

Dans ce tutoriel, vous apprendrez ce qui suit :
- Ce qu’est Cloudflare.
- Un examen plus approfondi de son mécanisme WAF.
- Comment fonctionne son système anti-bot d’un point de vue technique.
- Ce qui se passe lorsque vous ciblez un site protégé par Cloudflare à l’aide d’outils d’automatisation standard.
- Approches de haut niveau pour contourner Cloudflare.
- Comment contourner la vérification humaine de Cloudflare en Python.
- Comment contourner Cloudflare à grande échelle.
Plongeons dans l’aventure !
Qu’est-ce que Cloudflare ?
Cloudflare est une société d’infrastructure et de sécurité web qui exploite l’un des plus grands réseaux du web. Elle propose une gamme complète de services conçus pour rendre les sites web plus rapides et plus sûrs.
À la base, Cloudflare fonctionne principalement comme un CDN(Content Delivery Network), mettant en cache le contenu d’un site sur un réseau mondial afin d’améliorer les temps de chargement et de réduire la latence. En outre, il offre des fonctionnalités telles que la protection DDoS(Distributed Denial-of-Service), un WAF (Web Application Firewall), la gestion des robots, des services DNS, etc.
En intégrant le réseau de Cloudflare, les sites peuvent rapidement bénéficier d’une sécurité renforcée et de performances optimisées. Cloudflare est ainsi devenu la solution de référence pour des millions de sites web dans le monde.
Comprendre les mécanismes anti-bots de Cloudflare
L’une des raisons pour lesquelles Cloudflare est si populaire est son WAF(Web Application Firewall). Celui-ci peut être activé sur n’importe quelle page web desservie par son réseau mondial. En détail, il représente l’une des solutions les plus efficaces contre les scrapers, les crawlers indésirables et les bots en général.
Plus précisément, le WAF de Cloudflare se trouve devant vos applications web. Il inspecte et filtre les requêtes entrantes en temps réel afin d’arrêter les attaques ou le trafic indésirable avant qu’ils n’atteignent vos serveurs ou n’accèdent à vos pages web.
Dans le cadre de sa stratégie de défense multicouche, le WAF de Cloudflare utilise des algorithmes propriétaires pour détecter et bloquer les robots malveillants. Ces algorithmes analysent plusieurs caractéristiques du trafic entrant, notamment :
- Empreintes TLS: Inspecte la façon dont la poignée de main TLS est effectuée par le client HTTP ou le navigateur. Il examine des détails tels que les suites de chiffrement proposées, l’ordre de négociation et d’autres caractéristiques de bas niveau. Les robots et les clients non standard ont souvent des signatures TLS inhabituelles, qui ne ressemblent pas à celles d’un navigateur et qui les trahissent.
- Détails de la requête HTTP: Examine les en-têtes HTTP, les cookies, les chaînes de l’agent utilisateur et d’autres aspects. Les robots réutilisent souvent des configurations par défaut ou suspectes qui diffèrent de celles utilisées par les vrais navigateurs.
- Empreintes JavaScript: Exécute JavaScript dans le navigateur du client pour recueillir des informations détaillées sur l’environnement. Il s’agit notamment de la version exacte du navigateur, du système d’exploitation, des polices ou extensions installées, et même de caractéristiques matérielles subtiles. Ces données forment une empreinte digitale qui permet de distinguer les utilisateurs réels des scripts automatisés.
- Analyse comportementale: L’un des meilleurs indicateurs d’un trafic automatisé est un comportement non naturel. Cloudflare surveille des schémas tels que des requêtes rapides, l’absence de mouvements de souris, des chemins de clics identiques, des temps d’inactivité, etc. Il utilise l’apprentissage automatique pour déterminer si le comportement de navigation correspond à celui d’un humain ou d’un robot. Il s’agit de l’une des techniques anti-bots les plus complexes.
Cloudflare propose généralement deux modes de vérification humaine :
- Toujours montrer le défi de la vérification humaine
- Vérification humaine automatisée (uniquement en cas de détection d’une activité suspecte)
Découvrez les deux options ci-dessous !
Mode #1 : Toujours montrer le défi de la vérification humaine
Le premier mode est moins courant mais offre une protection plus forte. L’idée est de toujours exiger une vérification humaine lors du premier accès à un site.
