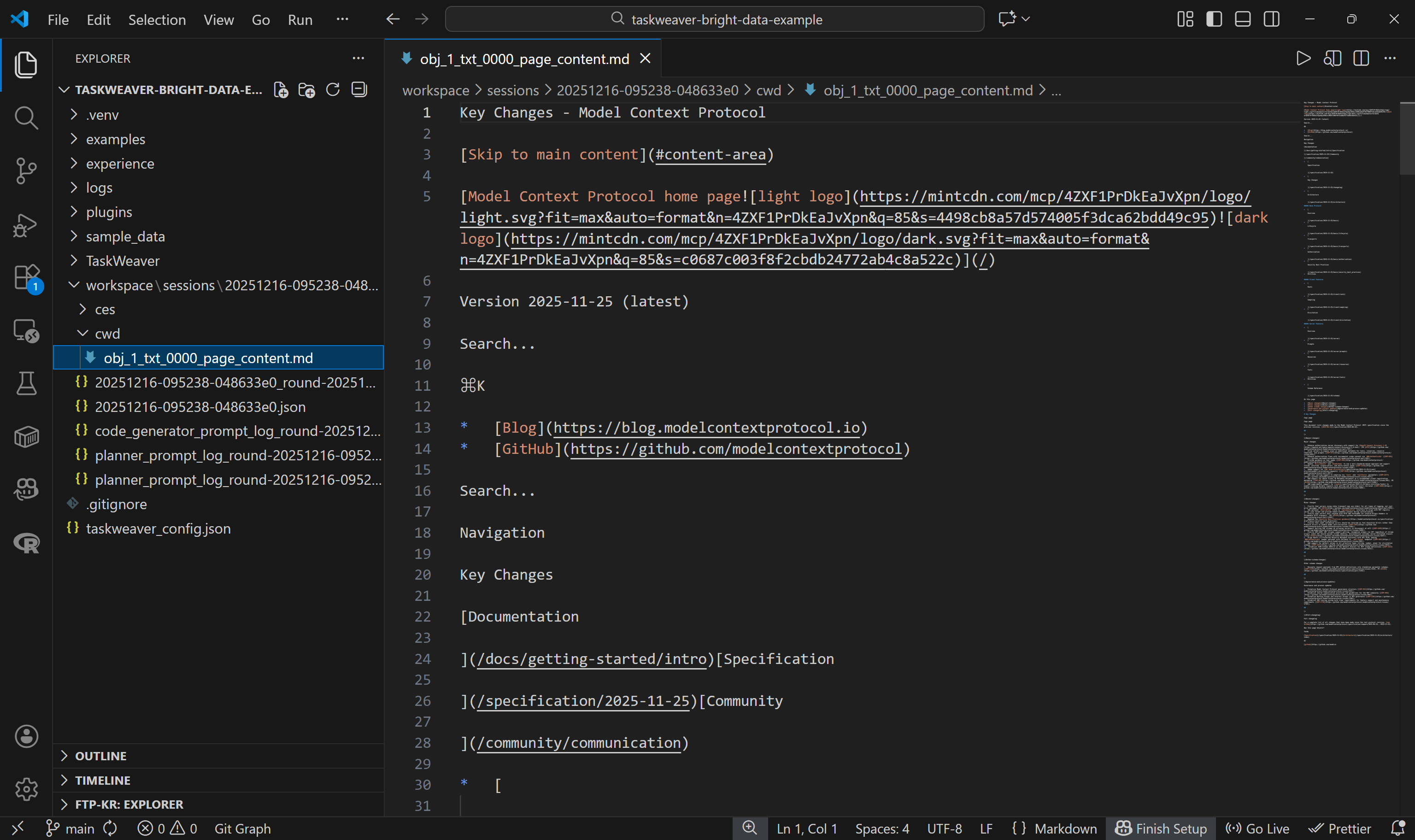
Celui-ci correspond exactement à la version Markdown de la page cible, ce qui signifie que la fonction API Web Unlocker dans le code Python généré a parfaitement fonctionné. Waouh !
Maintenant, allez plus loin avec votre agent. Testez différentes invites pour gérer des scénarios plus réalistes et adaptés à l’entreprise.
Et voilà ! Vous avez réussi à créer un agent IA code-first intégré à Bright Data à l’aide de TaskWeaver. Cet agent peut récupérer de manière fiable des données prêtes pour l’IA à partir de n’importe quelle page web.
Prochaines étapes
L’intégration présentée ici est un exemple basique. Pour faire passer votre agent TaskWeaver au niveau supérieur et le rendre prêt pour la production, envisagez les améliorations suivantes :
- Intégrez des solutions Bright Data supplémentaires, telles que l’API SERP, pour donner à l’agent la possibilité de rechercher sur le web et de collecter des données en temps réel.
- Configurez l’interface utilisateur Web comme un terrain de jeu pour simplifier le développement, les tests et la surveillance de votre agent.
- Activez des fonctionnalités avancées telles que la compression rapide, la sélection automatique des plugins etla télémétrie/observabilité afin d’améliorer les performances, l’évolutivité et la maintenabilité.
Conclusion
Dans ce tutoriel, vous avez vu comment intégrer Bright Data à TaskWeaver grâce à des plugins personnalisés qui se connectent à des API externes.
Cette configuration permet d’effectuer des recherches Web en temps réel, d’extraire des données structurées, d’accéder à des flux Web en direct et d’automatiser les interactions Web. En tirant parti de la suite complète de services Bright Data pour l’IA, vous libérez tout le potentiel de vos agents IA axés sur le code !
Créez gratuitement un compte Bright Data dès aujourd’hui et découvrez nos solutions de données web prêtes pour l’IA.