Par exemple, voici comment StackOverflow fonctionne à l’heure où nous écrivons ces lignes. Essayez de le visiter en mode incognito (pour garantir une nouvelle session sans cookies), et vous verrez un CAPTCHA appelé Cloudflare Turnstile, même si vous êtes un véritable utilisateur humain :
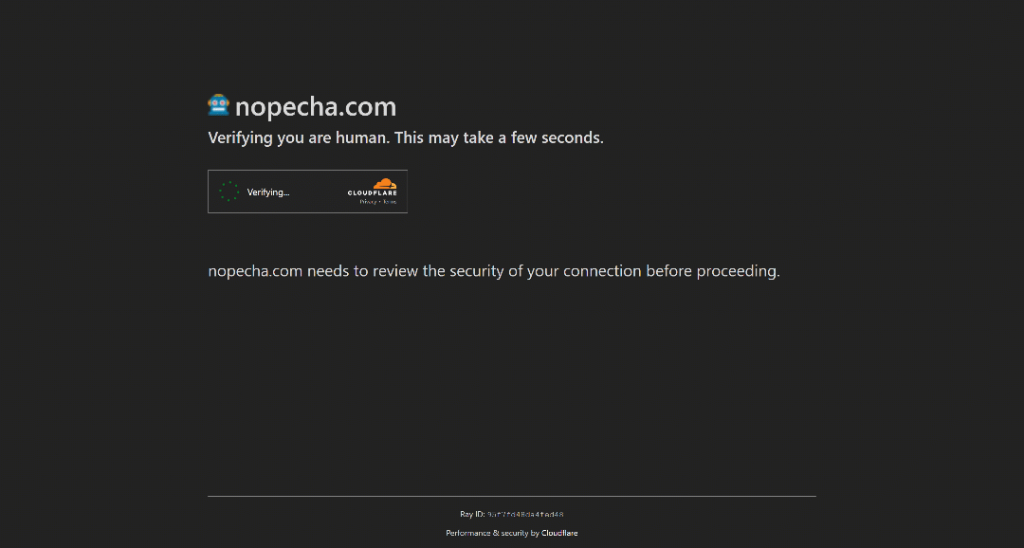
Note: Au moment où vous lisez cet article, la protection contre les robots de StackOverflow peut avoir changé ou fonctionner différemment.
Dans ce cas, si vous construisez un script automatisé, la seule option est d’automatiser l’interaction CAPTCHA du Tourniquet d’une manière semblable à celle d’un humain. C’est un véritable défi, car Turnstile s’appuie sur une analyse comportementale en coulisses et sur d’autres vérifications exclusives. C’est ainsi qu’il parvient à vérifier que vous êtes humain en un seul clic.
Mode #2 : Défi de la vérification humaine automatisée
Dans ce mode, Cloudflare n’émet un défi que s’il soupçonne qu’une requête pourrait provenir d’un robot. Pour ce faire, il présente un défi JavaScript, qui s’exécute de manière invisible dans le navigateur pour vérifier que le client se comporte comme un utilisateur légitime :
Cette procédure est transparente et s’achève généralement automatiquement si vous êtes un être humain utilisant un navigateur ordinaire. Si vous réussissez, vous pouvez continuer à naviguer sur le site sans interruption. Étant donné que ce mode ne perturbe que très peu les utilisateurs ordinaires, il est de loin le mode Cloudflare le plus courant.
Toutefois, si le défi JavaScript échoue (ce qui signifie que Cloudflare conclut que le client est probablement un robot), il affichera un CAPTCHA en forme de tourniquet pour une vérification humaine :
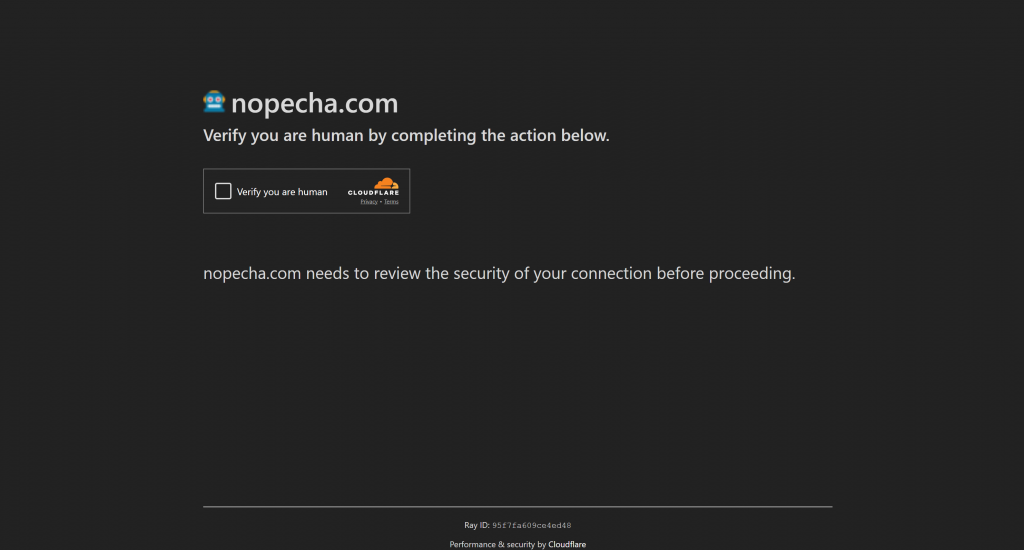
Vous vous retrouvez alors dans la situation décrite dans le scénario précédent. Dans ce cas, l’utilisation d’un robot qui présente des empreintes digitales semblables à celles d’un humain peut suffire à passer la vérification initiale, évitant ainsi le CAPTCHA en forme de tourniquet. Toutefois, si le CAPTCHA apparaît, vous devez trouver un moyen de le traiter.
Comment fonctionne Cloudflare en détail d’un point de vue technique
Essayez d’ouvrir la page de test Cloudflare de NopeCHA en mode incognito à l’aide de votre navigateur. Cette page est protégée par le WAF de Cloudflare, de sorte que le processus de vérification automatisé basé sur JavaScript commencera immédiatement.
En arrière-plan, une série de requêtes POST est échangée avec les points d’extrémité de Cloudflare, transmettant des données chiffrées dans leurs charges utiles :

Le contenu exact de ces charges utiles n’a pas été rendu public. Cependant, sur la base des stratégies de détection connues de Cloudflare, il est raisonnable de supposer qu’elles comprennent plusieurs types d’empreintes de navigateurs et de systèmes.
Étant donné que votre navigateur et votre configuration matérielle sont légitimes, cette épreuve devrait être automatiquement réussie. Sinon, procédez à l’interaction utilisateur requise (c’est-à-dire cliquez sur la case à cocher).
Une fois la vérification réussie, le serveur Cloudflare émet un cookie cf_clearance, qui indique que cette session d’utilisateur spécifique est autorisée à accéder au site web :
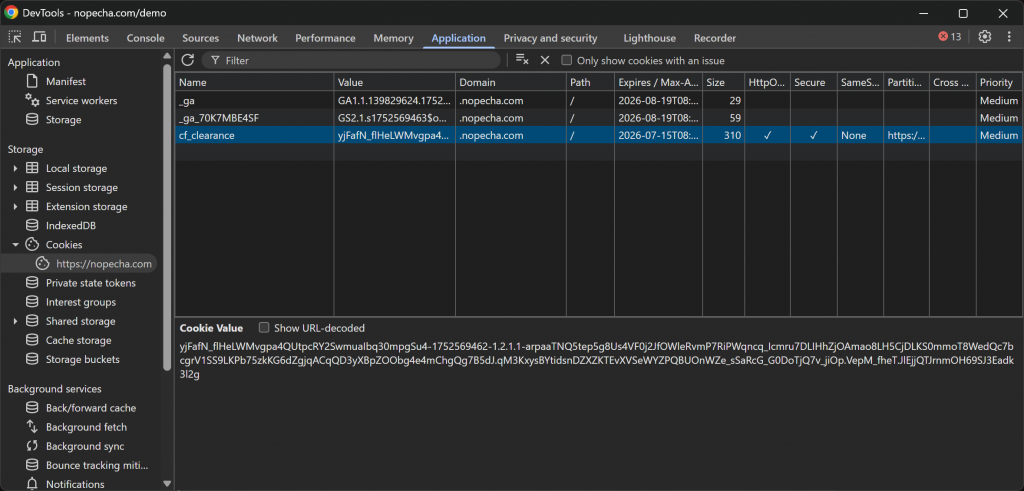
Dans ce cas, le cookie est valable pendant 15 jours. Cela signifie qu’il pourrait théoriquement être réutilisé par un robot automatisé pendant quelques semaines pour accéder au site cible sans avoir à résoudre à nouveau le processus de vérification.
Ce qui se passe lorsque vous essayez de vous connecter à un site protégé par Cloudflare
Voyons maintenant ce qui se passe lorsqu’un robot automatique tente de visiter une page protégée par Cloudflare.
Remarque: les exemples de scripts ci-dessous sont écrits en Python, mais les mêmes principes s’appliquent quel que soit le langage de programmation, le client HTTP ou l’outil d’automatisation du navigateur que vous choisissez.
Pour cette démonstration, nous utiliserons la page de défi Cloudflare de ScrapingCourse:
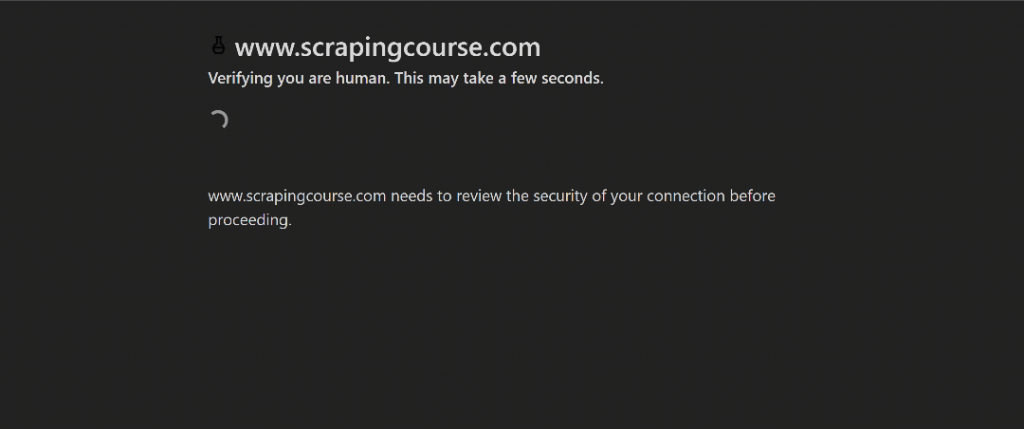
Il s’agit d’un site qui nécessite de passer la vérification de Cloudflare. Une fois le défi relevé avec succès, la page suivante s’affiche :
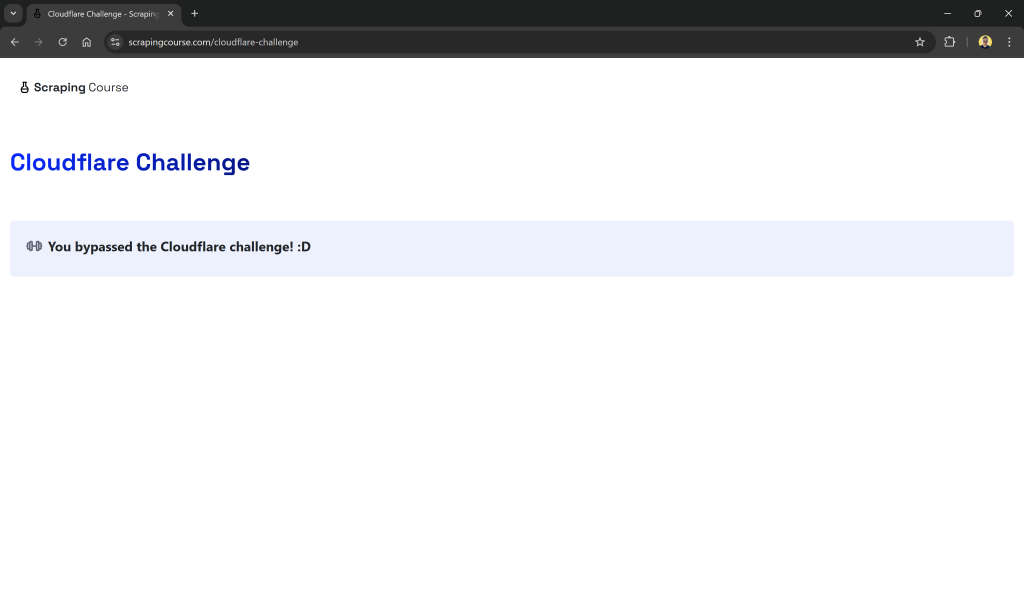
Dans les exemples suivants, nous vérifierons spécifiquement si le contenu de la page récupérée comprend la chaîne de caractères :
"You bypassed the Cloudflare challenge! :D"Cela confirmera que le processus de vérification a été mené à bien.
À titre de test de base, nous allons voir ce qui se passe lorsque nous visitons la page protégée par Cloudflare ci-dessus en utilisant deux approches différentes :
- Avec un client HTTP comme Requests
- Avec un outil d’automatisation du navigateur comme Playwright
Cibler les pages protégées par Cloudflare avec des requêtes
Vérifiez si les requêtes peuvent automatiquement contourner la vérification humaine de Cloudflare avec :
# pip install requests
import requests
# Connect to the target page
response = requests.get(
"https://www.scrapingcourse.com/cloudflare-challenge"
)
# Raise exceptions in case of HTTP error status codes
response.raise_for_status()
# Verify if you received the success page
html = response.text
print("Cloudflare Bypassed:", "You bypassed the Cloudflare challenge! :D" in html) Notez que le script n’atteindra même pas l’instruction print() finale. Au lieu de cela, il échouera avec :
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://www.scrapingcourse.com/cloudflare-challengeComme vous pouvez le voir, Cloudflare a reconnu que la demande provenait d’un script automatisé et l’a bloquée avec une réponse 403 Forbidden.
Visiter des pages protégées par Cloudflare avec Playwright
Essayons maintenant avec une solution d’automatisation du navigateur comme Playwright:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
from playwright.sync_api import TimeoutError
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Go to the target page
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
try:
# Wait for the desired text to be on the page
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
challenge_bypassed = False
# Close the browser and release its resources
browser.close()
print("Cloudflare Bypassed:", challenge_bypassed)Ce script demande à un navigateur Chromium de visiter la page cible. Il utilise ensuite un localisateur pour vérifier si un élément contenant le texte requis apparaît sur la page, en l’attendant automatiquement (par défaut, Playwright attend jusqu’à 30 secondes).
Lancez les commandes d’installation nécessaires et exécutez le script ci-dessus. Vous obtiendrez le résultat suivant :
Cloudflare Bypassed: FalseSi vous l’exécutez en mode headless(headless=False), vous remarquerez que le script reste bloqué sur la page de vérification de Cloudflare. Celle-ci affiche un CAPTCHA Turnstile et attend qu’il soit résolu manuellement :

Remarque: si vous essayez d’automatiser le fait de cocher la case Turnstile, la vérification échouera. En effet, Cloudflare est suffisamment intelligent pour détecter qu’il s’agit d’une opération automatisée et non d’une véritable interaction humaine.
Approches de haut niveau pour contourner Cloudflare
Explorez trois approches que vous pouvez utiliser pour contourner la protection de Cloudflare avec votre script automatisé.
Approche #1 : Contourner entièrement Cloudflare
N’oubliez pas que Cloudflare agit comme un CDN, ce qui signifie qu’il met en cache et distribue le contenu du site sur plusieurs serveurs géographiquement dispersés. Ainsi, les sites distribués par Cloudflare ne sont généralement accessibles que par les serveurs du réseau CDN.
Imaginez maintenant que vous parveniez à découvrir l’adresse IP du serveur du site derrière le CDN. La conséquence serait que vous pourriez interagir avec le site tout en contournant entièrement Cloudflare. En effet, Cloudflare ne peut évaluer que les requêtes qui passent par son réseau.
Cela est possible en consultant des outils de recherche d’historique DNS tels que SecurityTrails pour identifier tout enregistrement DNS historique révélant l’adresse IP du serveur d’origine. Une fois l’adresse IP obtenue, vous pouvez tenter d’envoyer des requêtes directement au serveur, sans passer par Cloudflare.
Le problème est que le serveur peut avoir des configurations supplémentaires en place pour n’accepter que les requêtes provenant de la plage d’adresses IP de Cloudflare. Il serait alors pratiquement impossible de se connecter directement au site sans être bloqué. En outre, il est très difficile et peu probable de trouver l’adresse IP d’origine du serveur.
Approche n°2 : S’appuyer sur un solveur Cloudflare
En ligne, vous pouvez trouver plusieurs bibliothèques gratuites et open-source conçues pour contourner Cloudflare. Parmi les plus populaires, citons
- cloudscraper: Un module Python qui gère les défis anti-bot de Cloudflare.
- Cfscrape: Un module PHP léger pour contourner les pages anti-bots de Cloudflare.
- Humanoïde: Un paquet Node.js pour contourner les défis JavaScript anti-bot de Cloudflare.
Il n’est pas surprenant que la plupart de ces projets n’aient pas été mis à jour depuis des années. La raison en est que les développeurs ont abandonné en raison de la lutte permanente pour suivre les mises à jour de Cloudflare. Ces outils ne fonctionnent donc généralement pas longtemps.
Approche #3 : Utiliser une solution d’automatisation avec des capacités de contournement de Cloudflare
Dans la plupart des cas, la meilleure solution pour gratter un site protégé par Cloudflare est d’utiliser une solution d’automatisation tout-en-un. Pour être efficaces, ces bibliothèques ou services en ligne doivent offrir au moins les caractéristiques suivantes :
- Rendu JavaScript, afin que les défis JavaScript de Cloudflare puissent être exécutés correctement.
- TLS, l’en-tête HTTP et l’empreinte digitale du navigateur pour simuler des utilisateurs réels et éviter la détection.
- Capacités de résolution des CAPTCHA de Turnstile, pour gérer la vérification humaine de Cloudflare lorsqu’elle apparaît.
- Simulation d’une interaction humaine, par exemple en déplaçant la souris le long d’une courbe B-spline afin d’imiter le comportement naturel de l’utilisateur.
En outre, les solutions haut de gamme comprennent souvent un réseau proxy intégré qui permet de faire pivoter les adresses IP et de réduire le risque de blocage.
Dans les deux chapitres suivants, vous verrez à l’œuvre des solutions open-source et des solutions essentiellement premium !
Comment contourner le contrôle humain de Cloudflare en Python
La plupart des solutions open-source qui prétendent contourner Cloudflare n’y parviennent que pendant une période limitée. En effet, il s’agit essentiellement d’un jeu du chat et de la souris, et leur nature open-source (où les ingénieurs de Cloudflare peuvent facilement étudier leur code) n’aide pas.
Il n’est donc pas surprenant que de nombreux outils qui fonctionnaient autrefois (comme Puppeteer Stealth) n’atteignent plus leur objectif. Néanmoins, à l’heure où nous écrivons ces lignes, il existe deux solutions qui parviennent à contourner les protections de Cloudflare :
- Camoufox: Un navigateur Python open-source anti-détection basé sur une version personnalisée de Firefox, conçu pour échapper à la détection des robots et permettre le web scraping.
- SeleniumBase: Une boîte à outils Python open-source de qualité professionnelle pour l’automatisation avancée des sites web.
Voyons comment les deux se comportent par rapport à la page défi Cloudflare de ScrapingCourse !
Contourner le tourniquet de Clouflare avec Camoufox
Tout d’abord, installez Camoufox dans votre projet Python avec :
pip install camoufox[geoip]Ensuite, récupérez les dépendances supplémentaires requises avec :
python -m camoufox fetchPour plus d’informations, consultez le guide d’installation officiel.
La bibliothèque Python de Camoufox est construite sur Playwright, son API est donc très similaire. Visitez le site cible, attendez que le défi du tourniquet apparaisse, et gérez-le (s’il apparaît effectivement) en utilisant la logique suivante :
# pip install camoufox[geoip]
# python -m camoufox fetch
from camoufox.sync_api import Camoufox
from playwright.sync_api import TimeoutError
with Camoufox(
headless=False,
humanize=True,
window=(1280, 720) # So that the Turnstile checkbox is on coordinate (210, 290)
) as browser:
page = browser.new_page()
# Visit the target page
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
# Wait for the Cloudflare Turnstile to appear and load
page.wait_for_load_state(state="domcontentloaded")
page.wait_for_load_state("networkidle")
page.wait_for_timeout(5000) # 5 seconds
# Ckick the Turnstile checkbox (if it is present)
page.mouse.click(210, 290)
try:
# Wait for the desired text to appear
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
# The text did not appear
challenge_bypassed = False
# Close the browser and release its resources
browser.close()
print("Cloudflare Bypassed:", challenge_bypassed)Notez que la logique de gestion des tourniquets est un peu délicate. Elle repose sur l’hypothèse que la case à cocher “Tourniquet” apparaîtra approximativement à la coordonnée (210, 290) sur une fenêtre de navigateur de 1280×720.
Exécutez le script ci-dessus et vous obtiendrez le résultat suivant :
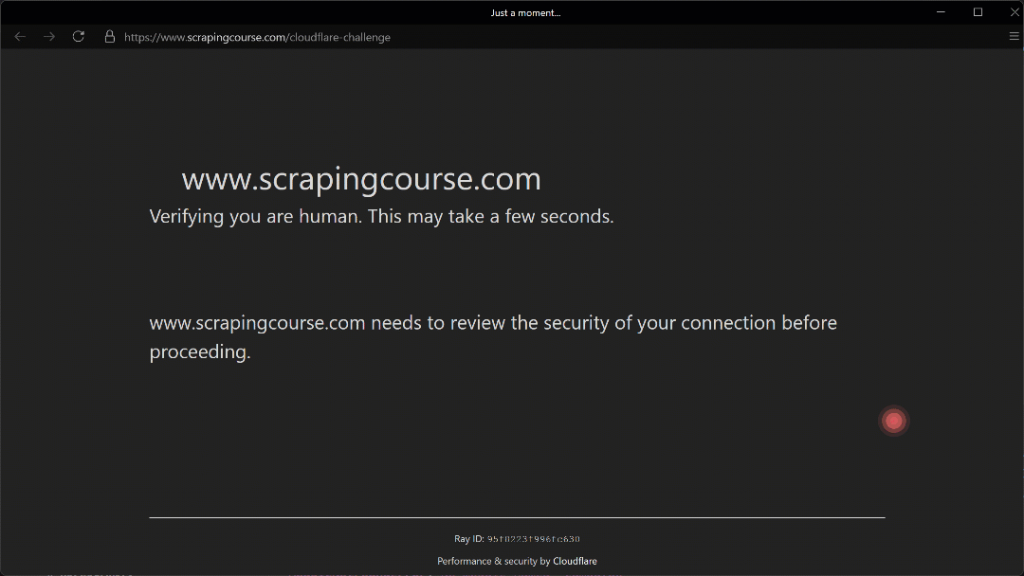
Le mouvement automatisé de la souris vers la coordonnée (210, 290) semble réaliste grâce au paramètre Humanize=True.
Comme on le voit ici, Camoufox réussit à cliquer sur la case à cocher. En conséquence, dans le terminal, vous verrez cette sortie :
Cloudflare Bypassed: TrueMission accomplie !
Éviter Clouflare avec SeleniumBase
Installez SeleniumBase avec :
pip install seleniumbaseEnsuite, utilisez-le pour gérer Cloudflare :
# pip install seleniumbase
from seleniumbase import Driver
from seleniumbase.common.exceptions import TextNotVisibleException
# Launch in undetected-chromedriver mode
driver = Driver(uc=True)
# Visit the target page
url = "https://www.scrapingcourse.com/cloudflare-challenge"
driver.uc_open_with_reconnect(url, 4)
# Click the Turnstile (if it is present) and reload the page
driver.uc_gui_click_captcha()
try:
# Wait for the desired text to appear
driver.wait_for_text("You bypassed the Cloudflare challenge! :D", "main")
challenge_bypassed = True
except TextNotVisibleException:
# The text did not appear
challenge_bypassed = False
# Close the browser and release its resources
driver.quit()
print("Cloudflare Bypassed:", challenge_bypassed) En mode uc=True (qui utilise undetected-chromedriver sous le capot), SeleniumBase peut tirer parti de la méthode dédiée uc_gui_click_captcha() pour gérer le CAPTCHA du Tourniquet, s’il apparaît. Cela signifie qu’il n’y a pas besoin de logique de clic personnalisée cette fois-ci.
Exécutez le script et vous devriez voir :
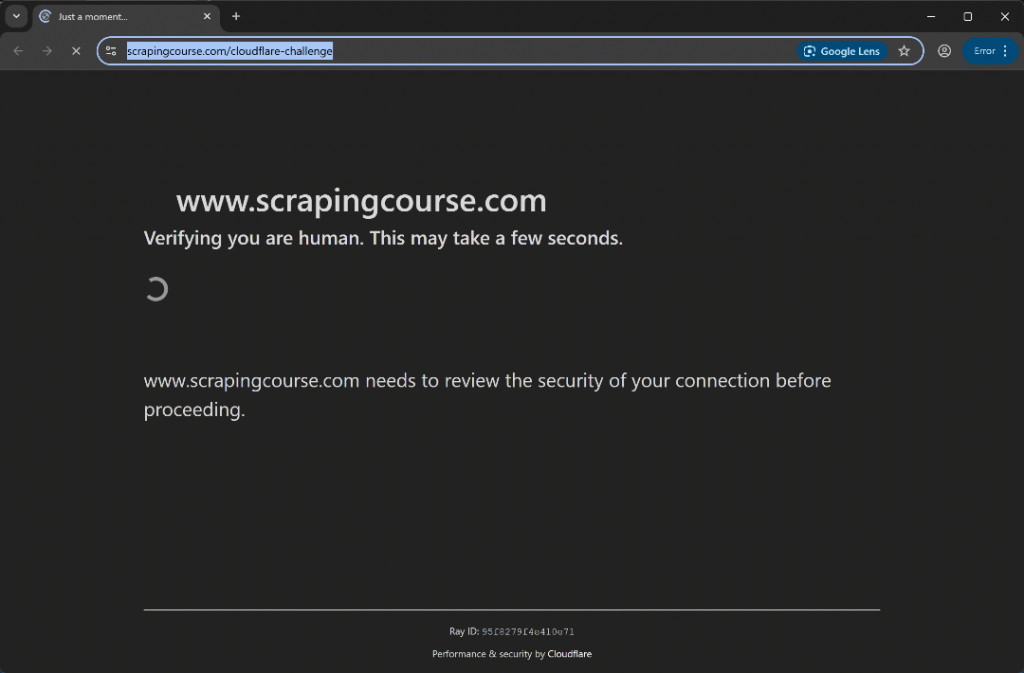
Cette fois, le script d’automatisation contourne la phase de vérification initiale sans même déclencher le CAPTCHA Turnstile. De toute façon, la méthode uc_gui_click_captcha() aurait été capable de le gérer avec succès. Ceci est possible grâce au mode UC, que vous pouvez découvrir dans notre guide SeleniumBase scraping.
Et voilà ! Cloudflare a été contourné une fois de plus.
Comment contourner Cloudflare à grande échelle
Les deux bibliothèques présentées précédemment fonctionnent bien pour les scripts d’automatisation simples, mais présentent trois inconvénients majeurs :
- Pour obtenir un pourcentage élevé de résultats efficaces, ils doivent faire fonctionner les navigateurs en mode tête. Cela consomme beaucoup de ressources système et rend l’extensibilité plus difficile.
- Elles sont incohérentes et peuvent cesser de fonctionner temporairement si Cloudflare met à jour sa logique de détection. Étant donné que ces solutions sont maintenues par la communauté, les mises à jour peuvent prendre des jours, voire des semaines, avant d’être publiées.
- Il n’existe pas de support officiel. Vous devez compter sur les ressources en ligne et l’aide de la communauté.
Pour ces raisons, les bibliothèques open-source dotées de capacités de contournement de Cloudflare ne sont pas recommandées pour les projets de production. Pour obtenir des résultats plus évolutifs et plus cohérents, ainsi que le soutien d’une équipe d’assistancedédiée 24 heures sur 24 et 7 jours sur 7, vousavez besoin de produits haut de gamme tels que ceux fournis par Bright Data.
Plus précisément, nous nous concentrerons ici sur les deux solutions suivantes :
- Web Unlocker: Un point final de scraping tout-en-un qui inclut toutes les capacités de contournement anti-bot pour récupérer le code HTML de n’importe quel site.
- Navigateur API: Un navigateur cloud infiniment évolutif conçu pour prendre en charge n’importe quel flux de travail d’automatisation. Il s’intègre à Puppeteer, Selenium, Playwright et à tout autre outil d’automatisation par navigateur. Il comprend une gestion avancée des empreintes digitales, une résolution CAPTCHA intégrée et une rotation automatisée du proxy.
Découvrez comment intégrer ces outils en Python (bien qu’ils supportent n’importe quel langage de programmation) dans vos scripts d’automatisation !
Contourner Cloudflare avec Web Unlocker
Avant de commencer, suivez le guide officiel pour configurer gratuitement Web Unlocker dans votre compte Bright Data. Vous devrez également générer une clé d’API Bright Data pour authentifier vos requêtes au point de terminaison Web Unlocker.
Nous supposerons ici que le nom de votre zone Web Unlocker est web_unlocker.
Une fois les étapes ci-dessus terminées, testez Web Unlocker sur la page cible utilisée dans cet article :
# pip install requests
import requests
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Replace with your Bright Data API key
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
data = {
"zone": "web_unlocker", # Replace with the name of your Web Unlocker zone
"url": "https://www.scrapingcourse.com/cloudflare-challenge",
"format": "raw"
}
# Perform a request to the Web Unlocker endpoint
response = requests.post(
"https://api.brightdata.com/request",
json=data,
headers=headers
)
# Get the response and check if Cloudflare was bypassed
html = response.text
print("Cloudflare Bypassed:", "You bypassed the Cloudflare challenge! :D" in html)Web Unlocker renvoie le contenu HTML de la page derrière le mur de vérification Cloudflare. En particulier, la variable html contiendra un contenu comme celui-ci :
<!doctype html>
<html lang="en"><head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Cloudflare Challenge - ScrapingCourse.com</title>
<!-- omitted for brevity ... -->
<main class="page-content py-4" id="main-content" data-testid="main-content" data-content="main">
<div class="container" id="content-container" data-testid="content-container" data-content="container">
<div class="cloudflareChallenge">
<h1 id="page-title" class="page-title text-4xl font-bold mb-2 text-left gradient-text highlight gradient-text leading-10" data-testid="page-title" data-content="title">
Cloudflare Challenge
</h1>
<div class="challenge-info bg-[#EDF1FD] rounded-md p-4 mb-8 mt-5" id="challenge-info" data-testid="challenge-info" data-content="challenge-info">
<div class="info-header flex items-center gap-2 pb-2" id="info-header" data-testid="info-header" data-content="info-header">
<img width="25" height="15" src="https://www.scrapingcourse.com/assets/images/challenge.svg" data-testid="challenge-image" data-content="challenge-image">
<h2 class="challenge-title text-xl font-bold" id="challenge-title" data-testid="challenge-title" data-content="challenge-title">
You bypassed the Cloudflare challenge! 😀
</h2>
</div>
</div>
</div>
</div>
</main>
<!-- omitted for brevity ... -->
</html>C’est exactement le contenu HTML de la page derrière le mur de vérification humaine de Cloudflare. Il n’est donc pas surprenant que la sortie du script soit :
Cloudflare Bypassed: TrueNotez que vous ne serez facturé que pour les demandes acceptées et qu’une version d’essai gratuite est disponible !
Automatiser Cloudflare avec l’API du navigateur
Comme condition préalable, configurez un produit Browser API dans votre compte Bright Data. Sur la page de la zone, copiez l’URL de connexion Playwright CDP :
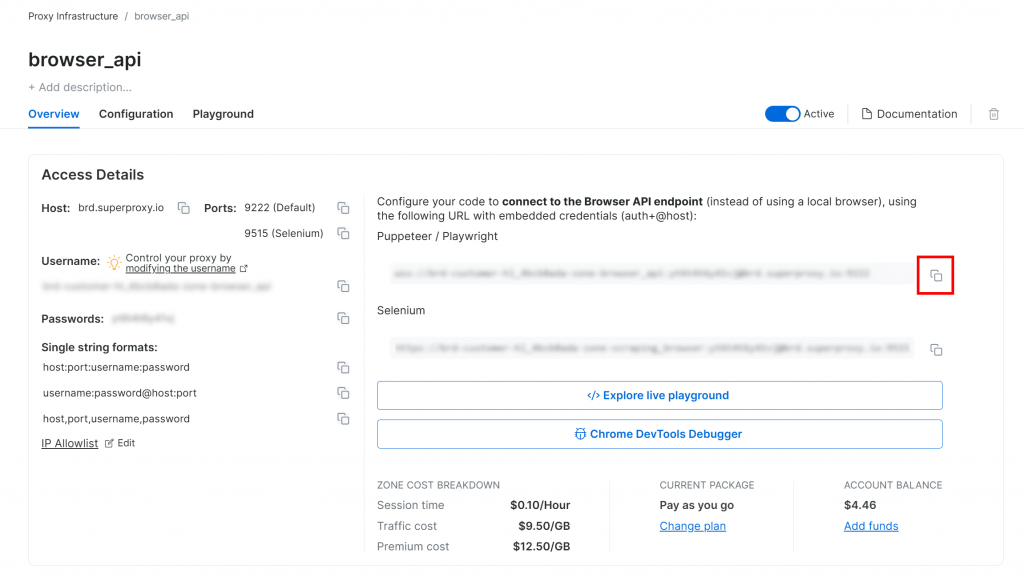
Cette URL contient vos informations d’identification et vous permet d’indiquer à toute solution d’automatisation de navigateur prenant en charge leprotocole CDP (Chrome DevTools Protocol) à distance de se connecter à l’API du navigateur Bright Data. En d’autres termes, votre outil d’automatisation fonctionnera sur une instance de navigateur hébergée à distance et gérée par Bright Data. Cela signifie que l’évolutivité et la maintenance du navigateur sont gérées pour vous.
Étendez le script Playwright présenté précédemment pour vous connecter à l’API du navigateur via l’URL CDP :
# pip install playwright
# python install -m playwright install
from playwright.sync_api import sync_playwright
from playwright.sync_api import TimeoutError
BRIGHT_DATA_API_CDP_URL = "<YOUR_BRIGHT_DATA_API_CDP_URL>" # Replace with your Browser API Playwright CDP URL
with sync_playwright() as p:
# Connect to the remote Browser API
browser = p.chromium.connect_over_cdp(BRIGHT_DATA_API_CDP_URL)
page = browser.new_page()
# Go to the target page
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
try:
# Wait for the desired text to be on the page
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
challenge_bypassed = False
# Close the browser and release its resources
browser.close()
print("Cloudflare Bypassed:", challenge_bypassed)Cette fois, le script contournera avec succès la vérification de Cloudflare grâce aux capacités avancées de l’API du navigateur. Vous verrez la sortie suivante dans le terminal :
Cloudflare Bypassed: TrueBravo ! Le contournement de Cloudflare n’est plus un problème.
Conclusion
Dans cet article, vous avez appris comment fonctionne Cloudflare et exploré des solutions pratiques pour le contourner dans vos flux d’automatisation. Comme vous l’avez vu, contourner les mesures anti-scraping de Cloudflare est un défi, mais certainement possible.
Quelle que soit l’approche choisie, tout devient plus facile avec des solutions professionnelles, rapides et fiables telles que :
- Web Unlocker: Un point d’accès qui contourne automatiquement les limitations de débit, les empreintes digitales et d’autres restrictions anti-bots.
- Browser API: Un navigateur entièrement hébergé qui vous permet d’automatiser l’interaction avec n’importe quelle page web.
Inscrivez-vous gratuitement et découvrez les solutions de Bright Data qui répondent le mieux à vos besoins !





